Thread: [PATCH] Add sortsupport for range types and btree_gist
Hi all!
The motivation behind this is that incrementally building up a GiST
index for certain input data can create a terrible tree structure.
Furthermore, exclusion constraints are commonly implemented using GiST
indices and for that use case, data is mostly orderable.
By sorting the data before inserting it into the index results in a much
better index structure, leading to significant performance improvements.
Testing was done using following setup, with about 50 million rows:
CREATE EXTENSION btree_gist;
CREATE TABLE t (id uuid, block_range int4range);
CREATE INDEX ON before USING GIST (id, block_range);
COPY t FROM '..' DELIMITER ',' CSV HEADER;
using
SELECT * FROM t WHERE id = '..' AND block_range && '..'
as test query, using a unpatched instance and one with the patch applied.
Some stats for fetching 10,000 random rows using the query above,
100 iterations to get good averages.
The benchmarking was done on a unpatched instance compiled using the
exact same options as with the patch applied.
[ Results are noted in a unpatched -> patched fashion. ]
First set of results are after the initial CREATE TABLE, CREATE INDEX
and a COPY to the table, thereby incrementally building the index.
Shared Hit Blocks (average): 110.97 -> 78.58
Shared Read Blocks (average): 58.90 -> 47.42
Execution Time (average): 1.10 -> 0.83 ms
I/O Read Time (average): 0.19 -> 0.15 ms
After a REINDEX on the table, the results improve even more:
Shared Hit Blocks (average): 84.24 -> 8.54
Shared Read Blocks (average): 49.89 -> 0.74
Execution Time (average): 0.84 -> 0.065 ms
I/O Read Time (average): 0.16 -> 0.004 ms
Additionally, the time a REINDEX takes also improves significantly:
672407.584 ms (11:12.408) -> 130670.232 ms (02:10.670)
Most of the sortsupport for btree_gist was implemented by re-using
already existing infrastructure. For the few remaining types (bit, bool,
cash, enum, interval, macaddress8 and time) I manually implemented them
directly in btree_gist.
It might make sense to move them into the backend for uniformity, but I
wanted to get other opinions on that first.
`make check-world` reports no regressions.
Attached below, besides the patch, are also two scripts for benchmarking.
`bench-gist.py` to benchmark the actual patch, example usage of this
would be e.g. `./bench-gist.py -o results.csv public.table`. This
expects a local instance with no authentication and default `postgres`
user. The port can be set using the `--port` option.
`plot.py` prints average values (as used above) and creates boxplots for
each statistic from the result files produced with `bench-gist.py`.
Depends on matplotlib and pandas.
Additionally, if needed, the sample dataset used to benchmark this is
available to independently verify the results [1].
Thanks,
Christoph Heiss
---
[1] https://drive.google.com/file/d/1SKRiUYd78_zl7CeD8pLDoggzCCh0wj39
Attachment
Hi Christoph! > On 15 Jun 2022, at 15:45, Christoph Heiss <christoph.heiss@cybertec.at> wrote: > > By sorting the data before inserting it into the index results in a much better index structure, leading to significantperformance improvements. Here's my version of the very similar idea [0]. It lacks range types support. On a quick glance your version lacks support of abbreviated sort, so I think benchmarks can be pushed event further :) Let's merge our efforts and create combined patch? Please, create a new entry for the patch on Commitfest. Thank you! Best regards, Andrey Borodin. [0] https://commitfest.postgresql.org/37/2824/
On Wed, Jun 15, 2022 at 3:45 AM Christoph Heiss
<christoph.heiss@cybertec.at> wrote:
> `make check-world` reports no regressions.
cfbot is reporting a crash in contrib/btree_gist:
https://cirrus-ci.com/github/postgresql-cfbot/postgresql/commitfest/38/3686
Thanks,
--Jacob
This entry has been waiting on author input for a while (our current
threshold is roughly two weeks), so I've marked it Returned with
Feedback.
Once you think the patchset is ready for review again, you (or any
interested party) can resurrect the patch entry by visiting
https://commitfest.postgresql.org/38/3686/
and changing the status to "Needs Review", and then changing the
status again to "Move to next CF". (Don't forget the second step;
hopefully we will have streamlined this in the near future!)
Thanks,
--Jacob
Hi! Sorry for the long delay. This fixes the crashes, now all tests run fine w/ and w/o debug configuration. That shouldn't even have slipped through as such. Notable changes from v1: - gbt_enum_sortsupport() now passes on fcinfo->flinfo enum_cmp_internal() needs a place to cache the typcache entry. - inet sortsupport now uses network_cmp() directly Thanks, Christoph Heiss
Attachment
Hi, On 2022-08-31 21:15:40 +0200, Christoph Heiss wrote: > Notable changes from v1: > - gbt_enum_sortsupport() now passes on fcinfo->flinfo > enum_cmp_internal() needs a place to cache the typcache entry. > - inet sortsupport now uses network_cmp() directly Updated the patch to add the minimal change for meson compat. Greetings, Andres Freund
Attachment
On 2022-10-02 00:23:32 -0700, Andres Freund wrote: > Updated the patch to add the minimal change for meson compat. Now I made the same mistake of not adding the change... Clearly I need to stop for tonight. Either way, here's the hopefully correct change.
Attachment
Hi,
No deep code review yet, but CF is approaching its end and i didn't
have time to look at this earlier :/
Below are some things i've tested so far.
Am Mittwoch, dem 15.06.2022 um 12:45 +0200 schrieb Christoph Heiss:
> Testing was done using following setup, with about 50 million rows:
>
> CREATE EXTENSION btree_gist;
> CREATE TABLE t (id uuid, block_range int4range);
> CREATE INDEX ON before USING GIST (id, block_range);
> COPY t FROM '..' DELIMITER ',' CSV HEADER;
>
> using
>
> SELECT * FROM t WHERE id = '..' AND block_range && '..'
>
> as test query, using a unpatched instance and one with the patch
> applied.
>
> Some stats for fetching 10,000 random rows using the query above,
> 100 iterations to get good averages.
>
Here are my results with repeating this:
HEAD:
-- token index (buffering=auto)
CREATE INDEX Time: 700213,110 ms (11:40,213)
HEAD patched:
-- token index (buffering=auto)
CREATE INDEX Time: 136229,400 ms (02:16,229)
So index creation speed on the test set (table filled with the tokens
and then creating the index afterwards) gets a lot of speedup with this
patch and default buffering strategy.
> The benchmarking was done on a unpatched instance compiled using the
> > exact same options as with the patch applied.
> > [ Results are noted in a unpatched -> patched fashion. ]
> >
> > First set of results are after the initial CREATE TABLE, CREATE
> INDEX
> > and a COPY to the table, thereby incrementally building the index.
> >
> > Shared Hit Blocks (average): 110.97 -> 78.58
> > Shared Read Blocks (average): 58.90 -> 47.42
> > Execution Time (average): 1.10 -> 0.83 ms
> > I/O Read Time (average): 0.19 -> 0.15 ms
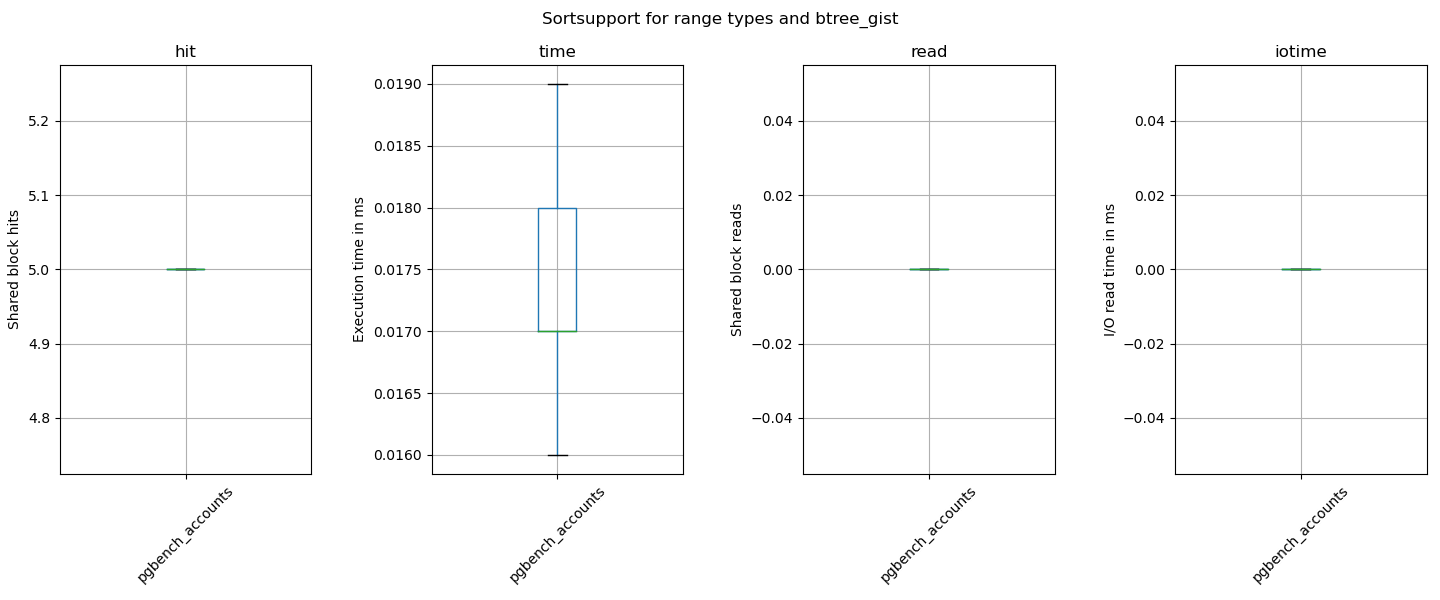
I've changed this a little and did the following:
CREATE EXTENSION btree_gist;
CREATE TABLE t (id uuid, block_range int4range);
COPY t FROM '..' DELIMITER ',' CSV HEADER;
CREATE INDEX ON before USING GIST (id, block_range);
So creating the index _after_ having loaded the tokens.
My configuration was:
shared_buffers = 4G
max_wal_size = 6G
effective_cache_size = 4g # (default, index fits)
maintenance_work_mem = 1G
Here are my numbers from the attached benchmark script
HEAD -> HEAD patched:
Shared Hit Blocks (avg) : 76.81 -> 9.17
Shared Read Blocks (avg): 0.43 -> 0.11
Execution Time (avg) : 0.40 -> 0.05
IO Read Time (avg) : 0.001 -> 0.0007
So with these settings i see an improvement with the provided test set.
Since this patches adds sortsupport for all other existing opclasses, i
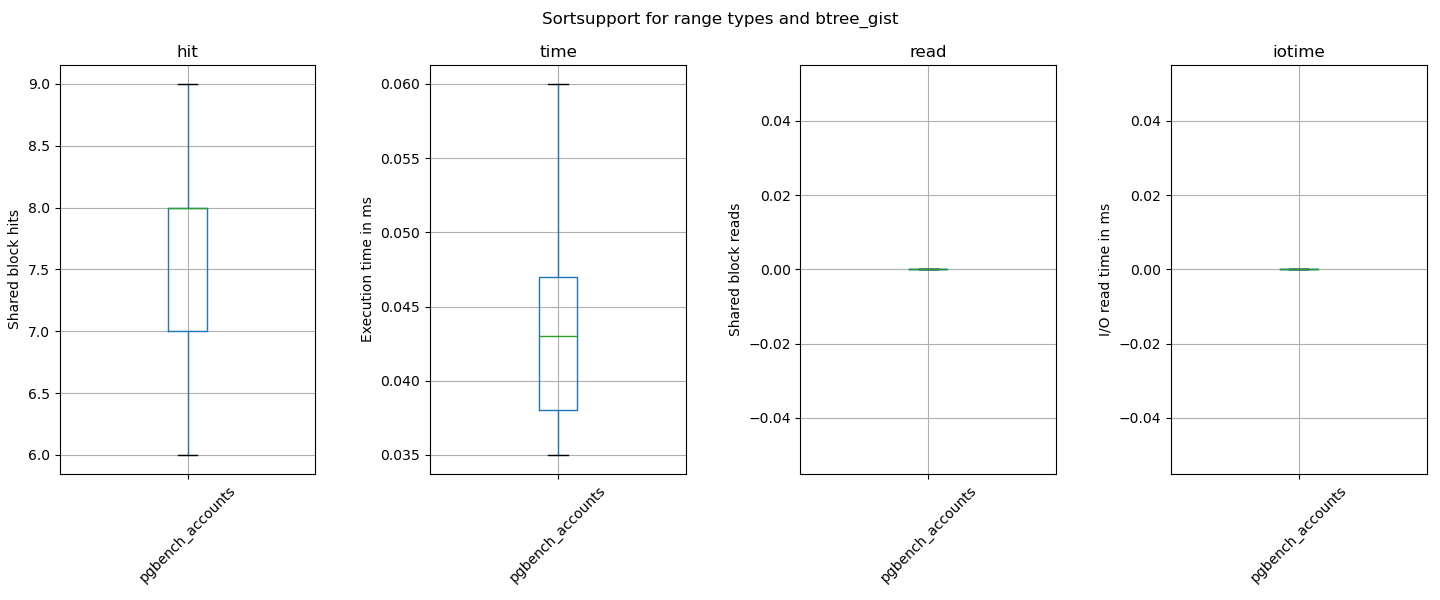
thought to give it a try with another test set. What i did was to adapt
the benchmark script (see attached) to use the "pgbench_accounts" table
which i changed to instead using the primary key to have a btree_gist
index on column "aid".
I let pgbench fill its tables with scale = 1000, dropped the primary
key, create the btree_gist on "aid" with default buffering strategy:
pgbench -s 1000 -i bernd
ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey ;
CREATE INDEX ON pgbench_accounts USING gist(aid);
Ran the benchmark script bench-gist-pgbench_accounts.py:
The numbers are:
HEAD -> HEAD patched
Shared Hit Blocks (avg) : 4.85 -> 8.75
Shared Read Blocks (avg): 0.14 -> 0.17
Execution Time (avg) : 0.01 -> 0.05
IO Read Time (avg) : 0.0003 -> 0.0009
So numbers got worse here. You can uncover this when using pgbench
against that modified table in a much more worse outcome.
Running
pgbench -s 1000 -c 16 -j 16 -S -Mprepared -T 300
on my workstation at least 3 times gives me the following numbers:
HEAD:
tps = 215338.784398 (without initial connection time)
tps = 212826.513727 (without initial connection time)
tps = 212102.857891 (without initial connection time)
HEAD patched:
tps = 126487.796716 (without initial connection time)
tps = 125076.391528 (without initial connection time)
tps = 124538.946388 (without initial connection time)
So this doesn't look good. While this patch gets a real improvement for
the provided tokens, it makes performance for at least int4 on this
test worse. Though the picture changes again if you build the index
buffered:
tps = 198409.248911 (without initial connection time)
tps = 194431.827394 (without initial connection time)
tps = 195657.532281 (without initial connection time)
which is again close to current HEAD (i have no idea why it is even
*that* slower, since "buffered=on" shouldn't employ sortsupport, no?).
Of course, built time for the index in this case is much slower again:
-- pgbench_accounts index (buffered)
CREATE INDEX Time: 900912,924 ms (15:00,913)
So while providing a huge improvement on index creation speed it's
sometimes still required to carefully check the index quality.
[...]
> Most of the sortsupport for btree_gist was implemented by re-using
> already existing infrastructure. For the few remaining types (bit,
> bool,
> cash, enum, interval, macaddress8 and time) I manually implemented
> them
> directly in btree_gist.
> It might make sense to move them into the backend for uniformity, but
> I
> wanted to get other opinions on that first.
Hmm i'd say we leave them in the contrib module until they are required
somewhere else, too or make a separate patch for them? Do we have plans
to have such requirement in the backend already?
Attached is a rebased patch against current HEAD.
Thanks
Bernd
Attachment
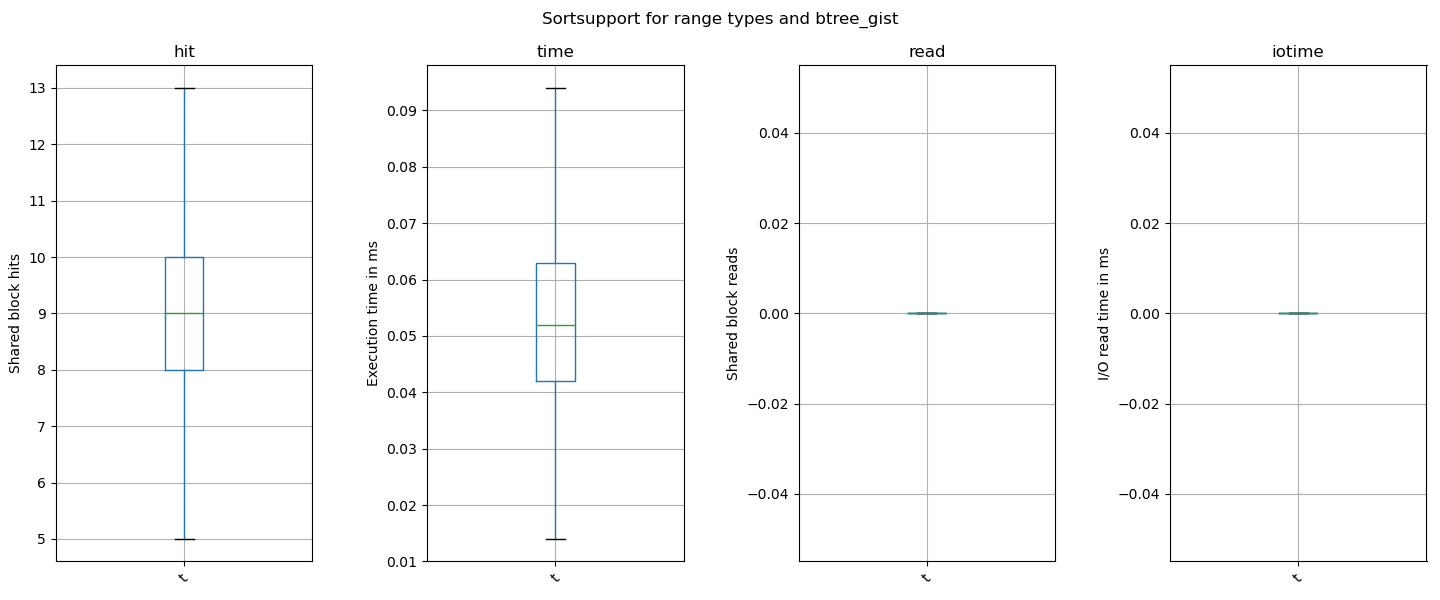{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Thu, Dec 1, 2022 at 1:27 AM Bernd Helmle <mailings@oopsware.de> wrote:
>
> Hi,
>
> No deep code review yet, but CF is approaching its end and i didn't
> have time to look at this earlier :/
>
> Below are some things i've tested so far.
>
> Am Mittwoch, dem 15.06.2022 um 12:45 +0200 schrieb Christoph Heiss:
>
>
> > Testing was done using following setup, with about 50 million rows:
> >
> > CREATE EXTENSION btree_gist;
> > CREATE TABLE t (id uuid, block_range int4range);
> > CREATE INDEX ON before USING GIST (id, block_range);
> > COPY t FROM '..' DELIMITER ',' CSV HEADER;
> >
> > using
> >
> > SELECT * FROM t WHERE id = '..' AND block_range && '..'
> >
> > as test query, using a unpatched instance and one with the patch
> > applied.
> >
> > Some stats for fetching 10,000 random rows using the query above,
> > 100 iterations to get good averages.
> >
>
> Here are my results with repeating this:
>
> HEAD:
> -- token index (buffering=auto)
> CREATE INDEX Time: 700213,110 ms (11:40,213)
>
> HEAD patched:
>
> -- token index (buffering=auto)
> CREATE INDEX Time: 136229,400 ms (02:16,229)
>
> So index creation speed on the test set (table filled with the tokens
> and then creating the index afterwards) gets a lot of speedup with this
> patch and default buffering strategy.
>
> > The benchmarking was done on a unpatched instance compiled using the
> > > exact same options as with the patch applied.
> > > [ Results are noted in a unpatched -> patched fashion. ]
> > >
> > > First set of results are after the initial CREATE TABLE, CREATE
> > INDEX
> > > and a COPY to the table, thereby incrementally building the index.
> > >
> > > Shared Hit Blocks (average): 110.97 -> 78.58
> > > Shared Read Blocks (average): 58.90 -> 47.42
> > > Execution Time (average): 1.10 -> 0.83 ms
> > > I/O Read Time (average): 0.19 -> 0.15 ms
>
> I've changed this a little and did the following:
>
> CREATE EXTENSION btree_gist;
> CREATE TABLE t (id uuid, block_range int4range);
> COPY t FROM '..' DELIMITER ',' CSV HEADER;
> CREATE INDEX ON before USING GIST (id, block_range);
>
> So creating the index _after_ having loaded the tokens.
> My configuration was:
>
> shared_buffers = 4G
> max_wal_size = 6G
> effective_cache_size = 4g # (default, index fits)
> maintenance_work_mem = 1G
>
>
> Here are my numbers from the attached benchmark script
>
> HEAD -> HEAD patched:
>
> Shared Hit Blocks (avg) : 76.81 -> 9.17
> Shared Read Blocks (avg): 0.43 -> 0.11
> Execution Time (avg) : 0.40 -> 0.05
> IO Read Time (avg) : 0.001 -> 0.0007
>
> So with these settings i see an improvement with the provided test set.
> Since this patches adds sortsupport for all other existing opclasses, i
> thought to give it a try with another test set. What i did was to adapt
> the benchmark script (see attached) to use the "pgbench_accounts" table
> which i changed to instead using the primary key to have a btree_gist
> index on column "aid".
>
> I let pgbench fill its tables with scale = 1000, dropped the primary
> key, create the btree_gist on "aid" with default buffering strategy:
>
> pgbench -s 1000 -i bernd
>
> ALTER TABLE pgbench_accounts DROP CONSTRAINT pgbench_accounts_pkey ;
> CREATE INDEX ON pgbench_accounts USING gist(aid);
>
> Ran the benchmark script bench-gist-pgbench_accounts.py:
>
\d pgbench_accounts
Table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------
aid | integer | | not null |
bid | integer | | |
abalance | integer | | |
filler | character(84) | | |
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
you do `CREATE INDEX ON pgbench_accounts USING gist(aid);`
but the original patch didn't change contrib/btree_gist/btree_int4.c
So I doubt your benchmark is related to the original patch.
or maybe I missed something.
also per doc:
`
sortsupport
Returns a comparator function to sort data in a way that preserves
locality. It is used by CREATE INDEX and REINDEX commands. The quality
of the created index depends on how well the sort order determined by
the comparator function preserves locality of the inputs.
`
from the doc, add sortsupport function will only influence index build time?
+/*
+ * GiST sortsupport comparator for ranges.
+ *
+ * Operates solely on the lower bounds of the ranges, comparing them using
+ * range_cmp_bounds().
+ * Empty ranges are sorted before non-empty ones.
+ */
+static int
+range_gist_cmp(Datum a, Datum b, SortSupport ssup)
+{
+ RangeType *range_a = DatumGetRangeTypeP(a);
+ RangeType *range_b = DatumGetRangeTypeP(b);
+ TypeCacheEntry *typcache = ssup->ssup_extra;
+ RangeBound lower1,
+ lower2;
+ RangeBound upper1,
+ upper2;
+ bool empty1,
+ empty2;
+ int result;
+
+ if (typcache == NULL) {
+ Assert(RangeTypeGetOid(range_a) == RangeTypeGetOid(range_b));
+ typcache = lookup_type_cache(RangeTypeGetOid(range_a), TYPECACHE_RANGE_INFO);
+
+ /*
+ * Cache the range info between calls to avoid having to call
+ * lookup_type_cache() for each comparison.
+ */
+ ssup->ssup_extra = typcache;
+ }
+
+ range_deserialize(typcache, range_a, &lower1, &upper1, &empty1);
+ range_deserialize(typcache, range_b, &lower2, &upper2, &empty2);
+
+ /* For b-tree use, empty ranges sort before all else */
+ if (empty1 && empty2)
+ result = 0;
+ else if (empty1)
+ result = -1;
+ else if (empty2)
+ result = 1;
+ else
+ result = range_cmp_bounds(typcache, &lower1, &lower2);
+
+ if ((Datum) range_a != a)
+ pfree(range_a);
+
+ if ((Datum) range_b != b)
+ pfree(range_b);
+
+ return result;
+}
per https://www.postgresql.org/docs/current/gist-extensibility.html
QUOTE:
All the GiST support methods are normally called in short-lived memory
contexts; that is, CurrentMemoryContext will get reset after each
tuple is processed. It is therefore not very important to worry about
pfree'ing everything you palloc. However, in some cases it's useful
for a support method to
ENDOF_QUOTE
so removing the following part should be OK.
+ if ((Datum) range_a != a)
+ pfree(range_a);
+
+ if ((Datum) range_b != b)
+ pfree(range_b);
comparison solely on the lower bounds looks strange to me.
if lower bound is the same, then compare upper bound, so the
range_gist_cmp function is consistent with function range_compare.
so following change:
+ else
+ result = range_cmp_bounds(typcache, &lower1, &lower2);
to
`
else
{
result = range_cmp_bounds(typcache, &lower1, &lower2);
if (result == 0)
result = range_cmp_bounds(typcache, &upper1, &upper2);
}
`
does contrib/btree_gist/btree_gist--1.7--1.8.sql function be declared
as strict ? (I am not sure)
other than that, the whole patch looks good.
On Wed, Jan 10, 2024 at 8:00 AM jian he <jian.universality@gmail.com> wrote:
>
> `
> from the doc, add sortsupport function will only influence index build time?
>
> +/*
> + * GiST sortsupport comparator for ranges.
> + *
> + * Operates solely on the lower bounds of the ranges, comparing them using
> + * range_cmp_bounds().
> + * Empty ranges are sorted before non-empty ones.
> + */
> +static int
> +range_gist_cmp(Datum a, Datum b, SortSupport ssup)
> +{
> + RangeType *range_a = DatumGetRangeTypeP(a);
> + RangeType *range_b = DatumGetRangeTypeP(b);
> + TypeCacheEntry *typcache = ssup->ssup_extra;
> + RangeBound lower1,
> + lower2;
> + RangeBound upper1,
> + upper2;
> + bool empty1,
> + empty2;
> + int result;
> +
> + if (typcache == NULL) {
> + Assert(RangeTypeGetOid(range_a) == RangeTypeGetOid(range_b));
> + typcache = lookup_type_cache(RangeTypeGetOid(range_a), TYPECACHE_RANGE_INFO);
> +
> + /*
> + * Cache the range info between calls to avoid having to call
> + * lookup_type_cache() for each comparison.
> + */
> + ssup->ssup_extra = typcache;
> + }
> +
> + range_deserialize(typcache, range_a, &lower1, &upper1, &empty1);
> + range_deserialize(typcache, range_b, &lower2, &upper2, &empty2);
> +
> + /* For b-tree use, empty ranges sort before all else */
> + if (empty1 && empty2)
> + result = 0;
> + else if (empty1)
> + result = -1;
> + else if (empty2)
> + result = 1;
> + else
> + result = range_cmp_bounds(typcache, &lower1, &lower2);
> +
> + if ((Datum) range_a != a)
> + pfree(range_a);
> +
> + if ((Datum) range_b != b)
> + pfree(range_b);
> +
> + return result;
> +}
>
> per https://www.postgresql.org/docs/current/gist-extensibility.html
> QUOTE:
> All the GiST support methods are normally called in short-lived memory
> contexts; that is, CurrentMemoryContext will get reset after each
> tuple is processed. It is therefore not very important to worry about
> pfree'ing everything you palloc. However, in some cases it's useful
> for a support method to
> ENDOF_QUOTE
>
> so removing the following part should be OK.
> + if ((Datum) range_a != a)
> + pfree(range_a);
> +
> + if ((Datum) range_b != b)
> + pfree(range_b);
>
> comparison solely on the lower bounds looks strange to me.
> if lower bound is the same, then compare upper bound, so the
> range_gist_cmp function is consistent with function range_compare.
> so following change:
>
> + else
> + result = range_cmp_bounds(typcache, &lower1, &lower2);
> to
> `
> else
> {
> result = range_cmp_bounds(typcache, &lower1, &lower2);
> if (result == 0)
> result = range_cmp_bounds(typcache, &upper1, &upper2);
> }
> `
>
> does contrib/btree_gist/btree_gist--1.7--1.8.sql function be declared
> as strict ? (I am not sure)
> other than that, the whole patch looks good.
the original author email address (christoph.heiss@cybertec.at)
Address not found.
so I don't include it.
I split the original author's patch into 2.
1. Add GiST sortsupport function for all the btree-gist module data
types except anyrange data type (which actually does not in this
module)
2. Add GiST sortsupport function for anyrange data type.
What changed compared to the original patch:
1. The original patch missed some operator class for all the data
types in btree-gist modules. So I added them.
now add sortsupport function for all the following data types in btree-gist:
int2,int4,int8,float4,float8,numeric
timestamp with time zone,
timestamp without time zone, time with time zone, time without time zone, date
interval, oid, money, char
varchar, text, bytea, bit, varbit
macaddr, macaddr8, inet, cidr, uuid, bool, enum
2. range_gist_cmp: the gist range sortsupport function, it looks like
range_cmp, but the range typcache is cached,
so we don't need to repeatedly call lookup_type_cache.
refactor: As mentioned above, if the range lower bound is the same
then compare the upper bound.
I aslo refactored the comment.
what I am confused:
In fmgr.h
/*
* Support for cleaning up detoasted copies of inputs. This must only
* be used for pass-by-ref datatypes, and normally would only be used
* for toastable types. If the given pointer is different from the
* original argument, assume it's a palloc'd detoasted copy, and pfree it.
* NOTE: most functions on toastable types do not have to worry about this,
* but we currently require that support functions for indexes not leak
* memory.
*/
#define PG_FREE_IF_COPY(ptr,n) \
do { \
if ((Pointer) (ptr) != PG_GETARG_POINTER(n)) \
pfree(ptr); \
} while (0)
but the doc (https://www.postgresql.org/docs/current/gist-extensibility.html)
says:
All the GiST support methods are normally called in short-lived memory
contexts; that is, CurrentMemoryContext will get reset after each
tuple is processed. It is therefore not very important to worry about
pfree'ing everything you palloc.
ENDOF_QUOTE
so I am not sure in range_gist_cmp, we need the following:
`
if ((Datum) range_a != a)
pfree(range_a);
if ((Datum) range_b != b)
pfree(range_b);
`
Attachment
> On 10 Jan 2024, at 19:18, jian he <jian.universality@gmail.com> wrote:
>
> what I am confused:
> In fmgr.h
>
> /*
> * Support for cleaning up detoasted copies of inputs. This must only
> * be used for pass-by-ref datatypes, and normally would only be used
> * for toastable types. If the given pointer is different from the
> * original argument, assume it's a palloc'd detoasted copy, and pfree it.
> * NOTE: most functions on toastable types do not have to worry about this,
> * but we currently require that support functions for indexes not leak
> * memory.
> */
> #define PG_FREE_IF_COPY(ptr,n) \
> do { \
> if ((Pointer) (ptr) != PG_GETARG_POINTER(n)) \
> pfree(ptr); \
> } while (0)
>
> but the doc (https://www.postgresql.org/docs/current/gist-extensibility.html)
> says:
> All the GiST support methods are normally called in short-lived memory
> contexts; that is, CurrentMemoryContext will get reset after each
> tuple is processed. It is therefore not very important to worry about
> pfree'ing everything you palloc.
> ENDOF_QUOTE
>
> so I am not sure in range_gist_cmp, we need the following:
> `
> if ((Datum) range_a != a)
> pfree(range_a);
> if ((Datum) range_b != b)
> pfree(range_b);
> `
I think GiST sortsupport comments are more relevant, so there's no need for this pfree()s.
Also, please check other thread, maybe you will find some useful code there [0,1]. It was committed[2] once, but
reverted.Please make sure that corrections made there are taken into account in your patch.
Thanks for working on this!
Best regards, Andrey Borodin.
[0] https://commitfest.postgresql.org/31/2824/
[1]
https://www.postgresql.org/message-id/flat/285041639646332%40sas1-bf93f9015d57.qloud-c.yandex.net#0e5b4ed57d861d38a3d836c9ec09c0c5
[2] https://github.com/postgres/postgres/commit/9f984ba6d23dc6eecebf479ab1d3f2e550a4e9be
Am Mittwoch, dem 10.01.2024 um 08:00 +0800 schrieb jian he: > you do `CREATE INDEX ON pgbench_accounts USING gist(aid);` > but the original patch didn't change contrib/btree_gist/btree_int4.c > So I doubt your benchmark is related to the original patch. > or maybe I missed something. > The patch originally does this: +ALTER OPERATOR FAMILY gist_int4_ops USING gist ADD + FUNCTION 11 (int4, int4) btint4sortsupport (internal) ; This adds sortsupport function to int4 as well. We reuse existing btint4sortsupport() function, so no need to change btree_int4.c. > also per doc: > ` > sortsupport > Returns a comparator function to sort data in a way that preserves > locality. It is used by CREATE INDEX and REINDEX commands. The > quality > of the created index depends on how well the sort order determined by > the comparator function preserves locality of the inputs. > ` > from the doc, add sortsupport function will only influence index > build time? > Thats the point of this patch. Though it influences the index quality in a way which seems to cause the measured performance regression upthread. > > per https://www.postgresql.org/docs/current/gist-extensibility.html > QUOTE: > All the GiST support methods are normally called in short-lived > memory > contexts; that is, CurrentMemoryContext will get reset after each > tuple is processed. It is therefore not very important to worry about > pfree'ing everything you palloc. However, in some cases it's useful > for a support method to > ENDOF_QUOTE > > so removing the following part should be OK. > + if ((Datum) range_a != a) > + pfree(range_a); > + > + if ((Datum) range_b != b) > + pfree(range_b); > Probably, i think we get a different range objects in case of detoasting in this case. > comparison solely on the lower bounds looks strange to me. > if lower bound is the same, then compare upper bound, so the > range_gist_cmp function is consistent with function range_compare. > so following change: > > + else > + result = range_cmp_bounds(typcache, &lower1, &lower2); > to > ` > else > { > result = range_cmp_bounds(typcache, &lower1, &lower2); > if (result == 0) > result = range_cmp_bounds(typcache, &upper1, &upper2); > } > ` > > does contrib/btree_gist/btree_gist--1.7--1.8.sql function be declared > as strict ? (I am not sure) > other than that, the whole patch looks good. > > That's something surely to consider.
Am Mittwoch, dem 10.01.2024 um 20:13 +0500 schrieb Andrey M. Borodin: > I think GiST sortsupport comments are more relevant, so there's no > need for this pfree()s. > > Also, please check other thread, maybe you will find some useful code > there [0,1]. It was committed[2] once, but reverted. Please make sure > that corrections made there are taken into account in your patch. > At least, i believe we have the same problem described here (many thanks Andrey for the links, i wasn't aware about this discussion): https://www.postgresql.org/message-id/98b34b51-a6db-acc4-1bcf-a29caf69bbc7%40iki.fi > Thanks for working on this! Absolutely. This patch needs input ...
On Wed, 10 Jan 2024 at 19:49, jian he <jian.universality@gmail.com> wrote:
>
> On Wed, Jan 10, 2024 at 8:00 AM jian he <jian.universality@gmail.com> wrote:
> >
> > `
> > from the doc, add sortsupport function will only influence index build time?
> >
> > +/*
> > + * GiST sortsupport comparator for ranges.
> > + *
> > + * Operates solely on the lower bounds of the ranges, comparing them using
> > + * range_cmp_bounds().
> > + * Empty ranges are sorted before non-empty ones.
> > + */
> > +static int
> > +range_gist_cmp(Datum a, Datum b, SortSupport ssup)
> > +{
> > + RangeType *range_a = DatumGetRangeTypeP(a);
> > + RangeType *range_b = DatumGetRangeTypeP(b);
> > + TypeCacheEntry *typcache = ssup->ssup_extra;
> > + RangeBound lower1,
> > + lower2;
> > + RangeBound upper1,
> > + upper2;
> > + bool empty1,
> > + empty2;
> > + int result;
> > +
> > + if (typcache == NULL) {
> > + Assert(RangeTypeGetOid(range_a) == RangeTypeGetOid(range_b));
> > + typcache = lookup_type_cache(RangeTypeGetOid(range_a), TYPECACHE_RANGE_INFO);
> > +
> > + /*
> > + * Cache the range info between calls to avoid having to call
> > + * lookup_type_cache() for each comparison.
> > + */
> > + ssup->ssup_extra = typcache;
> > + }
> > +
> > + range_deserialize(typcache, range_a, &lower1, &upper1, &empty1);
> > + range_deserialize(typcache, range_b, &lower2, &upper2, &empty2);
> > +
> > + /* For b-tree use, empty ranges sort before all else */
> > + if (empty1 && empty2)
> > + result = 0;
> > + else if (empty1)
> > + result = -1;
> > + else if (empty2)
> > + result = 1;
> > + else
> > + result = range_cmp_bounds(typcache, &lower1, &lower2);
> > +
> > + if ((Datum) range_a != a)
> > + pfree(range_a);
> > +
> > + if ((Datum) range_b != b)
> > + pfree(range_b);
> > +
> > + return result;
> > +}
> >
> > per https://www.postgresql.org/docs/current/gist-extensibility.html
> > QUOTE:
> > All the GiST support methods are normally called in short-lived memory
> > contexts; that is, CurrentMemoryContext will get reset after each
> > tuple is processed. It is therefore not very important to worry about
> > pfree'ing everything you palloc. However, in some cases it's useful
> > for a support method to
> > ENDOF_QUOTE
> >
> > so removing the following part should be OK.
> > + if ((Datum) range_a != a)
> > + pfree(range_a);
> > +
> > + if ((Datum) range_b != b)
> > + pfree(range_b);
> >
> > comparison solely on the lower bounds looks strange to me.
> > if lower bound is the same, then compare upper bound, so the
> > range_gist_cmp function is consistent with function range_compare.
> > so following change:
> >
> > + else
> > + result = range_cmp_bounds(typcache, &lower1, &lower2);
> > to
> > `
> > else
> > {
> > result = range_cmp_bounds(typcache, &lower1, &lower2);
> > if (result == 0)
> > result = range_cmp_bounds(typcache, &upper1, &upper2);
> > }
> > `
> >
> > does contrib/btree_gist/btree_gist--1.7--1.8.sql function be declared
> > as strict ? (I am not sure)
> > other than that, the whole patch looks good.
>
> the original author email address (christoph.heiss@cybertec.at)
> Address not found.
> so I don't include it.
>
> I split the original author's patch into 2.
> 1. Add GiST sortsupport function for all the btree-gist module data
> types except anyrange data type (which actually does not in this
> module)
> 2. Add GiST sortsupport function for anyrange data type.
CFBot shows that the patch does not apply anymore as in [1]:
=== Applying patches on top of PostgreSQL commit ID
7014c9a4bba2d1b67d60687afb5b2091c1d07f73 ===
=== applying patch
./v5-0001-Add-GIST-sortsupport-function-for-all-the-btree-g.patch
patching file contrib/btree_gist/Makefile
Hunk #1 FAILED at 33.
1 out of 1 hunk FAILED -- saving rejects to file contrib/btree_gist/Makefile.rej
...
The next patch would create the file
contrib/btree_gist/btree_gist--1.7--1.8.sql,
which already exists! Applying it anyway.
patching file contrib/btree_gist/btree_gist--1.7--1.8.sql
Hunk #1 FAILED at 1.
1 out of 1 hunk FAILED -- saving rejects to file
contrib/btree_gist/btree_gist--1.7--1.8.sql.rej
patching file contrib/btree_gist/btree_gist.control
Hunk #1 FAILED at 1.
1 out of 1 hunk FAILED -- saving rejects to file
contrib/btree_gist/btree_gist.control.rej
...
patching file contrib/btree_gist/meson.build
Hunk #1 FAILED at 50.
1 out of 1 hunk FAILED -- saving rejects to file
contrib/btree_gist/meson.build.rej
Please post an updated version for the same.
[1] - http://cfbot.cputube.org/patch_46_3686.log
Regards,
Vignesh
Am Freitag, dem 26.01.2024 um 18:31 +0530 schrieb vignesh C: > CFBot shows that the patch does not apply anymore as in [1]: > === Applying patches on top of PostgreSQL commit ID I've started working on it and planning to submit a polished patch for the upcoming CF.
Am Mittwoch, dem 10.01.2024 um 22:18 +0800 schrieb jian he:
>
> I split the original author's patch into 2.
> 1. Add GiST sortsupport function for all the btree-gist module data
> types except anyrange data type (which actually does not in this
> module)
> 2. Add GiST sortsupport function for anyrange data type.
>
Please find attached a new version of this patch set with the following
changes/adjustments:
- Rebased to current master
- Heavily reworked *_cmp() functions to properly
decode GPT_VARKEY and GBT_KEY input.
For some datatypes the btree comparison functions were reused and the
input arguments not properly handled. This patch adds dedicated
btree_gist sortsupport comparison methods for all datatypes.
There was another patch from Andrey Borodin (thanks again for the hint)
and a deeper review done by Heikki in [1]. I've incorporated Heikkis
findings in this patch, too.
[...]
I've also updated the btree_gist documentation to reflect the default
sorted built strategy this patch introduces now.
Additionally i did some benchmarks again on this new version on the
patch. Still, index build speed improvement is quite impressive on the
dataset originally provided by Christoph Heiss (since its not available
anymore i've uploaded it here [2] again):
HEAD
(Index was built with default buffering setting)
---------------------
REINDEX (s) 4809
CREATE INDEX (s) 4920
btree_gist sortsupport
----------------------
REINDEX (s) 573
CREATE INDEX (s) 578
I created another pgbench based custom script to measure the single
core speed of the lookup query of the bench-gist.py script. This looks
like this:
init.sql
--------
BEGIN;
DROP TABLE IF EXISTS test_dataset;
CREATE TABLE test_dataset(keyid integer not null, id text not null,
block_range int4range);
CREATE TEMP SEQUENCE testset_seq;
INSERT INTO test_dataset SELECT nextval('testset_seq'), id, block_range
FROM test ORDER BY random() LIMIT 10000;
CREATE UNIQUE INDEX ON test_dataset(keyid);
COMMIT;
bench.pgbench
-------------
\set keyid random(1, 10000)
SELECT id, block_range FROM test_dataset WHERE keyid = :keyid \gset
SELECT id, block_range FROM test WHERE id = ':id' AND block_range &&
':block_range';
Run by
for in in `seq 1 3`; do psql -qXf init.pgbench && pgbench -n -r -c 1 -T
60 -f bench.pgbench; done
With this i get the following (on prewarmed index and table):
HEAD
-------------------------------------
pgbench single core tps=248,67
btree_gist sortsupport
----------------------------
pgbench single core tps=1830,33
This is an average over 3 runs each (complete results attached). So
this looks really impressive and i hope i didn't do something entirely
wrong (still learning about this GiST stuff).
> what I am confused:
> In fmgr.h
>
> /*
> * Support for cleaning up detoasted copies of inputs. This must
> only
> * be used for pass-by-ref datatypes, and normally would only be used
> * for toastable types. If the given pointer is different from the
> * original argument, assume it's a palloc'd detoasted copy, and
> pfree it.
> * NOTE: most functions on toastable types do not have to worry about
> this,
> * but we currently require that support functions for indexes not
> leak
> * memory.
> */
> #define PG_FREE_IF_COPY(ptr,n) \
> do { \
> if ((Pointer) (ptr) != PG_GETARG_POINTER(n)) \
> pfree(ptr); \
> } while (0)
>
> but the doc
> (https://www.postgresql.org/docs/current/gist-extensibility.html)
> says:
> All the GiST support methods are normally called in short-lived
> memory
> contexts; that is, CurrentMemoryContext will get reset after each
> tuple is processed. It is therefore not very important to worry about
> pfree'ing everything you palloc.
> ENDOF_QUOTE
>
> so I am not sure in range_gist_cmp, we need the following:
> `
> if ((Datum) range_a != a)
> pfree(range_a);
> if ((Datum) range_b != b)
> pfree(range_b);
> `
Turns out this is not true for sortsupport: the comparison function is
called for each tuple during sorting, which will leak the detoasted
(and probably copied datum) in the sort memory context. See the same
for e.g. numeric and text, which i needed to change to pass the key
values correctly to the text_cmp() or numeric_cmp() function in these
cases.
I've adapted the PG_FREE_IF_COPY() macro for these functions and
introduced GBT_FREE_IF_COPY() in btree_utils_var.h, since the former
relies on fcinfo.
I'll add the patch again to the upcoming CF for another review round.
[1]
https://www.postgresql.org/message-id/c0846e34-8b3a-e1bf-c88e-021eb241a481%40iki.fi
[2] https://drive.google.com/file/d/1CPNFGR53-FUto1zjXPMM2Yrn0GaGfGFz/view?usp=drive_link
Attachment
On Fri, Feb 9, 2024 at 2:14 AM Bernd Helmle <mailings@oopsware.de> wrote:
>
> Am Mittwoch, dem 10.01.2024 um 22:18 +0800 schrieb jian he:
> >
> > I split the original author's patch into 2.
> > 1. Add GiST sortsupport function for all the btree-gist module data
> > types except anyrange data type (which actually does not in this
> > module)
> > 2. Add GiST sortsupport function for anyrange data type.
> >
>
> > what I am confused:
> > In fmgr.h
> >
> > /*
> > * Support for cleaning up detoasted copies of inputs. This must
> > only
> > * be used for pass-by-ref datatypes, and normally would only be used
> > * for toastable types. If the given pointer is different from the
> > * original argument, assume it's a palloc'd detoasted copy, and
> > pfree it.
> > * NOTE: most functions on toastable types do not have to worry about
> > this,
> > * but we currently require that support functions for indexes not
> > leak
> > * memory.
> > */
> > #define PG_FREE_IF_COPY(ptr,n) \
> > do { \
> > if ((Pointer) (ptr) != PG_GETARG_POINTER(n)) \
> > pfree(ptr); \
> > } while (0)
> >
> > but the doc
> > (https://www.postgresql.org/docs/current/gist-extensibility.html)
> > says:
> > All the GiST support methods are normally called in short-lived
> > memory
> > contexts; that is, CurrentMemoryContext will get reset after each
> > tuple is processed. It is therefore not very important to worry about
> > pfree'ing everything you palloc.
> > ENDOF_QUOTE
> >
> > so I am not sure in range_gist_cmp, we need the following:
> > `
> > if ((Datum) range_a != a)
> > pfree(range_a);
> > if ((Datum) range_b != b)
> > pfree(range_b);
> > `
>
> Turns out this is not true for sortsupport: the comparison function is
> called for each tuple during sorting, which will leak the detoasted
> (and probably copied datum) in the sort memory context. See the same
> for e.g. numeric and text, which i needed to change to pass the key
> values correctly to the text_cmp() or numeric_cmp() function in these
> cases.
>
+ <para>
+ Per default <filename>btree_gist</filename> builts
<acronym>GiST</acronym> indexe with
+ <function>sortsupport</function> in <firstterm>sorted</firstterm>
mode. This usually results in a
+ much better index quality and smaller index sizes by much faster
index built speed. It is still
+ possible to revert to buffered built strategy by using the
<literal>buffering</literal> parameter
+ when creating the index.
+ </para>
+
I believe `built` |`builts` should be `build`.
Also
maybe we can simply copy some texts from
https://www.postgresql.org/docs/current/gist-implementation.html.
how about the following:
<para>
The sorted method is only available if each of the opclasses used by the
index provides a <function>sortsupport</function> function, as described
in <xref linkend="gist-extensibility"/>. If they do, this method is
usually the best, so it is used by default.
It is still possible to change to a buffered build strategy by using
the <literal>buffering</literal> parameter
to the CREATE INDEX command.
</para>
you've changed contrib/btree_gist/meson.build, seems we also need to
change contrib/btree_gist/Makefile
gist_point_sortsupport have `if (ssup->abbreviate)`, does
range_gist_sortsupport also this part?
I think the `if(ssup->abbreviate)` part is optional?
Can we add some comments on it?
Am Montag, dem 12.02.2024 um 21:00 +0800 schrieb jian he: > + <para> > + Per default <filename>btree_gist</filename> builts > <acronym>GiST</acronym> indexe with > + <function>sortsupport</function> in <firstterm>sorted</firstterm> > mode. This usually results in a > + much better index quality and smaller index sizes by much faster > index built speed. It is still > + possible to revert to buffered built strategy by using the > <literal>buffering</literal> parameter > + when creating the index. > + </para> > + > I believe `built` |`builts` should be `build`. Right, Fixed. > Also > maybe we can simply copy some texts from > https://www.postgresql.org/docs/current/gist-implementation.html. > how about the following: > <para> > The sorted method is only available if each of the opclasses used > by the > index provides a <function>sortsupport</function> function, as > described > in <xref linkend="gist-extensibility"/>. If they do, this method > is > usually the best, so it is used by default. > It is still possible to change to a buffered build strategy by > using > the <literal>buffering</literal> parameter > to the CREATE INDEX command. > </para> Hmm not sure what you are trying to achieve with this? The opclasses in btree_gist provides sortsupport, but by reading the above i would get the impression they're still optional. > > you've changed contrib/btree_gist/meson.build, seems we also need to > change contrib/btree_gist/Makefile > Oh, good catch. I'm so focused on meson already that i totally forgot the good old Makefile. Fixed. > gist_point_sortsupport have `if (ssup->abbreviate)`, does > range_gist_sortsupport also this part? > I think the `if(ssup->abbreviate)` part is optional? > Can we add some comments on it? I've thought about abbreviated keys support but put that aside for later. I wanted to focus on general sortsupport first before getting my hands on it and so postponed it for another round. If we agree that this patch needs support for abbreviated keys now, i certainly can work on it. Thanks for your review, Bernd
Attachment
Hi,
Here is a rebased version of the patch. Since i don't have anything to
add at the moment and the numbers looks promising and to move on, i've
marked this patch "Ready For Committer".
Thanks,
Bernd
Attachment
> On 22 Mar 2024, at 18:20, Bernd Helmle <mailings@oopsware.de> wrote: > > Here is a rebased version of the patch. FWIW it would be nice at least port tests from commit that I referenced upthread. Nowadays we have injection points, so these tests can be much more stable. Sorry for bringing up this so late. Best regards, Andrey Borodin.
Hi Andrey,
Am Freitag, dem 22.03.2024 um 18:27 +0500 schrieb Andrey M. Borodin:
> > Here is a rebased version of the patch.
>
> FWIW it would be nice at least port tests from commit that I
> referenced upthread.
> Nowadays we have injection points, so these tests can be much more
> stable.
Alright, that's a reasonable point. I will look into this. Did you see
other important things missing?
Changed status back to "Waiting On Author".
Thanks,
Bernd
> On 25 Oct 2024, at 19:41, Bernd Helmle <mailings@oopsware.de> wrote:
>
> So this is a new rebased version of the patches including regression
> tests with default (sortsupport) and buffering behavior. I split up the
> tests for buffering vs. non-buffering but kept them basically the same
> for testing the index builts.
Hi Bernde!
Thanks for the patch!
I have some notes.
First patch:
0. We have PG_FREE_IF_COPY(), does it suits your needs?
1. Tests do not check what actual build method is used. You can add INJECTION_POINT("gist-sort-build") and expect a
noticethere or something like that.
2. "Per default" -> "By default", "indexe" -> "index", "index quality" -> NULL (in 14 quality was bad, since 15 same
"quality")
Second patch:
0. PG_FREE_IF_COPY in range_gist_cmp? :)
1. Some test of this new functionality?
Thanks!
Best regards, Andrey Borodin.
Am Samstag, dem 26.10.2024 um 11:40 +0300 schrieb Andrey M. Borodin:
> First patch:
> 0. We have PG_FREE_IF_COPY(), does it suits your needs?
PG_FREE_IF_COPY() requires FunctionCallInfo (the macro uses
PG_GETARG_POINTER() to reference the pointer value to compare), which
is not usable in the context we need it.
> 1. Tests do not check what actual build method is used. You can add
> INJECTION_POINT("gist-sort-build") and expect a notice there or
> something like that.
Hmm good idea, i give it a try.
> 2. "Per default" -> "By default", "indexe" -> "index", "index
> quality" -> NULL (in 14 quality was bad, since 15 same "quality")
>
> Second patch:
> 0. PG_FREE_IF_COPY in range_gist_cmp? :)
See above.
> 1. Some test of this new functionality?
Right, but i am unsure where this belongs to. Perhaps to
src/test/regress/sql/rangetypes.sql ? We can extend the gist tests
there.
> On 11 Nov 2024, at 21:41, Bernd Helmle <mailings@oopsware.de> wrote:
>
> Updated and rebased patches attached.
Hi Bernd!
Some nitpicking:
0. postgres % git apply ~/Downloads/v7.3-Add-GIST-sortsupport-*
/Users/x4mmm/Downloads/v7.3-Add-GIST-sortsupport-btree-gist.patch:19: space before tab in indent.
oid oid_buffering timestamp timestamp_buffering timestamptz \
/Users/x4mmm/Downloads/v7.3-Add-GIST-sortsupport-btree-gist.patch:20: space before tab in indent.
timestamptz_buffering time time_buffering timetz timetz_buffering date \
/Users/x4mmm/Downloads/v7.3-Add-GIST-sortsupport-btree-gist.patch:21: space before tab in indent.
date_buffering interval interval_buffering macaddr macaddr_buffering \
/Users/x4mmm/Downloads/v7.3-Add-GIST-sortsupport-btree-gist.patch:22: space before tab in indent.
macaddr8 macaddr8_buffering inet inet_buffering cidr cidr_buffering text \
/Users/x4mmm/Downloads/v7.3-Add-GIST-sortsupport-btree-gist.patch:23: space before tab in indent.
text_buffering varchar varchar_buffering char char_buffering \
warning: 5 lines add whitespace errors.
1. I'm mostly seening patches formatted with `git patch-format` rather than diffs as patches...
2. Changes in contrib/btree_gist/btree_gist.c seem unnecessary.
3. Why do you move "typedef struct int32key" to btree_gist.h, but do not need to move all other keys?
4. These ifdedfs are not needed, just do INJECTION_POINT()
#ifdef USE_INJECTION_POINTS
INJECTION_POINT("btree-gist-sorted-build");
#endif
Also, there are 61 occurance of this code. Why not just 1 in gist_indexsortbuild() ?
Thanks!
Best regards, Andrey Borodin.
Am Montag, dem 11.11.2024 um 23:03 +0500 schrieb Andrey M. Borodin:
> Some nitpicking:
> 0. postgres % git apply ~/Downloads/v7.3-Add-GIST-sortsupport-*
> /Users/x4mmm/Downloads/v7.3-Add-GIST-sortsupport-btree-gist.patch:19:
> space before tab in indent.
I obviously shouldn't do patches after a long work day....
[...]
>
> 1. I'm mostly seening patches formatted with `git patch-format`
> rather than diffs as patches...
>
Will do.
> 2. Changes in contrib/btree_gist/btree_gist.c seem unnecessary.
>
Agreed. Will fix
> 3. Why do you move "typedef struct int32key" to btree_gist.h, but do
> not need to move all other keys?
>
Hmm, afair i did this back in an earlier stage of the patch and forgot
about it. It needs to be moved back to btree_int4.c, will fix.
> 4. These ifdedfs are not needed, just do INJECTION_POINT()
> #ifdef USE_INJECTION_POINTS
> INJECTION_POINT("btree-gist-sorted-build");
> #endif
>
I never worked with injection points before, i copied that pattern from
the docs somewhere, where those #ifdef's are used. Will fix.
> Also, there are 61 occurance of this code. Why not just 1 in
> gist_indexsortbuild() ?
>
>
Right, but after thinking about this i'd even go further: naming the
injection points for the sortsupport according to their datatype
they're called on. That would connect the regression test with the
specific datatype/sortsupport function and this would make sure the
correct sortsupport function for the specific test case is called.
Though that means that each test needs to attach/detach the injection
point itself...
What do you think?
Thanks,
Bernd
> On 25 Nov 2024, at 20:40, Bernd Helmle <mailings@oopsware.de> wrote: > > Hi Bernd! Thanks for the new patch version. There are still some problems with tests. 0. You rely on order of test execution. "init.sql" test must prepend any other test. I doubt it is guaranteed. 1. There's a typo float8__buffering in Makefile 2. cidr type seems to be left behind 3. Tests do not seem to work when your configuration lacks injection points. You can see how tests with injection points are excluded in other modules... Perhaps, let's ask Michael. Michael, we have 30 tests with checks that need injection points. But these 30 tests also test functionality that needs tobe tested even in build without injection points. Do we have to extract checks with injection point into separate regression test? So that we can exclude this test in buildswithout injection points. Thanks! Best regards, Andrey Borodin.
Thanks for your valuable input, Michael! > On 29 Nov 2024, at 09:42, Michael Paquier <michael@paquier.xyz> wrote: > > As a whole, I'm very dubious about the need for injection points at > all here. The sortsupport property claimed for this patch tells that > this results in smaller index sizes, but the tests don't really check > that: they just make sure that sortsupport routine paths are taken. > What this should test is not the path taken, but how the new code > affects the index data generated. Actually, that’s exactly what we wanted to test: which paths are taken. Resulting index might be of a very same size in case of B-tree-over-GiST. Resulting index is drastically smaller for geometry,e.g. PostGIS. But event that’s not main effect: the index is simply build much faster (on par with actual B-tree). We need this sort support for btree_gist to be able to use non-geometry datatypes in combination with geometry. e.g. CREATE INDEX ON table USING gist(project_id_of_type_int,geometric_column); Currently, having anything non-geometric in GiST slows down it 10x, because sorting build path is not taken. In PG15 we put extra effort to make resulting indexes indistinguishable from normally-built. Primarily for the sake of IndexScanperformance. Best regards, Andrey Borodin.
Hi Michael, Am Freitag, dem 29.11.2024 um 13:42 +0900 schrieb Michael Paquier: [...] > Any module that requires the module injection_points to be installed > can do a few things, none of them are done this way in this patch: > - Add EXTRA_INSTALL=src/test/modules/injection_points. > - You could make a test able to run installcheck, but you should use > an extra query that checks if the module is available for > installation > by querying pg_available_extensions and use two possible output > files: > one for the case where the module is *not* installed and one for the > case where the module is installed. A simpler way would be to block > installcheck, or add SQL tests in src/test/modules/injection_points. > Both options don't seem adapted to me here as they impact the > portability of existing tests. > I don't like this. This smells like we use the wrong tool. Andrey had the idea to use them because it looked as a compelling idea to check whether sortsupport is used in the code path or not. Maybe we should just use a specific DEBUG message and make sure it's handled by the tests accordingly. > As a whole, I'm very dubious about the need for injection points at > all here. The sortsupport property claimed for this patch tells that > this results in smaller index sizes, but the tests don't really check > that: they just make sure that sortsupport routine paths are taken. > What this should test is not the path taken, but how the new code > affects the index data generated. Perhaps pageinspect could be > something to use to show the difference in contents, not sure though. > No, this isn't the goal of sortsupport for btree_gist. It was a side effect before PG15 that it yielded a better index quality, but the primary goal is and was index creation speed. With sortsupport we're much much faster that the traditional buffered method. Originally this patch was pushed by a customer who had complains about the long build times of btree_gist indexes used by exclusion constraints they're heavily relying on. See a benchmark i've posted in this thread here with test data: https://www.postgresql.org/message-id/2f2e88bf1d44d06c1baf27bbf3db880f42a5cb87.camel@oopsware.de > The number of tests added to contrib/btree_gist/Makefile is not > acceptable for a patch of this size, leading to a large bloat. And > that's harder to maintain in the long-term. Yes, it is not really nice, but i have no better idea atm on how to test both code paths equally without repeating the tests again. Index creation must yield the same results than buffered index build strategy. Originally i just added the tests to the same test file, but then decided to split them up to make it simpler to review and maintain. I'm open for better ideas. Thanks for your comments Bernd
> On 30 Nov 2024, at 18:14, Bernd Helmle <mailings@oopsware.de> wrote: > > I don't like this. This smells like we use the wrong tool. Andrey had > the idea to use them because it looked as a compelling idea to check > whether sortsupport is used in the code path or not. > > Maybe we should just use a specific DEBUG message and make sure it's > handled by the tests accordingly. We tried to go that route, random DEBUG1 lines were breaking tests (autovacuum or something like that, there was somethingnon-deterministic). I think we can dig exact reason from 2021 thread why we abandoned that idea... I think we have two options: 1. Just do not commit tests. We ran it manually, saw that paths are taken, we are happy. 2. Have just one file that builds sorted index on a table with few tuples for each data type. We do not need to test that core sorting (or buffered) build works. AFAIR there's plenty of other tests to verify that. Injection points seemed to me exactly the technogy that could help us to have tests for this patch. But at this point Itlooks like it's reasonable to take approach 1, as we did before. Best regards, Andrey Borodin.
> On 9 Dec 2024, at 22:10, Bernd Helmle <mailings@oopsware.de> wrote: > > So here's a version with the original, unchanged regression tests and > injection point removed (i hope i forgot nothing to revert). Besides unnecessary indentation changes in contrib/btree_gist/Makefile, the patch seems good to me. Best regards, Andrey Borodin.
Hi,
Am Montag, dem 09.12.2024 um 18:10 +0100 schrieb Bernd Helmle:
> > I think we have two options:
> > 1. Just do not commit tests. We ran it manually, saw that paths are
> > taken, we are happy.
>
> So here's a version with the original, unchanged regression tests and
> injection point removed (i hope i forgot nothing to revert).
>
> This version also fixes cidr sortsupport (thanks again Andrey for
> spotting this), where i accidently used inet instead of the correct
> cidr datatype to pass down to the sortsupport function.
Please find a new rebased version of this patch. No changes to the
patch itself, but it didn't apply without conflicts anymore.
Thanks,
Bernd
Attachment
On 11/03/2025 20:28, Bernd Helmle wrote: > Please find a new rebased version of this patch. Hmm, if we implement sortsupport function for GiST, we can register it for B-tree opfamily as well. The range comparison function has quite high overhead thanks to detoasting, but I'm nevertheless seeing a tiny speedup. I tested that with: setup: create table intranges (r int4range); insert into intranges select int4range(g, g+10) from generate_series(1, 1000000) g; vacuum freeze intranges; test script 'rangesort.sql': set work_mem='100 MB'; explain analyze select r from intranges order by r; test: pgbench -n -f rangesort.sql -P1 postgres -t100 On my laptop, that reports avg latency of 152 ms on master, and 149 ms latency with the patch. Nothing to write home about, but we might as well take it if we have the sortsupport function for gist anyway. So I added it for the btree opfamily too, and moved the function to rangetypes.c since it's not just for gist anymore. I Ccmmitted that part, and will start looking more closely at the remaining btree_gist parts now. -- Heikki Linnakangas Neon (https://neon.tech)
On 02/04/2025 20:18, Heikki Linnakangas wrote: > So I added it for the btree opfamily too, and moved the function to > rangetypes.c since it's not just for gist anymore. I Ccmmitted that > part, and will start looking more closely at the remaining btree_gist > parts now. Here's an updated version of the remaining parts. Found a couple of bugs: * The stuff to save the FmgrInfo for gbt_enum_sortsupport() was broken. It saved the address of FmgrInfo struct that was allocated in a local variable, on the stack, in SortSupport->ssup-extra, and expected it to be valid on subsequent call to gbt_enum_ssup_cmp(). It went unnoticed because enum_cmp() only accesses the FmgrInfo struct if it encounters odd enum values, i.e. enum values that have been added with ALTER TYPE ADD VALUE. I fixed that, and modified the existing enum test to cover that case. * The gist_bpchar_ops opfamily was using the built-in bpchar_sortsupport() function directly. That's not right, you need to have a shim that extracts and comparse just the 'lower' value, just like for all other datatypes. I think that was just a simple oversight, but it happened to pass the tests because bpchar_sortsupport() would not outright crash, even though we were passing it garbage. It's interesting that because the gist sortsupport function is used just to order the input during build, everything still works if it sorts the input to a completely bogus ordering, it just gets slower. At one point while fixing that, I also accidentally used "btcharcmp" instead of "bpcharcmp", and all the tests passed with that too. Those are now fixed. I also harmonized the comments to use the same phrasing for all the datatypes, marked all the sortsupport functions as PARALLEL SAFE, and reformatted slightly. > + <para> > + By default <filename>btree_gist</filename> builds <acronym>GiST</acronym> index with > + <function>sortsupport</function> in <firstterm>sorted</firstterm> mode. This usually results in > + much faster index built speed. It is still possible to revert to buffered built strategy > + by using the <literal>buffering</literal> parameter when creating the index. > + </para> I'm inclined to leave out this paragraph. That's not specific to the btree_gist module, you can make any GiST index slower by disabling the sorted mode; but why would you do that? Let's mention in the release notes that btree_gist index builds got faster, and leave it at that. -- Heikki Linnakangas Neon (https://neon.tech)
Attachment
On 02/04/2025 22:41, Heikki Linnakangas wrote: > On 02/04/2025 20:18, Heikki Linnakangas wrote: >> So I added it for the btree opfamily too, and moved the function to >> rangetypes.c since it's not just for gist anymore. I Ccmmitted that >> part, and will start looking more closely at the remaining btree_gist >> parts now. > > Here's an updated version of the remaining parts. Found a couple of bugs: Committed with some further cosmetic fixes. Thanks for the patience, this has been lingering for a long time, especially if you count the earlier attempt back in 2021! -- Heikki Linnakangas Neon (https://neon.tech)
Am Mittwoch, dem 02.04.2025 um 22:41 +0300 schrieb Heikki Linnakangas: > * The stuff to save the FmgrInfo for gbt_enum_sortsupport() was > broken. > It saved the address of FmgrInfo struct that was allocated in a local > variable, on the stack, in SortSupport->ssup-extra, and expected it > to > be valid on subsequent call to gbt_enum_ssup_cmp(). It went unnoticed > because enum_cmp() only accesses the FmgrInfo struct if it encounters > odd enum values, i.e. enum values that have been added with ALTER > TYPE > ADD VALUE. I fixed that, and modified the existing enum test to cover > that case. > Ugh, i obviously didn't pay enough attention here. > * The gist_bpchar_ops opfamily was using the built-in > bpchar_sortsupport() function directly. That's not right, you need to > have a shim that extracts and comparse just the 'lower' value, just > like > for all other datatypes. I think that was just a simple oversight, > but > it happened to pass the tests because bpchar_sortsupport() would not > outright crash, even though we were passing it garbage. It's > interesting > that because the gist sortsupport function is used just to order the > input during build, everything still works if it sorts the input to a > completely bogus ordering, it just gets slower. At one point while > fixing that, I also accidentally used "btcharcmp" instead of > "bpcharcmp", and all the tests passed with that too. > Yes, i missed that. Originally the code did this all over the place with many other types, too. I seem to have overseen this somehow. > Those are now fixed. I also harmonized the comments to use the same > phrasing for all the datatypes, marked all the sortsupport functions > as > PARALLEL SAFE, and reformatted slightly. Note that the original coding was by Christoph Heiss and i picked up his work and rewrote/fixed especially the part with the direct use of sortsupport functions and many other issues spotted by testing and by Andrey. Many thanks for picking this up. There are users out there which are going to be very happy with this if no further issues arise. :)
On 03/04/2025 18:00, Bernd Helmle wrote: > Note that the original coding was by Christoph Heiss and i picked up > his work and rewrote/fixed especially the part with the direct use of > sortsupport functions and many other issues spotted by testing and by > Andrey. Sorry Christoph I missed you in the commit message! -- Heikki Linnakangas Neon (https://neon.tech)
> On 3 Apr 2025, at 16:13, Heikki Linnakangas <hlinnaka@iki.fi> wrote: > > Committed Cool! Thank you!!! Best regards, Andrey Borodin.