Thread: pgcon unconference / impact of block size on performance
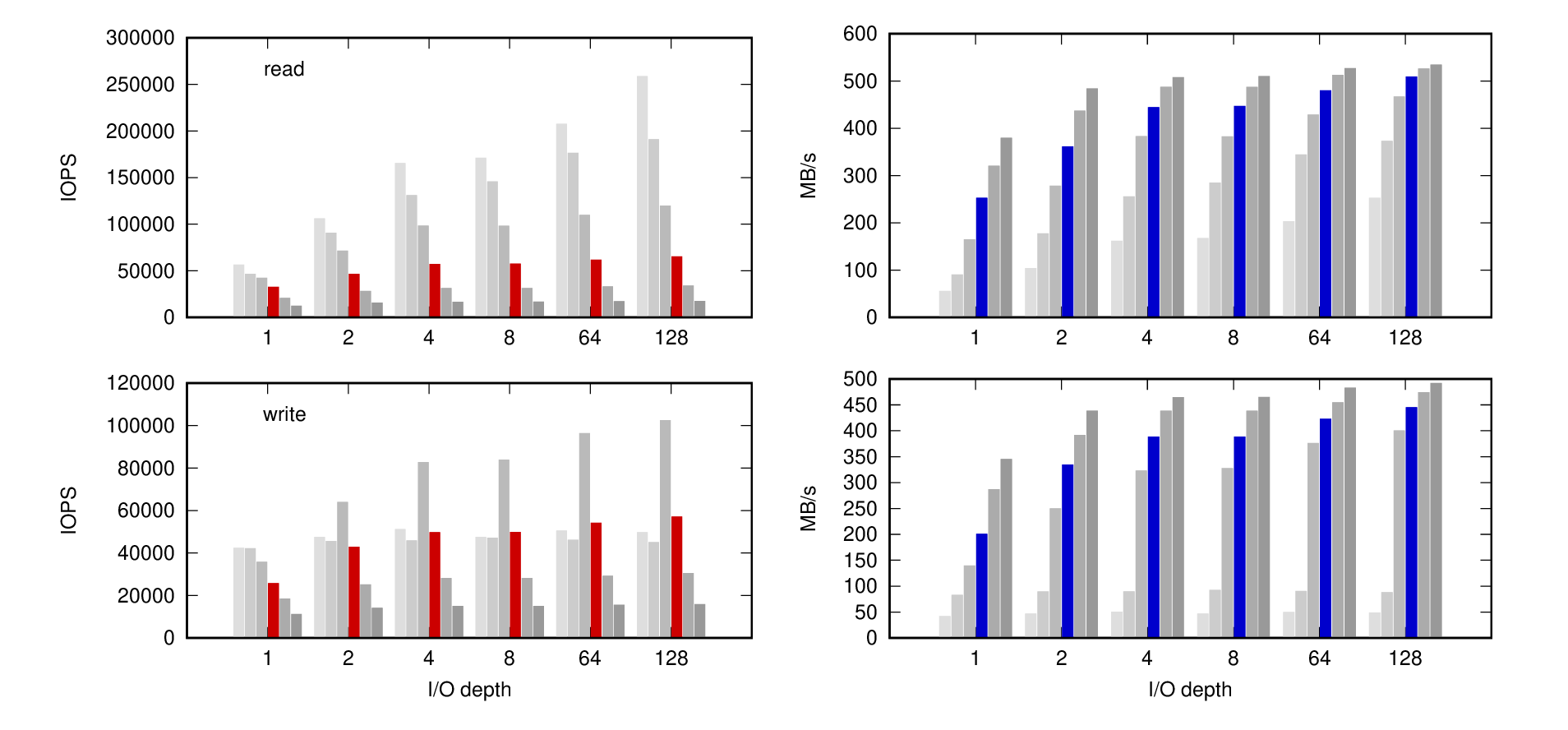
Hi, At on of the pgcon unconference sessions a couple days ago, I presented a bunch of benchmark results comparing performance with different data/WAL block size. Most of the OLTP results showed significant gains (up to 50%) with smaller (4k) data pages. This opened a long discussion about possible explanations - I claimed one of the main factors is the adoption of flash storage, due to pretty fundamental differences between HDD and SSD systems. But the discussion concluded with an agreement to continue investigating this, so here's an attempt to support the claim with some measurements/data. Let me present results of low-level fio benchmarks on a couple different HDD and SSD drives. This should eliminate any postgres-related influence (e.g. FPW), and demonstrates inherent HDD/SSD differences. Each of the PDF pages shows results for five basic workloads: - random read - random write - random r/w - sequential read - sequential write The chars on the left show IOPS, charts on right bandwidth. The x-axis shows I/O depth - number of concurrent I/O requests or queue length, with values 1, 2, 4, 8, 64, 128. And each "group" shows results for different page size (1K, 2K, 4K, 8K, 16K, 32K). The colored page size is the default value (8K). This makes it clear how a page size affects performance (IOPS and BW) for a given I/O depth, and also the impact of higher I/O depth. I do think the difference between HDD and SSD storage is pretty clearly visible (even though there is some variability between the SSD devices). IMHO the crucial difference is that for HDD, the page size has almost no impact on IOPS (in the random workloads). If you look at the random read results, the page size does not matter - once you fix the I/O depth, the result are pretty much exactly the same. For the random write test it's even clearer, because the I/O depth does not matter and you get 350 IOPS no matter the page size or I/O depth. This makes perfect sense, because for "spinning rust" the dominant part is seeking to the right part of the platter. And once you've seeked to the right place, it does not matter much if you read 1K or 32K - the cost is much lower than the seek. And the economy is pretty simple - you can't really improve IOPS, but you can improve bandwidth by using larger pages. If you do 350 IOPS, it can be either 350kB/s with 1K pages or 11MB/s with 32KB pages). So we'd gain very little by using smaller pages, and larger pages improve bandwidth - not just for random tests, but sequential too. And 8KB seems like a reasonable compromise - bandwidth with 32KB pages is better, but with higher I/O depths (8 or more) we get pretty close, likely due to hitting SATA limits. Now, compare this to the SSD. There are some differences between the models, manufacturers, interface etc. but the impact of page size on IOPS is pretty clear. On the Optane you can get +20-30% by using 4K pages, on the Samsung it's even more, etc. This means that workloads dominated by random I/O get significant benefit from smaller pages. Another consequence of this is that for sequential workloads, the difference between page sizes is smaller, because when smaller pages reach better IOPS this reduces the difference in bandwidth. If you imagine two extremes: 1) different pages yield the same IOPS 2) different pages yield the same bandwidth then old-school HDDs are pretty close to (1), while future storage systems (persistent memory) is likely close to (2). This matters, because various trade-offs we've made in the past are reasonable for (1), but will be inefficient for (2). And as the results I shared during the pgcon session suggest, we might do so much better even for current SSDs, which are somewhere between (1) and (2). The other important factor is the native SSD page, which is similar to sectors on HDD. SSDs however don't allow in-place updates, and have to reset/rewrite of the whole native page. It's actually more complicated, because the reset happens at a much larger scale (~8MB block), so it does matter how quickly we "dirty" the data. The consequence is that using data pages smaller than the native page (depends on the device, but seems 4K is the common value) either does not help or actually hurts the write performance. All the SSD results show this behavior - the Optane and Samsung nicely show that 4K is much better (in random write IOPS) than 8K, but 1-2K pages make it worse. I'm sure there are other important factors - for example, eliminating the very expensive "seek" cost (SSDs can do 10k-100k IOPS easily, while HDDs did ~100-400 IOPS), other steps start to play much bigger role. I wouldn't be surprised if memcpy() started to matter, for example. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Sat, Jun 4, 2022 at 5:23 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
Hi,
At on of the pgcon unconference sessions a couple days ago, I presented
a bunch of benchmark results comparing performance with different
data/WAL block size. Most of the OLTP results showed significant gains
(up to 50%) with smaller (4k) data pages.
Thanks for sharing this Thomas.
We’ve been doing similar tests with different storage classes in kubernetes clusters.
Roberto
On 6/5/22 02:21, Roberto Mello wrote: > On Sat, Jun 4, 2022 at 5:23 PM Tomas Vondra > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>> > wrote: > > Hi, > > At on of the pgcon unconference sessions a couple days ago, I presented > a bunch of benchmark results comparing performance with different > data/WAL block size. Most of the OLTP results showed significant gains > (up to 50%) with smaller (4k) data pages. > > > Thanks for sharing this Thomas. > > We’ve been doing similar tests with different storage classes in > kubernetes clusters. > Can you share some of the results? Might be interesting, particularly if you use network-attached storage (like EBS, etc.). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi Tomas, > Hi, > > At on of the pgcon unconference sessions a couple days ago, I presented a > bunch of benchmark results comparing performance with different data/WAL > block size. Most of the OLTP results showed significant gains (up to 50%) with > smaller (4k) data pages. Nice. I just saw this https://wiki.postgresql.org/wiki/PgCon_2022_Developer_Unconference , do you have any plans for publishingthose other graphs too (e.g. WAL block size impact)? > This opened a long discussion about possible explanations - I claimed one of the > main factors is the adoption of flash storage, due to pretty fundamental > differences between HDD and SSD systems. But the discussion concluded with an > agreement to continue investigating this, so here's an attempt to support the > claim with some measurements/data. > > Let me present results of low-level fio benchmarks on a couple different HDD > and SSD drives. This should eliminate any postgres-related influence (e.g. FPW), > and demonstrates inherent HDD/SSD differences. > All the SSD results show this behavior - the Optane and Samsung nicely show > that 4K is much better (in random write IOPS) than 8K, but 1-2K pages make it > worse. > [..] Can you share what Linux kernel version, what filesystem , it's mount options and LVM setup were you using if any(?) I've hastily tried your script on 4VCPU/32GB RAM/1xNVMe device @ ~900GB (AWS i3.xlarge), kernel 5.x, ext4 defaults, no LVM,libaio only, fio deviations: runtime -> 1min, 64GB file, 1 iteration only. Results are attached, w/o graphs. > Now, compare this to the SSD. There are some differences between the models, manufacturers, interface etc. but the impactof page size on IOPS is pretty clear. On the Optane you can get +20-30% by using 4K pages, on the Samsung it's evenmore, etc. This means that workloads dominated by random I/O get significant benefit from smaller pages. Yup, same here, reproduced, 1.42x faster on writes: [root@x ~]# cd libaio/nvme/randwrite/128/ # 128=queue depth [root@x 128]# grep -r "write:" * | awk '{print $1, $4, $5}' | sort -n 1k/1.txt: bw=24162KB/s, iops=24161, 2k/1.txt: bw=47164KB/s, iops=23582, 4k/1.txt: bw=280450KB/s, iops=70112, <<< 8k/1.txt: bw=393082KB/s, iops=49135, 16k/1.txt: bw=393103KB/s, iops=24568, 32k/1.txt: bw=393283KB/s, iops=12290, BTW it's interesting to compare to your's Optane 900P result (same two high bars for IOPS @ 4,8kB), but in my case it's evenmore import to select 4kB so it behaves more like Samsung 860 in your case # 1.41x on randreads [root@x ~]# cd libaio/nvme/randread/128/ # 128=queue depth [root@x 128]# grep -r "read :" | awk '{print $1, $5, $6}' | sort -n 1k/1.txt: bw=169938KB/s, iops=169937, 2k/1.txt: bw=376653KB/s, iops=188326, 4k/1.txt: bw=691529KB/s, iops=172882, <<< 8k/1.txt: bw=976916KB/s, iops=122114, 16k/1.txt: bw=990524KB/s, iops=61907, 32k/1.txt: bw=974318KB/s, iops=30447, I think that the above just a demonstration of device bandwidth saturation: 32k*30k IOPS =~ 1GB/s random reads. Given thatDB would be tuned @ 4kB for app(OLTP), but once upon a time Parallel Seq Scans "critical reports" could only achieve70% of what it could achieve on 8kB, correct? (I'm assuming most real systems are really OLTP but with some reporting/dataexporting needs). One way or another it would be very nice to be able to select the tradeoff using initdb(1)without the need to recompile, which then begs for some initdb --calibrate /mnt/nvme (effective_io_concurrency,DB page size, ...). Do you envision any plans for this we still in a need to gather more info exactly why this happens? (perf reports?) Also have you guys discussed on that meeting any long-term future plans on storage layer by any chance ? If sticking to 4kBpages on DB/page size/hardware sector size, wouldn't it be possible to win also disabling FPWs in the longer run usinguring (assuming O_DIRECT | O_ATOMIC one day?) I recall that Thomas M. was researching O_ATOMIC, I think he wrote some of that pretty nicely in [1] [1] - https://wiki.postgresql.org/wiki/FreeBSD/AtomicIO
Attachment
On 6/6/22 16:27, Jakub Wartak wrote: > Hi Tomas, > >> Hi, >> >> At on of the pgcon unconference sessions a couple days ago, I presented a >> bunch of benchmark results comparing performance with different data/WAL >> block size. Most of the OLTP results showed significant gains (up to 50%) with >> smaller (4k) data pages. > > Nice. I just saw this https://wiki.postgresql.org/wiki/PgCon_2022_Developer_Unconference , do you have any plans for publishing those other graphs too (e.g. WAL block size impact)? > Well, there's plenty of charts in the github repositories, including the charts I think you're asking for: https://github.com/tvondra/pg-block-bench-pgbench/blob/master/process/heatmaps/xeon/20220406-fpw/16/heatmap-tps.png https://github.com/tvondra/pg-block-bench-pgbench/blob/master/process/heatmaps/i5/20220427-fpw/16/heatmap-io-tps.png I admit the charts may not be documented very clearly :-( >> This opened a long discussion about possible explanations - I claimed one of the >> main factors is the adoption of flash storage, due to pretty fundamental >> differences between HDD and SSD systems. But the discussion concluded with an >> agreement to continue investigating this, so here's an attempt to support the >> claim with some measurements/data. >> >> Let me present results of low-level fio benchmarks on a couple different HDD >> and SSD drives. This should eliminate any postgres-related influence (e.g. FPW), >> and demonstrates inherent HDD/SSD differences. >> All the SSD results show this behavior - the Optane and Samsung nicely show >> that 4K is much better (in random write IOPS) than 8K, but 1-2K pages make it >> worse. >> > [..] > Can you share what Linux kernel version, what filesystem , it's > mount options and LVM setup were you using if any(?) > The PostgreSQL benchmarks were with 5.14.x kernels, with either ext4 or xfs filesystems. i5 uses LVM on the 6x SATA SSD devices, with this config: bench ~ # mdadm --detail /dev/md0 /dev/md0: Version : 0.90 Creation Time : Thu Feb 8 15:05:49 2018 Raid Level : raid0 Array Size : 586106880 (558.96 GiB 600.17 GB) Raid Devices : 6 Total Devices : 6 Preferred Minor : 0 Persistence : Superblock is persistent Update Time : Thu Feb 8 15:05:49 2018 State : clean Active Devices : 6 Working Devices : 6 Failed Devices : 0 Spare Devices : 0 Chunk Size : 512K Consistency Policy : none UUID : 24c6158c:36454b38:529cc8e5:b4b9cc9d (local to host bench) Events : 0.1 Number Major Minor RaidDevice State 0 8 1 0 active sync /dev/sda1 1 8 17 1 active sync /dev/sdb1 2 8 33 2 active sync /dev/sdc1 3 8 49 3 active sync /dev/sdd1 4 8 65 4 active sync /dev/sde1 5 8 81 5 active sync /dev/sdf1 bench ~ # mount | grep md0 /dev/md0 on /mnt/raid type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,sunit=16,swidth=96,noquota) and the xeon just uses ext4 on the device directly: /dev/nvme0n1p1 on /mnt/data type ext4 (rw,relatime) > I've hastily tried your script on 4VCPU/32GB RAM/1xNVMe device @ > ~900GB (AWS i3.xlarge), kernel 5.x, ext4 defaults, no LVM, libaio > only, fio deviations: runtime -> 1min, 64GB file, 1 iteration only. > Results are attached, w/o graphs. > >> Now, compare this to the SSD. There are some differences between >> the models, manufacturers, interface etc. but the impact of page >> size on IOPS is pretty clear. On the Optane you can get +20-30% by >> using 4K pages, on the Samsung it's even more, etc. This means that >> workloads dominated by random I/O get significant benefit from >> smaller pages. > > Yup, same here, reproduced, 1.42x faster on writes: > [root@x ~]# cd libaio/nvme/randwrite/128/ # 128=queue depth > [root@x 128]# grep -r "write:" * | awk '{print $1, $4, $5}' | sort -n > 1k/1.txt: bw=24162KB/s, iops=24161, > 2k/1.txt: bw=47164KB/s, iops=23582, > 4k/1.txt: bw=280450KB/s, iops=70112, <<< > 8k/1.txt: bw=393082KB/s, iops=49135, > 16k/1.txt: bw=393103KB/s, iops=24568, > 32k/1.txt: bw=393283KB/s, iops=12290, > > BTW it's interesting to compare to your's Optane 900P result (same > two high bars for IOPS @ 4,8kB), but in my case it's even more import > to select 4kB so it behaves more like Samsung 860 in your case > Thanks. Interesting! > # 1.41x on randreads > [root@x ~]# cd libaio/nvme/randread/128/ # 128=queue depth > [root@x 128]# grep -r "read :" | awk '{print $1, $5, $6}' | sort -n > 1k/1.txt: bw=169938KB/s, iops=169937, > 2k/1.txt: bw=376653KB/s, iops=188326, > 4k/1.txt: bw=691529KB/s, iops=172882, <<< > 8k/1.txt: bw=976916KB/s, iops=122114, > 16k/1.txt: bw=990524KB/s, iops=61907, > 32k/1.txt: bw=974318KB/s, iops=30447, > > I think that the above just a demonstration of device bandwidth > saturation: 32k*30k IOPS =~ 1GB/s random reads. Given that DB would > be tuned @ 4kB for app(OLTP), but once upon a time Parallel Seq > Scans "critical reports" could only achieve 70% of what it could > achieve on 8kB, correct? (I'm assuming most real systems are really > OLTP but with some reporting/data exporting needs). > Right, that's roughly my thinking too. Also, OLAP queries often do a lot of random I/O, due to index scans etc. I also wonder how is this related to filesystem page size - in all the benchmarks I did I used the default (4k), but maybe it'd behave if the filesystem page matched the data page. > One way or another it would be very nice to be able to select the > tradeoff using initdb(1) without the need to recompile, which then > begs for some initdb --calibrate /mnt/nvme (effective_io_concurrency, > DB page size, ...).> > Do you envision any plans for this we still in a need to gather more > info exactly why this happens? (perf reports?) > Not sure I follow. Plans for what? Something that calibrates cost parameters? That might be useful, but that's a rather separate issue from what's discussed here - page size, which needs to happen before initdb (at least with how things work currently). The other issue (e.g. with effective_io_concurrency) is that it very much depends on the access pattern - random pages and sequential pages will require very different e_i_c values. But again, that's something to discuss in a separate thread (e.g. [1]) [1]: https://postgr.es/m/Yl92RVoXVfs+z2Yj@momjian.us > Also have you guys discussed on that meeting any long-term future > plans on storage layer by any chance ? If sticking to 4kB pages on > DB/page size/hardware sector size, wouldn't it be possible to win > also disabling FPWs in the longer run using uring (assuming O_DIRECT > | O_ATOMIC one day?)> > I recall that Thomas M. was researching O_ATOMIC, I think he wrote > some of that pretty nicely in [1] > > [1] - https://wiki.postgresql.org/wiki/FreeBSD/AtomicIO No, no such discussion - at least no in this unconference slot. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
{kind=link}
{kind=link}
On 6/6/22 17:00, Tomas Vondra wrote: > > On 6/6/22 16:27, Jakub Wartak wrote: >> Hi Tomas, >> >>> Hi, >>> >>> At on of the pgcon unconference sessions a couple days ago, I presented a >>> bunch of benchmark results comparing performance with different data/WAL >>> block size. Most of the OLTP results showed significant gains (up to 50%) with >>> smaller (4k) data pages. >> >> Nice. I just saw this > https://wiki.postgresql.org/wiki/PgCon_2022_Developer_Unconference , do > you have any plans for publishing those other graphs too (e.g. WAL block > size impact)? >> > > Well, there's plenty of charts in the github repositories, including the > charts I think you're asking for: > > https://github.com/tvondra/pg-block-bench-pgbench/blob/master/process/heatmaps/xeon/20220406-fpw/16/heatmap-tps.png > > https://github.com/tvondra/pg-block-bench-pgbench/blob/master/process/heatmaps/i5/20220427-fpw/16/heatmap-io-tps.png > > > I admit the charts may not be documented very clearly :-( > >>> This opened a long discussion about possible explanations - I claimed one of the >>> main factors is the adoption of flash storage, due to pretty fundamental >>> differences between HDD and SSD systems. But the discussion concluded with an >>> agreement to continue investigating this, so here's an attempt to support the >>> claim with some measurements/data. >>> >>> Let me present results of low-level fio benchmarks on a couple different HDD >>> and SSD drives. This should eliminate any postgres-related influence (e.g. FPW), >>> and demonstrates inherent HDD/SSD differences. >>> All the SSD results show this behavior - the Optane and Samsung nicely show >>> that 4K is much better (in random write IOPS) than 8K, but 1-2K pages make it >>> worse. >>> >> [..] >> Can you share what Linux kernel version, what filesystem , it's >> mount options and LVM setup were you using if any(?) >> > > The PostgreSQL benchmarks were with 5.14.x kernels, with either ext4 or > xfs filesystems. > I realized I mentioned just two of the devices, used for the postgres test, but this thread is dealing mostly with about fio results. So let me list info about all the devices/filesystems: i5 -- Intel SSD 320 120GB SATA (SSDSA2CW12) /dev/sdh1 on /mnt/data type ext4 (rw,noatime) 6x Intel SSD DC S3700 100GB SATA (SSDSC2BA10), LVM RAID0 /dev/md0 on /mnt/raid type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,sunit=16,swidth=96,noquota) xeon ---- Samsung SSD 860 EVO 2TB SATA (RVT04B6Q) /dev/sde1 on /mnt/samsung type ext4 (rw,relatime) Intel Optane 900P 280GB NVMe (SSDPED1D280GA) /dev/nvme0n1p1 on /mnt/data type ext4 (rw,relatime) 3x Maxtor DiamondMax 21 500B 7.2k SATA (STM350063), LVM RAID0 /dev/md0 on /mnt/raid type ext4 (rw,relatime,stripe=48) # mdadm --detail /dev/md0 /dev/md0: Version : 1.2 Creation Time : Fri Aug 31 21:11:48 2018 Raid Level : raid0 Array Size : 1464763392 (1396.91 GiB 1499.92 GB) Raid Devices : 3 Total Devices : 3 Persistence : Superblock is persistent Update Time : Fri Aug 31 21:11:48 2018 State : clean Active Devices : 3 Working Devices : 3 Failed Devices : 0 Spare Devices : 0 Chunk Size : 64K Consistency Policy : none Name : bench2:0 (local to host bench2) UUID : 72e48e7b:a75554ea:05952b34:810ed6bc Events : 0 Number Major Minor RaidDevice State 0 8 17 0 active sync /dev/sdb1 1 8 33 1 active sync /dev/sdc1 2 8 49 2 active sync /dev/sdd1 Hopefully this is more complete ... -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello Tomas, > At on of the pgcon unconference sessions a couple days ago, I presented > a bunch of benchmark results comparing performance with different > data/WAL block size. Most of the OLTP results showed significant gains > (up to 50%) with smaller (4k) data pages. You wrote something about SSD a long time ago, but the link is now dead: http://www.fuzzy.cz/en/articles/ssd-benchmark-results-read-write-pgbench/ See also: http://www.cybertec.at/postgresql-block-sizes-getting-started/ http://blog.coelho.net/database/2014/08/08/postgresql-page-size-for-SSD.html [...] > The other important factor is the native SSD page, which is similar to > sectors on HDD. SSDs however don't allow in-place updates, and have to > reset/rewrite of the whole native page. It's actually more complicated, > because the reset happens at a much larger scale (~8MB block), so it > does matter how quickly we "dirty" the data. The consequence is that > using data pages smaller than the native page (depends on the device, > but seems 4K is the common value) either does not help or actually hurts > the write performance. > > All the SSD results show this behavior - the Optane and Samsung nicely > show that 4K is much better (in random write IOPS) than 8K, but 1-2K > pages make it worse. Yep. ISTM that uou should also consider the underlying FS block size. Ext4 uses 4 KiB by default, so if you write 2 KiB it will write 4 KiB anyway. There is no much doubt that with SSD we should reduce the default page size. There are some negative impacts (eg more space is lost because of headers and the number of tuples that can be fitted), but I guess the should be an overall benefit. It would help a lot if it would be possible to initdb with a different block size, without recompiling. -- Fabien.
On Sun, 5 Jun 2022 at 11:23, Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > At on of the pgcon unconference sessions a couple days ago, I presented > a bunch of benchmark results comparing performance with different > data/WAL block size. Most of the OLTP results showed significant gains > (up to 50%) with smaller (4k) data pages. A few years ago when you and I were doing analysis into the TPC-H benchmark, we found that larger page sizes helped various queries, especially Q1. It would be good to see what the block size changes in performance in a query such as: SELECT sum(value) FROM table_with_tuples_of_several_hundred_bytes;. I don't recall the reason why 32k pages helped there, but it seems reasonable that doing more work for each lookup in shared buffers might be 1 reason. Maybe some deeper analysis into various workloads might convince us that it might be worth having an initdb option to specify the blocksize. There'd be various hurdles to get over in the code to make that work. I doubt we could ever make the default smaller than it is today as it would nobody would be able to insert rows larger than 4 kilobytes into a table anymore. Plus pg_upgrade issues. David [1] https://www.postgresql.org/docs/current/limits.html
Hi Tomas, > Well, there's plenty of charts in the github repositories, including the charts I > think you're asking for: Thanks. > I also wonder how is this related to filesystem page size - in all the benchmarks I > did I used the default (4k), but maybe it'd behave if the filesystem page matched > the data page. That may be it - using fio on raw NVMe device (without fs/VFS at all) shows: [root@x libaio-raw]# grep -r -e 'write:' -e 'read :' * nvme/randread/128/1k/1.txt: read : io=7721.9MB, bw=131783KB/s, iops=131783, runt= 60001msec [b] nvme/randread/128/2k/1.txt: read : io=15468MB, bw=263991KB/s, iops=131995, runt= 60001msec [b] nvme/randread/128/4k/1.txt: read : io=30142MB, bw=514408KB/s, iops=128602, runt= 60001msec [b] nvme/randread/128/8k/1.txt: read : io=56698MB, bw=967635KB/s, iops=120954, runt= 60001msec nvme/randwrite/128/1k/1.txt: write: io=4140.9MB, bw=70242KB/s, iops=70241, runt= 60366msec [a] nvme/randwrite/128/2k/1.txt: write: io=8271.5MB, bw=141161KB/s, iops=70580, runt= 60002msec [a] nvme/randwrite/128/4k/1.txt: write: io=16543MB, bw=281164KB/s, iops=70291, runt= 60248msec nvme/randwrite/128/8k/1.txt: write: io=22924MB, bw=390930KB/s, iops=48866, runt= 60047msec So, I've found out two interesting things while playing with raw vs ext4: a) I've got 70k IOPS always randwrite even on 1k,2k,4k without ext4 (so as expected, this was ext4 4kb default fs page sizeimpact as you was thinking about when fio 1k was hitting ext4 4kB block) b) Another thing that you could also include in testing is that I've spotted a couple of times single-threaded fio mightcould be limiting factor (numjobs=1 by default), so I've tried with numjobs=2,group_reporting=1 and got this below ouputon ext4 defaults even while dropping caches (echo 3) each loop iteration -- something that I cannot explain (ext4 directI/O caching effect? how's that even possible? reproduced several times even with numjobs=1) - the point being 2066431kb IOPS @ ext4 direct-io > 131783 1kB IOPS @ raw, smells like some caching effect because for randwrite it does nothappen. I've triple-checked with iostat -x... it cannot be any internal device cache as with direct I/O that doesn't happen: [root@x libaio-ext4]# grep -r -e 'write:' -e 'read :' * nvme/randread/128/1k/1.txt: read : io=12108MB, bw=206644KB/s, iops=206643, runt= 60001msec [b] nvme/randread/128/2k/1.txt: read : io=18821MB, bw=321210KB/s, iops=160604, runt= 60001msec [b] nvme/randread/128/4k/1.txt: read : io=36985MB, bw=631208KB/s, iops=157802, runt= 60001msec [b] nvme/randread/128/8k/1.txt: read : io=57364MB, bw=976923KB/s, iops=122115, runt= 60128msec nvme/randwrite/128/1k/1.txt: write: io=1036.2MB, bw=17683KB/s, iops=17683, runt= 60001msec [a, as before] nvme/randwrite/128/2k/1.txt: write: io=2023.2MB, bw=34528KB/s, iops=17263, runt= 60001msec [a, as before] nvme/randwrite/128/4k/1.txt: write: io=16667MB, bw=282977KB/s, iops=70744, runt= 60311msec [reproduced benefit, as per earlieremail] nvme/randwrite/128/8k/1.txt: write: io=22997MB, bw=391839KB/s, iops=48979, runt= 60099msec > > One way or another it would be very nice to be able to select the > > tradeoff using initdb(1) without the need to recompile, which then > > begs for some initdb --calibrate /mnt/nvme (effective_io_concurrency, > > DB page size, ...).> Do you envision any plans for this we still in a > > need to gather more info exactly why this happens? (perf reports?) > > > > Not sure I follow. Plans for what? Something that calibrates cost parameters? > That might be useful, but that's a rather separate issue from what's discussed > here - page size, which needs to happen before initdb (at least with how things > work currently). [..] Sorry, I was too far teched and assumed you guys were talking very long term. -J.
[..] >I doubt we could ever > make the default smaller than it is today as it would nobody would be able to > insert rows larger than 4 kilobytes into a table anymore. Add error "values larger than 1/3 of a buffer page cannot be indexed" to that list... -J.
On 6/7/22 11:46, Jakub Wartak wrote: > Hi Tomas, > >> Well, there's plenty of charts in the github repositories, including the charts I >> think you're asking for: > > Thanks. > >> I also wonder how is this related to filesystem page size - in all the benchmarks I >> did I used the default (4k), but maybe it'd behave if the filesystem page matched >> the data page. > > That may be it - using fio on raw NVMe device (without fs/VFS at all) shows: > > [root@x libaio-raw]# grep -r -e 'write:' -e 'read :' * > nvme/randread/128/1k/1.txt: read : io=7721.9MB, bw=131783KB/s, iops=131783, runt= 60001msec [b] > nvme/randread/128/2k/1.txt: read : io=15468MB, bw=263991KB/s, iops=131995, runt= 60001msec [b] > nvme/randread/128/4k/1.txt: read : io=30142MB, bw=514408KB/s, iops=128602, runt= 60001msec [b] > nvme/randread/128/8k/1.txt: read : io=56698MB, bw=967635KB/s, iops=120954, runt= 60001msec > nvme/randwrite/128/1k/1.txt: write: io=4140.9MB, bw=70242KB/s, iops=70241, runt= 60366msec [a] > nvme/randwrite/128/2k/1.txt: write: io=8271.5MB, bw=141161KB/s, iops=70580, runt= 60002msec [a] > nvme/randwrite/128/4k/1.txt: write: io=16543MB, bw=281164KB/s, iops=70291, runt= 60248msec > nvme/randwrite/128/8k/1.txt: write: io=22924MB, bw=390930KB/s, iops=48866, runt= 60047msec > > So, I've found out two interesting things while playing with raw vs ext4: > a) I've got 70k IOPS always randwrite even on 1k,2k,4k without ext4 (so as expected, this was ext4 4kb default fs pagesize impact as you was thinking about when fio 1k was hitting ext4 4kB block) Right. Interesting, so for randread we get a consistent +30% speedup on raw devices with all page sizes, while on randwrite it's about 1.0x for 4K. The really puzzling thing is why is the filesystem so much slower for smaller pages. I mean, why would writing 1K be 1/3 of writing 4K? Why would a filesystem have such effect? > b) Another thing that you could also include in testing is that I've spotted a couple of times single-threaded fio mightcould be limiting factor (numjobs=1 by default), so I've tried with numjobs=2,group_reporting=1 and got this below ouputon ext4 defaults even while dropping caches (echo 3) each loop iteration -- something that I cannot explain (ext4 directI/O caching effect? how's that even possible? reproduced several times even with numjobs=1) - the point being 2066431kb IOPS @ ext4 direct-io > 131783 1kB IOPS @ raw, smells like some caching effect because for randwrite it does nothappen. I've triple-checked with iostat -x... it cannot be any internal device cache as with direct I/O that doesn't happen: > > [root@x libaio-ext4]# grep -r -e 'write:' -e 'read :' * > nvme/randread/128/1k/1.txt: read : io=12108MB, bw=206644KB/s, iops=206643, runt= 60001msec [b] > nvme/randread/128/2k/1.txt: read : io=18821MB, bw=321210KB/s, iops=160604, runt= 60001msec [b] > nvme/randread/128/4k/1.txt: read : io=36985MB, bw=631208KB/s, iops=157802, runt= 60001msec [b] > nvme/randread/128/8k/1.txt: read : io=57364MB, bw=976923KB/s, iops=122115, runt= 60128msec > nvme/randwrite/128/1k/1.txt: write: io=1036.2MB, bw=17683KB/s, iops=17683, runt= 60001msec [a, as before] > nvme/randwrite/128/2k/1.txt: write: io=2023.2MB, bw=34528KB/s, iops=17263, runt= 60001msec [a, as before] > nvme/randwrite/128/4k/1.txt: write: io=16667MB, bw=282977KB/s, iops=70744, runt= 60311msec [reproduced benefit, as perearlier email] > nvme/randwrite/128/8k/1.txt: write: io=22997MB, bw=391839KB/s, iops=48979, runt= 60099msec > No idea what might be causing this. BTW so you're not using direct-io to access the raw device? Or am I just misreading this? >>> One way or another it would be very nice to be able to select the >>> tradeoff using initdb(1) without the need to recompile, which then >>> begs for some initdb --calibrate /mnt/nvme (effective_io_concurrency, >>> DB page size, ...).> Do you envision any plans for this we still in a >>> need to gather more info exactly why this happens? (perf reports?) >>> >> >> Not sure I follow. Plans for what? Something that calibrates cost parameters? >> That might be useful, but that's a rather separate issue from what's discussed >> here - page size, which needs to happen before initdb (at least with how things >> work currently). > [..] > > Sorry, I was too far teched and assumed you guys were talking very long term. > Np, I think that'd be an useful tool, but it seems more like a completely separate discussion. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hi, > The really > puzzling thing is why is the filesystem so much slower for smaller pages. I mean, > why would writing 1K be 1/3 of writing 4K? > Why would a filesystem have such effect? Ha! I don't care at this point as 1 or 2kB seems too small to handle many real world scenarios ;) > > b) Another thing that you could also include in testing is that I've spotted a > couple of times single-threaded fio might could be limiting factor (numjobs=1 by > default), so I've tried with numjobs=2,group_reporting=1 and got this below > ouput on ext4 defaults even while dropping caches (echo 3) each loop iteration - > - something that I cannot explain (ext4 direct I/O caching effect? how's that > even possible? reproduced several times even with numjobs=1) - the point being > 206643 1kb IOPS @ ext4 direct-io > 131783 1kB IOPS @ raw, smells like some > caching effect because for randwrite it does not happen. I've triple-checked with > iostat -x... it cannot be any internal device cache as with direct I/O that doesn't > happen: > > > > [root@x libaio-ext4]# grep -r -e 'write:' -e 'read :' * > > nvme/randread/128/1k/1.txt: read : io=12108MB, bw=206644KB/s, > > iops=206643, runt= 60001msec [b] > > nvme/randread/128/2k/1.txt: read : io=18821MB, bw=321210KB/s, > > iops=160604, runt= 60001msec [b] > > nvme/randread/128/4k/1.txt: read : io=36985MB, bw=631208KB/s, > > iops=157802, runt= 60001msec [b] > > nvme/randread/128/8k/1.txt: read : io=57364MB, bw=976923KB/s, > > iops=122115, runt= 60128msec > > nvme/randwrite/128/1k/1.txt: write: io=1036.2MB, bw=17683KB/s, > > iops=17683, runt= 60001msec [a, as before] > > nvme/randwrite/128/2k/1.txt: write: io=2023.2MB, bw=34528KB/s, > > iops=17263, runt= 60001msec [a, as before] > > nvme/randwrite/128/4k/1.txt: write: io=16667MB, bw=282977KB/s, > > iops=70744, runt= 60311msec [reproduced benefit, as per earlier email] > > nvme/randwrite/128/8k/1.txt: write: io=22997MB, bw=391839KB/s, > > iops=48979, runt= 60099msec > > > > No idea what might be causing this. BTW so you're not using direct-io to access > the raw device? Or am I just misreading this? Both scenarios (raw and fs) have had direct=1 set. I just cannot understand how having direct I/O enabled (which disablescaching) achieves better read IOPS on ext4 than on raw device... isn't it contradiction? -J.
On 6/7/22 15:48, Jakub Wartak wrote: > Hi, > >> The really >> puzzling thing is why is the filesystem so much slower for smaller pages. I mean, >> why would writing 1K be 1/3 of writing 4K? >> Why would a filesystem have such effect? > > Ha! I don't care at this point as 1 or 2kB seems too small to handle many real world scenarios ;) > I think that's not quite true - a lot of OLTP works with fairly narrow rows, and if they use more data, it's probably in TOAST, so again split into smaller rows. It's true smaller pages would cut some of the limits (columns, index tuple, ...) of course, and that might be an issue. Independently of that, it seems like an interesting behavior and it might tell us something about how to optimize for larger pages. >>> b) Another thing that you could also include in testing is that I've spotted a >> couple of times single-threaded fio might could be limiting factor (numjobs=1 by >> default), so I've tried with numjobs=2,group_reporting=1 and got this below >> ouput on ext4 defaults even while dropping caches (echo 3) each loop iteration - >> - something that I cannot explain (ext4 direct I/O caching effect? how's that >> even possible? reproduced several times even with numjobs=1) - the point being >> 206643 1kb IOPS @ ext4 direct-io > 131783 1kB IOPS @ raw, smells like some >> caching effect because for randwrite it does not happen. I've triple-checked with >> iostat -x... it cannot be any internal device cache as with direct I/O that doesn't >> happen: >>> >>> [root@x libaio-ext4]# grep -r -e 'write:' -e 'read :' * >>> nvme/randread/128/1k/1.txt: read : io=12108MB, bw=206644KB/s, >>> iops=206643, runt= 60001msec [b] >>> nvme/randread/128/2k/1.txt: read : io=18821MB, bw=321210KB/s, >>> iops=160604, runt= 60001msec [b] >>> nvme/randread/128/4k/1.txt: read : io=36985MB, bw=631208KB/s, >>> iops=157802, runt= 60001msec [b] >>> nvme/randread/128/8k/1.txt: read : io=57364MB, bw=976923KB/s, >>> iops=122115, runt= 60128msec >>> nvme/randwrite/128/1k/1.txt: write: io=1036.2MB, bw=17683KB/s, >>> iops=17683, runt= 60001msec [a, as before] >>> nvme/randwrite/128/2k/1.txt: write: io=2023.2MB, bw=34528KB/s, >>> iops=17263, runt= 60001msec [a, as before] >>> nvme/randwrite/128/4k/1.txt: write: io=16667MB, bw=282977KB/s, >>> iops=70744, runt= 60311msec [reproduced benefit, as per earlier email] >>> nvme/randwrite/128/8k/1.txt: write: io=22997MB, bw=391839KB/s, >>> iops=48979, runt= 60099msec >>> >> >> No idea what might be causing this. BTW so you're not using direct-io to access >> the raw device? Or am I just misreading this? > > Both scenarios (raw and fs) have had direct=1 set. I just cannot understand how having direct I/O enabled (which disablescaching) achieves better read IOPS on ext4 than on raw device... isn't it contradiction? > Thanks for the clarification. Not sure what might be causing this. Did you use the same parameters (e.g. iodepth) in both cases? regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Sat, Jun 4, 2022 at 7:23 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > This opened a long discussion about possible explanations - I claimed > one of the main factors is the adoption of flash storage, due to pretty > fundamental differences between HDD and SSD systems. But the discussion > concluded with an agreement to continue investigating this, so here's an > attempt to support the claim with some measurements/data. Interesting. I wonder if the fact that x86 machines have a 4kB page size matters here. It seems hard to be sure because it's not something you can really change. But there are a few of your graphs where 4kB spikes up above any higher or lower value, and maybe that's why? -- Robert Haas EDB: http://www.enterprisedb.com
On 6/7/22 18:26, Robert Haas wrote: > On Sat, Jun 4, 2022 at 7:23 PM Tomas Vondra > <tomas.vondra@enterprisedb.com> wrote: >> This opened a long discussion about possible explanations - I claimed >> one of the main factors is the adoption of flash storage, due to pretty >> fundamental differences between HDD and SSD systems. But the discussion >> concluded with an agreement to continue investigating this, so here's an >> attempt to support the claim with some measurements/data. > > Interesting. I wonder if the fact that x86 machines have a 4kB page > size matters here. It seems hard to be sure because it's not something > you can really change. But there are a few of your graphs where 4kB > spikes up above any higher or lower value, and maybe that's why? > Possibly, but why would that be the case? Maybe there are places that do stuff with memory and have different optimizations based on length? I'd bet the 4k page is way more optimized than the other cases. But honestly, I think the SSD page size matters much more, and the main bump between 4k and 8k comes from having to deal with just a single page. Imagine you write 8k postgres page - the filesystem splits that into two 4k pages, and then eventually writes them to storage. It may happen the writeback flushes them separately, possibly even to different places on the device. Which might be more expensive to read later, etc. I'm just speculating, of course. Maybe the storage is smarter and can figure some of this internally, or maybe the locality will remain high. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jun 7, 2022 at 1:47 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote: > Possibly, but why would that be the case? Maybe there are places that do > stuff with memory and have different optimizations based on length? I'd > bet the 4k page is way more optimized than the other cases. I don't really know. It was just a thought. It feels like the fact that the page sizes are different could be hurting us somehow, but I don't really know what the mechanism would be. -- Robert Haas EDB: http://www.enterprisedb.com
Hi, got some answers!
TL;DR for fio it would make sense to use many stressfiles (instead of 1) and same for numjobs ~ VCPU to avoid various
pitfails.
> >> The really
> >> puzzling thing is why is the filesystem so much slower for smaller
> >> pages. I mean, why would writing 1K be 1/3 of writing 4K?
> >> Why would a filesystem have such effect?
> >
> > Ha! I don't care at this point as 1 or 2kB seems too small to handle
> > many real world scenarios ;)
[..]
> Independently of that, it seems like an interesting behavior and it might tell us
> something about how to optimize for larger pages.
OK, curiosity won:
With randwrite on ext4 directio using 4kb the avgqu-sz reaches ~90-100 (close to fio's 128 queue depth?) and I'm
getting~70k IOPS [with maxdepth=128]
With randwrite on ext4 directio using 1kb the avgqu-sz is just 0.7 and I'm getting just ~17-22k IOPS [with
maxdepth=128]-> conclusion: something is being locked thus preventing queue to build up
With randwrite on ext4 directio using 4kb the avgqu-sz reaches ~2.3 (so something is queued) and I'm also getting ~70k
IOPSwith minimal possible maxdepth=4 -> conclusion: I just need to split the lock contention by 4.
The 1kB (slow) profile top function is aio_write() -> .... -> iov_iter_get_pages() -> internal_get_user_pages_fast()
andthere's sadly plenty of "lock" keywords inside {related to memory manager, padding to full page size, inode locking}
alsoone can find some articles / commits related to it [1] which didn't made a good feeling to be honest as the fio is
usingjust 1 file (even while I'm on kernel 5.10.x). So I've switched to 4x files and numjobs=4 and got easily 60k IOPS,
contentionsolved whatever it was :) So I would assume PostgreSQL (with it's splitting data files by default on 1GB
boundariesand multiprocess architecture) should be relatively safe from such ext4 inode(?)/mm(?) contentions even with
smallest1kb block sizes on Direct I/O some day.
[1] - https://www.phoronix.com/scan.php?page=news_item&px=EXT4-DIO-Faster-DBs
> > Both scenarios (raw and fs) have had direct=1 set. I just cannot understand
> how having direct I/O enabled (which disables caching) achieves better read
> IOPS on ext4 than on raw device... isn't it contradiction?
> >
>
> Thanks for the clarification. Not sure what might be causing this. Did you use the
> same parameters (e.g. iodepth) in both cases?
Explanation: it's the CPU scheduler migrations mixing the performance result during the runs of fio (as you have in
yourframework). Various VCPUs seem to be having varying max IOPS characteristics (sic!) and CPU scheduler seems to be
unawareof it. At least on 1kB and 4kB blocksize this happens also notice that some VCPUs [XXXX marker] don't reach 100%
CPUreaching almost twice the result; while cores 0, 3 do reach 100% and lack CPU power to perform more. The only thing
thatI don't get is that it doesn't make sense from extened lscpu output (but maybe it's AWS XEN mixing real CPU
mappings,who knows).
[root@x ~]# for((x=0; x<=3; x++)) ; do echo "$x:"; taskset -c $x fio fio.ext4 | grep -e 'read :' -e 'cpu '; done
0:
read : io=2416.8MB, bw=123730KB/s, iops=123730, runt= 20001msec
cpu : usr=42.98%, sys=56.52%, ctx=2317, majf=0, minf=41 [XXXX: 100% cpu bottleneck and just 123k IOPS]
1:
read : io=4077.9MB, bw=208774KB/s, iops=208773, runt= 20001msec
cpu : usr=29.47%, sys=51.43%, ctx=2993, majf=0, minf=42 [XXXX, some idle power and 208k IOPS just by
switchingto core1...]
2:
read : io=4036.7MB, bw=206636KB/s, iops=206636, runt= 20001msec
cpu : usr=31.00%, sys=52.41%, ctx=2815, majf=0, minf=42 [XXXX]
3:
read : io=2398.4MB, bw=122791KB/s, iops=122791, runt= 20001msec
cpu : usr=44.20%, sys=55.20%, ctx=2522, majf=0, minf=41
[root@x ~]# for((x=0; x<=3; x++)) ; do echo "$x:"; taskset -c $x fio fio.raw | grep -e 'read :' -e 'cpu '; done
0:
read : io=2512.3MB, bw=128621KB/s, iops=128620, runt= 20001msec
cpu : usr=47.62%, sys=51.58%, ctx=2365, majf=0, minf=42
1:
read : io=4070.2MB, bw=206748KB/s, iops=206748, runt= 20159msec
cpu : usr=29.52%, sys=42.86%, ctx=2808, majf=0, minf=42 [XXXX]
2:
read : io=4101.3MB, bw=209975KB/s, iops=209975, runt= 20001msec
cpu : usr=28.05%, sys=45.09%, ctx=3419, majf=0, minf=42 [XXXX]
3:
read : io=2519.4MB, bw=128985KB/s, iops=128985, runt= 20001msec
cpu : usr=46.59%, sys=52.70%, ctx=2371, majf=0, minf=41
[root@x ~]# lscpu --extended
CPU NODE SOCKET CORE L1d:L1i:L2:L3 ONLINE MAXMHZ MINMHZ
0 0 0 0 0:0:0:0 yes 3000.0000 1200.0000
1 0 0 1 1:1:1:0 yes 3000.0000 1200.0000
2 0 0 0 0:0:0:0 yes 3000.0000 1200.0000
3 0 0 1 1:1:1:0 yes 3000.0000 1200.0000
[root@x ~]# lscpu | grep -e ^Model -e ^NUMA -e ^Hyper
NUMA node(s): 1
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHz
Hypervisor vendor: Xen
NUMA node0 CPU(s): 0-3
[root@x ~]# diff -u fio.raw fio.ext4
--- fio.raw 2022-06-08 12:32:26.603482453 +0000
+++ fio.ext4 2022-06-08 12:32:36.071621708 +0000
@@ -1,5 +1,5 @@
[global]
-filename=/dev/nvme0n1
+filename=/mnt/nvme/fio/data.file
size=256GB
direct=1
ioengine=libaio
[root@x ~]# cat fio.raw
[global]
filename=/dev/nvme0n1
size=256GB
direct=1
ioengine=libaio
runtime=20
numjobs=1
group_reporting=1
[job]
rw=randread
iodepth=128
bs=1k
size=64GB
[root@x ~]#
-J.
On 6/8/22 16:15, Jakub Wartak wrote:
> Hi, got some answers!
>
> TL;DR for fio it would make sense to use many stressfiles (instead of 1) and same for numjobs ~ VCPU to avoid various
pitfails.
> >>>> The really
>>>> puzzling thing is why is the filesystem so much slower for smaller
>>>> pages. I mean, why would writing 1K be 1/3 of writing 4K?
>>>> Why would a filesystem have such effect?
>>>
>>> Ha! I don't care at this point as 1 or 2kB seems too small to handle
>>> many real world scenarios ;)
> [..]
>> Independently of that, it seems like an interesting behavior and it might tell us
>> something about how to optimize for larger pages.
>
> OK, curiosity won:
>
> With randwrite on ext4 directio using 4kb the avgqu-sz reaches ~90-100 (close to fio's 128 queue depth?) and I'm
getting~70k IOPS [with maxdepth=128]
> With randwrite on ext4 directio using 1kb the avgqu-sz is just 0.7 and I'm getting just ~17-22k IOPS [with
maxdepth=128]-> conclusion: something is being locked thus preventing queue to build up
> With randwrite on ext4 directio using 4kb the avgqu-sz reaches ~2.3 (so something is queued) and I'm also getting
~70kIOPS with minimal possible maxdepth=4 -> conclusion: I just need to split the lock contention by 4.
>
> The 1kB (slow) profile top function is aio_write() -> .... -> iov_iter_get_pages() -> internal_get_user_pages_fast()
andthere's sadly plenty of "lock" keywords inside {related to memory manager, padding to full page size, inode locking}
alsoone can find some articles / commits related to it [1] which didn't made a good feeling to be honest as the fio is
usingjust 1 file (even while I'm on kernel 5.10.x). So I've switched to 4x files and numjobs=4 and got easily 60k IOPS,
contentionsolved whatever it was :) So I would assume PostgreSQL (with it's splitting data files by default on 1GB
boundariesand multiprocess architecture) should be relatively safe from such ext4 inode(?)/mm(?) contentions even with
smallest1kb block sizes on Direct I/O some day.
>
Interesting. So what parameter values would you suggest?
FWIW some of the tests I did were on xfs, so I wonder if that might be
hitting similar/other bottlenecks.
> [1] - https://www.phoronix.com/scan.php?page=news_item&px=EXT4-DIO-Faster-DBs
>
>>> Both scenarios (raw and fs) have had direct=1 set. I just cannot understand
>> how having direct I/O enabled (which disables caching) achieves better read
>> IOPS on ext4 than on raw device... isn't it contradiction?
>>>
>>
>> Thanks for the clarification. Not sure what might be causing this. Did you use the
>> same parameters (e.g. iodepth) in both cases?
>
> Explanation: it's the CPU scheduler migrations mixing the performance result during the runs of fio (as you have in
yourframework). Various VCPUs seem to be having varying max IOPS characteristics (sic!) and CPU scheduler seems to be
unawareof it. At least on 1kB and 4kB blocksize this happens also notice that some VCPUs [XXXX marker] don't reach 100%
CPUreaching almost twice the result; while cores 0, 3 do reach 100% and lack CPU power to perform more. The only thing
thatI don't get is that it doesn't make sense from extened lscpu output (but maybe it's AWS XEN mixing real CPU
mappings,who knows).
Uh, that's strange. I haven't seen anything like that, but I'm running
on physical HW and not AWS, so it's either that or maybe I just didn't
do the same test.
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
> > >>>> The really
> >>>> puzzling thing is why is the filesystem so much slower for smaller
> >>>> pages. I mean, why would writing 1K be 1/3 of writing 4K?
> >>>> Why would a filesystem have such effect?
> >>>
> >>> Ha! I don't care at this point as 1 or 2kB seems too small to handle
> >>> many real world scenarios ;)
> > [..]
> >> Independently of that, it seems like an interesting behavior and it
> >> might tell us something about how to optimize for larger pages.
> >
> > OK, curiosity won:
> >
> > With randwrite on ext4 directio using 4kb the avgqu-sz reaches ~90-100
> > (close to fio's 128 queue depth?) and I'm getting ~70k IOPS [with
> > maxdepth=128] With randwrite on ext4 directio using 1kb the avgqu-sz is just
> 0.7 and I'm getting just ~17-22k IOPS [with maxdepth=128] -> conclusion:
> something is being locked thus preventing queue to build up With randwrite on
> ext4 directio using 4kb the avgqu-sz reaches ~2.3 (so something is queued) and
> I'm also getting ~70k IOPS with minimal possible maxdepth=4 -> conclusion: I
> just need to split the lock contention by 4.
> >
> > The 1kB (slow) profile top function is aio_write() -> .... -> iov_iter_get_pages()
> -> internal_get_user_pages_fast() and there's sadly plenty of "lock" keywords
> inside {related to memory manager, padding to full page size, inode locking}
> also one can find some articles / commits related to it [1] which didn't made a
> good feeling to be honest as the fio is using just 1 file (even while I'm on kernel
> 5.10.x). So I've switched to 4x files and numjobs=4 and got easily 60k IOPS,
> contention solved whatever it was :) So I would assume PostgreSQL (with it's
> splitting data files by default on 1GB boundaries and multiprocess architecture)
> should be relatively safe from such ext4 inode(?)/mm(?) contentions even with
> smallest 1kb block sizes on Direct I/O some day.
> >
>
> Interesting. So what parameter values would you suggest?
At least have 4x filename= entries and numjobs=4
> FWIW some of the tests I did were on xfs, so I wonder if that might be hitting
> similar/other bottlenecks.
Apparently XFS also shows same contention on single file for 1..2kb randwrite, see [ZZZ].
[root@x ~]# mount|grep /mnt/nvme
/dev/nvme0n1 on /mnt/nvme type xfs (rw,relatime,attr2,inode64,logbufs=8,logbsize=32k,noquota)
# using 1 fio job and 1 file
[root@x ~]# grep -r -e 'read :' -e 'write:' libaio
libaio/nvme/randread/128/1k/1.txt: read : io=5779.1MB, bw=196573KB/s, iops=196573, runt= 30109msec
libaio/nvme/randread/128/2k/1.txt: read : io=10335MB, bw=352758KB/s, iops=176379, runt= 30001msec
libaio/nvme/randread/128/4k/1.txt: read : io=22220MB, bw=758408KB/s, iops=189601, runt= 30001msec
libaio/nvme/randread/128/8k/1.txt: read : io=28914MB, bw=986896KB/s, iops=123361, runt= 30001msec
libaio/nvme/randwrite/128/1k/1.txt: write: io=694856KB, bw=23161KB/s, iops=23161, runt= 30001msec [ZZZ]
libaio/nvme/randwrite/128/2k/1.txt: write: io=1370.7MB, bw=46782KB/s, iops=23390, runt= 30001msec [ZZZ]
libaio/nvme/randwrite/128/4k/1.txt: write: io=8261.3MB, bw=281272KB/s, iops=70318, runt= 30076msec [OK]
libaio/nvme/randwrite/128/8k/1.txt: write: io=11598MB, bw=394320KB/s, iops=49289, runt= 30118msec
# but it's all ok using 4 fio jobs and 4 files
[root@x ~]# grep -r -e 'read :' -e 'write:' libaio
libaio/nvme/randread/128/1k/1.txt: read : io=6174.6MB, bw=210750KB/s, iops=210750, runt= 30001msec
libaio/nvme/randread/128/2k/1.txt: read : io=12152MB, bw=413275KB/s, iops=206637, runt= 30110msec
libaio/nvme/randread/128/4k/1.txt: read : io=24382MB, bw=832116KB/s, iops=208028, runt= 30005msec
libaio/nvme/randread/128/8k/1.txt: read : io=29281MB, bw=985831KB/s, iops=123228, runt= 30415msec
libaio/nvme/randwrite/128/1k/1.txt: write: io=1692.2MB, bw=57748KB/s, iops=57748, runt= 30003msec
libaio/nvme/randwrite/128/2k/1.txt: write: io=3601.9MB, bw=122940KB/s, iops=61469, runt= 30001msec
libaio/nvme/randwrite/128/4k/1.txt: write: io=8470.8MB, bw=285857KB/s, iops=71464, runt= 30344msec
libaio/nvme/randwrite/128/8k/1.txt: write: io=11449MB, bw=390603KB/s, iops=48825, runt= 30014msec
> >>> Both scenarios (raw and fs) have had direct=1 set. I just cannot
> >>> understand
> >> how having direct I/O enabled (which disables caching) achieves
> >> better read IOPS on ext4 than on raw device... isn't it contradiction?
> >>>
> >>
> >> Thanks for the clarification. Not sure what might be causing this.
> >> Did you use the same parameters (e.g. iodepth) in both cases?
> >
> > Explanation: it's the CPU scheduler migrations mixing the performance result
> during the runs of fio (as you have in your framework). Various VCPUs seem to
> be having varying max IOPS characteristics (sic!) and CPU scheduler seems to be
> unaware of it. At least on 1kB and 4kB blocksize this happens also notice that
> some VCPUs [XXXX marker] don't reach 100% CPU reaching almost twice the
> result; while cores 0, 3 do reach 100% and lack CPU power to perform more.
> The only thing that I don't get is that it doesn't make sense from extened lscpu
> output (but maybe it's AWS XEN mixing real CPU mappings, who knows).
>
> Uh, that's strange. I haven't seen anything like that, but I'm running on physical
> HW and not AWS, so it's either that or maybe I just didn't do the same test.
I couldn't belived it until I've checked via taskset 😊 BTW: I don't have real HW with NVMe , but we might be with worth
checkingif placing (taskset -c ...) fio on hyperthreading VCPU is not causing (there's
/sys/devices/system/cpu/cpu0/topology/thread_siblingsand maybe lscpu(1) output). On AWS I have feeling that lscpu might
simplylie and I cannot identify which VCPU is HT and which isn't.
-J.
On 6/9/22 13:23, Jakub Wartak wrote:
>>>>>>> The really
>>>>>> puzzling thing is why is the filesystem so much slower for smaller
>>>>>> pages. I mean, why would writing 1K be 1/3 of writing 4K?
>>>>>> Why would a filesystem have such effect?
>>>>>
>>>>> Ha! I don't care at this point as 1 or 2kB seems too small to handle
>>>>> many real world scenarios ;)
>>> [..]
>>>> Independently of that, it seems like an interesting behavior and it
>>>> might tell us something about how to optimize for larger pages.
>>>
>>> OK, curiosity won:
>>>
>>> With randwrite on ext4 directio using 4kb the avgqu-sz reaches ~90-100
>>> (close to fio's 128 queue depth?) and I'm getting ~70k IOPS [with
>>> maxdepth=128] With randwrite on ext4 directio using 1kb the avgqu-sz is just
>> 0.7 and I'm getting just ~17-22k IOPS [with maxdepth=128] -> conclusion:
>> something is being locked thus preventing queue to build up With randwrite on
>> ext4 directio using 4kb the avgqu-sz reaches ~2.3 (so something is queued) and
>> I'm also getting ~70k IOPS with minimal possible maxdepth=4 -> conclusion: I
>> just need to split the lock contention by 4.
>>>
>>> The 1kB (slow) profile top function is aio_write() -> .... -> iov_iter_get_pages()
>> -> internal_get_user_pages_fast() and there's sadly plenty of "lock" keywords
>> inside {related to memory manager, padding to full page size, inode locking}
>> also one can find some articles / commits related to it [1] which didn't made a
>> good feeling to be honest as the fio is using just 1 file (even while I'm on kernel
>> 5.10.x). So I've switched to 4x files and numjobs=4 and got easily 60k IOPS,
>> contention solved whatever it was :) So I would assume PostgreSQL (with it's
>> splitting data files by default on 1GB boundaries and multiprocess architecture)
>> should be relatively safe from such ext4 inode(?)/mm(?) contentions even with
>> smallest 1kb block sizes on Direct I/O some day.
>>>
>>
>> Interesting. So what parameter values would you suggest?
>
> At least have 4x filename= entries and numjobs=4
>
>> FWIW some of the tests I did were on xfs, so I wonder if that might be hitting
>> similar/other bottlenecks.
>
> Apparently XFS also shows same contention on single file for 1..2kb randwrite, see [ZZZ].
>
I don't have any results yet, but after thinking about this a bit I find
this really strange. Why would there be any contention with a single fio
job? Doesn't contention imply multiple processes competing for the same
resource/lock etc.?
Isn't this simply due to the iodepth increase? IIUC with multiple fio
jobs, each will use a separate iodepth value. So with numjobs=4, we'll
really use iodepth*4, which can make a big difference.
>>>
>>> Explanation: it's the CPU scheduler migrations mixing the performance result
>> during the runs of fio (as you have in your framework). Various VCPUs seem to
>> be having varying max IOPS characteristics (sic!) and CPU scheduler seems to be
>> unaware of it. At least on 1kB and 4kB blocksize this happens also notice that
>> some VCPUs [XXXX marker] don't reach 100% CPU reaching almost twice the
>> result; while cores 0, 3 do reach 100% and lack CPU power to perform more.
>> The only thing that I don't get is that it doesn't make sense from extened lscpu
>> output (but maybe it's AWS XEN mixing real CPU mappings, who knows).
>>
>> Uh, that's strange. I haven't seen anything like that, but I'm running on physical
>> HW and not AWS, so it's either that or maybe I just didn't do the same test.
>
> I couldn't belived it until I've checked via taskset 😊 BTW: I don't
> have real HW with NVMe , but we might be with worth checking if
> placing (taskset -c ...) fio on hyperthreading VCPU is not causing
> (there's /sys/devices/system/cpu/cpu0/topology/thread_siblings and
> maybe lscpu(1) output). On AWS I have feeling that lscpu might simply
> lie and I cannot identify which VCPU is HT and which isn't.
Did you see the same issue with io_uring?
regards
--
Tomas Vondra
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
> On 6/9/22 13:23, Jakub Wartak wrote:
> >>>>>>> The really
> >>>>>> puzzling thing is why is the filesystem so much slower for
> >>>>>> smaller pages. I mean, why would writing 1K be 1/3 of writing 4K?
> >>>>>> Why would a filesystem have such effect?
> >>>>>
> >>>>> Ha! I don't care at this point as 1 or 2kB seems too small to
> >>>>> handle many real world scenarios ;)
> >>> [..]
> >>>> Independently of that, it seems like an interesting behavior and it
> >>>> might tell us something about how to optimize for larger pages.
> >>>
> >>> OK, curiosity won:
> >>>
> >>> With randwrite on ext4 directio using 4kb the avgqu-sz reaches
> >>> ~90-100 (close to fio's 128 queue depth?) and I'm getting ~70k IOPS
> >>> [with maxdepth=128] With randwrite on ext4 directio using 1kb the
> >>> avgqu-sz is just
> >> 0.7 and I'm getting just ~17-22k IOPS [with maxdepth=128] -> conclusion:
> >> something is being locked thus preventing queue to build up With
> >> randwrite on
> >> ext4 directio using 4kb the avgqu-sz reaches ~2.3 (so something is
> >> queued) and I'm also getting ~70k IOPS with minimal possible
> >> maxdepth=4 -> conclusion: I just need to split the lock contention by 4.
> >>>
> >>> The 1kB (slow) profile top function is aio_write() -> .... ->
> >>> iov_iter_get_pages()
> >> -> internal_get_user_pages_fast() and there's sadly plenty of "lock"
> >> -> keywords
> >> inside {related to memory manager, padding to full page size, inode
> >> locking} also one can find some articles / commits related to it [1]
> >> which didn't made a good feeling to be honest as the fio is using
> >> just 1 file (even while I'm on kernel 5.10.x). So I've switched to 4x
> >> files and numjobs=4 and got easily 60k IOPS, contention solved
> >> whatever it was :) So I would assume PostgreSQL (with it's splitting
> >> data files by default on 1GB boundaries and multiprocess
> >> architecture) should be relatively safe from such ext4 inode(?)/mm(?)
> contentions even with smallest 1kb block sizes on Direct I/O some day.
> >>>
> >>
> >> Interesting. So what parameter values would you suggest?
> >
> > At least have 4x filename= entries and numjobs=4
> >
> >> FWIW some of the tests I did were on xfs, so I wonder if that might
> >> be hitting similar/other bottlenecks.
> >
> > Apparently XFS also shows same contention on single file for 1..2kb randwrite,
> see [ZZZ].
> >
>
> I don't have any results yet, but after thinking about this a bit I find this really
> strange. Why would there be any contention with a single fio job? Doesn't contention
> imply multiple processes competing for the same resource/lock etc.?
Maybe 1 job throws a lot of concurrent random I/Os that contend against the same inodes / pages (?)
> Isn't this simply due to the iodepth increase? IIUC with multiple fio jobs, each
> will use a separate iodepth value. So with numjobs=4, we'll really use iodepth*4,
> which can make a big difference.
I was thinking the same (it should be enough to have big queue depth), but apparently one needs many files (inodes?)
too:
On 1 file I'm not getting a lot of IOPS on small blocksize (even with numjobs), < 20k IOPS always:
numjobs=1/ext4/io_uring/nvme/randwrite/128/1k/1.txt: write: IOPS=13.5k, BW=13.2MiB/s (13.8MB/s)(396MiB/30008msec); 0
zoneresets
numjobs=1/ext4/io_uring/nvme/randwrite/128/4k/1.txt: write: IOPS=49.1k, BW=192MiB/s (201MB/s)(5759MiB/30001msec); 0
zoneresets
numjobs=1/ext4/libaio/nvme/randwrite/128/1k/1.txt: write: IOPS=16.8k, BW=16.4MiB/s (17.2MB/s)(494MiB/30001msec); 0
zoneresets
numjobs=1/ext4/libaio/nvme/randwrite/128/4k/1.txt: write: IOPS=62.5k, BW=244MiB/s (256MB/s)(7324MiB/30001msec); 0 zone
resets
numjobs=1/xfs/io_uring/nvme/randwrite/128/1k/1.txt: write: IOPS=14.7k, BW=14.3MiB/s (15.0MB/s)(429MiB/30008msec); 0
zoneresets
numjobs=1/xfs/io_uring/nvme/randwrite/128/4k/1.txt: write: IOPS=46.4k, BW=181MiB/s (190MB/s)(5442MiB/30002msec); 0
zoneresets
numjobs=1/xfs/libaio/nvme/randwrite/128/1k/1.txt: write: IOPS=22.3k, BW=21.8MiB/s (22.9MB/s)(654MiB/30001msec); 0 zone
resets
numjobs=1/xfs/libaio/nvme/randwrite/128/4k/1.txt: write: IOPS=59.6k, BW=233MiB/s (244MB/s)(6988MiB/30001msec); 0 zone
resets
numjobs=4/ext4/io_uring/nvme/randwrite/128/1k/1.txt: write: IOPS=13.9k, BW=13.6MiB/s (14.2MB/s)(407MiB/30035msec); 0
zoneresets [FAIL 4*qdepth]
numjobs=4/ext4/io_uring/nvme/randwrite/128/4k/1.txt: write: IOPS=52.9k, BW=207MiB/s (217MB/s)(6204MiB/30010msec); 0
zoneresets
numjobs=4/ext4/libaio/nvme/randwrite/128/1k/1.txt: write: IOPS=17.9k, BW=17.5MiB/s (18.4MB/s)(525MiB/30001msec); 0
zoneresets [FAIL 4*qdepth]
numjobs=4/ext4/libaio/nvme/randwrite/128/4k/1.txt: write: IOPS=63.3k, BW=247MiB/s (259MB/s)(7417MiB/30001msec); 0 zone
resets
numjobs=4/xfs/io_uring/nvme/randwrite/128/1k/1.txt: write: IOPS=14.3k, BW=13.9MiB/s (14.6MB/s)(419MiB/30033msec); 0
zoneresets [FAIL 4*qdepth]
numjobs=4/xfs/io_uring/nvme/randwrite/128/4k/1.txt: write: IOPS=50.5k, BW=197MiB/s (207MB/s)(5917MiB/30010msec); 0
zoneresets
numjobs=4/xfs/libaio/nvme/randwrite/128/1k/1.txt: write: IOPS=19.6k, BW=19.1MiB/s (20.1MB/s)(574MiB/30001msec); 0 zone
resets[FAIL 4*qdepth]
numjobs=4/xfs/libaio/nvme/randwrite/128/4k/1.txt: write: IOPS=63.6k, BW=248MiB/s (260MB/s)(7448MiB/30001msec); 0 zone
resets
Now with 4 files: It is necessary to have *both* 4 files and bigger processes to get the result, irrespective of IO
interfaceand fs to get closer to at least half of IOPS max
numjobs=1/ext4/io_uring/nvme/randwrite/128/1k/1.txt: write: IOPS=28.3k, BW=27.6MiB/s (28.9MB/s)(834MiB/30230msec); 0
zoneresets
numjobs=1/ext4/io_uring/nvme/randwrite/128/4k/1.txt: write: IOPS=57.8k, BW=226MiB/s (237MB/s)(6772MiB/30001msec); 0
zoneresets
numjobs=1/ext4/libaio/nvme/randwrite/128/1k/1.txt: write: IOPS=17.3k, BW=16.9MiB/s (17.7MB/s)(506MiB/30001msec); 0
zoneresets
numjobs=1/ext4/libaio/nvme/randwrite/128/4k/1.txt: write: IOPS=61.6k, BW=240MiB/s (252MB/s)(7215MiB/30001msec); 0 zone
resets
numjobs=1/xfs/io_uring/nvme/randwrite/128/1k/1.txt: write: IOPS=24.3k, BW=23.8MiB/s (24.9MB/s)(713MiB/30008msec); 0
zoneresets
numjobs=1/xfs/io_uring/nvme/randwrite/128/4k/1.txt: write: IOPS=54.7k, BW=214MiB/s (224MB/s)(6408MiB/30002msec); 0
zoneresets
numjobs=1/xfs/libaio/nvme/randwrite/128/1k/1.txt: write: IOPS=22.1k, BW=21.6MiB/s (22.6MB/s)(648MiB/30001msec); 0 zone
resets
numjobs=1/xfs/libaio/nvme/randwrite/128/4k/1.txt: write: IOPS=65.7k, BW=257MiB/s (269MB/s)(7705MiB/30001msec); 0 zone
resets
numjobs=4/ext4/io_uring/nvme/randwrite/128/1k/1.txt: write: IOPS=34.1k, BW=33.3MiB/s (34.9MB/s)(999MiB/30020msec); 0
zoneresets [OK?]
numjobs=4/ext4/io_uring/nvme/randwrite/128/4k/1.txt: write: IOPS=64.5k, BW=252MiB/s (264MB/s)(7565MiB/30003msec); 0
zoneresets
numjobs=4/ext4/libaio/nvme/randwrite/128/1k/1.txt: write: IOPS=49.7k, BW=48.5MiB/s (50.9MB/s)(1456MiB/30001msec); 0
zoneresets [OK]
numjobs=4/ext4/libaio/nvme/randwrite/128/4k/1.txt: write: IOPS=67.1k, BW=262MiB/s (275MB/s)(7874MiB/30037msec); 0 zone
resets
numjobs=4/xfs/io_uring/nvme/randwrite/128/1k/1.txt: write: IOPS=33.9k, BW=33.1MiB/s (34.7MB/s)(994MiB/30026msec); 0
zoneresets [OK?]
numjobs=4/xfs/io_uring/nvme/randwrite/128/4k/1.txt: write: IOPS=67.7k, BW=264MiB/s (277MB/s)(7933MiB/30007msec); 0
zoneresets
numjobs=4/xfs/libaio/nvme/randwrite/128/1k/1.txt: write: IOPS=61.0k, BW=59.5MiB/s (62.4MB/s)(1786MiB/30001msec); 0
zoneresets [OK]
numjobs=4/xfs/libaio/nvme/randwrite/128/4k/1.txt: write: IOPS=69.2k, BW=270MiB/s (283MB/s)(8111MiB/30004msec); 0 zone
resets
It makes me thing this looks like some file/inode<->process kind of a locking (reminder: Direct I/O case) -- note that
evenwith files=4 and numjobs=1 it doesn't reach those levels it should. One way or another PostgreSQL should be safe on
OLTP- that's the first though, but on 2nd thought - when thinking about extreme IOPS and single-threaded checkpointer /
bgwriter/ walrecovery on standbys I'm not so sure. In potential future IO API implementations - with Direct I/O (???) -
the1kb, 2kb apparently would seem to be limited unless you parallelize those processes due to some internal kernel
locking(sigh! - at least that's what the result the 4 files/numjobs=1/../1k cases indicate; this may vary across kernel
versionsas per earlier link).
> >>>
> >>> Explanation: it's the CPU scheduler migrations mixing the
> >>> performance result
> >> during the runs of fio (as you have in your framework). Various
> >> VCPUs seem to be having varying max IOPS characteristics (sic!) and
> >> CPU scheduler seems to be unaware of it. At least on 1kB and 4kB
> >> blocksize this happens also notice that some VCPUs [XXXX marker]
> >> don't reach 100% CPU reaching almost twice the result; while cores 0, 3 do
> reach 100% and lack CPU power to perform more.
> >> The only thing that I don't get is that it doesn't make sense from
> >> extened lscpu output (but maybe it's AWS XEN mixing real CPU mappings,
> who knows).
> >>
> >> Uh, that's strange. I haven't seen anything like that, but I'm
> >> running on physical HW and not AWS, so it's either that or maybe I just didn't
> do the same test.
> >
> > I couldn't belived it until I've checked via taskset 😊 BTW: I don't
> > have real HW with NVMe , but we might be with worth checking if
> > placing (taskset -c ...) fio on hyperthreading VCPU is not causing
> > (there's /sys/devices/system/cpu/cpu0/topology/thread_siblings and
> > maybe lscpu(1) output). On AWS I have feeling that lscpu might simply
> > lie and I cannot identify which VCPU is HT and which isn't.
>
> Did you see the same issue with io_uring?
Yes, tested today, got similar results (io_uring doesn’t change a thing and BTW it looks like hypervisor shifts real HW
CPUsto logical VCPUs ) After reading this https://wiki.xenproject.org/wiki/Hyperthreading (section: Is Xen
hyperthreadingaware), I think solid NVMe testing shouldn't be conducted on anything virtualized - I have no control
overpotentially noisy CPU-heavy neighbors. So please take my results for with grain of salt, unless somebody reproduces
thistaskset -c .. fio tests on proper isolated HW, but another thing: that's where PostgreSQL runs in reality.
-J.
I did a couple tests to evaluate the impact of filesystem overhead and block size, so here are some preliminary results. I'm running a more extensive set of tests, but some of this seems interesting. I did two sets of tests: 1) fio test on raw devices 2) fio tests on ext4/xfs with different fs block size Both sets of tests were executed with varying iodepth (1, 2, 4, ...) and number of processes (1, 8). The results are attached - CSV file with results, and PDF with pivot tables showing them in more readable format. 1) raw device tests The results for raw devices have regular patterns, with smaller blocks giving better performance - particularly for read workloads. For write workloads, it's similar, except that 4K blocks perform better than 1-2K ones (this applies especially to the NVMe device). 2) fs tests This shows how the tests perform on ext4/xfs filesystems with different block sizes (1K-4K). Overall the patterns are fairly similar to raw devices. There are a couple strange things, though. For example, ext4 often behaves like this on the "write" (i.e. sequential write) benchmark: fs block 1K 2K 4K 8K 16K 32K -------------------------------------------------------------- 1024 33374 28290 27286 26453 22341 19568 2048 33420 38595 75741 63790 48474 33474 4096 33959 38913 73949 63940 49217 33017 It's somewhat expected that 1-2K blocks perform worse than 4K (the raw device behaves the same way), but notice how the behavior differs depending on the fs block. For 2k and 4K fs blocks the throughput improves, but for 1K blocks it just goes down. For higher iodepth values this is even more visible: fs block 1K 2K 4K 8K 16K 32K ------------------------------------------------------------ 1024 34879 25708 24744 23937 22527 19357 2048 31648 50348 282696 236118 121750 60646 4096 34273 39890 273395 214817 135072 66943 The interesting thing is xfs does not have this issue. Furthermore, it seems interesting to compare iops on a filesystem to the raw device, which might be seen as "best case" without the fs overhead. The "comparison" attachmens do exactly that. There are two interesting observations, here: 1) ext4 seems to have some issue with 1-2K random writes (randrw and randwrite tests) with larger 2-4K filesystem blocks. Consider for example this: fs block 1K 2K 4K 8K 16K 32K ------------------------------------------------------------------ 1024 214765 143564 108075 83098 58238 38569 2048 66010 216287 260116 214541 113848 57045 4096 66656 64155 268141 215860 109175 54877 Agian, the xfs does not behave like this. 2) Interestingly enough, compe cases can actually perform better on a filesystem than directly on the raw device - I'm not sure what's the explanation, but it only happens on the SSD RAID (not on the NVMe), and with higher iodepth values. regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
On Sat, Jun 4, 2022 at 6:23 PM Tomas Vondra <tomas.vondra@enterprisedb.com> wrote:
Hi,
At on of the pgcon unconference sessions a couple days ago, I presented
a bunch of benchmark results comparing performance with different
data/WAL block size. Most of the OLTP results showed significant gains
(up to 50%) with smaller (4k) data pages.
Wow. Random numbers are fantastic, Significant reduction in sequential throughput is a little painful though, I see 40% reduction in some cases if I'm reading that right. Any thoughts on why that's the case? Are there mitigations possible?
merlin
On 6/13/22 17:42, Merlin Moncure wrote: > On Sat, Jun 4, 2022 at 6:23 PM Tomas Vondra > <tomas.vondra@enterprisedb.com <mailto:tomas.vondra@enterprisedb.com>> > wrote: > > Hi, > > At on of the pgcon unconference sessions a couple days ago, I presented > a bunch of benchmark results comparing performance with different > data/WAL block size. Most of the OLTP results showed significant gains > (up to 50%) with smaller (4k) data pages. > > > Wow. Random numbers are fantastic, Significant reduction in sequential > throughput is a little painful though, I see 40% reduction in some cases > if I'm reading that right. Any thoughts on why that's the case? Are > there mitigations possible? > I think you read that right - given a fixed I/O depth, the throughput for sequential access gets reduced. Consider for example the attached chart with sequential read/write results for the Optane 900P. The IOPS increases for smaller blocks, but not enough to compensate for the bandwidth drop. Regarding the mitigations - I think prefetching (read-ahead) should do the trick. Just going to iodepth=2 mostly makes up for the bandwidth difference. You might argue prefetching would improve the random I/O results too, but I don't think that's the same thing - read-ahead for sequential workloads is much easier to implement (even transparently). regards -- Tomas Vondra EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
{kind=link}