Thread: Unicode Variation Selector and Combining character
Hi,
I tried it on PostgreSQL 13. If you use the Unicode Variation Selector and Combining Character, the base character and the Variation selector will be 2 in length. Since it will be one character on the display, we expect it to be one in length. Please provide a function corresponding to the unicode variasion selector. I hope It is supposed to be provided as an extension.
The functions that need to be supported are as follows:
char_length|character_length|substring|trim|btrim|left
|length|lpad|ltrim|regexp_match|regexp_matches
|regexp_replace|regexp_split_to_array|regexp_split_to_table
|replace|reverse|right|rpad|rtrim|split_part|strpos|substr|starts_with
Best regartds,
On 30.05.22 02:27, 荒井元成 wrote: > I tried it on PostgreSQL 13. If you use the Unicode Variation Selector > and Combining Character > > , the base character and the Variation selector will be 2 in length. > Since it will be one character on the display, we expect it to be one in > length. Please provide a function corresponding to the unicode variasion > selector. I hope It is supposed to be provided as an extension. > > The functions that need to be supported are as follows: > > char_length|character_length|substring|trim|btrim|left > > |length|lpad|ltrim|regexp_match|regexp_matches > > |regexp_replace|regexp_split_to_array|regexp_split_to_table > > |replace|reverse|right|rpad|rtrim|split_part|strpos|substr|starts_with Please show a test case of what you mean. For example, select char_length(...) returns X but should return Y Examples with Unicode escapes (U&'\NNNN...') would be the most robust.
Thank you for your reply.
We use IPAmj Mincho Font in the specifications of the Government of Japan.
https://moji.or.jp/mojikiban/font/
Exsample)IVS
I will attach an image.

D209007=# select char_length(U&'\+0066FE' || U&'\+0E0103') ;
char_length
-------------
2
(1 行)
I expect length 1.
Exsample)Combining Character
I will attach an image.

D209007=# select char_length(U&'\+00304B' || U&'\+00309A') ;
char_length
-------------
2
(1 行)
I expect length 1.
thank you.
-----Original Message-----
From: Peter Eisentraut <peter.eisentraut@enterprisedb.com>
Sent: Wednesday, June 1, 2022 2:27 PM
To: 荒井元成 <n2029@ndensan.co.jp>; pgsql-hackers@lists.postgresql.org
Subject: Re: Unicode Variation Selector and Combining character
On 30.05.22 02:27, 荒井元成 wrote:
> I tried it on PostgreSQL 13. If you use the Unicode Variation Selector
> and Combining Character
>
> , the base character and the Variation selector will be 2 in length.
> Since it will be one character on the display, we expect it to be one
> in length. Please provide a function corresponding to the unicode
> variasion selector. I hope It is supposed to be provided as an extension.
>
> The functions that need to be supported are as follows:
>
> char_length|character_length|substring|trim|btrim|left
>
> |length|lpad|ltrim|regexp_match|regexp_matches
>
> |regexp_replace|regexp_split_to_array|regexp_split_to_table
>
> |replace|reverse|right|rpad|rtrim|split_part|strpos|substr|starts_with
Please show a test case of what you mean. For example,
select char_length(...) returns X but should return Y
Examples with Unicode escapes (U&'\NNNN...') would be the most robust.
Attachment
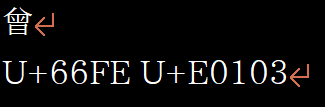{kind=link}
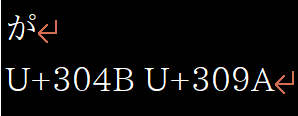{kind=link}
{kind=link}
{kind=link}
On Wed, Jun 1, 2022 at 6:15 PM 荒井元成 <n2029@ndensan.co.jp> wrote: > D209007=# select char_length(U&'\+0066FE' || U&'\+0E0103') ; > char_length > ------------- > 2 > (1 行) > > I expect length 1. No opinion here, but I did happen to see Noriyoshi Shinoda's slides about this topic a little while ago, comparing different databases: https://www.slideshare.net/noriyoshishinoda/postgresql-unconference-29-unicode-ivs It's the same with Latin combining characters... we count the individual codepoints of combining sequences: postgres=# select 'e' || U&'\0301', length('e' || U&'\0301'); ?column? | length ----------+-------- é | 2 (1 row)
On Wed, Jun 1, 2022 at 7:09 PM Thomas Munro <thomas.munro@gmail.com> wrote: > On Wed, Jun 1, 2022 at 6:15 PM 荒井元成 <n2029@ndensan.co.jp> wrote: > > D209007=# select char_length(U&'\+0066FE' || U&'\+0E0103') ; > > char_length > > ------------- > > 2 > > (1 行) > > > > I expect length 1. > > No opinion here, but I did happen to see Noriyoshi Shinoda's slides > about this topic a little while ago, comparing different databases: > > https://www.slideshare.net/noriyoshishinoda/postgresql-unconference-29-unicode-ivs > > It's the same with Latin combining characters... we count the > individual codepoints of combining sequences: > > postgres=# select 'e' || U&'\0301', length('e' || U&'\0301'); > ?column? | length > ----------+-------- > é | 2 > (1 row) Looking around a bit, it might be interesting to check if the icu_character_boundaries() function in Daniel Vérité's icu_ext treats IVSs as single grapheme clusters.
Thomas Munro wrote:
> Looking around a bit, it might be interesting to check if the
> icu_character_boundaries() function in Daniel Vérité's icu_ext treats
> IVSs as single grapheme clusters.
It does.
with strings(s) as (
values (U&'\+0066FE' || U&'\+0E0103'),
(U&'\+00304B' || U&'\+00309A')
)
select s,
octet_length(s),
char_length(s),
(select count(*) from icu_character_boundaries(s,'en')) as graphemes
from strings;
s | octet_length | char_length | graphemes
-----+--------------+-------------+-----------
曾󠄃 | 7 | 2 | 1
か゚ | 6 | 2 | 1
Best regards,
--
Daniel Vérité
https://postgresql.verite.pro/
Twitter: @DanielVerite
On 01.06.22 08:15, 荒井元成 wrote: > D209007=# select char_length(U&'\+0066FE' || U&'\+0E0103') ; > > char_length > > ------------- > > 2 > > (1 行) > > I expect length 1. The char_length function is defined to return the length in characters, so 2 is the correct answer. What you appear to be looking for is length in glyphs or length in graphemes or display width, or something like that. There is no built-in server side function for that. It looks like psql is getting the display width wrong, but that's a separate issue.
Thank you for your reply.
I will check if there is any function below char_length that is realized by icu_ext.
substring|trim|btrim|left
|lpad|ltrim|regexp_match|regexp_matches
|regexp_replace|regexp_split_to_array|regexp_split_to_table
|replace|reverse|right|rpad|rtrim|split_part|strpos|substr|starts_with
Best regards,
-----Original Message-----
From: Daniel Verite <daniel@manitou-mail.org>
Sent: Wednesday, June 1, 2022 6:46 PM
To: Thomas Munro <thomas.munro@gmail.com>
Cc: 荒井元成 <n2029@ndensan.co.jp>; Peter Eisentraut <peter.eisentraut@enterprisedb.com>; PostgreSQL Hackers
<pgsql-hackers@lists.postgresql.org>
Subject: Re: Unicode Variation Selector and Combining character
Thomas Munro wrote:
> Looking around a bit, it might be interesting to check if the
> icu_character_boundaries() function in Daniel Vérité's icu_ext treats
> IVSs as single grapheme clusters.
It does.
with strings(s) as (
values (U&'\+0066FE' || U&'\+0E0103'),
(U&'\+00304B' || U&'\+00309A')
)
select s,
octet_length(s),
char_length(s),
(select count(*) from icu_character_boundaries(s,'en')) as graphemes from strings;
s | octet_length | char_length | graphemes
-----+--------------+-------------+-----------
曾󠄃 | 7 | 2 | 1
か゚ | 6 | 2 | 1
Best regards,
--
Daniel Vérité
https://postgresql.verite.pro/
Twitter: @DanielVerite