Thread: Improving btree performance through specializing by key shape, take 2
Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
Hi, Here's a new patch, well-timed for the next feature freeze. [0] Last year I submitted a patchset that updated the way nbtree keys are compared [1]; by moving from index_getattr to an iterator-based approach. That patch did perform quite well for multi-column indexes, but significantly reduced performance for keys that benefit from Form_pg_attribute->attcacheoff. Here's generation 2 of this effort. Instead of proceeding to trying to shoehorn all types of btree keys into one common code path, this patchset acknowledges that there exist different shapes of keys that each have a different best way of accessing each subsequent key attribute. This patch achieves this by specializing the functions to different key shapes. The approach is comparable to JIT, but significantly different in that it optimizes a set of statically defined shapes, and not any arbitrary shape through a runtime compilation step. Jit could be implemented, but not easily with the APIs available to IndexAMs: the amhandler for indexes does not receive any information what the shape of the index is going to be; so 0001: Moves code that can benefit from key attribute accessor specialization out of their current files and into specializable files. The functions selected for specialization are either not much more than wrappers for specializable functions, or functions that have (hot) loops around specializable code; where specializable means accessing multiple IndexTuple attributes directly. 0002: Updates the specializable code to use the specialized attribute iteration macros 0003: Optimizes access to the key column when there's only one key column. 0004: Optimizes access to the key columns when we cannot use attcacheoff for the key columns 0005: Creates a helper function to populate all attcacheoff fields with their correct values; populating them with -2 whenever a cache offset is impossible to determine, as opposed to the default -1 (unknown); allowing functions to determine the cachability of the n-th attribute in O(1). 0006: Creates a specialization macro that replaces rd_indam->aminsert with its optimized variant, for improved index tuple insertion performance. These patches still have some rough edges (specifically: some functions that are being generated are unused, and intermediate patches don't compile), but I wanted to get this out to get some feedback on this approach. I expect the performance to be at least on par with current btree code, and I'll try to publish a more polished patchset with performance results sometime in the near future. I'll also try to re-attach dynamic page-level prefix truncation, but that depends on the amount of time I have and the amount of feedback on this patchset. -Matthias [0] The one for PG16, that is. [1] https://www.postgresql.org/message-id/CAEze2Whwvr8aYcBf0BeBuPy8mJGtwxGvQYA9OGR5eLFh6Q_ZvA@mail.gmail.com
Attachment
- v1-0004-Implement-specialized-uncacheable-attribute-itera.patch
- v1-0005-Add-a-function-whose-task-it-is-to-populate-all-a.patch
- v1-0002-Use-specialized-attribute-iterators-in-nbt-_spec..patch
- v1-0003-Optimize-attribute-iterator-access-for-single-col.patch
- v1-0001-Specialize-nbtree-functions-on-btree-key-shape.patch
- v1-0006-Specialize-the-nbtree-rd_indam-entry.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Peter Geoghegan
Date:
On Fri, Apr 8, 2022 at 9:55 AM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > Here's generation 2 of this effort. Instead of proceeding to trying to > shoehorn all types of btree keys into one common code path, this > patchset acknowledges that there exist different shapes of keys that > each have a different best way of accessing each subsequent key > attribute. This patch achieves this by specializing the functions to > different key shapes. Cool. > These patches still have some rough edges (specifically: some > functions that are being generated are unused, and intermediate > patches don't compile), but I wanted to get this out to get some > feedback on this approach. I attempted to apply your patch series to get some general sense of how it affects performance, by using my own test cases from previous nbtree project work. I gave up on that pretty quickly, though, since the code wouldn't compile. That in itself might have been okay (some "rough edges" are generally okay). The real problem was that it wasn't clear what I was expected to do about it! You mentioned that some of the patches just didn't compile, but which ones? How do I quickly get some idea of the benefits on offer here, however imperfect or preliminary? Can you post a version of this that compiles? As a general rule you should try to post patches that can be "test driven" easily. An opening paragraph that says "here is why you should care about my patch" is often something to strive for, too. I suspect that you actually could have done that here, but you didn't, for whatever reason. > I expect the performance to be at least on par with current btree > code, and I'll try to publish a more polished patchset with > performance results sometime in the near future. I'll also try to > re-attach dynamic page-level prefix truncation, but that depends on > the amount of time I have and the amount of feedback on this patchset. Can you give a few motivating examples? You know, queries that are sped up by the patch series, with an explanation of where the benefit comes from. You had some on the original thread, but that included dynamic prefix truncation stuff as well. Ideally you would also describe where the adversized improvements come from for each test case -- which patch, which enhancement (perhaps only in rough terms for now). -- Peter Geoghegan
Re: Improving btree performance through specializing by key shape, take 2
From
Peter Geoghegan
Date:
On Sun, Apr 10, 2022 at 2:44 PM Peter Geoghegan <pg@bowt.ie> wrote: > Can you post a version of this that compiles? I forgot to add: the patch also bitrot due to recent commit dbafe127. I didn't get stuck at this point (this is minor bitrot), but no reason not to rebase. -- Peter Geoghegan
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Sun, 10 Apr 2022 at 23:45, Peter Geoghegan <pg@bowt.ie> wrote: > > On Fri, Apr 8, 2022 at 9:55 AM Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > Here's generation 2 of this effort. Instead of proceeding to trying to > > shoehorn all types of btree keys into one common code path, this > > patchset acknowledges that there exist different shapes of keys that > > each have a different best way of accessing each subsequent key > > attribute. This patch achieves this by specializing the functions to > > different key shapes. > > Cool. > > > These patches still have some rough edges (specifically: some > > functions that are being generated are unused, and intermediate > > patches don't compile), but I wanted to get this out to get some > > feedback on this approach. > > I attempted to apply your patch series to get some general sense of > how it affects performance, by using my own test cases from previous > nbtree project work. I gave up on that pretty quickly, though, since > the code wouldn't compile. That in itself might have been okay (some > "rough edges" are generally okay). The real problem was that it wasn't > clear what I was expected to do about it! You mentioned that some of > the patches just didn't compile, but which ones? How do I quickly get > some idea of the benefits on offer here, however imperfect or > preliminary? > > Can you post a version of this that compiles? As a general rule you > should try to post patches that can be "test driven" easily. An > opening paragraph that says "here is why you should care about my > patch" is often something to strive for, too. I suspect that you > actually could have done that here, but you didn't, for whatever > reason. Yes, my bad. I pulled one patch that included unrelated changes from the set; but I missed that it also contained some changes that should've been in an earlier commit, thus breaking the set. I'll send an updated patchset soon (I'm planning on moving around when what is changed/added); but before that the attached incremental patch should help. FYI, the patchset has been tested on commit 05023a23, and compiles (with unused function warnings) after applying the attached patch. > > I expect the performance to be at least on par with current btree > > code, and I'll try to publish a more polished patchset with > > performance results sometime in the near future. I'll also try to > > re-attach dynamic page-level prefix truncation, but that depends on > > the amount of time I have and the amount of feedback on this patchset. > > Can you give a few motivating examples? You know, queries that are > sped up by the patch series, with an explanation of where the benefit > comes from. You had some on the original thread, but that included > dynamic prefix truncation stuff as well. Queries that I expect to be faster are situations where the index does front-to-back attribute accesses in a tight loop and repeated index lookups; such as in index builds, data loads, JOINs, or IN () and = ANY () operations; and then specifically for indexes with only a single key attribute, or indexes where we can determine based on the index attributes' types that nocache_index_getattr will be called at least once for a full _bt_compare call (i.e. att->attcacheoff cannot be set for at least one key attribute). Queries that I expect to be slower to a limited degree are hot loops on btree indexes that do not have a specifically optimized path, as there is some extra overhead calling the specialized functions. Other code might also see a minimal performance impact due to an increased binary size resulting in more cache thrashing. > Ideally you would also describe where the adversized improvements come > from for each test case -- which patch, which enhancement (perhaps > only in rough terms for now). In the previous iteration, I discerned that there are different "shapes" of indexes, some of which currently have significant overhead in the existing btree infrastructure. Especially indexes with multiple key attributes can see significant overhead while their attributes are being extracted, which (for a significant part) can be attributed to the O(n) behaviour of nocache_index_getattr. This O(n) overhead is currently avoided only by indexes with only a single key attribute and by indexes in which all key attributes have a fixed size (att->attlen > 0). The types of btree keys I discerned were: CREATE INDEX ON tst ... ... (single_key_attribute) ... (varlen, other, attributes, ...) ... (fixed_size, also_fixed, ...) ... (sometimes_null, other, attributes, ...) For single-key-attribute btrees, the performance benefits in the patch are achieved by reducing branching in the attribute extraction: There are no other key attributes to worry about, so much of the code dealing with looping over attributes can inline values, and thus reduce the amount of code generated in the hot path. For btrees with multiple key attributes, benefits are achieved if some attributes are of variable length (e.g. text): On master, if your index looks like CREATE INDEX ON tst (varlen, fixed, fixed), for the latter attributes the code will always hit the slow path of nocache_index_getattr. This introduces a significant overhead; as that function wants to re-establish that the requested attribute's offset is indeed not cached and not cacheable, and calculates the requested attributes' offset in the tuple from effectively zero. That is usually quite wasteful, as (in btree code, usually) we'd already calculated the previous attribute's offset just a moment ago; which should be reusable. In this patch, the code will use an attribute iterator (as described and demonstrated in the linked thread) to remove this O(n) per-attribute overhead and change the worst-case complexity of iterating over the attributes of such an index tuple from O(n^2) to O(n). Null attributes in the key are not yet handled in any special manner in this patch. That is mainly because it is impossible to statically determine which attribute is going to be null based on the index definition alone, and thus doesn't benefit as much from statically generated optimized paths. -Mathias
Attachment
Re: Improving btree performance through specializing by key shape, take 2
From
Peter Geoghegan
Date:
On Sun, Apr 10, 2022 at 4:08 PM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > I'll send an updated patchset soon (I'm planning on moving around when > what is changed/added); but before that the attached incremental patch > should help. FYI, the patchset has been tested on commit 05023a23, and > compiles (with unused function warnings) after applying the attached > patch. I can get it to work now, with your supplemental patch. > Queries that I expect to be faster are situations where the index does > front-to-back attribute accesses in a tight loop and repeated index > lookups; such as in index builds, data loads, JOINs, or IN () and = > ANY () operations; and then specifically for indexes with only a > single key attribute, or indexes where we can determine based on the > index attributes' types that nocache_index_getattr will be called at > least once for a full _bt_compare call (i.e. att->attcacheoff cannot > be set for at least one key attribute). I did some quick testing of the patch series -- pretty much just reusing my old test suite from the Postgres 12 and 13 nbtree work. This showed that there is a consistent improvement in some cases. It also failed to demonstrate any performance regressions. That's definitely a good start. I saw about a 4% reduction in runtime for the same UK land registry test that you yourself have run in the past for the same patch series [1]. I suspect that there just aren't that many ways to get that kind of speed up with this test case, except perhaps by further compressing the on-disk representation used by nbtree. My guess is that the patch reduces the runtime for this particular test case to a level that's significantly closer to the limit for this particular piece of silicon. Which is not to be sniffed at. Admittedly these test cases were chosen purely because they were convenient. They were originally designed to test space utilization, which isn't affected either way here. I like writing reproducible test cases for indexing stuff, and think that it could work well here too (even though you're not optimizing space utilization at all). A real test suite that targets a deliberately chosen cross section of "index shapes" might work very well. > In the previous iteration, I discerned that there are different > "shapes" of indexes, some of which currently have significant overhead > in the existing btree infrastructure. Especially indexes with multiple > key attributes can see significant overhead while their attributes are > being extracted, which (for a significant part) can be attributed to > the O(n) behaviour of nocache_index_getattr. This O(n) overhead is > currently avoided only by indexes with only a single key attribute and > by indexes in which all key attributes have a fixed size (att->attlen > > 0). Good summary. > The types of btree keys I discerned were: > CREATE INDEX ON tst ... > ... (single_key_attribute) > ... (varlen, other, attributes, ...) > ... (fixed_size, also_fixed, ...) > ... (sometimes_null, other, attributes, ...) > > For single-key-attribute btrees, the performance benefits in the patch > are achieved by reducing branching in the attribute extraction: There > are no other key attributes to worry about, so much of the code > dealing with looping over attributes can inline values, and thus > reduce the amount of code generated in the hot path. I agree that it might well be useful to bucket indexes into several different "index shape archetypes" like this. Roughly the same approach worked well for me in the past. This scheme might turn out to be reductive, but even then it could still be very useful (all models are wrong, some are useful, now as ever). > For btrees with multiple key attributes, benefits are achieved if some > attributes are of variable length (e.g. text): > On master, if your index looks like CREATE INDEX ON tst (varlen, > fixed, fixed), for the latter attributes the code will always hit the > slow path of nocache_index_getattr. This introduces a significant > overhead; as that function wants to re-establish that the requested > attribute's offset is indeed not cached and not cacheable, and > calculates the requested attributes' offset in the tuple from > effectively zero. Right. So this particular index shape seems like something that we treat in a rather naive way currently. Can you demonstrate that with a custom test case? (The result I cited before was from a '(varlen,varlen,varlen)' index, which is important, but less relevant.) [1] https://www.postgresql.org/message-id/flat/CAEze2Whwvr8aYcBf0BeBuPy8mJGtwxGvQYA9OGR5eLFh6Q_ZvA%40mail.gmail.com -- Peter Geoghegan
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Mon, 11 Apr 2022 at 03:11, Peter Geoghegan <pg@bowt.ie> wrote: > > On Sun, Apr 10, 2022 at 4:08 PM Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > I'll send an updated patchset soon (I'm planning on moving around when > > what is changed/added); but before that the attached incremental patch > > should help. FYI, the patchset has been tested on commit 05023a23, and > > compiles (with unused function warnings) after applying the attached > > patch. > > I can get it to work now, with your supplemental patch. Great. Attached is the updated patchset, with as main changes: - Rebased on top of 5bb2b6ab - All patches should compile when built on top of each preceding patch. - Reordered the patches to a more logical order, and cleaned up the content of each patch - Updated code so that GCC doesn't warn about unused code. - Add a patch for dynamic prefix truncation at page level; ref thread at [1]. - Fixed issues in the specialization macros that resulted in issues with DPT above. Still to-do: - Validate performance and share the numbers for the same test indexes in [1]. I'm planning on doing that next Monday. - Decide whether / how to keep the NBTS_ENABLED flag. The current #define in nbtree.h is a bad example of a compile-time configuration, that should be changed (even if we only want to be able to disable specialization at compile-time, it should be moved). Maybe: - More tests: PG already extensively tests the btree code while it is running the test suite - btree is the main index AM - but more tests might be needed to test the validity of the specialized code. > > Queries that I expect to be faster are situations where the index does > > front-to-back attribute accesses in a tight loop and repeated index > > lookups; such as in index builds, data loads, JOINs, or IN () and = > > ANY () operations; and then specifically for indexes with only a > > single key attribute, or indexes where we can determine based on the > > index attributes' types that nocache_index_getattr will be called at > > least once for a full _bt_compare call (i.e. att->attcacheoff cannot > > be set for at least one key attribute). > > I did some quick testing of the patch series -- pretty much just > reusing my old test suite from the Postgres 12 and 13 nbtree work. > This showed that there is a consistent improvement in some cases. It > also failed to demonstrate any performance regressions. That's > definitely a good start. > > I saw about a 4% reduction in runtime for the same UK land registry > test that you yourself have run in the past for the same patch series > [1]. That's good to know. The updated patches (as attached) have dynamic prefix truncation from the patch series in [1] added too, which should improve the performance by a few more percentage points in that specific test case. > I suspect that there just aren't that many ways to get that kind > of speed up with this test case, except perhaps by further compressing > the on-disk representation used by nbtree. My guess is that the patch > reduces the runtime for this particular test case to a level that's > significantly closer to the limit for this particular piece of > silicon. Which is not to be sniffed at. > > Admittedly these test cases were chosen purely because they were > convenient. They were originally designed to test space utilization, > which isn't affected either way here. I like writing reproducible test > cases for indexing stuff, and think that it could work well here too > (even though you're not optimizing space utilization at all). A real > test suite that targets a deliberately chosen cross section of "index > shapes" might work very well. I'm not sure what you're refering to. Is the set of indexes I used in [1] an example of what you mean by "test suite of index shapes"? > > In the previous iteration, I discerned that there are different > > "shapes" of indexes, some of which currently have significant overhead > > in the existing btree infrastructure. Especially indexes with multiple > > key attributes can see significant overhead while their attributes are > > being extracted, which (for a significant part) can be attributed to > > the O(n) behaviour of nocache_index_getattr. This O(n) overhead is > > currently avoided only by indexes with only a single key attribute and > > by indexes in which all key attributes have a fixed size (att->attlen > > > 0). > > Good summary. > > > The types of btree keys I discerned were: > > CREATE INDEX ON tst ... > > ... (single_key_attribute) > > ... (varlen, other, attributes, ...) > > ... (fixed_size, also_fixed, ...) > > ... (sometimes_null, other, attributes, ...) > > > > For single-key-attribute btrees, the performance benefits in the patch > > are achieved by reducing branching in the attribute extraction: There > > are no other key attributes to worry about, so much of the code > > dealing with looping over attributes can inline values, and thus > > reduce the amount of code generated in the hot path. > > I agree that it might well be useful to bucket indexes into several > different "index shape archetypes" like this. Roughly the same > approach worked well for me in the past. This scheme might turn out to > be reductive, but even then it could still be very useful (all models > are wrong, some are useful, now as ever). > > > For btrees with multiple key attributes, benefits are achieved if some > > attributes are of variable length (e.g. text): > > On master, if your index looks like CREATE INDEX ON tst (varlen, > > fixed, fixed), for the latter attributes the code will always hit the > > slow path of nocache_index_getattr. This introduces a significant > > overhead; as that function wants to re-establish that the requested > > attribute's offset is indeed not cached and not cacheable, and > > calculates the requested attributes' offset in the tuple from > > effectively zero. > > Right. So this particular index shape seems like something that we > treat in a rather naive way currently. But really every index shape is treated naively, except the cacheable index shapes. The main reason we haven't cared about it much is that you don't often see btrees with many key attributes, and when it's slow that is explained away 'because it is a big index and a wide index key' but still saves orders of magnitude over a table scan, so people generally don't complain about it. A notable exception was 80b9e9c4, where a customer complained about index scans being faster than index only scans. > Can you demonstrate that with a custom test case? (The result I cited > before was from a '(varlen,varlen,varlen)' index, which is important, > but less relevant.) Anything that has a variable length in any attribute other than the last; so that includes (varlen, int) and also (int, int, varlen, int, int, int, int). The catalogs currently seem to include only one such index: pg_proc_proname_args_nsp_index is an index on pg_proc (name (const), oidvector (varlen), oid (const)). - Matthias [1] https://www.postgresql.org/message-id/flat/CAEze2WhyBT2bKZRdj_U0KS2Sbewa1XoO_BzgpzLC09sa5LUROg%40mail.gmail.com#fe3369c4e202a7ed468e47bf5420f530
Attachment
- v2-0002-Use-specialized-attribute-iterators-in-backend-nb.patch
- v2-0005-Add-a-function-whose-task-it-is-to-populate-all-a.patch
- v2-0003-Specialize-the-nbtree-rd_indam-entry.patch
- v2-0004-Optimize-attribute-iterator-access-for-single-col.patch
- v2-0001-Specialize-nbtree-functions-on-btree-key-shape.patch
- v2-0006-Implement-specialized-uncacheable-attribute-itera.patch
- v2-0007-Implement-dynamic-prefix-compression-in-nbtree.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Sat, 16 Apr 2022 at 01:05, Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
> Still to-do:
>
> - Validate performance and share the numbers for the same test indexes
> in [1]. I'm planning on doing that next Monday.
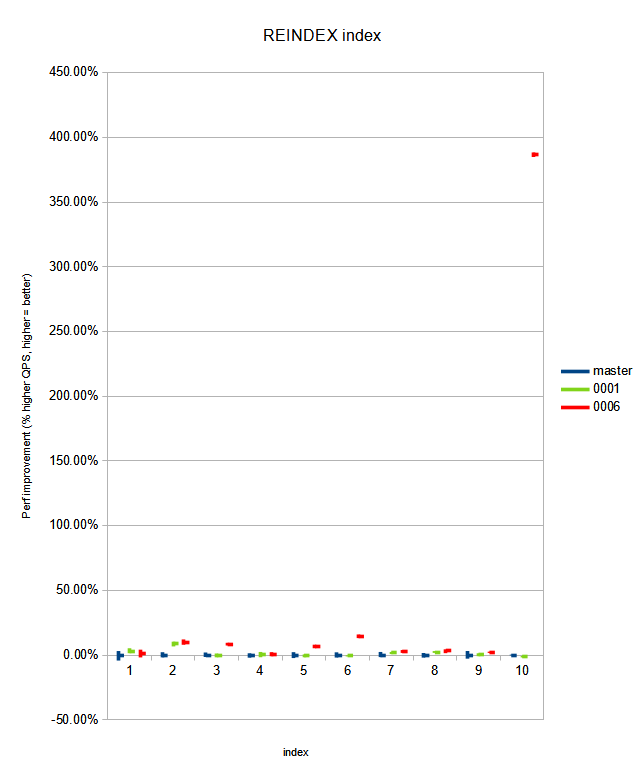
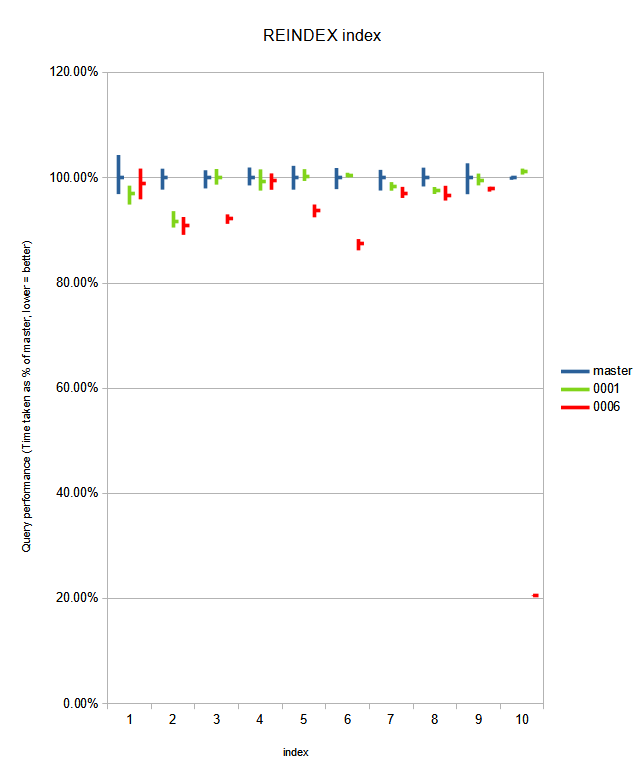
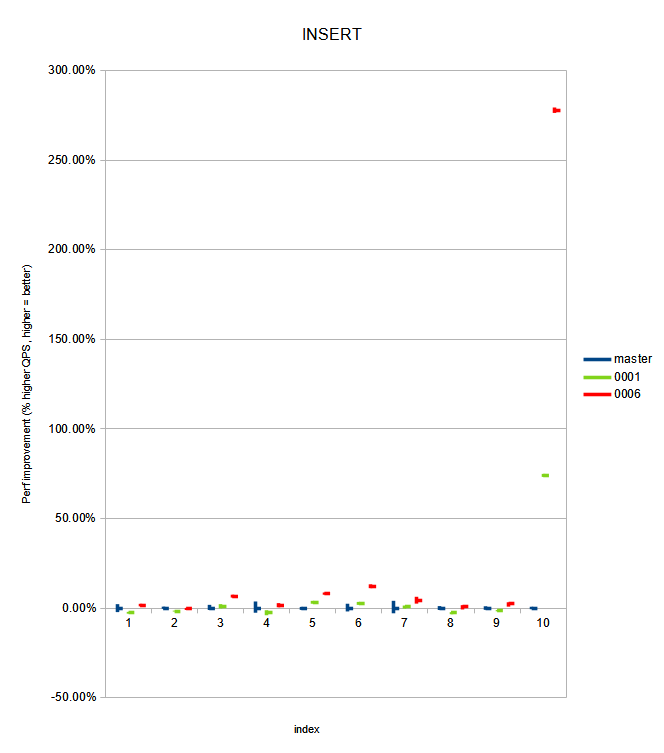
While working on benchmarking the v2 patchset, I noticed no
improvement on reindex, which I attributed to forgetting to also
specialize comparetup_index_btree in tuplesorth.c. After adding the
specialization there as well (attached in v3), reindex performance
improved significantly too.
Performance results attached in pgbench_log.[master,patched], which
includes the summarized output. Notes on those results:
- single-column reindex seem to have the same performance between
patch and master, within 1% error margins.
- multi-column indexes with useful ->attcacheoff also sees no obvious
performance degradation
- multi-column indexes with no useful ->attcacheoff see significant
insert performance improvement:
-8% runtime on 3 text attributes with default (C) collation ("ccl");
-9% runtime on 1 'en_US'-collated attribute + 2 text attributes
("ccl_collated");
-13% runtime on 1 null + 3 text attributes ("accl");
-74% runtime (!) on 31 'en_US'-collated 0-length text attributes + 1
uuid attribute ("worstcase" - I could not think of a worse index shape
than this one).
- reindex performance gains are much more visible: up to 84% (!) less
time spent for "worstcase", and 18-31% for the other multi-column
indexes mentioned above.
Other notes:
- The dataset I used is the same as I used in [1]: the pp-complete.csv
as was available on 2021-06-20, containing 26070307 rows.
- The performance was measured on 7 runs of the attached bench script,
using pgbench to measure statement times etc.
- Database was initialized with C locale, all tables are unlogged and
source table was VACUUM (FREEZE, ANALYZE)-ed before starting.
- (!) On HEAD @ 5bb2b6ab, INSERT is faster than REINDEX for the
"worstcase" index. I've not yet discovered why (only lightly looked
into it, no sort debugging), and considering that the issue does not
appear in similar quantities in the patched version, I'm not planning
on putting a lot of time into that.
- Per-transaction results for the run on master were accidentally
deleted, I don't consider them important enough to re-run the
benchmark.
> - Decide whether / how to keep the NBTS_ENABLED flag. The current
> #define in nbtree.h is a bad example of a compile-time configuration,
> that should be changed (even if we only want to be able to disable
> specialization at compile-time, it should be moved).
>
> Maybe:
>
> - More tests: PG already extensively tests the btree code while it is
> running the test suite - btree is the main index AM - but more tests
> might be needed to test the validity of the specialized code.
No work on those points yet.
I'll add this to CF 2022-07 for tracking.
Kind regards,
Matthias van de Meent.
[1]
https://www.postgresql.org/message-id/flat/CAEze2WhyBT2bKZRdj_U0KS2Sbewa1XoO_BzgpzLC09sa5LUROg%40mail.gmail.com#fe3369c4e202a7ed468e47bf5420f530
Attachment
- performance_comparison.txt
- v3-0003-Specialize-the-nbtree-rd_indam-entry.patch
- v3-0001-Specialize-nbtree-functions-on-btree-key-shape.patch
- v3-0002-Use-specialized-attribute-iterators-in-backend-nb.patch
- v3-0004-Optimize-attribute-iterator-access-for-single-col.patch
- v3-0005-Add-a-function-whose-task-it-is-to-populate-all-a.patch
- v3-0008-Add-specialization-to-btree-index-creation.patch
- v3-0007-Implement-dynamic-prefix-compression-in-nbtree.patch
- v3-0006-Implement-specialized-uncacheable-attribute-itera.patch
- pgbench_log.master
- pgbench_log.patched
- bench.sql
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Sun, 5 Jun 2022 at 21:12, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > While working on benchmarking the v2 patchset, I noticed no > improvement on reindex, which I attributed to forgetting to also > specialize comparetup_index_btree in tuplesorth.c. After adding the > specialization there as well (attached in v3), reindex performance > improved significantly too. PFA version 4 of this patchset. Changes: - Silence the compiler warnings, - Extract itup_attiter code into its own header, so that we don't get compiler warnings and pass the cfbot builds, - Re-order patches to be in a more logical order, - Updates to the dynamic prefix compression so that we don't always do a _bt_compare on the pages' highkey. memcmp(parentpage_rightsep, highkey) == 0 is often true, and allows us to skip the indirect function calls in _bt_compare most of the time. Based on local measurements, this patchset improves performance for all key shapes, with 2% to 600+% increased throughput (2-86% faster operations), depending on key shape. As can be seen in the attached pgbench output, the performance results are based on beta1 (f00a4f02, dated 2022-06-04) and thus not 100% current, but considering that no significant changes have been made in the btree AM code since, I believe these measurements are still quite valid. I also didn't re-run the numbers for the main branch; but I compared against the results of master in the last mail. This is because I run the performance tests locally, and a 7-iteration pgbench run for master requires 9 hours of downtime with this dataset, during which I can't use the system so as to not interfere with the performance tests. As such, I considered rerunning the benchmark for master to be not worth the time/effort/cost with the little changes that were committed. Kind regards, Matthias van de Meent.
Attachment
- pgbench_log.patched_v4.txt
- v4-0001-Specialize-nbtree-functions-on-btree-key-shape.patch
- v4-0002-Use-specialized-attribute-iterators-in-backend-nb.patch
- v4-0003-Specialize-the-nbtree-rd_indam-entry.patch
- v4-0004-Optimize-attribute-iterator-access-for-single-col.patch
- v4-0005-Add-a-function-whose-task-it-is-to-populate-all-a.patch
- v4-0006-Implement-specialized-uncacheable-attribute-itera.patch
- v4-0007-Add-specialization-to-btree-index-creation.patch
- v4-0008-Implement-dynamic-prefix-compression-in-nbtree.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Mon, 4 Jul 2022 at 16:18, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Sun, 5 Jun 2022 at 21:12, Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > While working on benchmarking the v2 patchset, I noticed no > > improvement on reindex, which I attributed to forgetting to also > > specialize comparetup_index_btree in tuplesorth.c. After adding the > > specialization there as well (attached in v3), reindex performance > > improved significantly too. > > PFA version 4 of this patchset. Changes: Version 5 now, which is identical to v4 except for bitrot fixes to deal with f58d7073. Kind regards, Matthias van de Meent.
Attachment
- v5-0002-Use-specialized-attribute-iterators-in-backend-nb.patch
- v5-0004-Optimize-attribute-iterator-access-for-single-col.patch
- v5-0003-Specialize-the-nbtree-rd_indam-entry.patch
- v5-0001-Specialize-nbtree-functions-on-btree-key-shape.patch
- v5-0005-Add-a-function-whose-task-it-is-to-populate-all-a.patch
- v5-0008-Implement-dynamic-prefix-compression-in-nbtree.patch
- v5-0007-Add-specialization-to-btree-index-creation.patch
- v5-0006-Implement-specialized-uncacheable-attribute-itera.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Wed, 27 Jul 2022 at 09:35, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Mon, 4 Jul 2022 at 16:18, Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > > > On Sun, 5 Jun 2022 at 21:12, Matthias van de Meent > > <boekewurm+postgres@gmail.com> wrote: > > > While working on benchmarking the v2 patchset, I noticed no > > > improvement on reindex, which I attributed to forgetting to also > > > specialize comparetup_index_btree in tuplesorth.c. After adding the > > > specialization there as well (attached in v3), reindex performance > > > improved significantly too. > > > > PFA version 4 of this patchset. Changes: > > Version 5 now, which is identical to v4 except for bitrot fixes to > deal with f58d7073. ... and now v6 to deal with d0b193c0 and co. I probably should've waited a bit longer this morning and checked master before sending, but that's not how it went. Sorry for the noise. Kind regards, Matthias van de Meent
Attachment
- v6-0005-Add-a-function-whose-task-it-is-to-populate-all-a.patch
- v6-0004-Optimize-attribute-iterator-access-for-single-col.patch
- v6-0003-Specialize-the-nbtree-rd_indam-entry.patch
- v6-0001-Specialize-nbtree-functions-on-btree-key-shape.patch
- v6-0002-Use-specialized-attribute-iterators-in-backend-nb.patch
- v6-0007-Add-specialization-to-btree-index-creation.patch
- v6-0006-Implement-specialized-uncacheable-attribute-itera.patch
- v6-0008-Implement-dynamic-prefix-compression-in-nbtree.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Wed, 27 Jul 2022 at 13:34, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Wed, 27 Jul 2022 at 09:35, Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > > > On Mon, 4 Jul 2022 at 16:18, Matthias van de Meent > > <boekewurm+postgres@gmail.com> wrote: > > > > > > On Sun, 5 Jun 2022 at 21:12, Matthias van de Meent > > > <boekewurm+postgres@gmail.com> wrote: > > > > While working on benchmarking the v2 patchset, I noticed no > > > > improvement on reindex, which I attributed to forgetting to also > > > > specialize comparetup_index_btree in tuplesorth.c. After adding the > > > > specialization there as well (attached in v3), reindex performance > > > > improved significantly too. > > > > > > PFA version 4 of this patchset. Changes: > > > > Version 5 now, which is identical to v4 except for bitrot fixes to > > deal with f58d7073. > > ... and now v6 to deal with d0b193c0 and co. > > I probably should've waited a bit longer this morning and checked > master before sending, but that's not how it went. Sorry for the > noise. Here's the dynamic prefix truncation patch on it's own (this was 0008). I'll test the performance of this tomorrow, but at least it compiles and passes check-world against HEAD @ 6e10631d. If performance doesn't disappoint (isn't measurably worse in known workloads), this will be the only patch in the patchset - specialization would then be dropped. Else, tomorrow I'll post the remainder of the patchset that specializes the nbtree functions on key shape. Kind regards, Matthias van de Meent.
Attachment
Re: Improving btree performance through specializing by key shape, take 2
From
David Christensen
Date:
Hi Matthias, I'm going to look at this patch series if you're still interested. What was the status of your final performance testingfor the 0008 patch alone vs the specialization series? Last I saw on the thread you were going to see if the specializationwas required or not. Best, David
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Thu, 12 Jan 2023 at 16:11, David Christensen <david@pgguru.net> wrote: > > Hi Matthias, > > I'm going to look at this patch series if you're still interested. What was the status of your final performance testingfor the 0008 patch alone vs the specialization series? Last I saw on the thread you were going to see if the specializationwas required or not. Thank you for your interest, and sorry for the delayed response. I've been working on rebasing and polishing the patches, and hit some issues benchmarking the set. Attached in Perf_results.xlsx are the results of my benchmarks, and a new rebased patchset. TLDR for benchmarks: There may be a small regression 0.5-1% in the patchset for reindex and insert-based workloads in certain corner cases, but I can't rule out that it's just a quirk of my testing setup. Master was taken at eb5ad4ff, and all patches are based on that as well. 0001 (former 0008) sees 2% performance loss on average on non-optimized index insertions - this performance loss is fixed with the rest of the patchset. The patchset was reordered again: 0001 contains the dynamic prefix truncation changes; 0002 and 0003 refactor and update btree code to specialize on key shape, and 0004 and 0006 define the specializations. 0005 is a separated addition to attcacheoff infrastructure that is useful on it's own; it flags an attribute with 'this attribute cannot have a cached offset, look at this other attribute instead'. A significant change from previous versions is that the specialized function identifiers are published as macros, so `_bt_compare` is published as a macro that (based on context) calls the specialized version. This reduced a lot of cognitive overhead and churn in the code. Kind regards, Matthias van de Meent
Attachment
- Perf_results.xlsx
- v8-0001-Implement-dynamic-prefix-compression-in-nbtree.patch
- v8-0005-Add-an-attcacheoff-populating-function.patch
- v8-0004-Optimize-nbts_attiter-for-nkeyatts-1-btrees.patch
- v8-0003-Use-specialized-attribute-iterators-in-the-specia.patch
- v8-0002-Specialize-nbtree-functions-on-btree-key-shape.patch
- v8-0006-btree-specialization-for-variable-length-multi-at.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Fri, 20 Jan 2023 at 20:37, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > On Thu, 12 Jan 2023 at 16:11, David Christensen <david@pgguru.net> wrote: > > > > Hi Matthias, > > > > I'm going to look at this patch series if you're still interested. What was the status of your final performance testingfor the 0008 patch alone vs the specialization series? Last I saw on the thread you were going to see if the specializationwas required or not. > > Thank you for your interest, and sorry for the delayed response. I've > been working on rebasing and polishing the patches, and hit some > issues benchmarking the set. Attached in Perf_results.xlsx are the > results of my benchmarks, and a new rebased patchset. Attached v9 which rebases the patchset on b90f0b57 to deal with compilation errors after d952373a. It also cleans up 0001 which previously added an unrelated file, but is otherwise unchanged. Kind regards, Matthias van de Meent
Attachment
- v9-0005-Add-an-attcacheoff-populating-function.patch
- v9-0004-Optimize-nbts_attiter-for-nkeyatts-1-btrees.patch
- v9-0003-Use-specialized-attribute-iterators-in-the-specia.patch
- v9-0001-Implement-dynamic-prefix-compression-in-nbtree.patch
- v9-0002-Specialize-nbtree-functions-on-btree-key-shape.patch
- v9-0006-btree-specialization-for-variable-length-multi-at.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Mon, 23 Jan 2023 at 14:54, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > On Fri, 20 Jan 2023 at 20:37, Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > On Thu, 12 Jan 2023 at 16:11, David Christensen <david@pgguru.net> wrote: > > > Last I saw on the thread you were going to see if the specialization was required or not. > > > > Thank you for your interest, and sorry for the delayed response. I've > > been working on rebasing and polishing the patches, and hit some > > issues benchmarking the set. Attached in Perf_results.xlsx are the > > results of my benchmarks, and a new rebased patchset. Attached v10 which fixes one compile warning, and fixes headerscheck/cpluspluscheck by adding nbtree_spec.h and nbtree_specfuncs.h to ignored headers files. It also fixes some cases of later modifications of earlier patches' code where the change should be incorporated in the earlier patch instead. I think this is ready for review, I don't . The top-level design of the patchset: 0001 modifies btree descent code to use dynamic prefix compression, i.e. skip comparing columns in binary search when the same column on tuples on both the left and the right of this tuple have been compared as 'equal'. It also includes an optimized path when the downlink's tuple's right neighbor's data is bytewise equal to the highkey of the page we descended onto - in those cases we don't need to run _bt_compare on the index tuple as we know that the result will be the same as that of the downlink tuple, i.e. it compare as "less than". NOTE that this patch when applied as stand-alone adds overhead for all indexes, with the benefits of the patch limited to non-unique indexes or indexes where the uniqueness is guaranteed only at later attributes. Later patches in the patchset return performance to a similar level as before 0001 for the impacted indexes. 0002 creates a scaffold for specializing nbtree functions, and moves the functions I selected for specialization into separate files. Those separate files (postfixed with _spec) are included in the original files through inclusion of the nbtree specialization header file with a macro variable. The code itself has not materially changed yet at this point. 0003 updates the functions selected in 0002 to utilize the specializable attribute iterator macros instead of manual attribute iteration. Then, 0004 adds specialization for single-attribute indexes, 0005 adds a helper function for populating attcacheoff (which is separately useful too, but essential in this patchset), and 0006 adds specialization for multi-column indexes of which the offsets of the last key column cannot be known. Kind regards, Matthias van de Meent.
Attachment
- v10-0004-Optimize-nbts_attiter-for-nkeyatts-1-btrees.patch
- v10-0005-Add-an-attcacheoff-populating-function.patch
- v10-0003-Use-specialized-attribute-iterators-in-the-speci.patch
- v10-0001-Implement-dynamic-prefix-compression-in-nbtree.patch
- v10-0002-Specialize-nbtree-functions-on-btree-key-shape.patch
- v10-0006-btree-specialization-for-variable-length-multi-a.patch
Re: Improving btree performance through specializing by key shape, take 2
From
"Gregory Stark (as CFM)"
Date:
Hm. The cfbot has a fairly trivial issue with this with a unused variable: 18:36:17.405] In file included from ../../src/include/access/nbtree.h:1184, [18:36:17.405] from verify_nbtree.c:27: [18:36:17.405] verify_nbtree.c: In function ‘palloc_btree_page’: [18:36:17.405] ../../src/include/access/nbtree_spec.h:51:23: error: unused variable ‘__nbts_ctx’ [-Werror=unused-variable] [18:36:17.405] 51 | #define NBTS_CTX_NAME __nbts_ctx [18:36:17.405] | ^~~~~~~~~~ [18:36:17.405] ../../src/include/access/nbtree_spec.h:54:43: note: in expansion of macro ‘NBTS_CTX_NAME’ [18:36:17.405] 54 | #define NBTS_MAKE_CTX(rel) const NBTS_CTX NBTS_CTX_NAME = _nbt_spec_context(rel) [18:36:17.405] | ^~~~~~~~~~~~~ [18:36:17.405] ../../src/include/access/nbtree_spec.h:264:28: note: in expansion of macro ‘NBTS_MAKE_CTX’ [18:36:17.405] 264 | #define nbts_prep_ctx(rel) NBTS_MAKE_CTX(rel) [18:36:17.405] | ^~~~~~~~~~~~~ [18:36:17.405] verify_nbtree.c:2974:2: note: in expansion of macro ‘nbts_prep_ctx’ [18:36:17.405] 2974 | nbts_prep_ctx(NULL); [18:36:17.405] | ^~~~~~~~~~~~~
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Tue, 4 Apr 2023 at 17:43, Gregory Stark (as CFM) <stark.cfm@gmail.com> wrote: > > Hm. The cfbot has a fairly trivial issue with this with a unused variable: Attached a rebase on top of HEAD @ 8cca660b to make the patch apply again. I think this is ready for review once again. As the patchset has seen no significant changes since v8 of the patchset this january [0], I've added a description of the changes below. Kind regards, Matthias van de Meent Neon, Inc. = Description of the patchset so far: This patchset implements two features that *taken togetther* improve the performance of our btree implementation: == Dynamic prefix truncation (0001) The code now tracks how many prefix attributes of the scan key are already considered equal based on earlier binsrch results, and ignores those prefix colums in further binsrch operations (sorted list; if both the high and low value of your range have the same prefix, the middle value will have that prefix, too). This reduces the number of calls into opclass-supplied (dynamic) compare functions, and thus increase performance for multi-key-attribute indexes where shared prefixes are common (e.g. index on (customer, order_id)). == Index key shape code specialization (0002-0006) Index tuple attribute accesses for multi-column indexes are often done through index_getattr, which gets very expensive for indexes which cannot use attcacheoff. However, single-key and attcacheoff-able indexes do benefit greatly from the attcacheoff optimization, so we can't just stop applying the optimization. This is why the second part of the patchset (0002 and up) adds infrastructure to generate specialized code paths that access key attributes in the most efficient way it knows of: Single key attributes do not go through loops/condtionals for which attribute it is (except certain exceptions, 0004), attcacheoff-able indexes get the same treatment as they do now, and indexes where attcacheoff cannot be used for all key attributes will get a special attribute iterator that incrementally calculates the offset of each attribute in the current index tuple (0005+0006). Although patch 0002 is large, most of the modified lines are functions being moved into different files. Once 0002 is understood, the following patches should be fairly easy to understand as well. = Why both features in one patchset? The overhead of keeping track of the prefix in 0001 can add up to several % of performance lost for the common index shape where dynamic prefix truncation cannot be applied (measured 5-9%); single-column unique indexes are the most sensitive to this. By adding the single-key-column code specialization in 0004, we reduce other types of overhead for the indexes most affected, which thus compensates for the additional overhead in 0001, resulting in a net-neutral result. = Benchmarks I haven't re-run the benchmarks for this since v8 at [0] as I haven't modified the patch significantly after that patch - only compiler complaint fixes and changes required for rebasing. The results from that benchmark: improvements vary between 'not significantly different from HEAD' to '250+% improved throughput for select INSERT workloads, and 360+% improved for select REINDEX workloads'. Graphs from that benchmark are also attached now; as LibreOffice Calc wasn't good at exporting the sheet with working graphs. [0] https://www.postgresql.org/message-id/CAEze2WixWviBYTWXiFLbD3AuLT4oqGk_MykS_ssB=TudeZ=ajQ@mail.gmail.com
Attachment
- v11-0003-Use-specialized-attribute-iterators-in-the-speci.patch
- v11-0004-Optimize-nbts_attiter-for-nkeyatts-1-btrees.patch
- v11-0005-Add-an-attcacheoff-populating-function.patch
- v11-0001-Implement-dynamic-prefix-compression-in-nbtree.patch
- v11-0002-Specialize-nbtree-functions-on-btree-key-shape.patch
- v11-0006-btree-specialization-for-variable-length-multi-a.patch
- REINDEX_qps_increase.png
- INSERT_time_spent.png
- REINDEX_time_spent.png
- INSERT_qps_increase.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
On Fri, Jun 23, 2023 at 2:21 AM Matthias van de Meent
<boekewurm+postgres@gmail.com> wrote:
>
> == Dynamic prefix truncation (0001)
> The code now tracks how many prefix attributes of the scan key are
> already considered equal based on earlier binsrch results, and ignores
> those prefix colums in further binsrch operations (sorted list; if
> both the high and low value of your range have the same prefix, the
> middle value will have that prefix, too). This reduces the number of
> calls into opclass-supplied (dynamic) compare functions, and thus
> increase performance for multi-key-attribute indexes where shared
> prefixes are common (e.g. index on (customer, order_id)).
I think the idea looks good to me.
I was looking into the 0001 patches, and I have one confusion in the
below hunk in the _bt_moveright function, basically, if the parent
page's right key is exactly matching the HIGH key of the child key
then I suppose while doing the "_bt_compare" with the HIGH_KEY we can
use the optimization right, i.e. column number from where we need to
start the comparison should be used what is passed by the caller. But
in the below hunk, you are always passing that as 'cmpcol' which is 1.
I think this should be '*comparecol' because '*comparecol' will either
hold the value passed by the parent if high key data exactly match
with the parent's right tuple or it will hold 1 in case it doesn't
match. Am I missing something?
@@ -247,13 +256,16 @@ _bt_moveright(Relation rel,
{
....
+ if (P_IGNORE(opaque) ||
+ _bt_compare(rel, key, page, P_HIKEY, &cmpcol) >= cmpval)
+ {
+ *comparecol = 1;
}
--
Regards,
Dilip Kumar
EnterpriseDB: http://www.enterprisedb.com
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Fri, 23 Jun 2023 at 11:26, Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Fri, Jun 23, 2023 at 2:21 AM Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > > > > == Dynamic prefix truncation (0001) > > The code now tracks how many prefix attributes of the scan key are > > already considered equal based on earlier binsrch results, and ignores > > those prefix colums in further binsrch operations (sorted list; if > > both the high and low value of your range have the same prefix, the > > middle value will have that prefix, too). This reduces the number of > > calls into opclass-supplied (dynamic) compare functions, and thus > > increase performance for multi-key-attribute indexes where shared > > prefixes are common (e.g. index on (customer, order_id)). > > I think the idea looks good to me. > > I was looking into the 0001 patches, Thanks for reviewing. > and I have one confusion in the > below hunk in the _bt_moveright function, basically, if the parent > page's right key is exactly matching the HIGH key of the child key > then I suppose while doing the "_bt_compare" with the HIGH_KEY we can > use the optimization right, i.e. column number from where we need to > start the comparison should be used what is passed by the caller. But > in the below hunk, you are always passing that as 'cmpcol' which is 1. > I think this should be '*comparecol' because '*comparecol' will either > hold the value passed by the parent if high key data exactly match > with the parent's right tuple or it will hold 1 in case it doesn't > match. Am I missing something? We can't carry _bt_compare prefix results across pages, because the key range of a page may shift while we're not holding a lock on that page. That's also why the code resets the prefix to 1 every time it accesses a new page ^1: it cannot guarantee correct results otherwise. See also [0] and [1] for why that is important. ^1: When following downlinks, the code above your quoted code tries to reuse the _bt_compare result of the parent page in the common case of a child page's high key that is bytewise equal to the right separator tuple of the parent page's downlink to this page. However, if it detects that this child high key has changed (i.e. not 100% bytewise equal), we can't reuse that result, and we'll have to re-establish all prefix info on that page from scratch. In any case, this only establishes the prefix for the right half of the page's keyspace, the prefix of the left half of the data still needs to be established separetely. I hope this explains the reasons for why we can't reuse comparecol as _bt_compare argument. Kind regards, Matthias van de Meent Neon, Inc. [0] https://www.postgresql.org/message-id/CAH2-Wzn_NAyK4pR0HRWO0StwHmxjP5qyu+X8vppt030XpqrO6w@mail.gmail.com
On Fri, Jun 23, 2023 at 8:16 PM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Fri, 23 Jun 2023 at 11:26, Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > and I have one confusion in the > > below hunk in the _bt_moveright function, basically, if the parent > > page's right key is exactly matching the HIGH key of the child key > > then I suppose while doing the "_bt_compare" with the HIGH_KEY we can > > use the optimization right, i.e. column number from where we need to > > start the comparison should be used what is passed by the caller. But > > in the below hunk, you are always passing that as 'cmpcol' which is 1. > > I think this should be '*comparecol' because '*comparecol' will either > > hold the value passed by the parent if high key data exactly match > > with the parent's right tuple or it will hold 1 in case it doesn't > > match. Am I missing something? > > We can't carry _bt_compare prefix results across pages, because the > key range of a page may shift while we're not holding a lock on that > page. That's also why the code resets the prefix to 1 every time it > accesses a new page ^1: it cannot guarantee correct results otherwise. > See also [0] and [1] for why that is important. Yeah that makes sense > ^1: When following downlinks, the code above your quoted code tries to > reuse the _bt_compare result of the parent page in the common case of > a child page's high key that is bytewise equal to the right separator > tuple of the parent page's downlink to this page. However, if it > detects that this child high key has changed (i.e. not 100% bytewise > equal), we can't reuse that result, and we'll have to re-establish all > prefix info on that page from scratch. > In any case, this only establishes the prefix for the right half of > the page's keyspace, the prefix of the left half of the data still > needs to be established separetely. > > I hope this explains the reasons for why we can't reuse comparecol as > _bt_compare argument. Yeah got it, thanks for explaining this. Now I see you have explained this in comments as well above the memcmp() statement. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
On Tue, Jun 27, 2023 at 9:42 AM Dilip Kumar <dilipbalaut@gmail.com> wrote: > > On Fri, Jun 23, 2023 at 8:16 PM Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > > > On Fri, 23 Jun 2023 at 11:26, Dilip Kumar <dilipbalaut@gmail.com> wrote: > > > > > > and I have one confusion in the > > > below hunk in the _bt_moveright function, basically, if the parent > > > page's right key is exactly matching the HIGH key of the child key > > > then I suppose while doing the "_bt_compare" with the HIGH_KEY we can > > > use the optimization right, i.e. column number from where we need to > > > start the comparison should be used what is passed by the caller. But > > > in the below hunk, you are always passing that as 'cmpcol' which is 1. > > > I think this should be '*comparecol' because '*comparecol' will either > > > hold the value passed by the parent if high key data exactly match > > > with the parent's right tuple or it will hold 1 in case it doesn't > > > match. Am I missing something? > > > > We can't carry _bt_compare prefix results across pages, because the > > key range of a page may shift while we're not holding a lock on that > > page. That's also why the code resets the prefix to 1 every time it > > accesses a new page ^1: it cannot guarantee correct results otherwise. > > See also [0] and [1] for why that is important. > > Yeah that makes sense > > > ^1: When following downlinks, the code above your quoted code tries to > > reuse the _bt_compare result of the parent page in the common case of > > a child page's high key that is bytewise equal to the right separator > > tuple of the parent page's downlink to this page. However, if it > > detects that this child high key has changed (i.e. not 100% bytewise > > equal), we can't reuse that result, and we'll have to re-establish all > > prefix info on that page from scratch. > > In any case, this only establishes the prefix for the right half of > > the page's keyspace, the prefix of the left half of the data still > > needs to be established separetely. > > > > I hope this explains the reasons for why we can't reuse comparecol as > > _bt_compare argument. > > Yeah got it, thanks for explaining this. Now I see you have explained > this in comments as well above the memcmp() statement. At high level 0001 looks fine to me, just some suggestions 1. +Notes about dynamic prefix truncation +------------------------------------- I feel instead of calling it "dynamic prefix truncation" should we can call it "dynamic prefix skipping", I mean we are not really truncating anything right, we are just skipping those attributes in comparison? 2. I think we should add some comments in the _bt_binsrch() function where we are having main logic around maintaining highcmpcol and lowcmpcol. I think the notes section explains that very clearly but adding some comments here would be good and then reference to that section in the README. -- Regards, Dilip Kumar EnterpriseDB: http://www.enterprisedb.com
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Tue, 27 Jun 2023 at 06:57, Dilip Kumar <dilipbalaut@gmail.com> wrote: > > At high level 0001 looks fine to me, just some suggestions Thanks for the review. > 1. > +Notes about dynamic prefix truncation > +------------------------------------- > > I feel instead of calling it "dynamic prefix truncation" should we can > call it "dynamic prefix skipping", I mean we are not > really truncating anything right, we are just skipping those > attributes in comparison? The reason I am using "prefix truncation" is that that is a fairly well-known term in literature (together with "prefix compression"), and it was introduced on this list with that name by Peter in 2018 [0]. I've seen no good reason to change terminology; especially considering that normal "static" prefix truncation/compression is also somewhere on my to-do list. > 2. > I think we should add some comments in the _bt_binsrch() function > where we are having main logic around maintaining highcmpcol and > lowcmpcol. > I think the notes section explains that very clearly but adding some > comments here would be good and then reference to that section in the > README. Updated in the attached version 12 of the patchset (which is also rebased on HEAD @ 9c13b681). No changes apart from rebase fixes and these added comments. Kind regards, Matthias van de Meent Neon (https://neon.tech) [0] https://www.postgresql.org/message-id/CAH2-Wzn_NAyK4pR0HRWO0StwHmxjP5qyu+X8vppt030XpqrO6w@mail.gmail.com
Attachment
- v12-0003-Use-specialized-attribute-iterators-in-the-speci.patch
- v12-0005-Add-an-attcacheoff-populating-function.patch
- v12-0004-Optimize-nbts_attiter-for-nkeyatts-1-btrees.patch
- v12-0002-Specialize-nbtree-functions-on-btree-key-shape.patch
- v12-0001-Implement-dynamic-prefix-compression-in-nbtree.patch
- v12-0006-btree-specialization-for-variable-length-multi-a.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Wed, 30 Aug 2023 at 21:50, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > Updated in the attached version 12 of the patchset (which is also > rebased on HEAD @ 9c13b681). No changes apart from rebase fixes and > these added comments. Rebased again to v13 to account for API changes in 9f060253 "Remove some more "snapshot too old" vestiges." Kind regards, Matthias van de Meent
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Mon, 18 Sept 2023 at 17:56, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Wed, 30 Aug 2023 at 21:50, Matthias van de Meent > <boekewurm+postgres@gmail.com> wrote: > > > > Updated in the attached version 12 of the patchset (which is also > > rebased on HEAD @ 9c13b681). No changes apart from rebase fixes and > > these added comments. > > Rebased again to v13 to account for API changes in 9f060253 "Remove > some more "snapshot too old" vestiges." ... and now attached. Kind regards, Matthias van de Meent
Attachment
- v13-0005-Add-an-attcacheoff-populating-function.patch
- v13-0001-Implement-dynamic-prefix-compression-in-nbtree.patch
- v13-0004-Optimize-nbts_attiter-for-nkeyatts-1-btrees.patch
- v13-0003-Use-specialized-attribute-iterators-in-the-speci.patch
- v13-0002-Specialize-nbtree-functions-on-btree-key-shape.patch
- v13-0006-btree-specialization-for-variable-length-multi-a.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Peter Geoghegan
Date:
On Mon, Sep 18, 2023 at 8:57 AM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > Rebased again to v13 to account for API changes in 9f060253 "Remove > > some more "snapshot too old" vestiges." > > ... and now attached. I see that this revised version is approximately as invasive as earlier versions were - it has specializations for almost everything. Do you really need to specialize basically all of nbtdedup.c, for example? In order for this patch series to have any hope of getting committed, there needs to be significant work on limiting the amount of code churn, and resulting object code size. There are various problems that come from whole-sale specializing all of this code. There are distributed costs -- costs that won't necessarily be in evidence from microbenchmarks. It might be worth familiarizing yourself with bloaty, a tool for profiling the size of binaries: https://github.com/google/bloaty Is it actually sensible to tie dynamic prefix compression to everything else here? Apparently there is a regression for certain cases caused by that patch (the first one), which necessitates making up the difference in later patches. But...isn't it also conceivable that some completely different optimization could do that for us instead? Why is there a regression from v13-0001-*? Can we just fix the regression directly? And if not, why not? I also have significant doubts about your scheme for avoiding invalidating the bounds of the page based on its high key matching the parent's separator. The subtle dynamic prefix compression race condition that I was worried about was one caused by page deletion. But page deletion doesn't change the high key at all (it does that for the deleted page, but that's hardly relevant). So how could checking the high key possibly help? Page deletion will make the pivot tuple in the parent page whose downlink originally pointed to the concurrently deleted page change, so that it points to the deleted page's original right sibling page (the sibling being the page that you need to worry about). This means that the lower bound for the not-deleted right sibling page has changed from under us. And that we lack any simple way of detecting that it might have happened. The race that I'm worried about is extremely narrow, because it involves a page deletion and a concurrent insert into the key space that was originally covered by the deleted page. It's extremely unlikely to happen in the real world, but it's still a bug. It's possible that it'd make sense to do a memcmp() of the high key using a copy of a separator from the parent page. That at least seems like it could be made safe. But I don't see what it has to do with dynamic prefix compression. In any case there is a simpler way to avoid the high key check for internal pages: do the _bt_binsrch first, and only consider _bt_moveright when the answer that _bt_binsrch gave suggests that we might actually need to call _bt_moveright. -- Peter Geoghegan
Re: Improving btree performance through specializing by key shape, take 2
From
Peter Geoghegan
Date:
On Mon, Sep 18, 2023 at 6:29 PM Peter Geoghegan <pg@bowt.ie> wrote: > I also have significant doubts about your scheme for avoiding > invalidating the bounds of the page based on its high key matching the > parent's separator. The subtle dynamic prefix compression race > condition that I was worried about was one caused by page deletion. > But page deletion doesn't change the high key at all (it does that for > the deleted page, but that's hardly relevant). So how could checking > the high key possibly help? To be clear, page deletion does what I described here (it does an in-place update of the downlink to the deleted page, so the same pivot tuple now points to its right sibling, which is our page of concern), in addition to fully removing the original pivot tuple whose downlink originally pointed to our page of concern. This is why page deletion makes the key space "move to the right", very much like a page split would. IMV it would be better if it made the key space "move to the left" instead, which would make page deletion close to the exact opposite of a page split -- that's what the Lanin & Shasha paper does (sort of). If you have this symmetry, then things like dynamic prefix compression are a lot simpler. ISTM that the only way that a scheme like yours could work, assuming that making page deletion closer to Lanin & Shasha is not going to happen, is something even more invasive than that: it might work if you had a page low key (not just a high key) on every page. You'd have to compare the lower bound separator key from the parent (which might itself be the page-level low key for the parent) to the page low key. That's not a serious suggestion; I'm just pointing out that you need to be able to compare like with like for a canary condition like this one, and AFAICT there is no lightweight practical way of doing that that is 100% robust. -- Peter Geoghegan
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Tue, 19 Sept 2023 at 03:56, Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Mon, Sep 18, 2023 at 6:29 PM Peter Geoghegan <pg@bowt.ie> wrote:
> > I also have significant doubts about your scheme for avoiding
> > invalidating the bounds of the page based on its high key matching the
> > parent's separator. The subtle dynamic prefix compression race
> > condition that I was worried about was one caused by page deletion.
> > But page deletion doesn't change the high key at all (it does that for
> > the deleted page, but that's hardly relevant). So how could checking
> > the high key possibly help?
>
> To be clear, page deletion does what I described here (it does an
> in-place update of the downlink to the deleted page, so the same pivot
> tuple now points to its right sibling, which is our page of concern),
> in addition to fully removing the original pivot tuple whose downlink
> originally pointed to our page of concern. This is why page deletion
> makes the key space "move to the right", very much like a page split
> would.
I am still aware of this issue, and I think we've discussed it in
detail earlier. I think it does not really impact this patchset. Sure,
I can't use dynamic prefix compression to its full potential, but I
still do get serious performance benefits:
FULL KEY _bt_compare calls:
'Optimal' full-tree DPT: average O(3)
Paged DPT (this patch): average O(2 * height)
... without HK opt: average O(3 * height)
Current: O(log2(n))
Single-attribute compares:
'Optimal' full-tree DPT: O(log(N))
Paged DPT (this patch): O(log(N))
Current: 0 (or, O(log(N) * natts))
So, in effect, this patch moves most compare operations to the level
of only one or two full key compare operations per page (on average).
I use "on average": on a sorted array with values ranging from
potentially minus infinity to positive infinity, it takes on average 3
compares before a binary search can determine the bounds of the
keyspace it has still to search. If one side's bounds is already
known, it takes on average 2 compare operations before these bounds
are known.
> IMV it would be better if it made the key space "move to the left"
> instead, which would make page deletion close to the exact opposite of
> a page split -- that's what the Lanin & Shasha paper does (sort of).
> If you have this symmetry, then things like dynamic prefix compression
> are a lot simpler.
>
> ISTM that the only way that a scheme like yours could work, assuming
> that making page deletion closer to Lanin & Shasha is not going to
> happen, is something even more invasive than that: it might work if
> you had a page low key (not just a high key) on every page.
Note that the "dynamic prefix compression" is currently only active on
the page level.
True, the patch does carry over _bt_compare's prefix result for the
high key on the child page, but we do that only if the highkey is
actually an exact copy of the right separator on the parent page. This
carry-over opportunity is extremely likely to happen, because the high
key generated in _bt_split is then later inserted on the parent page.
The only case where it could differ is in concurrent page deletions.
That is thus a case of betting a few cycles to commonly save many
cycles (memcmp vs _bt_compare full key compare.
Again, we do not actually skip a prefix on the compare call of the
P_HIGHKEY tuple, nor for the compares of the midpoints unless we've
found a tuple on the page that compares as smaller than the search
key.
> You'd have
> to compare the lower bound separator key from the parent (which might
> itself be the page-level low key for the parent) to the page low key.
> That's not a serious suggestion; I'm just pointing out that you need
> to be able to compare like with like for a canary condition like this
> one, and AFAICT there is no lightweight practical way of doing that
> that is 100% robust.
True, if we had consistent LOWKEYs on pages, that'd make this job much
easier: the prefix could indeed be carried over in full. But that's
not currently the case for the nbtree code, and this is the next best
thing, as it also has the benefit of working with all currently
supported physical formats of btree indexes.
Kind regards,
Matthias van de Meent
Re: Improving btree performance through specializing by key shape, take 2
From
Peter Geoghegan
Date:
On Tue, Sep 19, 2023 at 6:28 AM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > To be clear, page deletion does what I described here (it does an > > in-place update of the downlink to the deleted page, so the same pivot > > tuple now points to its right sibling, which is our page of concern), > > in addition to fully removing the original pivot tuple whose downlink > > originally pointed to our page of concern. This is why page deletion > > makes the key space "move to the right", very much like a page split > > would. > > I am still aware of this issue, and I think we've discussed it in > detail earlier. I think it does not really impact this patchset. Sure, > I can't use dynamic prefix compression to its full potential, but I > still do get serious performance benefits: Then why have you linked whatever the first patch does with the high key to dynamic prefix compression in the first place? Your commit message makes it sound like it's a way to get around the race condition that affects dynamic prefix compression, but as far as I can tell it has nothing whatsoever to do with that race condition. Questions: 1. Why shouldn't the high key thing be treated as an unrelated piece of work? I guess it's possible that it really should be structured that way, but even then it's your responsibility to make it clear why that is. As things stand, this presentation is very confusing. 2. Separately, why should dynamic prefix compression be tied to the specialization work? I also see no principled reason why it should be tied to the other two things. I didn't mind this sort of structure so much back when this work was very clearly exploratory -- I've certainly structured work in this area that way myself, in the past. But if you want this patch set to ever go beyond being an exploratory patch set, something has to change. I don't have time to do a comprehensive (or even a fairly cursory) analysis of which parts of the patch are helping, and which are marginal or even add no value. > > You'd have > > to compare the lower bound separator key from the parent (which might > > itself be the page-level low key for the parent) to the page low key. > > That's not a serious suggestion; I'm just pointing out that you need > > to be able to compare like with like for a canary condition like this > > one, and AFAICT there is no lightweight practical way of doing that > > that is 100% robust. > > True, if we had consistent LOWKEYs on pages, that'd make this job much > easier: the prefix could indeed be carried over in full. But that's > not currently the case for the nbtree code, and this is the next best > thing, as it also has the benefit of working with all currently > supported physical formats of btree indexes. I went over the low key thing again because I had to struggle to understand what your high key optimization had to do with dynamic prefix compression. I'm still struggling. I think that your commit message very much led me astray. Quoting it here: """ Although this limits the overall applicability of the performance improvement, it still allows for a nice performance improvement in most cases where initial columns have many duplicate values and a compare function that is not cheap. As an exception to the above rule, most of the time a pages' highkey is equal to the right seperator on the parent page due to how btree splits are done. By storing this right seperator from the parent page and then validating that the highkey of the child page contains the exact same data, we can restore the right prefix bound without having to call the relatively expensive _bt_compare. """ You're directly tying the high key optimization to the dynamic prefix compression optimization. But why? I have long understood that you gave up on the idea of keeping the bounds across levels of the tree (which does make sense to me), but yesterday the issue became totally muddled by this high key business. That's why I rehashed the earlier discussion, which I had previously understood to be settled. -- Peter Geoghegan
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Tue, 19 Sept 2023 at 22:49, Peter Geoghegan <pg@bowt.ie> wrote:
>
> On Tue, Sep 19, 2023 at 6:28 AM Matthias van de Meent
> <boekewurm+postgres@gmail.com> wrote:
> > > To be clear, page deletion does what I described here (it does an
> > > in-place update of the downlink to the deleted page, so the same pivot
> > > tuple now points to its right sibling, which is our page of concern),
> > > in addition to fully removing the original pivot tuple whose downlink
> > > originally pointed to our page of concern. This is why page deletion
> > > makes the key space "move to the right", very much like a page split
> > > would.
> >
> > I am still aware of this issue, and I think we've discussed it in
> > detail earlier. I think it does not really impact this patchset. Sure,
> > I can't use dynamic prefix compression to its full potential, but I
> > still do get serious performance benefits:
>
> Then why have you linked whatever the first patch does with the high
> key to dynamic prefix compression in the first place? Your commit
> message makes it sound like it's a way to get around the race
> condition that affects dynamic prefix compression, but as far as I can
> tell it has nothing whatsoever to do with that race condition.
We wouldn't have to store the downlink's right separator and compare
it to the highkey if we didn't deviate from L&Y's algorithm for DELETE
operations (which causes the race condition): just the right sibling's
block number would be enough.
(Yes, the right sibling's block number isn't available for the
rightmost downlink of a page. In those cases, we'd have to reuse the
parent page's high key with that of the downlink page, but I suppose
that'll be relatively rare).
> Questions:
>
> 1. Why shouldn't the high key thing be treated as an unrelated piece of work?
Because it was only significant and relatively visible after getting
rid of the other full key compare operations, and it touches
essentially the same areas. Splitting them out in more patches would
be a hassle.
> I guess it's possible that it really should be structured that way,
> but even then it's your responsibility to make it clear why that is.
Sure. But I think I've made that clear upthread too.
> As things stand, this presentation is very confusing.
I'll take a look at improving the presentation.
> 2. Separately, why should dynamic prefix compression be tied to the
> specialization work? I also see no principled reason why it should be
> tied to the other two things.
My performance results show that insert performance degrades by 2-3%
for single-column indexes if only dynamic the prefix truncation patch
is applied [0]. The specialization patches fix that regression on my
machine (5950x) due to having optimized code for the use case. I can't
say for certain that other machines will see the same results, but I
think results will at least be similar.
> I didn't mind this sort of structure so much back when this work was
> very clearly exploratory -- I've certainly structured work in this
> area that way myself, in the past. But if you want this patch set to
> ever go beyond being an exploratory patch set, something has to
> change.
I think it's fairly complete, and mostly waiting for review.
> I don't have time to do a comprehensive (or even a fairly
> cursory) analysis of which parts of the patch are helping, and which
> are marginal or even add no value.
It is a shame that you don't have the time to review this patch.
> > > You'd have
> > > to compare the lower bound separator key from the parent (which might
> > > itself be the page-level low key for the parent) to the page low key.
> > > That's not a serious suggestion; I'm just pointing out that you need
> > > to be able to compare like with like for a canary condition like this
> > > one, and AFAICT there is no lightweight practical way of doing that
> > > that is 100% robust.
> >
> > True, if we had consistent LOWKEYs on pages, that'd make this job much
> > easier: the prefix could indeed be carried over in full. But that's
> > not currently the case for the nbtree code, and this is the next best
> > thing, as it also has the benefit of working with all currently
> > supported physical formats of btree indexes.
>
> I went over the low key thing again because I had to struggle to
> understand what your high key optimization had to do with dynamic
> prefix compression. I'm still struggling. I think that your commit
> message very much led me astray. Quoting it here:
>
> """
> Although this limits [...] relatively expensive _bt_compare.
> """
>
> You're directly tying the high key optimization to the dynamic prefix
> compression optimization. But why?
The value of skipping the _bt_compare call on the highkey is
relatively much higher in the prefix-skip case than it is on master,
as on master it's only one of the log(n) _bt_compare calls on the
page, while in the patch it's one of (on average) 3 full key
_bt_compare calls. This makes it much easier to prove the performance
gain, which made me integrate it into that patch instead of keeping it
separate.
> I have long understood that you gave up on the idea of keeping the
> bounds across levels of the tree (which does make sense to me), but
> yesterday the issue became totally muddled by this high key business.
> That's why I rehashed the earlier discussion, which I had previously
> understood to be settled.
Understood. I'll see if I can improve the wording to something that is
more clear about what the optimization entails.
I'm planning to have these documentation changes to be included in the
next revision of the patchset, which will probably also reduce the
number of specialized functions (and with it the size of the binary).
It will take some extra time, because I would need to re-run the
performance suite, but the code changes should be very limited when
compared to the current patch (apart from moving code between .c and
_spec.c).
---
The meat of the changes are probably in 0001 (dynamic prefix skip),
0003 (change attribute iteration code to use specializable macros),
and 0006 (index attribute iteration for variable key offsets). 0002 is
mostly mechanical code movement, 0004 is a relatively easy
implementation of the iteration functionality for single-key-column
indexes, and 0005 adds an instrument for improving the efficiency of
attcacheoff by implementing negatively cached values ("cannot be
cached", instead of just "isn't cached") which are then used in 0006.
Kind regards,
Matthias van de Meent
Neon (https://neon.tech)
[0]
https://www.postgresql.org/message-id/CAEze2Wh_3%2B_Q%2BBefaLrpdXXR01vKr3R2R%3Dh5gFxR%2BU4%2B0Z%3D40w%40mail.gmail.com
Re: Improving btree performance through specializing by key shape, take 2
From
Peter Geoghegan
Date:
On Mon, Sep 25, 2023 at 9:13 AM Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > I think it's fairly complete, and mostly waiting for review. > > > I don't have time to do a comprehensive (or even a fairly > > cursory) analysis of which parts of the patch are helping, and which > > are marginal or even add no value. > > It is a shame that you don't have the time to review this patch. I didn't say that. Just that I don't have the time (or more like the inclination) to do most or all of the analysis that might allow us to arrive at a commitable patch. Most of the work with something like this is the analysis of the trade-offs, not writing code. There are all kinds of trade-offs that you could make with something like this, and the prospect of doing that myself is kind of daunting. Ideally you'd have made a significant start on that at this point. > > I have long understood that you gave up on the idea of keeping the > > bounds across levels of the tree (which does make sense to me), but > > yesterday the issue became totally muddled by this high key business. > > That's why I rehashed the earlier discussion, which I had previously > > understood to be settled. > > Understood. I'll see if I can improve the wording to something that is > more clear about what the optimization entails. Cool. -- Peter Geoghegan
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Thu, 26 Oct 2023 at 00:36, Peter Geoghegan <pg@bowt.ie> wrote: > Most of the work with something like > this is the analysis of the trade-offs, not writing code. There are > all kinds of trade-offs that you could make with something like this, > and the prospect of doing that myself is kind of daunting. Ideally > you'd have made a significant start on that at this point. I believe I'd already made most trade-offs clear earlier in the threads, along with rationales for the changes in behaviour. But here goes again: _bt_compare currently uses index_getattr() on each attribute of the key. index_getattr() is O(n) for the n-th attribute if the index tuple has any null or non-attcacheoff attributes in front of the current one. Thus, _bt_compare costs O(n^2) work with n=the number of attributes, which can cost several % of performance, but is very very bad in extreme cases, and doesO(n) calls to opclass-supplied compare operations. To solve most of the O(n) compare operations, we can optimize _bt_compare to only compare "interesting" attributes, i.e. we can apply "dynamic prefix truncation". This is implemented by patch 0001. This is further enhanced with 0002, where we skip the compare operations if the HIKEY is the same as the right separator of the downlink we followed (due to our page split code, this case is extremely likely). However, the above only changes the attribute indexing code in _bt_compare to O(n) for at most about 76% of the index tuples on the page (1 - (2 / log2(max_tuples_per_page))), while the other on average 20+% of the compare operations still have to deal with the O(n^2) total complexity of index_getattr. To fix this O(n^2) issue (the issue this thread was originally created for) the approach I implemented originally is to not use index_getattr but an "attribute iterator" that incrementally extracts the next attribute, while keeping track of the current offset into the tuple, so each next attribute would be O(1). That is implemented in the last patches of the patchset. This attribute iterator approach has an issue: It doesn't perform very well for indexes that make full use of attcacheoff. The bookkeeping for attribute iteration proved to be much more expensive than just reading attcacheoff from memory. This is why the latter patches (patchset 14 0003+) adapt the btree code to generate different paths for different "shapes" of key index attributes, to allow the current attcacheoff code to keep its performance, but to get higher performance for indexes where the attcacheoff optimization can not be applied. In passing, it also specializes the code for single-attribute indexes, so that they don't have to manage branching code, increasing their performance, too. TLDR: The specialization in 0003+ is applied because index_getattr is good when attcacheoff applies, but very bad when it doesn't. Attribute iteration is worse than index_getattr when attcacheoff applies, but is significantly better when attcacheoff does not work. By specializing we get the best of both worlds. The 0001 and 0002 optimizations were added later to further remove unneeded calls to the btree attribute compare functions, thus further reducing the total time spent in _bt_compare. Anyway. PFA v14 of the patchset. v13's 0001 is now split in two, containing prefix truncation in 0001, and 0002 containing the downlink's right separator/HIKEY optimization. Performance numbers (data attached): 0001 has significant gains in multi-column indexes with shared prefixes, where the prefix columns are expensive to compare, but otherwise doesn't have much impact. 0002 further improves performance across the board, but again mostly for indexes with expensive compare operations. 0007 sees performance improvements almost across the board, with only the 'ul' and 'tnt' indexes getting some worse results than master (but still better average results), All patches applied, per-index average performance improvements on 15 runs range from 3% to 290% across the board for INSERT benchmarks, and -2.83 to 370% for REINDEX. Configured with autoconf: config.log: > It was created by PostgreSQL configure 17devel, which was > generated by GNU Autoconf 2.69. Invocation command line was > > $ ./configure --enable-tap-tests --enable-depend --with-lz4 --with-zstd COPT=-ggdb -O3 --prefix=/home/matthias/projects/postgresql/pg_install--no-create --no-recursion Benchmark was done on 1m random rows of the pp-complete dataset, as found on UK Gov's S3 bucket [0]: using a parallel and threaded downloader is preferred because the throughput is measured in kBps per client. I'll do a few runs on the full dataset of 29M rows soon too, but master's performance is so bad for the 'worstcase' index that I can't finish its runs fast enough; benchmarking it takes hours per iteration. Kind regards, Matthias van de Meent Neon (https://neon.tech) [0] http://prod1.publicdata.landregistry.gov.uk.s3-website-eu-west-1.amazonaws.com/pp-complete.csv
Attachment
- image.png
- benchdata.zip
- v14-0005-btree-Optimize-nbts_attiter-for-indexes-with-a-s.patch
- v14-0002-btree-optimize-_bt_moveright-using-downlink-s-ri.patch
- v14-0001-btree-Implement-dynamic-prefix-compression.patch
- v14-0004-btree-Use-attribute-iterators-specialized-on-key.patch
- v14-0003-btree-Specialize-various-performance-sensitive-f.patch
- v14-0006-Add-an-attcacheoff-populating-function.patch
- v14-0007-btree-specialize-attribute-iteration-for-keys-th.patch
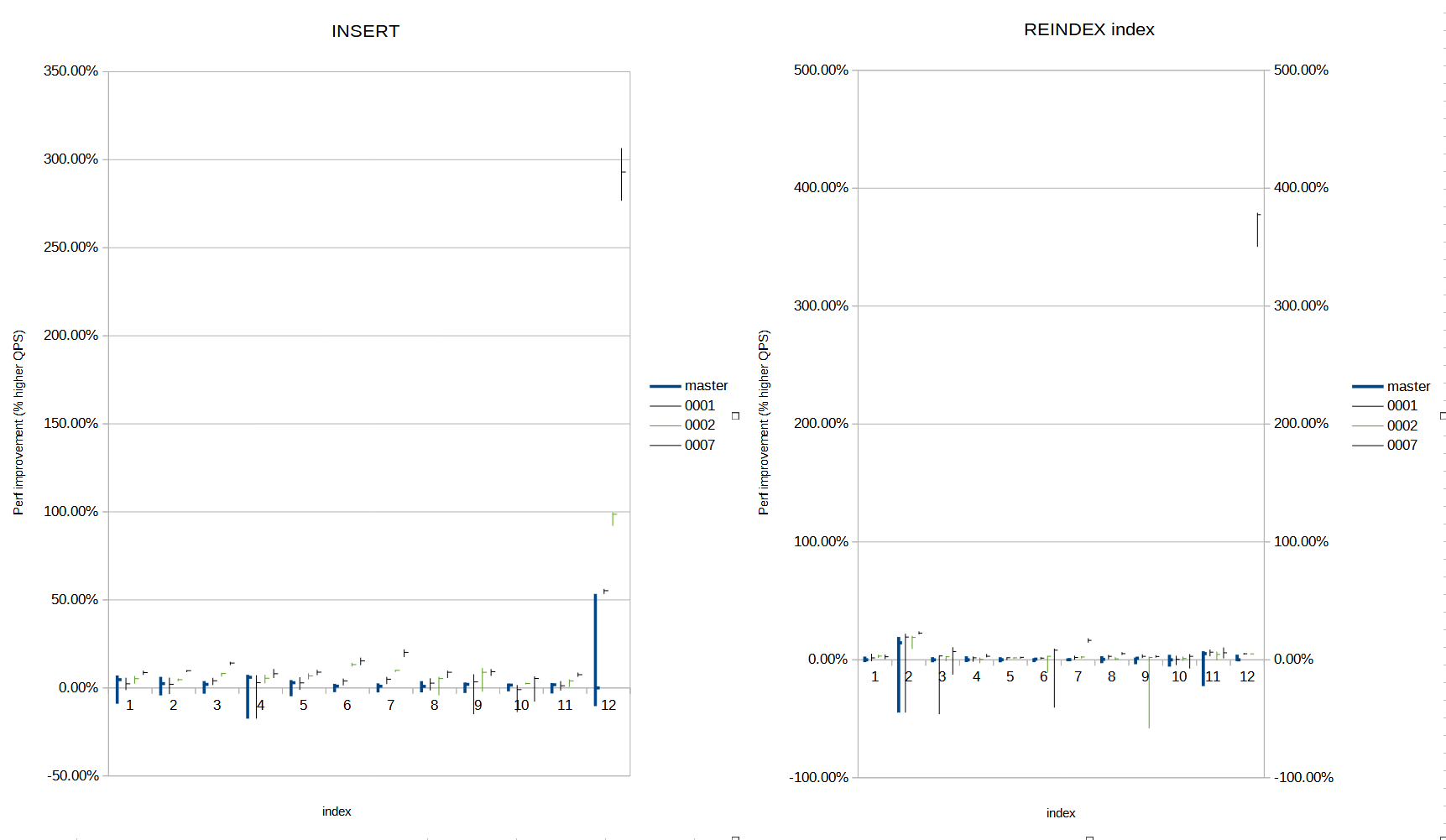{kind=link}
On Mon, 30 Oct 2023 at 21:50, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > > On Thu, 26 Oct 2023 at 00:36, Peter Geoghegan <pg@bowt.ie> wrote: > > Most of the work with something like > > this is the analysis of the trade-offs, not writing code. There are > > all kinds of trade-offs that you could make with something like this, > > and the prospect of doing that myself is kind of daunting. Ideally > > you'd have made a significant start on that at this point. > > I believe I'd already made most trade-offs clear earlier in the > threads, along with rationales for the changes in behaviour. But here > goes again: > > _bt_compare currently uses index_getattr() on each attribute of the > key. index_getattr() is O(n) for the n-th attribute if the index tuple > has any null or non-attcacheoff attributes in front of the current > one. Thus, _bt_compare costs O(n^2) work with n=the number of > attributes, which can cost several % of performance, but is very very > bad in extreme cases, and doesO(n) calls to opclass-supplied compare > operations. > > To solve most of the O(n) compare operations, we can optimize > _bt_compare to only compare "interesting" attributes, i.e. we can > apply "dynamic prefix truncation". This is implemented by patch 0001. > This is further enhanced with 0002, where we skip the compare > operations if the HIKEY is the same as the right separator of the > downlink we followed (due to our page split code, this case is > extremely likely). > > However, the above only changes the attribute indexing code in > _bt_compare to O(n) for at most about 76% of the index tuples on the > page (1 - (2 / log2(max_tuples_per_page))), while the other on average > 20+% of the compare operations still have to deal with the O(n^2) > total complexity of index_getattr. > To fix this O(n^2) issue (the issue this thread was originally created > for) the approach I implemented originally is to not use index_getattr > but an "attribute iterator" that incrementally extracts the next > attribute, while keeping track of the current offset into the tuple, > so each next attribute would be O(1). That is implemented in the last > patches of the patchset. > > This attribute iterator approach has an issue: It doesn't perform very > well for indexes that make full use of attcacheoff. The bookkeeping > for attribute iteration proved to be much more expensive than just > reading attcacheoff from memory. This is why the latter patches > (patchset 14 0003+) adapt the btree code to generate different paths > for different "shapes" of key index attributes, to allow the current > attcacheoff code to keep its performance, but to get higher > performance for indexes where the attcacheoff optimization can not be > applied. In passing, it also specializes the code for single-attribute > indexes, so that they don't have to manage branching code, increasing > their performance, too. > > TLDR: > The specialization in 0003+ is applied because index_getattr is good > when attcacheoff applies, but very bad when it doesn't. Attribute > iteration is worse than index_getattr when attcacheoff applies, but is > significantly better when attcacheoff does not work. By specializing > we get the best of both worlds. > > The 0001 and 0002 optimizations were added later to further remove > unneeded calls to the btree attribute compare functions, thus further > reducing the total time spent in _bt_compare. > > Anyway. > > PFA v14 of the patchset. v13's 0001 is now split in two, containing > prefix truncation in 0001, and 0002 containing the downlink's right > separator/HIKEY optimization. > > Performance numbers (data attached): > 0001 has significant gains in multi-column indexes with shared > prefixes, where the prefix columns are expensive to compare, but > otherwise doesn't have much impact. > 0002 further improves performance across the board, but again mostly > for indexes with expensive compare operations. > 0007 sees performance improvements almost across the board, with only > the 'ul' and 'tnt' indexes getting some worse results than master (but > still better average results), > > All patches applied, per-index average performance improvements on 15 > runs range from 3% to 290% across the board for INSERT benchmarks, and > -2.83 to 370% for REINDEX. > > Configured with autoconf: config.log: > > It was created by PostgreSQL configure 17devel, which was > > generated by GNU Autoconf 2.69. Invocation command line was > > > > $ ./configure --enable-tap-tests --enable-depend --with-lz4 --with-zstd COPT=-ggdb -O3 --prefix=/home/matthias/projects/postgresql/pg_install--no-create --no-recursion > > Benchmark was done on 1m random rows of the pp-complete dataset, as > found on UK Gov's S3 bucket [0]: using a parallel and threaded > downloader is preferred because the throughput is measured in kBps per > client. > > I'll do a few runs on the full dataset of 29M rows soon too, but > master's performance is so bad for the 'worstcase' index that I can't > finish its runs fast enough; benchmarking it takes hours per > iteration. CFBot shows that the patch does not apply anymore as in [1]: === Applying patches on top of PostgreSQL commit ID 55627ba2d334ce98e1f5916354c46472d414bda6 === === applying patch ./v14-0001-btree-Implement-dynamic-prefix-compression.patch ... Hunk #7 succeeded at 3169 with fuzz 2 (offset 75 lines). Hunk #8 succeeded at 3180 (offset 75 lines). Hunk #9 FAILED at 3157. Hunk #10 FAILED at 3180. Hunk #11 FAILED at 3218. 3 out of 11 hunks FAILED -- saving rejects to file contrib/amcheck/verify_nbtree.c.rej Please post an updated version for the same. [1] - http://cfbot.cputube.org/patch_46_3672.log Regards, Vignesh
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Sat, 27 Jan 2024 at 04:38, vignesh C <vignesh21@gmail.com> wrote: > CFBot shows that the patch does not apply anymore as in [1]: > === Applying patches on top of PostgreSQL commit ID > 55627ba2d334ce98e1f5916354c46472d414bda6 === > === applying patch ./v14-0001-btree-Implement-dynamic-prefix-compression.patch > ... > Hunk #7 succeeded at 3169 with fuzz 2 (offset 75 lines). > Hunk #8 succeeded at 3180 (offset 75 lines). > Hunk #9 FAILED at 3157. > Hunk #10 FAILED at 3180. > Hunk #11 FAILED at 3218. > 3 out of 11 hunks FAILED -- saving rejects to file > contrib/amcheck/verify_nbtree.c.rej > > Please post an updated version for the same. I've attached a rebased version, on top of HEAD @ 7b745d85. The changes for prefix compression [0] and the rightsep+hikey optimization [1] have been split off to separate patches/threads. I've also split previous patch number 0003 into multiple parts, to clearly delineate code movement vs modifications. Kind regards, Matthias van de Meent Neon (https://neon.tech) [0] https://commitfest.postgresql.org/46/4635/ [1] https://commitfest.postgresql.org/46/4638/
Attachment
- v15-0003-btree-Introduce-attribute-iterator-specializatio.patch
- v15-0002-btree-Introduce-basic-specialization.patch
- v15-0004-Add-an-attcacheoff-populating-function.patch
- v15-0005-btree-Optimize-nbts_attiter-for-indexes-with-a-s.patch
- v15-0001-btree-specialization-Prepare-code-for-specializa.patch
- v15-0006-btree-Specialize-various-performance-sensitive-f.patch
Re: Improving btree performance through specializing by key shape, take 2
From
Matthias van de Meent
Date:
On Thu, 1 Feb 2024 at 15:49, Matthias van de Meent <boekewurm+postgres@gmail.com> wrote: > I've attached a rebased version, on top of HEAD @ 7b745d85. The > changes for prefix compression [0] and the rightsep+hikey optimization > [1] have been split off to separate patches/threads. I've also split > previous patch number 0003 into multiple parts, to clearly delineate > code movement vs modifications. Rebased to v16 to fix bitrot from 8af25652. Again, short explanation ======== Current nbtree code is optimized for short index keys, i.e. with few attributes, and index keys with cacheable offsets (pg_attribute.attcacheoff). This is optimized for many cases, but for some index shapes (e.g. ON (textfield, intfield)) the current code doesn't work nice and adds significant overhead during descent: We repeatedly re-calculate attribute offsets for key attributes with uncacheable offsets. To fix this O(n^2) problem in _bt_compare(), the first idea was to use attribute offset iteration (as introduced 0003). Measurements showed that the changes do great work for uncacheable attribute offsets, but reduce the performance of indexes with cached offsets significantly. This meant that using this approach for all indexes was uneconomical: we couldn't reuse the same code across all index key shapes. To get around this performance issue, this patchset introduces specialization. Various key functions inside the btree AM which have hot paths that depend on key shape are "specialized" to one of 3 "index key shapes" identified in the patchset: "cached", "uncached", and "single attribute". Specialization is implemented with a helper header that #includes the to-be-specialized code once for each index key shape. The to-be-specialized code can then utilize several macros for iterating over index key attributes in the most efficient way available for that index key shape. For specific implementation details, see the comments in the header of include/access/nbtree_spec.h. Patches ======== 0001 moves code around without modification in preparation for specialization 0002 updates non-specialized code to hook into specialization infrastructure, without yet changing functionality. 0003 updates to-be-specialized code to use specialized index attribute iterators, and introduces the first specialization type "cached". This is no different from our current iteration type; it just has a new name and now fits in the scaffolding of specialization. 0004 introduces a helper function to be used in 0006, which calculates and stores attcacheoff for cacheable attributes, while also (new for attcacheoff) storing negative cache values (i.e. uncacheable) for those attributes that can't have attcacheoff, e.g. those behind a size of < 0. 0005 introduces the "single attribute" specialization, which realizes that the first attribute has a known offset in the index tuple data section, so it doesn't have to access or keep track of as much information, which saves cycles in the common case of single-attribute indexes. 0006 introduces the final, "uncached", specialization. It progressively calculates offsets of attributes as needed, rather than the start from scratch approach in indexgetattr(). Tradeoffs ======== This patch introduces a new CPP templating mechanism which is more complex than most other templates currently in use. This is certainly additional complexity, but the file structure used allow for a mostly similar C programming experience, with the only caveat that the file is not built into an object file directly, but included into another file (and thus shouldn't #include its own headers). By templating functions, this patch also increases the size of the PostgreSQL binary. Bloaty measured a 48kiB increase in size of the .text section of the binary (47MiB) built with debugging options at [^0], while a non-debug build of the same kind [^1] (9.89MiB) has an increase in size of 34.8kiB. Given the performance improvements achievable using this patch, I believe this patch is worth the increase in size. Performance ======== I haven't retested the results separately yet, but I assume the performance results of [2] hold mostly true in comparing 0002 vs 0007. I will do a performance (re-)evaluation of only this patch if so requested (or once I have time), but please do review the code, too. Kind regards, Matthias van de Meent [^0] ./configure --enable-depend --enable-tap-tests --enable-cassert --with-lz4 --enable-debug --with-zstd COPT='-O3 -g3' --prefix=~/projects/postgresql/pg_install [^1] ./configure --enable-depend --enable-tap-tests --with-lz4 --with-zstd COPT='-O3' --prefix=~/projects/postgresql/pg_install [2] https://www.postgresql.org/message-id/CAEze2WiqOONRQTUT1p_ZV19nyMA69UU2s0e2dp%2BjSBM%3Dj8snuw%40mail.gmail.com
Attachment
- v16-0005-btree-Optimize-nbts_attiter-for-indexes-with-a-s.patch
- v16-0002-btree-Introduce-basic-specialization.patch
- v16-0003-btree-Introduce-attribute-iterator-specializatio.patch
- v16-0004-Add-an-attcacheoff-populating-function.patch
- v16-0001-btree-specialization-Prepare-code-for-specializa.patch
- v16-0006-btree-Specialize-various-performance-sensitive-f.patch
> On Mon, Mar 04, 2024 at 09:39:37PM GMT, Matthias van de Meent wrote: > Performance > ======== > > I haven't retested the results separately yet, but I assume the > performance results of [2] hold mostly true in comparing 0002 vs 0007. > I will do a performance (re-)evaluation of only this patch if so > requested (or once I have time), but please do review the code, too. Yeah, if you don't mind it would be great to see a performance evaluation for the latest patch. The CF item is stored under the performance after all. In fact, looking at the results in [2], I would even ask for improving them: * The results posted so far seems to have two loads, insert and reindex, both are close to the best-case scenario for this feature. But you've also mentioned in the thread, that worst-case expectation is a hot loop over a B-Tree index without any specifically optimized path. It would be interesting too see how much impact this feature have under such less favorable load. * Just to be on the safe side, could you describe the testing environment? I'm asking, because the variance bars on the graph look suspicious -- they don't seem to directly depend on the number of columns in the index, so probably the variance is introduced by the environment itself. And if I read the graph correctly, in certain cases it's quite a lot of variance (up to -50% on the reindex?). * Do I interpret the results correctly, the 0007 patch got much larger performance boost between 10 and 12 columns? Any explanation why those numbers feature such dramatic difference? * [nit] It would be great to have a bit better color coding for readability. As a side note, I've got a bit lost in the relationship between this patch series and the one with dynamic prefix truncation. Should they be considered fully independent, for convenience of review, or is there anything that has to be taken into account? > [^0] ./configure --enable-depend --enable-tap-tests --enable-cassert > --with-lz4 --enable-debug --with-zstd COPT='-O3 -g3' > --prefix=~/projects/postgresql/pg_install Any particular reason you build with O3? AFAICT most of the time distributions use O2, so it probably will be a bit more realistic.