Thread: PostgreSQL 9.2 high replication lag - Part 2
Hello,
I posted here a couple of months ago about a high replication lag on PG 9.2. (I've switched to another mailserver, therefore, can't reply to the original thread).
I have done a couple of enhancements for the past few months and would like to share them with you, to ask your suggestions as the problem is still there.
Yes, I know I use a very old PG version. But a migration plan is in place to PG 13. I wish I had finished that project already, but it's taking longer than expected.
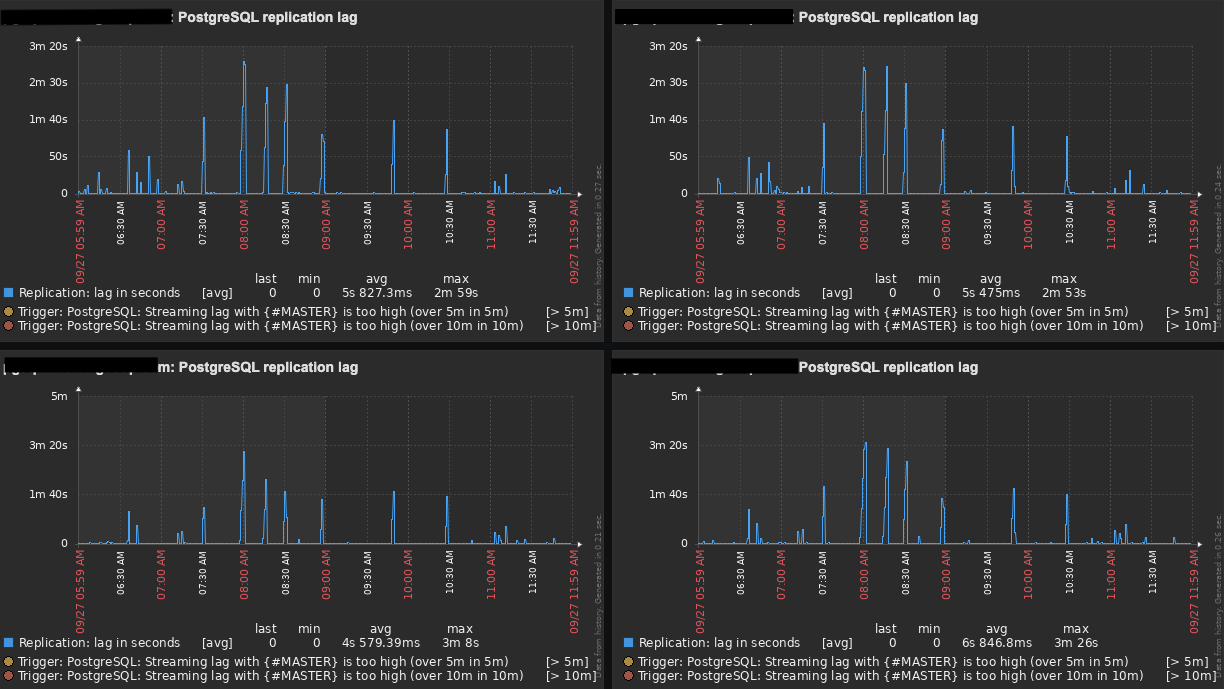
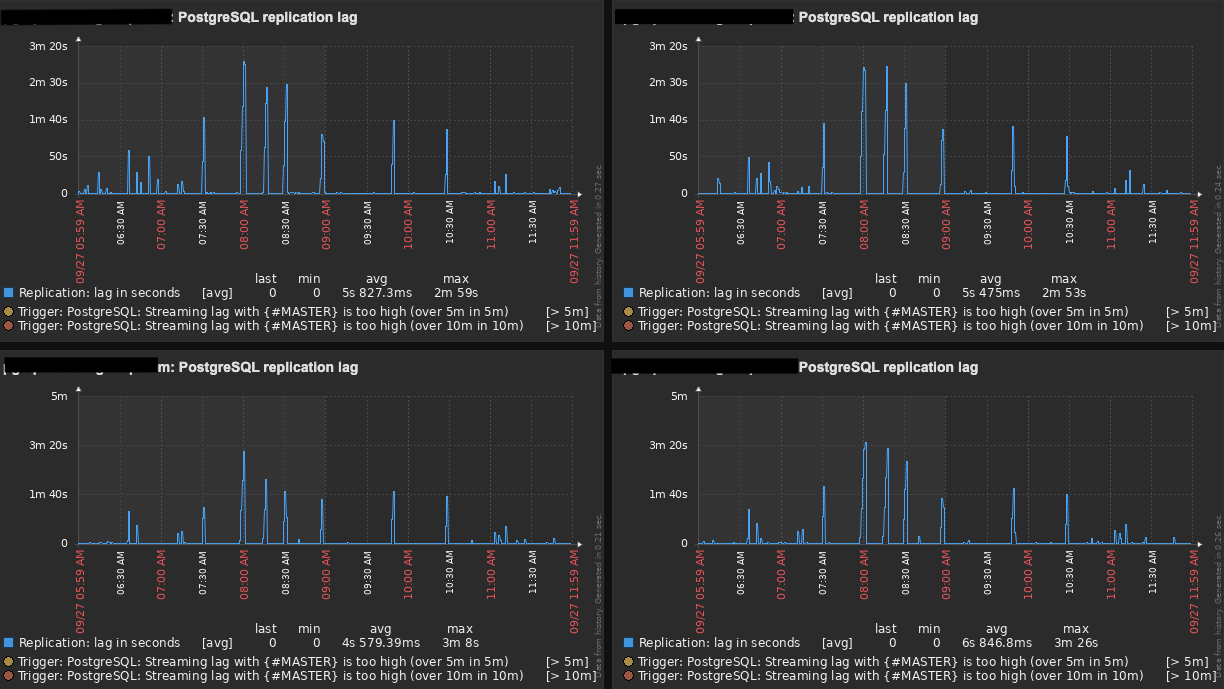
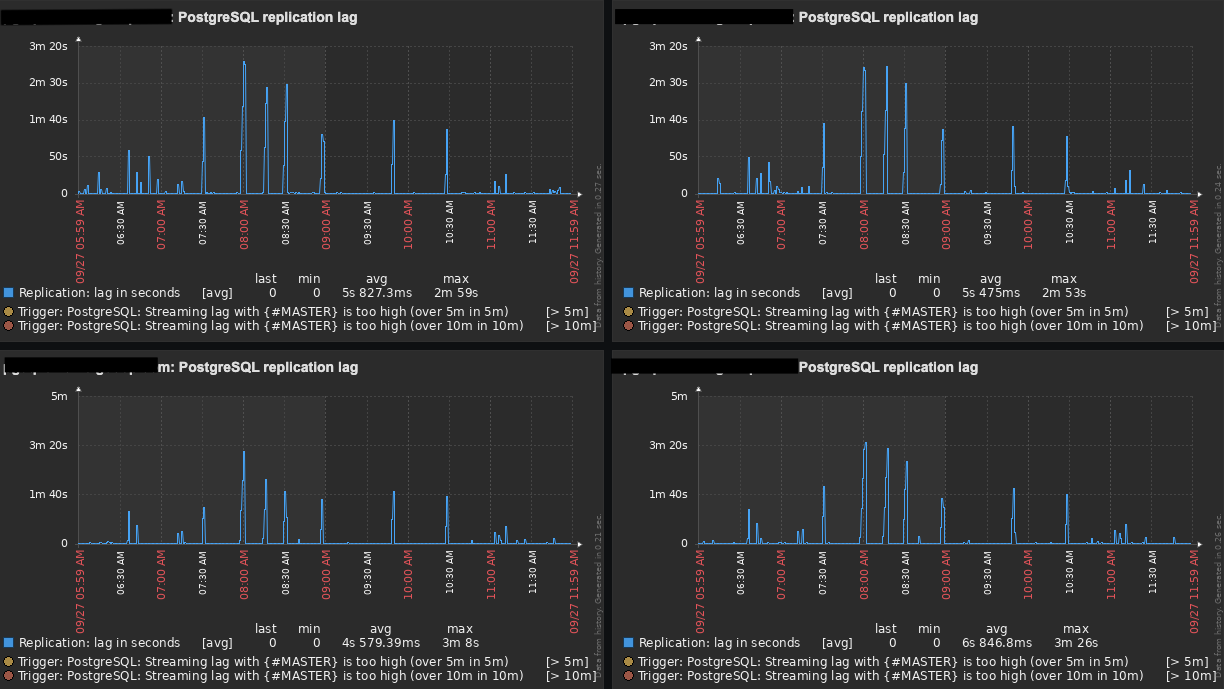
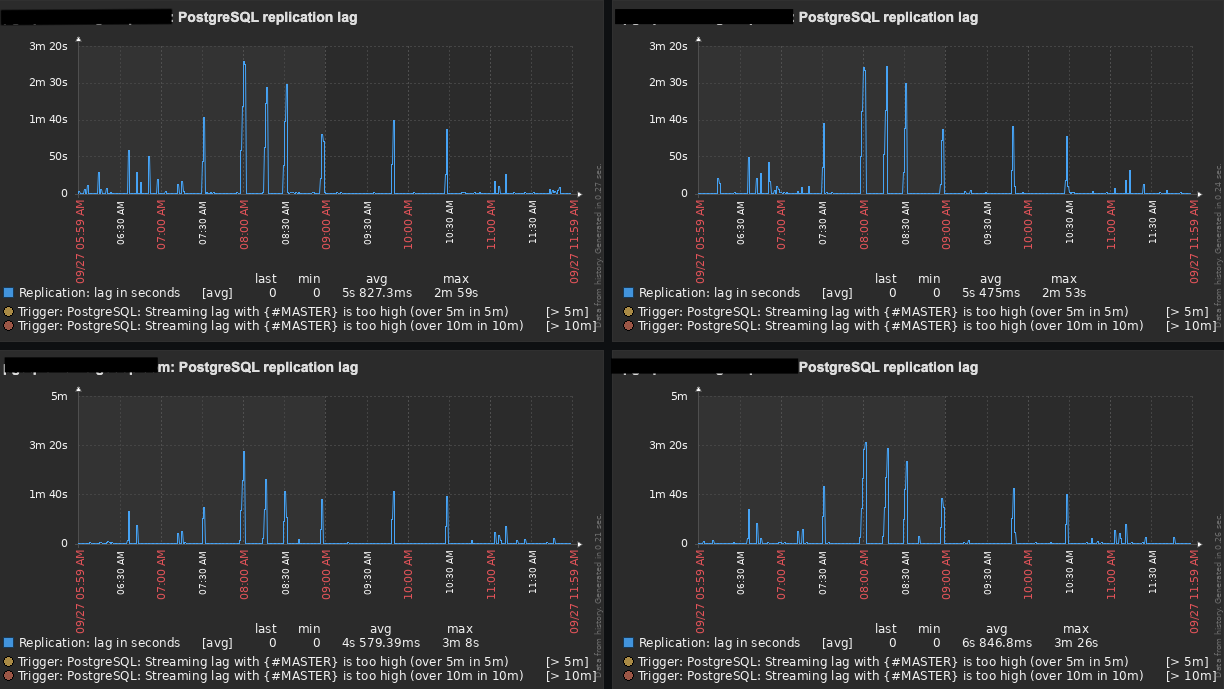
If you remember correctly, my original setup was: 1 Master and 1 Slave (100% of read-only traffic) running on AWS EC2 instances, and the replication lag was getting up to 10 minutes in some cases.
Since then, I have conducted the following improvements:
- Deployed more slaves to the stack, replacing that original slave with 4 new ones using AWS EBS GP3 volumes.
- Upgraded the Master's volumes from GP2 to GP3.
- Deployed Zabbix with the Zabbix PostgreSQL plugin to better monitor the databases and their hosts, to have better visibility.
- Have decreased max_standby_streaming_delay from 300s to 30s.
- Because I'm dealing with new Instances Types, now that I have deployed more slaves, I've tuned postgresql.conf file according to pgtune and pgconfig. You can check my postgresql.conf for a r4.4xlarge (16 vCPU, 122GB RAM) below:
- data_directory = '/pgsql/9.2/main'
hba_file = '/etc/postgresql/9.2/main/pg_hba.conf'
ident_file = '/etc/postgresql/9.2/main/pg_ident.conf'
external_pid_file = '/var/run/postgresql/9.2-main.pid'
hot_standby = on
listen_addresses = '*'
port = 5432
random_page_cost = 1.1
max_connections = 500
unix_socket_directory = '/var/run/postgresql'
shared_buffers = 31232MB
statement_timeout = 0
work_mem = 63963kB
maintenance_work_mem = 2GB
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.track = all
track_activity_query_size = 102400
wal_level = hot_standby
fsync = on
synchronous_commit = on
wal_buffers = 16MB
checkpoint_segments = 32
checkpoint_completion_target = 0.9
archive_mode = on
archive_command = '/pgsql/pg-archive-wal-to-slaves.sh "%p"'
archive_timeout = 1800
max_wal_senders = 20
wal_keep_segments = 1024
effective_cache_size = 93696MB
logging_collector = on
log_directory = '/data/postgresql/log'
log_filename = 'postgresql-9.2-main.log.%a'
log_rotation_age = 1440
log_rotation_size = 0
log_truncate_on_rotation = on
log_min_duration_statement = 1000
log_lock_waits = on
log_statement = 'ddl'
log_timezone = 'UTC'
stats_temp_directory = '/var/run/postgresql/9.2-main.pg_stat_tmp'
autovacuum = on
log_autovacuum_min_duration = 1000
autovacuum_max_workers = 5
autovacuum_naptime = 40s
autovacuum_vacuum_threshold = 200
autovacuum_analyze_threshold = 150
autovacuum_vacuum_scale_factor = 0.02
autovacuum_analyze_scale_factor = 0.005
deadlock_timeout = 2s
max_files_per_process = 4096
effective_io_concurrency = 200
hot_standby_feedback = on
# https://dba.stackexchange.com/a/280727
max_standby_streaming_delay = 30s
default_statistics_target = 100
- data_directory = '/pgsql/9.2/main'
After all those changes, our replication lag now gets up to 3 minutes (tops) with an average of 1:30 minutes. Even though it has improved a lot, it is still not great and I was hopping to get a few suggestions from you guys.
Any suggestions/comments will be much appreciated.
Cheers!
Lucas
Attachment
Anyone, please?
Lucas
On 2021-09-27 12:06, Lucas Possamai wrote:
Hello,
I posted here a couple of months ago about a high replication lag on PG 9.2. (I've switched to another mailserver, therefore, can't reply to the original thread).
I have done a couple of enhancements for the past few months and would like to share them with you, to ask your suggestions as the problem is still there.
Yes, I know I use a very old PG version. But a migration plan is in place to PG 13. I wish I had finished that project already, but it's taking longer than expected.
If you remember correctly, my original setup was: 1 Master and 1 Slave (100% of read-only traffic) running on AWS EC2 instances, and the replication lag was getting up to 10 minutes in some cases.
Since then, I have conducted the following improvements:
- Deployed more slaves to the stack, replacing that original slave with 4 new ones using AWS EBS GP3 volumes.
- Upgraded the Master's volumes from GP2 to GP3.
- Deployed Zabbix with the Zabbix PostgreSQL plugin to better monitor the databases and their hosts, to have better visibility.
- Have decreased max_standby_streaming_delay from 300s to 30s.
- Because I'm dealing with new Instances Types, now that I have deployed more slaves, I've tuned postgresql.conf file according to pgtune and pgconfig. You can check my postgresql.conf for a r4.4xlarge (16 vCPU, 122GB RAM) below:
- data_directory = '/pgsql/9.2/main'
hba_file = '/etc/postgresql/9.2/main/pg_hba.conf'
ident_file = '/etc/postgresql/9.2/main/pg_ident.conf'
external_pid_file = '/var/run/postgresql/9.2-main.pid'
hot_standby = on
listen_addresses = '*'
port = 5432
random_page_cost = 1.1
max_connections = 500
unix_socket_directory = '/var/run/postgresql'
shared_buffers = 31232MB
statement_timeout = 0
work_mem = 63963kB
maintenance_work_mem = 2GB
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.track = all
track_activity_query_size = 102400
wal_level = hot_standby
fsync = on
synchronous_commit = on
wal_buffers = 16MB
checkpoint_segments = 32
checkpoint_completion_target = 0.9
archive_mode = on
archive_command = '/pgsql/pg-archive-wal-to-slaves.sh "%p"'
archive_timeout = 1800
max_wal_senders = 20
wal_keep_segments = 1024
effective_cache_size = 93696MB
logging_collector = on
log_directory = '/data/postgresql/log'
log_filename = 'postgresql-9.2-main.log.%a'
log_rotation_age = 1440
log_rotation_size = 0
log_truncate_on_rotation = on
log_min_duration_statement = 1000
log_lock_waits = on
log_statement = 'ddl'
log_timezone = 'UTC'
stats_temp_directory = '/var/run/postgresql/9.2-main.pg_stat_tmp'
autovacuum = on
log_autovacuum_min_duration = 1000
autovacuum_max_workers = 5
autovacuum_naptime = 40s
autovacuum_vacuum_threshold = 200
autovacuum_analyze_threshold = 150
autovacuum_vacuum_scale_factor = 0.02
autovacuum_analyze_scale_factor = 0.005
deadlock_timeout = 2s
max_files_per_process = 4096
effective_io_concurrency = 200
hot_standby_feedback = on
# https://dba.stackexchange.com/a/280727
max_standby_streaming_delay = 30s
default_statistics_target = 100
After all those changes, our replication lag now gets up to 3 minutes (tops) with an average of 1:30 minutes. Even though it has improved a lot, it is still not great and I was hopping to get a few suggestions from you guys.
Any suggestions/comments will be much appreciated.
Cheers!
--Regards,
Lucas
Attachment
Hello,
I posted here a couple of months ago about a high replication lag on PG 9.2. (I've switched to another mailserver, therefore, can't reply to the original thread).
I have done a couple of enhancements for the past few months and would like to share them with you, to ask your suggestions as the problem is still there.
Yes, I know I use a very old PG version. But a migration plan is in place to PG 13. I wish I had finished that project already, but it's taking longer than expected.
If you remember correctly, my original setup was: 1 Master and 1 Slave (100% of read-only traffic) running on AWS EC2 instances, and the replication lag was getting up to 10 minutes in some cases.
Since then, I have conducted the following improvements:
- Deployed more slaves to the stack, replacing that original slave with 4 new ones using AWS EBS GP3 volumes.
- Upgraded the Master's volumes from GP2 to GP3.
- Deployed Zabbix with the Zabbix PostgreSQL plugin to better monitor the databases and their hosts, to have better visibility.
- Have decreased max_standby_streaming_delay from 300s to 30s.
- Because I'm dealing with new Instances Types, now that I have deployed more slaves, I've tuned postgresql.conf file according to pgtune and pgconfig. You can check my postgresql.conf for a r4.4xlarge (16 vCPU, 122GB RAM) below:
- data_directory = '/pgsql/9.2/main'
hba_file = '/etc/postgresql/9.2/main/pg_hba.conf'
ident_file = '/etc/postgresql/9.2/main/pg_ident.conf'
external_pid_file = '/var/run/postgresql/9.2-main.pid'
hot_standby = on
listen_addresses = '*'
port = 5432
random_page_cost = 1.1
max_connections = 500
unix_socket_directory = '/var/run/postgresql'
shared_buffers = 31232MB
statement_timeout = 0
work_mem = 63963kB
maintenance_work_mem = 2GB
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.track = all
track_activity_query_size = 102400
wal_level = hot_standby
fsync = on
synchronous_commit = on
wal_buffers = 16MB
checkpoint_segments = 32
checkpoint_completion_target = 0.9
archive_mode = on
archive_command = '/pgsql/pg-archive-wal-to-slaves.sh "%p"'
archive_timeout = 1800
max_wal_senders = 20
wal_keep_segments = 1024
effective_cache_size = 93696MB
logging_collector = on
log_directory = '/data/postgresql/log'
log_filename = 'postgresql-9.2-main.log.%a'
log_rotation_age = 1440
log_rotation_size = 0
log_truncate_on_rotation = on
log_min_duration_statement = 1000
log_lock_waits = on
log_statement = 'ddl'
log_timezone = 'UTC'
stats_temp_directory = '/var/run/postgresql/9.2-main.pg_stat_tmp'
autovacuum = on
log_autovacuum_min_duration = 1000
autovacuum_max_workers = 5
autovacuum_naptime = 40s
autovacuum_vacuum_threshold = 200
autovacuum_analyze_threshold = 150
autovacuum_vacuum_scale_factor = 0.02
autovacuum_analyze_scale_factor = 0.005
deadlock_timeout = 2s
max_files_per_process = 4096
effective_io_concurrency = 200
hot_standby_feedback = on
# https://dba.stackexchange.com/a/280727
max_standby_streaming_delay = 30s
default_statistics_target = 100
After all those changes, our replication lag now gets up to 3 minutes (tops) with an average of 1:30 minutes. Even though it has improved a lot, it is still not great and I was hopping to get a few suggestions from you guys.
Any suggestions/comments will be much appreciated.
Cheers!
--Regards,
Lucas

Attachment
Hi Ben,
Thanks for your reply.
I totally get what you're saying. However, upgrading directly from 9.2 to 14 using pg_upgrade isn't a good idea. I've tried it and have had many different issues.
The ideal scenario would be to do: 9.2 -> 10.x -> 12.x -> 14, however, that means several downtimes which we cannot have. So, using a 3rd party tool like Bucardo allow us to do that with almost no downtime. Plus, we have tested this approach on RDS and it works great.
Cheers,
Lucas
Lucas
On 2021-10-05 21:10, Ben Madin wrote:
Hi Lucas,I think I might have replied before, but the upgrade for one server should take less time than the lag you are describing... and looking at all the other work you have done, I think you might be investing your time in the wrong place. In AWS we run master in one zone (b), with 2 streaming replicas (one in a & one in b zones). Our biggest problems come from long running queries on the replicas not completing before the streaming takes over (set up for 30 seconds on our arrangement). We did have some problems with 9, but since upgrading to 10, then 11 and now 12 we have had no issues - and each upgrade was very smooth. We run our own because we were using pl/r & pl/python (not supported by RDS - but we have phased out pl/r and there are now boto commands available in RDS so we don't need to use pl/python any longer).Nonetheless, my gut feeling is that most people aren't likely to be putting much time into a version that is discontinued from this month.cheersBenOn Mon, 27 Sept 2021 at 07:06, Lucas Possamai <root@sud0.nz> wrote:Hello,
I posted here a couple of months ago about a high replication lag on PG 9.2. (I've switched to another mailserver, therefore, can't reply to the original thread).
I have done a couple of enhancements for the past few months and would like to share them with you, to ask your suggestions as the problem is still there.
Yes, I know I use a very old PG version. But a migration plan is in place to PG 13. I wish I had finished that project already, but it's taking longer than expected.
If you remember correctly, my original setup was: 1 Master and 1 Slave (100% of read-only traffic) running on AWS EC2 instances, and the replication lag was getting up to 10 minutes in some cases.
Since then, I have conducted the following improvements:
- Deployed more slaves to the stack, replacing that original slave with 4 new ones using AWS EBS GP3 volumes.
- Upgraded the Master's volumes from GP2 to GP3.
- Deployed Zabbix with the Zabbix PostgreSQL plugin to better monitor the databases and their hosts, to have better visibility.
- Have decreased max_standby_streaming_delay from 300s to 30s.
- Because I'm dealing with new Instances Types, now that I have deployed more slaves, I've tuned postgresql.conf file according to pgtune and pgconfig. You can check my postgresql.conf for a r4.4xlarge (16 vCPU, 122GB RAM) below:
- data_directory = '/pgsql/9.2/main'
hba_file = '/etc/postgresql/9.2/main/pg_hba.conf'
ident_file = '/etc/postgresql/9.2/main/pg_ident.conf'
external_pid_file = '/var/run/postgresql/9.2-main.pid'
hot_standby = on
listen_addresses = '*'
port = 5432
random_page_cost = 1.1
max_connections = 500
unix_socket_directory = '/var/run/postgresql'
shared_buffers = 31232MB
statement_timeout = 0
work_mem = 63963kB
maintenance_work_mem = 2GB
shared_preload_libraries = 'pg_stat_statements'
pg_stat_statements.track = all
track_activity_query_size = 102400
wal_level = hot_standby
fsync = on
synchronous_commit = on
wal_buffers = 16MB
checkpoint_segments = 32
checkpoint_completion_target = 0.9
archive_mode = on
archive_command = '/pgsql/pg-archive-wal-to-slaves.sh "%p"'
archive_timeout = 1800
max_wal_senders = 20
wal_keep_segments = 1024
effective_cache_size = 93696MB
logging_collector = on
log_directory = '/data/postgresql/log'
log_filename = 'postgresql-9.2-main.log.%a'
log_rotation_age = 1440
log_rotation_size = 0
log_truncate_on_rotation = on
log_min_duration_statement = 1000
log_lock_waits = on
log_statement = 'ddl'
log_timezone = 'UTC'
stats_temp_directory = '/var/run/postgresql/9.2-main.pg_stat_tmp'
autovacuum = on
log_autovacuum_min_duration = 1000
autovacuum_max_workers = 5
autovacuum_naptime = 40s
autovacuum_vacuum_threshold = 200
autovacuum_analyze_threshold = 150
autovacuum_vacuum_scale_factor = 0.02
autovacuum_analyze_scale_factor = 0.005
deadlock_timeout = 2s
max_files_per_process = 4096
effective_io_concurrency = 200
hot_standby_feedback = on
# https://dba.stackexchange.com/a/280727
max_standby_streaming_delay = 30s
default_statistics_target = 100
After all those changes, our replication lag now gets up to 3 minutes (tops) with an average of 1:30 minutes. Even though it has improved a lot, it is still not great and I was hopping to get a few suggestions from you guys.
Any suggestions/comments will be much appreciated.
Cheers!
--Regards,
Lucas--Dr Ben MadinBVMS MVPHMgmt PhD MANZCVS GAICDManaging Director