Thread: [PATCH] Covering SPGiST index
Hi, hackers!
--
I'd like to propose a patch which introduces a functionality to include additional columns to SPGiST index to increase speed of queries containing them due to making the scans index only in this case. To date this functionality was available in GiSt and btree, I suppose the same is useful in SPGiST also.
A few words on realisaton:
1. The patch is intended to be fully compatible with previous SPGiSt indexes so SpGist leaf tuple structure remains unchanged until the ending of key attribute. All changes are introduced only after it. Internal tuples remain unchanged at all.
2. Included data is added in the form very similar to heap tuple but unlike the later it should not start from MAXALIGN boundary. I.e. nulls mask (if exist) starts just after the key value (it doesn't need alignment). Each of included attributes start from their own typealign boundary. The goal is to make leaf tuples and therefore index more compact.
3. Leaf tuple header is modified to store additional per tuple flags:
a) is nullmask present - if there is at least one null value among included attributes of a tuple
(Note that this nullmask apply only to include attributes as nulls management for key attributes is already realised in SPGiSt by placing leafs with null keys in separate list not in the main index tree.)
b) is there variable length values among included. If there is no and key attribute is also fixed-length e.g. (kd-tree, quad-tree etc.) then leaf tuple processing can be speed up using attcacheoff.
These bits are incorporated into unused higher bits of nextOffset in the header SPGiST leaf tuple. Even if we have 64Kb pages and tuples of minimum 12 bytes (the length of the header on 32-bit architectures) + 4 bytes ItemIdData 14 bit for nextOffset is more than enough.
All this changes only affect private index structures so all outside behavior like WAL, vacuum etc will remain unchanged.
As usual I very much appreciate your feedback
Attachment
> 7 авг. 2020 г., в 16:59, Pavel Borisov <pashkin.elfe@gmail.com> написал(а): > > As usual I very much appreciate your feedback Thanks for the patch! Looks interesting. On a first glance the whole concept of non-multicolumn index with included attributes seems...well, just difficult to understand. But I expect for SP-GiST this must be single key with multiple included attributes, right? I couldn't find a test that checks impossibility of on 2-column SP-GiST, only few asserts about it. Is this checked somewhereelse? Thanks! Best regards, Andrey Borodin.
On a first glance the whole concept of non-multicolumn index with included attributes seems...well, just difficult to understand.
But I expect for SP-GiST this must be single key with multiple included attributes, right?
I couldn't find a test that checks impossibility of on 2-column SP-GiST, only few asserts about it. Is this checked somewhere else?
Yes, SpGist is by its construction a single-column index, there is no such thing like 2-column SP-GiST yet. In the same way like original SpGist will refuse to add a second key column, this remains after modification as well, with exception of columns attached by INCLUDE directive. They can be (INDEX_MAX_KEYS -1) pieces and they will not be used to create additional index trees (as there is only one), they will be just attached to the key tree leafs tuple.
I also little bit corrected error reporting for the case when user wants to invoke index build with not one column. Thanks!
--
Attachment
Also little bit corrected code formatting.
Attachment
Same code formatted as a patch.
пн, 10 авг. 2020 г. в 17:45, Pavel Borisov <pashkin.elfe@gmail.com>:
Also little bit corrected code formatting.
Attachment
I added changes in documentation into the patch.
Attachment
вт, 11 авг. 2020 г. в 12:11, Pavel Borisov <pashkin.elfe@gmail.com>:
I added changes in documentation into the patch.--
Attachment
With a little bugfix
вт, 11 авг. 2020 г. в 22:50, Pavel Borisov <pashkin.elfe@gmail.com>:
вт, 11 авг. 2020 г. в 12:11, Pavel Borisov <pashkin.elfe@gmail.com>:I added changes in documentation into the patch.--
Attachment
Hi! > 17 авг. 2020 г., в 21:04, Pavel Borisov <pashkin.elfe@gmail.com> написал(а): > > Postgres Professional: http://postgrespro.com > <v6-0001-Covering-SP-GiST-index-support-for-INCLUDE-column.patch> I'm looking into the patch. I have few notes: 1. I see that in src/backend/access/spgist/README you describe SP-GiST tuple as sequence of {Value, ItemPtr to heap, Includedattributes}. Is it different from regular IndexTuple where tid is within TupleHeader? 2. Instead of cluttering tuple->nextOffset with bit flags we could just change Tuple Header for leaf tuples with coveringindexes. Interpret tuples for indexes with included attributes differently, iff it makes code cleaner. There areso many changes with SGLT_SET_OFFSET\SGLT_GET_OFFSET that it seems viable to put some effort into research of other waysto represent two bits for null mask and varatts. 3. Comment "* SPGiST dead tuple: declaration for examining non-live tuples" does not precede relevant code. because structSpGistDeadTupleData was not moved. Thanks! Best regards, Andrey Borodin.
I'm looking into the patch. I have few notes:
1. I see that in src/backend/access/spgist/README you describe SP-GiST tuple as sequence of {Value, ItemPtr to heap, Included attributes}. Is it different from regular IndexTuple where tid is within TupleHeader?
Yes, the header of SpGist tuple is put down in a little bit different way than index tuple. It is also intended to connect spgist leaf tuples in chains on a leaf page so it already have more complex layout and bigger size that index tuple header.
SpGist tuple header size is 12 bytes which is a maxaligned value for 32 bit architectures, and key value can start just after it without any gap. This is of value, as unnecessary index size increase slows down performance and is evil anyway. The only part of this which is left now is a gap between SpGist tuple header and first value on 64 bit architecture (as maxalign value in this case is 16 bytes and 4 bytes per tuple can be saved). But I was discouraged to change this on the reason of binary compatibility with indexes built before and complexity of the change also, as quite many things in the code do depend on this maxaligned header (for inner and dead tuples also).
Another difference is that SpGist nulls mask is inserted after the key value before the first included one and apply only to included values. It is not needed for key values, as null key values in SpGist are stored in separate tree, and it is not needed to mark it null second time. Also nulls mask size in Spgist does depend on the number of included values in a tuple, unlike in IndexTuple which contains redundant nulls mask for all possible INDEX_MAX_KEYS. In certain cases we can store nulls mask in free bytes after key value before typealign of first included value. (E.g. if key value is varchar (radix tree) statistically we have only 1/8 of keys finishing exactly an maxalign, the others will have a natural gap for nulls mask.)
2. Instead of cluttering tuple->nextOffset with bit flags we could just change Tuple Header for leaf tuples with covering indexes. Interpret tuples for indexes with included attributes differently, iff it makes code cleaner. There are so many changes with SGLT_SET_OFFSET\SGLT_GET_OFFSET that it seems viable to put some effort into research of other ways to represent two bits for null mask and varatts.
Of course SpGist header can be done different for index with and without included columns. I see two reasons against this:
1. It will be needed to integrate many ifs and in many places keep in mind whether the index contains included values. It is expected to be much more code than now and not only in the parts which integrates included values to leaf tuples. I think this vast changes can puzzle reader much more than just two small macros evenly copy-pasted in the code.
2. I also see no need to increase SpGist tuple size just for inserting two bits which are now stored free of charge. I consulted with bit flags storage in IndexTupleData.t_tid and did it in a similar way. Macros for GET/SET are basically needed to make bit flags and offset modification independent and safe in any place of a code.
I added some extra comments and mentions in manual to make all the things clear (see v7 patch)
3. Comment "* SPGiST dead tuple: declaration for examining non-live tuples" does not precede relevant code. because struct SpGistDeadTupleData was not moved.
You are right, thank you! Corrected this and also removed some unnecessary declarations.
Thank you for your attention to the patch!
Attachment
On 24.08.2020 16:19, Pavel Borisov wrote:
I added some extra comments and mentions in manual to make all the things clear (see v7 patch)
The patch implements the proposed functionality, passes tests, and in general looks good to me.
I don't mind using a macro to differentiate tuples with and without included attributes. Any approach will require code changes. Though, I don't have a strong opinion about that.
A bit of nitpicking:
1) You mention backward compatibility in some comments. But, after this patch will be committed, it will be uneasy to distinct new and old phrases. So I suggest to rephrase them. You can either refer a specific version or just call it "compatibility with indexes without included attributes".
2) SpgLeafSize() function name seems misleading, as it actually refers to a tuple's size, not a leaf page. I suggest to rename it to SpgLeafTupleSize().
3) I didn't quite get the meaning of the assertion, that is added in a few places:
Assert(so->state.includeTupdesc->natts);
Should it be Assert(so->state.includeTupdesc->natts > 1) ?
4) There are a few typos in comments and docs:
s/colums/columns
s/include attribute/included attribute
and so on.
5) This comment in index_including.sql is outdated:
* 7. Check various AMs. All but btree and gist must fail.
6) New test lacks SET enable_seqscan TO off;
in addition to SET enable_bitmapscan TO off;
I also wonder, why both index_including_spgist.sql and index_including.sql tests are stable without running 'vacuum analyze' before the EXPLAIN that shows Index Only Scan plan. Is autovacuum just always fast enough to fill a visibility map, or I miss something?
-- Anastasia Lubennikova Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
3) I didn't quite get the meaning of the assertion, that is added in a few places:
Assert(so->state.includeTupdesc->natts);
Should it be Assert(so->state.includeTupdesc->natts > 1) ?
It is rather Assert(so->state.includeTupdesc->natts > 0) as INCLUDE tuple descriptor should not be initialized and filled in case of index without INCLUDE attributes and doesn't contain any info about key attribute which is processed by SpGist existing way separately for different SpGist tuple types i.e. leaf, prefix=inner and label tuples. So only INCLUDE attributes are counted there. This and similar Asserts are for the case includeTupdesc becomes mistakenly initialized by some future code change.
I completely agree with all the other suggestions and made corrections (see v8). Thank you very much for your review!
Also there is a separate patch 0002 to add VACUUM ANALYZE to index_including test which is not necessary for covering spgist.
One more point to note: in spgist_private.h I needed to shift down whole block between
"typedef struct SpGistSearchItem"
and
"} SpGistCache;"
to position it below tuples types declarations to insert pointer "SpGistLeafTuple leafTuple"; into struct SpGistSearchItem. This is the only change in this block and I apologize for possible inconvenience to review this change.
Attachment
> 27 авг. 2020 г., в 21:03, Pavel Borisov <pashkin.elfe@gmail.com> написал(а): > > see v8 For me is the only concerning point is putting nullmask and varatt bits into tuple->nextOffset. But, probably, we can go with this. But let's change macro a bit. When I see SGLT_SET_OFFSET(leafTuple->nextOffset, InvalidOffsetNumber); I expect that leafTuple->nextOffset is function argument by value and will not be changed. For example see ItemPointerSetOffsetNumber() - it's not exposing ip_posid. Also, I'd propose instead of >*(leafChainDatums + i * natts) and leafChainIsnulls + i * natts using something like >int some_index = i * natts; >leafChainDatumsp[some_index] and &leafChainIsnulls[some_index] But, probably, it's a matter of taste... Also I'm not sure would it be helpful to use instead of >isnull[0] and leafDatum[0] more complex >#define SpgKeyIndex 0 >isnull[SpgKeyIndex] and leafDatum[SpgKeyIndex] There is so many [0] in the patch... Thanks! Best regards, Andrey Borodin.
But let's change macro a bit. When I see
SGLT_SET_OFFSET(leafTuple->nextOffset, InvalidOffsetNumber);
I expect that leafTuple->nextOffset is function argument by value and will not be changed.
For example see ItemPointerSetOffsetNumber() - it's not exposing ip_posid.
Also, I'd propose instead of
>*(leafChainDatums + i * natts) and leafChainIsnulls + i * natts
using something like
>int some_index = i * natts;
>leafChainDatumsp[some_index] and &leafChainIsnulls[some_index]
But, probably, it's a matter of taste...
Also I'm not sure would it be helpful to use instead of
>isnull[0] and leafDatum[0]
more complex
>#define SpgKeyIndex 0
>isnull[SpgKeyIndex] and leafDatum[SpgKeyIndex]
There is so many [0] in the patch...
I agree with all of your proposals and integrated them into v9.
Thank you very much!
Attachment
> 31 авг. 2020 г., в 16:57, Pavel Borisov <pashkin.elfe@gmail.com> написал(а):
>
> I agree with all of your proposals and integrated them into v9.
I have a wild idea of renaming nextOffset in SpGistLeafTupleData.
Or at least documenting in comments that this field is more than just an offset.
This looks like assert rather than real runtime check in spgLeafTupleSize()
+ if (state->includeTupdesc->natts + 1 >= INDEX_MAX_KEYS)
+ ereport(ERROR,
+ (errcode(ERRCODE_TOO_MANY_COLUMNS),
+ errmsg("number of index columns (%d) exceeds limit (%d)",
+ state->includeTupdesc->natts, INDEX_MAX_KEYS)));
Even if you go with check, number of columns is state->includeTupdesc->natts + 1.
Also I'd refactor this
+ /* Form descriptor for INCLUDE columns if any */
+ if (IndexRelationGetNumberOfAttributes(index) > 1)
+ {
+ int i;
+
+ cache->includeTupdesc = CreateTemplateTupleDesc(
+ IndexRelationGetNumberOfAttributes(index) - 1);
+ for (i = 0; i < IndexRelationGetNumberOfAttributes(index) - 1; i++)
+ {
+ TupleDescInitEntry(cache->includeTupdesc, i + 1, NULL,
+ TupleDescAttr(index->rd_att, i + 1)->atttypid,
+ -1, 0);
+ }
+ }
+ else
+ cache->includeTupdesc = NULL;
into something like
cache->includeTupdesc = NULL;
for (i = 0; i < IndexRelationGetNumberOfAttributes(index) - 1; i++)
{
if (cache->includeTupdesc == NULL)
// init tuple description
// init entry
}
But, probably it's only a matter of taste.
Beside this, I think patch is ready for committer. If Anastasia has no objections, let's flip CF entry state.
Thanks!
Best regards, Andrey Borodin.
I have a wild idea of renaming nextOffset in SpGistLeafTupleData.
Or at least documenting in comments that this field is more than just an offset.
Seems reasonable as previous changes localized mentions of nextOffset only to leaf tuple definition and access macros. So I've done this renaming.
This looks like assert rather than real runtime check in spgLeafTupleSize()
+ if (state->includeTupdesc->natts + 1 >= INDEX_MAX_KEYS)
+ ereport(ERROR,
+ (errcode(ERRCODE_TOO_MANY_COLUMNS),
+ errmsg("number of index columns (%d) exceeds limit (%d)",
+ state->includeTupdesc->natts, INDEX_MAX_KEYS)));
Even if you go with check, number of columns is state->includeTupdesc->natts + 1.
I placed this check only once on SpGist state creation and replaced the other checks to asserts.
Also I'd refactor this
+ /* Form descriptor for INCLUDE columns if any */
Also done. Thanks a lot!
See v10.
Attachment
Pavel Borisov <pashkin.elfe@gmail.com> writes:
> [ v10-0001-Covering-SP-GiST-index-support-for-INCLUDE-colum.patch ]
I've started to review this, and I've got to say that I really disagree
with this choice:
+ * If there are INCLUDE columns, they are stored after a key value, each
+ * starting from its own typalign boundary. Unlike IndexTuple, first INCLUDE
+ * value does not need to start from MAXALIGN boundary, so SPGiST uses private
+ * routines to access them.
This seems to require far more new code than it could possibly be worth,
because most of the time anything you could save here is just going
to disappear into end-of-tuple alignment space anyway -- recall that
the overall index tuple length is going to be MAXALIGN'd no matter what.
I think you should yank this out and try to rely on standard tuple
construction/deconstruction code instead.
I also find it unacceptable that you stuck a tuple descriptor pointer into
the rd_amcache structure. The relcache only supports that being a flat
blob of memory. I see that you tried to hack around that by having
spgGetCache reconstruct a new tupdesc every time through, but (a) that's
actually worse than having no cache at all, and (b) spgGetCache doesn't
really know much about the longevity of the memory context it's called in.
This could easily lead to dangling tuple pointers, serious memory bloat
from repeated tupdesc construction, or quite possibly both. Safer would
be to build the tupdesc during initSpGistState(), or maybe just make it
on-demand. In view of the previous point, I'm also wondering if there's
any way to get the relcache's regular rd_att tupdesc to be useful here,
so we don't have to build one during scans at all.
(I wondered for a bit about whether you could keep a long-lived private
tupdesc in the relcache's rd_indexcxt context. But it looks like
relcache.c sometimes resets rd_amcache without also clearing the
rd_indexcxt, so that would probably lead to leakage.)
regards, tom lane
I've started to review this, and I've got to say that I really disagree
with this choice:
+ * If there are INCLUDE columns, they are stored after a key value, each
+ * starting from its own typalign boundary. Unlike IndexTuple, first INCLUDE
+ * value does not need to start from MAXALIGN boundary, so SPGiST uses private
+ * routines to access them.
This seems to require far more new code than it could possibly be worth,
because most of the time anything you could save here is just going
to disappear into end-of-tuple alignment space anyway -- recall that
the overall index tuple length is going to be MAXALIGN'd no matter what.
I think you should yank this out and try to rely on standard tuple
construction/deconstruction code instead.
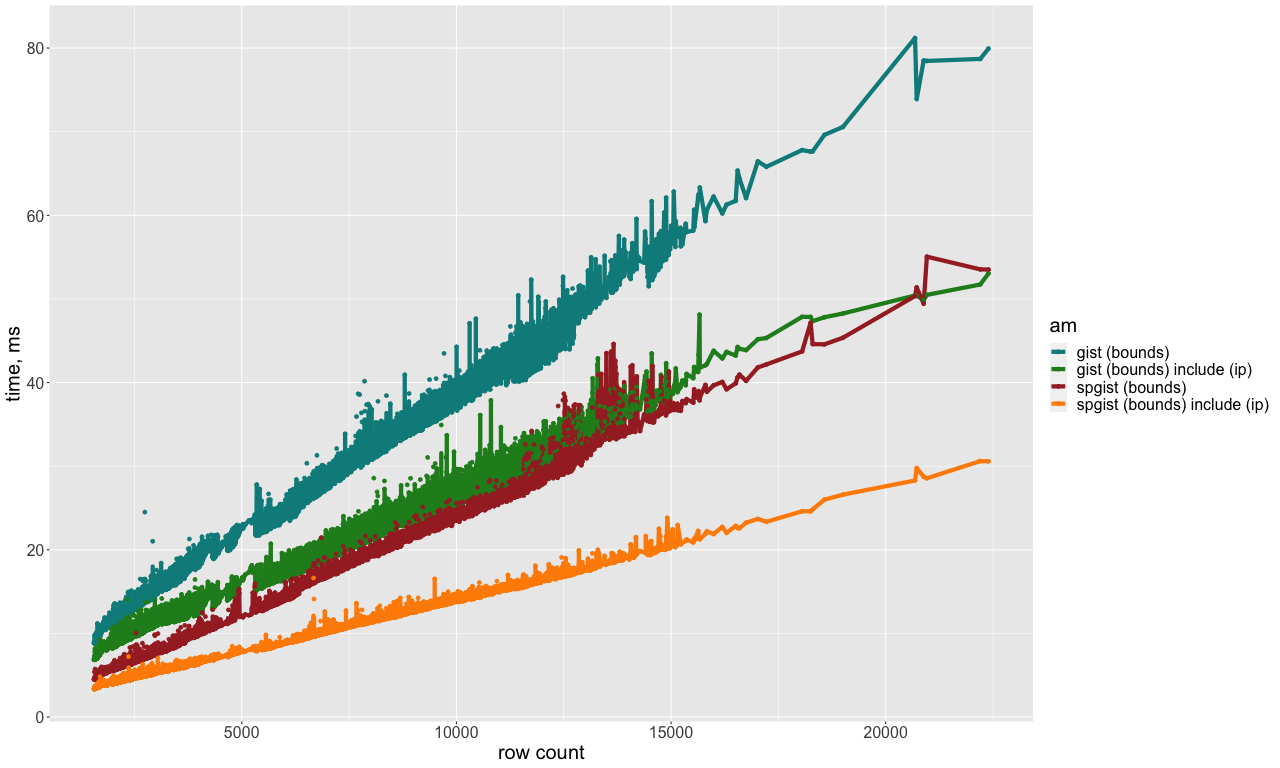
I'd say that much of the SELECT performance gain of SP-GiST over GiST is due to its lightweight pages, each containing more tuples so we can have less page fetches. And this is the main goal of having lightweight tuples.
PFA my performance measurements for box+cidr selects, with gist and spgist indexes built on box key-column and cidr (optionally) include column.
The way that seems acceptable to me is to add (optional) nulls mask into the end of existing style SpGistLeafTuple header and use indextuple routines to attach attributes after it. In this case, we can reduce the amount of code at the cost of adding one extra MAXALIGN size to the overall tuple size on 32-bit arch as now tuple header size of 12 bit already fits 3 MAXALIGNS (on 64 bit the header now is shorter than 2 maxaligns (12 bytes of 16) and nulls mask will be free of cost). If you mean this I try to make changes soon. What do you think of it?
I also find it unacceptable that you stuck a tuple descriptor pointer into
the rd_amcache structure. The relcache only supports that being a flat
blob of memory. I see that you tried to hack around that by having
spgGetCache reconstruct a new tupdesc every time through, but (a) that's
actually worse than having no cache at all, and (b) spgGetCache doesn't
really know much about the longevity of the memory context it's called in.
This could easily lead to dangling tuple pointers, serious memory bloat
from repeated tupdesc construction, or quite possibly both. Safer would
be to build the tupdesc during initSpGistState(), or maybe just make it
on-demand. In view of the previous point, I'm also wondering if there's
any way to get the relcache's regular rd_att tupdesc to be useful here,
so we don't have to build one during scans at all.
(I wondered for a bit about whether you could keep a long-lived private
tupdesc in the relcache's rd_indexcxt context. But it looks like
relcache.c sometimes resets rd_amcache without also clearing the
rd_indexcxt, so that would probably lead to leakage.)
I will consider this for sure, thanks.
Attachment
{kind=link}
вт, 17 нояб. 2020 г. в 11:36, Pavel Borisov <pashkin.elfe@gmail.com>:
I've started to review this, and I've got to say that I really disagree
with this choice:
+ * If there are INCLUDE columns, they are stored after a key value, each
+ * starting from its own typalign boundary. Unlike IndexTuple, first INCLUDE
+ * value does not need to start from MAXALIGN boundary, so SPGiST uses private
+ * routines to access them.
Tom, I took a stab at making the code for tuple creation/decomposition more optimal. Now I see several options for this:
1. Included values can be added after key value as a whole index tuple. Pro of this: it reuses existing code perfectly. Con is that it will introduce extra (empty) index tuple header.
2. Existing state: pro is that in my opinion, it has the least possible gaps. The con is the need to duplicate much of the existing code with some modification. Frankly I don't like this duplication very much even if it is only a private spgist code.
2A. Existing state can be shifted into fewer changes in index_form_tuple and index_deform_tuple if I shift the null mask after the tuple header and before the key value (SpGistTupleHeader+nullmask chunk will be maxaligned). This is what I proposed in the previous answer. I tried to work on this variant but it will need to duplicate index_form_tuple and index_deform_tuple code into private version. The reason is that spgist tuple has its own header of different size and in my understanding, it can not be incorporated using index_form_tuple.
3. I can split index_form_tuple into two parts: a) header adding and size calculation, b) filling attributes. External (a), which could be constructed differently for SpGist, and internal (b) being universal.
3A. I can make index_form_tuple accept pointer as an argument to create tuple in already palloced memory area (with the shift to its start). So external caller will be able to incorporate headers after calling index_form_tuple routine.
Maybe there is some other way I don't imagine yet. Which way do you think for me better to follow? What is your advice?
I also find it unacceptable that you stuck a tuple descriptor pointer into
the rd_amcache structure. The relcache only supports that being a flat
blob of memory. I see that you tried to hack around that by having
spgGetCache reconstruct a new tupdesc every time through, but (a) that's
actually worse than having no cache at all, and (b) spgGetCache doesn't
really know much about the longevity of the memory context it's called in.
This could easily lead to dangling tuple pointers, serious memory bloat
from repeated tupdesc construction, or quite possibly both. Safer would
be to build the tupdesc during initSpGistState(), or maybe just make it
on-demand. In view of the previous point, I'm also wondering if there's
any way to get the relcache's regular rd_att tupdesc to be useful here,
so we don't have to build one during scans at all.
I see that FormData_pg_attribute's inside TupleDescData are situated in a single memory chunk. If I add it at the ending of allocated SpGistCache as a copy of this chunk (using memcpy), not a pointer to it as it is now, will it be safe for use?
Or maybe it would still bel better to initialize tuple descriptor any time initSpGistState called without trying to cache it?
What will you advise?
Pavel Borisov <pashkin.elfe@gmail.com> writes:
> The way that seems acceptable to me is to add (optional) nulls mask into
> the end of existing style SpGistLeafTuple header and use indextuple
> routines to attach attributes after it. In this case, we can reduce the
> amount of code at the cost of adding one extra MAXALIGN size to the overall
> tuple size on 32-bit arch as now tuple header size of 12 bit already fits 3
> MAXALIGNS (on 64 bit the header now is shorter than 2 maxaligns (12 bytes
> of 16) and nulls mask will be free of cost). If you mean this I try to make
> changes soon. What do you think of it?
Yeah, that was pretty much the same conclusion I came to. For
INDEX_MAX_KEYS values up to 32, the nulls bitmap will fit into what's
now padding space on 64-bit machines. For backwards compatibility,
we'd have to be careful that the code knows there's no nulls bitmap in
an index without included columns, so I'm not sure how messy that will
be. But it's worth trying that way to see how it comes out.
regards, tom lane
> The way that seems acceptable to me is to add (optional) nulls mask into
> the end of existing style SpGistLeafTuple header and use indextuple
> routines to attach attributes after it. In this case, we can reduce the
> amount of code at the cost of adding one extra MAXALIGN size to the overall
> tuple size on 32-bit arch as now tuple header size of 12 bit already fits 3
> MAXALIGNS (on 64 bit the header now is shorter than 2 maxaligns (12 bytes
> of 16) and nulls mask will be free of cost). If you mean this I try to make
> changes soon. What do you think of it?
Yeah, that was pretty much the same conclusion I came to. For
INDEX_MAX_KEYS values up to 32, the nulls bitmap will fit into what's
now padding space on 64-bit machines. For backwards compatibility,
we'd have to be careful that the code knows there's no nulls bitmap in
an index without included columns, so I'm not sure how messy that will
be. But it's worth trying that way to see how it comes out.
I made a refactoring of the patch code according to the discussion:
1. Changed a leaf tuple format to: header - (optional) bitmask - key value - (optional) INCLUDE values
2. Re-use existing code of heap_fill_tuple() to fill data part of a leaf tuple
3. Splitted index_deform_tuple() into two portions: (a) bigger 'inner' one - index_deform_anyheader_tuple() - to make processing of index-like tuples (now IndexTuple and SpGistLeafTuple) working independent from type of tuple header. (b) a small 'outer' index_deform_tuple() and spgDeformLeafTuple() to make all header-specific processing and then call the inner (a)
4. Inserted a tuple descriptor into the SpGistCache chunk of memory. So cleaning the cached chunk will also invalidate the tuple descriptor and not make it dangling or leaked. This also allows not to build it every time unless the cache is invalidated.
5. Corrected amroutine->amcaninclude according to new upstream fix.
6. Returned big chunks that were shifted in spgist_private.h to their initial places where possible and made other cosmetic changes to improve the patch.
PFA v.11 of the patch.
Do you think the proposed changes are in the right direction?
Thank you!
--
Attachment
I've noticed CI error due to the fact that MSVC doesn't allow arrays of flexible size arrays and made a fix for the issue.
Also did some minor refinement in tuple creation.
PFA v12 of a patch.
чт, 26 нояб. 2020 г. в 21:48, Pavel Borisov <pashkin.elfe@gmail.com>:
> The way that seems acceptable to me is to add (optional) nulls mask into
> the end of existing style SpGistLeafTuple header and use indextuple
> routines to attach attributes after it. In this case, we can reduce the
> amount of code at the cost of adding one extra MAXALIGN size to the overall
> tuple size on 32-bit arch as now tuple header size of 12 bit already fits 3
> MAXALIGNS (on 64 bit the header now is shorter than 2 maxaligns (12 bytes
> of 16) and nulls mask will be free of cost). If you mean this I try to make
> changes soon. What do you think of it?
Yeah, that was pretty much the same conclusion I came to. For
INDEX_MAX_KEYS values up to 32, the nulls bitmap will fit into what's
now padding space on 64-bit machines. For backwards compatibility,
we'd have to be careful that the code knows there's no nulls bitmap in
an index without included columns, so I'm not sure how messy that will
be. But it's worth trying that way to see how it comes out.I made a refactoring of the patch code according to the discussion:1. Changed a leaf tuple format to: header - (optional) bitmask - key value - (optional) INCLUDE values2. Re-use existing code of heap_fill_tuple() to fill data part of a leaf tuple3. Splitted index_deform_tuple() into two portions: (a) bigger 'inner' one - index_deform_anyheader_tuple() - to make processing of index-like tuples (now IndexTuple and SpGistLeafTuple) working independent from type of tuple header. (b) a small 'outer' index_deform_tuple() and spgDeformLeafTuple() to make all header-specific processing and then call the inner (a)4. Inserted a tuple descriptor into the SpGistCache chunk of memory. So cleaning the cached chunk will also invalidate the tuple descriptor and not make it dangling or leaked. This also allows not to build it every time unless the cache is invalidated.5. Corrected amroutine->amcaninclude according to new upstream fix.6. Returned big chunks that were shifted in spgist_private.h to their initial places where possible and made other cosmetic changes to improve the patch.PFA v.11 of the patch.Do you think the proposed changes are in the right direction?Thank you!--
Attachment
Pavel Borisov <pashkin.elfe@gmail.com> writes:
> I've noticed CI error due to the fact that MSVC doesn't allow arrays of
> flexible size arrays and made a fix for the issue.
> Also did some minor refinement in tuple creation.
> PFA v12 of a patch.
The cfbot's still unhappy --- looks like you omitted a file from the
patch?
regards, tom lane
The cfbot's still unhappy --- looks like you omitted a file from the
patch?
You are right, thank you. Corrected this. PFA v13
Attachment
On further contemplation, it occurs to me that if we make the switch
to "key values are stored per normal rules", then even if there is an
index with pass-by-value keys out there someplace, it would only break
on big-endian architectures. On little-endian, the extra space
occupied by the Datum format would just seem to be padding space.
So this probably means that the theoretical compatibility hazard is
small enough to be negligible, and we should go with my option #2
(i.e., we need to replace SGLTDATUM with normal attribute-fetch logic).
regards, tom lane
I am sorry for the delay in reply. Now I've returned to the work on the patch.
-- First of all big thanks for good pieces of advice. I especially liked the idea of not allocating a big array in a picksplit procedure and doing deform and form tuples on the fly.
I found all notes mentioned are quite worth integrating into the patch, and have made the next version of a patch (with a pgindent done also). PFA v 14.
I hope I understand the way to modify SGLTDATUM in the right way. If not please let me know. (The macro SGLTDATUM itself is not removed, it calls fetch_att. And I find this suitable as the address for the first tuple attribute is MAXALIGNed).
Thanks again for your consideration. From now I hope to be able to work on the feature with not so big delay.
Attachment
In a v14 I forgot to add the test. PFA v15
--
Attachment
Pavel Borisov <pashkin.elfe@gmail.com> writes:
> In a v14 I forgot to add the test. PFA v15
I've committed this with a lot of mostly-cosmetic changes.
The not-so-cosmetic bits had to do with confusion between
the input data type and the leaf type, which isn't really
your fault because it was there before :-(.
One note is that I dropped the added regression test script
(index_including_spgist.sql) entirely, because I couldn't
see that it did anything that justified a permanent expenditure
of test cycles. It looks like you made that by doing s/gist/spgist/g
on index_including_gist.sql, which might be all right except that
that script was designed to test GiST-specific implementation concerns
that aren't too relevant to SP-GiST. AFAICT, removing that script had
exactly zero effect on the test coverage shown by gcov. There are
certainly bits of spgist that are depressingly under-covered, but I'm
afraid we need custom-designed test cases to get at them.
(wanders away wondering if the isolationtester could be used to test
the concurrency-sensitive parts of spgvacuum.c ...)
regards, tom lane
I've committed this with a lot of mostly-cosmetic changes.
The not-so-cosmetic bits had to do with confusion between
the input data type and the leaf type, which isn't really
your fault because it was there before :-(.
One note is that I dropped the added regression test script
(index_including_spgist.sql) entirely, because I couldn't
see that it did anything that justified a permanent expenditure
of test cycles. It looks like you made that by doing s/gist/spgist/g
on index_including_gist.sql, which might be all right except that
that script was designed to test GiST-specific implementation concerns
that aren't too relevant to SP-GiST. AFAICT, removing that script had
exactly zero effect on the test coverage shown by gcov. There are
certainly bits of spgist that are depressingly under-covered, but I'm
afraid we need custom-designed test cases to get at them.
(wanders away wondering if the isolationtester could be used to test
the concurrency-sensitive parts of spgvacuum.c ...)
regards, tom lane
Thanks a lot!
As for tests I mostly checked the storage and reconstruction of included attributes in the spgist index with radix and quadtree, with many included columns of different types and nulls among the values. But I consider it too big for regression. I attach radix test just in case. Do you consider something like this could be useful for testing and should I try to adapt something like this to make regression? Or do something like this on some database already in the regression suite?