Thread: Parallel Full Hash Join
Hello, While thinking about looping hash joins (an alternative strategy for limiting hash join memory usage currently being investigated by Melanie Plageman in a nearby thread[1]), the topic of parallel query deadlock hazards came back to haunt me. I wanted to illustrate the problems I'm aware of with the concrete code where I ran into this stuff, so here is a new-but-still-broken implementation of $SUBJECT. This was removed from the original PHJ submission when I got stuck and ran out of time in the release cycle for 11. Since the original discussion is buried in long threads and some of it was also a bit confused, here's a fresh description of the problems as I see them. Hopefully these thoughts might help Melanie's project move forward, because it's closely related, but I didn't want to dump another patch into that other thread. Hence this new thread. I haven't succeeded in actually observing a deadlock with the attached patch (though I did last year, very rarely), but I also haven't tried very hard. The patch seems to produce the right answers and is pretty scalable, so it's really frustrating not to be able to get it over the line. Tuple queue deadlock hazard: If the leader process is executing the subplan itself and waiting for all processes to arrive in ExecParallelHashEndProbe() (in this patch) while another process has filled up its tuple queue and is waiting for the leader to read some tuples an unblock it, they will deadlock forever. That can't happen in the the committed version of PHJ, because it never waits for barriers after it has begun emitting tuples. Some possible ways to fix this: 1. You could probably make it so that the PHJ_BATCH_SCAN_INNER phase in this patch (the scan for unmatched tuples) is executed by only one process, using the "detach-and-see-if-you-were-last" trick. Melanie proposed that for an equivalent problem in the looping hash join. I think it probably works, but it gives up a lot of parallelism and thus won't scale as nicely as the attached patch. 2. You could probably make it so that only the leader process drops out of executing the inner unmatched scan, and then I think you wouldn't have this very specific problem at the cost of losing some (but not all) parallelism (ie the leader), but there might be other variants of the problem. For example, a GatherMerge leader process might be blocked waiting for the next tuple for a tuple from P1, while P2 is try to write to a full queue, and P1 waits for P2. 3. You could introduce some kind of overflow for tuple queues, so that tuple queues can never block because they're full (until you run out of extra memory buffers or disk and error out). I haven't seriously looked into this but I'm starting to suspect it's the industrial strength general solution to the problem and variants of it that show up in other parallelism projects (Parallel Repartition). As Robert mentioned last time I talked about this[2], you'd probably only want to allow spooling (rather than waiting) when the leader is actually waiting for other processes; I'm not sure how exactly to control that. 4. <thinking-really-big>Goetz Graefe's writing about parallel sorting comes close to this topic, which he calls flow control deadlocks. He mentions the possibility of infinite spooling like (3) as a solution. He's describing a world where producers and consumers are running concurrently, and the consumer doesn't just decide to start running the subplan (what we call "leader participation"), so he doesn't actually have a problem like Gather deadlock. He describes planner-enforced rules that allow deadlock free execution even with fixed-size tuple queue flow control by careful controlling where order-forcing operators are allowed to appear, so he doesn't have a problem like Gather Merge deadlock. I'm not proposing we should create a whole bunch of producer and consumer processes to run different plan fragments, but I think you can virtualise the general idea in an async executor with "streams", and that also solves other problems when you start working with partitions in a world where it's not even sure how many workers will show up. I see this as a long term architectural goal requiring vast amounts of energy to achieve, hence my new interest in (3) for now.</thinking-really-big> Hypothetical inter-node deadlock hazard: Right now I think it is the case the whenever any node begins pulling tuples from a subplan, it continues to do so until either the query ends early or the subplan runs out of tuples. For example, Append processes its subplans one at a time until they're done -- it doesn't jump back and forth. Parallel Append doesn't necessarily run them in the order that they appear in the plan, but it still runs each one to completion before picking another one. If we ever had a node that didn't adhere to that rule, then two Parallel Full Hash Join nodes could dead lock, if some of the workers were stuck waiting in one while some were stuck waiting in the other. If we were happy to decree that that is a rule of the current PostgreSQL executor, then this hypothetical problem would go away. For example, consider the old patch I recently rebased[3] to allow Append over a bunch of FDWs representing remote shards to return tuples as soon as they're ready, not necessarily sequentially (and I think several others have worked on similar patches). To be committable under such a rule that applies globally to the whole executor, that patch would only be allowed to *start* them in any order, but once it's started pulling tuples from a given subplan it'd have to pull them all to completion before considering another node. (Again, that problem goes away in an async model like (4), which will also be able to do much more interesting things with FDWs, and it's the FDW thing that I think generates more interest in async execution than my rambling about abstract parallel query problems.) Some other notes on the patch: Aside from the deadlock problem, there are some minor details to tidy up (handling of late starters probably not quite right, rescans not yet considered). There is a fun hard-coded parameter that controls the parallel step size in terms of cache lines for the unmatched scan; I found that 8 was a lot faster than 4, but no slower than 128 on my laptop, so I set it to 8. More thoughts along those micro-optimistic lines: instead of match bit in the header, you could tag the pointer and sometimes avoid having to follow it, and you could prefetch next non-matching tuple's cacheline by looking a head a bit. [1] https://www.postgresql.org/message-id/flat/CA%2BhUKGKWWmf%3DWELLG%3DaUGbcugRaSQbtm0tKYiBut-B2rVKX63g%40mail.gmail.com [2] https://www.postgresql.org/message-id/CA%2BTgmoY4LogYcg1y5JPtto_fL-DBUqvxRiZRndDC70iFiVsVFQ%40mail.gmail.com [3] https://www.postgresql.org/message-id/flat/CA%2BhUKGLBRyu0rHrDCMC4%3DRn3252gogyp1SjOgG8SEKKZv%3DFwfQ%40mail.gmail.com -- Thomas Munro https://enterprisedb.com
Attachment
On Wed, Sep 11, 2019 at 11:23 PM Thomas Munro <thomas.munro@gmail.com> wrote:
While thinking about looping hash joins (an alternative strategy for
limiting hash join memory usage currently being investigated by
Melanie Plageman in a nearby thread[1]), the topic of parallel query
deadlock hazards came back to haunt me. I wanted to illustrate the
problems I'm aware of with the concrete code where I ran into this
stuff, so here is a new-but-still-broken implementation of $SUBJECT.
This was removed from the original PHJ submission when I got stuck and
ran out of time in the release cycle for 11. Since the original
discussion is buried in long threads and some of it was also a bit
confused, here's a fresh description of the problems as I see them.
Hopefully these thoughts might help Melanie's project move forward,
because it's closely related, but I didn't want to dump another patch
into that other thread. Hence this new thread.
I haven't succeeded in actually observing a deadlock with the attached
patch (though I did last year, very rarely), but I also haven't tried
very hard. The patch seems to produce the right answers and is pretty
scalable, so it's really frustrating not to be able to get it over the
line.
Tuple queue deadlock hazard:
If the leader process is executing the subplan itself and waiting for
all processes to arrive in ExecParallelHashEndProbe() (in this patch)
while another process has filled up its tuple queue and is waiting for
the leader to read some tuples an unblock it, they will deadlock
forever. That can't happen in the the committed version of PHJ,
because it never waits for barriers after it has begun emitting
tuples.
Some possible ways to fix this:
1. You could probably make it so that the PHJ_BATCH_SCAN_INNER phase
in this patch (the scan for unmatched tuples) is executed by only one
process, using the "detach-and-see-if-you-were-last" trick. Melanie
proposed that for an equivalent problem in the looping hash join. I
think it probably works, but it gives up a lot of parallelism and thus
won't scale as nicely as the attached patch.
I have attached a patch which implements this
(v1-0001-Parallel-FOJ-ROJ-single-worker-scan-buckets.patch).
For starters, in order to support parallel FOJ and ROJ, I re-enabled
setting the match bit for the tuples in the hashtable which
3e4818e9dd5be294d97c disabled. I did so using the code suggested in [1],
reading the match bit to see if it is already set before setting it.
Then, workers except for the last worker detach after exhausting the
outer side of a batch, leaving one worker to proceed to HJ_FILL_INNER
and do the scan of the hash table and emit unmatched inner tuples.
I have also attached a variant on this patch which I am proposing to
replace it (v1-0001-Parallel-FOJ-ROJ-single-worker-scan-chunks.patch)
which has a new ExecParallelScanHashTableForUnmatched() in which the
single worker doing the unmatched scan scans one HashMemoryChunk at a
time and then frees them as it goes. I thought this might perform better
than the version which uses the buckets because 1) it should do a bit
less pointer chasing and 2) it frees each chunk of the hash table as it
scans it which (maybe) would save a bit of time during
ExecHashTableDetachBatch() when it goes through and frees the hash
table, but, my preliminary tests showed a negligible difference between
this and the version using buckets. I will do a bit more testing,
though.
I tried a few other variants of these patches, including one in which
the workers detach from the batch inside of the batch loading and
probing phase machine, ExecParallelHashJoinNewBatch(). This meant that
all workers transition to HJ_FILL_INNER and then HJ_NEED_NEW_BATCH in
order to detach in the batch phase machine. This, however, involved
adding a lot of new variables to distinguish whether or or not the
unmatched outer scan was already done, whether or not the current worker
was the worker elected to do the scan, etc. Overall, it is probably
incorrect to use the HJ_NEED_NEW_BATCH state in this way. I had
originally tried this to avoid operating on the batch_barrier in the
main hash join state machine. I've found that the more different places
we add code attaching and detaching to the batch_barrier (and other PHJ
barriers, for that matter), the harder it is to debug the code, however,
I think in this case it is required.
(v1-0001-Parallel-FOJ-ROJ-single-worker-scan-buckets.patch).
For starters, in order to support parallel FOJ and ROJ, I re-enabled
setting the match bit for the tuples in the hashtable which
3e4818e9dd5be294d97c disabled. I did so using the code suggested in [1],
reading the match bit to see if it is already set before setting it.
Then, workers except for the last worker detach after exhausting the
outer side of a batch, leaving one worker to proceed to HJ_FILL_INNER
and do the scan of the hash table and emit unmatched inner tuples.
I have also attached a variant on this patch which I am proposing to
replace it (v1-0001-Parallel-FOJ-ROJ-single-worker-scan-chunks.patch)
which has a new ExecParallelScanHashTableForUnmatched() in which the
single worker doing the unmatched scan scans one HashMemoryChunk at a
time and then frees them as it goes. I thought this might perform better
than the version which uses the buckets because 1) it should do a bit
less pointer chasing and 2) it frees each chunk of the hash table as it
scans it which (maybe) would save a bit of time during
ExecHashTableDetachBatch() when it goes through and frees the hash
table, but, my preliminary tests showed a negligible difference between
this and the version using buckets. I will do a bit more testing,
though.
I tried a few other variants of these patches, including one in which
the workers detach from the batch inside of the batch loading and
probing phase machine, ExecParallelHashJoinNewBatch(). This meant that
all workers transition to HJ_FILL_INNER and then HJ_NEED_NEW_BATCH in
order to detach in the batch phase machine. This, however, involved
adding a lot of new variables to distinguish whether or or not the
unmatched outer scan was already done, whether or not the current worker
was the worker elected to do the scan, etc. Overall, it is probably
incorrect to use the HJ_NEED_NEW_BATCH state in this way. I had
originally tried this to avoid operating on the batch_barrier in the
main hash join state machine. I've found that the more different places
we add code attaching and detaching to the batch_barrier (and other PHJ
barriers, for that matter), the harder it is to debug the code, however,
I think in this case it is required.
2. You could probably make it so that only the leader process drops
out of executing the inner unmatched scan, and then I think you
wouldn't have this very specific problem at the cost of losing some
(but not all) parallelism (ie the leader), but there might be other
variants of the problem. For example, a GatherMerge leader process
might be blocked waiting for the next tuple for a tuple from P1, while
P2 is try to write to a full queue, and P1 waits for P2.
3. You could introduce some kind of overflow for tuple queues, so
that tuple queues can never block because they're full (until you run
out of extra memory buffers or disk and error out). I haven't
seriously looked into this but I'm starting to suspect it's the
industrial strength general solution to the problem and variants of it
that show up in other parallelism projects (Parallel Repartition). As
Robert mentioned last time I talked about this[2], you'd probably only
want to allow spooling (rather than waiting) when the leader is
actually waiting for other processes; I'm not sure how exactly to
control that.
4. <thinking-really-big>Goetz Graefe's writing about parallel sorting
comes close to this topic, which he calls flow control deadlocks. He
mentions the possibility of infinite spooling like (3) as a solution.
He's describing a world where producers and consumers are running
concurrently, and the consumer doesn't just decide to start running
the subplan (what we call "leader participation"), so he doesn't
actually have a problem like Gather deadlock. He describes
planner-enforced rules that allow deadlock free execution even with
fixed-size tuple queue flow control by careful controlling where
order-forcing operators are allowed to appear, so he doesn't have a
problem like Gather Merge deadlock. I'm not proposing we should
create a whole bunch of producer and consumer processes to run
different plan fragments, but I think you can virtualise the general
idea in an async executor with "streams", and that also solves other
problems when you start working with partitions in a world where it's
not even sure how many workers will show up. I see this as a long
term architectural goal requiring vast amounts of energy to achieve,
hence my new interest in (3) for now.</thinking-really-big>
Hypothetical inter-node deadlock hazard:
Right now I think it is the case the whenever any node begins pulling
tuples from a subplan, it continues to do so until either the query
ends early or the subplan runs out of tuples. For example, Append
processes its subplans one at a time until they're done -- it doesn't
jump back and forth. Parallel Append doesn't necessarily run them in
the order that they appear in the plan, but it still runs each one to
completion before picking another one. If we ever had a node that
didn't adhere to that rule, then two Parallel Full Hash Join nodes
could dead lock, if some of the workers were stuck waiting in one
while some were stuck waiting in the other.
If we were happy to decree that that is a rule of the current
PostgreSQL executor, then this hypothetical problem would go away.
For example, consider the old patch I recently rebased[3] to allow
Append over a bunch of FDWs representing remote shards to return
tuples as soon as they're ready, not necessarily sequentially (and I
think several others have worked on similar patches). To be
committable under such a rule that applies globally to the whole
executor, that patch would only be allowed to *start* them in any
order, but once it's started pulling tuples from a given subplan it'd
have to pull them all to completion before considering another node.
(Again, that problem goes away in an async model like (4), which will
also be able to do much more interesting things with FDWs, and it's
the FDW thing that I think generates more interest in async execution
than my rambling about abstract parallel query problems.)
The leader exclusion tactics and the spooling idea don't solve the
execution order deadlock possibility, so, this "all except last detach
and last does unmatched inner scan" seems like the best way to solve
both types of deadlock.
There is another option that could maintain some parallelism for the
unmatched inner scan.
This method is exactly like the "all except last detach and last does
unmatched inner scan" method from the perspective of the main hash join
state machine. The difference is in ExecParallelHashJoinNewBatch(). In
the batch_barrier phase machine, workers loop around looking for batches
that are not done.
In this "detach for now" method, all workers except the last one detach
from a batch after exhausting the outer side. They will mark the batch
they were just working on as "provisionally done" (as opposed to
"done"). The last worker advances the batch_barrier from
PHJ_BATCH_PROBING to PHJ_BATCH_SCAN_INNER.
All detached workers then proceed to HJ_NEED_NEW_BATCH and try to find
another batch to work on. If there are no batches that are neither
"done" or "provisionally done", then the worker will re-attach to
batches that are "provisionally done" and attempt to join in conducting
the unmatched inner scan. Once it finishes its worker there, it will
return to HJ_NEED_NEW_BATCH, enter ExecParallelHashJoinNewBatch() and
mark the batch as "done".
Because the worker detached from the batch, this method solves the tuple
queue flow control deadlock issue--this worker could not be attempting
to emit a tuple while the leader waits at the barrier for it. There is
no waiting at the barrier.
However, it is unclear to me whether or not this method will be at risk
of inter-node deadlock/execution order deadlock. It seems like this is
not more at risk than the existing code is for this issue.
If a worker never returns to the HashJoin after leaving to emit a tuple,
in any of the methods (and in master), the query would not finish
correctly because the workers are attached to the batch_barrier while
emitting tuples and, though they may not wait at this barrier again, the
hashtable is cleaned up by the last participant to detach, and this
would not happen if it doesn't return to the batch phase machine. I'm
not sure if this exhibits the problematic behavior detailed above, but,
if it does, it is not unique to this method.
execution order deadlock possibility, so, this "all except last detach
and last does unmatched inner scan" seems like the best way to solve
both types of deadlock.
There is another option that could maintain some parallelism for the
unmatched inner scan.
This method is exactly like the "all except last detach and last does
unmatched inner scan" method from the perspective of the main hash join
state machine. The difference is in ExecParallelHashJoinNewBatch(). In
the batch_barrier phase machine, workers loop around looking for batches
that are not done.
In this "detach for now" method, all workers except the last one detach
from a batch after exhausting the outer side. They will mark the batch
they were just working on as "provisionally done" (as opposed to
"done"). The last worker advances the batch_barrier from
PHJ_BATCH_PROBING to PHJ_BATCH_SCAN_INNER.
All detached workers then proceed to HJ_NEED_NEW_BATCH and try to find
another batch to work on. If there are no batches that are neither
"done" or "provisionally done", then the worker will re-attach to
batches that are "provisionally done" and attempt to join in conducting
the unmatched inner scan. Once it finishes its worker there, it will
return to HJ_NEED_NEW_BATCH, enter ExecParallelHashJoinNewBatch() and
mark the batch as "done".
Because the worker detached from the batch, this method solves the tuple
queue flow control deadlock issue--this worker could not be attempting
to emit a tuple while the leader waits at the barrier for it. There is
no waiting at the barrier.
However, it is unclear to me whether or not this method will be at risk
of inter-node deadlock/execution order deadlock. It seems like this is
not more at risk than the existing code is for this issue.
If a worker never returns to the HashJoin after leaving to emit a tuple,
in any of the methods (and in master), the query would not finish
correctly because the workers are attached to the batch_barrier while
emitting tuples and, though they may not wait at this barrier again, the
hashtable is cleaned up by the last participant to detach, and this
would not happen if it doesn't return to the batch phase machine. I'm
not sure if this exhibits the problematic behavior detailed above, but,
if it does, it is not unique to this method.
Some other notes on the patch:
Aside from the deadlock problem, there are some minor details to tidy
up (handling of late starters probably not quite right, rescans not
yet considered).
These would not be an issue with only one worker doing the scan but
would have to be handled in a potential new parallel-enabled solution
like I suggested above.
would have to be handled in a potential new parallel-enabled solution
like I suggested above.
There is a fun hard-coded parameter that controls
the parallel step size in terms of cache lines for the unmatched scan;
I found that 8 was a lot faster than 4, but no slower than 128 on my
laptop, so I set it to 8.
I didn't add this cache line optimization to my chunk scanning method. I
could do so. Do you think it is more relevant, less relevant, or the
same if only one worker is doing the unmatched inner scan?
could do so. Do you think it is more relevant, less relevant, or the
same if only one worker is doing the unmatched inner scan?
More thoughts along those micro-optimistic
lines: instead of match bit in the header, you could tag the pointer
and sometimes avoid having to follow it, and you could prefetch next
non-matching tuple's cacheline by looking a head a bit.
I would be happy to try doing this once we get the rest of the patch
ironed out so that seeing how much of a performance difference it makes
is more straightforward.
ironed out so that seeing how much of a performance difference it makes
is more straightforward.
[1] https://www.postgresql.org/message-id/flat/CA%2BhUKGKWWmf%3DWELLG%3DaUGbcugRaSQbtm0tKYiBut-B2rVKX63g%40mail.gmail.com
[2] https://www.postgresql.org/message-id/CA%2BTgmoY4LogYcg1y5JPtto_fL-DBUqvxRiZRndDC70iFiVsVFQ%40mail.gmail.com
[3] https://www.postgresql.org/message-id/flat/CA%2BhUKGLBRyu0rHrDCMC4%3DRn3252gogyp1SjOgG8SEKKZv%3DFwfQ%40mail.gmail.com
-- Melanie
Attachment
On Tue, Sep 22, 2020 at 8:49 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > On Wed, Sep 11, 2019 at 11:23 PM Thomas Munro <thomas.munro@gmail.com> wrote: >> 1. You could probably make it so that the PHJ_BATCH_SCAN_INNER phase >> in this patch (the scan for unmatched tuples) is executed by only one >> process, using the "detach-and-see-if-you-were-last" trick. Melanie >> proposed that for an equivalent problem in the looping hash join. I >> think it probably works, but it gives up a lot of parallelism and thus >> won't scale as nicely as the attached patch. > > I have attached a patch which implements this > (v1-0001-Parallel-FOJ-ROJ-single-worker-scan-buckets.patch). Hi Melanie, Thanks for working on this! I have a feeling this is going to be much easier to land than the mighty hash loop patch. And it's good to get one of our blocking design questions nailed down for both patches. I took it for a very quick spin and saw simple cases working nicely, but TPC-DS queries 51 and 97 (which contain full joins) couldn't be convinced to use it. Hmm. > For starters, in order to support parallel FOJ and ROJ, I re-enabled > setting the match bit for the tuples in the hashtable which > 3e4818e9dd5be294d97c disabled. I did so using the code suggested in [1], > reading the match bit to see if it is already set before setting it. Cool. I'm quite keen to add a "fill_inner" parameter for ExecHashJoinImpl() and have an N-dimensional lookup table of ExecHashJoin variants, so that this and much other related branching can be constant-folded out of existence by the compiler in common cases, which is why I think this is all fine, but that's for another day... > Then, workers except for the last worker detach after exhausting the > outer side of a batch, leaving one worker to proceed to HJ_FILL_INNER > and do the scan of the hash table and emit unmatched inner tuples. +1 Doing better is pretty complicated within our current execution model, and I think this is a good compromise for now. Costing for uneven distribution is tricky; depending on your plan shape, specifically whether there is something else to do afterwards to pick up the slack, it might or might not affect the total run time of the query. It seems like there's not much we can do about that. > I have also attached a variant on this patch which I am proposing to > replace it (v1-0001-Parallel-FOJ-ROJ-single-worker-scan-chunks.patch) > which has a new ExecParallelScanHashTableForUnmatched() in which the > single worker doing the unmatched scan scans one HashMemoryChunk at a > time and then frees them as it goes. I thought this might perform better > than the version which uses the buckets because 1) it should do a bit > less pointer chasing and 2) it frees each chunk of the hash table as it > scans it which (maybe) would save a bit of time during > ExecHashTableDetachBatch() when it goes through and frees the hash > table, but, my preliminary tests showed a negligible difference between > this and the version using buckets. I will do a bit more testing, > though. +1 I agree that it's the better of those two options. >> [stuff about deadlocks] > > The leader exclusion tactics and the spooling idea don't solve the > execution order deadlock possibility, so, this "all except last detach > and last does unmatched inner scan" seems like the best way to solve > both types of deadlock. Agreed (at least as long as our threads of query execution are made out of C call stacks and OS processes that block). >> Some other notes on the patch: >> >> Aside from the deadlock problem, there are some minor details to tidy >> up (handling of late starters probably not quite right, rescans not >> yet considered). > > These would not be an issue with only one worker doing the scan but > would have to be handled in a potential new parallel-enabled solution > like I suggested above. Makes sense. Not sure why I thought anything special was needed for rescans. >> There is a fun hard-coded parameter that controls >> the parallel step size in terms of cache lines for the unmatched scan; >> I found that 8 was a lot faster than 4, but no slower than 128 on my >> laptop, so I set it to 8. > > I didn't add this cache line optimization to my chunk scanning method. I > could do so. Do you think it is more relevant, less relevant, or the > same if only one worker is doing the unmatched inner scan? Yeah it's irrelevant for a single process, and even more irrelevant if we go with your chunk-based version. >> More thoughts along those micro-optimistic >> lines: instead of match bit in the header, you could tag the pointer >> and sometimes avoid having to follow it, and you could prefetch next >> non-matching tuple's cacheline by looking a head a bit. > > I would be happy to try doing this once we get the rest of the patch > ironed out so that seeing how much of a performance difference it makes > is more straightforward. Ignore that, I have no idea if the maintenance overhead for such an every-tuple-in-this-chain-is-matched tag bit would be worth it, it was just an idle thought. I think your chunk-scan plan seems sensible for now. From a quick peek: +/* + * Upon arriving at the barrier, if this worker is not the last worker attached, + * detach from the barrier and return false. If this worker is the last worker, + * remain attached and advance the phase of the barrier, return true to indicate + * you are the last or "elected" worker who is still attached to the barrier. + * Another name I considered was BarrierUniqueify or BarrierSoloAssign + */ +bool +BarrierDetachOrElect(Barrier *barrier) I tried to find some existing naming in writing about barriers/phasers, but nothing is jumping out at me. I think a lot of this stuff comes from super computing where I guess "make all of the threads give up except one" isn't a primitive they'd be too excited about :-) BarrierArriveAndElectOrDetach()... gah, no. + last = BarrierDetachOrElect(&batch->batch_barrier); I'd be nice to add some assertions after that, in the 'last' path, that there's only one participant and that the phase is as expected, just to make it even clearer to the reader, and a comment in the other path that we are no longer attached. + hjstate->hj_AllocatedBucketRange = 0; ... + pg_atomic_uint32 bucket; /* bucket allocator for unmatched inner scan */ ... + //volatile int mybp = 0; while (mybp == 0) Some leftover fragments of the bucket-scan version and debugging stuff.
On Mon, Sep 21, 2020 at 8:34 PM Thomas Munro <thomas.munro@gmail.com> wrote:
On Tue, Sep 22, 2020 at 8:49 AM Melanie Plageman
<melanieplageman@gmail.com> wrote:
> On Wed, Sep 11, 2019 at 11:23 PM Thomas Munro <thomas.munro@gmail.com> wrote:
I took it for a very quick spin and saw simple cases working nicely,
but TPC-DS queries 51 and 97 (which contain full joins) couldn't be
convinced to use it. Hmm.
Thanks for taking a look, Thomas!
Both query 51 and query 97 have full outer joins of two CTEs, each of
which are aggregate queries.
During planning when constructing the joinrel and choosing paths, in
hash_inner_and_outer(), we don't consider parallel hash parallel hash
join paths because the outerrel and innerrel do not have
partial_pathlists.
This code
if (joinrel->consider_parallel &&
save_jointype != JOIN_UNIQUE_OUTER &&
outerrel->partial_pathlist != NIL &&
bms_is_empty(joinrel->lateral_relids))
gates the code to generate partial paths for hash join.
My understanding of this is that if the inner and outerrel don't have
partial paths, then they can't be executed in parallel, so the join
could not be executed in parallel.
For the two TPC-DS queries, even if they use parallel aggs, the finalize
agg will have to be done by a single worker, so I don't think they could
be joined with a parallel hash join.
I added some logging inside the "if" statement and ran join_hash.sql in
regress to see what nodes were typically in the pathlist and partial
pathlist. All of them had basically just sequential scans as the outer
and inner rel paths. regress examples are definitely meant to be
minimal, so this probably wasn't the best place to look for examples of
more complex rels that can be joined with a parallel hash join.
Both query 51 and query 97 have full outer joins of two CTEs, each of
which are aggregate queries.
During planning when constructing the joinrel and choosing paths, in
hash_inner_and_outer(), we don't consider parallel hash parallel hash
join paths because the outerrel and innerrel do not have
partial_pathlists.
This code
if (joinrel->consider_parallel &&
save_jointype != JOIN_UNIQUE_OUTER &&
outerrel->partial_pathlist != NIL &&
bms_is_empty(joinrel->lateral_relids))
gates the code to generate partial paths for hash join.
My understanding of this is that if the inner and outerrel don't have
partial paths, then they can't be executed in parallel, so the join
could not be executed in parallel.
For the two TPC-DS queries, even if they use parallel aggs, the finalize
agg will have to be done by a single worker, so I don't think they could
be joined with a parallel hash join.
I added some logging inside the "if" statement and ran join_hash.sql in
regress to see what nodes were typically in the pathlist and partial
pathlist. All of them had basically just sequential scans as the outer
and inner rel paths. regress examples are definitely meant to be
minimal, so this probably wasn't the best place to look for examples of
more complex rels that can be joined with a parallel hash join.
>> Some other notes on the patch:
From a quick peek:
+/*
+ * Upon arriving at the barrier, if this worker is not the last
worker attached,
+ * detach from the barrier and return false. If this worker is the last worker,
+ * remain attached and advance the phase of the barrier, return true
to indicate
+ * you are the last or "elected" worker who is still attached to the barrier.
+ * Another name I considered was BarrierUniqueify or BarrierSoloAssign
+ */
+bool
+BarrierDetachOrElect(Barrier *barrier)
I tried to find some existing naming in writing about
barriers/phasers, but nothing is jumping out at me. I think a lot of
this stuff comes from super computing where I guess "make all of the
threads give up except one" isn't a primitive they'd be too excited
about :-)
BarrierArriveAndElectOrDetach()... gah, no.
You're right that Arrive should be in there.
So, I went with BarrierArriveAndDetachExceptLast()
It's specific, if not clever.
+ last = BarrierDetachOrElect(&batch->batch_barrier);
I'd be nice to add some assertions after that, in the 'last' path,
that there's only one participant and that the phase is as expected,
just to make it even clearer to the reader, and a comment in the other
path that we are no longer attached.
Assert and comment added to the single worker path.
The other path is just back to HJ_NEED_NEW_BATCH and workers will detach
there as before, so I'm not sure where we could add the comment about
the other workers detaching.
The other path is just back to HJ_NEED_NEW_BATCH and workers will detach
there as before, so I'm not sure where we could add the comment about
the other workers detaching.
+ hjstate->hj_AllocatedBucketRange = 0;
...
+ pg_atomic_uint32 bucket; /* bucket allocator for unmatched inner scan */
...
+ //volatile int mybp = 0; while (mybp == 0)
Some leftover fragments of the bucket-scan version and debugging stuff.
cleaned up (and rebased).
I also changed ExecScanHashTableForUnmatched() to scan HashMemoryChunks
in the hashtable instead of using the buckets to align parallel and
serial hash join code.
Originally, I had that code freeing the chunks of the hashtable after
finishing scanning them, however, I noticed this query from regress
failing:
select * from
(values (1, array[10,20]), (2, array[20,30])) as v1(v1x,v1ys)
left join (values (1, 10), (2, 20)) as v2(v2x,v2y) on v2x = v1x
left join unnest(v1ys) as u1(u1y) on u1y = v2y;
It is because the hash join gets rescanned and because there is only one
batch, ExecReScanHashJoin reuses the same hashtable.
QUERY PLAN
-------------------------------------------------------------
Nested Loop Left Join
-> Values Scan on "*VALUES*"
-> Hash Right Join
Hash Cond: (u1.u1y = "*VALUES*_1".column2)
Filter: ("*VALUES*_1".column1 = "*VALUES*".column1)
-> Function Scan on unnest u1
-> Hash
-> Values Scan on "*VALUES*_1"
I was freeing the hashtable as I scanned each chunk, which clearly
doesn't work for a single batch hash join which gets rescanned.
I don't see anything specific to parallel hash join in ExecReScanHashJoin(),
so, it seems like the same rules apply to parallel hash join. So, I will
have to remove the logic that frees the hash table after scanning each
chunk from the parallel function as well.
in the hashtable instead of using the buckets to align parallel and
serial hash join code.
Originally, I had that code freeing the chunks of the hashtable after
finishing scanning them, however, I noticed this query from regress
failing:
select * from
(values (1, array[10,20]), (2, array[20,30])) as v1(v1x,v1ys)
left join (values (1, 10), (2, 20)) as v2(v2x,v2y) on v2x = v1x
left join unnest(v1ys) as u1(u1y) on u1y = v2y;
It is because the hash join gets rescanned and because there is only one
batch, ExecReScanHashJoin reuses the same hashtable.
QUERY PLAN
-------------------------------------------------------------
Nested Loop Left Join
-> Values Scan on "*VALUES*"
-> Hash Right Join
Hash Cond: (u1.u1y = "*VALUES*_1".column2)
Filter: ("*VALUES*_1".column1 = "*VALUES*".column1)
-> Function Scan on unnest u1
-> Hash
-> Values Scan on "*VALUES*_1"
I was freeing the hashtable as I scanned each chunk, which clearly
doesn't work for a single batch hash join which gets rescanned.
I don't see anything specific to parallel hash join in ExecReScanHashJoin(),
so, it seems like the same rules apply to parallel hash join. So, I will
have to remove the logic that frees the hash table after scanning each
chunk from the parallel function as well.
(refine the comments and variable names and such) but just wanted to
check that these changes were in line with what you were thinking first.
Regards,
Melanie (Microsoft)
Attachment
I've attached a patch with the corrections I mentioned upthread.
I've gone ahead and run pgindent, though, I can't say that I'm very
happy with the result.
I'm still not quite happy with the name
BarrierArriveAndDetachExceptLast(). It's so literal. As you said, there
probably isn't a nice name for this concept, since it is a function with
the purpose of terminating parallelism.
Regards,
Melanie (Microsoft)
I've gone ahead and run pgindent, though, I can't say that I'm very
happy with the result.
I'm still not quite happy with the name
BarrierArriveAndDetachExceptLast(). It's so literal. As you said, there
probably isn't a nice name for this concept, since it is a function with
the purpose of terminating parallelism.
Regards,
Melanie (Microsoft)
Attachment
Hi Melanie, On Thu, Nov 5, 2020 at 7:34 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > > I've attached a patch with the corrections I mentioned upthread. > I've gone ahead and run pgindent, though, I can't say that I'm very > happy with the result. > > I'm still not quite happy with the name > BarrierArriveAndDetachExceptLast(). It's so literal. As you said, there > probably isn't a nice name for this concept, since it is a function with > the purpose of terminating parallelism. You sent in your patch, v3-0001-Support-Parallel-FOJ-and-ROJ.patch to pgsql-hackers on Nov 5, but you did not post it to the next CommitFest[1]. If this was intentional, then you need to take no action. However, if you want your patch to be reviewed as part of the upcoming CommitFest, then you need to add it yourself before 2021-01-01 AOE[2]. Also, rebasing to the current HEAD may be required as almost two months passed since when this patch is submitted. Thanks for your contributions. Regards, [1] https://commitfest.postgresql.org/31/ [2] https://en.wikipedia.org/wiki/Anywhere_on_Earth Regards, -- Masahiko Sawada EnterpriseDB: https://www.enterprisedb.com/
On Mon, Dec 28, 2020 at 9:49 PM Masahiko Sawada <sawada.mshk@gmail.com> wrote: > On Thu, Nov 5, 2020 at 7:34 AM Melanie Plageman > <melanieplageman@gmail.com> wrote: > > I've attached a patch with the corrections I mentioned upthread. > > I've gone ahead and run pgindent, though, I can't say that I'm very > > happy with the result. > > > > I'm still not quite happy with the name > > BarrierArriveAndDetachExceptLast(). It's so literal. As you said, there > > probably isn't a nice name for this concept, since it is a function with > > the purpose of terminating parallelism. > > You sent in your patch, v3-0001-Support-Parallel-FOJ-and-ROJ.patch to > pgsql-hackers on Nov 5, but you did not post it to the next > CommitFest[1]. If this was intentional, then you need to take no > action. However, if you want your patch to be reviewed as part of the > upcoming CommitFest, then you need to add it yourself before > 2021-01-01 AOE[2]. Also, rebasing to the current HEAD may be required > as almost two months passed since when this patch is submitted. Thanks > for your contributions. Thanks for this reminder Sawada-san. I had some feedback I meant to post in November but didn't get around to: +bool +BarrierArriveAndDetachExceptLast(Barrier *barrier) I committed this part (7888b099). I've attached a rebase of the rest of Melanie's v3 patch. + WAIT_EVENT_HASH_BATCH_PROBE, That new wait event isn't needed (we can't and don't wait). * PHJ_BATCH_PROBING -- all probe - * PHJ_BATCH_DONE -- end + + * PHJ_BATCH_DONE -- queries not requiring inner fill done + * PHJ_BATCH_FILL_INNER_DONE -- inner fill completed, all queries done Would it be better/tidier to keep _DONE as the final phase? That is, to switch around these two final phases. Or does that make it too hard to coordinate the detach-and-cleanup logic? +/* + * ExecPrepHashTableForUnmatched + * set up for a series of ExecScanHashTableForUnmatched calls + * return true if this worker is elected to do the unmatched inner scan + */ +bool +ExecParallelPrepHashTableForUnmatched(HashJoinState *hjstate) Comment name doesn't match function name.
Attachment
On Tue, Dec 29, 2020 at 03:28:12PM +1300, Thomas Munro wrote: > I had some feedback I meant to > post in November but didn't get around to: > > * PHJ_BATCH_PROBING -- all probe > - * PHJ_BATCH_DONE -- end > + > + * PHJ_BATCH_DONE -- queries not requiring inner fill done > + * PHJ_BATCH_FILL_INNER_DONE -- inner fill completed, all queries done > > Would it be better/tidier to keep _DONE as the final phase? That is, > to switch around these two final phases. Or does that make it too > hard to coordinate the detach-and-cleanup logic? I updated this to use your suggestion. My rationale for having PHJ_BATCH_DONE and then PHJ_BATCH_FILL_INNER_DONE was that, for a worker attaching to the batch for the first time, it might be confusing that it is in the PHJ_BATCH_FILL_INNER state (not the DONE state) and yet that worker still just detaches and moves on. It didn't seem intuitive. Anyway, I think that is all sort of confusing and unnecessary. I changed it to PHJ_BATCH_FILLING_INNER -- then when a worker who hasn't ever been attached to this batch before attaches, it will be in the PHJ_BATCH_FILLING_INNER phase, which it cannot help with and it will detach and move on. > > +/* > + * ExecPrepHashTableForUnmatched > + * set up for a series of ExecScanHashTableForUnmatched calls > + * return true if this worker is elected to do the > unmatched inner scan > + */ > +bool > +ExecParallelPrepHashTableForUnmatched(HashJoinState *hjstate) > > Comment name doesn't match function name. Updated -- and a few other comment updates too. I just attached the diff.
Attachment
On Fri, Mar 5, 2021 at 8:31 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Tue, Mar 2, 2021 at 11:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Fri, Feb 12, 2021 at 11:02 AM Melanie Plageman > > <melanieplageman@gmail.com> wrote: > > > I just attached the diff. > > > > Squashed into one patch for the cfbot to chew on, with a few minor > > adjustments to a few comments. > > I did some more minor tidying of comments and naming. It's been on my > to-do-list to update some phase names after commit 3048898e, and while > doing that I couldn't resist the opportunity to change DONE to FREE, > which somehow hurts my brain less, and makes much more obvious sense > after the bugfix in CF #3031 that splits DONE into two separate > phases. It also pairs obviously with ALLOCATE. I include a copy of > that bugix here too as 0001, because I'll likely commit that first, so > I rebased the stack of patches that way. 0002 includes the renaming I > propose (master only). Then 0003 is Melanie's patch, using the name > SCAN for the new match bit scan phase. I've attached an updated > version of my "phase diagram" finger painting, to show how it looks > with these three patches. "scan*" is new. Feedback on v6-0002-Improve-the-naming-of-Parallel-Hash-Join-phases.patch I like renaming DONE to FREE and ALLOCATE TO REALLOCATE in the grow barriers. FREE only makes sense for the Build barrier if you keep the added PHJ_BUILD_RUN phase, though, I assume you would change this patch if you decided not to add the new build barrier phase. I like the addition of the asterisks to indicate a phase is executed by a single arbitrary process. I was thinking, shall we add one of these to HJ_FILL_INNER since it is only done by one process in parallel right and full hash join? Maybe that's confusing because serial hash join uses that state machine too, though. Maybe **? Maybe we should invent a complicated symbolic language :) One tiny, random, unimportant thing: The function prototype for ExecParallelHashJoinPartitionOuter() calls its parameter "node" and, in the definition, it is called "hjstate". This feels like a good patch to throw in that tiny random change to make the name the same. static void ExecParallelHashJoinPartitionOuter(HashJoinState *node); static void ExecParallelHashJoinPartitionOuter(HashJoinState *hjstate)
Hi,
For v6-0003-Parallel-Hash-Full-Right-Outer-Join.patch
+ * current_chunk_idx: index in current HashMemoryChunk
The above comment seems to be better fit for ExecScanHashTableForUnmatched(), instead of ExecParallelPrepHashTableForUnmatched.
I wonder where current_chunk_idx should belong (considering the above comment and what the code does).
+ while (hashtable->current_chunk_idx < hashtable->current_chunk->used)
...
+ next = hashtable->current_chunk->next.unshared;
+ hashtable->current_chunk = next;
+ hashtable->current_chunk = next;
+ hashtable->current_chunk_idx = 0;
Each time we advance to the next chunk, current_chunk_idx is reset. It seems current_chunk_idx can be placed inside chunk.
Maybe the consideration is that, with the current formation we save space by putting current_chunk_idx field at a higher level.
If that is the case, a comment should be added.
Cheers
On Fri, Mar 5, 2021 at 5:31 PM Thomas Munro <thomas.munro@gmail.com> wrote:
On Tue, Mar 2, 2021 at 11:27 PM Thomas Munro <thomas.munro@gmail.com> wrote:
> On Fri, Feb 12, 2021 at 11:02 AM Melanie Plageman
> <melanieplageman@gmail.com> wrote:
> > I just attached the diff.
>
> Squashed into one patch for the cfbot to chew on, with a few minor
> adjustments to a few comments.
I did some more minor tidying of comments and naming. It's been on my
to-do-list to update some phase names after commit 3048898e, and while
doing that I couldn't resist the opportunity to change DONE to FREE,
which somehow hurts my brain less, and makes much more obvious sense
after the bugfix in CF #3031 that splits DONE into two separate
phases. It also pairs obviously with ALLOCATE. I include a copy of
that bugix here too as 0001, because I'll likely commit that first, so
I rebased the stack of patches that way. 0002 includes the renaming I
propose (master only). Then 0003 is Melanie's patch, using the name
SCAN for the new match bit scan phase. I've attached an updated
version of my "phase diagram" finger painting, to show how it looks
with these three patches. "scan*" is new.
On Fri, Apr 2, 2021 at 3:06 PM Zhihong Yu <zyu@yugabyte.com> wrote:
>
> Hi,
> For v6-0003-Parallel-Hash-Full-Right-Outer-Join.patch
>
> + * current_chunk_idx: index in current HashMemoryChunk
>
> The above comment seems to be better fit for ExecScanHashTableForUnmatched(), instead of
ExecParallelPrepHashTableForUnmatched.
> I wonder where current_chunk_idx should belong (considering the above comment and what the code does).
>
> + while (hashtable->current_chunk_idx < hashtable->current_chunk->used)
> ...
> + next = hashtable->current_chunk->next.unshared;
> + hashtable->current_chunk = next;
> + hashtable->current_chunk_idx = 0;
>
> Each time we advance to the next chunk, current_chunk_idx is reset. It seems current_chunk_idx can be placed inside
chunk.
> Maybe the consideration is that, with the current formation we save space by putting current_chunk_idx field at a
higherlevel.
> If that is the case, a comment should be added.
>
Thank you for the review. I think that moving the current_chunk_idx into
the HashMemoryChunk would probably take up too much space.
Other places that we loop through the tuples in the chunk, we are able
to just keep a local idx, like here in
ExecParallelHashIncreaseNumBuckets():
case PHJ_GROW_BUCKETS_REINSERTING:
...
while ((chunk = ExecParallelHashPopChunkQueue(hashtable, &chunk_s)))
{
size_t idx = 0;
while (idx < chunk->used)
but, since we cannot do that while also emitting tuples, I thought,
let's just stash the index in the hashtable for use in serial hash join
and the batch accessor for parallel hash join. A comment to this effect
sounds good to me.
On Tue, Apr 6, 2021 at 11:59 AM Melanie Plageman <melanieplageman@gmail.com> wrote:
On Fri, Apr 2, 2021 at 3:06 PM Zhihong Yu <zyu@yugabyte.com> wrote:
>
> Hi,
> For v6-0003-Parallel-Hash-Full-Right-Outer-Join.patch
>
> + * current_chunk_idx: index in current HashMemoryChunk
>
> The above comment seems to be better fit for ExecScanHashTableForUnmatched(), instead of ExecParallelPrepHashTableForUnmatched.
> I wonder where current_chunk_idx should belong (considering the above comment and what the code does).
>
> + while (hashtable->current_chunk_idx < hashtable->current_chunk->used)
> ...
> + next = hashtable->current_chunk->next.unshared;
> + hashtable->current_chunk = next;
> + hashtable->current_chunk_idx = 0;
>
> Each time we advance to the next chunk, current_chunk_idx is reset. It seems current_chunk_idx can be placed inside chunk.
> Maybe the consideration is that, with the current formation we save space by putting current_chunk_idx field at a higher level.
> If that is the case, a comment should be added.
>
Thank you for the review. I think that moving the current_chunk_idx into
the HashMemoryChunk would probably take up too much space.
Other places that we loop through the tuples in the chunk, we are able
to just keep a local idx, like here in
ExecParallelHashIncreaseNumBuckets():
case PHJ_GROW_BUCKETS_REINSERTING:
...
while ((chunk = ExecParallelHashPopChunkQueue(hashtable, &chunk_s)))
{
size_t idx = 0;
while (idx < chunk->used)
but, since we cannot do that while also emitting tuples, I thought,
let's just stash the index in the hashtable for use in serial hash join
and the batch accessor for parallel hash join. A comment to this effect
sounds good to me.
From the way HashJoinTable is used, I don't have better idea w.r.t. the location of current_chunk_idx.
It is not worth introducing another level of mapping between HashJoinTable and the chunk index.
So the current formation is fine with additional comment in ParallelHashJoinBatchAccessor (current comment doesn't explicitly mention current_chunk_idx).
Cheers
On Sat, Mar 6, 2021 at 12:31 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Tue, Mar 2, 2021 at 11:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Fri, Feb 12, 2021 at 11:02 AM Melanie Plageman > > <melanieplageman@gmail.com> wrote: > > > I just attached the diff. > > > > Squashed into one patch for the cfbot to chew on, with a few minor > > adjustments to a few comments. > > I did some more minor tidying of comments and naming. It's been on my > to-do-list to update some phase names after commit 3048898e, and while > doing that I couldn't resist the opportunity to change DONE to FREE, > which somehow hurts my brain less, and makes much more obvious sense > after the bugfix in CF #3031 that splits DONE into two separate > phases. It also pairs obviously with ALLOCATE. I include a copy of > that bugix here too as 0001, because I'll likely commit that first, so > I rebased the stack of patches that way. 0002 includes the renaming I > propose (master only). Then 0003 is Melanie's patch, using the name > SCAN for the new match bit scan phase. I've attached an updated > version of my "phase diagram" finger painting, to show how it looks > with these three patches. "scan*" is new. Patches 0002, 0003 no longer apply to the master branch, seemingly because of subsequent changes to pgstat, so need rebasing. Regards, Greg Nancarrow Fujitsu Australia
On Mon, May 31, 2021 at 10:47 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > On Sat, Mar 6, 2021 at 12:31 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > > On Tue, Mar 2, 2021 at 11:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > On Fri, Feb 12, 2021 at 11:02 AM Melanie Plageman > > > <melanieplageman@gmail.com> wrote: > > > > I just attached the diff. > > > > > > Squashed into one patch for the cfbot to chew on, with a few minor > > > adjustments to a few comments. > > > > I did some more minor tidying of comments and naming. It's been on my > > to-do-list to update some phase names after commit 3048898e, and while > > doing that I couldn't resist the opportunity to change DONE to FREE, > > which somehow hurts my brain less, and makes much more obvious sense > > after the bugfix in CF #3031 that splits DONE into two separate > > phases. It also pairs obviously with ALLOCATE. I include a copy of > > that bugix here too as 0001, because I'll likely commit that first, so > > I rebased the stack of patches that way. 0002 includes the renaming I > > propose (master only). Then 0003 is Melanie's patch, using the name > > SCAN for the new match bit scan phase. I've attached an updated > > version of my "phase diagram" finger painting, to show how it looks > > with these three patches. "scan*" is new. > > Patches 0002, 0003 no longer apply to the master branch, seemingly > because of subsequent changes to pgstat, so need rebasing. I am changing the status to "Waiting on Author" as the patch does not apply on Head. Regards, Vignesh
On Sat, Jul 10, 2021 at 9:13 AM vignesh C <vignesh21@gmail.com> wrote: > > On Mon, May 31, 2021 at 10:47 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > > On Sat, Mar 6, 2021 at 12:31 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > > > > On Tue, Mar 2, 2021 at 11:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > > On Fri, Feb 12, 2021 at 11:02 AM Melanie Plageman > > > > <melanieplageman@gmail.com> wrote: > > > > > I just attached the diff. > > > > > > > > Squashed into one patch for the cfbot to chew on, with a few minor > > > > adjustments to a few comments. > > > > > > I did some more minor tidying of comments and naming. It's been on my > > > to-do-list to update some phase names after commit 3048898e, and while > > > doing that I couldn't resist the opportunity to change DONE to FREE, > > > which somehow hurts my brain less, and makes much more obvious sense > > > after the bugfix in CF #3031 that splits DONE into two separate > > > phases. It also pairs obviously with ALLOCATE. I include a copy of > > > that bugix here too as 0001, because I'll likely commit that first, so > > > I rebased the stack of patches that way. 0002 includes the renaming I > > > propose (master only). Then 0003 is Melanie's patch, using the name > > > SCAN for the new match bit scan phase. I've attached an updated > > > version of my "phase diagram" finger painting, to show how it looks > > > with these three patches. "scan*" is new. > > > > Patches 0002, 0003 no longer apply to the master branch, seemingly > > because of subsequent changes to pgstat, so need rebasing. > > I am changing the status to "Waiting on Author" as the patch does not > apply on Head. > > Regards, > Vignesh > > Rebased patches attached. I will change status back to "Ready for Committer"
Attachment
On Fri, Jul 30, 2021 at 04:34:34PM -0400, Melanie Plageman wrote: > On Sat, Jul 10, 2021 at 9:13 AM vignesh C <vignesh21@gmail.com> wrote: > > > > On Mon, May 31, 2021 at 10:47 AM Greg Nancarrow <gregn4422@gmail.com> wrote: > > > > > > On Sat, Mar 6, 2021 at 12:31 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > > > > > > On Tue, Mar 2, 2021 at 11:27 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > > > On Fri, Feb 12, 2021 at 11:02 AM Melanie Plageman > > > > > <melanieplageman@gmail.com> wrote: > > > > > > I just attached the diff. > > > > > > > > > > Squashed into one patch for the cfbot to chew on, with a few minor > > > > > adjustments to a few comments. > > > > > > > > I did some more minor tidying of comments and naming. It's been on my > > > > to-do-list to update some phase names after commit 3048898e, and while > > > > doing that I couldn't resist the opportunity to change DONE to FREE, > > > > which somehow hurts my brain less, and makes much more obvious sense > > > > after the bugfix in CF #3031 that splits DONE into two separate > > > > phases. It also pairs obviously with ALLOCATE. I include a copy of > > > > that bugix here too as 0001, because I'll likely commit that first, so Hi Thomas, Do you intend to commit 0001 soon? Specially if this apply to 14 should be committed in the next days. > > > > I rebased the stack of patches that way. 0002 includes the renaming I > > > > propose (master only). Then 0003 is Melanie's patch, using the name > > > > SCAN for the new match bit scan phase. I've attached an updated > > > > version of my "phase diagram" finger painting, to show how it looks > > > > with these three patches. "scan*" is new. > > > 0002: my only concern is that this will cause innecesary pain in backpatch-ing future code... but not doing that myself will let that to the experts 0003: i'm testing this now, not at a big scale but just to try to find problems -- Jaime Casanova Director de Servicios Profesionales SystemGuards - Consultores de PostgreSQL
On Tue, Sep 21, 2021 at 9:29 AM Jaime Casanova <jcasanov@systemguards.com.ec> wrote: > Do you intend to commit 0001 soon? Specially if this apply to 14 should > be committed in the next days. Thanks for the reminder. Yes, I'm looking at this now, and looking into the crash of this patch set on CI: https://cirrus-ci.com/task/5282889613967360 Unfortunately, cfbot is using very simple and old CI rules which don't have a core dump analysis step on that OS. :-( (I have a big upgrade to all this CI stuff in the pipeline to fix that, get full access to all logs, go faster, and many other improvements, after learning a lot of tricks about running these types of systems over the past year -- more soon.) > 0003: i'm testing this now, not at a big scale but just to try to find > problems Thanks!
On Sat, Nov 6, 2021 at 11:04 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > > Rebased patches attached. I will change status back to "Ready for Committer" > > The CI showed a crash on freebsd, which I reproduced. > https://cirrus-ci.com/task/5203060415791104 > > The crash is evidenced in 0001 - but only ~15% of the time. > > I think it's the same thing which was committed and then reverted here, so > maybe I'm not saying anything new. > > https://commitfest.postgresql.org/33/3031/ > https://www.postgresql.org/message-id/flat/20200929061142.GA29096@paquier.xyz > > (gdb) p pstate->build_barrier->phase > Cannot access memory at address 0x7f82e0fa42f4 > > #1 0x00007f13de34f801 in __GI_abort () at abort.c:79 > #2 0x00005638e6a16d28 in ExceptionalCondition (conditionName=conditionName@entry=0x5638e6b62850 "!pstate || BarrierPhase(&pstate->build_barrier)>= PHJ_BUILD_RUN", > errorType=errorType@entry=0x5638e6a6f00b "FailedAssertion", fileName=fileName@entry=0x5638e6b625be "nodeHash.c", lineNumber=lineNumber@entry=3305)at assert.c:69 > #3 0x00005638e678085b in ExecHashTableDetach (hashtable=0x5638e8e6ca88) at nodeHash.c:3305 > #4 0x00005638e6784656 in ExecShutdownHashJoin (node=node@entry=0x5638e8e57cb8) at nodeHashjoin.c:1400 > #5 0x00005638e67666d8 in ExecShutdownNode (node=0x5638e8e57cb8) at execProcnode.c:812 > #6 ExecShutdownNode (node=0x5638e8e57cb8) at execProcnode.c:772 > #7 0x00005638e67cd5b1 in planstate_tree_walker (planstate=planstate@entry=0x5638e8e58580, walker=walker@entry=0x5638e6766680<ExecShutdownNode>, context=context@entry=0x0) at nodeFuncs.c:4009 > #8 0x00005638e67666b2 in ExecShutdownNode (node=0x5638e8e58580) at execProcnode.c:792 > #9 ExecShutdownNode (node=0x5638e8e58580) at execProcnode.c:772 > #10 0x00005638e67cd5b1 in planstate_tree_walker (planstate=planstate@entry=0x5638e8e58418, walker=walker@entry=0x5638e6766680<ExecShutdownNode>, context=context@entry=0x0) at nodeFuncs.c:4009 > #11 0x00005638e67666b2 in ExecShutdownNode (node=0x5638e8e58418) at execProcnode.c:792 > #12 ExecShutdownNode (node=node@entry=0x5638e8e58418) at execProcnode.c:772 > #13 0x00005638e675f518 in ExecutePlan (execute_once=<optimized out>, dest=0x5638e8df0058, direction=<optimized out>, numberTuples=0,sendTuples=<optimized out>, operation=CMD_SELECT, > use_parallel_mode=<optimized out>, planstate=0x5638e8e58418, estate=0x5638e8e57a10) at execMain.c:1658 > #14 standard_ExecutorRun () at execMain.c:410 > #15 0x00005638e6763e0a in ParallelQueryMain (seg=0x5638e8d823d8, toc=0x7f13df4e9000) at execParallel.c:1493 > #16 0x00005638e663f6c7 in ParallelWorkerMain () at parallel.c:1495 > #17 0x00005638e68542e4 in StartBackgroundWorker () at bgworker.c:858 > #18 0x00005638e6860f53 in do_start_bgworker (rw=<optimized out>) at postmaster.c:5883 > #19 maybe_start_bgworkers () at postmaster.c:6108 > #20 0x00005638e68619e5 in sigusr1_handler (postgres_signal_arg=<optimized out>) at postmaster.c:5272 > #21 <signal handler called> > #22 0x00007f13de425ff7 in __GI___select (nfds=nfds@entry=7, readfds=readfds@entry=0x7ffef03b8400, writefds=writefds@entry=0x0,exceptfds=exceptfds@entry=0x0, timeout=timeout@entry=0x7ffef03b8360) > at ../sysdeps/unix/sysv/linux/select.c:41 > #23 0x00005638e68620ce in ServerLoop () at postmaster.c:1765 > #24 0x00005638e6863bcc in PostmasterMain () at postmaster.c:1473 > #25 0x00005638e658fd00 in main (argc=8, argv=0x5638e8d54730) at main.c:198 Yes, this looks like that issue. I've attached a v8 set with the fix I suggested in [1] included. (I added it to 0001). - Melanie [1] https://www.postgresql.org/message-id/flat/20200929061142.GA29096%40paquier.xyz
Attachment
small mistake in v8. v9 attached. - Melanie
Attachment
On Sun, Nov 21, 2021 at 4:48 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > On Wed, Nov 17, 2021 at 01:45:06PM -0500, Melanie Plageman wrote: > > Yes, this looks like that issue. > > > > I've attached a v8 set with the fix I suggested in [1] included. > > (I added it to 0001). > > This is still crashing :( > https://cirrus-ci.com/task/6738329224871936 > https://cirrus-ci.com/task/4895130286030848 I added a core file backtrace to cfbot's CI recipe a few days ago, so now we have: https://cirrus-ci.com/task/5676480098205696 #3 0x00000000009cf57e in ExceptionalCondition (conditionName=0x29cae8 "BarrierParticipants(&accessor->shared->batch_barrier) == 1", errorType=<optimized out>, fileName=0x2ae561 "nodeHash.c", lineNumber=lineNumber@entry=2224) at assert.c:69 No locals. #4 0x000000000071575e in ExecParallelScanHashTableForUnmatched (hjstate=hjstate@entry=0x80a60a3c8, econtext=econtext@entry=0x80a60ae98) at nodeHash.c:2224
On Fri, Nov 26, 2021 at 3:11 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > On Sun, Nov 21, 2021 at 4:48 PM Justin Pryzby <pryzby@telsasoft.com> wrote: > > On Wed, Nov 17, 2021 at 01:45:06PM -0500, Melanie Plageman wrote: > > > Yes, this looks like that issue. > > > > > > I've attached a v8 set with the fix I suggested in [1] included. > > > (I added it to 0001). > > > > This is still crashing :( > > https://cirrus-ci.com/task/6738329224871936 > > https://cirrus-ci.com/task/4895130286030848 > > I added a core file backtrace to cfbot's CI recipe a few days ago, so > now we have: > > https://cirrus-ci.com/task/5676480098205696 > > #3 0x00000000009cf57e in ExceptionalCondition (conditionName=0x29cae8 > "BarrierParticipants(&accessor->shared->batch_barrier) == 1", > errorType=<optimized out>, fileName=0x2ae561 "nodeHash.c", > lineNumber=lineNumber@entry=2224) at assert.c:69 > No locals. > #4 0x000000000071575e in ExecParallelScanHashTableForUnmatched > (hjstate=hjstate@entry=0x80a60a3c8, > econtext=econtext@entry=0x80a60ae98) at nodeHash.c:2224 I believe this assert can be safely removed. It is possible for a worker to attach to the batch barrier after the "last" worker was elected to scan and emit unmatched inner tuples. This is safe because the batch barrier is already in phase PHJ_BATCH_SCAN and this newly attached worker will simply detach from the batch barrier and look for a new batch to work on. The order of events would be as follows: W1: advances batch to PHJ_BATCH_SCAN W2: attaches to batch barrier in ExecParallelHashJoinNewBatch() W1: calls ExecParallelScanHashTableForUnmatched() (2 workers attached to barrier at this point) W2: detaches from the batch barrier The attached v10 patch removes this assert and updates the comment in ExecParallelScanHashTableForUnmatched(). I'm not sure if I should add more detail about this scenario in ExecParallelHashJoinNewBatch() under PHJ_BATCH_SCAN or if the detail in ExecParallelScanHashTableForUnmatched() is sufficient. - Melanie
Attachment
On Wed, Jan 12, 2022 at 10:30 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > On Fri, Nov 26, 2021 at 3:11 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > #3 0x00000000009cf57e in ExceptionalCondition (conditionName=0x29cae8 > > "BarrierParticipants(&accessor->shared->batch_barrier) == 1", > > errorType=<optimized out>, fileName=0x2ae561 "nodeHash.c", > > lineNumber=lineNumber@entry=2224) at assert.c:69 > > No locals. > > #4 0x000000000071575e in ExecParallelScanHashTableForUnmatched > > (hjstate=hjstate@entry=0x80a60a3c8, > > econtext=econtext@entry=0x80a60ae98) at nodeHash.c:2224 > > I believe this assert can be safely removed. Agreed. I was looking at this with a view to committing it, but I need more time. This will be at the front of my queue when the tree reopens. I'm trying to find the tooling I had somewhere that could let you test attaching and detaching at every phase. The attached version is just pgindent'd.
Attachment
2022年4月8日(金) 20:30 Thomas Munro <thomas.munro@gmail.com>: > > On Wed, Jan 12, 2022 at 10:30 AM Melanie Plageman > <melanieplageman@gmail.com> wrote: > > On Fri, Nov 26, 2021 at 3:11 PM Thomas Munro <thomas.munro@gmail.com> wrote: > > > #3 0x00000000009cf57e in ExceptionalCondition (conditionName=0x29cae8 > > > "BarrierParticipants(&accessor->shared->batch_barrier) == 1", > > > errorType=<optimized out>, fileName=0x2ae561 "nodeHash.c", > > > lineNumber=lineNumber@entry=2224) at assert.c:69 > > > No locals. > > > #4 0x000000000071575e in ExecParallelScanHashTableForUnmatched > > > (hjstate=hjstate@entry=0x80a60a3c8, > > > econtext=econtext@entry=0x80a60ae98) at nodeHash.c:2224 > > > > I believe this assert can be safely removed. > > Agreed. > > I was looking at this with a view to committing it, but I need more > time. This will be at the front of my queue when the tree reopens. > I'm trying to find the tooling I had somewhere that could let you test > attaching and detaching at every phase. > > The attached version is just pgindent'd. Hi Thomas This patch is marked as "Waiting for Committer" in the current commitfest [1] with yourself as committer; do you have any plans to move ahead with this? [1] https://commitfest.postgresql.org/40/2903/ Regards Ian Barwick
On Thu, Nov 17, 2022 at 5:22 PM Ian Lawrence Barwick <barwick@gmail.com> wrote: > This patch is marked as "Waiting for Committer" in the current commitfest [1] > with yourself as committer; do you have any plans to move ahead with this? Yeah, sorry for lack of progress. Aiming to get this in shortly.
Here is a rebased and lightly hacked-upon version that I'm testing.
0001-Scan-for-unmatched-hash-join-tuples-in-memory-order.patch
* this change can stand on its own, separately from any PHJ changes
* renamed hashtable->current_chunk[_idx] to unmatched_scan_{chunk,idx}
* introduced a local variable to avoid some x->y->z stuff
* removed some references to no-longer-relevant hj_XXX variables in
the Prep function
I haven't attempted to prove anything about the performance of this
one yet, but it seems fairly obvious that it can't be worse than what
we're doing today. I have suppressed the urge to look into improving
locality and software prefetching.
0002-Parallel-Hash-Full-Join.patch
* reuse the same umatched_scan_{chunk,idx} variables as above
* rename the list of chunks to scan to work_queue
* fix race/memory leak if we see PHJ_BATCH_SCAN when we attach (it
wasn't OK to just fall through)
That "work queue" name/concept already exists in other places that
need to process every chunk, namely rebucketing and repartitioning.
In later work, I'd like to harmonise these work queues, but I'm not
trying to increase the size of this patch set at this time, I just
want to use consistent naming.
I don't love the way that both ExecHashTableDetachBatch() and
ExecParallelPrepHashTableForUnmatched() duplicate logic relating to
the _SCAN/_FREE protocol, but I'm struggling to find a better idea.
Perhaps I just need more coffee.
I think your idea of opportunistically joining the scan if it's
already running makes sense to explore for a later step, ie to make
multi-batch PHFJ fully fair, and I think that should be a fairly easy
code change, and I put in some comments where changes would be needed.
Continuing to test, more soon.
Attachment
On Sat, Mar 25, 2023 at 09:21:34AM +1300, Thomas Munro wrote:
> * reuse the same umatched_scan_{chunk,idx} variables as above
> * rename the list of chunks to scan to work_queue
> * fix race/memory leak if we see PHJ_BATCH_SCAN when we attach (it
> wasn't OK to just fall through)
ah, good catch.
> I don't love the way that both ExecHashTableDetachBatch() and
> ExecParallelPrepHashTableForUnmatched() duplicate logic relating to
> the _SCAN/_FREE protocol, but I'm struggling to find a better idea.
> Perhaps I just need more coffee.
I'm not sure if I have strong feelings either way.
To confirm I understand, though: in ExecHashTableDetachBatch(), the call
to BarrierArriveAndDetachExceptLast() serves only to advance the barrier
phase through _SCAN, right? It doesn't really matter if this worker is
the last worker since BarrierArriveAndDetach() handles that for us.
There isn't another barrier function to do this (and I mostly think it
is fine), but I did have to think on it for a bit.
Oh, and, unrelated, but it is maybe worth updating the BarrierAttach()
function comment to mention BarrierArriveAndDetachExceptLast().
> I think your idea of opportunistically joining the scan if it's
> already running makes sense to explore for a later step, ie to make
> multi-batch PHFJ fully fair, and I think that should be a fairly easy
> code change, and I put in some comments where changes would be needed.
makes sense.
I have some very minor pieces of feedback, mainly about extraneous
commas that made me uncomfortable ;)
> From 8b526377eb4a4685628624e75743aedf37dd5bfe Mon Sep 17 00:00:00 2001
> From: Thomas Munro <thomas.munro@gmail.com>
> Date: Fri, 24 Mar 2023 14:19:07 +1300
> Subject: [PATCH v12 1/2] Scan for unmatched hash join tuples in memory order.
>
> In a full/right outer join, we need to scan every tuple in the hash
> table to find the ones that were not matched while probing, so that we
Given how you are using the word "so" here, I think that comma before it
is not needed.
> @@ -2083,58 +2079,45 @@ bool
> ExecScanHashTableForUnmatched(HashJoinState *hjstate, ExprContext *econtext)
> {
> HashJoinTable hashtable = hjstate->hj_HashTable;
> - HashJoinTuple hashTuple = hjstate->hj_CurTuple;
> + HashMemoryChunk chunk;
>
> - for (;;)
> + while ((chunk = hashtable->unmatched_scan_chunk))
> {
> - /*
> - * hj_CurTuple is the address of the tuple last returned from the
> - * current bucket, or NULL if it's time to start scanning a new
> - * bucket.
> - */
> - if (hashTuple != NULL)
> - hashTuple = hashTuple->next.unshared;
> - else if (hjstate->hj_CurBucketNo < hashtable->nbuckets)
> - {
> - hashTuple = hashtable->buckets.unshared[hjstate->hj_CurBucketNo];
> - hjstate->hj_CurBucketNo++;
> - }
> - else if (hjstate->hj_CurSkewBucketNo < hashtable->nSkewBuckets)
> + while (hashtable->unmatched_scan_idx < chunk->used)
> {
> - int j = hashtable->skewBucketNums[hjstate->hj_CurSkewBucketNo];
> + HashJoinTuple hashTuple = (HashJoinTuple)
> + (HASH_CHUNK_DATA(hashtable->unmatched_scan_chunk) +
> + hashtable->unmatched_scan_idx);
>
> - hashTuple = hashtable->skewBucket[j]->tuples;
> - hjstate->hj_CurSkewBucketNo++;
> - }
> - else
> - break; /* finished all buckets */
> + MinimalTuple tuple = HJTUPLE_MINTUPLE(hashTuple);
> + int hashTupleSize = (HJTUPLE_OVERHEAD + tuple->t_len);
>
> - while (hashTuple != NULL)
> - {
> - if (!HeapTupleHeaderHasMatch(HJTUPLE_MINTUPLE(hashTuple)))
> - {
> - TupleTableSlot *inntuple;
> + /* next tuple in this chunk */
> + hashtable->unmatched_scan_idx += MAXALIGN(hashTupleSize);
>
> - /* insert hashtable's tuple into exec slot */
> - inntuple = ExecStoreMinimalTuple(HJTUPLE_MINTUPLE(hashTuple),
> - hjstate->hj_HashTupleSlot,
> - false); /* do not pfree */
> - econtext->ecxt_innertuple = inntuple;
> + if (HeapTupleHeaderHasMatch(HJTUPLE_MINTUPLE(hashTuple)))
> + continue;
>
> - /*
> - * Reset temp memory each time; although this function doesn't
> - * do any qual eval, the caller will, so let's keep it
> - * parallel to ExecScanHashBucket.
> - */
> - ResetExprContext(econtext);
I don't think I had done this before. Good call.
> + /* insert hashtable's tuple into exec slot */
> + econtext->ecxt_innertuple =
> + ExecStoreMinimalTuple(HJTUPLE_MINTUPLE(hashTuple),
> + hjstate->hj_HashTupleSlot,
> + false);
> From 6f4e82f0569e5b388440ca0ef268dd307388e8f8 Mon Sep 17 00:00:00 2001
> From: Thomas Munro <thomas.munro@gmail.com>
> Date: Fri, 24 Mar 2023 15:23:14 +1300
> Subject: [PATCH v12 2/2] Parallel Hash Full Join.
>
> Full and right outer joins were not supported in the initial
> implementation of Parallel Hash Join, because of deadlock hazards (see
no comma needed before the "because" here
> discussion). Therefore FULL JOIN inhibited page-based parallelism,
> as the other join strategies can't do it either.
I actually don't quite understand what this means? It's been awhile for
me, so perhaps I'm being dense, but what is page-based parallelism?
Also, I would put a comma after "Therefore" :)
> Add a new PHJ phase PHJ_BATCH_SCAN that scans for unmatched tuples on
> the inner side of one batch's hash table. For now, sidestep the
> deadlock problem by terminating parallelism there. The last process to
> arrive at that phase emits the unmatched tuples, while others detach and
> are free to go and work on other batches, if there are any, but
> otherwise they finish the join early.
>
> That unfairness is considered acceptable for now, because it's better
> than no parallelism at all. The build and probe phases are run in
> parallel, and the new scan-for-unmatched phase, while serial, is usually
> applied to the smaller of the two relations and is either limited by
> some multiple of work_mem, or it's too big and is partitioned into
> batches and then the situation is improved by batch-level parallelism.
> In future work on deadlock avoidance strategies, we may find a way to
> parallelize the new phase safely.
Is it worth mentioning something about parallel-oblivious parallel hash
join not being able to do this still? Or is that obvious?
> *
> @@ -2908,6 +3042,12 @@ ExecParallelHashTupleAlloc(HashJoinTable hashtable, size_t size,
> chunk->next.shared = hashtable->batches[curbatch].shared->chunks;
> hashtable->batches[curbatch].shared->chunks = chunk_shared;
>
> + /*
> + * Also make this the head of the work_queue list. This is used as a
> + * cursor for scanning all chunks in the batch.
> + */
> + hashtable->batches[curbatch].shared->work_queue = chunk_shared;
> +
> if (size <= HASH_CHUNK_THRESHOLD)
> {
> /*
> @@ -3116,18 +3256,31 @@ ExecHashTableDetachBatch(HashJoinTable hashtable)
> {
> int curbatch = hashtable->curbatch;
> ParallelHashJoinBatch *batch = hashtable->batches[curbatch].shared;
> + bool attached = true;
>
> /* Make sure any temporary files are closed. */
> sts_end_parallel_scan(hashtable->batches[curbatch].inner_tuples);
> sts_end_parallel_scan(hashtable->batches[curbatch].outer_tuples);
>
> - /* Detach from the batch we were last working on. */
> - if (BarrierArriveAndDetach(&batch->batch_barrier))
> + /* After attaching we always get at least to PHJ_BATCH_PROBE. */
> + Assert(BarrierPhase(&batch->batch_barrier) == PHJ_BATCH_PROBE ||
> + BarrierPhase(&batch->batch_barrier) == PHJ_BATCH_SCAN);
> +
> + /*
> + * Even if we aren't doing a full/right outer join, we'll step through
> + * the PHJ_BATCH_SCAN phase just to maintain the invariant that freeing
> + * happens in PHJ_BATCH_FREE, but that'll be wait-free.
> + */
> + if (BarrierPhase(&batch->batch_barrier) == PHJ_BATCH_PROBE)
full/right joins should never fall into this code path, right?
If so, would we be able to assert about that? Maybe it doesn't make
sense, though...
> + attached = BarrierArriveAndDetachExceptLast(&batch->batch_barrier);
> + if (attached && BarrierArriveAndDetach(&batch->batch_barrier))
> {
> /*
> - * Technically we shouldn't access the barrier because we're no
> - * longer attached, but since there is no way it's moving after
> - * this point it seems safe to make the following assertion.
> + * We are not longer attached to the batch barrier, but we're the
> + * process that was chosen to free resources and it's safe to
> + * assert the current phase. The ParallelHashJoinBatch can't go
> + * away underneath us while we are attached to the build barrier,
> + * making this access safe.
> */
> Assert(BarrierPhase(&batch->batch_barrier) == PHJ_BATCH_FREE);
Otherwise, LGTM.
- Melanie
On Sun, Mar 26, 2023 at 9:52 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > I have some very minor pieces of feedback, mainly about extraneous > commas that made me uncomfortable ;) Offensive punctuation removed. > > discussion). Therefore FULL JOIN inhibited page-based parallelism, > > as the other join strategies can't do it either. > > I actually don't quite understand what this means? It's been awhile for > me, so perhaps I'm being dense, but what is page-based parallelism? Reworded. I just meant our usual kind of "partial path" parallelism (the kind when you don't know anything at all about the values of the tuples that each process sees, and typically it's chopped up by storage pages at the scan level). > > That unfairness is considered acceptable for now, because it's better > > than no parallelism at all. The build and probe phases are run in > > parallel, and the new scan-for-unmatched phase, while serial, is usually > > applied to the smaller of the two relations and is either limited by > > some multiple of work_mem, or it's too big and is partitioned into > > batches and then the situation is improved by batch-level parallelism. > > In future work on deadlock avoidance strategies, we may find a way to > > parallelize the new phase safely. > > Is it worth mentioning something about parallel-oblivious parallel hash > join not being able to do this still? Or is that obvious? That's kind of what I meant above. > > @@ -3116,18 +3256,31 @@ ExecHashTableDetachBatch(HashJoinTable hashtable) > full/right joins should never fall into this code path, right? Yeah, this is the normal way we detach from a batch. This is reached when shutting down the executor early, or when moving to the next batch, etc. *** I found another problem. I realised that ... FULL JOIN ... LIMIT n might be able to give wrong answers with unlucky scheduling. Unfortunately I have been unable to reproduce the phenomenon I am imagining yet but I can't think of any mechanism that prevents the following sequence of events: P0 probes, pulls n tuples from the outer relation and then the executor starts to shut down (see commit 3452dc52 which pushed down LIMIT), but just then P1 attaches, right before P0 does. P1 continues, and finds < n outer tuples while probing and then runs out so it enters the unmatched scan phase, and starts emitting bogusly unmatched tuples. Some outer tuples we needed to get the complete set of match bits and thus the right answer were buffered inside P0's subplan and abandoned. I've attached a simple fixup for this problem. Short version: if you're abandoning your PHJ_BATCH_PROBE phase without reaching the end, you must be shutting down, so the executor must think it's OK to abandon tuples this process has buffered, so it must also be OK to throw all unmatched tuples out the window too, as if this process was about to emit them. Right? *** With all the long and abstract discussion of hard to explain problems in this thread and related threads, I thought I should take a step back and figure out a way to demonstrate what this thing really does visually. I wanted to show that this is a very useful feature that unlocks previously unobtainable parallelism, and to show the compromise we've had to make so far in an intuitive way. With some extra instrumentation hacked up locally, I produced the attached "progress" graphs for a very simple query: SELECT COUNT(*) FROM r FULL JOIN s USING (i). Imagine a time axis along the bottom, but I didn't bother to add numbers because I'm just trying to convey the 'shape' of execution with relative times and synchronisation points. Figures 1-3 show that phases 'h' (hash) and 'p' (probe) are parallelised and finish sooner as we add more processes to help out, but 's' (= the unmatched inner tuple scan) is not. Note that if all inner tuples are matched, 's' becomes extremely small and the parallelism is almost as fair as a plain old inner join, but here I've maximised it: all inner tuples were unmatched, because the two relations have no matches at all. Even if we achieve perfect linear scalability for the other phases, the speedup will be governed by https://en.wikipedia.org/wiki/Amdahl%27s_law and the only thing that can mitigate that is if there is more useful work those early-quitting processes could do somewhere else in your query plan. Figure 4 shows that it gets a lot fairer in a multi-batch join, because there is usually useful work to do on other batches of the same join. Notice how processes initially work on loading, probing and scanning different batches to reduce contention, but they are capable of ganging up to load and/or probe the same batch if there is nothing else left to do (for example P2 and P3 both work on p5 near the end). For now, they can't do that for the s phases. (BTW, the little gaps before loading is the allocation phase that I didn't bother to plot because they can't fit a label on them; this visualisation technique is a WIP.) With the "opportunistic" change we are discussing for later work, figure 4 would become completely fair (P0 and P2 would be able to join in and help out with s6 and s7), but single-batch figures 1-3 would not (that would require a different executor design AFAICT, or a eureka insight we haven't had yet; see long-winded discussion). The last things I'm thinking about now: Are the planner changes right? Are the tests enough? I suspect we'll finish up changing that chunk-based approach yet again in future work on memory efficiency, but I'm OK with that; this change suits the current problem and we don't know what we'll eventually settle on with more research.
Attachment
On Mon, Mar 27, 2023 at 7:04 PM Thomas Munro <thomas.munro@gmail.com> wrote: > I found another problem. I realised that ... FULL JOIN ... LIMIT n > might be able to give wrong answers with unlucky scheduling. > Unfortunately I have been unable to reproduce the phenomenon I am > imagining yet but I can't think of any mechanism that prevents the > following sequence of events: > > P0 probes, pulls n tuples from the outer relation and then the > executor starts to shut down (see commit 3452dc52 which pushed down > LIMIT), but just then P1 attaches, right before P0 does. P1 > continues, and finds < n outer tuples while probing and then runs out > so it enters the unmatched scan phase, and starts emitting bogusly > unmatched tuples. Some outer tuples we needed to get the complete set > of match bits and thus the right answer were buffered inside P0's > subplan and abandoned. > > I've attached a simple fixup for this problem. Short version: if > you're abandoning your PHJ_BATCH_PROBE phase without reaching the end, > you must be shutting down, so the executor must think it's OK to > abandon tuples this process has buffered, so it must also be OK to > throw all unmatched tuples out the window too, as if this process was > about to emit them. Right? I understand the scenario you are thinking of, however, I question how those incorrectly formed tuples would ever be returned by the query. The hashjoin would only start to shutdown once enough tuples had been emitted to satisfy the limit, at which point, those tuples buffered in p0 may be emitted by this worker but wouldn't be included in the query result, no? I suppose even if what I said is true, we do not want the hashjoin node to ever produce incorrect tuples. In which case, your fix seems correct to me. > With all the long and abstract discussion of hard to explain problems > in this thread and related threads, I thought I should take a step > back and figure out a way to demonstrate what this thing really does > visually. I wanted to show that this is a very useful feature that > unlocks previously unobtainable parallelism, and to show the > compromise we've had to make so far in an intuitive way. With some > extra instrumentation hacked up locally, I produced the attached > "progress" graphs for a very simple query: SELECT COUNT(*) FROM r FULL > JOIN s USING (i). Imagine a time axis along the bottom, but I didn't > bother to add numbers because I'm just trying to convey the 'shape' of > execution with relative times and synchronisation points. > > Figures 1-3 show that phases 'h' (hash) and 'p' (probe) are > parallelised and finish sooner as we add more processes to help out, > but 's' (= the unmatched inner tuple scan) is not. Note that if all > inner tuples are matched, 's' becomes extremely small and the > parallelism is almost as fair as a plain old inner join, but here I've > maximised it: all inner tuples were unmatched, because the two > relations have no matches at all. Even if we achieve perfect linear > scalability for the other phases, the speedup will be governed by > https://en.wikipedia.org/wiki/Amdahl%27s_law and the only thing that > can mitigate that is if there is more useful work those early-quitting > processes could do somewhere else in your query plan. > > Figure 4 shows that it gets a lot fairer in a multi-batch join, > because there is usually useful work to do on other batches of the > same join. Notice how processes initially work on loading, probing > and scanning different batches to reduce contention, but they are > capable of ganging up to load and/or probe the same batch if there is > nothing else left to do (for example P2 and P3 both work on p5 near > the end). For now, they can't do that for the s phases. (BTW, the > little gaps before loading is the allocation phase that I didn't > bother to plot because they can't fit a label on them; this > visualisation technique is a WIP.) > > With the "opportunistic" change we are discussing for later work, > figure 4 would become completely fair (P0 and P2 would be able to join > in and help out with s6 and s7), but single-batch figures 1-3 would > not (that would require a different executor design AFAICT, or a > eureka insight we haven't had yet; see long-winded discussion). Cool diagrams! > The last things I'm thinking about now: Are the planner changes > right? I think the current changes are correct. I wonder if we have to change anything in initial/final_cost_hashjoin to account for the fact that for a single batch full/right parallel hash join, part of the execution is serial. And, if so, do we need to consider the estimated number of unmatched tuples to be emitted? > Are the tests enough? So, the tests currently in the patch set cover the unmatched tuple scan phase for single batch parallel full hash join. I've attached the dumbest possible addition to that which adds in a multi-batch full parallel hash join case. I did not do any checking to ensure I picked the case which would add the least execution time to the test, etc. Of course, this does leave the skip_unmatched code you added uncovered, but I think if we had the testing infrastructure to test that, we would be on a beach somewhere reading a book instead of beating our heads against the wall trying to determine if there are any edge cases we are missing in adding this feature. - Melanie
Attachment
On Fri, Mar 31, 2023 at 8:23 AM Melanie Plageman <melanieplageman@gmail.com> wrote: > I understand the scenario you are thinking of, however, I question how > those incorrectly formed tuples would ever be returned by the query. The > hashjoin would only start to shutdown once enough tuples had been > emitted to satisfy the limit, at which point, those tuples buffered in > p0 may be emitted by this worker but wouldn't be included in the query > result, no? Yeah, I think I must have been confused by that too early on. The thing is, Gather asks every worker process for n tuples so that any one of them could satisfy the LIMIT if required, but it's unknown which process's output the Gather node will receive first (or might make it into intermediate nodes and affect the results). I guess to see bogus unmatched tuples actually escaping anywhere (with the earlier patches) you'd need parallel leader off + diabolical scheduling? I thought about 3 solutions before settling on #3: (1) Hypothetically, P1 could somehow steal/finish P0's work, but our executor has no mechanism for anything like that. (2) P0 isn't allowed to leave the probe early, instead it has to keep going but throw away the tuples it'd normally emit, so we are sure we have all the match bits in shared memory. (3) P0 seizes responsibility for emitting those tuples, but then does nothing because the top level executor doesn't want more tuples, which in practice looks like a flag telling everyone else not to bother. Idea #1 would probably require shared address space (threads) and a non-recursive executor, as speculated about a few times before, and that type of magic could address several kinds of deadlock risks, but in this case we still wouldn't want to do that even if we could; it's work that is provably (by idea #3's argument) a waste of time. Idea #2 is a horrible pessimisation of idea #1 within our existing executor design, but it helped me think about what it really means to be authorised to throw away tuples from on high. > I suppose even if what I said is true, we do not want the hashjoin node > to ever produce incorrect tuples. In which case, your fix seems correct to me. Yeah, that's a good way to put it. > > The last things I'm thinking about now: Are the planner changes > > right? > > I think the current changes are correct. I wonder if we have to change > anything in initial/final_cost_hashjoin to account for the fact that > for a single batch full/right parallel hash join, part of the > execution is serial. And, if so, do we need to consider the estimated > number of unmatched tuples to be emitted? I have no idea how to model that, and I'm assuming the existing model should continue to work as well as it does today "on average". The expected number of tuples will be the same across all workers, it's just an unfortunate implementation detail that the distribution sucks (but is still much better than a serial plan). I wondered if get_parallel_divisor() might provide some inspiration but that's dealing with a different problem: a partial extra process that will take some of the work (ie tuples) away from the other processes, and that's not the case here. > > Are the tests enough? > > So, the tests currently in the patch set cover the unmatched tuple scan > phase for single batch parallel full hash join. I've attached the > dumbest possible addition to that which adds in a multi-batch full > parallel hash join case. I did not do any checking to ensure I picked > the case which would add the least execution time to the test, etc. Thanks, added. I should probably try to figure out how to get the join_hash tests to run with smaller tables. It's one of the slower tests and this adds to it. I vaguely recall it was hard to get the batch counts to be stable across the build farm, which makes me hesitant to change the tests but perhaps I can figure out how to screw it down... I decided to drop the scan order change for now (0001 in v13). Yes, it's better than what we have now, but it seems to cut off some other possible ideas to do even better, so it feels premature to change it without more work. I changed the parallel unmatched scan back to being as similar as possible to the serial one for now. I committed the main patch. Here are a couple of ideas that came up while working on this, for future study: * the "opportunistic help" thing you once suggested to make it a little fairer in multi-batch cases. Quick draft attached, for future experimentation. Seems to work pretty well, but could definitely be tidier and there may be holes in it. Pretty picture attached. * should we pass HJ_FILL_INNER(hjstate) into a new parameter fill_inner to ExecHashJoinImpl(), so that we can make specialised hash join routines for the yes and no cases, so that we can remove branching and memory traffic related to match bits? * could we use tagged pointers to track matched tuples? Tuples are MAXALIGNed, so bits 0 and 1 of pointers to them are certainly always 0. Perhaps we could use bit 0 for "matched" and bit 1 for "I am not the last tuple in my chain, you'll have to check the next one too". Then you could scan for unmatched without following many pointers, if you're lucky. You could skip the required masking etc for that if !fill_inner. * should we use software prefetching to smooth over the random memory order problem when you do have to follow them? Though it's hard to prefetch chains, here we have an array full of pointers at least to the first tuples in each chain. This probably goes along with the general hash join memory prefetching work that I started a couple of years back and need to restart for 17. * this idea is probably stupid overkill, but it's something that v13-0001 made me think about: could it be worth the effort to sample a fraction of the match bits in the hash table buckets (with the scheme above), and determine whether you'll be emitting a high fraction of the tuples, and then switch to chunk based so that you can do it in memory order if so? That requires having the match flag in *two* places, which seems silly; you'd need some experimental evidence that any of this is worth bothering with * currently, the "hash inner" phase only loads tuples into batch 0's hash table (the so-called "hybrid Grace" technique), but if there are (say) 4 processes, you could actually load batches 0-3 into memory during that phase, to avoid having to dump 1-3 out to disk and then immediately load them back in again; you'd get to skip "l1", "l2", "l3" on those diagrams and finish a good bit faster
Attachment
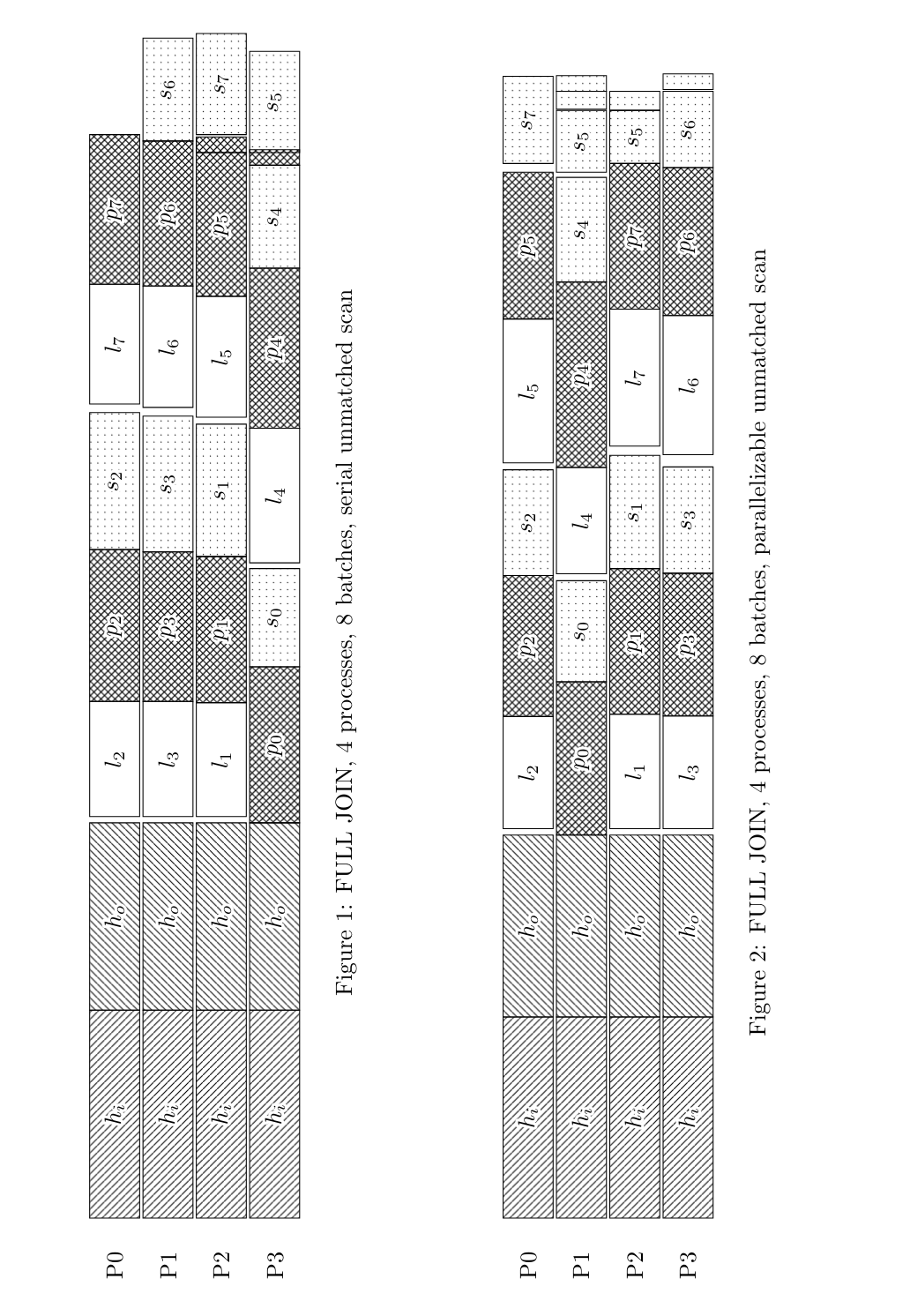{kind=link}
Thomas Munro <thomas.munro@gmail.com> writes:
> I committed the main patch.
This left the following code in hash_inner_and_outer (joinpath.c):
/*
* If the joinrel is parallel-safe, we may be able to consider a
* partial hash join. However, we can't handle JOIN_UNIQUE_OUTER,
* because the outer path will be partial, and therefore we won't be
* able to properly guarantee uniqueness. Similarly, we can't handle
* JOIN_FULL and JOIN_RIGHT, because they can produce false null
* extended rows. Also, the resulting path must not be parameterized.
*/
if (joinrel->consider_parallel &&
save_jointype != JOIN_UNIQUE_OUTER &&
outerrel->partial_pathlist != NIL &&
bms_is_empty(joinrel->lateral_relids))
{
The comment is no longer in sync with the code: this if-test used to
reject JOIN_FULL and JOIN_RIGHT, and no longer does so, but the comment
still claims it should. Shouldn't we drop the sentence beginning
"Similarly"? (I see that there's now one sub-section that still rejects
such cases, but it no longer seems correct to claim that they're rejected
overall.)
regards, tom lane
On Wed, Apr 5, 2023 at 7:37 AM Tom Lane <tgl@sss.pgh.pa.us> wrote: > The comment is no longer in sync with the code: this if-test used to > reject JOIN_FULL and JOIN_RIGHT, and no longer does so, but the comment > still claims it should. Shouldn't we drop the sentence beginning > "Similarly"? (I see that there's now one sub-section that still rejects > such cases, but it no longer seems correct to claim that they're rejected > overall.) Yeah, thanks. Done.
Thomas Munro <thomas.munro@gmail.com> writes:
> I committed the main patch.
BTW, it was easy to miss in all the buildfarm noise from
last-possible-minute patches, but chimaera just showed something
that looks like a bug in this code [1]:
2023-04-08 12:25:28.709 UTC [18027:321] pg_regress/join_hash LOG: statement: savepoint settings;
2023-04-08 12:25:28.709 UTC [18027:322] pg_regress/join_hash LOG: statement: set local max_parallel_workers_per_gather
=2;
2023-04-08 12:25:28.710 UTC [18027:323] pg_regress/join_hash LOG: statement: explain (costs off)
select count(*) from simple r full outer join simple s on (r.id = 0 - s.id);
2023-04-08 12:25:28.710 UTC [18027:324] pg_regress/join_hash LOG: statement: select count(*) from simple r full outer
joinsimple s on (r.id = 0 - s.id);
TRAP: failed Assert("BarrierParticipants(&batch->batch_barrier) == 1"), File: "nodeHash.c", Line: 2118, PID: 19147
postgres: parallel worker for PID 18027 (ExceptionalCondition+0x84)[0x10ae2bfa4]
postgres: parallel worker for PID 18027 (ExecParallelPrepHashTableForUnmatched+0x224)[0x10aa67544]
postgres: parallel worker for PID 18027 (+0x3db868)[0x10aa6b868]
postgres: parallel worker for PID 18027 (+0x3c4204)[0x10aa54204]
postgres: parallel worker for PID 18027 (+0x3c81b8)[0x10aa581b8]
postgres: parallel worker for PID 18027 (+0x3b3d28)[0x10aa43d28]
postgres: parallel worker for PID 18027 (standard_ExecutorRun+0x208)[0x10aa39768]
postgres: parallel worker for PID 18027 (ParallelQueryMain+0x2bc)[0x10aa4092c]
postgres: parallel worker for PID 18027 (ParallelWorkerMain+0x660)[0x10a874870]
postgres: parallel worker for PID 18027 (StartBackgroundWorker+0x2a8)[0x10ab8abf8]
postgres: parallel worker for PID 18027 (+0x50290c)[0x10ab9290c]
postgres: parallel worker for PID 18027 (+0x5035e4)[0x10ab935e4]
postgres: parallel worker for PID 18027 (PostmasterMain+0x1304)[0x10ab96334]
postgres: parallel worker for PID 18027 (main+0x86c)[0x10a79daec]
regards, tom lane
[1] https://buildfarm.postgresql.org/cgi-bin/show_log.pl?nm=chimaera&dt=2023-04-08%2012%3A07%3A08
On Sat, Apr 8, 2023 at 12:33 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> Thomas Munro <thomas.munro@gmail.com> writes:
> > I committed the main patch.
>
> BTW, it was easy to miss in all the buildfarm noise from
> last-possible-minute patches, but chimaera just showed something
> that looks like a bug in this code [1]:
>
> 2023-04-08 12:25:28.709 UTC [18027:321] pg_regress/join_hash LOG: statement: savepoint settings;
> 2023-04-08 12:25:28.709 UTC [18027:322] pg_regress/join_hash LOG: statement: set local
max_parallel_workers_per_gather= 2;
> 2023-04-08 12:25:28.710 UTC [18027:323] pg_regress/join_hash LOG: statement: explain (costs off)
> select count(*) from simple r full outer join simple s on (r.id = 0 - s.id);
> 2023-04-08 12:25:28.710 UTC [18027:324] pg_regress/join_hash LOG: statement: select count(*) from simple r full
outerjoin simple s on (r.id = 0 - s.id);
> TRAP: failed Assert("BarrierParticipants(&batch->batch_barrier) == 1"), File: "nodeHash.c", Line: 2118, PID: 19147
> postgres: parallel worker for PID 18027 (ExceptionalCondition+0x84)[0x10ae2bfa4]
> postgres: parallel worker for PID 18027 (ExecParallelPrepHashTableForUnmatched+0x224)[0x10aa67544]
> postgres: parallel worker for PID 18027 (+0x3db868)[0x10aa6b868]
> postgres: parallel worker for PID 18027 (+0x3c4204)[0x10aa54204]
> postgres: parallel worker for PID 18027 (+0x3c81b8)[0x10aa581b8]
> postgres: parallel worker for PID 18027 (+0x3b3d28)[0x10aa43d28]
> postgres: parallel worker for PID 18027 (standard_ExecutorRun+0x208)[0x10aa39768]
> postgres: parallel worker for PID 18027 (ParallelQueryMain+0x2bc)[0x10aa4092c]
> postgres: parallel worker for PID 18027 (ParallelWorkerMain+0x660)[0x10a874870]
> postgres: parallel worker for PID 18027 (StartBackgroundWorker+0x2a8)[0x10ab8abf8]
> postgres: parallel worker for PID 18027 (+0x50290c)[0x10ab9290c]
> postgres: parallel worker for PID 18027 (+0x5035e4)[0x10ab935e4]
> postgres: parallel worker for PID 18027 (PostmasterMain+0x1304)[0x10ab96334]
> postgres: parallel worker for PID 18027 (main+0x86c)[0x10a79daec]
Having not done much debugging on buildfarm animals before, I don't
suppose there is any way to get access to the core itself? I'd like to
see how many participants the batch barrier had at the time of the
assertion failure. I assume it was 2, but I just wanted to make sure I
understand the race.
- Melanie
Melanie Plageman <melanieplageman@gmail.com> writes:
> Having not done much debugging on buildfarm animals before, I don't
> suppose there is any way to get access to the core itself? I'd like to
> see how many participants the batch barrier had at the time of the
> assertion failure. I assume it was 2, but I just wanted to make sure I
> understand the race.
I don't know about chimaera in particular, but buildfarm animals are
not typically configured to save any build products. They'd run out
of disk space after awhile :-(.
If you think the number of participants would be useful data, I'd
suggest replacing that Assert with an elog() that prints what you
want to know.
regards, tom lane
On Sat, Apr 8, 2023 at 1:30 PM Melanie Plageman
<melanieplageman@gmail.com> wrote:
>
> On Sat, Apr 8, 2023 at 12:33 PM Tom Lane <tgl@sss.pgh.pa.us> wrote:
> >
> > Thomas Munro <thomas.munro@gmail.com> writes:
> > > I committed the main patch.
> >
> > BTW, it was easy to miss in all the buildfarm noise from
> > last-possible-minute patches, but chimaera just showed something
> > that looks like a bug in this code [1]:
> >
> > 2023-04-08 12:25:28.709 UTC [18027:321] pg_regress/join_hash LOG: statement: savepoint settings;
> > 2023-04-08 12:25:28.709 UTC [18027:322] pg_regress/join_hash LOG: statement: set local
max_parallel_workers_per_gather= 2;
> > 2023-04-08 12:25:28.710 UTC [18027:323] pg_regress/join_hash LOG: statement: explain (costs off)
> > select count(*) from simple r full outer join simple s on (r.id = 0 - s.id);
> > 2023-04-08 12:25:28.710 UTC [18027:324] pg_regress/join_hash LOG: statement: select count(*) from simple r full
outerjoin simple s on (r.id = 0 - s.id);
> > TRAP: failed Assert("BarrierParticipants(&batch->batch_barrier) == 1"), File: "nodeHash.c", Line: 2118, PID: 19147
So, after staring at this for awhile, I suspect this assertion is just
plain wrong. BarrierArriveAndDetachExceptLast() contains this code:
if (barrier->participants > 1)
{
--barrier->participants;
SpinLockRelease(&barrier->mutex);
return false;
}
Assert(barrier->participants == 1);
So in between this assertion and the one we tripped,
if (!BarrierArriveAndDetachExceptLast(&batch->batch_barrier))
{
...
return false;
}
/* Now we are alone with this batch. */
Assert(BarrierPhase(&batch->batch_barrier) == PHJ_BATCH_SCAN);
Assert(BarrierParticipants(&batch->batch_barrier) == 1);
Another worker attached to the batch barrier, saw that it was in
PHJ_BATCH_SCAN, marked it done and detached. This is fine.
BarrierArriveAndDetachExceptLast() is meant to ensure no one waits
(deadlock hazard) and that at least one worker stays to do the unmatched
scan. It doesn't hurt anything for another worker to join and find out
there is no work to do.
We should simply delete this assertion.
- Melanie
On Sat, Apr 08, 2023 at 02:19:54PM -0400, Melanie Plageman wrote: > Another worker attached to the batch barrier, saw that it was in > PHJ_BATCH_SCAN, marked it done and detached. This is fine. > BarrierArriveAndDetachExceptLast() is meant to ensure no one waits > (deadlock hazard) and that at least one worker stays to do the unmatched > scan. It doesn't hurt anything for another worker to join and find out > there is no work to do. > > We should simply delete this assertion. I have added an open item about that. This had better be tracked. -- Michael
Attachment
On Mon, Apr 10, 2023 at 11:33 AM Michael Paquier <michael@paquier.xyz> wrote: > On Sat, Apr 08, 2023 at 02:19:54PM -0400, Melanie Plageman wrote: > > Another worker attached to the batch barrier, saw that it was in > > PHJ_BATCH_SCAN, marked it done and detached. This is fine. > > BarrierArriveAndDetachExceptLast() is meant to ensure no one waits > > (deadlock hazard) and that at least one worker stays to do the unmatched > > scan. It doesn't hurt anything for another worker to join and find out > > there is no work to do. > > > > We should simply delete this assertion. Agreed, and pushed. Thanks! > I have added an open item about that. This had better be tracked. Thanks, will update.