Thread: Massive parallel queue table causes index deterioration, but REINDEX fails with deadlocks.
Massive parallel queue table causes index deterioration, but REINDEX fails with deadlocks.
Hi,
I am using an SQL queue for distributing work to massively parallel workers. Workers come in servers with 12 parallel threads. One of those worker sets handles 7 transactions per second. If I add a second one, for 24 parallel workers, it scales to 14 /s. Even a third, for 36 parallel workers, I can add to reach 21 /s. If I try a fourth set, 48 workers, I end up in trouble. But that isn't even so much my problem rather than the fact that in short time, the performance will deteriorate, and it looks like that is because the queue index deteriorates and needs a REINDEX. The queue table is essentially this:
CREATE TABLE Queue ( jobId bigint, action text, pending boolean, result text );
the dequeue operation is essentially this:
BEGIN SELECT jobId, action FROM Queue WHERE pending FOR UPDATE SKIP LOCKED
which is a wonderful concept with the SKIP LOCKED.
Then I perform the action and finally:
UPDATE Queue SET pending = false, result = ? WHERE jobId = ? COMMIT
I thought to keep my index tight, I would define it like this:
CREATE UNIQUE INDEX Queue_idx_pending ON Queue(jobId) WHERE pending;
so that only pending jobs are in that index.
When a job is done, follow up work is often inserted into the Queue as pending, thus adding to that index.
Below is the performance chart.
The blue line at the bottom is the db server.
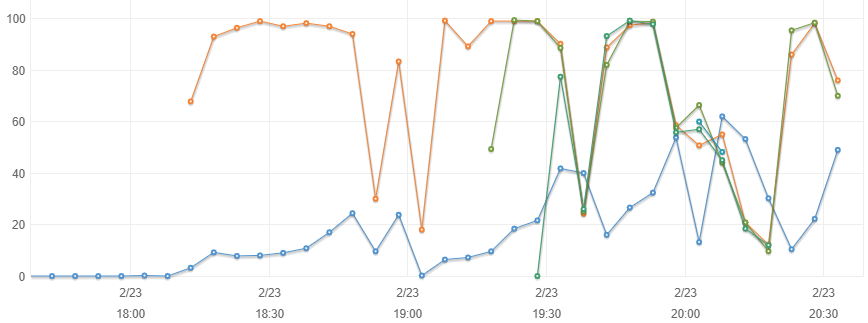
You can see the orange line is the first worker server with 12 threads. It settled into a steady state of 7/s ran with 90% CPU for some 30 min, and then the database CPU% started climbing and I tried to rebuild the indexes on the queue, got stuck there, exclusive lock, no jobs were processing, but the exclusive lock was never obtained for too long. So I shut down the worker server. Database quiet I could resolve the messed up indexes and restarted again. Soon I added a second worker server (green line) starting around 19:15. Once settled in they were pulling 14/s together. but you can see in just 15 min, the db server CPU % climbed again to over 40% and the performance of the workers dropped, their load falling to 30%. Now at around 19:30 I stopped them all, REINDEXed the queue table and then started 3 workers servers simultaneously. They settled in to 21/s but in just 10 min again the deterioration happened. Again I stopped them all, REINDEXed, and now started 4 worker servers (48 threads). This time 5 min was not enough to see them ever settling into a decent 28/s transaction rate, but I guess they might have reached that for a minute or two, only for the index deteriorating again. I did another stop now started only 2 servers and again, soon the index deteriorated again.
Clearly that index is deteriorating quickly, in about 10,000 transactions.
BTW: when I said 7/s, it is in reality about 4 times as many transactions, because of the follow up jobs that also get added on this queue. So 10,0000 transactions may be 30 or 40 k transactions before the index deteriorates.
Do you have any suggestion how I can avoid that index deterioration problem smoothly?
I figured I might just pause all workers briefly to schedule the REINDEX Queue command, but the problem with this is that while the transaction volume is large, some jobs may take minutes to process, and in that case we need to wait minutes to quiet the database with then 47 workers sitting as idle capacity waiting for the 48th to finish so that the index can be rebuilt!
Of course I tried to resolve the issue with vacuumdb --analyze (just in case if the autovacuum doesn't act in time) and that doesn't help. Vacuumdb --full --analyze would probably help but can't work because it required an exclusive table lock. I tried to just create a new index of the same
CREATE UNIQUE INDEX Queue_idx2_pending ON Queue(jobId) WHERE pending; DROP INDEX Queue_idx_pending; ANALYZE Queue;
but with that I got completely stuck with two indexes where I could not remove either of them for those locking issues. And REINDEX will give me a deadlock error rightout.
I am looking for a way to manage that index so that it does not deteriorate.
May be if I was not defining it with
... WHERE pending;
then it would only grow, but never shrink. May be that helps somehow? I doubt it though. Adding to an index also causes deterioration, and most of the rows would be irrelevant because they would be past work. It would be nicer if there was another smooth way.
regards,
-Gunther
Attachment
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
On Sat, Feb 23, 2019 at 1:06 PM Gunther <raj@gusw.net> wrote: > I thought to keep my index tight, I would define it like this: > > CREATE UNIQUE INDEX Queue_idx_pending ON Queue(jobId) WHERE pending; > > so that only pending jobs are in that index. > > When a job is done, follow up work is often inserted into the Queue as pending, thus adding to that index. How many distinct jobIds are there in play, roughly? Would you say that there are many fewer distinct Jobs than distinct entries in the index/table? Is the number of jobs fixed at a fairly low number, that doesn't really grow as the workload needs to scale up? -- Peter Geoghegan
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
On 2/23/2019 16:13, Peter Geoghegan wrote: > On Sat, Feb 23, 2019 at 1:06 PM Gunther <raj@gusw.net> wrote: >> I thought to keep my index tight, I would define it like this: >> >> CREATE UNIQUE INDEX Queue_idx_pending ON Queue(jobId) WHERE pending; >> >> so that only pending jobs are in that index. >> >> When a job is done, follow up work is often inserted into the Queue as pending, thus adding to that index. > How many distinct jobIds are there in play, roughly? Would you say > that there are many fewer distinct Jobs than distinct entries in the > index/table? Is the number of jobs fixed at a fairly low number, that > doesn't really grow as the workload needs to scale up? Jobs start on another, external queue, there were about 200,000 of them waiting when I started the run. When the SQL Queue is empty, the workers pick one job from the external queue and add it to the SQL queue. When that happens immediately 2 more jobs are created on that queue. Let's cal it phase 1 a and b When phase 1 a has been worked off, another follow-up job is created. Let' s call it phase 2. When phase 2 has been worked off, a final phase 3 job is created. When that is worked off, nothing new is created, and the next item is pulled from the external queue and added to the SQL queue. So this means, each of the 200,000 items add (up to) 4 jobs onto the queue during their processing. But since these 200,000 items are on an external queue, the SQL queue itself is not stuffed full at all. It only slowly grows, and on the main index where we have only the pending jobs, there are only probably than 20 at any given point in time. When I said 7 jobs per second, it meant 7/s simultaneously for all these 3+1 phases, i.e., 28 jobs per second. And at that rate it takes little less than 30 min for the index to deteriorate. I.e. once about 50,000 queue entries have been processed through that index it has deteriorated to become nearly unusable until it is rebuilt. thanks, -Gunther
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
On Sun, 24 Feb 2019 at 10:06, Gunther <raj@gusw.net> wrote: > I am using an SQL queue for distributing work to massively parallel workers. Workers come in servers with 12 parallel threads.One of those worker sets handles 7 transactions per second. If I add a second one, for 24 parallel workers, it scalesto 14 /s. Even a third, for 36 parallel workers, I can add to reach 21 /s. If I try a fourth set, 48 workers, I endup in trouble. But that isn't even so much my problem rather than the fact that in short time, the performance will deteriorate,and it looks like that is because the queue index deteriorates and needs a REINDEX. It sounds very much like auto-vacuum is simply unable to keep up with the rate at which the table is being updated. Please be aware, that by default, auto-vacuum is configured to run fairly slowly so as not to saturate low-end machines. vacuum_cost_limit / autovacuum_vacuum_cost limit control how many "points" the vacuum process can accumulate before it will perform an autovacuum_vacuum_cost_delay / vacuum_cost_delay. Additionally, after an auto-vacuum run completes it will wait for autovacuum_naptime before checking again if any tables require some attention. I think you should be monitoring how many auto-vacuums workers are busy during your runs. If you find that the "queue" table is being vacuumed almost constantly, then you'll likely want to increase vacuum_cost_limit / autovacuum_vacuum_cost_limit. You could get an idea of how often this table is being auto-vacuumed by setting log_autovacuum_min_duration to 0 and checking the logs. Another way to check would be to sample what: SELECT query FROM pg_stat_activity WHERE query LIKE 'autovacuum%'; returns. You may find that all of the workers are busy most of the time. If so, that indicates that the cost limits need to be raised. -- David Rowley http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training & Services
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Some ideas: You could ALTER TABLE SET (fillfactor=50) to try to maximize use of HOT indices during UPDATEs (check pg_stat_user_indexes). You could also ALTER TABLE SET autovacuum parameters for more aggressive vacuuming. You could recreate indices using the CONCURRENTLY trick (CREATE INDEX CONCURRENTLY new; DROP old; ALTER .. RENAME;) On Sat, Feb 23, 2019 at 04:05:51PM -0500, Gunther wrote: > I am using an SQL queue for distributing work to massively parallel workers. > Workers come in servers with 12 parallel threads. One of those worker sets > handles 7 transactions per second. If I add a second one, for 24 parallel > workers, it scales to 14 /s. Even a third, for 36 parallel workers, I can > add to reach 21 /s. If I try a fourth set, 48 workers, I end up in trouble. > But that isn't even so much my problem rather than the fact that in short > time, the performance will deteriorate, and it looks like that is because > the queue index deteriorates and needs a REINDEX. > > The queue table is essentially this: > > CREATE TABLE Queue ( > jobId bigint, > action text, > pending boolean, > result text > ); > > the dequeue operation is essentially this: > > BEGIN > > SELECT jobId, action > FROM Queue > WHERE pending > FOR UPDATE SKIP LOCKED > > which is a wonderful concept with the SKIP LOCKED. > > Then I perform the action and finally: > > UPDATE Queue > SET pending = false, > result = ? > WHERE jobId = ? > > COMMIT > > I thought to keep my index tight, I would define it like this: > > CREATE UNIQUE INDEX Queue_idx_pending ON Queue(jobId) WHERE pending; > > so that only pending jobs are in that index. > > When a job is done, follow up work is often inserted into the Queue as > pending, thus adding to that index. > > Below is the performance chart. > > The blue line at the bottom is the db server. > > > You can see the orange line is the first worker server with 12 threads. It > settled into a steady state of 7/s ran with 90% CPU for some 30 min, and > then the database CPU% started climbing and I tried to rebuild the indexes > on the queue, got stuck there, exclusive lock, no jobs were processing, but > the exclusive lock was never obtained for too long. So I shut down the > worker server. Database quiet I could resolve the messed up indexes and > restarted again. Soon I added a second worker server (green line) starting > around 19:15. Once settled in they were pulling 14/s together. but you can > see in just 15 min, the db server CPU % climbed again to over 40% and the > performance of the workers dropped, their load falling to 30%. Now at around > 19:30 I stopped them all, REINDEXed the queue table and then started 3 > workers servers simultaneously. They settled in to 21/s but in just 10 min > again the deterioration happened. Again I stopped them all, REINDEXed, and > now started 4 worker servers (48 threads). This time 5 min was not enough to > see them ever settling into a decent 28/s transaction rate, but I guess they > might have reached that for a minute or two, only for the index > deteriorating again. I did another stop now started only 2 servers and > again, soon the index deteriorated again. > > Clearly that index is deteriorating quickly, in about 10,000 transactions. > > BTW: when I said 7/s, it is in reality about 4 times as many transactions, > because of the follow up jobs that also get added on this queue. So 10,0000 > transactions may be 30 or 40 k transactions before the index deteriorates. > > Do you have any suggestion how I can avoid that index deterioration problem > smoothly? > > I figured I might just pause all workers briefly to schedule the REINDEX > Queue command, but the problem with this is that while the transaction > volume is large, some jobs may take minutes to process, and in that case we > need to wait minutes to quiet the database with then 47 workers sitting as > idle capacity waiting for the 48th to finish so that the index can be > rebuilt! > > Of course I tried to resolve the issue with vacuumdb --analyze (just in case > if the autovacuum doesn't act in time) and that doesn't help. Vacuumdb > --full --analyze would probably help but can't work because it required an > exclusive table lock. > > I tried to just create a new index of the same > > CREATE UNIQUE INDEX Queue_idx2_pending ON Queue(jobId) WHERE pending; > DROP INDEX Queue_idx_pending; > ANALYZE Queue; > > but with that I got completely stuck with two indexes where I could not > remove either of them for those locking issues. And REINDEX will give me a > deadlock error rightout. > > I am looking for a way to manage that index so that it does not deteriorate. > > May be if I was not defining it with > > ... WHERE pending; > > then it would only grow, but never shrink. May be that helps somehow? I > doubt it though. Adding to an index also causes deterioration, and most of > the rows would be irrelevant because they would be past work. It would be > nicer if there was another smooth way.
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Some ideas:
You could ALTER TABLE SET (fillfactor=50) to try to maximize use of HOT indices
during UPDATEs (check pg_stat_user_indexes).
You could also ALTER TABLE SET autovacuum parameters for more aggressive vacuuming.
You could recreate indices using the CONCURRENTLY trick
(CREATE INDEX CONCURRENTLY new; DROP old; ALTER .. RENAME;)
One manual VACUUM FREEZE coupled with lowering the vacuum sensitivity on that one table helps quite a bit by increasing the frequency shortening the runtimes of autovacuums, but it's not a total solution.
My next step is to partition the table on the "active" boolean flag, which eliminates the need for the partial indexes, and allows for different fillfactor for each partition (50 for true, 100 for false). This should also aid vacuum speed and make re-indexing the hot partition much faster. However, we have to upgrade to v11 first to enable row migration, so I can't yet report on how much of a solution that is.
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Thank you all for responding so far.
David Rowley and Justin Pryzby suggested things about autovacuum. But I don't think autovacuum has any helpful role here. I am explicitly doing a vacuum on that table. And it doesn't help at all. Almost not at all.
I want to believe that
VACUUM FREEZE Queue;
will push the database CPU% down again once it is climbing up, and I can do this may be 3 to 4 times, but ultimately I will always have to rebuild the index. But also, none of these vaccuum operations I do takes very long at all. It is just not efficacious at all.
Rebuilding the index by building a new index and removing the old, then rename, and vacuum again, is prone to get stuck.
I tried to do it in a transaction. But it says CREATE INDEX can't be done in a transaction.
Need to CREATE INDEX CONCURRENTLY ... and I can't even do that in a procedure.
If I do it manually by issuing first CREATE INDEX CONCURRENTLY new and then DROP INDEX CONCURRENTLY old, it might work once, but usually it just gets stuck with two indexes. Although I noticed that it would actually put CPU back down and improve transaction throughput.
I also noticed that after I quit from DROP INDEX CONCURRENTLY old, that index is shown as INVALID
\d Queue... Indexes: "queue_idx_pending" UNIQUE, btree (jobId, action) WHERE pending INVALID "queue_idx_pending2" UNIQUE, btree (jobId, action) WHERE pending INVALID "queue_idx_pending3" UNIQUE, btree (jobId, action) WHERE pending INVALID "queue_idx_pending4" UNIQUE, btree (jobId, action) WHERE pending INVALID "queue_idx_pending5" UNIQUE, btree (jobId, action) WHERE pending INVALID "queue_idx_pending6" UNIQUE, btree (jobId, action) WHERE pending ...
and so I keep doing that same routine hands-on, every time that the CPU% creeps above 50% I do
CREATE UNIQUE INDEX CONCURRENTLY Queue_idx_pending6 ON Queue(jobId, action) WHERE currentlyOpen; DROP INDEX CONCURRENTLY Queue_idx_pending5;
at which place it hangs, I interrupt the DROP command, which leaves the old index behind as "INVALID".
VACUUM FREEZE ANALYZE Queue;
At this point the db's CPU% dropping below 20% after the new index has been built.
Unfortunately this is totally hands on approach I have to do this every 5 minutes or so. And possibly the time between these necessities decreases. It also leads to inefficiency over time, even despite the CPU seemingly recovering.
So this isn't sustainable like that (worse because my Internet constantly drops).
What I am most puzzled by is that no matter how long I wait, the DROP INDEX CONCURRENTLY never completes. Why is that?
Also, the REINDEX command always fails with a deadlock because there is a row lock and a complete table lock involved.
I consider this ultimately a bug, or at the very least there is room for improvement. And I am on version 11.1.
regards,
-Gunther
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
On Sun, Feb 24, 2019 at 12:45:34PM -0500, Gunther wrote: > What I am most puzzled by is that no matter how long I wait, the DROP INDEX > CONCURRENTLY never completes. Why is that? https://www.postgresql.org/docs/11/sql-dropindex.html CONCURRENTLY [...] With this option, the command instead waits until conflicting transactions have completed. Do you have a longrunning txn ? That's possibly the cause of the original issue; vacuum cannot mark tuples as dead until txns have finished. > I consider this ultimately a bug, or at the very least there is room for > improvement. And I am on version 11.1. Did you try upgrading to 11.2 ? I suspect this doesn't affect the query plan..but may be relevant? https://www.postgresql.org/docs/11/release-11-2.html |Improve ANALYZE's handling of concurrently-updated rows (Jeff Janes, Tom Lane) | |Previously, rows deleted by an in-progress transaction were omitted from ANALYZE's sample, but this has been found to leadto more inconsistency than including them would do. In effect, the sample now corresponds to an MVCC snapshot as of ANALYZE'sstart time. Justin
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
On Sun, Feb 24, 2019 at 10:02 AM Gunther <raj@gusw.net> wrote: > David Rowley and Justin Pryzby suggested things about autovacuum. But I don't think autovacuum has any helpful role here. My suspicion is that this has something to do with the behavior of B-Tree indexes with lots of duplicates. See also: https://www.postgresql.org/message-id/flat/CAH2-Wznf1uVBguutwrvR%2B6NcXTKYhagvNOY3-dg9dzcYiu_vKw%40mail.gmail.com#993f152a41a1e2c257d12d118aa7ebfc I am working on a patch to address the problem which is slated for Postgres 12. I give an illustrative example of one of the problems that my patch addresses here (it actually addresses a number of distinct issues all at once): https://postgr.es/m/CAH2-Wzmf0fvVhU+SSZpGW4Qe9t--j_DmXdX3it5JcdB8FF2EsA@mail.gmail.com Do you think that that could be a significant factor here? I found your response to my initial questions unclear. Using a Postgres table as a queue is known to create particular problems with bloat, especially index bloat. Fixing the underlying behavior in the nbtree code would likely sharply limit the growth in index bloat over time, though it still may not make queue-like tables completely painless to operate. The problem is described in high level terms from a user's perspective here: https://brandur.org/postgres-queues -- Peter Geoghegan
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Also, the REINDEX command always fails with a deadlock because there is a row lock and a complete table lock involved.
I consider this ultimately a bug, or at the very least there is room for improvement. And I am on version 11.1.
regards,
-Gunther
REINDEX doesn't work concurrently yet (slated for v12).
I think your solution may be something like this:
1. Create a new table, same columns, partitioned on the pending column.
2. Rename your existing queue table old_queue to the partitioned table as a default partition.
3. Rename new table to queue
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
On Sun, Feb 24, 2019 at 04:34:34PM -0500, Corey Huinker wrote: > I think your solution may be something like this: > 1. Create a new table, same columns, partitioned on the pending column. > 2. Rename your existing queue table old_queue to the partitioned table as a > default partition. > 3. Rename new table to queue > 4. add old_queue as the default partition of queue > 5. add a new partition for pending = true rows, set the fillfactor kind of FYI, the "default partition" isn't just for various and sundry uncategorized tuples (like a relkind='r' inheritence without any constraint). It's for "tuples which are excluded by every other partition". And "row migration" doesn't happen during "ALTER..ATTACH", only UPDATE. So you'll be unable to attach a partition for pending=true if the default partition includes any such rows: |ERROR: updated partition constraint for default partition "t0" would be violated by some row I think you'll need to schedule a maintenance window, create a new partitioned heirarchy, and INSERT INTO queue SELECT * FROM old_queue, or similar. Justin
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
On Sun, Feb 24, 2019 at 04:34:34PM -0500, Corey Huinker wrote:
> I think your solution may be something like this:
> 1. Create a new table, same columns, partitioned on the pending column.
> 2. Rename your existing queue table old_queue to the partitioned table as a
> default partition.
> 3. Rename new table to queue
> 4. add old_queue as the default partition of queue
> 5. add a new partition for pending = true rows, set the fillfactor kind of
FYI, the "default partition" isn't just for various and sundry uncategorized
tuples (like a relkind='r' inheritence without any constraint). It's for
"tuples which are excluded by every other partition". And "row migration"
doesn't happen during "ALTER..ATTACH", only UPDATE. So you'll be unable to
attach a partition for pending=true if the default partition includes any such
rows:
|ERROR: updated partition constraint for default partition "t0" would be violated by some row
I think you'll need to schedule a maintenance window, create a new partitioned
heirarchy, and INSERT INTO queue SELECT * FROM old_queue, or similar.
Justin
Good point, I forgot about that. I had also considered making a partitioned table, adding a "true" partition to that, and then making the partitioned table an inheritance partition of the existing table, then siphoning off rows from the original table until such time as it has no more pending rows, then doing a transaction where you de-inherit the partitioned table, and then attach the original table as the false partition. It's all a lot of acrobatics to try to minimize downtime and it could be done better by having a longer maintenance window, but I got the impression from the OP that big windows were not to be had.
Re: Massive parallel queue table causes index deterioration, but REINDEX fails with deadlocks.
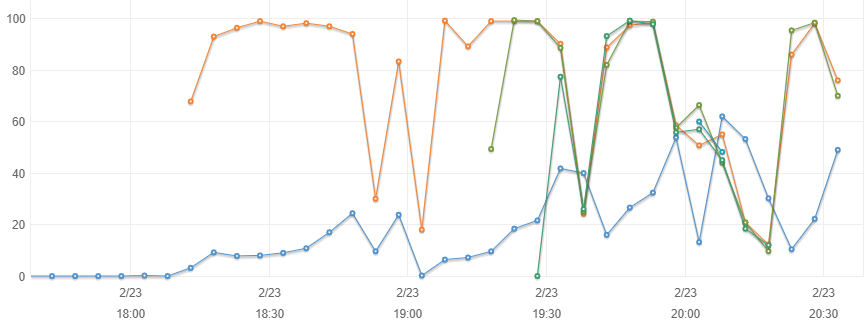
the dequeue operation is essentially this:
BEGIN SELECT jobId, action FROM Queue WHERE pending FOR UPDATE SKIP LOCKED
Attachment
{kind=link}
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Thank you all for responding so far.
David Rowley and Justin Pryzby suggested things about autovacuum. But I don't think autovacuum has any helpful role here. I am explicitly doing a vacuum on that table. And it doesn't help at all. Almost not at all.
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Wow, yes, partition instead of index, that is interesting. Thanks Corey and Justin.
The index isn't required at all if all my pending jobs are in a partition of only pending jobs. In that case the plan can just be a sequential scan.
And Jeff James, sorry, I failed to show the LIMIT 1 clause on my dequeue query. That was an omission. My query is actually somewhat more complex and I just translated it down to the essentials but forgot the LIMIT 1 clause.
SELECT seqNo, action FROM QueueWHERE pending AND ... other criteria ...LIMIT 1FOR UPDATE SKIP LOCKED;
And sorry I didn't capture the stats for vacuum verbose. And they would be confusing because there are other things involved.
Anyway, I think the partitioned table is the right and brilliant solution, because an index really isn't required. The actual pending partition will always remain quite small, and being a queue, it doesn't even matter how big it might grow, as long as new rows are inserted at the end and not in the middle of the data file and still there be some way of fast skip over the part of the dead rows at the beginning that have already been processed and moved away.
Good thing is, I don't worry about maintenance window. I have the leisure to simply tear down my design now and make a better design. What's 2 million transactions if I can re-process them at a rate of 80/s? 7 hours max. I am still in development. So, no need to worry about migration / transition acrobatics. So if I take Corey's steps and envision the final result, not worrying about the transition steps, then I understand this:
1. Create the Queue table partitioned on the pending column, this creates the partition with the pending jobs (on which I set the fillfactor kind of low, maybe 50) and the default partition with all the rest. Of course that allows people with a constant transaction volume to also partition on jobId or completionTime and move chunks out to cold archive storage. But that's beside the current point.
-Gunther
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Wow, yes, partition instead of index, that is interesting. Thanks Corey and Justin.
The index isn't required at all if all my pending jobs are in a partition of only pending jobs. In that case the plan can just be a sequential scan.
And Jeff James, sorry, I failed to show the LIMIT 1 clause on my dequeue query. That was an omission. My query is actually somewhat more complex and I just translated it down to the essentials but forgot the LIMIT 1 clause.
SELECT seqNo, action FROM QueueWHERE pending AND ... other criteria ...LIMIT 1FOR UPDATE SKIP LOCKED;
And sorry I didn't capture the stats for vacuum verbose. And they would be confusing because there are other things involved.
Anyway, I think the partitioned table is the right and brilliant solution, because an index really isn't required. The actual pending partition will always remain quite small, and being a queue, it doesn't even matter how big it might grow, as long as new rows are inserted at the end and not in the middle of the data file and still there be some way of fast skip over the part of the dead rows at the beginning that have already been processed and moved away.
Good thing is, I don't worry about maintenance window. I have the leisure to simply tear down my design now and make a better design. What's 2 million transactions if I can re-process them at a rate of 80/s? 7 hours max. I am still in development. So, no need to worry about migration / transition acrobatics. So if I take Corey's steps and envision the final result, not worrying about the transition steps, then I understand this:
1. Create the Queue table partitioned on the pending column, this creates the partition with the pending jobs (on which I set the fillfactor kind of low, maybe 50) and the default partition with all the rest. Of course that allows people with a constant transaction volume to also partition on jobId or completionTime and move chunks out to cold archive storage. But that's beside the current point.
-Gunther
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
On Sun, Feb 24, 2019 at 10:06:10PM -0500, Gunther wrote: > The index isn't required at all if all my pending jobs are in a partition of > only pending jobs. In that case the plan can just be a sequential scan. .. > because an index really isn't required. The actual pending partition will > always remain quite small, and being a queue, it doesn't even matter how big > it might grow, as long as new rows are inserted at the end and not in the > middle of the data file and still there be some way of fast skip over the > part of the dead rows at the beginning that have already been processed and > moved away. .. > One question I have though: I imagine our pending partition heap file to now > be essentially sequentially organized as a queue. New jobs are appended at > the end, old jobs are at the beginning. As pending jobs become completed > (pending = false) these initial rows will be marked as dead. So, while the > number of live rows will remain small in that pending partition, sequential > scans will have to skip over the dead rows in the beginning. > > Does PostgreSQL structure its files such that skipping over dead rows is > fast? Or do the dead rows have to be read and discarded during a table scan? .. > Of course vacuum eliminates dead rows, but unless I do vacuum full, it will > not re-pack the live rows, and that requires an exclusive table lock. So, > what is the benefit of vacuuming that pending partition? What I _/don't/_ > want is insertion of new jobs to go into open slots at the beginning of the > file. I want them to be appended (in Oracle there is an INSERT /*+APPEND*/ > hint for that. How does that work in PostgreSQL? > > Ultimately that partition will amass too many dead rows, then what do I do? Why don't you want to reuse free space in the table ? When you UPDATE the tuples and set pending='f', the row will be moved to another partition, and the "dead" tuple in the pending partition can be reused for a future INSERT. The table will remain small, as you said, only as large as the number of items in the pending queue, plus tuples not yet vacuumed and not yet available for reuse. (BTW, index scans do intelligently skip over dead rows if the table/index are vacuumed sufficiently often). > 1. Create the Queue table partitioned on the pending column, this creates > the partition with the pending jobs (on which I set the fillfactor kind of > low, maybe 50) and the default partition with all the rest. Of course that > allows people with a constant transaction volume to also partition on jobId > or completionTime and move chunks out to cold archive storage. But that's > beside the current point. I suggest you might want to partition on something other than (or in addition to) the boolean column. For example, if you have a timestamp column for "date_processed", then the active queue would be for "processed IS NULL" (which I think would actually have to be the DEFAULT partition). Or you could use sub-partitioning, or partition on multiple columns (pending, date_processed) or similar. Justin
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Anyway, I think the partitioned table is the right and brilliant solution, because an index really isn't required. The actual pending partition will always remain quite small, and being a queue, it doesn't even matter how big it might grow, as long as new rows are inserted at the end and not in the middle of the data file and still there be some way of fast skip over the part of the dead rows at the beginning that have already been processed and moved away.Good thing is, I don't worry about maintenance window. I have the leisure to simply tear down my design now and make a better design. What's 2 million transactions if I can re-process them at a rate of 80/s? 7 hours max. I am still in development. So, no need to worry about migration / transition acrobatics. So if I take Corey's steps and envision the final result, not worrying about the transition steps, then I understand this:
1. Create the Queue table partitioned on the pending column, this creates the partition with the pending jobs (on which I set the fillfactor kind of low, maybe 50) and the default partition with all the rest. Of course that allows people with a constant transaction volume to also partition on jobId or completionTime and move chunks out to cold archive storage. But that's beside the current point.
One question I have though: I imagine our pending partition heap file to now be essentially sequentially organized as a queue. New jobs are appended at the end, old jobs are at the beginning. As pending jobs become completed (pending = false) these initial rows will be marked as dead. So, while the number of live rows will remain small in that pending partition, sequential scans will have to skip over the dead rows in the beginning.
Of course vacuum eliminates dead rows, but unless I do vacuum full, it will not re-pack the live rows, and that requires an exclusive table lock. So, what is the benefit of vacuuming that pending partition? What I don't want is insertion of new jobs to go into open slots at the beginning of the file. I want them to be appended (in Oracle there is an INSERT /*+APPEND*/ hint for that. How does that work in PostgreSQL?
Ultimately that partition will amass too many dead rows, then what do I do? I don't think that the OS has a way to truncate files physically from the head, does it? I guess it could set the file pointer from the first block to a later block. But I don't know of an IOCTL/FCNTL command for that. On some OS there is a way of making blocks sparse again, is that how PostgreSQL might do it? Just knock out blocks as sparse from the front of the file?
Re: Massive parallel queue table causes index deterioration, but REINDEX fails with deadlocks.
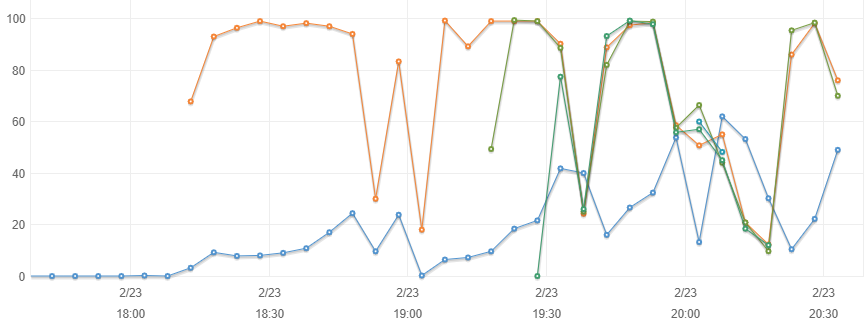
Hi,
I am using an SQL queue for distributing work to massively parallel workers.
I figured I might just pause all workers briefly to schedule the REINDEX Queue command, but the problem with this is that while the transaction volume is large, some jobs may take minutes to process, and in that case we need to wait minutes to quiet the database with then 47 workers sitting as idle capacity waiting for the 48th to finish so that the index can be rebuilt!
Attachment
{kind=link}
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Anyway, I think the partitioned table is the right and brilliant solution, because an index really isn't required. The actual pending partition will always remain quite small, and being a queue, it doesn't even matter how big it might grow, as long as new rows are inserted at the end and not in the middle of the data file and still there be some way of fast skip over the part of the dead rows at the beginning that have already been processed and moved away.
Re: Massive parallel queue table causes index deterioration, butREINDEX fails with deadlocks.
Regards,
Michael Vitale
Monday, February 25, 2019 3:30 PMOn Sat, Feb 23, 2019 at 4:06 PM Gunther <raj@gusw.net> wrote:Hi,
I am using an SQL queue for distributing work to massively parallel workers.
You should look into specialized queueing software....I figured I might just pause all workers briefly to schedule the REINDEX Queue command, but the problem with this is that while the transaction volume is large, some jobs may take minutes to process, and in that case we need to wait minutes to quiet the database with then 47 workers sitting as idle capacity waiting for the 48th to finish so that the index can be rebuilt!
The jobs that take minutes are themselves the problem. They prevent tuples from being cleaned up, meaning all the other jobs needs to grovel through the detritus every time they need to claim a new row. If you got those long running jobs to end, you probably wouldn't even need to reindex--the problem would go away on its own as the dead-to-all tuples get cleaned up.Locking a tuple and leaving the transaction open for minutes is going to cause no end of trouble on a highly active system. You should look at a three-state method where the tuple can be pending/claimed/finished, rather than pending/locked/finished. That way the process commits immediately after claiming the tuple, and then records the outcome in another transaction once it is done processing. You will need a way to detect processes that failed after claiming a row but before finishing, but implementing that is going to be easier than all of this re-indexing stuff you are trying to do now. You would claim the row by updating a field in it to have something distinctive about the process, like its hostname and pid, so you can figure out if it is still running when it comes time to clean up apparently forgotten entries.Cheers,Jeff