Thread: cost_sort() improvements
Hi!
Current estimation of sort cost has following issues:
- it doesn't differ one and many columns sort
- it doesn't pay attention to comparison function cost and column width
- it doesn't try to count number of calls of comparison function on per column
basis
At least [1] and [2] hit into to that issues and have an objections/questions
about correctness of cost sort estimation. Suggested patch tries to improve
current estimation and solve that issues.
Basic ideas:
- let me introduce some designations
i - index of column, started with 1
N - number of tuples to sort
Gi - number of groups, calculated by i number columns. Obviously,
G0 == 1. Number of groups is caculated by estimate_num_groups().
NGi - number of tuples in one group. NG0 == N and NGi = N/G(i-1)
Fi - cost of comparison function call of i-th column
Wi - average width in bytes of 1-ith column.
Ci - total cost of one comparison call of column calculated as
Fi * fine_function(Wi) where fine_function(Wi) looks like:
if (Wi <= sizeof(Datum))
return 1.0; //any type passed in Datum
else
return 1 + log16(Wi/sizeof(Datum));
log16 just an empirical choice
- So, cost for first column is 2.0 * C0 * log2(N)
First column is always compared, multiplier 2.0 is defined per regression
test. Seems, it estimates a cost for transferring tuple to CPU cache,
starting cost for unpacking tuple, cost of call qsort compare wrapper
function, etc. Removing this multiplier causes too optimistic prediction of
cost.
- cost for i-th columns:
Ci * log2(NGi) => Ci * log2(N/G(i-1))
So, here I believe, that i-th comparison function will be called only inside
group which number is defined by (i-1) leading columns. Note, following
discussion [1] I add multiplier 1.5 here to be closer to worst case when
groups are significantly differ. Right now there is no way to determine how
differ they could be. Note, this formula describes cost of first column too
except difference with multiplier.
- Final cost is cpu_operator_cost * N * sum(per column costs described above).
Note, for single column with width <= sizeof(datum) and F1 = 1 this formula
gives exactly the same result as current one.
- for Top-N sort empiric is close to old one: use 2.0 multiplier as constant
under log2, and use log2(Min(NGi, output_tuples)) for second and following
columns.
I believe, suggested method could be easy enhanced to support [1] and used in [2].
Open items:
- Fake Var. I faced with generate_append_tlist() which generates Var with
varno = 0, it was invented, as I can see, at 2002 with comment 'should be
changed in future'. Future hasn't yet come... I've added workaround to
prevent call estimate_num_group() with such Vars, but I'm not sure that is
enough.
- Costs of all comparison functions now are the same and equal to 1. May be,
it's time to change that.
- Empiric constants. I know, it's impossible to remove them at all, but, may
be, we need to find better estimation of them.
[1] https://commitfest.postgresql.org/18/1124/
[2] https://commitfest.postgresql.org/18/1651/
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
Attachment
On Thu, Jun 28, 2018 at 9:47 AM, Teodor Sigaev <teodor@sigaev.ru> wrote: > Current estimation of sort cost has following issues: > - it doesn't differ one and many columns sort > - it doesn't pay attention to comparison function cost and column width > - it doesn't try to count number of calls of comparison function on per > column > basis I've been suspicious of the arbitrary way in which I/O for external sorts is costed by cost_sort() for a long time. I'm not 100% sure about how we should think about this question, but I am sure that it needs to be improved in *some* way. It's really not difficult to show that external sorts are now often faster than internal sorts, because they're able to be completed on-the-fly, which can have very good CPU cache characteristics, and because the I/O latency can be hidden fairly well much of the time. Of course, as memory is taken away, external sorts will eventually get slower and slower, but it's surprising how little difference it makes. (This makes me tempted to look into a sort_mem GUC, even though I suspect that that will be controversial.) Clearly there is a cost to doing I/O even when an external sort is faster than an internal sort "in isolation"; I/O does not magically become something that we don't have to worry about. However, the I/O cost seems more and more like a distributed cost. We don't really have a way of thinking about that at all. I'm not sure if that much bigger problem needs to be addressed before this specific problem with cost_sort() can be addressed. -- Peter Geoghegan
Peter Geoghegan wrote:
> On Thu, Jun 28, 2018 at 9:47 AM, Teodor Sigaev <teodor@sigaev.ru> wrote:
>> Current estimation of sort cost has following issues:
>> - it doesn't differ one and many columns sort
>> - it doesn't pay attention to comparison function cost and column width
>> - it doesn't try to count number of calls of comparison function on per
>> column
>> basis
>
> I've been suspicious of the arbitrary way in which I/O for external
> sorts is costed by cost_sort() for a long time. I'm not 100% sure
> about how we should think about this question, but I am sure that it
> needs to be improved in *some* way.
Agree, but I think it should be separated patch to attack this issue. And I
don't have an idea how to do it, at least right now. Nevertheless, I hope, issue
of estimation of disk-based sort isn't a blocker of CPU cost estimation
improvements.
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
On 06/29/2018 04:36 PM, Teodor Sigaev wrote: > > > Peter Geoghegan wrote: >> On Thu, Jun 28, 2018 at 9:47 AM, Teodor Sigaev <teodor@sigaev.ru> wrote: >>> Current estimation of sort cost has following issues: >>> - it doesn't differ one and many columns sort >>> - it doesn't pay attention to comparison function cost and column >>> width >>> - it doesn't try to count number of calls of comparison function on >>> per >>> column >>> basis >> >> I've been suspicious of the arbitrary way in which I/O for >> external sorts is costed by cost_sort() for a long time. I'm not >> 100% sure about how we should think about this question, but I am >> sure that it needs to be improved in *some* way. >> > Agree, but I think it should be separated patch to attack this > issue. And I don't have an idea how to do it, at least right now. > Nevertheless, I hope, issue of estimation of disk-based sort isn't a > blocker of CPU cost estimation improvements. > Yes, I agree this should be addressed separately. Peter is definitely right that should look at costing internal vs. external sorts (after all, it's generally foolish to argue with *him* about sorting stuff). But the costing changes discussed here are due to my nagging from the GROUP BY patch (and also the "incremental sort" patch). The internal vs. external costing seems like an independent issue. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Hi,
I'll do more experiments/tests next week, but let me share at least some
initial thoughts ...
On 06/28/2018 06:47 PM, Teodor Sigaev wrote:
> Hi!
>
> Current estimation of sort cost has following issues:
> - it doesn't differ one and many columns sort
> - it doesn't pay attention to comparison function cost and column width
> - it doesn't try to count number of calls of comparison function on per
> column
> basis
>
> At least [1] and [2] hit into to that issues and have an
> objections/questions about correctness of cost sort estimation.
> Suggested patch tries to improve current estimation and solve that issues.
>
For those not following the two patches ("GROUP BY optimization" [1] and
"Incremental sort" [2]): This wasn't a major issue so far, because we
are not reordering the grouping keys to make the sort cheaper (which is
what [1] does), nor do we ignore some of the sort keys (which is what
[2] does, pretty much). Both patches need to estimate number of
comparisons on different columns and/or size of groups (i.e. ndistinct).
> Basic ideas:
> - let me introduce some designations
> i - index of column, started with 1
> N - number of tuples to sort
> Gi - number of groups, calculated by i number columns. Obviously,
> G0 == 1. Number of groups is caculated by estimate_num_groups().
> NGi - number of tuples in one group. NG0 == N and NGi = N/G(i-1)
> Fi - cost of comparison function call of i-th column
OK, so Fi is pretty much whatever CREATE FUNCTION ... COST says, right?
> Wi - average width in bytes of 1-ith column.
> Ci - total cost of one comparison call of column calculated as
> Fi * fine_function(Wi) where fine_function(Wi) looks like:
> if (Wi <= sizeof(Datum))
> return 1.0; //any type passed in Datum
> else
> return 1 + log16(Wi/sizeof(Datum));
> log16 just an empirical choice
> - So, cost for first column is 2.0 * C0 * log2(N)
> First column is always compared, multiplier 2.0 is defined per
> regression
> test. Seems, it estimates a cost for transferring tuple to CPU cache,
> starting cost for unpacking tuple, cost of call qsort compare wrapper
> function, etc. Removing this multiplier causes too optimistic
> prediction of
> cost.
Hmm, makes sense. But doesn't that mean it's mostly a fixed per-tuple
cost, not directly related to the comparison? For example, why should it
be multiplied by C0? That is, if I create a very expensive comparator
(say, with cost 100), why should it increase the cost for transferring
the tuple to CPU cache, unpacking it, etc.?
I'd say those costs are rather independent of the function cost, and
remain rather fixed, no matter what the function cost is.
Perhaps you haven't noticed that, because the default funcCost is 1?
> - cost for i-th columns:
> Ci * log2(NGi) => Ci * log2(N/G(i-1))
OK. So essentially for each column we take log2(tuples_per_group), as
total number of comparisons in quick-sort is O(N * log2(N)).
> So, here I believe, that i-th comparison function will be called only
> inside
> group which number is defined by (i-1) leading columns. Note, following
> discussion [1] I add multiplier 1.5 here to be closer to worst case when
> groups are significantly differ. Right now there is no way to
> determine how
> differ they could be. Note, this formula describes cost of first
> column too
> except difference with multiplier.
The number of new magic constants introduced by this patch is somewhat
annoying. 2.0, 1.5, 0.125, ... :-(
> - Final cost is cpu_operator_cost * N * sum(per column costs described
> above).
> Note, for single column with width <= sizeof(datum) and F1 = 1 this
> formula
> gives exactly the same result as current one.
> - for Top-N sort empiric is close to old one: use 2.0 multiplier as
> constant
> under log2, and use log2(Min(NGi, output_tuples)) for second and
> following
> columns.
>
I think compute_cpu_sort_cost is somewhat confused whether
per_tuple_cost is directly a cost, or a coefficient that will be
multiplied with cpu_operator_cost to get the actual cost.
At the beginning it does this:
per_tuple_cost = comparison_cost;
so it inherits the value passed to cost_sort(), which is supposed to be
cost. But then it does the work, which includes things like this:
per_tuple_cost += 2.0 * funcCost * LOG2(tuples);
where funcCost is pretty much pg_proc.procost. AFAIK that's meant to be
a value in units of cpu_operator_cost. And at the end it does this
per_tuple_cost *= cpu_operator_cost;
I.e. it gets multiplied with another cost. That doesn't seem right.
For most cost_sort calls this may not matter as the comparison_cost is
set to 0.0, but plan_cluster_use_sort() sets this explicitly to:
comparisonCost
= 2.0 * (indexExprCost.startup + indexExprCost.per_tuple);
which is likely to cause issues.
Also, why do we need this?
if (sortop != InvalidOid)
{
Oid funcOid = get_opcode(sortop);
funcCost = get_func_cost(funcOid);
}
Presumably if we get to costing sort, we know the pathkey can be sorted
and has sort operator, no? Or am I missing something?
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 06/28/2018 06:47 PM, Teodor Sigaev wrote:
> Hi!
>
> ...
>
> - cost for i-th columns:
> Ci * log2(NGi) => Ci * log2(N/G(i-1))
> So, here I believe, that i-th comparison function will be called only
> inside
> group which number is defined by (i-1) leading columns. Note, following
> discussion [1] I add multiplier 1.5 here to be closer to worst case when
> groups are significantly differ. Right now there is no way to
> determine how
> differ they could be. Note, this formula describes cost of first
> column too
> except difference with multiplier.
One more thought about estimating the worst case - I wonder if simply
multiplying the per-tuple cost by 1.5 is the right approach. It does not
seem particularly principled, and it's trivial simple to construct
counter-examples defeating it (imagine columns with 99% of the rows
having the same value, and then many values in exactly one row - that
will defeat the ndistinct-based group size estimates).
The reason why constructing such counter-examples is so simple is that
this relies entirely on the ndistinct stats, ignoring the other stats we
already have. I think this might leverage the per-column MCV lists (and
eventually multi-column MCV lists, if that ever gets committed).
We're estimating the number of tuples in group (after fixing values in
the preceding columns), because that's what determines the number of
comparisons we need to make at a given stage. The patch does this by
estimating the average group size, by estimating ndistinct of the
preceding columns G(i-1), and computing ntuples/G(i-1).
But consider that we also have MCV lists for each column - if there is a
very common value, it should be there. So let's say M(i) is a frequency
of the most common value in i-th column, determined either from the MCV
list or as 1/ndistinct for that column. Then if m(i) is minimum of M(i)
for the fist i columns, then the largest possible group of values when
comparing values in i-th column is
N * m(i-1)
This seems like a better way to estimate the worst case. I don't know if
this should be used instead of NG(i), or if those two estimates should
be combined in some way.
I think estimating the largest group we need to sort should be helpful
for the incremental sort patch, so I'm adding Alexander to this thread.
regards
--
Tomas Vondra http://www.2ndQuadrant.com
PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
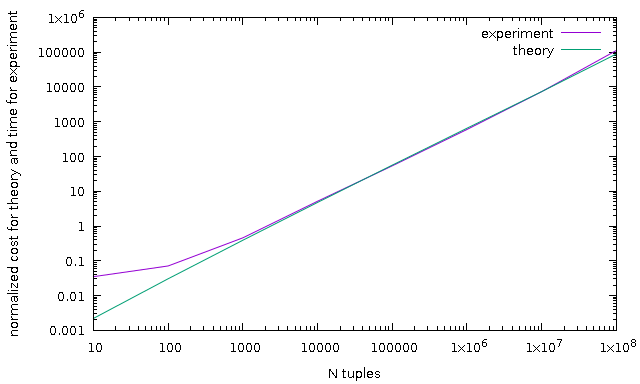
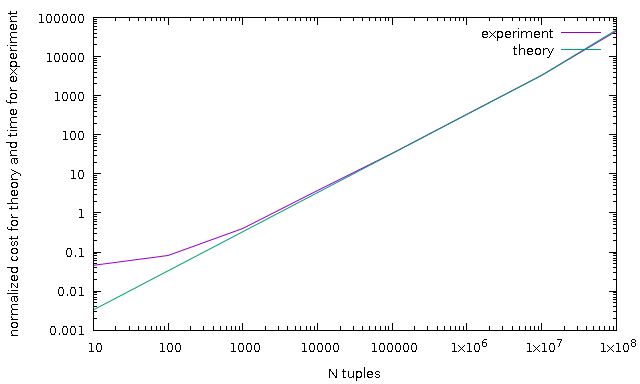
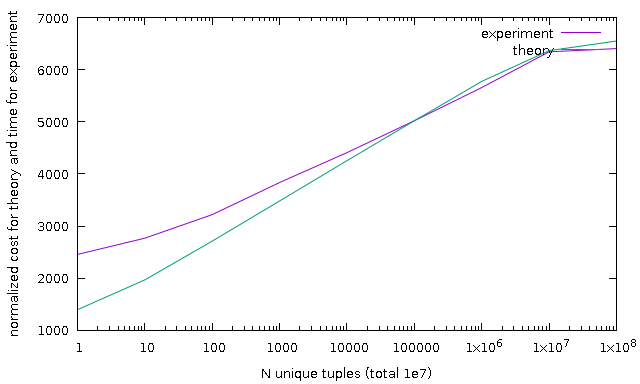
> At least [1] and [2] hit into to that issues and have an objections/questions > about correctness of cost sort estimation. Suggested patch tries to improve > current estimation and solve that issues. Sorry for long delay but issue was even more complicated than I thought. When I tried to add cost_sort to GROUP BY patch I found it isn't work well as I hoped :(. The root of problem is suggested cost_sort improvement doesn't take into account uniqueness of first column and it's cost always the same. I tried to make experiments with all the same and all unique column and found that execution time could be significantly differ (up to 3 times on 1e7 randomly generated integer values). And I went to read book and papers. So, I suggest new algorithm based on ideas in [3], [4]. In term of that papers, let I use designations from previous my email and Xi - number of tuples with key Ki, then estimation is: log(N! / (X1! * X2! * ..)) ~ sum(Xi * log(N/Xi)) In our case all Xi are the same because now we don't have an estimation of group sizes, we have only estimation of number of groups. In this case, formula becomes: N * log(NumberOfGroups). Next, to support correct estimation of multicolumn sort we need separately compute each column, so, let k is a column number, Gk - number of groups defined by k columns: N * sum( FCk * log(Gk) ) and FCk is a sum(Cj) over k columns. Gk+1 is defined as estimate_num_groups(NGk) - i.e. it's recursive, that's means that comparison of k-th columns includes all comparison j-th columns < k. Next, I found that this formula gives significant underestimate with N < 1e4 and using [5] (See Chapter 8.2 and Theorem 4.1) found that we can use N + N * log(N) formula which actually adds a multiplier in simple case but it's unclear for me how to add that multimplier to multicolumn formula, so I added just a separate term proportional to N. As demonstration, I add result of some test, *sh and *plt are scripts to reproduce results. Note, all charts are normalized because computed cost as not a milliseconds. p.pl is a parser for JSON format of explain analyze. N test - sort unique values with different number of tuples NN test - same as previous one but sort of single value (all the same values) U test - fixed number of total values (1e7) but differ number of unique values Hope, new estimation much more close to real sort timing. New estimation function gives close result to old estimation function on trivial examples, but ~10% more expensive, and three of regression tests aren't passed, will look closer later. Patch doesn't include regression test changes. > [1] https://commitfest.postgresql.org/18/1124/ > [2] https://commitfest.postgresql.org/18/1651/ [3] https://algs4.cs.princeton.edu/home/, course Algorithms, Robert Sedgewick, Kevin Wayne, [4] "Quicksort Is Optimal For Many Equal Keys", Sebastian Wild, arXiv:1608.04906v4 [cs.DS] 1 Nov 2017 [5] "Introduction to algorithms", Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, ISBN 0-07-013143-0 -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
Attachment
{kind=link}
{kind=link}
{kind=link}
> OK, so Fi is pretty much whatever CREATE FUNCTION ... COST says, right? exactly > Hmm, makes sense. But doesn't that mean it's mostly a fixed per-tuple > cost, not directly related to the comparison? For example, why should it > be multiplied by C0? That is, if I create a very expensive comparator > (say, with cost 100), why should it increase the cost for transferring > the tuple to CPU cache, unpacking it, etc.? > > I'd say those costs are rather independent of the function cost, and > remain rather fixed, no matter what the function cost is. > > Perhaps you haven't noticed that, because the default funcCost is 1? May be, but see my email https://www.postgresql.org/message-id/ee14392b-d753-10ce-f5ed-7b2f7e277512%40sigaev.ru about additional term proportional to N > The number of new magic constants introduced by this patch is somewhat > annoying. 2.0, 1.5, 0.125, ... :-( 2.0 is removed in last patch, 1.5 leaved and could be removed when I understand you letter with group size estimation :) 0.125 should be checked, and I suppose we couldn't remove it at all because it "average over whole word" constant. > >> - Final cost is cpu_operator_cost * N * sum(per column costs described >> above). >> Note, for single column with width <= sizeof(datum) and F1 = 1 this >> formula >> gives exactly the same result as current one. >> - for Top-N sort empiric is close to old one: use 2.0 multiplier as >> constant >> under log2, and use log2(Min(NGi, output_tuples)) for second and >> following >> columns. >> > > I think compute_cpu_sort_cost is somewhat confused whether > per_tuple_cost is directly a cost, or a coefficient that will be > multiplied with cpu_operator_cost to get the actual cost. > > At the beginning it does this: > > per_tuple_cost = comparison_cost; > > so it inherits the value passed to cost_sort(), which is supposed to be > cost. But then it does the work, which includes things like this: > > per_tuple_cost += 2.0 * funcCost * LOG2(tuples); > > where funcCost is pretty much pg_proc.procost. AFAIK that's meant to be > a value in units of cpu_operator_cost. And at the end it does this > > per_tuple_cost *= cpu_operator_cost; > > I.e. it gets multiplied with another cost. That doesn't seem right. Huh, you are right, will fix in v8. > Also, why do we need this? > > if (sortop != InvalidOid) > { > Oid funcOid = get_opcode(sortop); > > funcCost = get_func_cost(funcOid); > } Safety first :). Will remove. -- Teodor Sigaev E-mail: teodor@sigaev.ru WWW: http://www.sigaev.ru/
V8 contains fixes of Tomas Vondra complaints:
- correct usage of comparison_cost
- remove uneeded check of sortop
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
Attachment
> One more thought about estimating the worst case - I wonder if simply
> multiplying the per-tuple cost by 1.5 is the right approach. It does not
> seem particularly principled, and it's trivial simple to construct
> counter-examples defeating it (imagine columns with 99% of the rows
> having the same value, and then many values in exactly one row - that
> will defeat the ndistinct-based group size estimates).
Agree. But right now that is best what we have. and constant 1.5 easily could be
changed to 1 or 10 - it is just arbitrary value, intuitively chosen. As I
mentioned in v7 patch description, new estimation function provides ~10% bigger
estimation and this constant should not be very large, because we could easily
get overestimation.
>
> The reason why constructing such counter-examples is so simple is that
> this relies entirely on the ndistinct stats, ignoring the other stats we
> already have. I think this might leverage the per-column MCV lists (and
> eventually multi-column MCV lists, if that ever gets committed).
>
> We're estimating the number of tuples in group (after fixing values in
> the preceding columns), because that's what determines the number of
> comparisons we need to make at a given stage. The patch does this by
> estimating the average group size, by estimating ndistinct of the
> preceding columns G(i-1), and computing ntuples/G(i-1).
>
> But consider that we also have MCV lists for each column - if there is a
> very common value, it should be there. So let's say M(i) is a frequency
> of the most common value in i-th column, determined either from the MCV
> list or as 1/ndistinct for that column. Then if m(i) is minimum of M(i)
> for the fist i columns, then the largest possible group of values when
> comparing values in i-th column is
>
> N * m(i-1)
>
> This seems like a better way to estimate the worst case. I don't know if
> this should be used instead of NG(i), or if those two estimates should
> be combined in some way.
Agree, definitely we need an estimation of larger group size to use it in
cost_sort. But I don't feel power to do that, pls, could you attack a computing
group size issue? Thank you.
>
> I think estimating the largest group we need to sort should be helpful
> for the incremental sort patch, so I'm adding Alexander to this thread.Agree
I think so. suggested estimation algorithm should be modified to support leading
preordered keys and this form could be directly used in GROUP BY and incremental
sort patches.
--
Teodor Sigaev E-mail: teodor@sigaev.ru
WWW: http://www.sigaev.ru/
On 07/12/2018 05:00 PM, Teodor Sigaev wrote: > >> One more thought about estimating the worst case - I wonder if simply >> multiplying the per-tuple cost by 1.5 is the right approach. It does not >> seem particularly principled, and it's trivial simple to construct >> counter-examples defeating it (imagine columns with 99% of the rows >> having the same value, and then many values in exactly one row - that >> will defeat the ndistinct-based group size estimates). > > Agree. But right now that is best what we have. and constant 1.5 easily > could be changed to 1 or 10 - it is just arbitrary value, intuitively > chosen. As I mentioned in v7 patch description, new estimation function > provides ~10% bigger estimation and this constant should not be very > large, because we could easily get overestimation. > >> >> The reason why constructing such counter-examples is so simple is that >> this relies entirely on the ndistinct stats, ignoring the other stats we >> already have. I think this might leverage the per-column MCV lists (and >> eventually multi-column MCV lists, if that ever gets committed). >> >> We're estimating the number of tuples in group (after fixing values in >> the preceding columns), because that's what determines the number of >> comparisons we need to make at a given stage. The patch does this by >> estimating the average group size, by estimating ndistinct of the >> preceding columns G(i-1), and computing ntuples/G(i-1). >> >> But consider that we also have MCV lists for each column - if there is a >> very common value, it should be there. So let's say M(i) is a frequency >> of the most common value in i-th column, determined either from the MCV >> list or as 1/ndistinct for that column. Then if m(i) is minimum of M(i) >> for the fist i columns, then the largest possible group of values when >> comparing values in i-th column is >> >> N * m(i-1) >> >> This seems like a better way to estimate the worst case. I don't know if >> this should be used instead of NG(i), or if those two estimates should >> be combined in some way. > Agree, definitely we need an estimation of larger group size to use it > in cost_sort. But I don't feel power to do that, pls, could you attack a > computing group size issue? Thank you. > Attached is a simple patch illustrating this MCV-based approach. I don't claim it's finished / RFC, but hopefully it's sufficient to show what I meant. I'm not sure how to plug it into the v8 of your patch at this point, so I've simply added an elog to estimate_num_groups to also print the estimate or largest group for GROUP BY queries. It's largely a simplified copy of estimate_num_groups() and there's a couple of comments of how it might be improved further. >> >> I think estimating the largest group we need to sort should be helpful >> for the incremental sort patch, so I'm adding Alexander to this >> thread.Agree > I think so. suggested estimation algorithm should be modified to support > leading preordered keys and this form could be directly used in GROUP BY > and incremental sort patches. Right. What I think the function estimating the group size could do in case of incremental sort is producing two values - maximum size of the leading group, and maximum group size overall. The first one would be useful for startup cost, the second one for total cost. regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
Attachment
On 07/12/2018 04:31 PM, Teodor Sigaev wrote: >> At least [1] and [2] hit into to that issues and have an >> objections/questions about correctness of cost sort estimation. >> Suggested patch tries to improve current estimation and solve that >> issues. > > Sorry for long delay but issue was even more complicated than I thought. > When I tried to add cost_sort to GROUP BY patch I found it isn't work > well as I hoped :(. The root of problem is suggested cost_sort > improvement doesn't take into account uniqueness of first column and > it's cost always the same. I tried to make experiments with all the same > and all unique column and found that execution time could be > significantly differ (up to 3 times on 1e7 randomly generated integer > values). And I went to read book and papers. > > So, I suggest new algorithm based on ideas in [3], [4]. In term of that > papers, let I use designations from previous my email and Xi - number > of tuples with key Ki, then estimation is: > log(N! / (X1! * X2! * ..)) ~ sum(Xi * log(N/Xi)) > In our case all Xi are the same because now we don't have an estimation of > group sizes, we have only estimation of number of groups. In this case, > formula becomes: N * log(NumberOfGroups). Next, to support correct > estimation > of multicolumn sort we need separately compute each column, so, let k is a > column number, Gk - number of groups defined by k columns: > N * sum( FCk * log(Gk) ) > and FCk is a sum(Cj) over k columns. Gk+1 is defined as > estimate_num_groups(NGk) - i.e. it's recursive, that's means that > comparison of k-th columns includes all comparison j-th columns < k. > > Next, I found that this formula gives significant underestimate with N < > 1e4 and using [5] (See Chapter 8.2 and Theorem 4.1) found that we can > use N + N * log(N) formula which actually adds a multiplier in simple > case but it's unclear for me how to add that multimplier to multicolumn > formula, so I added just a separate term proportional to N. > I'm sorry, but I'm getting lost in the notation and how you came up with those formulas - I don't know where to look in the papers, books etc. Could you perhaps summarize the reasoning or at least point me to the relevant parts of the sources, so that I know which parts to focus on? > As demonstration, I add result of some test, *sh and *plt are scripts to > reproduce results. Note, all charts are normalized because computed > cost as not a milliseconds. p.pl is a parser for JSON format of explain > analyze. > > N test - sort unique values with different number of tuples > NN test - same as previous one but sort of single value (all the same > values) > U test - fixed number of total values (1e7) but differ number of unique > values > > Hope, new estimation much more close to real sort timing. New estimation > function gives close result to old estimation function on trivial > examples, but ~10% more expensive, and three of regression tests aren't > passed, will look closer later. Patch doesn't include regression test > changes. Interesting. I wonder if there's a way to address the difference at the lower end? regards -- Tomas Vondra http://www.2ndQuadrant.com PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On Sun, Jul 22, 2018 at 10:22:10PM +0200, Tomas Vondra wrote: > Could you perhaps summarize the reasoning or at least point me to the > relevant parts of the sources, so that I know which parts to focus on? Teodor, this patch is waiting for some input from you. I have moved it to next CF for now, 2018-11. -- Michael
Attachment
> On Tue, Oct 2, 2018 at 3:58 AM Michael Paquier <michael@paquier.xyz> wrote: > > On Sun, Jul 22, 2018 at 10:22:10PM +0200, Tomas Vondra wrote: > > Could you perhaps summarize the reasoning or at least point me to the > > relevant parts of the sources, so that I know which parts to focus on? > > Teodor, this patch is waiting for some input from you. I have moved it > to next CF for now, 2018-11. The patch also needs to be adjusted - it fails on "make check" on join, aggregates and partition_aggregate.
On 2018-11-29 17:53:31 +0100, Dmitry Dolgov wrote: > > On Tue, Oct 2, 2018 at 3:58 AM Michael Paquier <michael@paquier.xyz> wrote: > > > > On Sun, Jul 22, 2018 at 10:22:10PM +0200, Tomas Vondra wrote: > > > Could you perhaps summarize the reasoning or at least point me to the > > > relevant parts of the sources, so that I know which parts to focus on? > > > > Teodor, this patch is waiting for some input from you. I have moved it > > to next CF for now, 2018-11. > > The patch also needs to be adjusted - it fails on "make check" on join, > aggregates and partition_aggregate. As nothing has happened since, I'm marking this as returned with feedback. Greetings, Andres Freund