Thread: Contention preventing locking
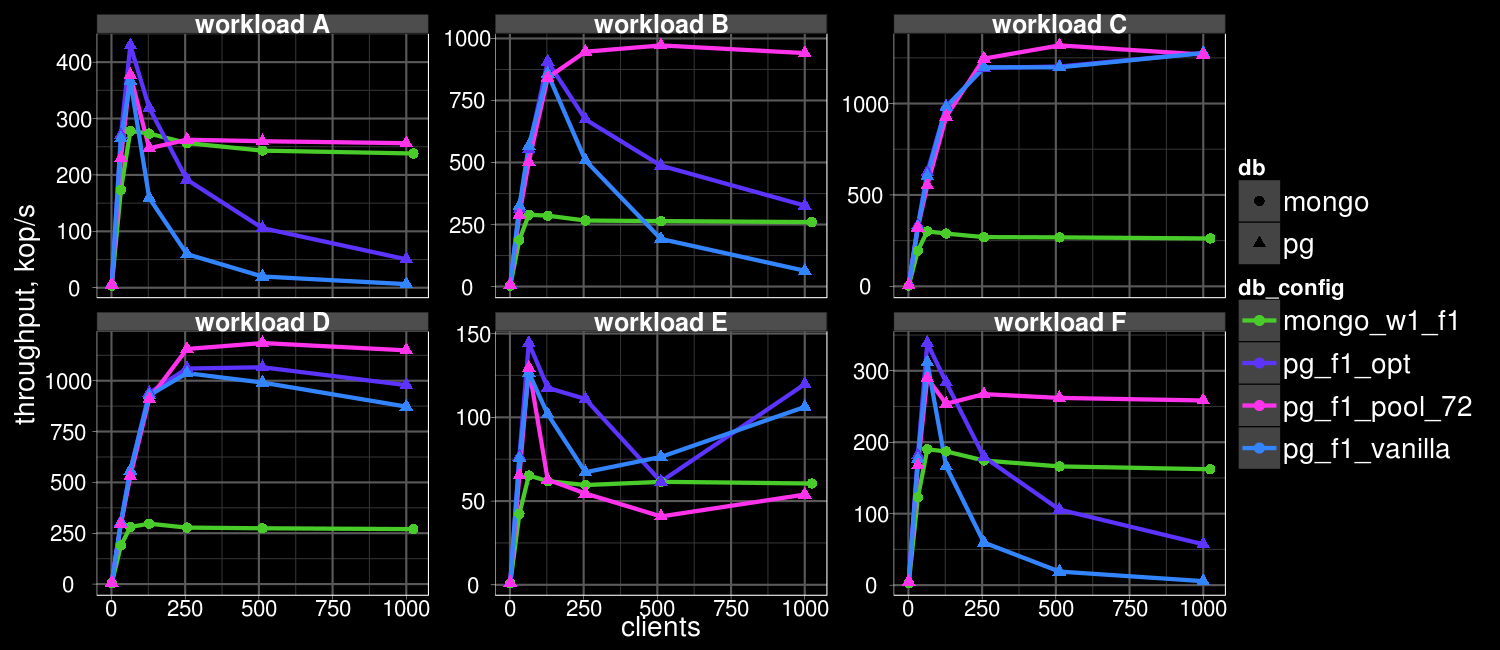
Hi, PostgreSQL performance degrades signficantly in case of high contention. You can look at the attached YCSB results (ycsb-zipf-pool.png) to estimate the level of this degradation. Postgres is acquiring two kind of heavy weight locks during update: it locks TID of the updated tuple and XID of transaction created this version. In debugger I see the following picture: if several transactions are trying to update the same record, then first of all they compete for SnapshotDirty.xmax transaction lock in EvalPlanQualFetch. Then in heap_tuple_update they are trying to lock TID of the updated tuple: heap_acquire_tuplock in heapam.c After that transactions wait completion of the transaction updated the tuple: XactLockTableWait in heapam.c So in heap_acquire_tuplock all competing transactions are waiting for TID of the updated version. When transaction which changed this tuple is committed, one of the competitors will grant this lock and proceed, creating new version of the tuple. Then all other competitors will be awaken and ... find out that locked tuple is not the last version any more. Then they will locate new version and try to lock it... The more competitors we have, then more attempts they all have to perform (quadratic complexity). My idea was that we can avoid such performance degradation if we somehow queue competing transactions so that they will get control one-by-one, without doing useless work. First of all I tried to replace TID lock with PK (primary key) lock. Unlike TID, PK of record is not changed during hot update. The second idea is that instead immediate releasing lock after update we can hold it until the end of transaction. And this optimization really provides improve of performance - it corresponds to pg_f1_opt configuration at the attached diagram. For some workloads it provides up to two times improvement comparing with vanilla Postgres. But there are many problems with correct (non-prototype) implementation of this approach: handling different types of PK, including compound keys, PK updates,... Another approach, which I have recently implemented, is much simpler and address another lock kind: transaction lock. The idea o this approach is mostly the same: all competing transaction are waiting for transaction which is changing the tuple. Then one of them is given a chance to proceed and now all other transactions are waiting for this transaction and so on: T1<-T2,T3,T4,T5,T6,T7,T8,T9 T2<-T3,T4,T5,T6,T7,T8,T9 T3<-T4,T5,T6,T7,T8,T9 ... <- here corresponds to "wait for" dependency between transactions. If we change this picture to T1<-T2, T2<-T3, T3<-T4, T4<-T5, T5<-T6, T6<-T7, T7<-T8, T8<-T9 then number of lock requests can be significantly reduced. And it can be implemented using very simple patch (attached xlock.patch). I hope that I have not done something incorrect here. Effect of this simple patch is even larger: more than 3 times for 50..70 clients. Please look at the attached xlock.pdf spreadsheet. Unfortunately combination of this two approaches gives worser result than just single xlock.patch. Certainly this patch also requires further improvement, for example it will not correctly work in case of aborting transactions due to deadlock or some other reasons. I just want to know option of community if the proposed approaches to reduce contention are really promising and it makes sense to continue work in this direction. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
{kind=link}
Hello.
Just want to notice - this work also correlates with https://www.postgresql.org/message-id/CAEepm%3D18buPTwNWKZMrAXLqja1Tvezw6sgFJKPQ%2BsFFTuwM0bQ%40mail.gmail.com paper.
It provides more general way to address the issue comparing to single optimisations (but they could do the work too, of course).
Thanks,
Michail.
чт, 15 февр. 2018 г. в 19:00, Konstantin Knizhnik <k.knizhnik@postgrespro.ru>:
Hi,
PostgreSQL performance degrades signficantly in case of high contention.
You can look at the attached YCSB results (ycsb-zipf-pool.png) to
estimate the level of this degradation.
Postgres is acquiring two kind of heavy weight locks during update: it
locks TID of the updated tuple and XID of transaction created this version.
In debugger I see the following picture: if several transactions are
trying to update the same record, then first of all they compete for
SnapshotDirty.xmax transaction lock in EvalPlanQualFetch.
Then in heap_tuple_update they are trying to lock TID of the updated
tuple: heap_acquire_tuplock in heapam.c
After that transactions wait completion of the transaction updated the
tuple: XactLockTableWait in heapam.c
So in heap_acquire_tuplock all competing transactions are waiting for
TID of the updated version. When transaction which changed this tuple is
committed, one of the competitors will grant this lock and proceed,
creating new version of the tuple. Then all other competitors will be
awaken and ... find out that locked tuple is not the last version any more.
Then they will locate new version and try to lock it... The more
competitors we have, then more attempts they all have to perform
(quadratic complexity).
My idea was that we can avoid such performance degradation if we somehow
queue competing transactions so that they will get control one-by-one,
without doing useless work.
First of all I tried to replace TID lock with PK (primary key) lock.
Unlike TID, PK of record is not changed during hot update. The second
idea is that instead immediate releasing lock after update we can hold
it until the end of transaction. And this optimization really provides
improve of performance - it corresponds to pg_f1_opt configuration at
the attached diagram.
For some workloads it provides up to two times improvement comparing
with vanilla Postgres. But there are many problems with correct
(non-prototype) implementation of this approach:
handling different types of PK, including compound keys, PK updates,...
Another approach, which I have recently implemented, is much simpler
and address another lock kind: transaction lock.
The idea o this approach is mostly the same: all competing transaction
are waiting for transaction which is changing the tuple.
Then one of them is given a chance to proceed and now all other
transactions are waiting for this transaction and so on:
T1<-T2,T3,T4,T5,T6,T7,T8,T9
T2<-T3,T4,T5,T6,T7,T8,T9
T3<-T4,T5,T6,T7,T8,T9
...
<- here corresponds to "wait for" dependency between transactions.
If we change this picture to
T1<-T2, T2<-T3, T3<-T4, T4<-T5, T5<-T6, T6<-T7, T7<-T8, T8<-T9
then number of lock requests can be significantly reduced.
And it can be implemented using very simple patch (attached xlock.patch).
I hope that I have not done something incorrect here.
Effect of this simple patch is even larger: more than 3 times for
50..70 clients.
Please look at the attached xlock.pdf spreadsheet.
Unfortunately combination of this two approaches gives worser result
than just single xlock.patch.
Certainly this patch also requires further improvement, for example it
will not correctly work in case of aborting transactions due to deadlock
or some other reasons.
I just want to know option of community if the proposed approaches to
reduce contention are really promising and it makes sense to continue
work in this direction.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
On 16.02.2018 11:59, Michail Nikolaev wrote:
Hello.Just want to notice - this work also correlates with https://www.postgresql.org/message-id/CAEepm%3D18buPTwNWKZMrAXLqja1Tvezw6sgFJKPQ%2BsFFTuwM0bQ%40mail.gmail.com paper.It provides more general way to address the issue comparing to single optimisations (but they could do the work too, of course).
Certainly, contention-aware lock scheduler is much more general way of addressing this problem.
But amount of efforts needed to implement such scheduler and integrate it in Postgres core is almost non-comparable.
I did some more tests with much simple benchmark than YCSB: it just execute specified percent of single record updates and selects for relatively small table.
I used 50% of updates, 100 records table size and vary number of connections from 10 to 1000 with step 10.
This benchmark (pgrw.c) and updated version of xlock patch are attached to this mail.
Results are present at the following spreadsheet:
https://docs.google.com/spreadsheets/d/1QOYfUehy8U3sdasMjGnPGQJY8JiRfZmlS64YRBM0YTo/edit?usp=sharing
I repeated tests several times. Dips on the chart corresponds to the auto-vacuum periods. For some reasons them are larger for xlock optimization.
But, you can notice that xlock optimization significantly reduce degradation speed although doesn't completely eliminate this negative trend.
Thanks,Michail.чт, 15 февр. 2018 г. в 19:00, Konstantin Knizhnik <k.knizhnik@postgrespro.ru>:Hi,
PostgreSQL performance degrades signficantly in case of high contention.
You can look at the attached YCSB results (ycsb-zipf-pool.png) to
estimate the level of this degradation.
Postgres is acquiring two kind of heavy weight locks during update: it
locks TID of the updated tuple and XID of transaction created this version.
In debugger I see the following picture: if several transactions are
trying to update the same record, then first of all they compete for
SnapshotDirty.xmax transaction lock in EvalPlanQualFetch.
Then in heap_tuple_update they are trying to lock TID of the updated
tuple: heap_acquire_tuplock in heapam.c
After that transactions wait completion of the transaction updated the
tuple: XactLockTableWait in heapam.c
So in heap_acquire_tuplock all competing transactions are waiting for
TID of the updated version. When transaction which changed this tuple is
committed, one of the competitors will grant this lock and proceed,
creating new version of the tuple. Then all other competitors will be
awaken and ... find out that locked tuple is not the last version any more.
Then they will locate new version and try to lock it... The more
competitors we have, then more attempts they all have to perform
(quadratic complexity).
My idea was that we can avoid such performance degradation if we somehow
queue competing transactions so that they will get control one-by-one,
without doing useless work.
First of all I tried to replace TID lock with PK (primary key) lock.
Unlike TID, PK of record is not changed during hot update. The second
idea is that instead immediate releasing lock after update we can hold
it until the end of transaction. And this optimization really provides
improve of performance - it corresponds to pg_f1_opt configuration at
the attached diagram.
For some workloads it provides up to two times improvement comparing
with vanilla Postgres. But there are many problems with correct
(non-prototype) implementation of this approach:
handling different types of PK, including compound keys, PK updates,...
Another approach, which I have recently implemented, is much simpler
and address another lock kind: transaction lock.
The idea o this approach is mostly the same: all competing transaction
are waiting for transaction which is changing the tuple.
Then one of them is given a chance to proceed and now all other
transactions are waiting for this transaction and so on:
T1<-T2,T3,T4,T5,T6,T7,T8,T9
T2<-T3,T4,T5,T6,T7,T8,T9
T3<-T4,T5,T6,T7,T8,T9
...
<- here corresponds to "wait for" dependency between transactions.
If we change this picture to
T1<-T2, T2<-T3, T3<-T4, T4<-T5, T5<-T6, T6<-T7, T7<-T8, T8<-T9
then number of lock requests can be significantly reduced.
And it can be implemented using very simple patch (attached xlock.patch).
I hope that I have not done something incorrect here.
Effect of this simple patch is even larger: more than 3 times for
50..70 clients.
Please look at the attached xlock.pdf spreadsheet.
Unfortunately combination of this two approaches gives worser result
than just single xlock.patch.
Certainly this patch also requires further improvement, for example it
will not correctly work in case of aborting transactions due to deadlock
or some other reasons.
I just want to know option of community if the proposed approaches to
reduce contention are really promising and it makes sense to continue
work in this direction.
--
Konstantin Knizhnik
Postgres Professional: http://www.postgrespro.com
The Russian Postgres Company
-- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
On 15 February 2018 at 16:00, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > So in heap_acquire_tuplock all competing transactions are waiting for TID of > the updated version. When transaction which changed this tuple is committed, > one of the competitors will grant this lock and proceed, creating new > version of the tuple. Then all other competitors will be awaken and ... find > out that locked tuple is not the last version any more. > Then they will locate new version and try to lock it... The more competitors > we have, then more attempts they all have to perform (quadratic complexity). What about the tuple lock? You are saying that is ineffective? src/backend/access/heap/README.tuplock > My idea was that we can avoid such performance degradation if we somehow > queue competing transactions so that they will get control one-by-one, > without doing useless work. > First of all I tried to replace TID lock with PK (primary key) lock. Unlike > TID, PK of record is not changed during hot update. The second idea is that > instead immediate releasing lock after update we can hold it until the end > of transaction. And this optimization really provides improve of performance > - it corresponds to pg_f1_opt configuration at the attached diagram. > For some workloads it provides up to two times improvement comparing with > vanilla Postgres. But there are many problems with correct (non-prototype) > implementation of this approach: > handling different types of PK, including compound keys, PK updates,... Try locking the root tid rather than the TID, that is at least unique per page for a chain of tuples, just harder to locate. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 20.02.2018 14:26, Simon Riggs wrote: > On 15 February 2018 at 16:00, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: > >> So in heap_acquire_tuplock all competing transactions are waiting for TID of >> the updated version. When transaction which changed this tuple is committed, >> one of the competitors will grant this lock and proceed, creating new >> version of the tuple. Then all other competitors will be awaken and ... find >> out that locked tuple is not the last version any more. >> Then they will locate new version and try to lock it... The more competitors >> we have, then more attempts they all have to perform (quadratic complexity). > What about the tuple lock? You are saying that is ineffective? > > src/backend/access/heap/README.tuplock In my last mail ni this thread I have mentioned that update of tuple cause setting of three heavy weight locks: 1. Locking of SnapshotDirty.xmax transaction (XactLockTableWait) in EvalPlanQualFetch 2. Tuple lock (heap_acquire_tuplock) in heap_tuple_update 3. Transaction lock (XactLockTableWait) in heap_tuple_update So what I see in debugger and monitoring pg_locks, is that under high contention there are a lot transactions waiting for SnapshotDirty.xmax. This lock is obtained before tuple lock, so tuple lock can not help in this case. > > >> My idea was that we can avoid such performance degradation if we somehow >> queue competing transactions so that they will get control one-by-one, >> without doing useless work. >> First of all I tried to replace TID lock with PK (primary key) lock. Unlike >> TID, PK of record is not changed during hot update. The second idea is that >> instead immediate releasing lock after update we can hold it until the end >> of transaction. And this optimization really provides improve of performance >> - it corresponds to pg_f1_opt configuration at the attached diagram. >> For some workloads it provides up to two times improvement comparing with >> vanilla Postgres. But there are many problems with correct (non-prototype) >> implementation of this approach: >> handling different types of PK, including compound keys, PK updates,... > Try locking the root tid rather than the TID, that is at least unique > per page for a chain of tuples, just harder to locate. > But locking primary key is more efficient, isn't it? The problem with primary key is that it doesn't always exists or can be compound, but if it exists and has integer type, then get be obtained easily than root tid. For pgrw benchmark primary key lock provides even better results than transaction lock chaining: https://docs.google.com/spreadsheets/d/1QOYfUehy8U3sdasMjGnPGQJY8JiRfZmlS64YRBM0YTo/edit?usp=sharing But for YCSB benchmark xlock optimization is more efficient: https://docs.google.com/spreadsheets/d/136BfsABXEbzrleZHYoli7XAyDFUAxAXZDHl5EvJR_0Q/edit?usp=sharing -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 20 February 2018 at 13:19, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > > On 20.02.2018 14:26, Simon Riggs wrote: >> >> On 15 February 2018 at 16:00, Konstantin Knizhnik >> <k.knizhnik@postgrespro.ru> wrote: >> >>> So in heap_acquire_tuplock all competing transactions are waiting for TID >>> of >>> the updated version. When transaction which changed this tuple is >>> committed, >>> one of the competitors will grant this lock and proceed, creating new >>> version of the tuple. Then all other competitors will be awaken and ... >>> find >>> out that locked tuple is not the last version any more. >>> Then they will locate new version and try to lock it... The more >>> competitors >>> we have, then more attempts they all have to perform (quadratic >>> complexity). >> >> What about the tuple lock? You are saying that is ineffective? >> >> src/backend/access/heap/README.tuplock > > > In my last mail ni this thread I have mentioned that update of tuple cause > setting of three heavy weight locks: > > 1. Locking of SnapshotDirty.xmax transaction (XactLockTableWait) in > EvalPlanQualFetch > 2. Tuple lock (heap_acquire_tuplock) in heap_tuple_update > 3. Transaction lock (XactLockTableWait) in heap_tuple_update > > So what I see in debugger and monitoring pg_locks, is that under high > contention there are a lot transactions waiting for SnapshotDirty.xmax. > This lock is obtained before tuple lock, so tuple lock can not help in this > case. Hmm, that situation occurs erroneously, as I previously observed https://www.postgresql.org/message-id/CANP8%2BjKoMAyXvMO2hUqFzHX8fYSFc82q9MEse2zAEOC8vxwDfA%40mail.gmail.com So if you apply the patch on the thread above, does performance improve? -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 20.02.2018 16:42, Simon Riggs wrote: > On 20 February 2018 at 13:19, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> >> On 20.02.2018 14:26, Simon Riggs wrote: >>> On 15 February 2018 at 16:00, Konstantin Knizhnik >>> <k.knizhnik@postgrespro.ru> wrote: >>> >>>> So in heap_acquire_tuplock all competing transactions are waiting for TID >>>> of >>>> the updated version. When transaction which changed this tuple is >>>> committed, >>>> one of the competitors will grant this lock and proceed, creating new >>>> version of the tuple. Then all other competitors will be awaken and ... >>>> find >>>> out that locked tuple is not the last version any more. >>>> Then they will locate new version and try to lock it... The more >>>> competitors >>>> we have, then more attempts they all have to perform (quadratic >>>> complexity). >>> What about the tuple lock? You are saying that is ineffective? >>> >>> src/backend/access/heap/README.tuplock >> >> In my last mail ni this thread I have mentioned that update of tuple cause >> setting of three heavy weight locks: >> >> 1. Locking of SnapshotDirty.xmax transaction (XactLockTableWait) in >> EvalPlanQualFetch >> 2. Tuple lock (heap_acquire_tuplock) in heap_tuple_update >> 3. Transaction lock (XactLockTableWait) in heap_tuple_update >> >> So what I see in debugger and monitoring pg_locks, is that under high >> contention there are a lot transactions waiting for SnapshotDirty.xmax. >> This lock is obtained before tuple lock, so tuple lock can not help in this >> case. > Hmm, that situation occurs erroneously, as I previously observed > https://www.postgresql.org/message-id/CANP8%2BjKoMAyXvMO2hUqFzHX8fYSFc82q9MEse2zAEOC8vxwDfA%40mail.gmail.com > > So if you apply the patch on the thread above, does performance improve? > First of all this patch is not correct: it cause pin/unpin buffer disbalance and I get a lot of errors: Update failed: ERROR: buffer 343 is not owned by resource owner Portal When I slightly modify it by moving ReleaseBuffer(buffer) inside switch I get almost the same performance as Vanilla. And when I combined it with pklock patch, then I get similar performance with vanilla+pklock, but with much larger dips: https://docs.google.com/spreadsheets/d/1QOYfUehy8U3sdasMjGnPGQJY8JiRfZmlS64YRBM0YTo/edit?usp=sharing -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 20.02.2018 14:26, Simon Riggs wrote: > Try locking the root tid rather than the TID, that is at least unique > per page for a chain of tuples, just harder to locate. > As far as I understand, it is necessary to traverse the whole page to locate root tuple, isn't it? If so, then I expect it to be too expensive operation. Scanning the whole page on tuple update seems to be not an acceptable solution. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 20 February 2018 at 16:07, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > > On 20.02.2018 14:26, Simon Riggs wrote: >> >> Try locking the root tid rather than the TID, that is at least unique >> per page for a chain of tuples, just harder to locate. >> > As far as I understand, it is necessary to traverse the whole page to locate > root tuple, isn't it? > If so, then I expect it to be too expensive operation. Scanning the whole > page on tuple update seems to be not an acceptable solution. Probably. It occurs to me that you can lock the root tid in index_fetch_heap(). I hear other DBMS lock via the index. However, anything you do with tuple locking could interact badly with heap_update and the various lock modes, so be careful. You also have contention for heap_page_prune_opt() and with SELECTs to consider, so I think you need to look at both page and tuple locking. -- Simon Riggs http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Remote DBA, Training & Services
On 20.02.2018 19:39, Simon Riggs wrote: > On 20 February 2018 at 16:07, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> >> On 20.02.2018 14:26, Simon Riggs wrote: >>> Try locking the root tid rather than the TID, that is at least unique >>> per page for a chain of tuples, just harder to locate. >>> >> As far as I understand, it is necessary to traverse the whole page to locate >> root tuple, isn't it? >> If so, then I expect it to be too expensive operation. Scanning the whole >> page on tuple update seems to be not an acceptable solution. > Probably. > > It occurs to me that you can lock the root tid in index_fetch_heap(). > I hear other DBMS lock via the index. > > However, anything you do with tuple locking could interact badly with > heap_update and the various lock modes, so be careful. > > You also have contention for heap_page_prune_opt() and with SELECTs to > consider, so I think you need to look at both page and tuple locking. > So, if I correctly understand the primary goal of setting tuple lock in heapam.c is to avoid contention caused by concurrent release of all waiters. But my transaction lock chaining patch eliminates this problem in other way. So what about combining your patch (do not lock Snapshot.xmax) + with my xlock patch and ... completely eliminate tuple lock in heapam? In this case update of tuple will require obtaining just one heavy weight lock. I made such experiment and didn't find any synchronization problems with my pgrw test. Performance is almost the same as with vanilla+xlock patch: https://docs.google.com/spreadsheets/d/1QOYfUehy8U3sdasMjGnPGQJY8JiRfZmlS64YRBM0YTo/edit?usp=sharing I wonder why instead of chaining transaction locks (which can be done quite easily) approach with extra tuple lock was chosen? May be I missed something? -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Thu, Feb 15, 2018 at 9:30 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > Hi, > > PostgreSQL performance degrades signficantly in case of high contention. > You can look at the attached YCSB results (ycsb-zipf-pool.png) to estimate > the level of this degradation. > > Postgres is acquiring two kind of heavy weight locks during update: it locks > TID of the updated tuple and XID of transaction created this version. > In debugger I see the following picture: if several transactions are trying > to update the same record, then first of all they compete for > SnapshotDirty.xmax transaction lock in EvalPlanQualFetch. > Then in heap_tuple_update they are trying to lock TID of the updated tuple: > heap_acquire_tuplock in heapam.c > There is no function named heap_tuple_update. Do you mean to say heap_update? > After that transactions wait completion of the transaction updated the > tuple: XactLockTableWait in heapam.c > > So in heap_acquire_tuplock all competing transactions are waiting for TID of > the updated version. When transaction which changed this tuple is committed, > one of the competitors will grant this lock and proceed, creating new > version of the tuple. Then all other competitors will be awaken and ... find > out that locked tuple is not the last version any more. > Then they will locate new version and try to lock it... The more competitors > we have, then more attempts they all have to perform (quadratic complexity). > The attempts are controlled by marking the tuple as locked by me after waiting on SnapshotDirty.xmax. So, the backend which marks the tuple as locked must get the tuple to update and I think it is ensured in code that only one backend will be allowed to do so. I can see some serialization in this logic, but I think we should first try to get the theory behind the contention problem you are seeing before trying to find the solution for it. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On Tue, Feb 20, 2018 at 10:34 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > > On 20.02.2018 19:39, Simon Riggs wrote: >> >> On 20 February 2018 at 16:07, Konstantin Knizhnik >> <k.knizhnik@postgrespro.ru> wrote: >>> >>> >>> On 20.02.2018 14:26, Simon Riggs wrote: >>>> >>>> Try locking the root tid rather than the TID, that is at least unique >>>> per page for a chain of tuples, just harder to locate. >>>> >>> As far as I understand, it is necessary to traverse the whole page to >>> locate >>> root tuple, isn't it? >>> If so, then I expect it to be too expensive operation. Scanning the whole >>> page on tuple update seems to be not an acceptable solution. >> >> Probably. >> >> It occurs to me that you can lock the root tid in index_fetch_heap(). >> I hear other DBMS lock via the index. >> >> However, anything you do with tuple locking could interact badly with >> heap_update and the various lock modes, so be careful. >> >> You also have contention for heap_page_prune_opt() and with SELECTs to >> consider, so I think you need to look at both page and tuple locking. >> > > So, if I correctly understand the primary goal of setting tuple lock in > heapam.c is to avoid contention caused > by concurrent release of all waiters. > But my transaction lock chaining patch eliminates this problem in other way. > So what about combining your patch (do not lock Snapshot.xmax) + with my > xlock patch and ... completely eliminate tuple lock in heapam? > In this case update of tuple will require obtaining just one heavy weight > lock. > > I made such experiment and didn't find any synchronization problems with my > pgrw test. > Performance is almost the same as with vanilla+xlock patch: > > https://docs.google.com/spreadsheets/d/1QOYfUehy8U3sdasMjGnPGQJY8JiRfZmlS64YRBM0YTo/edit?usp=sharing > > I wonder why instead of chaining transaction locks (which can be done quite > easily) approach with extra tuple lock was chosen? Can you please explain, how it can be done easily without extra tuple locks? I have tried to read your patch but due to lack of comments, it is not clear what you are trying to achieve. As far as I can see you are changing the locktag passed to LockAcquireExtended by the first waiter for the transaction. How will it achieve the serial waiting protocol (queue the waiters for tuple) for a particular tuple being updated? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 26.02.2018 17:00, Amit Kapila wrote: > On Thu, Feb 15, 2018 at 9:30 PM, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> Hi, >> >> PostgreSQL performance degrades signficantly in case of high contention. >> You can look at the attached YCSB results (ycsb-zipf-pool.png) to estimate >> the level of this degradation. >> >> Postgres is acquiring two kind of heavy weight locks during update: it locks >> TID of the updated tuple and XID of transaction created this version. >> In debugger I see the following picture: if several transactions are trying >> to update the same record, then first of all they compete for >> SnapshotDirty.xmax transaction lock in EvalPlanQualFetch. >> Then in heap_tuple_update they are trying to lock TID of the updated tuple: >> heap_acquire_tuplock in heapam.c >> > There is no function named heap_tuple_update. Do you mean to say heap_update? Yes, sorry. I mean heap_update. > >> After that transactions wait completion of the transaction updated the >> tuple: XactLockTableWait in heapam.c >> >> So in heap_acquire_tuplock all competing transactions are waiting for TID of >> the updated version. When transaction which changed this tuple is committed, >> one of the competitors will grant this lock and proceed, creating new >> version of the tuple. Then all other competitors will be awaken and ... find >> out that locked tuple is not the last version any more. >> Then they will locate new version and try to lock it... The more competitors >> we have, then more attempts they all have to perform (quadratic complexity). >> > The attempts are controlled by marking the tuple as locked by me after > waiting on SnapshotDirty.xmax. So, the backend which marks the tuple > as locked must get the tuple to update and I think it is ensured in > code that only one backend will be allowed to do so. I can see some > serialization in this logic, but I think we should first try to get > the theory behind the contention problem you are seeing before trying > to find the solution for it. > Sorry, I could not say, that I completely understand logic of locking updated tuples in Postgres, although I have spent some time inspecting this code. It seems to be strange and quite inefficient to me that updating one tuple requires obtaining three heavy-weight locks. Did you read this thread: https://www.postgresql.org/message-id/CANP8%2BjKoMAyXvMO2hUqFzHX8fYSFc82q9MEse2zAEOC8vxwDfA%40mail.gmail.com In any, the summary of all my last experiments with locking is the following: 1. My proposal with transaction lock chaining can reduce performance degradation with increasing number of competing transactions. But degradation still takes place. Moreover, my recent experiments shows that lock chaining can cause deadlocks. It seems to me that I know the reason of such deadlocks, but right now have no idea how to fix them. 2. Replacing tuple TID locks with tuple PK lock has positive effect only if lock is hold until end of transaction. Certainly we can not lock all updated tuples (it will cause lock hash overflow). But we can keep until end of transaction just some small number of tuple locks. Unfortunately it is not the only problem with this solution: it is relatively simple to implement in case of integer primary key, but handling all kind of PKs, including compound keys requires more efforts. Also there can be no PK at all... 3. Alternative to PK lock is root tuple lock (head of hot update chain). Unfortunately there is no efficient way (at least I do not know one) of locating root tuple. Scanning the whole page seems to be too inefficient. If we perform index scan, than we actually start with root tuple, so it is possible to somehow propagate it. But it doesn't work in case of heap scan. And I suspect that as in case of PK lock, it can increase performance only of lock is hold until end of transaction. So the problem with lock contention really exist. It can be quite easily reproduced at the computer with large number of core with either pgbench with zipf distribution, either with YCSB benchmark, either with my pgrw benchmark... But how to fix it is unclear. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On 26.02.2018 17:20, Amit Kapila wrote: > On Tue, Feb 20, 2018 at 10:34 PM, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> >> On 20.02.2018 19:39, Simon Riggs wrote: >>> On 20 February 2018 at 16:07, Konstantin Knizhnik >>> <k.knizhnik@postgrespro.ru> wrote: >>>> >>>> On 20.02.2018 14:26, Simon Riggs wrote: >>>>> Try locking the root tid rather than the TID, that is at least unique >>>>> per page for a chain of tuples, just harder to locate. >>>>> >>>> As far as I understand, it is necessary to traverse the whole page to >>>> locate >>>> root tuple, isn't it? >>>> If so, then I expect it to be too expensive operation. Scanning the whole >>>> page on tuple update seems to be not an acceptable solution. >>> Probably. >>> >>> It occurs to me that you can lock the root tid in index_fetch_heap(). >>> I hear other DBMS lock via the index. >>> >>> However, anything you do with tuple locking could interact badly with >>> heap_update and the various lock modes, so be careful. >>> >>> You also have contention for heap_page_prune_opt() and with SELECTs to >>> consider, so I think you need to look at both page and tuple locking. >>> >> So, if I correctly understand the primary goal of setting tuple lock in >> heapam.c is to avoid contention caused >> by concurrent release of all waiters. >> But my transaction lock chaining patch eliminates this problem in other way. >> So what about combining your patch (do not lock Snapshot.xmax) + with my >> xlock patch and ... completely eliminate tuple lock in heapam? >> In this case update of tuple will require obtaining just one heavy weight >> lock. >> >> I made such experiment and didn't find any synchronization problems with my >> pgrw test. >> Performance is almost the same as with vanilla+xlock patch: >> >> https://docs.google.com/spreadsheets/d/1QOYfUehy8U3sdasMjGnPGQJY8JiRfZmlS64YRBM0YTo/edit?usp=sharing >> >> I wonder why instead of chaining transaction locks (which can be done quite >> easily) approach with extra tuple lock was chosen? > Can you please explain, how it can be done easily without extra tuple > locks? I have tried to read your patch but due to lack of comments, > it is not clear what you are trying to achieve. As far as I can see > you are changing the locktag passed to LockAcquireExtended by the > first waiter for the transaction. How will it achieve the serial > waiting protocol (queue the waiters for tuple) for a particular tuple > being updated? > The idea of transaction lock chaining was very simple. I have explained it in the first main in this thread. Assumed that transaction T1 has updated tuple R1. Transaction T2 also tries to update this tuple and so waits for T1 XID. If then yet another transaction T3 also tries to update R1, then it should wait for T2, not for T1. In this case commit of transaction T1 will awake just one transaction and not all other transaction pretending to update this tuple. So there will be no races between multiple transactions which consume a lot of system resources. Unfortunately the way i have implemented this idea: release lock of the original XID and tries to obtain lock of the XID of last waiting transaction can lead to deadlock. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, Feb 26, 2018 at 8:26 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > On 26.02.2018 17:20, Amit Kapila wrote: >> >> Can you please explain, how it can be done easily without extra tuple >> locks? I have tried to read your patch but due to lack of comments, >> it is not clear what you are trying to achieve. As far as I can see >> you are changing the locktag passed to LockAcquireExtended by the >> first waiter for the transaction. How will it achieve the serial >> waiting protocol (queue the waiters for tuple) for a particular tuple >> being updated? >> > The idea of transaction lock chaining was very simple. I have explained it > in the first main in this thread. > Assumed that transaction T1 has updated tuple R1. > Transaction T2 also tries to update this tuple and so waits for T1 XID. > If then yet another transaction T3 also tries to update R1, then it should > wait for T2, not for T1. > Isn't this exactly we try to do via tuple locks (heap_acquire_tuplock)? Currently, T2 before waiting for T1 will acquire tuple lock on R1 and T3 will wait on T2 (not on T-1) to release the tuple lock on R-1 and similarly, the other waiters should form a queue and will be waked one-by-one. After this as soon T2 is waked up, it will release the lock on tuple and will try to fetch the updated tuple. Now, releasing the lock on tuple by T-2 will allow T-3 to also proceed and as T-3 was supposed to wait on T-1 (according to tuple satisfies API), it will immediately be released and it will also try to do the same work as is done by T-2. One of those will succeed and other have to re-fetch the updated-tuple again. I think in this whole process backends may need to wait multiple times either on tuple lock or xact lock. It seems the reason for these waits is that we immediately release the tuple lock (acquired by heap_acquire_tuplock) once the transaction on which we were waiting is finished. AFAICU, the reason for releasing the tuple lock immediately instead of at end of the transaction is that we don't want to accumulate too many locks as that can lead to the unbounded use of shared memory. How about if we release the tuple lock at end of the transaction unless the transaction acquires more than a certain threshold (say 10 or 50) of such locks in which case we will fall back to current strategy? -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 28.02.2018 16:32, Amit Kapila wrote: > On Mon, Feb 26, 2018 at 8:26 PM, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> On 26.02.2018 17:20, Amit Kapila wrote: >>> Can you please explain, how it can be done easily without extra tuple >>> locks? I have tried to read your patch but due to lack of comments, >>> it is not clear what you are trying to achieve. As far as I can see >>> you are changing the locktag passed to LockAcquireExtended by the >>> first waiter for the transaction. How will it achieve the serial >>> waiting protocol (queue the waiters for tuple) for a particular tuple >>> being updated? >>> >> The idea of transaction lock chaining was very simple. I have explained it >> in the first main in this thread. >> Assumed that transaction T1 has updated tuple R1. >> Transaction T2 also tries to update this tuple and so waits for T1 XID. >> If then yet another transaction T3 also tries to update R1, then it should >> wait for T2, not for T1. >> > Isn't this exactly we try to do via tuple locks > (heap_acquire_tuplock)? Currently, T2 before waiting for T1 will > acquire tuple lock on R1 and T3 will wait on T2 (not on T-1) to > release the tuple lock on R-1 and similarly, the other waiters should > form a queue and will be waked one-by-one. After this as soon T2 is > waked up, it will release the lock on tuple and will try to fetch the > updated tuple. Now, releasing the lock on tuple by T-2 will allow T-3 > to also proceed and as T-3 was supposed to wait on T-1 (according to > tuple satisfies API), it will immediately be released and it will also > try to do the same work as is done by T-2. One of those will succeed > and other have to re-fetch the updated-tuple again. Yes, but two notices: 1. Tuple lock is used inside heap_* functions. But not in EvalPlanQualFetch where transaction lock is also used. 2. Tuple lock is hold until the end of update, not until commit of the transaction. So other transaction can receive conrol before this transaction is completed. And contention still takes place. Contention is reduced and performance is increased only if locks (either tuple lock, either xid lock) are hold until the end of transaction. Unfortunately it may lead to deadlock. My last attempt to reduce contention was to replace shared lock with exclusive in XactLockTableWait and removing unlock from this function. So only one transaction can get xact lock and will will hold it until the end of transaction. Also tuple lock seems to be not needed in this case. It shows better performance on pgrw test but on YCSB benchmark with workload A (50% of updates) performance was even worser than with vanilla postgres. But was is wost of all - there are deadlocks in pgbench tests. > I think in this whole process backends may need to wait multiple times > either on tuple lock or xact lock. It seems the reason for these > waits is that we immediately release the tuple lock (acquired by > heap_acquire_tuplock) once the transaction on which we were waiting is > finished. AFAICU, the reason for releasing the tuple lock immediately > instead of at end of the transaction is that we don't want to > accumulate too many locks as that can lead to the unbounded use of > shared memory. How about if we release the tuple lock at end of the > transaction unless the transaction acquires more than a certain > threshold (say 10 or 50) of such locks in which case we will fall back > to current strategy? > Certainly, I have tested such version. Unfortunately it doesn't help. Tuple lock is using tuple TID. But once transaction has made the update, new version of tuple will be produced with different TID and all new transactions will see this version, so them will not notice this lock at all. This is why my first attempt to address content was to replace TID lock with PK (primary key) lock. And it really helps to reduce contention and degradation of performance with increasing number of connections. But it is not so easy to correctly extract Pk in all cases. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Thu, Mar 1, 2018 at 1:22 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > On 28.02.2018 16:32, Amit Kapila wrote: >> >> On Mon, Feb 26, 2018 at 8:26 PM, Konstantin Knizhnik >> <k.knizhnik@postgrespro.ru> wrote: > > > Yes, but two notices: > 1. Tuple lock is used inside heap_* functions. But not in EvalPlanQualFetch > where transaction lock is also used. > 2. Tuple lock is hold until the end of update, not until commit of the > transaction. So other transaction can receive conrol before this transaction > is completed. And contention still takes place. > Contention is reduced and performance is increased only if locks (either > tuple lock, either xid lock) are hold until the end of transaction. > Unfortunately it may lead to deadlock. > > My last attempt to reduce contention was to replace shared lock with > exclusive in XactLockTableWait and removing unlock from this function. So > only one transaction can get xact lock and will will hold it until the end > of transaction. Also tuple lock seems to be not needed in this case. It > shows better performance on pgrw test but on YCSB benchmark with workload A > (50% of updates) performance was even worser than with vanilla postgres. But > was is wost of all - there are deadlocks in pgbench tests. > >> I think in this whole process backends may need to wait multiple times >> either on tuple lock or xact lock. It seems the reason for these >> waits is that we immediately release the tuple lock (acquired by >> heap_acquire_tuplock) once the transaction on which we were waiting is >> finished. AFAICU, the reason for releasing the tuple lock immediately >> instead of at end of the transaction is that we don't want to >> accumulate too many locks as that can lead to the unbounded use of >> shared memory. How about if we release the tuple lock at end of the >> transaction unless the transaction acquires more than a certain >> threshold (say 10 or 50) of such locks in which case we will fall back >> to current strategy? >> > Certainly, I have tested such version. Unfortunately it doesn't help. Tuple > lock is using tuple TID. But once transaction has made the update, new > version of tuple will be produced with different TID and all new > transactions will see this version, so them will not notice this lock at > all. > Sure, but out of all new transaction again the only one transaction will allow to update it and among new waiters, only one should get access to it. The situation should be better than when all the waiters attempt to lock and update the tuple with same CTID. -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com
On 03.03.2018 16:44, Amit Kapila wrote: > On Thu, Mar 1, 2018 at 1:22 PM, Konstantin Knizhnik > <k.knizhnik@postgrespro.ru> wrote: >> On 28.02.2018 16:32, Amit Kapila wrote: >>> On Mon, Feb 26, 2018 at 8:26 PM, Konstantin Knizhnik >>> <k.knizhnik@postgrespro.ru> wrote: >> >> Yes, but two notices: >> 1. Tuple lock is used inside heap_* functions. But not in EvalPlanQualFetch >> where transaction lock is also used. >> 2. Tuple lock is hold until the end of update, not until commit of the >> transaction. So other transaction can receive conrol before this transaction >> is completed. And contention still takes place. >> Contention is reduced and performance is increased only if locks (either >> tuple lock, either xid lock) are hold until the end of transaction. >> Unfortunately it may lead to deadlock. >> >> My last attempt to reduce contention was to replace shared lock with >> exclusive in XactLockTableWait and removing unlock from this function. So >> only one transaction can get xact lock and will will hold it until the end >> of transaction. Also tuple lock seems to be not needed in this case. It >> shows better performance on pgrw test but on YCSB benchmark with workload A >> (50% of updates) performance was even worser than with vanilla postgres. But >> was is wost of all - there are deadlocks in pgbench tests. >> >>> I think in this whole process backends may need to wait multiple times >>> either on tuple lock or xact lock. It seems the reason for these >>> waits is that we immediately release the tuple lock (acquired by >>> heap_acquire_tuplock) once the transaction on which we were waiting is >>> finished. AFAICU, the reason for releasing the tuple lock immediately >>> instead of at end of the transaction is that we don't want to >>> accumulate too many locks as that can lead to the unbounded use of >>> shared memory. How about if we release the tuple lock at end of the >>> transaction unless the transaction acquires more than a certain >>> threshold (say 10 or 50) of such locks in which case we will fall back >>> to current strategy? >>> >> Certainly, I have tested such version. Unfortunately it doesn't help. Tuple >> lock is using tuple TID. But once transaction has made the update, new >> version of tuple will be produced with different TID and all new >> transactions will see this version, so them will not notice this lock at >> all. >> > Sure, but out of all new transaction again the only one transaction > will allow to update it and among new waiters, only one should get > access to it. The situation should be better than when all the > waiters attempt to lock and update the tuple with same CTID. > I do not argue against necessity of tuple lock. It certainly helps to reduce contention... But still is not able to completely eliminate the problem (prevent significant performance degradation with increasing number of competing transactions). Better results can be achieved with: a) Replacing TID lock with PK lock and holding this lock till the end of transaction b) Chaining xact locks. I failed to make second approach work, it still suffers from deadlocks. I wonder if approach with PK locks can be considered as perspective? Should I spent some more time to make it more reliable (support different PK types, handle cases of non-hot updates and tables without PK,,...)? Or it is dead-end solution in any case? Another idea suggested by Simon is to lock root tuple (head of hot update chain). But there is no efficient way to locate this root in Postgres. -- Konstantin Knizhnik Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
On Mon, Mar 5, 2018 at 1:26 PM, Konstantin Knizhnik <k.knizhnik@postgrespro.ru> wrote: > > On 03.03.2018 16:44, Amit Kapila wrote: >> >> On Thu, Mar 1, 2018 at 1:22 PM, Konstantin Knizhnik >> <k.knizhnik@postgrespro.ru> wrote: >>> >>> On 28.02.2018 16:32, Amit Kapila wrote: >>>> >>>> On Mon, Feb 26, 2018 at 8:26 PM, Konstantin Knizhnik >>>> <k.knizhnik@postgrespro.ru> wrote: >>> >>> >>> Yes, but two notices: >>> 1. Tuple lock is used inside heap_* functions. But not in >>> EvalPlanQualFetch >>> where transaction lock is also used. >>> 2. Tuple lock is hold until the end of update, not until commit of the >>> transaction. So other transaction can receive conrol before this >>> transaction >>> is completed. And contention still takes place. >>> Contention is reduced and performance is increased only if locks (either >>> tuple lock, either xid lock) are hold until the end of transaction. >>> Unfortunately it may lead to deadlock. >>> >>> My last attempt to reduce contention was to replace shared lock with >>> exclusive in XactLockTableWait and removing unlock from this function. So >>> only one transaction can get xact lock and will will hold it until the >>> end >>> of transaction. Also tuple lock seems to be not needed in this case. It >>> shows better performance on pgrw test but on YCSB benchmark with workload >>> A >>> (50% of updates) performance was even worser than with vanilla postgres. >>> But >>> was is wost of all - there are deadlocks in pgbench tests. >>> >>>> I think in this whole process backends may need to wait multiple times >>>> either on tuple lock or xact lock. It seems the reason for these >>>> waits is that we immediately release the tuple lock (acquired by >>>> heap_acquire_tuplock) once the transaction on which we were waiting is >>>> finished. AFAICU, the reason for releasing the tuple lock immediately >>>> instead of at end of the transaction is that we don't want to >>>> accumulate too many locks as that can lead to the unbounded use of >>>> shared memory. How about if we release the tuple lock at end of the >>>> transaction unless the transaction acquires more than a certain >>>> threshold (say 10 or 50) of such locks in which case we will fall back >>>> to current strategy? >>>> >>> Certainly, I have tested such version. Unfortunately it doesn't help. >>> Tuple >>> lock is using tuple TID. But once transaction has made the update, new >>> version of tuple will be produced with different TID and all new >>> transactions will see this version, so them will not notice this lock at >>> all. >>> >> Sure, but out of all new transaction again the only one transaction >> will allow to update it and among new waiters, only one should get >> access to it. The situation should be better than when all the >> waiters attempt to lock and update the tuple with same CTID. >> > > I do not argue against necessity of tuple lock. > It certainly helps to reduce contention... But still is not able to > completely eliminate the problem (prevent significant performance > degradation with increasing number of competing transactions). > Yeah, that is what I thought should happen. I think if we have that kind of solution, it will perform much better with zheap [1] where TIDs won't change in many of the cases. > Better > results can be achieved with: > a) Replacing TID lock with PK lock and holding this lock till the end of > transaction > b) Chaining xact locks. > > I failed to make second approach work, it still suffers from deadlocks. > I wonder if approach with PK locks can be considered as perspective? > Should I spent some more time to make it more reliable (support different PK > types, handle cases of non-hot updates and tables without PK,,...)? > Or it is dead-end solution in any case? > I don't know, maybe you can try to completely sketch out the solution and see how much impact it has. If it can be done with the reasonable effort, then maybe it is worth pursuing. [1] - https://www.postgresql.org/message-id/CAA4eK1%2BYtM5vxzSM2NZm%2BpC37MCwyvtkmJrO_yRBQeZDp9Wa2w%40mail.gmail.com -- With Regards, Amit Kapila. EnterpriseDB: http://www.enterprisedb.com