Thread: [GENERAL] pg_rewind - restore new slave failed to startup during recovery
Hi
I have 1 master and 1 slave wal streaming replication setup and the Application connects via a load balancer (LTM) where the all connections are redirected to the master member (master db).
We have archive_mode enabled.
I am trying to test to use pg_rewind to restore the new slave (old master) after a failover while the system is under load.
Here are the steps I take to test:
1. Disable the master ltm member (all connections redired to slave member)
2. Promote slave (touch promote.me)
3. Stop the master db (old master)
4. Do pg_rewind on the new slave (old master)
5. Start the new slave.
Please see attached psql.jpg for the result from the pg_rewind.
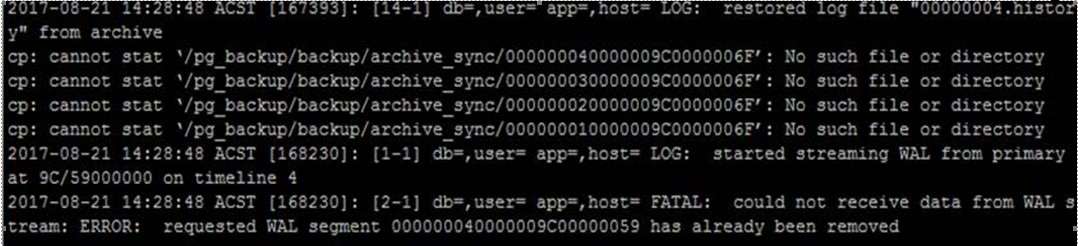
However, when I tried to start the new slave, I am getting the error that it cannot locate the archive wal files and can not receive data from WAL stream error.
Please see attached logs.jpg.
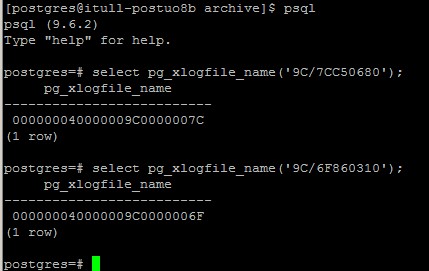
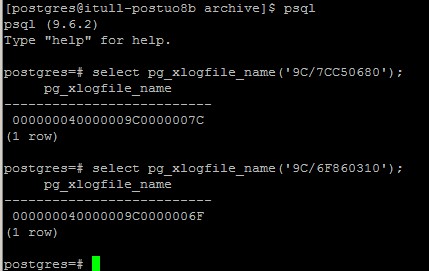
Checking the on the new master, I see that the check point that its trying to restore is the file 000000040000009C0000006F, but the file does not exist anywhere on the new master. Not in the pg_xlog or the archive folder. (as specified in the postgresql.conf)
Please see attached psql.jpg.
Here is my recovery.conf :
standby_mode = 'on'
primary_conninfo = 'host=10.69.19.18 user=replicant’
trigger_file = '/var/run/promote_me'
restore_command = 'cp /pg_backup/backup/archive_sync/%f "%p"'
does anyone know why?
Under what conditions will pg_rewind wont’ work?
Thanks.
Regards
Dylan
Attachment
{kind=link}
{kind=link}
{kind=link}
Re: [GENERAL] pg_rewind - restore new slave failed to startup during recovery
On Tue, Aug 22, 2017 at 9:52 AM, Dylan Luong <Dylan.Luong@unisa.edu.au> wrote: > I have 1 master and 1 slave wal streaming replication setup and the > Application connects via a load balancer (LTM) where the all connections are > redirected to the master member (master db). > > We have archive_mode enabled. First things first. What is the version of PostgreSQL involved here? > I am trying to test to use pg_rewind to restore the new slave (old master) > after a failover while the system is under load. Don't worry. pg_rewind works :) > Here are the steps I take to test: > > 1. Disable the master ltm member (all connections redired to slave > member) > 2. Promote slave (touch promote.me) > 3. Stop the master db (old master) > 4. Do pg_rewind on the new slave (old master) > 5. Start the new slave. That flow looks correct to me. No I think that you should trigger manually a checkpoint after step 2 on the promoted standby so as its control file gets forcibly updated correctly with its new timeline number. This is a small but critical point people usually miss. The documentation of pg_rewind does not mention this point when using a live source server, and many people have fallen into this trap up to now... We should really mention that in the docs. What do others think? > Checking the on the new master, I see that the check point that its trying > to restore is the file 000000040000009C0000006F, but the file does not exist > anywhere on the new master. Not in the pg_xlog or the archive folder. (as > specified in the postgresql.conf) 4 is the number of the last timeline the promoted standby has been using, right? > Please see attached psql.jpg. > > Here is my recovery.conf : > standby_mode = 'on' > primary_conninfo = 'host=10.69.19.18 user=replicant’ > trigger_file = '/var/run/promote_me' > restore_command = 'cp /pg_backup/backup/archive_sync/%f "%p"' > > does anyone know why? What are the contents of /pg_backup/backup/archive_sync/? Are you sure that the promoted standby has archived correctly the first segment of its new timeline for example? > Under what conditions will pg_rewind wont’ work? Only one WAL segment missing would prevent any base backup or rewound node to reach a consistent point. You need to be careful about the contents of your archives. Now a failover done correctly is a tricky thing, which could likely fail if you don't issue a checkpoint immediately on the promoted standby if pg_rewind is kicked in the process before an automatic checkpoint happens (because of timeout or volume, whichever). -- Michael
Thanks Michael. > First things first. What is the version of PostgreSQL involved here? The PostgreSQL is version 9.6. >4 is the number of the last timeline the promoted standby has been using, right? The history file in pg_xlog, is dated at the time of promotion on the standby (current master) -rw-------. 1 postgres postgres 131 Aug 21 13:26 00000004.history $ more 00000004.history 1 20/5C000098 no recovery target specified 2 76/F8000098 no recovery target specified 3 9C/7CC50680 no recovery target specified > What are the contents of /pg_backup/backup/archive_sync/? The archive folder is /pg_backup/backup/archive, I ftp'ed all the contents from the /pg_backup/backup/archive folder fromthe new master to the /pg_backup/backup/archive_sync on the new slave. -----Original Message----- From: Michael Paquier [mailto:michael.paquier@gmail.com] Sent: Tuesday, 22 August 2017 10:37 AM To: Dylan Luong <Dylan.Luong@unisa.edu.au> Cc: pgsql-general@postgresql.org Subject: Re: [GENERAL] pg_rewind - restore new slave failed to startup during recovery On Tue, Aug 22, 2017 at 9:52 AM, Dylan Luong <Dylan.Luong@unisa.edu.au> wrote: > I have 1 master and 1 slave wal streaming replication setup and the > Application connects via a load balancer (LTM) where the all > connections are redirected to the master member (master db). > > We have archive_mode enabled. First things first. What is the version of PostgreSQL involved here? > I am trying to test to use pg_rewind to restore the new slave (old > master) after a failover while the system is under load. Don't worry. pg_rewind works :) > Here are the steps I take to test: > > 1. Disable the master ltm member (all connections redired to slave > member) > 2. Promote slave (touch promote.me) > 3. Stop the master db (old master) > 4. Do pg_rewind on the new slave (old master) > 5. Start the new slave. That flow looks correct to me. No I think that you should trigger manually a checkpoint after step 2 on the promoted standbyso as its control file gets forcibly updated correctly with its new timeline number. This is a small but criticalpoint people usually miss. The documentation of pg_rewind does not mention this point when using a live source server,and many people have fallen into this trap up to now... We should really mention that in the docs. What do othersthink? > Checking the on the new master, I see that the check point that its > trying to restore is the file 000000040000009C0000006F, but the file > does not exist anywhere on the new master. Not in the pg_xlog or the > archive folder. (as specified in the postgresql.conf) 4 is the number of the last timeline the promoted standby has been using, right? > Please see attached psql.jpg. > > Here is my recovery.conf : > standby_mode = 'on' > primary_conninfo = 'host=10.69.19.18 user=replicant’ > trigger_file = '/var/run/promote_me' > restore_command = 'cp /pg_backup/backup/archive_sync/%f "%p"' > > does anyone know why? What are the contents of /pg_backup/backup/archive_sync/? Are you sure that the promoted standby has archived correctly thefirst segment of its new timeline for example? > Under what conditions will pg_rewind wont’ work? Only one WAL segment missing would prevent any base backup or rewound node to reach a consistent point. You need to be carefulabout the contents of your archives. Now a failover done correctly is a tricky thing, which could likely fail if youdon't issue a checkpoint immediately on the promoted standby if pg_rewind is kicked in the process before an automaticcheckpoint happens (because of timeout or volume, whichever). -- Michael
Re: [GENERAL] pg_rewind - restore new slave failed to startup during recovery
On Tue, Aug 22, 2017 at 9:52 AM, Dylan Luong <Dylan.Luong@unisa.edu.au> wrote:
> 1. Disable the master ltm member (all connections redired to slave
> member)
> 2. Promote slave (touch promote.me)
> 3. Stop the master db (old master)
> 4. Do pg_rewind on the new slave (old master)
> 5. Start the new slave.
That flow looks correct to me. No I think that you should trigger
manually a checkpoint after step 2 on the promoted standby so as its
control file gets forcibly updated correctly with its new timeline
number. This is a small but critical point people usually miss. The
documentation of pg_rewind does not mention this point when using a
live source server, and many people have fallen into this trap up to
now... We should really mention that in the docs. What do others
think?
Re: [GENERAL] pg_rewind - restore new slave failed to startup during recovery
On Tue, Aug 22, 2017 at 11:39 PM, Magnus Hagander <magnus@hagander.net> wrote: > On Tue, Aug 22, 2017 at 3:06 AM, Michael Paquier <michael.paquier@gmail.com> > wrote: >> That flow looks correct to me. No I think that you should trigger >> manually a checkpoint after step 2 on the promoted standby so as its >> control file gets forcibly updated correctly with its new timeline >> number. This is a small but critical point people usually miss. The >> documentation of pg_rewind does not mention this point when using a >> live source server, and many people have fallen into this trap up to >> now... We should really mention that in the docs. What do others >> think? > > If the documentation is missing such a clearly critical step, then I would > say that's a definite documentation bug and it needs to be fixed. We can't > really fault people for missing a small detail if we didn't document the > small detail... What do you think about the attached? I would recommend a back-patch down to 9.5 to get the documentation right everywhere but I think as well that this may not be enough. We could document as well an example of a full-fledged failover flow in the Notes, in short: 1) Promote a standby. 2) Stop the old master cleanly. If it has been killed atrociously, make it finish recovery once and then stop it so as its WAL data is ahead of the point WAL has fork after the promotion (shutdown checkpoint record is at least here). 3) Prepare source server for the rewind. 3-1) Using file copy, stop the source server (promoted standby) cleanly first. 3-2) Using SQL, issue a checkpoint on the source server to update its control file and making sure that the timeline number is up-do-date on disk. 4) Perform the actual rewind. This will need WAL segments on the target from the point WAL has forked to the shutdown checkpoint record created at step 2). 5) Create recovery.conf on the target and point it to the source for streaming, or archives. Then let it perform recovery. -- Michael