Thread: [HACKERS] Fix performance degradation of contended LWLock on NUMA
Good day, everyone.
This patch improves performance of contended LWLock.
It was tested on 4 socket 72 core x86 server (144 HT) Centos 7.1
gcc 4.8.5
Results:
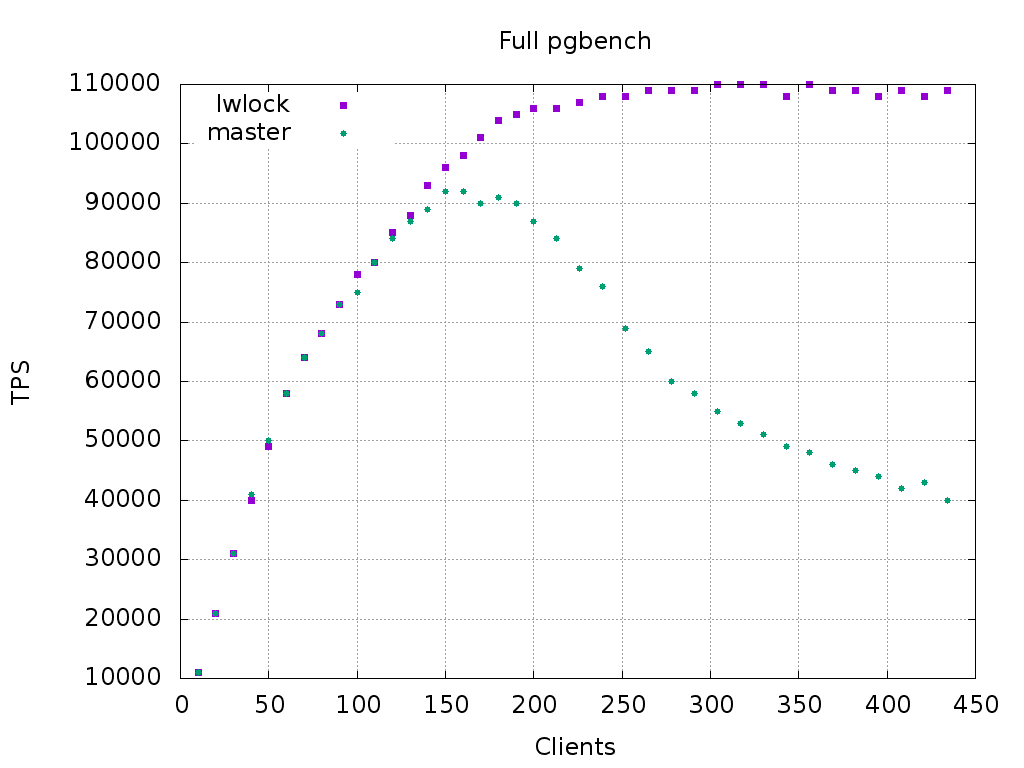
pgbench -i -s 300 + pgbench --skip-some-updates
Clients | master | patched
========+=========+=======
30 | 32k | 32k
50 | 53k | 53k
100 | 102k | 107k
150 | 120k | 131k
200 | 129k | 148k
252 | 121k | 159k
304 | 101k | 163k
356 | 79k | 166k
395 | 70k | 166k
434 | 62k | 166k
pgbench -i -s 900 + pgbench
Clients | master | patched
========+=========+=======
30 | 31k | 31k
50 | 50k | 49k
100 | 75k | 78k
150 | 92k | 96k
200 | 87k | 106k
252 | 69k | 108k
304 | 55k | 110k
356 | 48k | 110k
395 | 44k | 108k
434 | 40k | 109k
I could not claim read-only benchmarks are affected in any way: results
are unstable between postgresql restarts and varies in a same interval
for both versions. Although some micro-optimization were made to ensure
this parity.
Since investigations exist on changing shared buffers structure (by
removing LWLock from a buffer hash partition lock [1]), I stopped
attempts to gather more reliable statistic for readonly benchmarks.
[1] Takashi Horikawa "Don't stop the world"
https://www.pgcon.org/2017/schedule/events/1078.en.html
Also, looks like patch doesn't affect single NUMA node performance
significantly.
postgresql.conf is tuned with following parameters:
shared_buffers = 32GB
max_connections = 500
fsync = on
synchronous_commit = on
full_page_writes = off
wal_buffers = 16MB
wal_writer_flush_after = 16MB
commit_delay = 2
max_wal_size = 16GB
Patch changes the way LWLock is acquired.
Before patch, lock is acquired using following procedure:
1. first LWLock->state is checked for ability to take a lock, and CAS
performed (either lock could be acquired or not). And it is retried if
status were changed.
2. if lock is not acquired at first 1, Proc is put into wait list, using
LW_FLAG_LOCKED bit of LWLock->state as a spin-lock for wait list.
In fact, profile shows that LWLockWaitListLock spends a lot of CPU on
contendend LWLock (upto 20%).
Additional CAS loop is inside pg_atomic_fetch_or_u32 for setting
LW_FLAG_HAS_WAITERS. And releasing wait list lock is another CAS loop
on the same LWLock->state.
3. after that state is checked again, because lock could be released
before Proc were queued into wait list.
4. if lock were acquired at step 3, Proc should be dequeued from wait
list (another spin lock and CAS loop). And this operation could be
quite heavy, because whole list should be traversed.
Patch makes lock acquiring in single CAS loop:
1. LWLock->state is read, and ability for lock acquiring is detected.
If there is possibility to take a lock, CAS tried.
If CAS were successful, lock is aquired (same to original version).
2. but if lock is currently held by other backend, we check ability for
taking WaitList lock. If wait list lock is not help by anyone, CAS
perfomed for taking WaitList lock and set LW_FLAG_HAS_WAITERS at once.
If CAS were successful, then LWLock were still held at the moment wait
list lock were held - this proves correctness of new algorithm. And
Proc is queued to wait list then.
3. Otherwise spin_delay is performed, and loop returns to step 1.
So invariant is preserved:
- either we grab the lock,
- or we set HAS_WAITERS while lock were held by someone, and queue self
into wait list.
Algorithm for LWLockWaitForVar is also refactored. New version is:
1. If lock is not held by anyone, it immediately exit.
2. Otherwise it is checked for ability to take WaitList lock, because
variable is protected with it. If so, CAS is performed, and if it is
successful, loop breaked to step 4.
3. Otherwise spin_delay perfomed, and loop returns to step 1.
4. var is checked for change.
If it were changed, we unlock wait list lock and exit.
Note: it could not change in following steps because we are holding
wait list lock.
5. Otherwise CAS on setting necessary flags is performed. If it succeed,
then queue Proc to wait list and exit.
6. If Case failed, then there is possibility for LWLock to be already
released - if so then we should unlock wait list and exit.
7. Otherwise loop returns to step 5.
So invariant is preserved:
- either we found LWLock free,
- or we found changed variable,
- or we set flags and queue self while LWLock were held.
Spin_delay is not performed at step 7, because we should release wait
list lock as soon as possible.
Additionally, taking wait list lock is skipped in both algorithms if
SpinDelayStatus.spins is less than part of spins_per_delay loop
iterations (so, it is initial iterations, and some iterations after
pg_usleep, because SpinDelayStatus.spins is reset after sleep). It
effectively turns LWLock into spinlock on low contended case. It was
made because unpatched behaviour (test-queue-retest-unqueue) is already
looks like cutted spin, and shows on "contended but not much" load
sometimes better performance against patch without "spin". Also, before
adding "spin" top performance of patched were equal to top performance
of unpatched, it just didn't degrade.
(Thanks to Teodor Sigaev for suggestion).
Patch consists of 6 commits:
1. Change LWLockWaitListLock to have function-wide delayStatus instead
of local to atomic_read loop. It is already gives some improvement,
but not too much.
2. Refactor acquiring LWLock.
3. Refactor LWLockWaitForVar. Also, LWLockQueueSelf and
LWLockDeququeSelf are removed because they are not referenced since
this commit.
4. Make LWLock to look more like spin lock.
5. Fix comment about algorithm.
6. Make initialization of SpinDelayStatus lighter, because it is on a
fast path of LWLock.
As I couild understand, main benefit cames from XLogInsertLock,
XLogFlushLock and CLogControlLock. XLogInsertLock became spin-lock on
most cases, and it was remarkable boost to add "spin" behaviour to
LWLockWaitForVar because it is used in checking that xlog already
flushed till desired position. Other locks just stop to degrade on high
load.
Patch conflicts with LWLock optimization for Power processors
https://commitfest.postgresql.org/14/984/
Alexandr Korotkov (my chief) doesn't mind if this patch will be
accepted first, and Power will be readdressed after.
PS.
For SHARED lock `skip_wait_list = spins_per_delay / 2;` . Probably it is
better to set it to more conservative `spins_per_delay / 4`, but I have
no enough evidence in favor of either decision.
Though it is certainly better to have it larger, than
`spins_per_delay / 8` that is set for EXCLUSIVE lock.
With regards,
--
Sokolov Yura aka funny_falcon
Postgres Professional: https://postgrespro.ru
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
{kind=link}
{kind=link}
On Mon, Jun 5, 2017 at 9:22 AM, Sokolov Yura <funny.falcon@postgrespro.ru> wrote: > Good day, everyone. > > This patch improves performance of contended LWLock. > It was tested on 4 socket 72 core x86 server (144 HT) Centos 7.1 > gcc 4.8.5 > > Patch makes lock acquiring in single CAS loop: > 1. LWLock->state is read, and ability for lock acquiring is detected. > If there is possibility to take a lock, CAS tried. > If CAS were successful, lock is aquired (same to original version). > 2. but if lock is currently held by other backend, we check ability for > taking WaitList lock. If wait list lock is not help by anyone, CAS > perfomed for taking WaitList lock and set LW_FLAG_HAS_WAITERS at once. > If CAS were successful, then LWLock were still held at the moment wait > list lock were held - this proves correctness of new algorithm. And > Proc is queued to wait list then. > 3. Otherwise spin_delay is performed, and loop returns to step 1. Interesting work. Thanks for posting. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2017-06-05 16:22, Sokolov Yura wrote: > Good day, everyone. > > This patch improves performance of contended LWLock. > Patch makes lock acquiring in single CAS loop: > 1. LWLock->state is read, and ability for lock acquiring is detected. > If there is possibility to take a lock, CAS tried. > If CAS were successful, lock is aquired (same to original version). > 2. but if lock is currently held by other backend, we check ability for > taking WaitList lock. If wait list lock is not help by anyone, CAS > perfomed for taking WaitList lock and set LW_FLAG_HAS_WAITERS at > once. > If CAS were successful, then LWLock were still held at the moment > wait > list lock were held - this proves correctness of new algorithm. And > Proc is queued to wait list then. > 3. Otherwise spin_delay is performed, and loop returns to step 1. > I'm sending rebased version with couple of one-line tweaks. (less skip_wait_list on shared lock, and don't update spin-stat on aquiring) With regards, -- Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On 2017-07-18 20:20, Sokolov Yura wrote: > On 2017-06-05 16:22, Sokolov Yura wrote: >> Good day, everyone. >> >> This patch improves performance of contended LWLock. >> Patch makes lock acquiring in single CAS loop: >> 1. LWLock->state is read, and ability for lock acquiring is detected. >> If there is possibility to take a lock, CAS tried. >> If CAS were successful, lock is aquired (same to original version). >> 2. but if lock is currently held by other backend, we check ability >> for >> taking WaitList lock. If wait list lock is not help by anyone, CAS >> perfomed for taking WaitList lock and set LW_FLAG_HAS_WAITERS at >> once. >> If CAS were successful, then LWLock were still held at the moment >> wait >> list lock were held - this proves correctness of new algorithm. And >> Proc is queued to wait list then. >> 3. Otherwise spin_delay is performed, and loop returns to step 1. >> > > I'm sending rebased version with couple of one-line tweaks. > (less skip_wait_list on shared lock, and don't update spin-stat on > aquiring) > > With regards, Here are results for zipfian distribution (50/50 r/w) in conjunction with "lazy hash table for XidInMVCCSnapshot": (https://www.postgresql.org/message-id/642da34694800dab801f04c62950ce8a%40postgrespro.ru) clients | master | hashsnap2 | hashsnap2_lwlock --------+--------+-----------+------------------ 10 | 203384 | 203813 | 204852 20 | 334344 | 334268| 363510 40 | 228496 | 231777 | 383820 70 | 146892 | 148173 | 221326 110 | 99741 | 111580 | 157327 160 | 65257 | 81230 | 112028 230 | 38344 | 56790 | 77514 310 | 22355 | 39249 | 55907 400 | 13402 | 26899 | 39742 500 | 8382 | 17855 | 28362 650 | 5313 | 11450 | 17497 800 | 3352 | 7816 | 11030 With regards, -- Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company
Hi,
On 07/18/2017 01:20 PM, Sokolov Yura wrote:
> I'm sending rebased version with couple of one-line tweaks.
> (less skip_wait_list on shared lock, and don't update spin-stat on
> aquiring)
>
I have been running this patch on a 2S/28C/56T/256Gb w/ 2 x RAID10 SSD
setup (1 to 375 clients on logged tables).
I'm seeing
-M prepared: Up to 11% improvement
-M prepared -S: No improvement, no regression ("noise")
-M prepared -N: Up to 12% improvement
for all runs the improvement shows up the closer you get to the number
of CPU threads, or above. Although I'm not seeing the same improvements
as you on very large client counts there are definitely improvements :)
Some comments:
==============
lwlock.c:
---------
+ * This race is avoiding by taking lock for wait list using CAS with a old
+ * state value, so it could succeed only if lock is still held.
Necessary flag
+ * is set with same CAS.
+ *
+ * Inside LWLockConflictsWithVar wait list lock is reused to protect
variable
+ * value. So first it is acquired to check variable value, then flags are
+ * set with second CAS before queueing to wait list to ensure lock were not
+ * released yet.
* This race is avoided by taking a lock for the wait list using CAS
with the old * state value, so it would only succeed if lock is still held.
Necessary flag * is set using the same CAS. * * Inside LWLockConflictsWithVar the wait list lock is reused to
protect the variable * value. First the lock is acquired to check the variable value, then
flags are * set with a second CAS before queuing to the wait list in order to
ensure that the lock was not * released yet.
+static void
+add_lwlock_stats_spin_stat(LWLock *lock, SpinDelayStatus *delayStatus)
Add a method description.
+ /*
+ * This barrier is never needed for correctness, and it is no-op
+ * on x86. But probably first iteration of cas loop in
+ * ProcArrayGroupClearXid will succeed oftener with it.
+ */
* "more often"
+static inline bool
+LWLockAttemptLockOrQueueSelf(LWLock *lock, LWLockMode mode, LWLockMode
waitmode)
I'll leave it to the Committer to decide if this method is too big to be
"inline".
+ /*
+ * We intentionally do not call finish_spin_delay here, cause loop above
+ * usually finished in queueing into wait list on contention, and doesn't
+ * reach spins_per_delay (and so, doesn't sleep inside of
+ * perform_spin_delay). Also, different LWLocks has very different
+ * contention pattern, and it is wrong to update spin-lock statistic based
+ * on LWLock contention.
+ */
/* * We intentionally do not call finish_spin_delay here, because the
loop above * usually finished by queuing into the wait list on contention, and
doesn't * reach spins_per_delay thereby doesn't sleep inside of * perform_spin_delay. Also, different LWLocks has very
different* contention pattern, and it is wrong to update spin-lock statistic based * on LWLock contention. */
s_lock.c:
---------
+ if (status->spins == 0)
+ /* but we didn't spin either, so ignore */
+ return;
Use { } for the if, or move the comment out of the nesting for readability.
Open questions:
---------------
* spins_per_delay as extern
* Calculation of skip_wait_list
You could run the patch through pgindent too.
Passes make check-world.
Status: Waiting on Author
Best regards, Jesper
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Hi, Jesper
Thank you for reviewing.
On 2017-09-08 18:33, Jesper Pedersen wrote:
> Hi,
>
> On 07/18/2017 01:20 PM, Sokolov Yura wrote:
>> I'm sending rebased version with couple of one-line tweaks.
>> (less skip_wait_list on shared lock, and don't update spin-stat on
>> aquiring)
>>
>
> I have been running this patch on a 2S/28C/56T/256Gb w/ 2 x RAID10 SSD
> setup (1 to 375 clients on logged tables).
>
> I'm seeing
>
> -M prepared: Up to 11% improvement
> -M prepared -S: No improvement, no regression ("noise")
> -M prepared -N: Up to 12% improvement
>
> for all runs the improvement shows up the closer you get to the number
> of CPU threads, or above. Although I'm not seeing the same
> improvements as you on very large client counts there are definitely
> improvements :)
It is expected:
- patch "fixes NUMA": for example, it doesn't give improvement on 1
socket
at all (I've tested it using numactl to bind to 1 socket)
- and certainly it gives less improvement on 2 sockets than on 4 sockets
(and 28 cores vs 72 cores also gives difference),
- one of hot points were CLogControlLock, and it were fixed with
"Group mode for CLOG updates" [1]
>
> Some comments:
> ==============
>
> lwlock.c:
> ---------
>
> ...
>
> +static void
> +add_lwlock_stats_spin_stat(LWLock *lock, SpinDelayStatus *delayStatus)
>
> Add a method description.
Neighbor functions above also has no description, that is why I didn't
add.
But ok, I've added now.
>
> +static inline bool
> +LWLockAttemptLockOrQueueSelf(LWLock *lock, LWLockMode mode,
> LWLockMode waitmode)
>
> I'll leave it to the Committer to decide if this method is too big to
> be "inline".
GCC 4.9 doesn't want to inline it without directive, and function call
is then remarkable in profile.
Attach contains version with all suggestions applied except remove of
"inline".
> Open questions:
> ---------------
> * spins_per_delay as extern
> * Calculation of skip_wait_list
Currently calculation of skip_wait_list is mostly empirical (ie best
i measured).
I strongly think that instead of spins_per_delay something dependent
on concrete lock should be used. I tried to store it in a LWLock
itself, but it were worse.
Recently I understand it should be stored in array indexed by tranche,
but I didn't implement it yet, and therefore didn't measure.
[1]: https://commitfest.postgresql.org/14/358/
--
With regards,
Sokolov Yura aka funny_falcon
Postgres Professional: https://postgrespro.ru
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
Hi,
On 09/08/2017 03:35 PM, Sokolov Yura wrote:
>> I'm seeing
>>
>> -M prepared: Up to 11% improvement
>> -M prepared -S: No improvement, no regression ("noise")
>> -M prepared -N: Up to 12% improvement
>>
>> for all runs the improvement shows up the closer you get to the number
>> of CPU threads, or above. Although I'm not seeing the same
>> improvements as you on very large client counts there are definitely
>> improvements :)
>
> It is expected:
> - patch "fixes NUMA": for example, it doesn't give improvement on 1 socket
> at all (I've tested it using numactl to bind to 1 socket)
> - and certainly it gives less improvement on 2 sockets than on 4 sockets
> (and 28 cores vs 72 cores also gives difference),
> - one of hot points were CLogControlLock, and it were fixed with
> "Group mode for CLOG updates" [1]
>
I'm planning to re-test that patch.
>>
>> +static inline bool
>> +LWLockAttemptLockOrQueueSelf(LWLock *lock, LWLockMode mode,
>> LWLockMode waitmode)
>>
>> I'll leave it to the Committer to decide if this method is too big to
>> be "inline".
>
> GCC 4.9 doesn't want to inline it without directive, and function call
> is then remarkable in profile.
>
> Attach contains version with all suggestions applied except remove of
> "inline".
>
Yes, ideally the method will be kept at "inline".
>> Open questions:
>> ---------------
>> * spins_per_delay as extern
>> * Calculation of skip_wait_list
>
> Currently calculation of skip_wait_list is mostly empirical (ie best
> i measured).
>
Ok, good to know.
> I strongly think that instead of spins_per_delay something dependent
> on concrete lock should be used. I tried to store it in a LWLock
> itself, but it were worse.
Yes, LWLock should be kept as small as possible, and cache line aligned
due to the cache storms, as shown by perf c2c.
> Recently I understand it should be stored in array indexed by tranche,
> but I didn't implement it yet, and therefore didn't measure.
>
Different constants for the LWLock could have an impact, but the
constants would also be dependent on machine setup, and work load.
Thanks for working on this !
Best regards, Jesper
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
On 09/11/2017 11:01 AM, Jesper Pedersen wrote: > Thanks for working on this ! > Moved to "Ready for Committer". Best regards, Jesper -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Hi, On 2017-06-05 16:22:58 +0300, Sokolov Yura wrote: > Patch changes the way LWLock is acquired. > > Before patch, lock is acquired using following procedure: > 1. first LWLock->state is checked for ability to take a lock, and CAS > performed (either lock could be acquired or not). And it is retried if > status were changed. > 2. if lock is not acquired at first 1, Proc is put into wait list, using > LW_FLAG_LOCKED bit of LWLock->state as a spin-lock for wait list. > In fact, profile shows that LWLockWaitListLock spends a lot of CPU on > contendend LWLock (upto 20%). > Additional CAS loop is inside pg_atomic_fetch_or_u32 for setting > LW_FLAG_HAS_WAITERS. And releasing wait list lock is another CAS loop > on the same LWLock->state. > 3. after that state is checked again, because lock could be released > before Proc were queued into wait list. > 4. if lock were acquired at step 3, Proc should be dequeued from wait > list (another spin lock and CAS loop). And this operation could be > quite heavy, because whole list should be traversed. > > Patch makes lock acquiring in single CAS loop: > 1. LWLock->state is read, and ability for lock acquiring is detected. > If there is possibility to take a lock, CAS tried. > If CAS were successful, lock is aquired (same to original version). > 2. but if lock is currently held by other backend, we check ability for > taking WaitList lock. If wait list lock is not help by anyone, CAS > perfomed for taking WaitList lock and set LW_FLAG_HAS_WAITERS at once. > If CAS were successful, then LWLock were still held at the moment wait > list lock were held - this proves correctness of new algorithm. And > Proc is queued to wait list then. > 3. Otherwise spin_delay is performed, and loop returns to step 1. Right, something like this didn't use to be possible because we'd both the LWLock->state and LWLock->mutex. But after 008608b9d5106 that's not a concern anymore. > Algorithm for LWLockWaitForVar is also refactored. New version is: > 1. If lock is not held by anyone, it immediately exit. > 2. Otherwise it is checked for ability to take WaitList lock, because > variable is protected with it. If so, CAS is performed, and if it is > successful, loop breaked to step 4. > 3. Otherwise spin_delay perfomed, and loop returns to step 1. > 4. var is checked for change. > If it were changed, we unlock wait list lock and exit. > Note: it could not change in following steps because we are holding > wait list lock. > 5. Otherwise CAS on setting necessary flags is performed. If it succeed, > then queue Proc to wait list and exit. > 6. If Case failed, then there is possibility for LWLock to be already > released - if so then we should unlock wait list and exit. > 7. Otherwise loop returns to step 5. > > So invariant is preserved: > - either we found LWLock free, > - or we found changed variable, > - or we set flags and queue self while LWLock were held. > > Spin_delay is not performed at step 7, because we should release wait > list lock as soon as possible. That seems unconvincing - by not delaying you're more likely to *increase* the time till the current locker that holds the lock can release the lock. > Additionally, taking wait list lock is skipped in both algorithms if > SpinDelayStatus.spins is less than part of spins_per_delay loop > iterations (so, it is initial iterations, and some iterations after > pg_usleep, because SpinDelayStatus.spins is reset after sleep). I quite strongly think it's a good idea to change this at the same time as the other changes you're proposing here. I think it's a worthwhile thing to pursue, but that change also has quit ethe potential for regressing in some cases. - Andres -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Hi,
On 2017-09-08 22:35:39 +0300, Sokolov Yura wrote:
> From 722a8bed17f82738135264212dde7170b8c0f397 Mon Sep 17 00:00:00 2001
> From: Sokolov Yura <funny.falcon@postgrespro.ru>
> Date: Mon, 29 May 2017 09:25:41 +0000
> Subject: [PATCH 1/6] More correct use of spinlock inside LWLockWaitListLock.
>
> SpinDelayStatus should be function global to count iterations correctly,
> and produce more correct delays.
>
> Also if spin didn't spin, do not count it in spins_per_delay correction.
> It wasn't necessary before cause delayStatus were used only in contented
> cases.
I'm not convinced this is benefial. Adds a bit of overhead to the
casewhere LW_FLAG_LOCKED can be set immediately. OTOH, it's not super
likely to make a large difference if the lock has to be taken anyway...
> +
> +/* just shortcut to not declare lwlock_stats variable at the end of function */
> +static void
> +add_lwlock_stats_spin_stat(LWLock *lock, SpinDelayStatus *delayStatus)
> +{
> + lwlock_stats *lwstats;
> +
> + lwstats = get_lwlock_stats_entry(lock);
> + lwstats->spin_delay_count += delayStatus->delays;
> +}
> #endif /* LWLOCK_STATS */
This seems like a pretty independent change.
> /*
> * Internal function that tries to atomically acquire the lwlock in the passed
> - * in mode.
> + * in mode. If it could not grab the lock, it doesn't puts proc into wait
> + * queue.
> *
> - * This function will not block waiting for a lock to become free - that's the
> - * callers job.
> + * It is used only in LWLockConditionalAcquire.
> *
> - * Returns true if the lock isn't free and we need to wait.
> + * Returns true if the lock isn't free.
> */
> static bool
> -LWLockAttemptLock(LWLock *lock, LWLockMode mode)
> +LWLockAttemptLockOnce(LWLock *lock, LWLockMode mode)
This now has become a fairly special cased function, I'm not convinced
it makes much sense with the current naming and functionality.
> +/*
> + * Internal function that tries to atomically acquire the lwlock in the passed
> + * in mode or put it self into waiting queue with waitmode.
> + * This function will not block waiting for a lock to become free - that's the
> + * callers job.
> + *
> + * Returns true if the lock isn't free and we are in a wait queue.
> + */
> +static inline bool
> +LWLockAttemptLockOrQueueSelf(LWLock *lock, LWLockMode mode, LWLockMode waitmode)
> +{
> + uint32 old_state;
> + SpinDelayStatus delayStatus;
> + bool lock_free;
> + uint32 mask,
> + add;
> +
> + AssertArg(mode == LW_EXCLUSIVE || mode == LW_SHARED);
> +
> + if (mode == LW_EXCLUSIVE)
> + {
> + mask = LW_LOCK_MASK;
> + add = LW_VAL_EXCLUSIVE;
> + }
> + else
> + {
> + mask = LW_VAL_EXCLUSIVE;
> + add = LW_VAL_SHARED;
> + }
> +
> + init_local_spin_delay(&delayStatus);
The way you moved this around has the disadvantage that we now do this -
a number of writes - even in the very common case where the lwlock can
be acquired directly.
> + /*
> + * Read once outside the loop. Later iterations will get the newer value
> + * either via compare & exchange or with read after perform_spin_delay.
> + */
> + old_state = pg_atomic_read_u32(&lock->state);
> + /* loop until we've determined whether we could acquire the lock or not */
> + while (true)
> + {
> + uint32 desired_state;
> +
> + desired_state = old_state;
> +
> + lock_free = (old_state & mask) == 0;
> + if (lock_free)
> {
> - if (lock_free)
> + desired_state += add;
> + if (pg_atomic_compare_exchange_u32(&lock->state,
> + &old_state, desired_state))
> {
> /* Great! Got the lock. */
> #ifdef LOCK_DEBUG
> if (mode == LW_EXCLUSIVE)
> lock->owner = MyProc;
> #endif
> - return false;
> + break;
> + }
> + }
> + else if ((old_state & LW_FLAG_LOCKED) == 0)
> + {
> + desired_state |= LW_FLAG_LOCKED | LW_FLAG_HAS_WAITERS;
> + if (pg_atomic_compare_exchange_u32(&lock->state,
> + &old_state, desired_state))
> + {
> + LWLockQueueSelfLocked(lock, waitmode);
> + break;
> }
> - else
> - return true; /* somebody else has the lock */
> + }
> + else
> + {
> + perform_spin_delay(&delayStatus);
> + old_state = pg_atomic_read_u32(&lock->state);
> }
> }
> - pg_unreachable();
> +#ifdef LWLOCK_STATS
> + add_lwlock_stats_spin_stat(lock, &delayStatus);
> +#endif
> +
> + /*
> + * We intentionally do not call finish_spin_delay here, because the loop
> + * above usually finished by queuing into the wait list on contention, and
> + * doesn't reach spins_per_delay thereby doesn't sleep inside of
> + * perform_spin_delay. Also, different LWLocks has very different
> + * contention pattern, and it is wrong to update spin-lock statistic based
> + * on LWLock contention.
> + */
Huh? This seems entirely unconvincing. Without adjusting this here we'll
just spin the same way every iteration. Especially for the case where
somebody else holds LW_FLAG_LOCKED that's quite bad.
> From e5b13550fc48d62b0b855bedd7fcd5848b806b09 Mon Sep 17 00:00:00 2001
> From: Sokolov Yura <funny.falcon@postgrespro.ru>
> Date: Tue, 30 May 2017 18:54:25 +0300
> Subject: [PATCH 5/6] Fix implementation description in a lwlock.c .
>
> ---
> src/backend/storage/lmgr/lwlock.c | 17 ++++++++---------
> 1 file changed, 8 insertions(+), 9 deletions(-)
>
> diff --git a/src/backend/storage/lmgr/lwlock.c b/src/backend/storage/lmgr/lwlock.c
> index 334c2a2d96..0a41c2c4e2 100644
> --- a/src/backend/storage/lmgr/lwlock.c
> +++ b/src/backend/storage/lmgr/lwlock.c
> @@ -62,16 +62,15 @@
> * notice that we have to wait. Unfortunately by the time we have finished
> * queuing, the former locker very well might have already finished it's
> * work. That's problematic because we're now stuck waiting inside the OS.
> -
> - * To mitigate those races we use a two phased attempt at locking:
> - * Phase 1: Try to do it atomically, if we succeed, nice
> - * Phase 2: Add ourselves to the waitqueue of the lock
> - * Phase 3: Try to grab the lock again, if we succeed, remove ourselves from
> - * the queue
> - * Phase 4: Sleep till wake-up, goto Phase 1
> *
> - * This protects us against the problem from above as nobody can release too
> - * quick, before we're queued, since after Phase 2 we're already queued.
> + * This race is avoided by taking a lock for the wait list using CAS with the old
> + * state value, so it would only succeed if lock is still held. Necessary flag
> + * is set using the same CAS.
> + *
> + * Inside LWLockConflictsWithVar the wait list lock is reused to protect the variable
> + * value. First the lock is acquired to check the variable value, then flags are
> + * set with a second CAS before queuing to the wait list in order to ensure that the lock was not
> + * released yet.
> * -------------------------------------------------------------------------
> */
I think this needs more extensive surgery.
> From cc74a849a64e331930a2285e15445d7f08b54169 Mon Sep 17 00:00:00 2001
> From: Sokolov Yura <funny.falcon@postgrespro.ru>
> Date: Fri, 2 Jun 2017 11:34:23 +0000
> Subject: [PATCH 6/6] Make SpinDelayStatus a bit lighter.
>
> It saves couple of instruction of fast path of spin-loop, and so makes
> fast path of LWLock a bit faster (and in other places where spinlock is
> used).
> Also it makes call to perform_spin_delay a bit slower, that could
> positively affect on spin behavior, especially if no `pause` instruction
> present.
Whaa? That seems pretty absurd reasoning.
One big advantage of this is that we should be able to make LW_SHARED
acquisition an xadd. I'd done that previously, when the separate
spinlock still existed, and it was quite beneficial for performance on
larger systems. But it was some fiddly code - should be easier now.
Requires some careful management when noticing that an xadd acquired a
shared lock even though there's a conflicting exclusive lock, but
increase the fastpath.
Greetings,
Andres Freund
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
Hi,
On 2017-10-19 03:03, Andres Freund wrote:
> Hi,
>
> On 2017-09-08 22:35:39 +0300, Sokolov Yura wrote:
>> /*
>> * Internal function that tries to atomically acquire the lwlock in
>> the passed
>> - * in mode.
>> + * in mode. If it could not grab the lock, it doesn't puts proc into
>> wait
>> + * queue.
>> *
>> - * This function will not block waiting for a lock to become free -
>> that's the
>> - * callers job.
>> + * It is used only in LWLockConditionalAcquire.
>> *
>> - * Returns true if the lock isn't free and we need to wait.
>> + * Returns true if the lock isn't free.
>> */
>> static bool
>> -LWLockAttemptLock(LWLock *lock, LWLockMode mode)
>> +LWLockAttemptLockOnce(LWLock *lock, LWLockMode mode)
>
> This now has become a fairly special cased function, I'm not convinced
> it makes much sense with the current naming and functionality.
It just had not to be as complex as LWLockAttpemptLockOrQueueSelf.
Their functionality is too different.
>> +/*
>> + * Internal function that tries to atomically acquire the lwlock in
>> the passed
>> + * in mode or put it self into waiting queue with waitmode.
>> + * This function will not block waiting for a lock to become free -
>> that's the
>> + * callers job.
>> + *
>> + * Returns true if the lock isn't free and we are in a wait queue.
>> + */
>> +static inline bool
>> +LWLockAttemptLockOrQueueSelf(LWLock *lock, LWLockMode mode,
>> LWLockMode waitmode)
>> +{
>> + uint32 old_state;
>> + SpinDelayStatus delayStatus;
>> + bool lock_free;
>> + uint32 mask,
>> + add;
>> +
>> + AssertArg(mode == LW_EXCLUSIVE || mode == LW_SHARED);
>> +
>> + if (mode == LW_EXCLUSIVE)
>> + {
>> + mask = LW_LOCK_MASK;
>> + add = LW_VAL_EXCLUSIVE;
>> + }
>> + else
>> + {
>> + mask = LW_VAL_EXCLUSIVE;
>> + add = LW_VAL_SHARED;
>> + }
>> +
>> + init_local_spin_delay(&delayStatus);
>
> The way you moved this around has the disadvantage that we now do this
> -
> a number of writes - even in the very common case where the lwlock can
> be acquired directly.
Excuse me, I don't understand fine.
Do you complain against init_local_spin_delay placed here?
Placing it in other place will complicate code.
Or you complain against setting `mask` and `add`?
At least it simplifies loop body. For example, it is simpler to write
specialized Power assembly using already filled `mask+add` registers
(i have a working draft with power assembly).
In both cases, I think simpler version should be accepted first. It acts
as algorithm definition. And it already gives measurable improvement.
After some testing, attempt to improve it may be performed (assuming
release will be in a next autumn, there is enough time for testing and
improvements)
I can be mistaken.
>> + /*
>> + * We intentionally do not call finish_spin_delay here, because the
>> loop
>> + * above usually finished by queuing into the wait list on
>> contention, and
>> + * doesn't reach spins_per_delay thereby doesn't sleep inside of
>> + * perform_spin_delay. Also, different LWLocks has very different
>> + * contention pattern, and it is wrong to update spin-lock statistic
>> based
>> + * on LWLock contention.
>> + */
>
> Huh? This seems entirely unconvincing. Without adjusting this here
> we'll
> just spin the same way every iteration. Especially for the case where
> somebody else holds LW_FLAG_LOCKED that's quite bad.
LWLock's are very different. Some of them are always short-term
(BufferLock), others are always locked for a long time. Some sparse, and
some crowded. It is quite bad to tune single variable `spins_per_delay`
by such different load.
And it is already tuned by spin-locks. And spin-locks tune it quite
well.
I've tried to place this delay into lock itself (it has 2 free bytes),
but this attempt performed worse.
Now I understand, that delays should be stored in array indexed by
tranche. But I have no time to test this idea. And I doubt it will give
cardinally better results (ie > 5%), so I think it is better to accept
patch in this way, and then experiment with per-tranche delay.
>
>> From e5b13550fc48d62b0b855bedd7fcd5848b806b09 Mon Sep 17 00:00:00 2001
>> From: Sokolov Yura <funny.falcon@postgrespro.ru>
>> Date: Tue, 30 May 2017 18:54:25 +0300
>> Subject: [PATCH 5/6] Fix implementation description in a lwlock.c .
>>
>> ---
>> src/backend/storage/lmgr/lwlock.c | 17 ++++++++---------
>> 1 file changed, 8 insertions(+), 9 deletions(-)
>>
>> diff --git a/src/backend/storage/lmgr/lwlock.c
>> b/src/backend/storage/lmgr/lwlock.c
>> index 334c2a2d96..0a41c2c4e2 100644
>> --- a/src/backend/storage/lmgr/lwlock.c
>> +++ b/src/backend/storage/lmgr/lwlock.c
>> @@ -62,16 +62,15 @@
>> * notice that we have to wait. Unfortunately by the time we have
>> finished
>> * queuing, the former locker very well might have already finished
>> it's
>> * work. That's problematic because we're now stuck waiting inside
>> the OS.
>> -
>> - * To mitigate those races we use a two phased attempt at locking:
>> - * Phase 1: Try to do it atomically, if we succeed, nice
>> - * Phase 2: Add ourselves to the waitqueue of the lock
>> - * Phase 3: Try to grab the lock again, if we succeed, remove
>> ourselves from
>> - * the queue
>> - * Phase 4: Sleep till wake-up, goto Phase 1
>> *
>> - * This protects us against the problem from above as nobody can
>> release too
>> - * quick, before we're queued, since after Phase 2 we're already
>> queued.
>> + * This race is avoided by taking a lock for the wait list using CAS
>> with the old
>> + * state value, so it would only succeed if lock is still held.
>> Necessary flag
>> + * is set using the same CAS.
>> + *
>> + * Inside LWLockConflictsWithVar the wait list lock is reused to
>> protect the variable
>> + * value. First the lock is acquired to check the variable value,
>> then flags are
>> + * set with a second CAS before queuing to the wait list in order to
>> ensure that the lock was not
>> + * released yet.
>> *
>> -------------------------------------------------------------------------
>> */
>
> I think this needs more extensive surgery.
Again I don't understand what you mean. Looks like my English is not
very fluent :-(
Do you mean, there should be more thorough description?
Is description from letter is good enough to be copied into this
comment?
>> From cc74a849a64e331930a2285e15445d7f08b54169 Mon Sep 17 00:00:00 2001
>> From: Sokolov Yura <funny.falcon@postgrespro.ru>
>> Date: Fri, 2 Jun 2017 11:34:23 +0000
>> Subject: [PATCH 6/6] Make SpinDelayStatus a bit lighter.
>>
>> It saves couple of instruction of fast path of spin-loop, and so makes
>> fast path of LWLock a bit faster (and in other places where spinlock
>> is
>> used).
>
>> Also it makes call to perform_spin_delay a bit slower, that could
>> positively affect on spin behavior, especially if no `pause`
>> instruction
>> present.
>
> Whaa? That seems pretty absurd reasoning.
:-) AMD Opteron doesn't respect "pause" instruction at all (as it is
written in s_lock.h , and several times mentioned in Internet).
Given whole reason of `perfrom_spin_delay` is to spent time somewhere,
making it a tiny-bit slower may only improve things :-)
On 2017-10-19 02:28, Andres Freund wrote:
> On 2017-06-05 16:22:58 +0300, Sokolov Yura wrote:
>> Algorithm for LWLockWaitForVar is also refactored. New version is:
>> 1. If lock is not held by anyone, it immediately exit.
>> 2. Otherwise it is checked for ability to take WaitList lock, because
>> variable is protected with it. If so, CAS is performed, and if it is
>> successful, loop breaked to step 4.
>> 3. Otherwise spin_delay perfomed, and loop returns to step 1.
>> 4. var is checked for change.
>> If it were changed, we unlock wait list lock and exit.
>> Note: it could not change in following steps because we are holding
>> wait list lock.
>> 5. Otherwise CAS on setting necessary flags is performed. If it
>> succeed,
>> then queue Proc to wait list and exit.
>> 6. If CAS failed, then there is possibility for LWLock to be already
>> released - if so then we should unlock wait list and exit.
>> 7. Otherwise loop returns to step 5.
>>
>> So invariant is preserved:
>> - either we found LWLock free,
>> - or we found changed variable,
>> - or we set flags and queue self while LWLock were held.
>>
>> Spin_delay is not performed at step 7, because we should release wait
>> list lock as soon as possible.
>
> That seems unconvincing - by not delaying you're more likely to
> *increase* the time till the current locker that holds the lock can
> release the lock.
But why? If our CAS wasn't satisfied, then other's one were satisfied.
So there is always overall progress. And if it will sleep in this
loop, then other waiters will spin in first loop in this functions.
But given concrete usage of LWLockWaitForVar, probably it is not too
bad to hold other waiters in first loop in this function (they loops
until we release WaitListLock or lock released at whole).
I'm in doubts what is better. May I keep it unchanged now?
BTW, I found a small mistake in this place: I forgot to set
LW_FLAG_LOCKED in a state before this CAS. Looks like it wasn't real
error, because CAS always failed at first loop iteration (because real
`lock->state` had LW_FLAG_LOCKED already set), and after failed CAS
state adsorbs value from `lock->state`.
I'll fix it.
> One big advantage of this is that we should be able to make LW_SHARED
> acquisition an xadd. I'd done that previously, when the separate
> spinlock still existed, and it was quite beneficial for performance on
> larger systems. But it was some fiddly code - should be easier now.
> Requires some careful management when noticing that an xadd acquired a
> shared lock even though there's a conflicting exclusive lock, but
> increase the fastpath.
--
Sokolov Yura aka funny_falcon
Postgres Professional: https://postgrespro.ru
The Russian Postgres Company
--
Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgsql-hackers
> On 2017-10-19 02:28, Andres Freund wrote: >> On 2017-06-05 16:22:58 +0300, Sokolov Yura wrote: >>> Algorithm for LWLockWaitForVar is also refactored. New version is: >>> 1. If lock is not held by anyone, it immediately exit. >>> 2. Otherwise it is checked for ability to take WaitList lock, because >>> variable is protected with it. If so, CAS is performed, and if it >>> is >>> successful, loop breaked to step 4. >>> 3. Otherwise spin_delay perfomed, and loop returns to step 1. >>> 4. var is checked for change. >>> If it were changed, we unlock wait list lock and exit. >>> Note: it could not change in following steps because we are holding >>> wait list lock. >>> 5. Otherwise CAS on setting necessary flags is performed. If it >>> succeed, >>> then queue Proc to wait list and exit. >>> 6. If CAS failed, then there is possibility for LWLock to be already >>> released - if so then we should unlock wait list and exit. >>> 7. Otherwise loop returns to step 5. >>> >>> So invariant is preserved: >>> - either we found LWLock free, >>> - or we found changed variable, >>> - or we set flags and queue self while LWLock were held. >>> >>> Spin_delay is not performed at step 7, because we should release wait >>> list lock as soon as possible. >> >> That seems unconvincing - by not delaying you're more likely to >> *increase* the time till the current locker that holds the lock can >> release the lock. > > But why? If our CAS wasn't satisfied, then other's one were satisfied. > So there is always overall progress. And if it will sleep in this > loop, then other waiters will spin in first loop in this functions. > But given concrete usage of LWLockWaitForVar, probably it is not too > bad to hold other waiters in first loop in this function (they loops > until we release WaitListLock or lock released at whole). > > I'm in doubts what is better. May I keep it unchanged now? In fact, if waiter will sleep here, lock holder will not be able to set variable we are waiting for, and therefore will not release lock. It is stated in the comment for the loop: + * Note: value could not change again cause we are holding WaitList lock. So delaying here we certainly will degrade. > > BTW, I found a small mistake in this place: I forgot to set > LW_FLAG_LOCKED in a state before this CAS. Looks like it wasn't real > error, because CAS always failed at first loop iteration (because real > `lock->state` had LW_FLAG_LOCKED already set), and after failed CAS > state adsorbs value from `lock->state`. > I'll fix it. Attach contains version with a fix. -- Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Attachment
On 2017-10-19 14:36:56 +0300, Sokolov Yura wrote: > > > + init_local_spin_delay(&delayStatus); > > > > The way you moved this around has the disadvantage that we now do this - > > a number of writes - even in the very common case where the lwlock can > > be acquired directly. > > Excuse me, I don't understand fine. > Do you complain against init_local_spin_delay placed here? Yes. > Placing it in other place will complicate code. > Or you complain against setting `mask` and `add`? That seems right. > In both cases, I think simpler version should be accepted first. It acts > as algorithm definition. And it already gives measurable improvement. Well, in scalability. I'm less sure about uncontended performance. > > > + * We intentionally do not call finish_spin_delay here, because > > > the loop > > > + * above usually finished by queuing into the wait list on > > > contention, and > > > + * doesn't reach spins_per_delay thereby doesn't sleep inside of > > > + * perform_spin_delay. Also, different LWLocks has very different > > > + * contention pattern, and it is wrong to update spin-lock > > > statistic based > > > + * on LWLock contention. > > > + */ > > > > Huh? This seems entirely unconvincing. Without adjusting this here we'll > > just spin the same way every iteration. Especially for the case where > > somebody else holds LW_FLAG_LOCKED that's quite bad. > > LWLock's are very different. Some of them are always short-term > (BufferLock), others are always locked for a long time. That seems not particularly relevant. The same is true for spinlocks. The relevant question isn't how long the lwlock is held, it's how long LW_FLAG_LOCKED is held - and that should only depend on contention (i.e. bus speed, amount of times put into sleep while holding lock, etc), not on how long the lock is held. > I've tried to place this delay into lock itself (it has 2 free bytes), > but this attempt performed worse. That seems unsurprising - there's a *lot* of locks, and we'd have to tune all of them. Additionally there's a bunch of platforms where we do *not* have free bytes (consider the embedding in BufferTag). > Now I understand, that delays should be stored in array indexed by > tranche. But I have no time to test this idea. And I doubt it will give > cardinally better results (ie > 5%), so I think it is better to accept > patch in this way, and then experiment with per-tranche delay. I don't think tranches have any decent predictive power here. Greetings, Andres Freund -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
Hello, On 2017-10-19 19:46, Andres Freund wrote: > On 2017-10-19 14:36:56 +0300, Sokolov Yura wrote: >> > > + init_local_spin_delay(&delayStatus); >> > >> > The way you moved this around has the disadvantage that we now do this - >> > a number of writes - even in the very common case where the lwlock can >> > be acquired directly. >> >> Excuse me, I don't understand fine. >> Do you complain against init_local_spin_delay placed here? > > Yes. I could place it before perform_spin_delay under `if (!spin_inited)` if you think it is absolutely must. > > >> Placing it in other place will complicate code. > > >> Or you complain against setting `mask` and `add`? > > That seems right. > > >> In both cases, I think simpler version should be accepted first. It >> acts >> as algorithm definition. And it already gives measurable improvement. > > Well, in scalability. I'm less sure about uncontended performance. > > > >> > > + * We intentionally do not call finish_spin_delay here, because >> > > the loop >> > > + * above usually finished by queuing into the wait list on >> > > contention, and >> > > + * doesn't reach spins_per_delay thereby doesn't sleep inside of >> > > + * perform_spin_delay. Also, different LWLocks has very different >> > > + * contention pattern, and it is wrong to update spin-lock >> > > statistic based >> > > + * on LWLock contention. >> > > + */ >> > >> > Huh? This seems entirely unconvincing. Without adjusting this here we'll >> > just spin the same way every iteration. Especially for the case where >> > somebody else holds LW_FLAG_LOCKED that's quite bad. >> >> LWLock's are very different. Some of them are always short-term >> (BufferLock), others are always locked for a long time. > > That seems not particularly relevant. The same is true for > spinlocks. The relevant question isn't how long the lwlock is held, > it's > how long LW_FLAG_LOCKED is held - and that should only depend on > contention (i.e. bus speed, amount of times put into sleep while > holding > lock, etc), not on how long the lock is held. > >> I've tried to place this delay into lock itself (it has 2 free bytes), >> but this attempt performed worse. > > That seems unsurprising - there's a *lot* of locks, and we'd have to > tune all of them. Additionally there's a bunch of platforms where we do > *not* have free bytes (consider the embedding in BufferTag). > > >> Now I understand, that delays should be stored in array indexed by >> tranche. But I have no time to test this idea. And I doubt it will >> give >> cardinally better results (ie > 5%), so I think it is better to accept >> patch in this way, and then experiment with per-tranche delay. > > I don't think tranches have any decent predictive power here. Look after "Make acquiring LWLock to look more like spinlock". First `skip_wait_list` iterations there is no attempt to queue self into wait list. It gives most of improvement. (without it there is just no degradation on high number of clients, but a little decline on low clients, because current algorithm is also a little `spinny` (because it attempts to acquire lock again after queueing into wait list)). `skip_wait_list` depends on tranche very much. And per-tranche `skip_wait_list` should be calculated based on ability to acquire lock without any sleep, ie without both queuing itself into wait list and falling into `pg_usleep` inside `perform_spin_delay` . I suppose, it is obvious that `spins_per_delay` have to be proportional to `skip_wait_list` (it should be at least greater than `skip_wait_list`). Therefore `spins_per_delay` is also should be runtime-dependent on lock's tranche. Am I wrong? Without that per-tranche auto-tuning, it is better to not touch `spins_per_delay` inside of `LWLockAttemptLockOrQueue`, I think. With regards, -- Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
On 2017-10-20 11:54, Sokolov Yura wrote: > Hello, > > On 2017-10-19 19:46, Andres Freund wrote: >> On 2017-10-19 14:36:56 +0300, Sokolov Yura wrote: >>> > > + init_local_spin_delay(&delayStatus); >>> > >>> > The way you moved this around has the disadvantage that we now do this - >>> > a number of writes - even in the very common case where the lwlock can >>> > be acquired directly. >>> >>> Excuse me, I don't understand fine. >>> Do you complain against init_local_spin_delay placed here? >> >> Yes. > > I could place it before perform_spin_delay under `if (!spin_inited)` if > you > think it is absolutely must. I looked at assembly, and remembered, that last commit simplifies `init_local_spin_delay` to just two-three writes of zeroes (looks like compiler combines 2*4byte write into 1*8 write). Compared to code around (especially in LWLockAcquire itself), this overhead is negligible. Though, I found that there is benefit in calling LWLockAttemptLockOnce before entering loop with calls to LWLockAttemptLockOrQueue in the LWLockAcquire (in there is not much contention). And this way, `inline` decorator for LWLockAttemptLockOrQueue could be omitted. Given, clang doesn't want to inline this function, it could be the best way. Should I add such commit to patch? -- With regards, Sokolov Yura aka funny_falcon Postgres Professional: https://postgrespro.ru The Russian Postgres Company -- Sent via pgsql-hackers mailing list (pgsql-hackers@postgresql.org) To make changes to your subscription: http://www.postgresql.org/mailpref/pgsql-hackers
2017-11-06 18:07 GMT+03:00 Sokolov Yura <funny.falcon@postgrespro.ru>:
>
> On 2017-10-20 11:54, Sokolov Yura wrote:
>>
>> Hello,
>>
>> On 2017-10-19 19:46, Andres Freund wrote:
>>>
>>> On 2017-10-19 14:36:56 +0300, Sokolov Yura wrote:
>>>>
>>>> > > + init_local_spin_delay(&delayStatus);
>>>> >
>>>> > The way you moved this around has the disadvantage that we now do this -
>>>> > a number of writes - even in the very common case where the lwlock can
>>>> > be acquired directly.
>>>>
>>>> Excuse me, I don't understand fine.
>>>> Do you complain against init_local_spin_delay placed here?
>>>
>>>
>>> Yes.
>>
>>
>> I could place it before perform_spin_delay under `if (!spin_inited)` if you
>> think it is absolutely must.
>
>
> I looked at assembly, and remembered, that last commit simplifies
> `init_local_spin_delay` to just two-three writes of zeroes (looks
> like compiler combines 2*4byte write into 1*8 write). Compared to
> code around (especially in LWLockAcquire itself), this overhead
> is negligible.
>
> Though, I found that there is benefit in calling LWLockAttemptLockOnce
> before entering loop with calls to LWLockAttemptLockOrQueue in the
> LWLockAcquire (in there is not much contention). And this way, `inline`
> decorator for LWLockAttemptLockOrQueue could be omitted. Given, clang
> doesn't want to inline this function, it could be the best way.
>
> On 2017-10-20 11:54, Sokolov Yura wrote:
>>
>> Hello,
>>
>> On 2017-10-19 19:46, Andres Freund wrote:
>>>
>>> On 2017-10-19 14:36:56 +0300, Sokolov Yura wrote:
>>>>
>>>> > > + init_local_spin_delay(&delayStatus);
>>>> >
>>>> > The way you moved this around has the disadvantage that we now do this -
>>>> > a number of writes - even in the very common case where the lwlock can
>>>> > be acquired directly.
>>>>
>>>> Excuse me, I don't understand fine.
>>>> Do you complain against init_local_spin_delay placed here?
>>>
>>>
>>> Yes.
>>
>>
>> I could place it before perform_spin_delay under `if (!spin_inited)` if you
>> think it is absolutely must.
>
>
> I looked at assembly, and remembered, that last commit simplifies
> `init_local_spin_delay` to just two-three writes of zeroes (looks
> like compiler combines 2*4byte write into 1*8 write). Compared to
> code around (especially in LWLockAcquire itself), this overhead
> is negligible.
>
> Though, I found that there is benefit in calling LWLockAttemptLockOnce
> before entering loop with calls to LWLockAttemptLockOrQueue in the
> LWLockAcquire (in there is not much contention). And this way, `inline`
> decorator for LWLockAttemptLockOrQueue could be omitted. Given, clang
> doesn't want to inline this function, it could be the best way.
In attach version with LWLockAcquireOnce called before entering loop
in LWLockAcquire.
With regards,
Sokolov Yura
Attachment
2017-11-26 19:51 GMT+03:00 Юрий Соколов <funny.falcon@gmail.com>:
>
> 2017-11-06 18:07 GMT+03:00 Sokolov Yura <funny.falcon@postgrespro.ru>:
> >
> > On 2017-10-20 11:54, Sokolov Yura wrote:
> >>
> >> Hello,
> >>
> >> On 2017-10-19 19:46, Andres Freund wrote:
> >>>
> >>> On 2017-10-19 14:36:56 +0300, Sokolov Yura wrote:
> >>>>
> >>>> > > + init_local_spin_delay(&delayStatus);
> >>>> >
> >>>> > The way you moved this around has the disadvantage that we now do this -
> >>>> > a number of writes - even in the very common case where the lwlock can
> >>>> > be acquired directly.
> >>>>
> >>>> Excuse me, I don't understand fine.
> >>>> Do you complain against init_local_spin_delay placed here?
> >>>
> >>>
> >>> Yes.
> >>
> >>
> >> I could place it before perform_spin_delay under `if (!spin_inited)` if you
> >> think it is absolutely must.
> >
> >
> > I looked at assembly, and remembered, that last commit simplifies
> > `init_local_spin_delay` to just two-three writes of zeroes (looks
> > like compiler combines 2*4byte write into 1*8 write). Compared to
> > code around (especially in LWLockAcquire itself), this overhead
> > is negligible.
> >
> > Though, I found that there is benefit in calling LWLockAttemptLockOnce
> > before entering loop with calls to LWLockAttemptLockOrQueue in the
> > LWLockAcquire (in there is not much contention). And this way, `inline`
> > decorator for LWLockAttemptLockOrQueue could be omitted. Given, clang
> > doesn't want to inline this function, it could be the best way.
>
> In attach version with LWLockAcquireOnce called before entering loop
> in LWLockAcquire.
>
Oh... there were stupid error in previos file.>
> 2017-11-06 18:07 GMT+03:00 Sokolov Yura <funny.falcon@postgrespro.ru>:
> >
> > On 2017-10-20 11:54, Sokolov Yura wrote:
> >>
> >> Hello,
> >>
> >> On 2017-10-19 19:46, Andres Freund wrote:
> >>>
> >>> On 2017-10-19 14:36:56 +0300, Sokolov Yura wrote:
> >>>>
> >>>> > > + init_local_spin_delay(&delayStatus);
> >>>> >
> >>>> > The way you moved this around has the disadvantage that we now do this -
> >>>> > a number of writes - even in the very common case where the lwlock can
> >>>> > be acquired directly.
> >>>>
> >>>> Excuse me, I don't understand fine.
> >>>> Do you complain against init_local_spin_delay placed here?
> >>>
> >>>
> >>> Yes.
> >>
> >>
> >> I could place it before perform_spin_delay under `if (!spin_inited)` if you
> >> think it is absolutely must.
> >
> >
> > I looked at assembly, and remembered, that last commit simplifies
> > `init_local_spin_delay` to just two-three writes of zeroes (looks
> > like compiler combines 2*4byte write into 1*8 write). Compared to
> > code around (especially in LWLockAcquire itself), this overhead
> > is negligible.
> >
> > Though, I found that there is benefit in calling LWLockAttemptLockOnce
> > before entering loop with calls to LWLockAttemptLockOrQueue in the
> > LWLockAcquire (in there is not much contention). And this way, `inline`
> > decorator for LWLockAttemptLockOrQueue could be omitted. Given, clang
> > doesn't want to inline this function, it could be the best way.
>
> In attach version with LWLockAcquireOnce called before entering loop
> in LWLockAcquire.
>
Attachment
Hi Yura, On 11/27/2017 07:41 AM, Юрий Соколов wrote: >>> I looked at assembly, and remembered, that last commit simplifies >>> `init_local_spin_delay` to just two-three writes of zeroes (looks >>> like compiler combines 2*4byte write into 1*8 write). Compared to >>> code around (especially in LWLockAcquire itself), this overhead >>> is negligible. >>> >>> Though, I found that there is benefit in calling LWLockAttemptLockOnce >>> before entering loop with calls to LWLockAttemptLockOrQueue in the >>> LWLockAcquire (in there is not much contention). And this way, `inline` >>> decorator for LWLockAttemptLockOrQueue could be omitted. Given, clang >>> doesn't want to inline this function, it could be the best way. >> >> In attach version with LWLockAcquireOnce called before entering loop >> in LWLockAcquire. >> > > Oh... there were stupid error in previos file. > Attached fixed version. > I can reconfirm my performance findings with this patch; system same as up-thread. Thanks ! Best regards, Jesper
Hi, On 11/27/2017 07:41 AM, Юрий Соколов wrote: >>> I looked at assembly, and remembered, that last commit simplifies >>> `init_local_spin_delay` to just two-three writes of zeroes (looks >>> like compiler combines 2*4byte write into 1*8 write). Compared to >>> code around (especially in LWLockAcquire itself), this overhead >>> is negligible. >>> >>> Though, I found that there is benefit in calling LWLockAttemptLockOnce >>> before entering loop with calls to LWLockAttemptLockOrQueue in the >>> LWLockAcquire (in there is not much contention). And this way, `inline` >>> decorator for LWLockAttemptLockOrQueue could be omitted. Given, clang >>> doesn't want to inline this function, it could be the best way. >> >> In attach version with LWLockAcquireOnce called before entering loop >> in LWLockAcquire. >> > > Oh... there were stupid error in previos file. > Attached fixed version. > As the patch still applies, make check-world passes and I believe that Yura has provided feedback for Andres' comments I'll leave this entry in "Ready for Committer". Best regards, Jesper
Hi, On 01/02/2018 11:09 AM, Jesper Pedersen wrote: >> Oh... there were stupid error in previos file. >> Attached fixed version. >> > > As the patch still applies, make check-world passes and I believe that > Yura has provided feedback for Andres' comments I'll leave this entry in > "Ready for Committer". > The patch from November 27, 2017 still applies (with hunks), passes "make check-world" and shows performance improvements. Keeping it in "Ready for Committer". Best regards, Jesper
Hi, On 03/01/2018 10:50 AM, Jesper Pedersen wrote: >> As the patch still applies, make check-world passes and I believe that >> Yura has provided feedback for Andres' comments I'll leave this entry >> in "Ready for Committer". >> > > The patch from November 27, 2017 still applies (with hunks), passes > "make check-world" and shows performance improvements. > > Keeping it in "Ready for Committer". > The patch from November 27, 2017 still applies (with hunks), https://commitfest.postgresql.org/18/1166/ passes "make check-world" and shows performance improvements. Keeping it in "Ready for Committer". Best regards, Jesper
> On Mon, 2 Jul 2018 at 15:54, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > > The patch from November 27, 2017 still applies (with hunks), > > https://commitfest.postgresql.org/18/1166/ > > passes "make check-world" and shows performance improvements. > > Keeping it in "Ready for Committer". Looks like for some reason this patch is failing to attract committers, any idea why? One of the plausible explanations for me is that the patch requires some more intensive benchmarking of different workloads and types of lock contention to make everyone more confident about it. But then it's not exactly clear for me, what it has to do with NUMA? Non uniform memory access effects were not mentioned here even once, and we're not talking about e.g. migrating the memory between nodes - does it mean that NUMA here is a replacement for a multi-core system? Thinking in this direction I've performed few tests of this patch (using so far only one type of zipfian'ish workload) on my modest few cores laptop, wondering if I can see any difference at all. To my surprise, while on "bare" hardware I've indeed got some visible performance improvement, when I tried to run the same tests on a postgres inside a virtual machine under qemu-kvm, some of them were few percents slower in comparison with the master (depending on the number of virtual cpus). Probably it's related to the situation, when locks can behave differently with preemtable vcpus - I'll try to perform few more rounds of testing to make clear if it's something significant or not. Als I wonder if it makes sense to take a look at the [1], where the similar topic is discussed. [1]: https://www.postgresql.org/message-id/flat/CAPpHfdsZPS%3Db85cxcqO7YjoH3vtPBKYhVRLkZ_WMVbfZB-3bHA%40mail.gmail.com#a5e6d14c098e95e6a36ebd392f280c7a
On 2018-11-10 20:18:33 +0100, Dmitry Dolgov wrote: > > On Mon, 2 Jul 2018 at 15:54, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > > > > The patch from November 27, 2017 still applies (with hunks), > > > > https://commitfest.postgresql.org/18/1166/ > > > > passes "make check-world" and shows performance improvements. > > > > Keeping it in "Ready for Committer". > > Looks like for some reason this patch is failing to attract committers, any > idea why? One of the plausible explanations for me is that the patch requires > some more intensive benchmarking of different workloads and types of lock > contention to make everyone more confident about it. Personally it's twofold: 1) It changes a lot of things, more than I think are strictly necessary to achieve the goal. 2) While clearly the retry logic is not necessary anymore (it was introduced when wait-queue was protected by a separate spinlock, which could not atomically manipulated together with the lock's state), there's reasons why it would be advantageous to keep: My original patch for changing lwlocks to atomics, used lock xadd / fetch_add to acquire shared locks (just incrementing the #shared bits after an unlocked check) - obviously that can cause superfluous failures for concurrent lock releases. Having the retry logic around can make that safe. Using lock xadd to acquire shared locks turns out to be considerably more efficient - most locks where the lock state is contended (rather than just having processes wait), tend to have a very large fraction of shared lockers. And being able to do such a lock acquisition on a conteded cacheline with just a single locked operation, commonly without retries, is quite beneficial. Greetings, Andres Freund
> On Sat, Nov 10, 2018 at 8:37 PM Andres Freund <andres@anarazel.de> wrote: > > On 2018-11-10 20:18:33 +0100, Dmitry Dolgov wrote: > > > On Mon, 2 Jul 2018 at 15:54, Jesper Pedersen <jesper.pedersen@redhat.com> wrote: > > > > > > The patch from November 27, 2017 still applies (with hunks), > > > > > > https://commitfest.postgresql.org/18/1166/ > > > > > > passes "make check-world" and shows performance improvements. > > > > > > Keeping it in "Ready for Committer". > > > > Looks like for some reason this patch is failing to attract committers, any > > idea why? One of the plausible explanations for me is that the patch requires > > some more intensive benchmarking of different workloads and types of lock > > contention to make everyone more confident about it. > > Personally it's twofold: > > 1) It changes a lot of things, more than I think are strictly > necessary to achieve the goal. > > 2) While clearly the retry logic is not necessary anymore (it was > introduced when wait-queue was protected by a separate spinlock, which > could not atomically manipulated together with the lock's state), > there's reasons why it would be advantageous to keep: My original > patch for changing lwlocks to atomics, used lock xadd / fetch_add > to acquire shared locks (just incrementing the #shared bits after an > unlocked check) - obviously that can cause superfluous failures for > concurrent lock releases. Having the retry logic around can make > that safe. > > Using lock xadd to acquire shared locks turns out to be considerably > more efficient - most locks where the lock state is contended (rather > than just having processes wait), tend to have a very large fraction > of shared lockers. And being able to do such a lock acquisition on a > conteded cacheline with just a single locked operation, commonly > without retries, is quite beneficial. Due to lack of response and taking into account this commentary, I'm marking this patch as "Returned with feedback", but hopefully I can pick it up later to improve.
пт, 30 нояб. 2018 г., 19:21 Dmitry Dolgov 9erthalion6@gmail.com:
> On Sat, Nov 10, 2018 at 8:37 PM Andres Freund <andres@anarazel.de> wrote:
>
> On 2018-11-10 20:18:33 +0100, Dmitry Dolgov wrote:
> > > On Mon, 2 Jul 2018 at 15:54, Jesper Pedersen <jesper.pedersen@redhat.com> wrote:
> > >
> > > The patch from November 27, 2017 still applies (with hunks),
> > >
> > > https://commitfest.postgresql.org/18/1166/
> > >
> > > passes "make check-world" and shows performance improvements.
> > >
> > > Keeping it in "Ready for Committer".
> >
> > Looks like for some reason this patch is failing to attract committers, any
> > idea why? One of the plausible explanations for me is that the patch requires
> > some more intensive benchmarking of different workloads and types of lock
> > contention to make everyone more confident about it.
>
> Personally it's twofold:
>
> 1) It changes a lot of things, more than I think are strictly
> necessary to achieve the goal.
>
> 2) While clearly the retry logic is not necessary anymore (it was
> introduced when wait-queue was protected by a separate spinlock, which
> could not atomically manipulated together with the lock's state),
> there's reasons why it would be advantageous to keep: My original
> patch for changing lwlocks to atomics, used lock xadd / fetch_add
> to acquire shared locks (just incrementing the #shared bits after an
> unlocked check) - obviously that can cause superfluous failures for
> concurrent lock releases. Having the retry logic around can make
> that safe.
>
> Using lock xadd to acquire shared locks turns out to be considerably
> more efficient - most locks where the lock state is contended (rather
> than just having processes wait), tend to have a very large fraction
> of shared lockers. And being able to do such a lock acquisition on a
> conteded cacheline with just a single locked operation, commonly
> without retries, is quite beneficial.
Due to lack of response and taking into account this commentary, I'm marking
this patch as "Returned with feedback", but hopefully I can pick it up later to
improve.
Good luck.
> On Fri, Nov 30, 2018 at 10:31 PM Юрий Соколов <funny.falcon@gmail.com> wrote: > >> Due to lack of response and taking into account this commentary, I'm marking >> this patch as "Returned with feedback", but hopefully I can pick it up later to >> improve. > > Good luck. Unexpected for me, but promising reaction - regardless of the meaning of it maybe there are chances that you'll be here to help with the future versions, thanks.