Thread: Re: [pgadmin-hackers] Declarative partitioning in pgAdmin4
Hi
[moving to the pgadmin-hackers mailing list as this a pgAdmin feature]
On Wed, Apr 26, 2017 at 8:20 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
-- Hi DaveMurtuza and I started thinking about "How to add Declarative Partitioning" support in pgAdmin4. We thought instead of showing Partition Table under existing Tables collection, we should add new collection node "Partition Tables". Showing table under the table node recursively will require lots of code changes in table and it's child nodes (column, index, trigger, etc..) which is more complex and error prone.
Perhaps, but from the user's perspective, there's no reason to list them separately - they are just tables with a different structure from others. We shouldn't confuse the user just because it's more convenient for us.
I really think it should look like this:
- Tables
- t1
- Columns
- Constraints
- Partitions
- p1
- Sub Objects (whatever they may be)
...
- p2
...
- t2
...
Below is the design that we can implement:
- Create new "Partition Tables" collection node. User will be able to create partition table by clicking "Create -> Partition Table" menu that we will add on collection node. We will share the dialog prototype later once we will have complete understanding of it.
Can you share a mock-up of the dialog? The Figma tool that Shirley shared looks like it'll be good for doing that - I can invite you to the team.
- Once table is created user will be able to create partitions by clicking "Create -> Partitions" menu will be added on each partitioned table node. We will share the dialog prototype later once we will have complete understanding of it.
I would expect the user to be able to define the partitioning scheme when they create the table; e.g. on a new tab. It shouldn't be a two step process.
- We will have to show sub nodes like (column, index, trigger, constraints, etc..) on main table while some of the sub nodes won't require for partitions like (column and many more again require some more knowledge on partitioning).
OK.
Apart from above we will have to figure out following:
- How to remove partitions(table) from existing tables node as value of relkind column is 'r' for partitions.
- Partitioning scheme to show in SQL pane for partitions.
- Some unknown issue/features of Declarative partitioning.
OK.
The above implementation may take more time, so it might possible that we may not be able to finish it by 14th May (deadline).
It would be nice to have it by then, but the true deadline will be a later beta (TBD, but probably beta 2 which is sufficiently far off).
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hello!
On Wed, Apr 26, 2017 at 4:26 AM Dave Page <dpage@pgadmin.org> wrote:
Hi[moving to the pgadmin-hackers mailing list as this a pgAdmin feature]On Wed, Apr 26, 2017 at 8:20 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi DaveMurtuza and I started thinking about "How to add Declarative Partitioning" support in pgAdmin4. We thought instead of showing Partition Table under existing Tables collection, we should add new collection node "Partition Tables". Showing table under the table node recursively will require lots of code changes in table and it's child nodes (column, index, trigger, etc..) which is more complex and error prone.Perhaps, but from the user's perspective, there's no reason to list them separately - they are just tables with a different structure from others. We shouldn't confuse the user just because it's more convenient for us.I really think it should look like this:- Tables- t1- Columns- Constraints- Partitions- p1- Sub Objects (whatever they may be)...- p2...- t2...
Below is the design that we can implement:
- Create new "Partition Tables" collection node. User will be able to create partition table by clicking "Create -> Partition Table" menu that we will add on collection node. We will share the dialog prototype later once we will have complete understanding of it.
Can you share a mock-up of the dialog? The Figma tool that Shirley shared looks like it'll be good for doing that - I can invite you to the team.
- Once table is created user will be able to create partitions by clicking "Create -> Partitions" menu will be added on each partitioned table node. We will share the dialog prototype later once we will have complete understanding of it.
I would expect the user to be able to define the partitioning scheme when they create the table; e.g. on a new tab. It shouldn't be a two step process.
- We will have to show sub nodes like (column, index, trigger, constraints, etc..) on main table while some of the sub nodes won't require for partitions like (column and many more again require some more knowledge on partitioning).
OK.Apart from above we will have to figure out following:
- How to remove partitions(table) from existing tables node as value of relkind column is 'r' for partitions.
- Partitioning scheme to show in SQL pane for partitions.
- Some unknown issue/features of Declarative partitioning.
OK.
Seems like there are a couple of assumptions being made here:
- Users need to see partitioned tables when expanding parent table
- Users need to view partitioned tables in context to their parent table (Dave says yes, Akshay and Murtuza say no)
- Users want to create a partitioned table through the browser (Akshay and Murtuza say yes, Dave says no)
Plus some technical concerns:
- Making code changes in table is complex and error prone
- How to move partitions from one node to another
I think the first assumption is important to validate or invalidate before even thinking about how to implement or addressing technical concerns. We may come to learn that there are solutions that don't require a lot of technical maneuvering, or perhaps learn there's no need for change at all.
Akshay and Murtuza, I'm happy to work with you on doing some research (interviews to discover user needs and pains, creating mockups, getting feedback etc) and coming up with some solutions based on user feedback.
On Wed, Apr 26, 2017 at 11:06 PM, Shirley Wang <swang@pivotal.io> wrote:
Hello!On Wed, Apr 26, 2017 at 4:26 AM Dave Page <dpage@pgadmin.org> wrote:Hi[moving to the pgadmin-hackers mailing list as this a pgAdmin feature]On Wed, Apr 26, 2017 at 8:20 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi DaveMurtuza and I started thinking about "How to add Declarative Partitioning" support in pgAdmin4. We thought instead of showing Partition Table under existing Tables collection, we should add new collection node "Partition Tables". Showing table under the table node recursively will require lots of code changes in table and it's child nodes (column, index, trigger, etc..) which is more complex and error prone.Perhaps, but from the user's perspective, there's no reason to list them separately - they are just tables with a different structure from others. We shouldn't confuse the user just because it's more convenient for us.I really think it should look like this:- Tables- t1- Columns- Constraints- Partitions- p1- Sub Objects (whatever they may be)...- p2...- t2...Below is the design that we can implement:
- Create new "Partition Tables" collection node. User will be able to create partition table by clicking "Create -> Partition Table" menu that we will add on collection node. We will share the dialog prototype later once we will have complete understanding of it.
Can you share a mock-up of the dialog? The Figma tool that Shirley shared looks like it'll be good for doing that - I can invite you to the team.
- Once table is created user will be able to create partitions by clicking "Create -> Partitions" menu will be added on each partitioned table node. We will share the dialog prototype later once we will have complete understanding of it.
I would expect the user to be able to define the partitioning scheme when they create the table; e.g. on a new tab. It shouldn't be a two step process.
- We will have to show sub nodes like (column, index, trigger, constraints, etc..) on main table while some of the sub nodes won't require for partitions like (column and many more again require some more knowledge on partitioning).
OK.Apart from above we will have to figure out following:
- How to remove partitions(table) from existing tables node as value of relkind column is 'r' for partitions.
- Partitioning scheme to show in SQL pane for partitions.
- Some unknown issue/features of Declarative partitioning.
OK.Seems like there are a couple of assumptions being made here:- Users need to see partitioned tables when expanding parent table- Users need to view partitioned tables in context to their parent table (Dave says yes, Akshay and Murtuza say no)- Users want to create a partitioned table through the browser (Akshay and Murtuza say yes, Dave says no)Plus some technical concerns:- Making code changes in table is complex and error prone- How to move partitions from one node to anotherI think the first assumption is important to validate or invalidate before even thinking about how to implement or addressing technical concerns. We may come to learn that there are solutions that don't require a lot of technical maneuvering, or perhaps learn there's no need for change at all.Akshay and Murtuza, I'm happy to work with you on doing some research (interviews to discover user needs and pains, creating mockups, getting feedback etc) and coming up with some solutions based on user feedback.
Sure, it would be great. We will require some R&D about which feature/controls(Inheritance, Constraints, Indexes, Triggers and may be more) works with partitioning and which we will have to disabled if user will create partition table.
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
On Wed, Apr 26, 2017 at 6:36 PM, Shirley Wang <swang@pivotal.io> wrote:
Hello!On Wed, Apr 26, 2017 at 4:26 AM Dave Page <dpage@pgadmin.org> wrote:Hi[moving to the pgadmin-hackers mailing list as this a pgAdmin feature]On Wed, Apr 26, 2017 at 8:20 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi DaveMurtuza and I started thinking about "How to add Declarative Partitioning" support in pgAdmin4. We thought instead of showing Partition Table under existing Tables collection, we should add new collection node "Partition Tables". Showing table under the table node recursively will require lots of code changes in table and it's child nodes (column, index, trigger, etc..) which is more complex and error prone.Perhaps, but from the user's perspective, there's no reason to list them separately - they are just tables with a different structure from others. We shouldn't confuse the user just because it's more convenient for us.I really think it should look like this:- Tables- t1- Columns- Constraints- Partitions- p1- Sub Objects (whatever they may be)...- p2...- t2...Below is the design that we can implement:
- Create new "Partition Tables" collection node. User will be able to create partition table by clicking "Create -> Partition Table" menu that we will add on collection node. We will share the dialog prototype later once we will have complete understanding of it.
Can you share a mock-up of the dialog? The Figma tool that Shirley shared looks like it'll be good for doing that - I can invite you to the team.
- Once table is created user will be able to create partitions by clicking "Create -> Partitions" menu will be added on each partitioned table node. We will share the dialog prototype later once we will have complete understanding of it.
I would expect the user to be able to define the partitioning scheme when they create the table; e.g. on a new tab. It shouldn't be a two step process.
- We will have to show sub nodes like (column, index, trigger, constraints, etc..) on main table while some of the sub nodes won't require for partitions like (column and many more again require some more knowledge on partitioning).
OK.Apart from above we will have to figure out following:
- How to remove partitions(table) from existing tables node as value of relkind column is 'r' for partitions.
- Partitioning scheme to show in SQL pane for partitions.
- Some unknown issue/features of Declarative partitioning.
OK.Seems like there are a couple of assumptions being made here:- Users need to see partitioned tables when expanding parent table
If by "assumption" you mean "fact", then yes :-). Users need to be able to see and manipulate partitions. Whilst some sub-objects are defined on the parent table (e.g. the columns), others are defined on the individual partitions (e.g. triggers, indexes).
- Users need to view partitioned tables in context to their parent table (Dave says yes, Akshay and Murtuza say no)
That's not what was said. Akshay and Murtuza were proposing a new collection node, e.g.
- Schema
- Functions
- Partitioned Tables
- Tables
- Views
I'm saying that that unnecessarily complicates things for the user. The fact that a table happens to use declarative partitioning, doesn't make it a different type of object as far as Postgres is concerned, nor should it for us.
- Users want to create a partitioned table through the browser (Akshay and Murtuza say yes, Dave says no)
I didn't say that. I said it shouldn't be a two-part process.
Plus some technical concerns:- Making code changes in table is complex and error prone- How to move partitions from one node to anotherI think the first assumption is important to validate or invalidate before even thinking about how to implement or addressing technical concerns. We may come to learn that there are solutions that don't require a lot of technical maneuvering, or perhaps learn there's no need for change at all.
Akshay and Murtuza, I'm happy to work with you on doing some research (interviews to discover user needs and pains, creating mockups, getting feedback etc) and coming up with some solutions based on user feedback.
How would users come up with feedback, given that the feature doesn't exist in the field yet?
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi Dave
As per discussion I have changed the logic of showing partitioned table in browser tree. Attached is the screenshot.
Let me know your thoughts.
On Thu, Apr 27, 2017 at 1:44 PM, Dave Page <dpage@pgadmin.org> wrote:
On Wed, Apr 26, 2017 at 6:36 PM, Shirley Wang <swang@pivotal.io> wrote:Hello!On Wed, Apr 26, 2017 at 4:26 AM Dave Page <dpage@pgadmin.org> wrote:Hi[moving to the pgadmin-hackers mailing list as this a pgAdmin feature]On Wed, Apr 26, 2017 at 8:20 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi DaveMurtuza and I started thinking about "How to add Declarative Partitioning" support in pgAdmin4. We thought instead of showing Partition Table under existing Tables collection, we should add new collection node "Partition Tables". Showing table under the table node recursively will require lots of code changes in table and it's child nodes (column, index, trigger, etc..) which is more complex and error prone.Perhaps, but from the user's perspective, there's no reason to list them separately - they are just tables with a different structure from others. We shouldn't confuse the user just because it's more convenient for us.I really think it should look like this:- Tables- t1- Columns- Constraints- Partitions- p1- Sub Objects (whatever they may be)...- p2...- t2...Below is the design that we can implement:
- Create new "Partition Tables" collection node. User will be able to create partition table by clicking "Create -> Partition Table" menu that we will add on collection node. We will share the dialog prototype later once we will have complete understanding of it.
Can you share a mock-up of the dialog? The Figma tool that Shirley shared looks like it'll be good for doing that - I can invite you to the team.
- Once table is created user will be able to create partitions by clicking "Create -> Partitions" menu will be added on each partitioned table node. We will share the dialog prototype later once we will have complete understanding of it.
I would expect the user to be able to define the partitioning scheme when they create the table; e.g. on a new tab. It shouldn't be a two step process.
- We will have to show sub nodes like (column, index, trigger, constraints, etc..) on main table while some of the sub nodes won't require for partitions like (column and many more again require some more knowledge on partitioning).
OK.Apart from above we will have to figure out following:
- How to remove partitions(table) from existing tables node as value of relkind column is 'r' for partitions.
- Partitioning scheme to show in SQL pane for partitions.
- Some unknown issue/features of Declarative partitioning.
OK.Seems like there are a couple of assumptions being made here:- Users need to see partitioned tables when expanding parent tableIf by "assumption" you mean "fact", then yes :-). Users need to be able to see and manipulate partitions. Whilst some sub-objects are defined on the parent table (e.g. the columns), others are defined on the individual partitions (e.g. triggers, indexes).- Users need to view partitioned tables in context to their parent table (Dave says yes, Akshay and Murtuza say no)That's not what was said. Akshay and Murtuza were proposing a new collection node, e.g.- Schema- Functions- Partitioned Tables- Tables- ViewsI'm saying that that unnecessarily complicates things for the user. The fact that a table happens to use declarative partitioning, doesn't make it a different type of object as far as Postgres is concerned, nor should it for us.- Users want to create a partitioned table through the browser (Akshay and Murtuza say yes, Dave says no)I didn't say that. I said it shouldn't be a two-part process.Plus some technical concerns:- Making code changes in table is complex and error prone- How to move partitions from one node to anotherI think the first assumption is important to validate or invalidate before even thinking about how to implement or addressing technical concerns. We may come to learn that there are solutions that don't require a lot of technical maneuvering, or perhaps learn there's no need for change at all.Akshay and Murtuza, I'm happy to work with you on doing some research (interviews to discover user needs and pains, creating mockups, getting feedback etc) and coming up with some solutions based on user feedback.How would users come up with feedback, given that the feature doesn't exist in the field yet?--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
On Thu, Apr 27, 2017 at 7:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi DaveAs per discussion I have changed the logic of showing partitioned table in browser tree. Attached is the screenshot.Let me know your thoughts.
Greenplum has had declarative partitioning for quite some time, I haven't spent much time diving into the Postgres implementation specifically, however, we have had some pain and I would suggest a little bit of thought behind this.
The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
-- Rob
On Thu, Apr 27, 2017 at 12:01 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi DaveAs per discussion I have changed the logic of showing partitioned table in browser tree. Attached is the screenshot.Let me know your thoughts.
That's pretty much what I had in mind, yes. There are certain object types that would need to be rendered under the partitions themselves instead of the parent though.
--On Thu, Apr 27, 2017 at 1:44 PM, Dave Page <dpage@pgadmin.org> wrote:On Wed, Apr 26, 2017 at 6:36 PM, Shirley Wang <swang@pivotal.io> wrote:Hello!On Wed, Apr 26, 2017 at 4:26 AM Dave Page <dpage@pgadmin.org> wrote:Hi[moving to the pgadmin-hackers mailing list as this a pgAdmin feature]On Wed, Apr 26, 2017 at 8:20 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi DaveMurtuza and I started thinking about "How to add Declarative Partitioning" support in pgAdmin4. We thought instead of showing Partition Table under existing Tables collection, we should add new collection node "Partition Tables". Showing table under the table node recursively will require lots of code changes in table and it's child nodes (column, index, trigger, etc..) which is more complex and error prone.Perhaps, but from the user's perspective, there's no reason to list them separately - they are just tables with a different structure from others. We shouldn't confuse the user just because it's more convenient for us.I really think it should look like this:- Tables- t1- Columns- Constraints- Partitions- p1- Sub Objects (whatever they may be)...- p2...- t2...Below is the design that we can implement:
- Create new "Partition Tables" collection node. User will be able to create partition table by clicking "Create -> Partition Table" menu that we will add on collection node. We will share the dialog prototype later once we will have complete understanding of it.
Can you share a mock-up of the dialog? The Figma tool that Shirley shared looks like it'll be good for doing that - I can invite you to the team.
- Once table is created user will be able to create partitions by clicking "Create -> Partitions" menu will be added on each partitioned table node. We will share the dialog prototype later once we will have complete understanding of it.
I would expect the user to be able to define the partitioning scheme when they create the table; e.g. on a new tab. It shouldn't be a two step process.
- We will have to show sub nodes like (column, index, trigger, constraints, etc..) on main table while some of the sub nodes won't require for partitions like (column and many more again require some more knowledge on partitioning).
OK.Apart from above we will have to figure out following:
- How to remove partitions(table) from existing tables node as value of relkind column is 'r' for partitions.
- Partitioning scheme to show in SQL pane for partitions.
- Some unknown issue/features of Declarative partitioning.
OK.Seems like there are a couple of assumptions being made here:- Users need to see partitioned tables when expanding parent tableIf by "assumption" you mean "fact", then yes :-). Users need to be able to see and manipulate partitions. Whilst some sub-objects are defined on the parent table (e.g. the columns), others are defined on the individual partitions (e.g. triggers, indexes).- Users need to view partitioned tables in context to their parent table (Dave says yes, Akshay and Murtuza say no)That's not what was said. Akshay and Murtuza were proposing a new collection node, e.g.- Schema- Functions- Partitioned Tables- Tables- ViewsI'm saying that that unnecessarily complicates things for the user. The fact that a table happens to use declarative partitioning, doesn't make it a different type of object as far as Postgres is concerned, nor should it for us.- Users want to create a partitioned table through the browser (Akshay and Murtuza say yes, Dave says no)I didn't say that. I said it shouldn't be a two-part process.Plus some technical concerns:- Making code changes in table is complex and error prone- How to move partitions from one node to anotherI think the first assumption is important to validate or invalidate before even thinking about how to implement or addressing technical concerns. We may come to learn that there are solutions that don't require a lot of technical maneuvering, or perhaps learn there's no need for change at all.Akshay and Murtuza, I'm happy to work with you on doing some research (interviews to discover user needs and pains, creating mockups, getting feedback etc) and coming up with some solutions based on user feedback.How would users come up with feedback, given that the feature doesn't exist in the field yet?--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Apr 27, 2017 at 3:18 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:
On Thu, Apr 27, 2017 at 7:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi DaveAs per discussion I have changed the logic of showing partitioned table in browser tree. Attached is the screenshot.Let me know your thoughts.Greenplum has had declarative partitioning for quite some time, I haven't spent much time diving into the Postgres implementation specifically, however, we have had some pain and I would suggest a little bit of thought behind this.The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
Perhaps, though I doubt that number would be common in Postgres. The problem though, is that there are both stats and sub-objects (indexes and triggers for example) that are part of the child partitions, not the parent - and they may differ from partition to partition. I don't see that we have any choice but to display them so users can work with them.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
How might you propose grouping them (based on the way they work in Postgres)?
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
Perhaps, though I doubt that number would be common in Postgres. The problem though, is that there are both stats and sub-objects (indexes and triggers for example) that are part of the child partitions, not the parent - and they may differ from partition to partition.
Certainly there differences in Postgres and Greenplum and this might very well be one of those places.
I don't see that we have any choice but to display them so users can work with them.
We don't want to hide them, I do think we want to make accessing them a useful experience. If we rephrase this statement as "How might we display partitioned tables so that users are able to work with and modify the pieces they need?", this opens us up to different opportunities in how we display them.
Even with a simple case of 90 days of data partitioned by day, a drop down showing 90 tables that are all mostly the same is a little overwhelming.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
How might you propose grouping them (based on the way they work in Postgres)?
Honestly I'm not sure. We didn't really start thinking about this until the other day so we are starting to look into the pains that Greenplum customers have. Sharing that pain we discover back to the pgAdmin community and seeing if it makes sense from a Postgres perspective. After that I need to dive into the Postgres implementation.
-- Rob
Hi All
To implement Declarative Partitioning in existing Table dialog below changes should be implemented:
- Icon: As we have separate icon for view and materialised view, we should have for partition table. I didn't find any in font awesome.
- Inheritance:
- A partition cannot have any parents other than the partitioned table it is a partition of, nor can a regular table inherit from a partitioned table making the latter its parent. That means partitioned tables and partitions do not participate in inheritance with regular tables.
- When user creates regular table then Inherited from table(s) control should not display partitioned table.
- A partition cannot have any parents other than the partitioned table it is a partition of, nor can a regular table inherit from a partitioned table making the latter its parent. That means partitioned tables and partitions do not participate in inheritance with regular tables.
- Constraints:
- Primary/Foreign/Unique/Exclusion constraints are not supported on partitioned table. In that case respective controls should be disabled for partitioned table.
- We will have to check which constraints are applicable on partitions(of partitioned table) still some R&D require. Can someone help me here.
- For regular tables in Foreign Key constraints tab References control should not list partition tables.
- Check constraints : cannot add NO INHERIT constraint to partitioned table, so that control is disabled for partition table.
- Advanced Tab:
- Relation works with partition table theirs is an error if "With indexes?" is set to Yes, so we need to disabled that for partition table.
- "Has OIDs?" and "Unlogged?" works but not sure about "Fill factor" and "Of type".
- Parameter Tab:
- Gives error (unrecognized parameter "autovacuum_enabled") for all parameters of Table Tab and working fine for "Toast Table" it's working.
- Required switch control to specify whether it is a regular table or partitioned table. I have added it on General tab. Please refer Partition_Switch.png
- Will have to add new tab "Partition" which will have one select2 control to define its Range partition or List partition. Refer Partition_Tab.png
- Design following controls in Partition tab:
- How to add columns in case of Range/List partition? LIST partition key supports only one column. For RANGE user can specify multiple columns.
- How to specify expression, COLLATE while adding columns for partition.
- We need subnode control so that user will add number of partition with there values of the main table. Need lot of R&D for this.
- We will have to provide "Create partition", "Attach Partition" and "Detech partition" context menu options on Partitions collection node.
On Thu, Apr 27, 2017 at 9:14 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:
The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
Perhaps, though I doubt that number would be common in Postgres. The problem though, is that there are both stats and sub-objects (indexes and triggers for example) that are part of the child partitions, not the parent - and they may differ from partition to partition.Certainly there differences in Postgres and Greenplum and this might very well be one of those places.I don't see that we have any choice but to display them so users can work with them.We don't want to hide them, I do think we want to make accessing them a useful experience. If we rephrase this statement as "How might we display partitioned tables so that users are able to work with and modify the pieces they need?", this opens us up to different opportunities in how we display them.Even with a simple case of 90 days of data partitioned by day, a drop down showing 90 tables that are all mostly the same is a little overwhelming.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
How might you propose grouping them (based on the way they work in Postgres)?Honestly I'm not sure. We didn't really start thinking about this until the other day so we are starting to look into the pains that Greenplum customers have. Sharing that pain we discover back to the pgAdmin community and seeing if it makes sense from a Postgres perspective. After that I need to dive into the Postgres implementation.-- Rob
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
Hi
--
On Tue, May 2, 2017 at 2:46 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AllTo implement Declarative Partitioning in existing Table dialog below changes should be implemented:
- Icon: As we have separate icon for view and materialised view, we should have for partition table. I didn't find any in font awesome.
They are really different object types though (even having their own collections), which isn't the case here. I'm not against having a slightly modified icon, but I don't think it's necessary. Note that the object icons come from pgAdmin III, and were custom designed for us. They aren't in font awesome etc. We'd need to tweak one of the existing ones.
- Inheritance:
- A partition cannot have any parents other than the partitioned table it is a partition of, nor can a regular table inherit from a partitioned table making the latter its parent. That means partitioned tables and partitions do not participate in inheritance with regular tables.
- When user creates regular table then Inherited from table(s) control should not display partitioned table.
- Constraints:
- Primary/Foreign/Unique/
Exclusion constraints are not supported on partitioned table. In that case respective controls should be disabled for partitioned table. - We will have to check which constraints are applicable on partitions(of partitioned table) still some R&D require. Can someone help me here.
- For regular tables in Foreign Key constraints tab References control should not list partition tables.
- Check constraints : cannot add NO INHERIT constraint to partitioned table, so that control is disabled for partition table.
- Advanced Tab:
- Relation works with partition table theirs is an error if "With indexes?" is set to Yes, so we need to disabled that for partition table.
- "Has OIDs?" and "Unlogged?" works but not sure about "Fill factor" and "Of type".
- Parameter Tab:
- Gives error (unrecognized parameter "autovacuum_enabled") for all parameters of Table Tab and working fine for "Toast Table" it's working.
Can you detail what operations someone would likely want (or need) to perform on the parent/child tables; e.g.
Parent:
- View stats
- View data
- Truncate
- View/create columns
- Bulk-create indexes
- Bulk-create foreign keys
Child:
- View stats
- View data
- Truncate
- Create indexes
- Create foreign keys
Apart from above we will have to do following:
- Required switch control to specify whether it is a regular table or partitioned table. I have added it on General tab. Please refer Partition_Switch.png
- Will have to add new tab "Partition" which will have one select2 control to define its Range partition or List partition. Refer Partition_Tab.png
"Partitions"?
- Design following controls in Partition tab:
- How to add columns in case of Range/List partition? LIST partition key supports only one column. For RANGE user can specify multiple columns.
- How to specify expression, COLLATE while adding columns for partition.
- We need subnode control so that user will add number of partition with there values of the main table. Need lot of R&D for this.
- We will have to provide "Create partition", "Attach Partition" and "Detech partition" context menu options on Partitions collection node.
OK.
Thanks! This is a complex one :-(
Let me know if I forgot something to add that we may need to handle/implement.--On Thu, Apr 27, 2017 at 9:14 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
Perhaps, though I doubt that number would be common in Postgres. The problem though, is that there are both stats and sub-objects (indexes and triggers for example) that are part of the child partitions, not the parent - and they may differ from partition to partition.Certainly there differences in Postgres and Greenplum and this might very well be one of those places.I don't see that we have any choice but to display them so users can work with them.We don't want to hide them, I do think we want to make accessing them a useful experience. If we rephrase this statement as "How might we display partitioned tables so that users are able to work with and modify the pieces they need?", this opens us up to different opportunities in how we display them.Even with a simple case of 90 days of data partitioned by day, a drop down showing 90 tables that are all mostly the same is a little overwhelming.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
How might you propose grouping them (based on the way they work in Postgres)?Honestly I'm not sure. We didn't really start thinking about this until the other day so we are starting to look into the pains that Greenplum customers have. Sharing that pain we discover back to the pgAdmin community and seeing if it makes sense from a Postgres perspective. After that I need to dive into the Postgres implementation.-- Rob
--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Tue, May 2, 2017 at 10:56 AM Dave Page <dpage@pgadmin.org> wrote:
HiOn Tue, May 2, 2017 at 2:46 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllTo implement Declarative Partitioning in existing Table dialog below changes should be implemented:
- Icon: As we have separate icon for view and materialised view, we should have for partition table. I didn't find any in font awesome.
They are really different object types though (even having their own collections), which isn't the case here. I'm not against having a slightly modified icon, but I don't think it's necessary. Note that the object icons come from pgAdmin III, and were custom designed for us. They aren't in font awesome etc. We'd need to tweak one of the existing ones.
- Inheritance:
- A partition cannot have any parents other than the partitioned table it is a partition of, nor can a regular table inherit from a partitioned table making the latter its parent. That means partitioned tables and partitions do not participate in inheritance with regular tables.
- When user creates regular table then Inherited from table(s) control should not display partitioned table.
- Constraints:
- Primary/Foreign/Unique/Exclusion constraints are not supported on partitioned table. In that case respective controls should be disabled for partitioned table.
- We will have to check which constraints are applicable on partitions(of partitioned table) still some R&D require. Can someone help me here.
- For regular tables in Foreign Key constraints tab References control should not list partition tables.
- Check constraints : cannot add NO INHERIT constraint to partitioned table, so that control is disabled for partition table.
- Advanced Tab:
- Relation works with partition table theirs is an error if "With indexes?" is set to Yes, so we need to disabled that for partition table.
- "Has OIDs?" and "Unlogged?" works but not sure about "Fill factor" and "Of type".
- Parameter Tab:
- Gives error (unrecognized parameter "autovacuum_enabled") for all parameters of Table Tab and working fine for "Toast Table" it's working.
Can you detail what operations someone would likely want (or need) to perform on the parent/child tables; e.g.Parent:- View stats- View data- Truncate- View/create columns- Bulk-create indexes- Bulk-create foreign keysChild:- View stats- View data- Truncate- Create indexes- Create foreign keysApart from above we will have to do following:
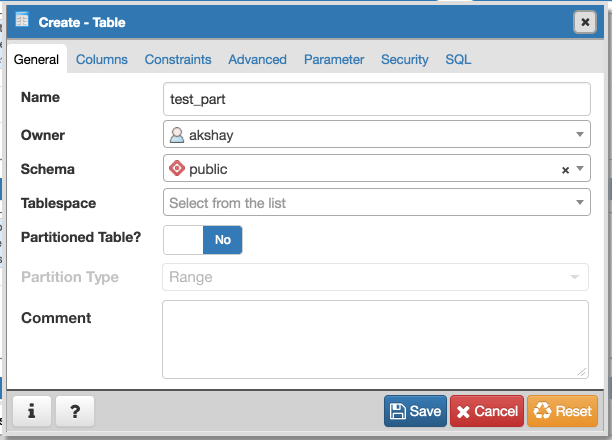
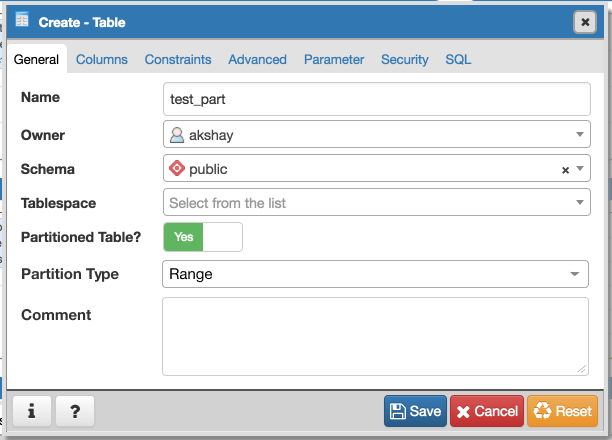
- Required switch control to specify whether it is a regular table or partitioned table. I have added it on General tab. Please refer Partition_Switch.png
- Will have to add new tab "Partition" which will have one select2 control to define its Range partition or List partition. Refer Partition_Tab.png
"Partitions"?
Is there a reason why 'Partition' needs to open in a new tab? If there's only one field, we should include it on the same page since the tabs don't dictate necessary steps in a sequential order. Users will be able to find what they need without navigating to another part of the dialog.
Example:
- Design following controls in Partition tab:
- How to add columns in case of Range/List partition? LIST partition key supports only one column. For RANGE user can specify multiple columns.
- How to specify expression, COLLATE while adding columns for partition.
- We need subnode control so that user will add number of partition with there values of the main table. Need lot of R&D for this.
- We will have to provide "Create partition", "Attach Partition" and "Detech partition" context menu options on Partitions collection node.
OK.Thanks! This is a complex one :-(Let me know if I forgot something to add that we may need to handle/implement.--On Thu, Apr 27, 2017 at 9:14 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
Perhaps, though I doubt that number would be common in Postgres. The problem though, is that there are both stats and sub-objects (indexes and triggers for example) that are part of the child partitions, not the parent - and they may differ from partition to partition.Certainly there differences in Postgres and Greenplum and this might very well be one of those places.I don't see that we have any choice but to display them so users can work with them.We don't want to hide them, I do think we want to make accessing them a useful experience. If we rephrase this statement as "How might we display partitioned tables so that users are able to work with and modify the pieces they need?", this opens us up to different opportunities in how we display them.Even with a simple case of 90 days of data partitioned by day, a drop down showing 90 tables that are all mostly the same is a little overwhelming.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
How might you propose grouping them (based on the way they work in Postgres)?Honestly I'm not sure. We didn't really start thinking about this until the other day so we are starting to look into the pains that Greenplum customers have. Sharing that pain we discover back to the pgAdmin community and seeing if it makes sense from a Postgres perspective. After that I need to dive into the Postgres implementation.-- Rob
--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Hi Shirley
--

On Wed, May 3, 2017 at 3:31 AM, Shirley Wang <swang@pivotal.io> wrote:
On Tue, May 2, 2017 at 10:56 AM Dave Page <dpage@pgadmin.org> wrote:HiOn Tue, May 2, 2017 at 2:46 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllTo implement Declarative Partitioning in existing Table dialog below changes should be implemented:
- Icon: As we have separate icon for view and materialised view, we should have for partition table. I didn't find any in font awesome.
They are really different object types though (even having their own collections), which isn't the case here. I'm not against having a slightly modified icon, but I don't think it's necessary. Note that the object icons come from pgAdmin III, and were custom designed for us. They aren't in font awesome etc. We'd need to tweak one of the existing ones.
- Inheritance:
- A partition cannot have any parents other than the partitioned table it is a partition of, nor can a regular table inherit from a partitioned table making the latter its parent. That means partitioned tables and partitions do not participate in inheritance with regular tables.
- When user creates regular table then Inherited from table(s) control should not display partitioned table.
- Constraints:
- Primary/Foreign/Unique/
Exclusion constraints are not supported on partitioned table. In that case respective controls should be disabled for partitioned table. - We will have to check which constraints are applicable on partitions(of partitioned table) still some R&D require. Can someone help me here.
- For regular tables in Foreign Key constraints tab References control should not list partition tables.
- Check constraints : cannot add NO INHERIT constraint to partitioned table, so that control is disabled for partition table.
- Advanced Tab:
- Relation works with partition table theirs is an error if "With indexes?" is set to Yes, so we need to disabled that for partition table.
- "Has OIDs?" and "Unlogged?" works but not sure about "Fill factor" and "Of type".
- Parameter Tab:
- Gives error (unrecognized parameter "autovacuum_enabled") for all parameters of Table Tab and working fine for "Toast Table" it's working.
Can you detail what operations someone would likely want (or need) to perform on the parent/child tables; e.g.Parent:- View stats- View data- Truncate- View/create columns- Bulk-create indexes- Bulk-create foreign keysChild:- View stats- View data- Truncate- Create indexes- Create foreign keysApart from above we will have to do following:
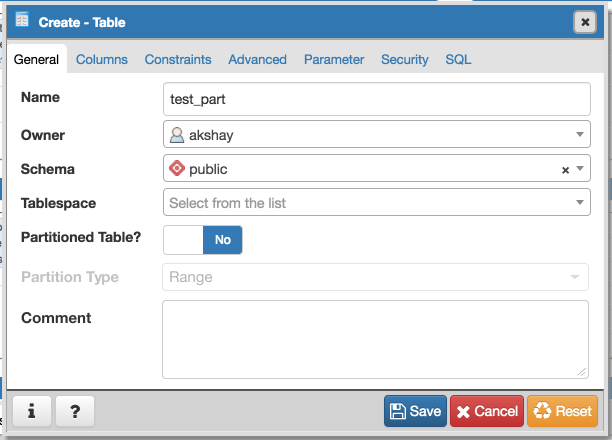
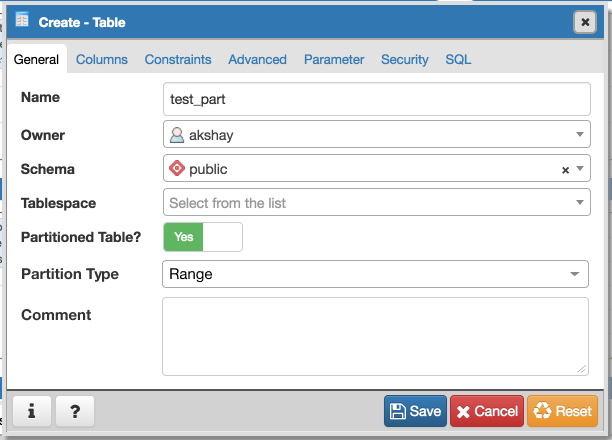
- Required switch control to specify whether it is a regular table or partitioned table. I have added it on General tab. Please refer Partition_Switch.png
- Will have to add new tab "Partition" which will have one select2 control to define its Range partition or List partition. Refer Partition_Tab.png
"Partitions"?Is there a reason why 'Partition' needs to open in a new tab? If there's only one field, we should include it on the same page since the tabs don't dictate necessary steps in a sequential order. Users will be able to find what they need without navigating to another part of the dialog.
There are lots of controls yet to design like column(s), number of partitions, partition schemes will be part of "Partitions" Tab. We will need that.
Example:
- Design following controls in Partition tab:
- How to add columns in case of Range/List partition? LIST partition key supports only one column. For RANGE user can specify multiple columns.
- How to specify expression, COLLATE while adding columns for partition.
- We need subnode control so that user will add number of partition with there values of the main table. Need lot of R&D for this.
- We will have to provide "Create partition", "Attach Partition" and "Detech partition" context menu options on Partitions collection node.
OK.Thanks! This is a complex one :-(Let me know if I forgot something to add that we may need to handle/implement.--On Thu, Apr 27, 2017 at 9:14 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
Perhaps, though I doubt that number would be common in Postgres. The problem though, is that there are both stats and sub-objects (indexes and triggers for example) that are part of the child partitions, not the parent - and they may differ from partition to partition.Certainly there differences in Postgres and Greenplum and this might very well be one of those places.I don't see that we have any choice but to display them so users can work with them.We don't want to hide them, I do think we want to make accessing them a useful experience. If we rephrase this statement as "How might we display partitioned tables so that users are able to work with and modify the pieces they need?", this opens us up to different opportunities in how we display them.Even with a simple case of 90 days of data partitioned by day, a drop down showing 90 tables that are all mostly the same is a little overwhelming.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
How might you propose grouping them (based on the way they work in Postgres)?Honestly I'm not sure. We didn't really start thinking about this until the other day so we are starting to look into the pains that Greenplum customers have. Sharing that pain we discover back to the pgAdmin community and seeing if it makes sense from a Postgres perspective. After that I need to dive into the Postgres implementation.-- Rob
--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
Hi Dave
As per my understanding below operations required
Parent:
- View table data.
- View stats.
- Create regular/partitioned table
- Create N number of partitions.
- Drop/ Drop cascade, Truncate.
- Attach/Detach Partitions.
- Not able to create constraints excluding check constraint.
- View Table Data.
- View stats.
- View partition scheme in SQL pane
- Create primary/foreign/.. key constraint.
- Drop/ Drop cascade, Truncate
On Tue, May 2, 2017 at 8:25 PM, Dave Page <dpage@pgadmin.org> wrote:
HiOn Tue, May 2, 2017 at 2:46 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllTo implement Declarative Partitioning in existing Table dialog below changes should be implemented:
- Icon: As we have separate icon for view and materialised view, we should have for partition table. I didn't find any in font awesome.
They are really different object types though (even having their own collections), which isn't the case here. I'm not against having a slightly modified icon, but I don't think it's necessary. Note that the object icons come from pgAdmin III, and were custom designed for us. They aren't in font awesome etc. We'd need to tweak one of the existing ones.
- Inheritance:
- A partition cannot have any parents other than the partitioned table it is a partition of, nor can a regular table inherit from a partitioned table making the latter its parent. That means partitioned tables and partitions do not participate in inheritance with regular tables.
- When user creates regular table then Inherited from table(s) control should not display partitioned table.
- Constraints:
- Primary/Foreign/Unique/Exclusi
on constraints are not supported on partitioned table. In that case respective controls should be disabled for partitioned table. - We will have to check which constraints are applicable on partitions(of partitioned table) still some R&D require. Can someone help me here.
- For regular tables in Foreign Key constraints tab References control should not list partition tables.
- Check constraints : cannot add NO INHERIT constraint to partitioned table, so that control is disabled for partition table.
- Advanced Tab:
- Relation works with partition table theirs is an error if "With indexes?" is set to Yes, so we need to disabled that for partition table.
- "Has OIDs?" and "Unlogged?" works but not sure about "Fill factor" and "Of type".
- Parameter Tab:
- Gives error (unrecognized parameter "autovacuum_enabled") for all parameters of Table Tab and working fine for "Toast Table" it's working.
Can you detail what operations someone would likely want (or need) to perform on the parent/child tables; e.g.Parent:- View stats- View data- Truncate- View/create columns- Bulk-create indexes- Bulk-create foreign keysChild:- View stats- View data- Truncate- Create indexes- Create foreign keysApart from above we will have to do following:
- Required switch control to specify whether it is a regular table or partitioned table. I have added it on General tab. Please refer Partition_Switch.png
- Will have to add new tab "Partition" which will have one select2 control to define its Range partition or List partition. Refer Partition_Tab.png
"Partitions"?
- Design following controls in Partition tab:
- How to add columns in case of Range/List partition? LIST partition key supports only one column. For RANGE user can specify multiple columns.
- How to specify expression, COLLATE while adding columns for partition.
- We need subnode control so that user will add number of partition with there values of the main table. Need lot of R&D for this.
- We will have to provide "Create partition", "Attach Partition" and "Detech partition" context menu options on Partitions collection node.
OK.Thanks! This is a complex one :-(Let me know if I forgot something to add that we may need to handle/implement.--On Thu, Apr 27, 2017 at 9:14 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
Perhaps, though I doubt that number would be common in Postgres. The problem though, is that there are both stats and sub-objects (indexes and triggers for example) that are part of the child partitions, not the parent - and they may differ from partition to partition.Certainly there differences in Postgres and Greenplum and this might very well be one of those places.I don't see that we have any choice but to display them so users can work with them.We don't want to hide them, I do think we want to make accessing them a useful experience. If we rephrase this statement as "How might we display partitioned tables so that users are able to work with and modify the pieces they need?", this opens us up to different opportunities in how we display them.Even with a simple case of 90 days of data partitioned by day, a drop down showing 90 tables that are all mostly the same is a little overwhelming.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
How might you propose grouping them (based on the way they work in Postgres)?Honestly I'm not sure. We didn't really start thinking about this until the other day so we are starting to look into the pains that Greenplum customers have. Sharing that pain we discover back to the pgAdmin community and seeing if it makes sense from a Postgres perspective. After that I need to dive into the Postgres implementation.-- Rob
--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Great, thanks.
I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.
Please now document how those features will be implemented; e.g, for each one:
- View table data: Parent and partition context menu.
- Attach/detach partitions: Parent properties dialogue
...
That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.
--
On Wed, May 3, 2017 at 1:00 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi DaveAs per my understanding below operations requiredParent:Child:
- View table data.
- View stats.
- Create regular/partitioned table
- Create N number of partitions.
- Drop/ Drop cascade, Truncate.
- Attach/Detach Partitions.
- Not able to create constraints excluding check constraint.
- View Table Data.
- View stats.
- View partition scheme in SQL pane
- Create primary/foreign/.. key constraint.
- Drop/ Drop cascade, Truncate
On Tue, May 2, 2017 at 8:25 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Tue, May 2, 2017 at 2:46 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllTo implement Declarative Partitioning in existing Table dialog below changes should be implemented:
- Icon: As we have separate icon for view and materialised view, we should have for partition table. I didn't find any in font awesome.
They are really different object types though (even having their own collections), which isn't the case here. I'm not against having a slightly modified icon, but I don't think it's necessary. Note that the object icons come from pgAdmin III, and were custom designed for us. They aren't in font awesome etc. We'd need to tweak one of the existing ones.
- Inheritance:
- A partition cannot have any parents other than the partitioned table it is a partition of, nor can a regular table inherit from a partitioned table making the latter its parent. That means partitioned tables and partitions do not participate in inheritance with regular tables.
- When user creates regular table then Inherited from table(s) control should not display partitioned table.
- Constraints:
- Primary/Foreign/Unique/Exclusi
on constraints are not supported on partitioned table. In that case respective controls should be disabled for partitioned table. - We will have to check which constraints are applicable on partitions(of partitioned table) still some R&D require. Can someone help me here.
- For regular tables in Foreign Key constraints tab References control should not list partition tables.
- Check constraints : cannot add NO INHERIT constraint to partitioned table, so that control is disabled for partition table.
- Advanced Tab:
- Relation works with partition table theirs is an error if "With indexes?" is set to Yes, so we need to disabled that for partition table.
- "Has OIDs?" and "Unlogged?" works but not sure about "Fill factor" and "Of type".
- Parameter Tab:
- Gives error (unrecognized parameter "autovacuum_enabled") for all parameters of Table Tab and working fine for "Toast Table" it's working.
Can you detail what operations someone would likely want (or need) to perform on the parent/child tables; e.g.Parent:- View stats- View data- Truncate- View/create columns- Bulk-create indexes- Bulk-create foreign keysChild:- View stats- View data- Truncate- Create indexes- Create foreign keysApart from above we will have to do following:
- Required switch control to specify whether it is a regular table or partitioned table. I have added it on General tab. Please refer Partition_Switch.png
- Will have to add new tab "Partition" which will have one select2 control to define its Range partition or List partition. Refer Partition_Tab.png
"Partitions"?
- Design following controls in Partition tab:
- How to add columns in case of Range/List partition? LIST partition key supports only one column. For RANGE user can specify multiple columns.
- How to specify expression, COLLATE while adding columns for partition.
- We need subnode control so that user will add number of partition with there values of the main table. Need lot of R&D for this.
- We will have to provide "Create partition", "Attach Partition" and "Detech partition" context menu options on Partitions collection node.
OK.Thanks! This is a complex one :-(Let me know if I forgot something to add that we may need to handle/implement.--On Thu, Apr 27, 2017 at 9:14 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
Perhaps, though I doubt that number would be common in Postgres. The problem though, is that there are both stats and sub-objects (indexes and triggers for example) that are part of the child partitions, not the parent - and they may differ from partition to partition.Certainly there differences in Postgres and Greenplum and this might very well be one of those places.I don't see that we have any choice but to display them so users can work with them.We don't want to hide them, I do think we want to make accessing them a useful experience. If we rephrase this statement as "How might we display partitioned tables so that users are able to work with and modify the pieces they need?", this opens us up to different opportunities in how we display them.Even with a simple case of 90 days of data partitioned by day, a drop down showing 90 tables that are all mostly the same is a little overwhelming.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
How might you propose grouping them (based on the way they work in Postgres)?Honestly I'm not sure. We didn't really start thinking about this until the other day so we are starting to look into the pains that Greenplum customers have. Sharing that pain we discover back to the pgAdmin community and seeing if it makes sense from a Postgres perspective. After that I need to dive into the Postgres implementation.-- Rob
--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi!
 We've found that this matrix is really helpful in answering "What's the smallest thing we can build that solves the most important problems?". We typically do this as a team (engineers, designers, and product managers) once we have enough context about user behavior and technical complexity.
We've found that this matrix is really helpful in answering "What's the smallest thing we can build that solves the most important problems?". We typically do this as a team (engineers, designers, and product managers) once we have enough context about user behavior and technical complexity.
On Wed, May 3, 2017 at 8:08 AM Dave Page <dpage@pgadmin.org> wrote:
Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.
Either way we implement this feature, we should test the workflow of how people go through table partitioning with users to get validation on whether or not our decisions make sense for them.
Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.On Wed, May 3, 2017 at 1:00 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi DaveAs per my understanding below operations requiredParent:Child:
- View table data.
- View stats.
- Create regular/partitioned table
- Create N number of partitions.
- Drop/ Drop cascade, Truncate.
- Attach/Detach Partitions.
- Not able to create constraints excluding check constraint.
- View Table Data.
- View stats.
- View partition scheme in SQL pane
- Create primary/foreign/.. key constraint.
- Drop/ Drop cascade, Truncate
It seems like the operations above detail a potential full feature set for table partitioning which is a good starting point. It would be worthwhile to consider what's the minimum we need to include for the first release of table partitioning.
As we get live feedback and release frequently, we can add additional features and fix bugs. If we cut the scope of this, we'll be more confident that we can reach the deadline and deliver user value.
We can determine what should be included by plotting these features within a matrix. Typically user value is on one axis and technical complexity on another, although these can change depending on what your team needs.
We've found that this matrix is really helpful in answering "What's the smallest thing we can build that solves the most important problems?". We typically do this as a team (engineers, designers, and product managers) once we have enough context about user behavior and technical complexity.I can facilitate a session where we run through this exercise. It typically takes about an hour.
Attachment
Hi All
--
On Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:
Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.
As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:
Parent:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partition_bound_specis:{ IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) } - Design discussion required here for how user will specify all the above combinations.
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here. - Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
On Wed, May 3, 2017 at 1:00 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi DaveAs per my understanding below operations requiredParent:Child:
- View table data.
- View stats.
- Create regular/partitioned table
- Create N number of partitions.
- Drop/ Drop cascade, Truncate.
- Attach/Detach Partitions.
- Not able to create constraints excluding check constraint.
- View Table Data.
- View stats.
- View partition scheme in SQL pane
- Create primary/foreign/.. key constraint.
- Drop/ Drop cascade, Truncate
On Tue, May 2, 2017 at 8:25 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Tue, May 2, 2017 at 2:46 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllTo implement Declarative Partitioning in existing Table dialog below changes should be implemented:
- Icon: As we have separate icon for view and materialised view, we should have for partition table. I didn't find any in font awesome.
They are really different object types though (even having their own collections), which isn't the case here. I'm not against having a slightly modified icon, but I don't think it's necessary. Note that the object icons come from pgAdmin III, and were custom designed for us. They aren't in font awesome etc. We'd need to tweak one of the existing ones.
- Inheritance:
- A partition cannot have any parents other than the partitioned table it is a partition of, nor can a regular table inherit from a partitioned table making the latter its parent. That means partitioned tables and partitions do not participate in inheritance with regular tables.
- When user creates regular table then Inherited from table(s) control should not display partitioned table.
- Constraints:
- Primary/Foreign/Unique/Exclusi
on constraints are not supported on partitioned table. In that case respective controls should be disabled for partitioned table. - We will have to check which constraints are applicable on partitions(of partitioned table) still some R&D require. Can someone help me here.
- For regular tables in Foreign Key constraints tab References control should not list partition tables.
- Check constraints : cannot add NO INHERIT constraint to partitioned table, so that control is disabled for partition table.
- Advanced Tab:
- Relation works with partition table theirs is an error if "With indexes?" is set to Yes, so we need to disabled that for partition table.
- "Has OIDs?" and "Unlogged?" works but not sure about "Fill factor" and "Of type".
- Parameter Tab:
- Gives error (unrecognized parameter "autovacuum_enabled") for all parameters of Table Tab and working fine for "Toast Table" it's working.
Can you detail what operations someone would likely want (or need) to perform on the parent/child tables; e.g.Parent:- View stats- View data- Truncate- View/create columns- Bulk-create indexes- Bulk-create foreign keysChild:- View stats- View data- Truncate- Create indexes- Create foreign keysApart from above we will have to do following:
- Required switch control to specify whether it is a regular table or partitioned table. I have added it on General tab. Please refer Partition_Switch.png
- Will have to add new tab "Partition" which will have one select2 control to define its Range partition or List partition. Refer Partition_Tab.png
"Partitions"?
- Design following controls in Partition tab:
- How to add columns in case of Range/List partition? LIST partition key supports only one column. For RANGE user can specify multiple columns.
- How to specify expression, COLLATE while adding columns for partition.
- We need subnode control so that user will add number of partition with there values of the main table. Need lot of R&D for this.
- We will have to provide "Create partition", "Attach Partition" and "Detech partition" context menu options on Partitions collection node.
OK.Thanks! This is a complex one :-(Let me know if I forgot something to add that we may need to handle/implement.--On Thu, Apr 27, 2017 at 9:14 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:The issues we consistently face:
- The huge (often thousands sometimes tens of thousands) number of partitions makes rendering all of the partitions painfully slow and frequently not useful.
Perhaps, though I doubt that number would be common in Postgres. The problem though, is that there are both stats and sub-objects (indexes and triggers for example) that are part of the child partitions, not the parent - and they may differ from partition to partition.Certainly there differences in Postgres and Greenplum and this might very well be one of those places.I don't see that we have any choice but to display them so users can work with them.We don't want to hide them, I do think we want to make accessing them a useful experience. If we rephrase this statement as "How might we display partitioned tables so that users are able to work with and modify the pieces they need?", this opens us up to different opportunities in how we display them.Even with a simple case of 90 days of data partitioned by day, a drop down showing 90 tables that are all mostly the same is a little overwhelming.
- When end users are interested in looking at their partitions they frequently don't want all of them displayed mindlessly
- They are looking at a subset of partitions
- Partitions are typically grouped around their inheritance properties.
How might you propose grouping them (based on the way they work in Postgres)?Honestly I'm not sure. We didn't really start thinking about this until the other day so we are starting to look into the pains that Greenplum customers have. Sharing that pain we discover back to the pgAdmin community and seeing if it makes sense from a Postgres perspective. After that I need to dive into the Postgres implementation.-- Rob
--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Hi
--
On Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partitionis:_bound_spec { IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Designdiscussion required here. - Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:
- Changes that prevent pgAdmin breaking
- Changes that prevent pgAdmin showing incorrect data/info
- Changes that enable pgAdmin to show correct info
- Changes that add functionality for creating/dropping partitioned tables as one unit
- Changes that add functionality for modifying individual partitions independently
Please document the requirements and initial plan on the pgAdmin Redmine Wiki.
Thanks!
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi
--
On Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:
HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partitionis:_bound_spec { IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here. - Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.
I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.
Thanks!--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
On Thu, May 11, 2017 at 11:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
HiOn Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partitionis:_bound_spec { IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here. - Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.
Which meeting?
Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
Akshay, Dave,
I'm filling in for Shirley this week. If you are referring to the weekly meeting tomorrow, I'm planning on joining that and can walk through an exercise to help figure out prioritization.
Thanks,
Anne
On Thu, May 11, 2017 at 9:24 AM Dave Page <dave.page@enterprisedb.com> wrote:
On Thu, May 11, 2017 at 11:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:HiOn Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partition_bound_specis:{ IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here.- Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.Which meeting?--Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
--
Anne Thomas
Product Manager
Pivotal Labs
Hi Dave
--
On Thu, May 11, 2017 at 6:54 PM, Dave Page <dave.page@enterprisedb.com> wrote:
On Thu, May 11, 2017 at 11:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: HiOn Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partitionis:_bound_spec { IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here. - Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.Which meeting?
Meeting with Shirley, which wasn't schedule last Friday as I was on leave.
--Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Hi All
I have started implementation for Declarative Partitioning in pgAdmin4. Following are the tasks that I have implemented till now:
- Show partitioned table and it's partitions under the parent table. Refer Partitioned_Table.png
- To implement above I have created 'partitions' collection node and 'partition' node under table node which is nothing but table node itself. To reduce redundant/duplicate code I have made following changes:
- Create new file "utils.py" under tables folder. Create a new class BaseTableView(PGChildNodeView): derived from PGChildNodeView. TableView and PartitionsView (new class for partition table) is derived from BaseTableView.
- Move the common logic like dependencies, dependents, reversed engineered sql, statistics, reset statistics in BaseTableView class functions and then call that function from derived class like BaseTableView.get_table_dependencies(self, tid)
- Will move more generic logic as we progress on this task.
- Updated supported nodes list in DataGrid(View Data), Backup, Maintenance, Restore to show context menu for partitions.
- Make sure dependencies, dependents, statistics, truncate, delete/drop and Reset Statistics works with partitions.
- Updated jinja template to show correct reversed engineered sql for partitioned table. Please refer the "List_with_expression.png" for List partition and "Range_with_column_expression.png" for Range partition.
- Updated jinja template to show correct sql for partitions of parent table. Please refer "SQL_Range_Partitions.png" and "SQL_List_Partitions.png". Some R&D is still require for other syntax too.
On Thu, May 11, 2017 at 7:06 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi DaveOn Thu, May 11, 2017 at 6:54 PM, Dave Page <dave.page@enterprisedb.com> wrote:On Thu, May 11, 2017 at 11:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: HiOn Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partitionis:_bound_spec { IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here. - Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.Which meeting?Meeting with Shirley, which wasn't schedule last Friday as I was on leave.--Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
Hi Akshay!
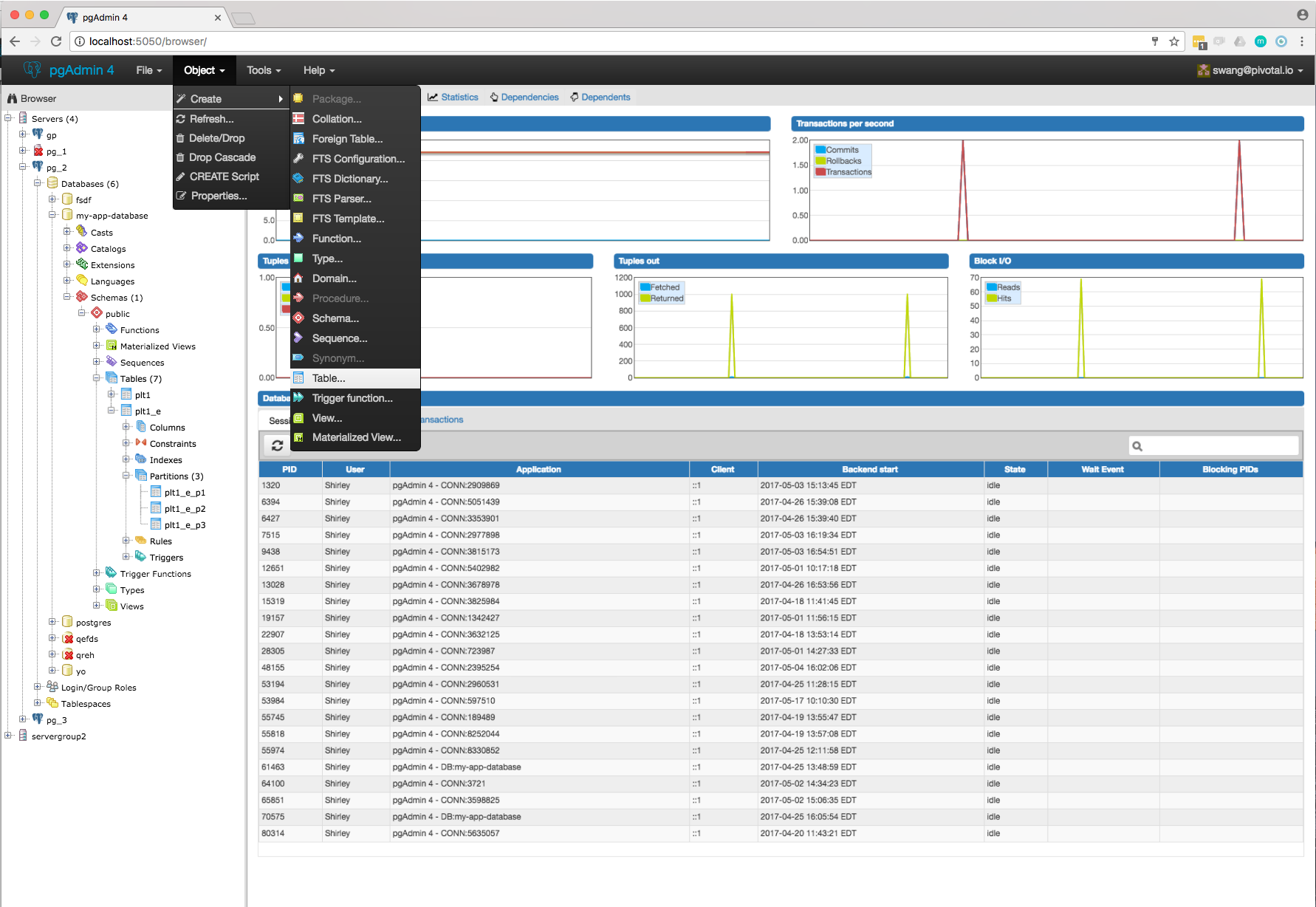
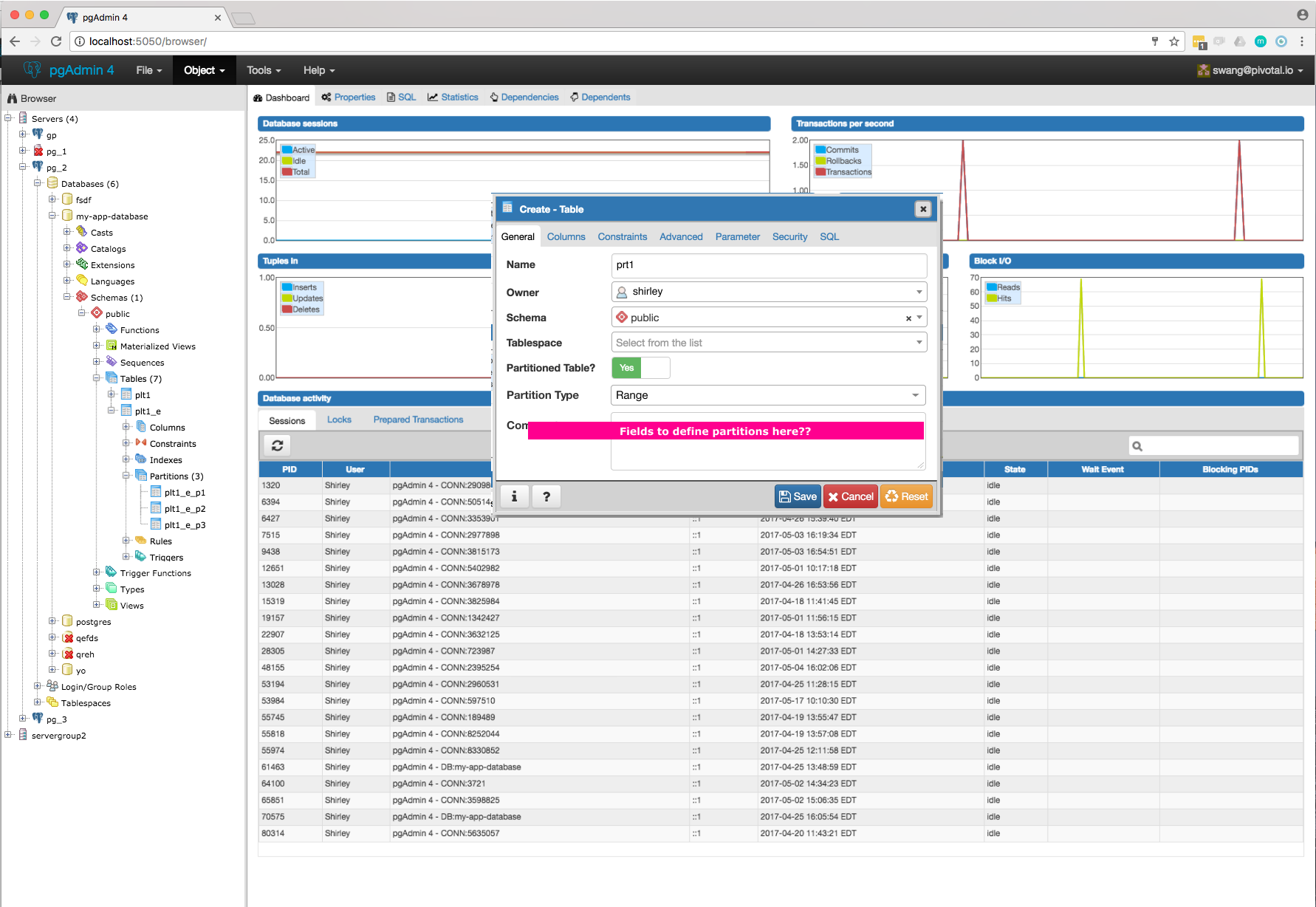
Is this the workflow that you think users are going to engage in given what you're building? Anne mentioned you're in the process of figuring out what's required for defining the partitions, so you'll notice pink boxes with text in areas where that might happen.
The modules that appear for partitioning are based on the ones we saw a few weeks ago, let me know if that has changed in any way.
01 user creates a table, if one doesn't already exist
02 user selects 'yes' for partitioning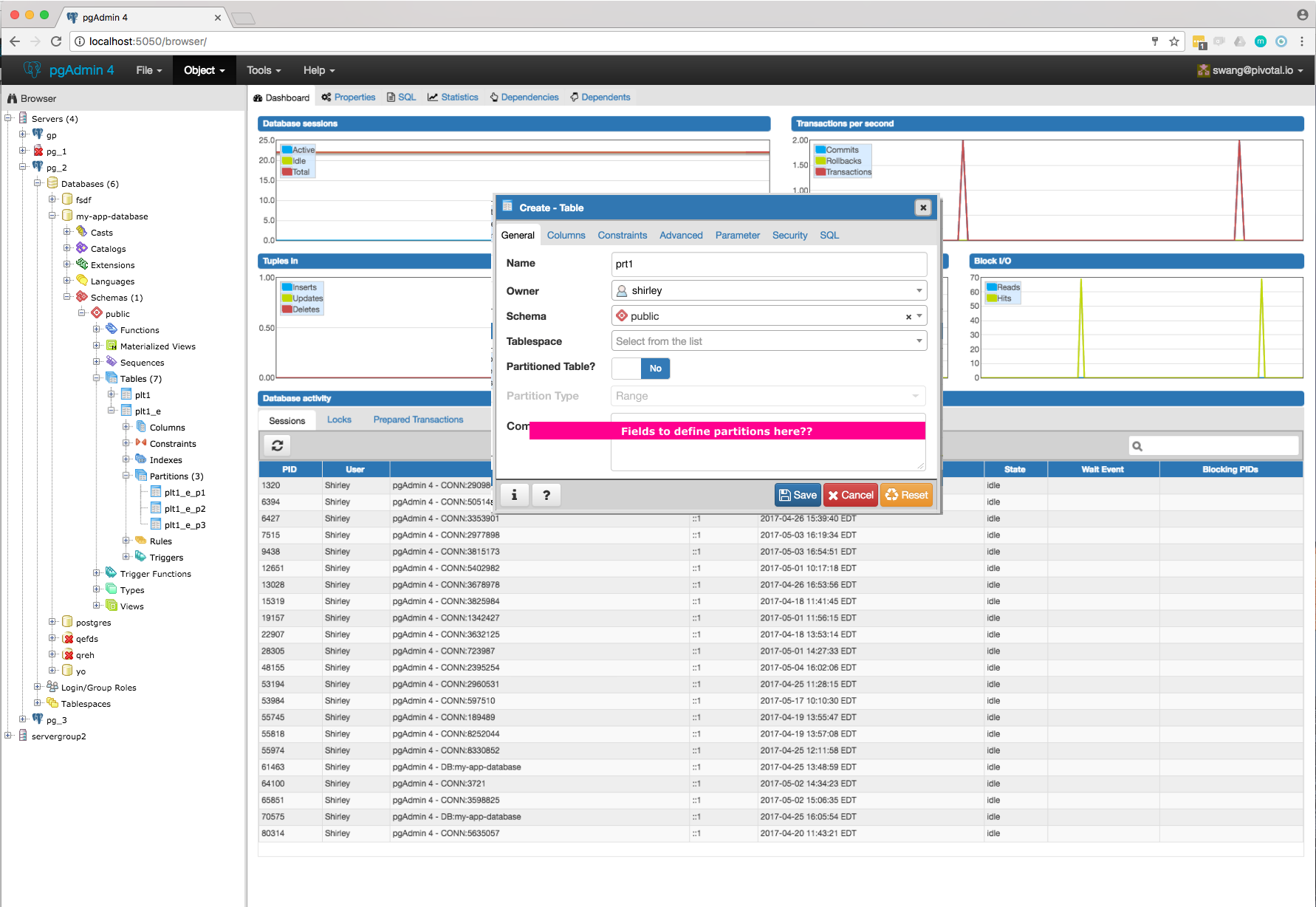
03 user defines type of partition and ranges
04 After hitting submit, browser is updated with new table and partitions, and user is taken to SQL tab. (What is this step for?)
You mentioned Postgres users need to go into individual partitions frequently and its common to have different indexes for each partition. However, I wonder if the naming convention created will provide enough context for people to remember which partition has the specific properties they're looking for. If we imagine a scenario where a user has more than 30 or 40 partitions, and they need to look for one partition, it might be quite time consuming for people to find the right one.
We're trying to find Postgres users to test this flow with, especially since the success of this design relies on users knowing how to interact with the partitions in their browser.
On Thu, May 18, 2017 at 6:41 AM Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AllI have started implementation for Declarative Partitioning in pgAdmin4. Following are the tasks that I have implemented till now:Please let me know above looks good and am I going in right direction.
- Show partitioned table and it's partitions under the parent table. Refer Partitioned_Table.png
- To implement above I have created 'partitions' collection node and 'partition' node under table node which is nothing but table node itself. To reduce redundant/duplicate code I have made following changes:
- Create new file "utils.py" under tables folder. Create a new class BaseTableView(PGChildNodeView): derived from PGChildNodeView. TableView and PartitionsView (new class for partition table) is derived from BaseTableView.
- Move the common logic like dependencies, dependents, reversed engineered sql, statistics, reset statistics in BaseTableView class functions and then call that function from derived class like BaseTableView.get_table_dependencies(self, tid)
- Will move more generic logic as we progress on this task.
- Updated supported nodes list in DataGrid(View Data), Backup, Maintenance, Restore to show context menu for partitions.
- Make sure dependencies, dependents, statistics, truncate, delete/drop and Reset Statistics works with partitions.
- Updated jinja template to show correct reversed engineered sql for partitioned table. Please refer the "List_with_expression.png" for List partition and "Range_with_column_expression.png" for Range partition.
- Updated jinja template to show correct sql for partitions of parent table. Please refer "SQL_Range_Partitions.png" and "SQL_List_Partitions.png". Some R&D is still require for other syntax too.
On Thu, May 11, 2017 at 7:06 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi DaveOn Thu, May 11, 2017 at 6:54 PM, Dave Page <dave.page@enterprisedb.com> wrote:On Thu, May 11, 2017 at 11:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:HiOn Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partition_bound_specis:{ IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here.- Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.Which meeting?Meeting with Shirley, which wasn't schedule last Friday as I was on leave.--Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake----

Attachment
Also, I forgot to mention, these mockups are in Figma: https://www.figma.com/file/RnmYyytaZdjsDHQWrMw5U0co/Create-partition-table?node-id=16%3A54
Feel free to play around and change things :)
On Thu, May 18, 2017 at 11:36 AM Shirley Wang <swang@pivotal.io> wrote:
Hi Akshay!Is this the workflow that you think users are going to engage in given what you're building? Anne mentioned you're in the process of figuring out what's required for defining the partitions, so you'll notice pink boxes with text in areas where that might happen.The modules that appear for partitioning are based on the ones we saw a few weeks ago, let me know if that has changed in any way.01 user creates a table, if one doesn't already exist02 user selects 'yes' for partitioning03 user defines type of partition and ranges04 After hitting submit, browser is updated with new table and partitions, and user is taken to SQL tab. (What is this step for?)You mentioned Postgres users need to go into individual partitions frequently and its common to have different indexes for each partition. However, I wonder if the naming convention created will provide enough context for people to remember which partition has the specific properties they're looking for. If we imagine a scenario where a user has more than 30 or 40 partitions, and they need to look for one partition, it might be quite time consuming for people to find the right one.We're trying to find Postgres users to test this flow with, especially since the success of this design relies on users knowing how to interact with the partitions in their browser.On Thu, May 18, 2017 at 6:41 AM Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllI have started implementation for Declarative Partitioning in pgAdmin4. Following are the tasks that I have implemented till now:Please let me know above looks good and am I going in right direction.
- Show partitioned table and it's partitions under the parent table. Refer Partitioned_Table.png
- To implement above I have created 'partitions' collection node and 'partition' node under table node which is nothing but table node itself. To reduce redundant/duplicate code I have made following changes:
- Create new file "utils.py" under tables folder. Create a new class BaseTableView(PGChildNodeView): derived from PGChildNodeView. TableView and PartitionsView (new class for partition table) is derived from BaseTableView.
- Move the common logic like dependencies, dependents, reversed engineered sql, statistics, reset statistics in BaseTableView class functions and then call that function from derived class like BaseTableView.get_table_dependencies(self, tid)
- Will move more generic logic as we progress on this task.
- Updated supported nodes list in DataGrid(View Data), Backup, Maintenance, Restore to show context menu for partitions.
- Make sure dependencies, dependents, statistics, truncate, delete/drop and Reset Statistics works with partitions.
- Updated jinja template to show correct reversed engineered sql for partitioned table. Please refer the "List_with_expression.png" for List partition and "Range_with_column_expression.png" for Range partition.
- Updated jinja template to show correct sql for partitions of parent table. Please refer "SQL_Range_Partitions.png" and "SQL_List_Partitions.png". Some R&D is still require for other syntax too.
On Thu, May 11, 2017 at 7:06 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi DaveOn Thu, May 11, 2017 at 6:54 PM, Dave Page <dave.page@enterprisedb.com> wrote:On Thu, May 11, 2017 at 11:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:HiOn Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partition_bound_specis:{ IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here.- Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.Which meeting?Meeting with Shirley, which wasn't schedule last Friday as I was on leave.--Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake----Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246

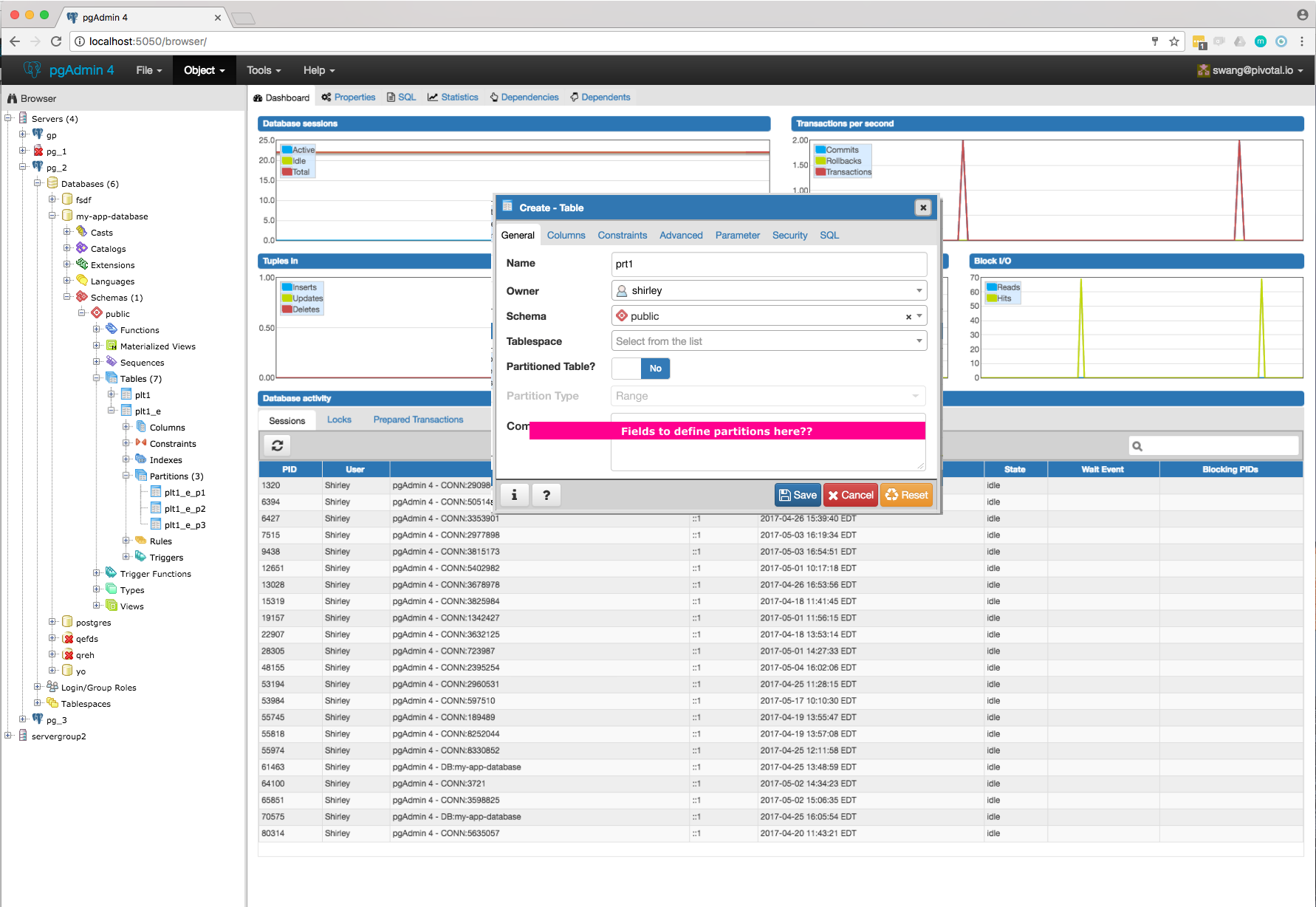
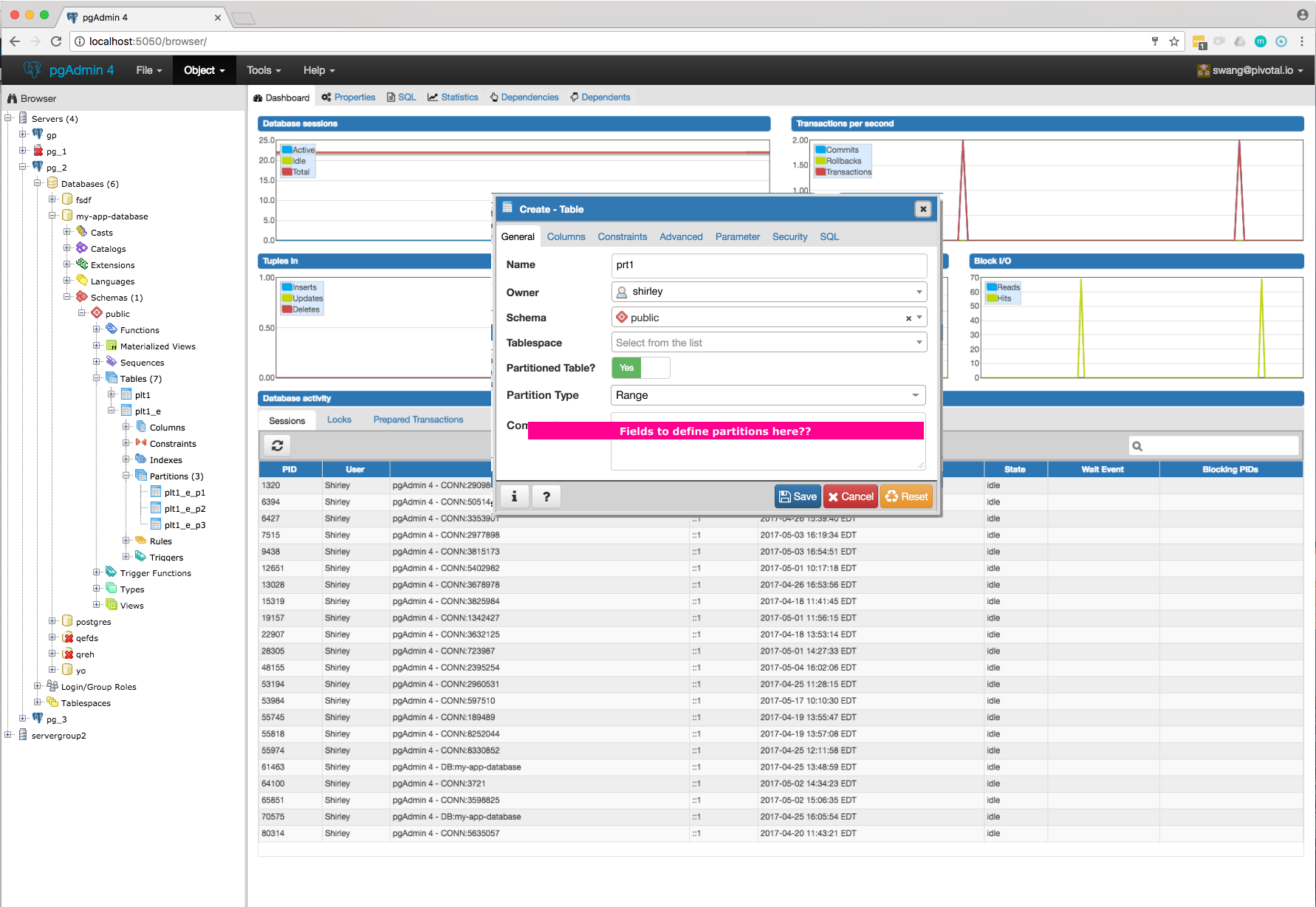
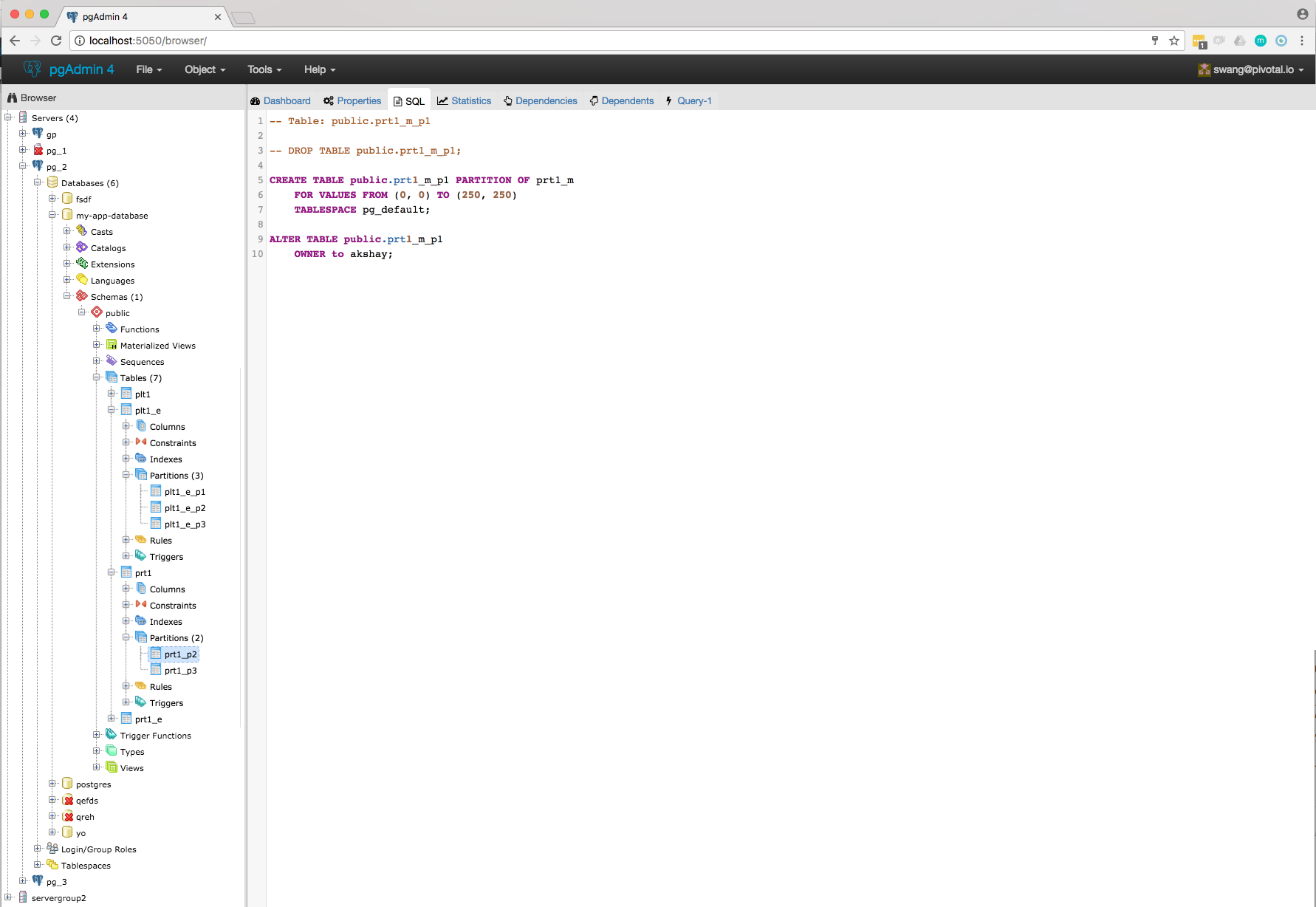
Attachment
Hi Shirley
--
On Thu, May 18, 2017 at 9:06 PM, Shirley Wang <swang@pivotal.io> wrote:
Hi Akshay!Is this the workflow that you think users are going to engage in given what you're building? Anne mentioned you're in the process of figuring out what's required for defining the partitions, so you'll notice pink boxes with text in areas where that might happen.The modules that appear for partitioning are based on the ones we saw a few weeks ago, let me know if that has changed in any way.01 user creates a table, if one doesn't already exist02 user selects 'yes' for partitioning
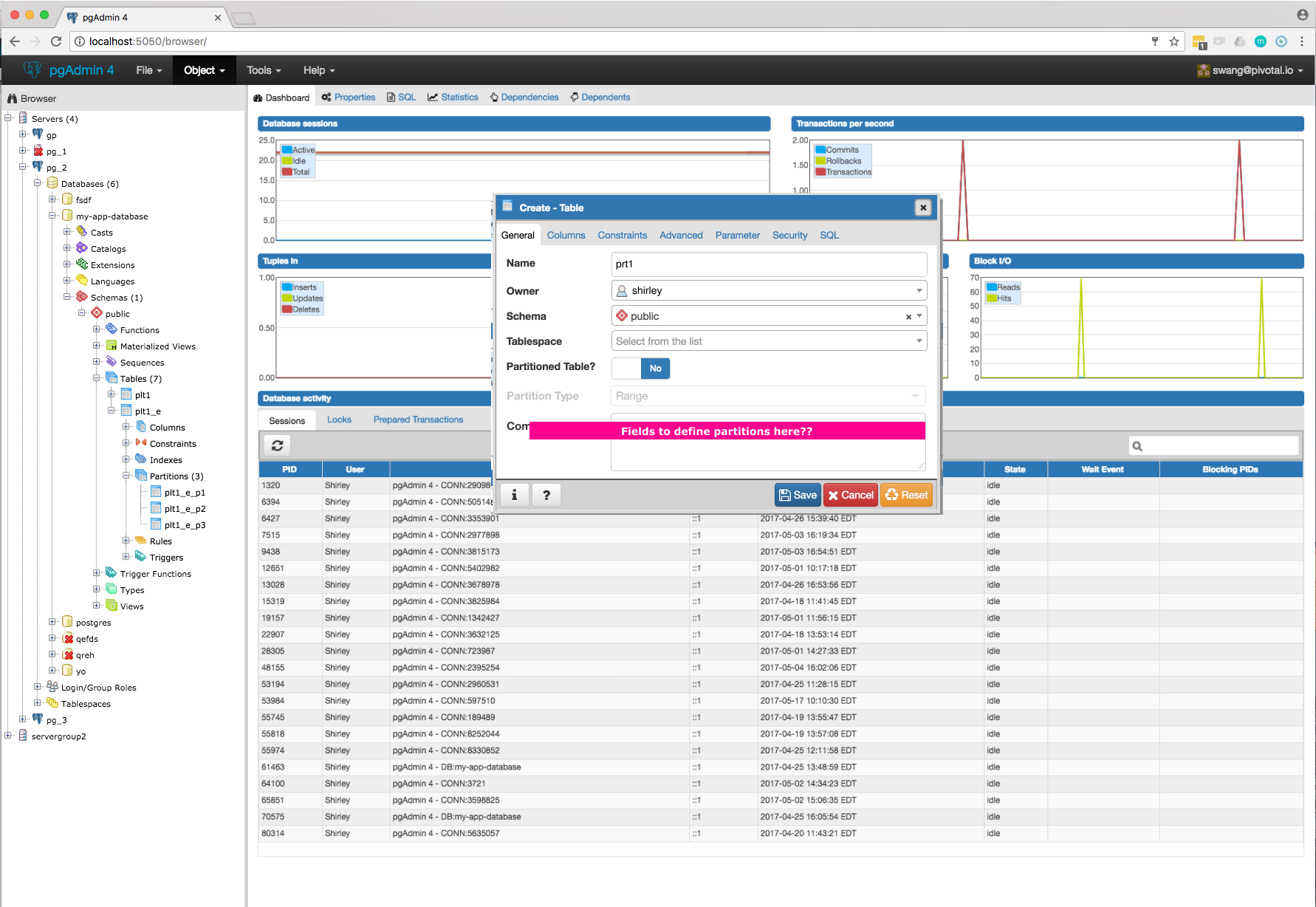
Step 1 and 2 are correct.
03 user defines type of partition and ranges
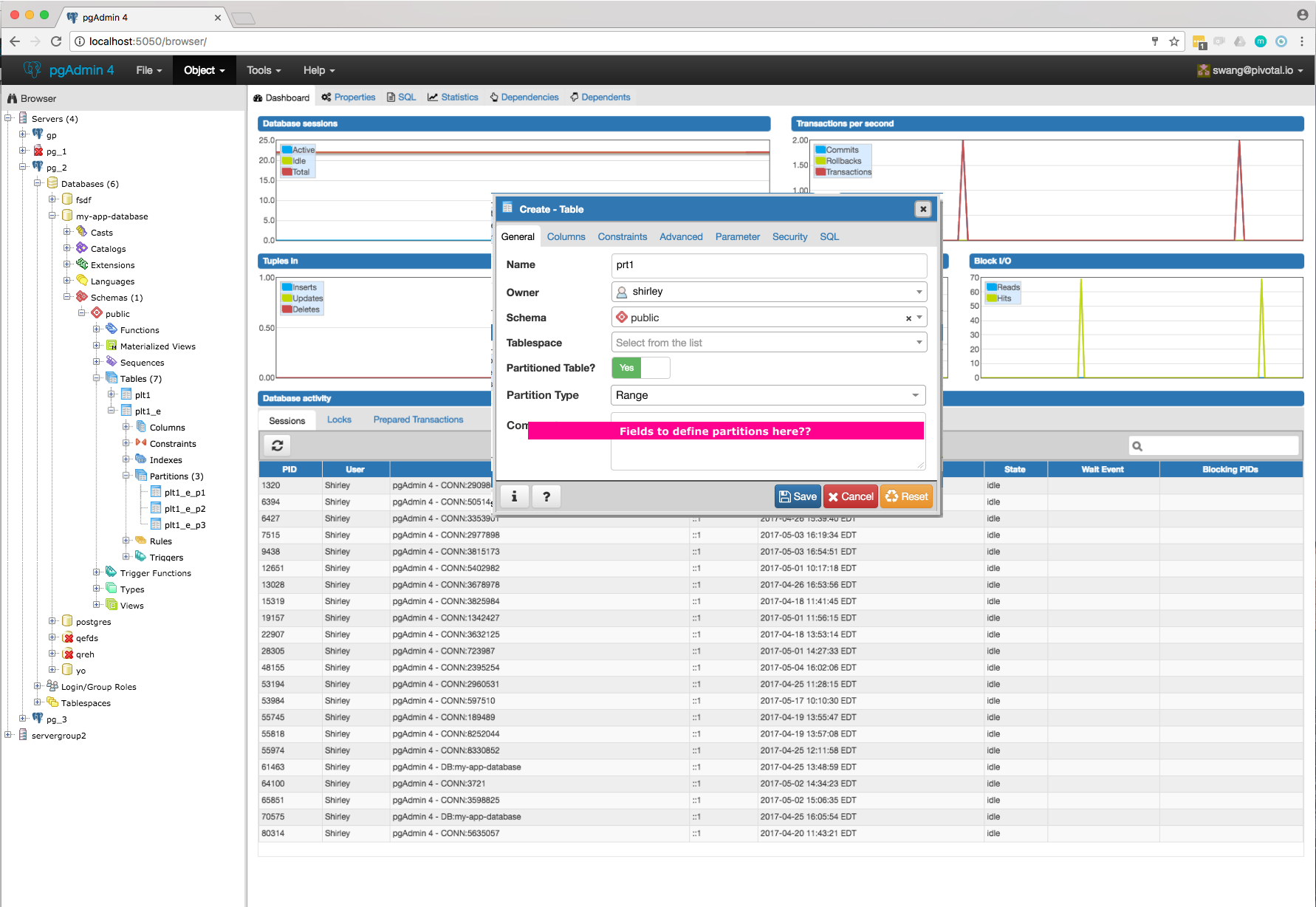
We will create a new tabs "Partitions" and 'Partition Type' combo will go on that tab along with following controls:
- User should be able to specify Key Column(s) (Based on partition type) to create partitioned(parent) table. Some of the examples of list and range partitions are as below:
- CREATE TABLE prt1 (a int, b int, c varchar) PARTITION BY RANGE(a);
- CREATE TABLE prt1_e (a int, b int, c varchar) PARTITION BY RANGE(((a + b)/2));
- CREATE TABLE prt1_m (a int, b int, c varchar) PARTITION BY RANGE(a, ((a + b)/2));
- CREATE TABLE plt1 (a int, b int, c text) PARTITION BY LIST(c);
- CREATE TABLE plt1_e (a int, b int, c text) PARTITION BY LIST(ltrim(c, 'A'));
- CREATE TABLE prt1 (a int, b int, c varchar) PARTITION BY RANGE(a);
- User should be able to create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec partition_bound_spec is:{ IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }
04 After hitting submit, browser is updated with new table and partitions, and user is taken to SQL tab. (What is this step for?)
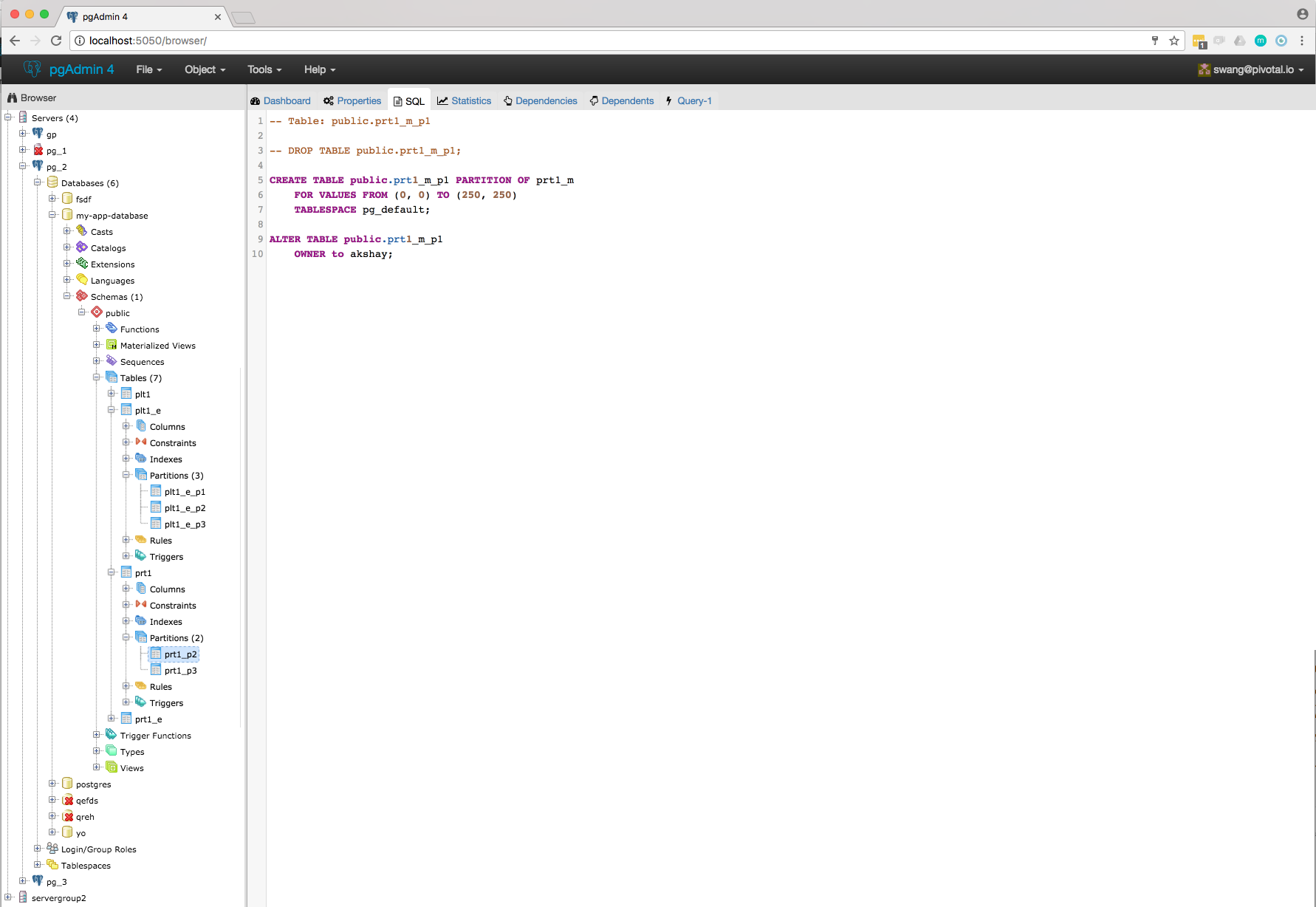
When user click on "OK" button of create table dialog, browser tree will be updated, but i am not sure SQL tab comes in focus, no need of that.
You mentioned Postgres users need to go into individual partitions frequently and its common to have different indexes for each partition. However, I wonder if the naming convention created will provide enough context for people to remember which partition has the specific properties they're looking for. If we imagine a scenario where a user has more than 30 or 40 partitions, and they need to look for one partition, it might be quite time consuming for people to find the right one.
User will provide the name of his/her choice while creating partitions from 'Create Table' dialog, so it's upto the user.
We're trying to find Postgres users to test this flow with, especially since the success of this design relies on users knowing how to interact with the partitions in their browser.Hi AllI have started implementation for Declarative Partitioning in pgAdmin4. Following are the tasks that I have implemented till now:Please let me know above looks good and am I going in right direction.
- Show partitioned table and it's partitions under the parent table. Refer Partitioned_Table.png
- To implement above I have created 'partitions' collection node and 'partition' node under table node which is nothing but table node itself. To reduce redundant/duplicate code I have made following changes:
- Create new file "utils.py" under tables folder. Create a new class BaseTableView(PGChildNod
eView): derived from PGChildNodeView. TableView and PartitionsView (new class for partition table) is derived from BaseTableView. - Move the common logic like dependencies, dependents, reversed engineered sql, statistics, reset statistics in BaseTableView class functions and then call that function from derived class like BaseTableView.get_t
able_dependencies(self, tid) - Will move more generic logic as we progress on this task.
- Updated supported nodes list in DataGrid(View Data), Backup, Maintenance, Restore to show context menu for partitions.
- Make sure dependencies, dependents, statistics, truncate, delete/drop and Reset Statistics works with partitions.
- Updated jinja template to show correct reversed engineered sql for partitioned table. Please refer the "List_with_expression.png" for List partition and "Range_with_column_expression.
png" for Range partition. - Updated jinja template to show correct sql for partitions of parent table. Please refer "SQL_Range_Partitions.png" and "SQL_List_Partitions.png". Some R&D is still require for other syntax too.
On Thu, May 11, 2017 at 7:06 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi DaveOn Thu, May 11, 2017 at 6:54 PM, Dave Page <dave.page@enterprisedb.com> wrote:On Thu, May 11, 2017 at 11:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: HiOn Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partitionis:_bound_spec { IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here. - Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.Which meeting?Meeting with Shirley, which wasn't schedule last Friday as I was on leave.--Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake----Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
On Thu, May 18, 2017 at 11:22 PM, Shirley Wang <swang@pivotal.io> wrote:
Also, I forgot to mention, these mockups are in Figma: https://www.figma.com/file/RnmYyytaZdjsDHQWrMw5U0co/ Create-partition-table?node- id=16%3A54 Feel free to play around and change things :)
Not able to open the above URL. It's 404 when I opened it.
On Thu, May 18, 2017 at 11:36 AM Shirley Wang <swang@pivotal.io> wrote:Hi Akshay!Is this the workflow that you think users are going to engage in given what you're building? Anne mentioned you're in the process of figuring out what's required for defining the partitions, so you'll notice pink boxes with text in areas where that might happen.The modules that appear for partitioning are based on the ones we saw a few weeks ago, let me know if that has changed in any way.01 user creates a table, if one doesn't already exist02 user selects 'yes' for partitioning03 user defines type of partition and ranges04 After hitting submit, browser is updated with new table and partitions, and user is taken to SQL tab. (What is this step for?)You mentioned Postgres users need to go into individual partitions frequently and its common to have different indexes for each partition. However, I wonder if the naming convention created will provide enough context for people to remember which partition has the specific properties they're looking for. If we imagine a scenario where a user has more than 30 or 40 partitions, and they need to look for one partition, it might be quite time consuming for people to find the right one.We're trying to find Postgres users to test this flow with, especially since the success of this design relies on users knowing how to interact with the partitions in their browser.Hi AllI have started implementation for Declarative Partitioning in pgAdmin4. Following are the tasks that I have implemented till now:Please let me know above looks good and am I going in right direction.
- Show partitioned table and it's partitions under the parent table. Refer Partitioned_Table.png
- To implement above I have created 'partitions' collection node and 'partition' node under table node which is nothing but table node itself. To reduce redundant/duplicate code I have made following changes:
- Create new file "utils.py" under tables folder. Create a new class BaseTableView(PGChildNod
eView): derived from PGChildNodeView. TableView and PartitionsView (new class for partition table) is derived from BaseTableView. - Move the common logic like dependencies, dependents, reversed engineered sql, statistics, reset statistics in BaseTableView class functions and then call that function from derived class like BaseTableView.get_
table_dependencies(self, tid) - Will move more generic logic as we progress on this task.
- Updated supported nodes list in DataGrid(View Data), Backup, Maintenance, Restore to show context menu for partitions.
- Make sure dependencies, dependents, statistics, truncate, delete/drop and Reset Statistics works with partitions.
- Updated jinja template to show correct reversed engineered sql for partitioned table. Please refer the "List_with_expression.png" for List partition and "Range_with_column_expression.
png" for Range partition. - Updated jinja template to show correct sql for partitions of parent table. Please refer "SQL_Range_Partitions.png" and "SQL_List_Partitions.png". Some R&D is still require for other syntax too.
On Thu, May 11, 2017 at 7:06 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi DaveOn Thu, May 11, 2017 at 6:54 PM, Dave Page <dave.page@enterprisedb.com> wrote:On Thu, May 11, 2017 at 11:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: HiOn Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partitionis:_bound_spec { IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Designdiscussion required here. - Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.Which meeting?Meeting with Shirley, which wasn't schedule last Friday as I was on leave.--Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake----Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246




Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
On Thu, May 18, 2017 at 11:41 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AllI have started implementation for Declarative Partitioning in pgAdmin4. Following are the tasks that I have implemented till now:Please let me know above looks good and am I going in right direction.
- Show partitioned table and it's partitions under the parent table. Refer Partitioned_Table.png
- To implement above I have created 'partitions' collection node and 'partition' node under table node which is nothing but table node itself. To reduce redundant/duplicate code I have made following changes:
- Create new file "utils.py" under tables folder. Create a new class BaseTableView(PGChildNod
eView): derived from PGChildNodeView. TableView and PartitionsView (new class for partition table) is derived from BaseTableView. - Move the common logic like dependencies, dependents, reversed engineered sql, statistics, reset statistics in BaseTableView class functions and then call that function from derived class like BaseTableView.get_
table_dependencies(self, tid) - Will move more generic logic as we progress on this task.
- Updated supported nodes list in DataGrid(View Data), Backup, Maintenance, Restore to show context menu for partitions.
- Make sure dependencies, dependents, statistics, truncate, delete/drop and Reset Statistics works with partitions.
- Updated jinja template to show correct reversed engineered sql for partitioned table. Please refer the "List_with_expression.png" for List partition and "Range_with_column_expression.
png" for Range partition. - Updated jinja template to show correct sql for partitions of parent table. Please refer "SQL_Range_Partitions.png" and "SQL_List_Partitions.png". Some R&D is still require for other syntax too.
Certainly looks like it to me. We may want to tweak some things based on the work Shirley is doing, but I think we're on the right path.
Good work!
On Thu, May 11, 2017 at 7:06 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi DaveOn Thu, May 11, 2017 at 6:54 PM, Dave Page <dave.page@enterprisedb.com> wrote:On Thu, May 11, 2017 at 11:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: HiOn Thu, May 4, 2017 at 4:00 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Thu, May 4, 2017 at 10:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllOn Wed, May 3, 2017 at 5:35 PM, Dave Page <dpage@pgadmin.org> wrote:Great, thanks.I think it's clear that we need to display the child partitions in the treeview. I don't see any other sensible way of enabling those operations without an extremely contrived dialogue design.Please now document how those features will be implemented; e.g, for each one:- View table data: Parent and partition context menu.- Attach/detach partitions: Parent properties dialogue...That will then give us a list of places we'll need to (re)design dialogues and menus etc. for.As per my knowledge on Partitioning, I think we will have to implement following things in parent and child:Parent:Child:
- View Table data : No need to change any logic, it's working.
- Correct jinja template to show correct SQL in SQL pane.
- Create partitioned table -
- Add one switch control ("Partitioned Table?") in General tab of Table dialog.
- Add new tab "Partitions".
- Add one select2 control (Partition Type :Range/List) in "Partitions" tab.
- Create one subnode control to specify number of key columns with expressions. For List partition only one row will be there + button will be disabled, and for Range partition + button will be enabled. Here is the syntax as per documentation [ PARTITION BY { RANGE | LIST } ( { column_name | ( expression ) } [ COLLATE collation ] [ opclass ] [, ... ] ) ]. Design discussion required here for how user will specify expression, collate and opclass.
- Create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partitionis:_bound_spec { IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) }- Design discussion required here for how user will specify all the above combinations.
- Properties dialog "Partitions" Tab:
- Partition Type control must be disabled.
- User will be able to create/modify existing partitions. User won't be able to delete partitions as there are two modes Detach/Drop and we will have separate menu for it.
- Drop/ Drop cascade, Truncate: No need to change any logic, it's working.
- Attach Partitions: Create context menu on partitioned table. When user clicks, open one dialog with some controls to provide table(to be attach) and partition_bound_spec
. Design discussion required here. - Not able to create constraints excluding check constraint: We will have to disable context menu, remove child nodes from browser tree for constraints and disable controls from the dialog.
Apart from above it may be possible that I miss something, so we need to cover that too.
- View Table Data: Add context menu.
- Detach partition: Create context menu, when user click popped up confirmation message box.
- View partition scheme in SQL pane: Changes required in jinja template.
- Create primary/foreign/.. key constraint: No need to change any logic on GUI, but may need to change queries to fetch the partitioned tables.
- Drop/ Drop cascade, Truncate: No need to change any logic.
OK, good. So now, let's break that down into a list of tasks, that we can prioritise with Shirley. The initial list should be prioritised based on your understanding I think, given the following criteria:- Changes that prevent pgAdmin breaking- Changes that prevent pgAdmin showing incorrect data/info- Changes that enable pgAdmin to show correct info- Changes that add functionality for creating/dropping partitioned tables as one unit- Changes that add functionality for modifying individual partitions independentlyPlease document the requirements and initial plan on the pgAdmin Redmine Wiki.I have updated Redmine Wiki page regarding what needs to be implemented for partitioning. Can we discuss prioritisation of the task based on above criteria in the our meeting. Meanwhile I have started working on showing correct SQL for partitioned table.Which meeting?Meeting with Shirley, which wasn't schedule last Friday as I was on leave.--Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake----
Dave Page
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
VP, Chief Architect, Tools & Installers
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
On Fri, May 19, 2017 at 2:19 AM Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
On Thu, May 18, 2017 at 11:22 PM, Shirley Wang <swang@pivotal.io> wrote:Also, I forgot to mention, these mockups are in Figma: https://www.figma.com/file/RnmYyytaZdjsDHQWrMw5U0co/Create-partition-table?node-id=16%3A54Feel free to play around and change things :)Not able to open the above URL. It's 404 when I opened it.
Whoops. I just sent you an invite for edit access.
For the rest of the community, here's a link for view access: https://www.figma.com/file/RnmYyytaZdjsDHQWrMw5U0co/Create-partition-table
Attachment
Hi All
As continuation I have worked on "Partition" Tab and added some controls where user will be able to specify the key columns and create N number of partitions:
- Added Partition Type combo box where user will define the Type(Range/List)
- "Partition Keys" subnode control where there is combo box to specify it is column or expression. If it is column then on expanding subnode control all the columns specified to create main table will be listed here. User won't be able to select multiple columns here. If it is expression then user will be able to specify correct expression with correct parenthesis. In case of List partition only one row will be allowed.
- "Partitions" control is used to create N number of partitions. In case of Range partition there are three columns "Name", "Value From" and "Value To". If partition key is combination of multiple columns or combination of column and expression then user will have to provide (,) comma separated values. Refer "Range_Partition.png". In case of List partition there are two columns "Name" and "Values In" and user will have to provide (,) separated list for "Values In" column. Refer "List_Partition.png".
- Once user will define the partition keys and partitions based on the columns define for main table and then user will rename/delete any column from "Columns" Tab we will warn user about renaming/deleting any column will reset all the rows define under partitions tab. This is just because we can rename/delete the column from partition keys but not sure how we can remove/rename it from the expression defined by the user.
- Major challenge here is while creating partitions(second subnode control in attached image) according to the documentation user will be able to create constraints( Primary, Foreign, Unique...). How user will be able to add constraints from GUI? Do we need to implement a new control where one subnode control contains the whole "Constraints" Tab or any other solution.
Please review it. Suggestions/Comments are welcome.
On Fri, May 19, 2017 at 11:03 PM, Shirley Wang <swang@pivotal.io> wrote:
Hi ShirleyOn Thu, May 18, 2017 at 9:06 PM, Shirley Wang <swang@pivotal.io> wrote:Hi Akshay!Is this the workflow that you think users are going to engage in given what you're building? Anne mentioned you're in the process of figuring out what's required for defining the partitions, so you'll notice pink boxes with text in areas where that might happen.The modules that appear for partitioning are based on the ones we saw a few weeks ago, let me know if that has changed in any way.01 user creates a table, if one doesn't already exist02 user selects 'yes' for partitioningStep 1 and 2 are correct.03 user defines type of partition and rangesWe will create a new tabs "Partitions" and 'Partition Type' combo will go on that tab along with following controls:
- User should be able to specify Key Column(s) (Based on partition type) to create partitioned(parent) table. Some of the examples of list and range partitions are as below:
- CREATE TABLE prt1 (a int, b int, c varchar) PARTITION BY RANGE(a);
- CREATE TABLE prt1_e (a int, b int, c varchar) PARTITION BY RANGE(((a + b)/2));
- CREATE TABLE prt1_m (a int, b int, c varchar) PARTITION BY RANGE(a, ((a + b)/2));
- CREATE TABLE plt1 (a int, b int, c text) PARTITION BY LIST(c);
- CREATE TABLE plt1_e (a int, b int, c text) PARTITION BY LIST(ltrim(c, 'A'));
- User should be able to create N number of partitions:
- Design one control (subnode control) so that user will add N number of partitions. Here is the syntax as per documentation CREATE TABLE table_name PARTITION OF parent_table [ ( { column_name [ WITH OPTIONS ] [ column_constraint [ ... ] ] | table_constraint } [, ... ] ) ] FOR VALUES partition_bound_spec
partition_bound_spec is:{ IN ( { bound_literal | NULL } [, ...] ) | FROM ( { bound_literal | UNBOUNDED } [, ...] ) TO ( { bound_literal | UNBOUNDED } [, ...] ) } Design(GUI) discussion required for above two, which control should we used so that user will be easily able to create N number of partitions.
Ok. Hopefully we'll get some interviews set up for next week that'll help us determine the best workflow for this.


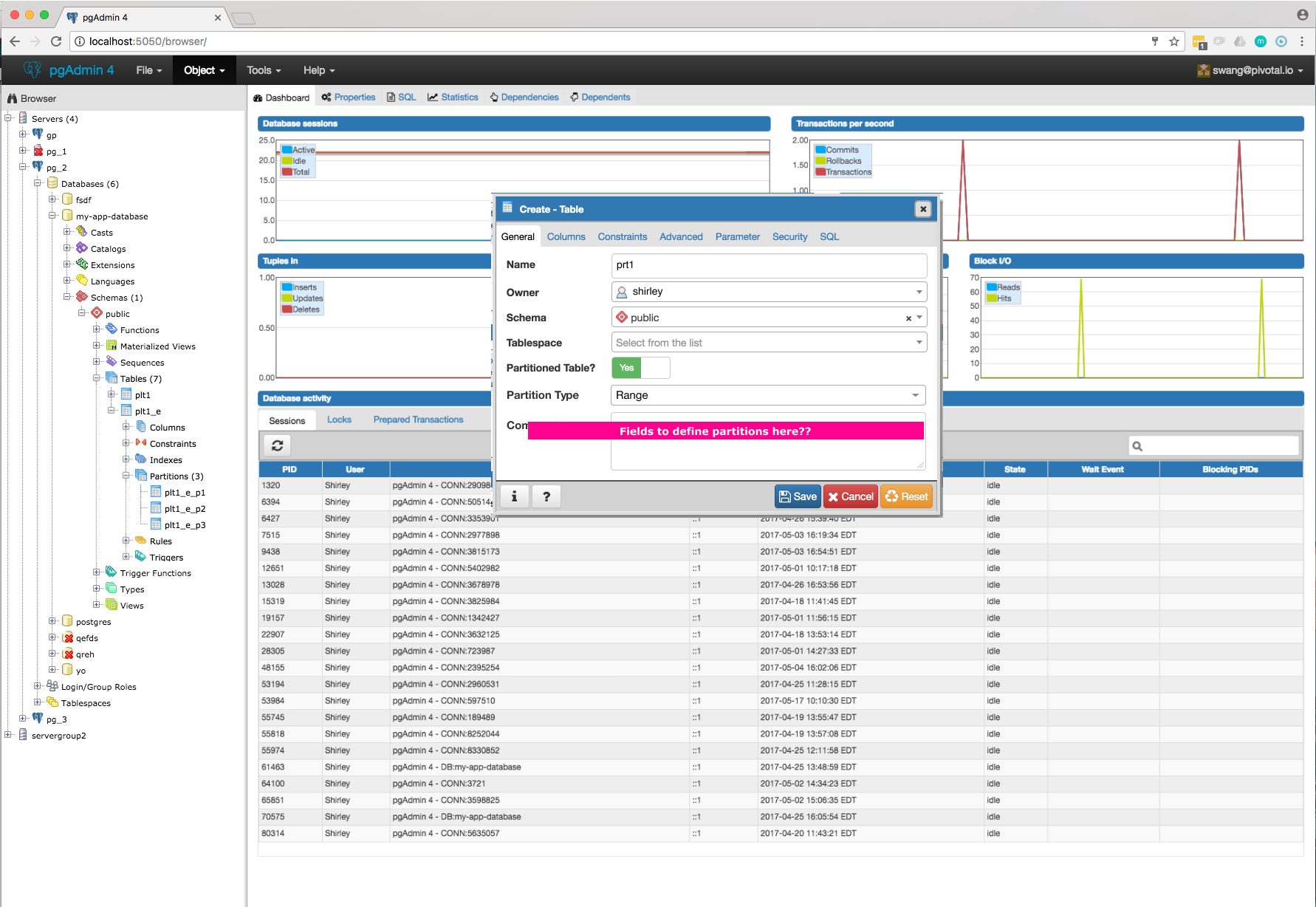
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
On Mon, May 22, 2017 at 5:28 AM Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AllAs continuation I have worked on "Partition" Tab and added some controls where user will be able to specify the key columns and create N number of partitions:
- Added Partition Type combo box where user will define the Type(Range/List)
- "Partition Keys" subnode control where there is combo box to specify it is column or expression. If it is column then on expanding subnode control all the columns specified to create main table will be listed here. User won't be able to select multiple columns here. If it is expression then user will be able to specify correct expression with correct parenthesis. In case of List partition only one row will be allowed.
To get out an MVP, perhaps we should focus on just establishing a partition for a single range and list, then figure out how an expression would work. It seems like the majority of use cases for using a range partition would be by date so let's get that functionality working and worry about expressions once we have live feedback to minimize risk (excess time spent developing features with many unknowns about user behavior)
- "Partitions" control is used to create N number of partitions. In case of Range partition there are three columns "Name", "Value From" and "Value To". If partition key is combination of multiple columns or combination of column and expression then user will have to provide (,) comma separated values. Refer "Range_Partition.png". In case of List partition there are two columns "Name" and "Values In" and user will have to provide (,) separated list for "Values In" column. Refer "List_Partition.png".
Here's a sketch of what a single range would look like:
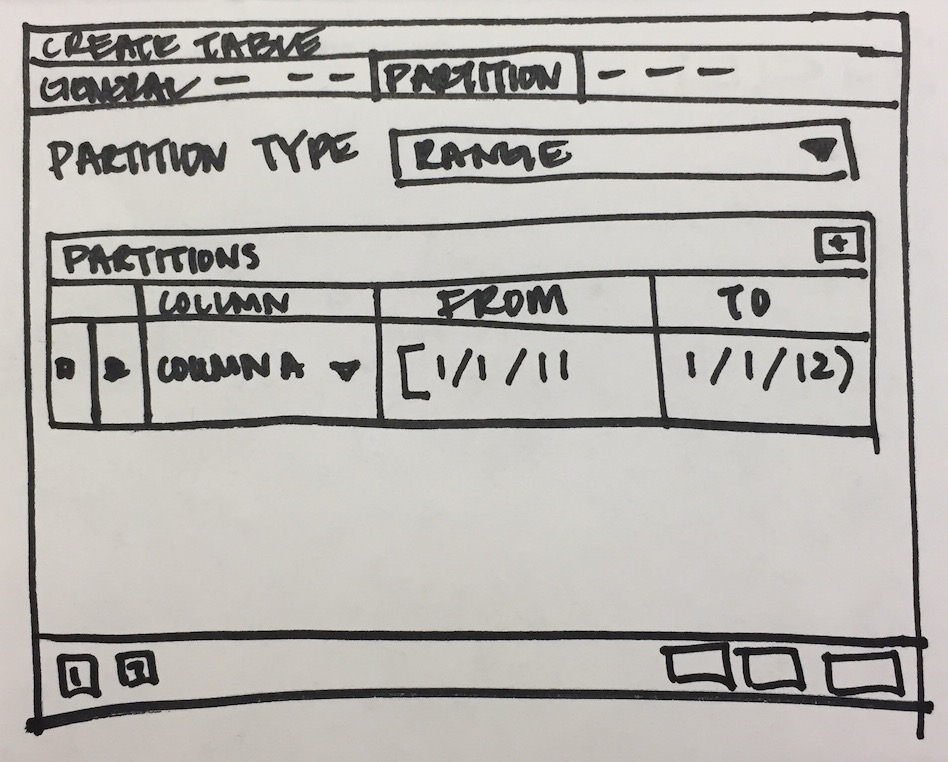
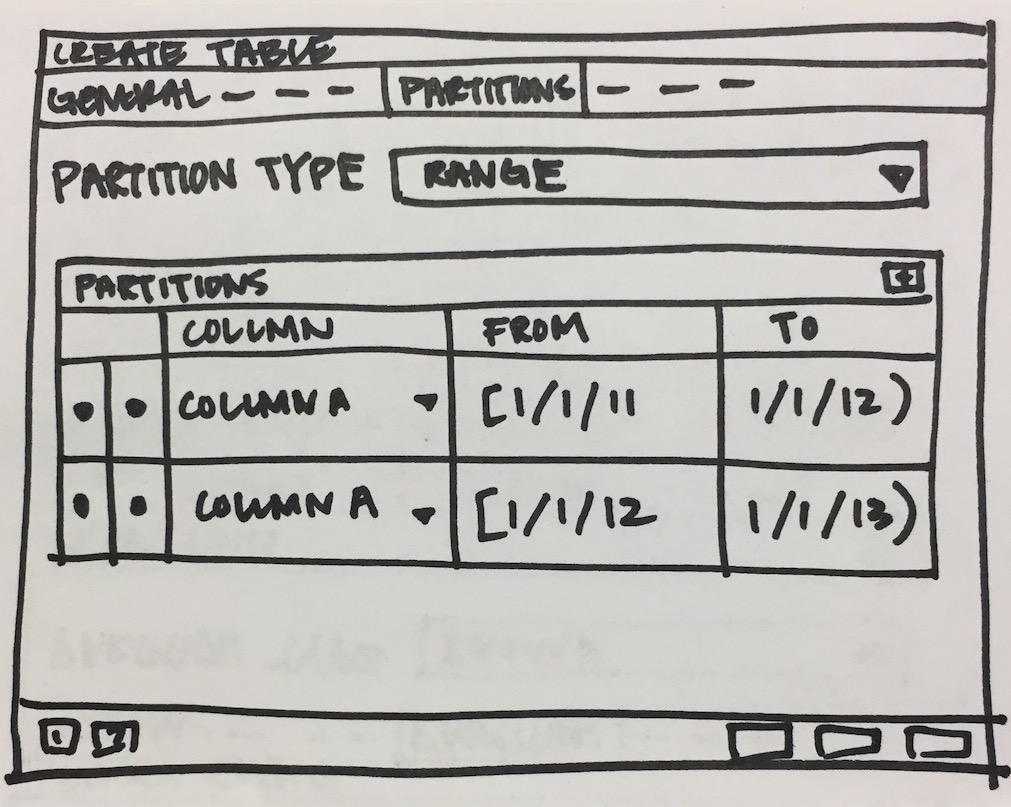
Note: Apart from above there are following that needs to be taken care:
- Once user will define the partition keys and partitions based on the columns define for main table and then user will rename/delete any column from "Columns" Tab we will warn user about renaming/deleting any column will reset all the rows define under partitions tab. This is just because we can rename/delete the column from partition keys but not sure how we can remove/rename it from the expression defined by the user.
That's fine, as long as they are still able to do so after a warning.
- Major challenge here is while creating partitions(second subnode control in attached image) according to the documentation user will be able to create constraints( Primary, Foreign, Unique...). How user will be able to add constraints from GUI? Do we need to implement a new control where one subnode control contains the whole "Constraints" Tab or any other solution.
We can probably leverage the same table. We're investigating constraints as well.
Shirley & Rob
Attachment
On Tue, May 23, 2017 at 2:59 AM, Shirley Wang <swang@pivotal.io> wrote:
Hi AllAs continuation I have worked on "Partition" Tab and added some controls where user will be able to specify the key columns and create N number of partitions:
- Added Partition Type combo box where user will define the Type(Range/List)
- "Partition Keys" subnode control where there is combo box to specify it is column or expression. If it is column then on expanding subnode control all the columns specified to create main table will be listed here. User won't be able to select multiple columns here. If it is expression then user will be able to specify correct expression with correct parenthesis. In case of List partition only one row will be allowed.
To get out an MVP, perhaps we should focus on just establishing a partition for a single range and list, then figure out how an expression would work. It seems like the majority of use cases for using a range partition would be by date so let's get that functionality working and worry about expressions once we have live feedback to minimize risk (excess time spent developing features with many unknowns about user behavior)
I personally think it is not that difficult to implement expressions we just need to get the value given by user and create proper SQL to create the table. For example User will create one partitioned table with three columns a,b and c. from partitions key control user will select first row as column (a) and second row as expression ((a+b)/2) so we will have to create table with "PARTITION BY RANGE (a, ((a+b)/2)". I think we should consider this as well.
- "Partitions" control is used to create N number of partitions. In case of Range partition there are three columns "Name", "Value From" and "Value To". If partition key is combination of multiple columns or combination of column and expression then user will have to provide (,) comma separated values. Refer "Range_Partition.png". In case of List partition there are two columns "Name" and "Values In" and user will have to provide (,) separated list for "Values In" column. Refer "List_Partition.png".
Here's a sketch of what a single range would look like:Note: Apart from above there are following that needs to be taken care:
- Once user will define the partition keys and partitions based on the columns define for main table and then user will rename/delete any column from "Columns" Tab we will warn user about renaming/deleting any column will reset all the rows define under partitions tab. This is just because we can rename/delete the column from partition keys but not sure how we can remove/rename it from the expression defined by the user.
That's fine, as long as they are still able to do so after a warning.
- Major challenge here is while creating partitions(second subnode control in attached image) according to the documentation user will be able to create constraints( Primary, Foreign, Unique...). How user will be able to add constraints from GUI? Do we need to implement a new control where one subnode control contains the whole "Constraints" Tab or any other solution.
We can probably leverage the same table. We're investigating constraints as well.Shirley & Rob


Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
It's less about implementing what's easy, and more about implementing what we know for sure will provide user value.
Given that in the expression you used, the variables 'a' and 'b' have undefined values, there's still a chance that we're missing a large chunk of context for successful implementation.
Could you explain what 'a' and 'b' represent?
Where would users find values for 'a' and 'b'? (are they columns?)
What is the use case for partitioning by (a+b)/2?
How frequently will people partition this way?
It's possible to design for the range and list partitions and know we can achieve success because we understand how users would go through this workflow. Not sure about expressions.
Attachment
On Tue, May 23, 2017 at 10:09 AM, Shirley Wang <swang@pivotal.io> wrote:
It's possible to design for the range and list partitions and know we can achieve success because we understand how users would go through this workflow. Not sure about expressions.
Maybe to pile on this a bit.
When Shirley and I were discussing the workflows it was obvious when we were looking at 'normal' range or list partition use cases. Generally the only open question we had about the workflow was whether or not users would be building tables net new or whether they were more likely to have a table that was growing too large and therefore needed to create a new partitioned table.
We couldn't think of a reason why a user would want to take the average of two columns and partition by this derived value. It added to the question of why/how a user would consider this as an idea a priori or whether this would be an insight given analysis of existing data.
I assume this was supported for a specific use case. if you could share that it would be awesome. I guess the long and short of it is, we are having a difficult time imagining the workflow for this feature.
-- Rob
Hi Shirley
--
On Tue, May 23, 2017 at 7:39 PM, Shirley Wang <swang@pivotal.io> wrote:
It's less about implementing what's easy, and more about implementing what we know for sure will provide user value.
Agreed, but if that feature(expression) is available in postgresql then users/QA will ask why that is not present in pgAdmin4. If implementation is complex then we could think to include it or not, if we will provide that its upto the user they want to use it or not.
Given that in the expression you used, the variables 'a' and 'b' have undefined values, there's still a chance that we're missing a large chunk of context for successful implementation.
Could you explain what 'a' and 'b' represent?
Where would users find values for 'a' and 'b'? (are they columns?)
a and b are columns.
What is the use case for partitioning by (a+b)/2?
How frequently will people partition this way?
That is just an example of expression, there is no use case for above example.
It's possible to design for the range and list partitions and know we can achieve success because we understand how users would go through this workflow. Not sure about expressions.
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Hi Robert
--
On Tue, May 23, 2017 at 8:09 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:
On Tue, May 23, 2017 at 10:09 AM, Shirley Wang <swang@pivotal.io> wrote:It's possible to design for the range and list partitions and know we can achieve success because we understand how users would go through this workflow. Not sure about expressions.Maybe to pile on this a bit.When Shirley and I were discussing the workflows it was obvious when we were looking at 'normal' range or list partition use cases. Generally the only open question we had about the workflow was whether or not users would be building tables net new or whether they were more likely to have a table that was growing too large and therefore needed to create a new partitioned table.We couldn't think of a reason why a user would want to take the average of two columns and partition by this derived value. It added to the question of why/how a user would consider this as an idea a priori or whether this would be an insight given analysis of existing data.I assume this was supported for a specific use case. if you could share that it would be awesome. I guess the long and short of it is, we are having a difficult time imagining the workflow for this feature.
Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
Partitions based on first letter of their username
CREATE TABLE users (
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');
-- Rob
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');
Thank you for the example, you are absolutely correct and we were confused.
Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.
I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.
-- Rob
Hi All
Following are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:
On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)
--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob
--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi!
Here's a summary of the interviews thus far:
DBAs tend to create a partition strategy based on their experience and some alignment on their end users goals (analysts, report writers, and app developers). Once that partition strategy is created, they are usually forced to iterate on that strategy later based on feedback from end users of what the usage pattern are.
We've identified a couple workflows that are key in partitioning based on whether they are maintaining a successful strategy or iterating to improve the strategy.
One workflow is for rollups, which is for maintaining partitions at different granularities as data ages. We've learned that older data is less acted upon than recent data so users group together older data for viewing purposes. The other workflow is for splits, which when users discover that the data isn't granular enough so a single partition is being leveraged too many times. Users need to then reevaluate their strategy and tune partitions.
To reevaluate strategies, DBAs ask themselves a few questions
- Is the partition stable?
- Are the queries analysts, report writers, and app developers are writing getting the correct data?
- Are the partitions organized in a way that analysts, report writers, and app developers are able to achieve their goals? (ex. goals for app developer might be fast query while goal for report writer might be ability to get data so they can turn out reports faster. Goals might be conflicting)
There are two needs from DBAs in terms of tuning partitioning strategies (there are more but addressing these two will provide the most value to users). One is to modify one or more child partitions by adding indexes or other such things, and the other is to recreate the parent table because there is inheritance to consider.
For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.
On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:
On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers--Dave Page
Hi
--
On Mon, Jun 5, 2017 at 4:34 PM, Shirley Wang <swang@pivotal.io> wrote:
Hi!Here's a summary of the interviews thus far:DBAs tend to create a partition strategy based on their experience and some alignment on their end users goals (analysts, report writers, and app developers). Once that partition strategy is created, they are usually forced to iterate on that strategy later based on feedback from end users of what the usage pattern are.We've identified a couple workflows that are key in partitioning based on whether they are maintaining a successful strategy or iterating to improve the strategy.One workflow is for rollups, which is for maintaining partitions at different granularities as data ages. We've learned that older data is less acted upon than recent data so users group together older data for viewing purposes. The other workflow is for splits, which when users discover that the data isn't granular enough so a single partition is being leveraged too many times. Users need to then reevaluate their strategy and tune partitions.To reevaluate strategies, DBAs ask themselves a few questions- Is the partition stable?- Are the queries analysts, report writers, and app developers are writing getting the correct data?- Are the partitions organized in a way that analysts, report writers, and app developers are able to achieve their goals? (ex. goals for app developer might be fast query while goal for report writer might be ability to get data so they can turn out reports faster. Goals might be conflicting)There are two needs from DBAs in terms of tuning partitioning strategies (there are more but addressing these two will provide the most value to users). One is to modify one or more child partitions by adding indexes or other such things, and the other is to recreate the parent table because there is inheritance to consider.
The former is what I was bleating about when I said we needed to expose partitions to the user. The latter isn't relevant - declarative partitioning in Postgres doesn't use inheritance.
So... it sounds like we're on the right lines :-)
For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, Jun 5, 2017 at 11:45 AM, Dave Page <dpage@pgadmin.org> wrote:
The former is what I was bleating about when I said we needed to expose partitions to the user. The latter isn't relevant - declarative partitioning in Postgres doesn't use inheritance.
The former is certainly the most interesting. We do need to expose the partitions but only exposing them individually might be a bit overwhelming. What we found was that the number of partitions users have, (given existing means of leveraging partitions) vary from ~100 up to 10k. Basically what we were thinking about was how we can create a workflow/interface that allows users to modify one or more children at once. Furthermore, it would be nice if we could figure out an easy (easy-ish) way for users to identify the one or more partitions that need to be modified.
For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.
For other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.
-- Rob
So... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
I guess what I didn't say is YES. What Akshay and Ashesh are building is going to absolutely be fundamental to any workflows being defined in these interviews.
-- Rob
On Mon, Jun 5, 2017 at 12:17 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:
On Mon, Jun 5, 2017 at 11:45 AM, Dave Page <dpage@pgadmin.org> wrote:The former is what I was bleating about when I said we needed to expose partitions to the user. The latter isn't relevant - declarative partitioning in Postgres doesn't use inheritance.The former is certainly the most interesting. We do need to expose the partitions but only exposing them individually might be a bit overwhelming. What we found was that the number of partitions users have, (given existing means of leveraging partitions) vary from ~100 up to 10k. Basically what we were thinking about was how we can create a workflow/interface that allows users to modify one or more children at once. Furthermore, it would be nice if we could figure out an easy (easy-ish) way for users to identify the one or more partitions that need to be modified.For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.For other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, Jun 5, 2017 at 5:17 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:
On Mon, Jun 5, 2017 at 11:45 AM, Dave Page <dpage@pgadmin.org> wrote:The former is what I was bleating about when I said we needed to expose partitions to the user. The latter isn't relevant - declarative partitioning in Postgres doesn't use inheritance.The former is certainly the most interesting. We do need to expose the partitions but only exposing them individually might be a bit overwhelming. What we found was that the number of partitions users have, (given existing means of leveraging partitions) vary from ~100 up to 10k. Basically what we were thinking about was how we can create a workflow/interface that allows users to modify one or more children at once. Furthermore, it would be nice if we could figure out an easy (easy-ish) way for users to identify the one or more partitions that need to be modified.
Yes, that does need more thought.
For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.
You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.
Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.
For other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.
Right.
-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:
For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.
No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.
-- Rob
For other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi All
--
For further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))
When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);
Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?
One option could be
Tables
->measurement(table)
->Partitions
->measurement_y2006(Partition of measurement and parent of p1)
->Partitions
->p1
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.
Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:
On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
Akshay,
Have you determined the minimum feature set you are shooting for before you commit this? The reason I ask is that we were thinking that some level of simple automation would probably be nice to make this super useful.
Basically if you consider a simple example of partitioning 90 days of data by day the manual process of creating the names and to - from fields becomes rather painful. If you couple that with potentially wanting to do list subpartitioning if just multiplies the work.
If we could get something committed then we could more easily work to define where simple automation makes sense and where it doesn't.
-- Rob
On Tue, Jun 13, 2017 at 6:59 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)To achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--
To add some interview context - from talking to DBAs, partitioning is the most frequent use case we should account for first. Breaking down child partitions into smaller pieces wasn't something we heard as a need. This is probably not the highest priority work needed now.
We should think about when it would be good to release partitioning for some feedback. Did you already have this planned out?
On Tue, Jun 13, 2017 at 9:46 AM Robert Eckhardt <reckhardt@pivotal.io> wrote:
Akshay,Have you determined the minimum feature set you are shooting for before you commit this? The reason I ask is that we were thinking that some level of simple automation would probably be nice to make this super useful.
Basically if you consider a simple example of partitioning 90 days of data by day the manual process of creating the names and to - from fields becomes rather painful. If you couple that with potentially wanting to do list subpartitioning if just multiplies the work.If we could get something committed then we could more easily work to define where simple automation makes sense and where it doesn't.-- RobOn Tue, Jun 13, 2017 at 6:59 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)To achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers--Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--
Some questions/comments/sketches:
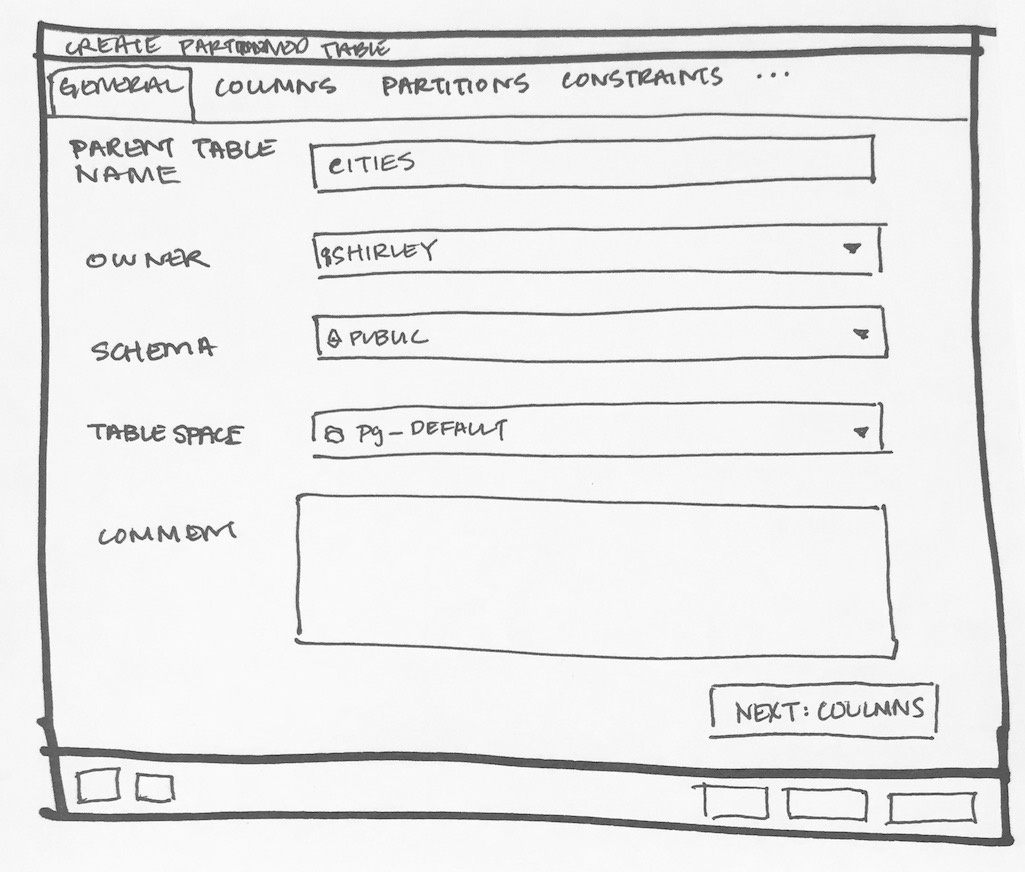
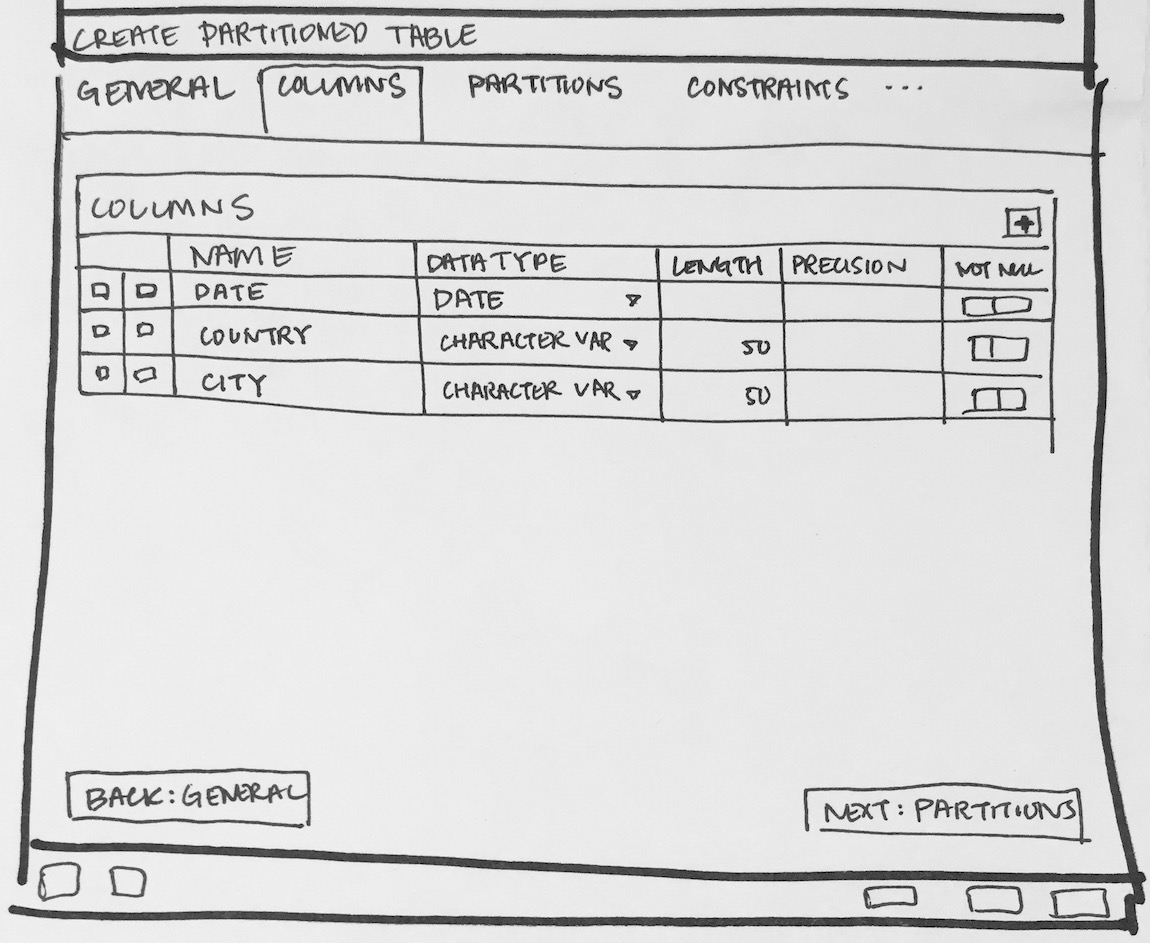
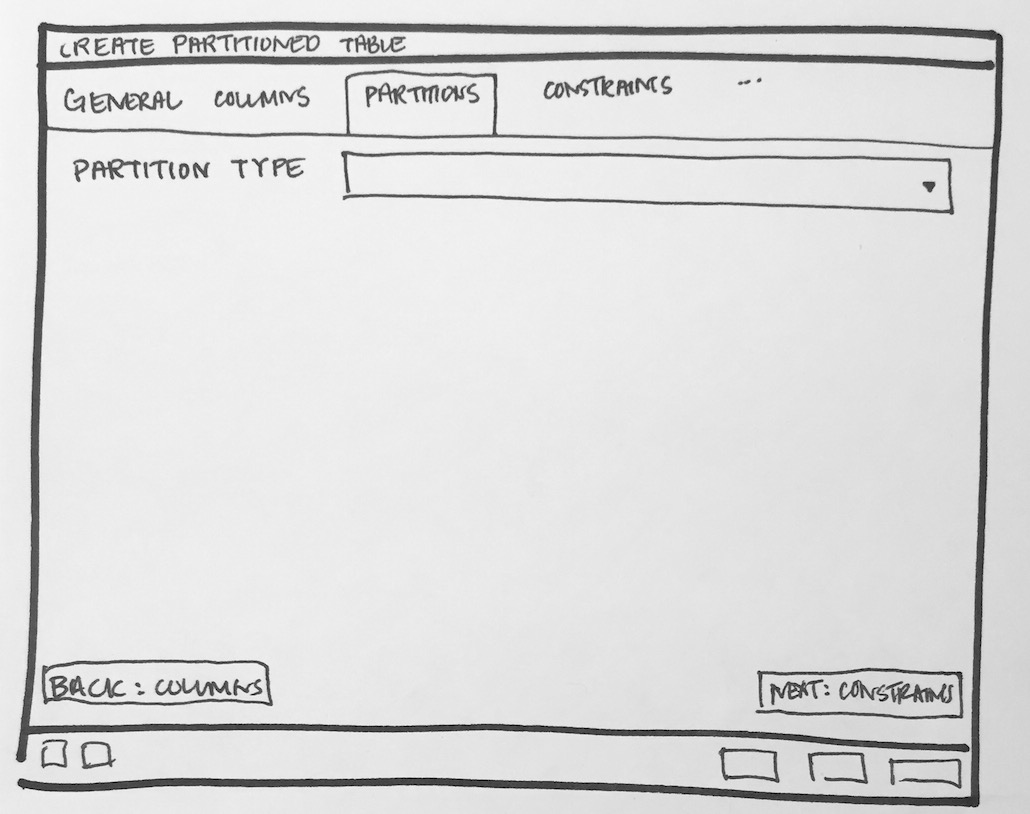
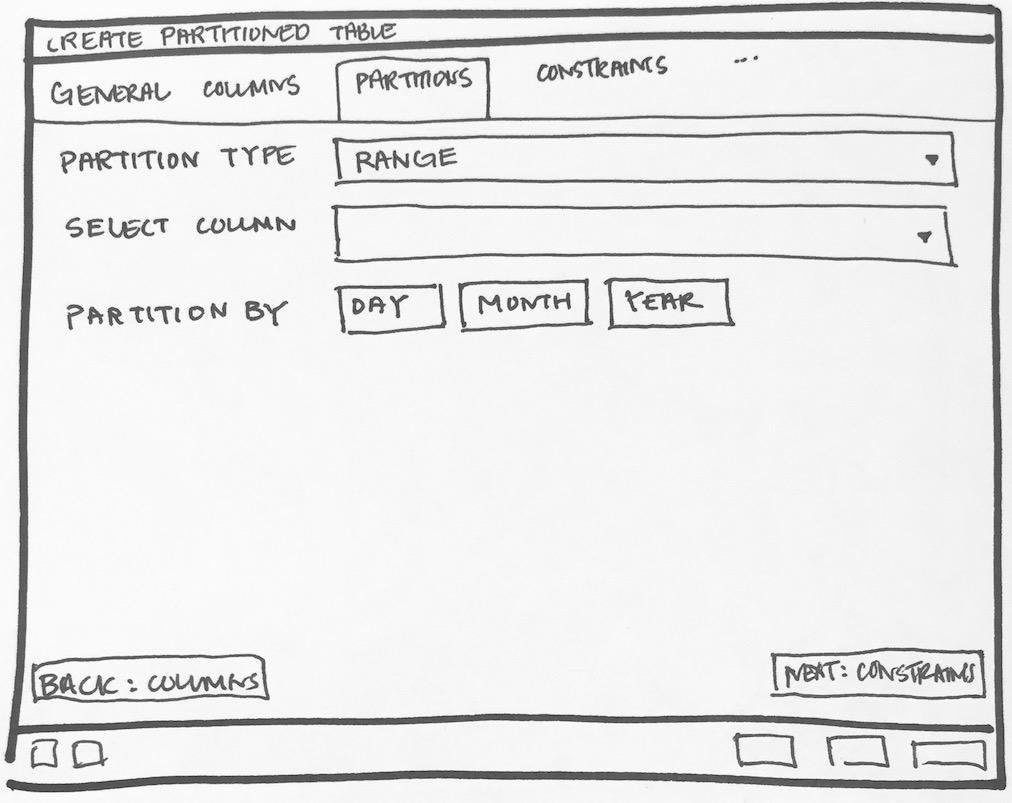
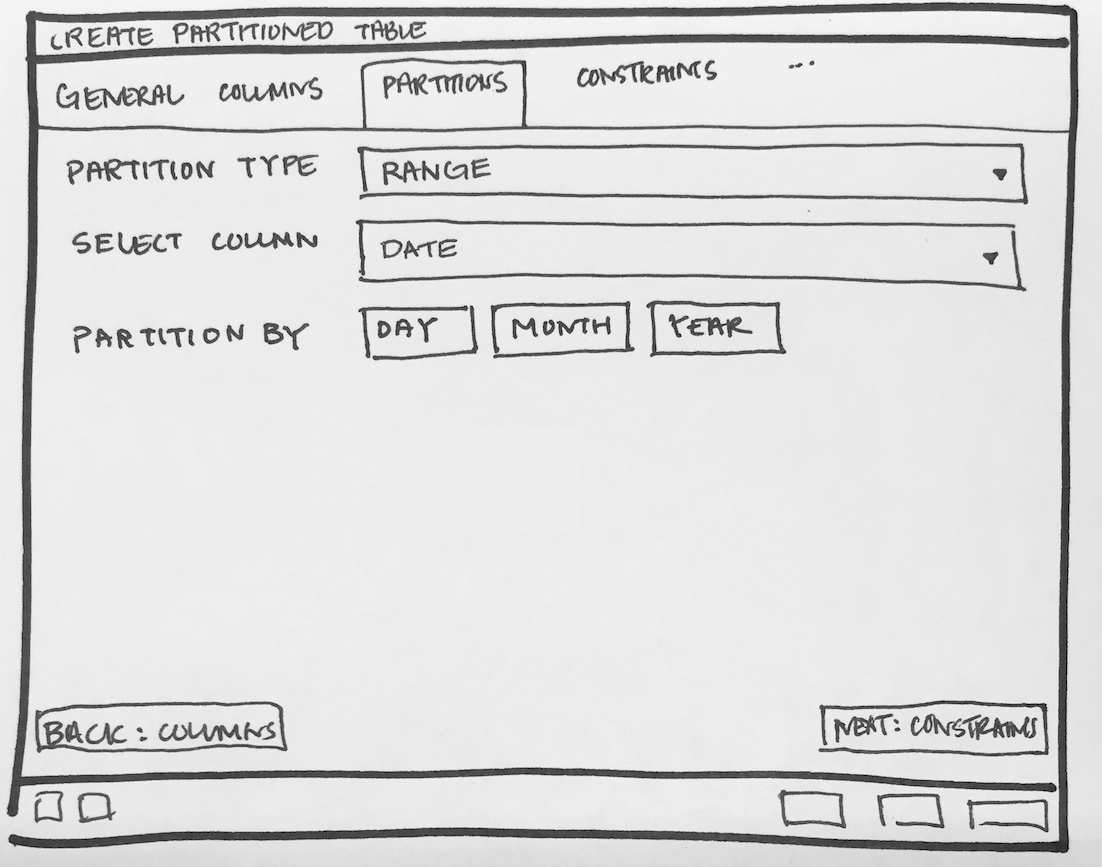

- The constraints tab as is implemented now enables constraints for the parent table, correct? If so, and if someone wants to apply constraints to partitions, as I understand it they would need to apply that to each child partition. If that is true, then the tab structure along the top would need to change to show constraints only after child partitions are created to avoid confusion. OR perhaps at the menu level, have an option for creating a partitioned table rather than table.
- The steps to create a table with partitions seems to have very clear steps. I think it would benefit from a more 'wizard-like' step by step flow.
Here's a sketch of a workflow. Just to note, the ellipses are for other tabs that might be necessary. I wasn't sure if there were any.
Also, at this point don't worry about buttons versus a dropdown - those can change.
01 fill out general info. User would click next.
02 User fills out info for columns. Since inheriting columns is not possible, we should remove that field entirely.
03 User selects partition type from drop down menu.
04 Options specific to Range partitions appear (ex. columns and width of dates)
05 User selects the column they want to partition by from the drop down, which should have columns prepopulated as options to choose from.
06 Once the user selects 'Day', 'month', or 'year' partitions, they see a loading screen as the app generates partitions
07 Partitions appear below as editable fields if users need to modify certain partition names.
Note: We're assuming that the best naming convention here is the [tablename_partitionrange], but this could change. Given that a user might be creating tens or hundreds of partitions, this would be valuable to those who need a memorable name quickly.
08 Constraints
Not sure what would need to go on this screen or if it's necessary at this level to apply triggers or keys.
Also, here's a link to a clickable mockup if you'd like to try going through the app.
Shirley
On Tue, Jun 13, 2017 at 10:28 AM Shirley Wang <swang@pivotal.io> wrote:
To add some interview context - from talking to DBAs, partitioning is the most frequent use case we should account for first. Breaking down child partitions into smaller pieces wasn't something we heard as a need. This is probably not the highest priority work needed now.We should think about when it would be good to release partitioning for some feedback. Did you already have this planned out?On Tue, Jun 13, 2017 at 9:46 AM Robert Eckhardt <reckhardt@pivotal.io> wrote:Akshay,Have you determined the minimum feature set you are shooting for before you commit this? The reason I ask is that we were thinking that some level of simple automation would probably be nice to make this super useful.Basically if you consider a simple example of partitioning 90 days of data by day the manual process of creating the names and to - from fields becomes rather painful. If you couple that with potentially wanting to do list subpartitioning if just multiplies the work.If we could get something committed then we could more easily work to define where simple automation makes sense and where it doesn't.-- RobOn Tue, Jun 13, 2017 at 6:59 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)To achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers--Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--
Attachment
On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)
I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?
To achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1
Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.
I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.
The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.
Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi Shirley,
Please see my reply inline..
On Wed, Jun 14, 2017 at 5:29 AM, Shirley Wang <swang@pivotal.io> wrote:
Some questions/comments/sketches:- The constraints tab as is implemented now enables constraints for the parent table, correct? If so, and if someone wants to apply constraints to partitions, as I understand it they would need to apply that to each child partition. If that is true, then the tab structure along the top would need to change to show constraints only after child partitions are created to avoid confusion. OR perhaps at the menu level, have an option for creating a partitioned table rather than table.
Couple of observation about the table constraints:
- PostgreSQL allow to create CHECK constraint on both partition (parent) table, and its children partitions.
- Rest of the constraints may not be applicable on the parent table.
So - the question is: whether we should allow to create constraints for the child partitions from the parent node, or not.
If yes - then:
We will need a switch control (flag) in each of the constraints (in the subnode control) to distinguish whether the constraint will be applied on parent/child table.
It think - we can also implement bulk triggers, constraints, indexes from the parent table, which can be applied to all the children partitions.
We can give these functionality in the
- The steps to create a table with partitions seems to have very clear steps. I think it would benefit from a more 'wizard-like' step by step flow.
Hmm.
Are you saying - we should switch to use the Wizard for table creation?
I think - that should be done in as a separate module.
Any way - we will need to properties dialog for editing the properties of an existing partition table.
Here's a sketch of a workflow. Just to note, the ellipses are for other tabs that might be necessary. I wasn't sure if there were any.Also, at this point don't worry about buttons versus a dropdown - those can change.01 fill out general info. User would click next.02 User fills out info for columns. Since inheriting columns is not possible, we should remove that field entirely.03 User selects partition type from drop down menu.04 Options specific to Range partitions appear (ex. columns and width of dates)
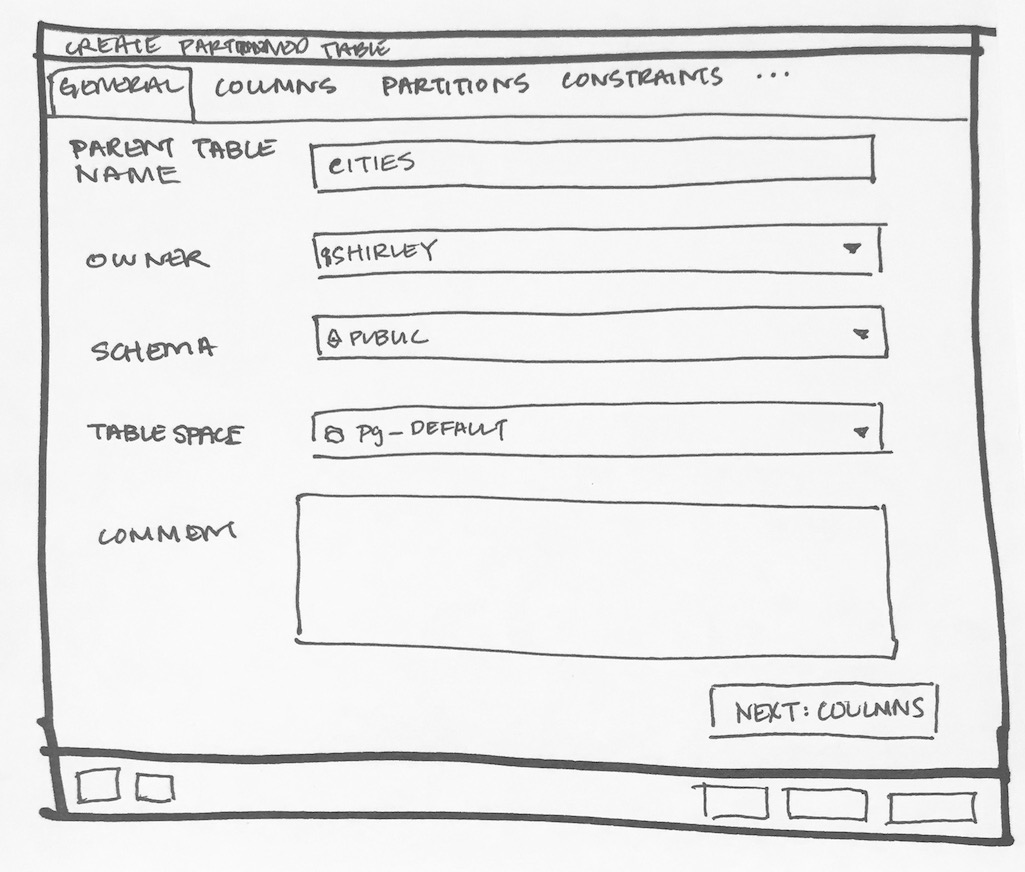
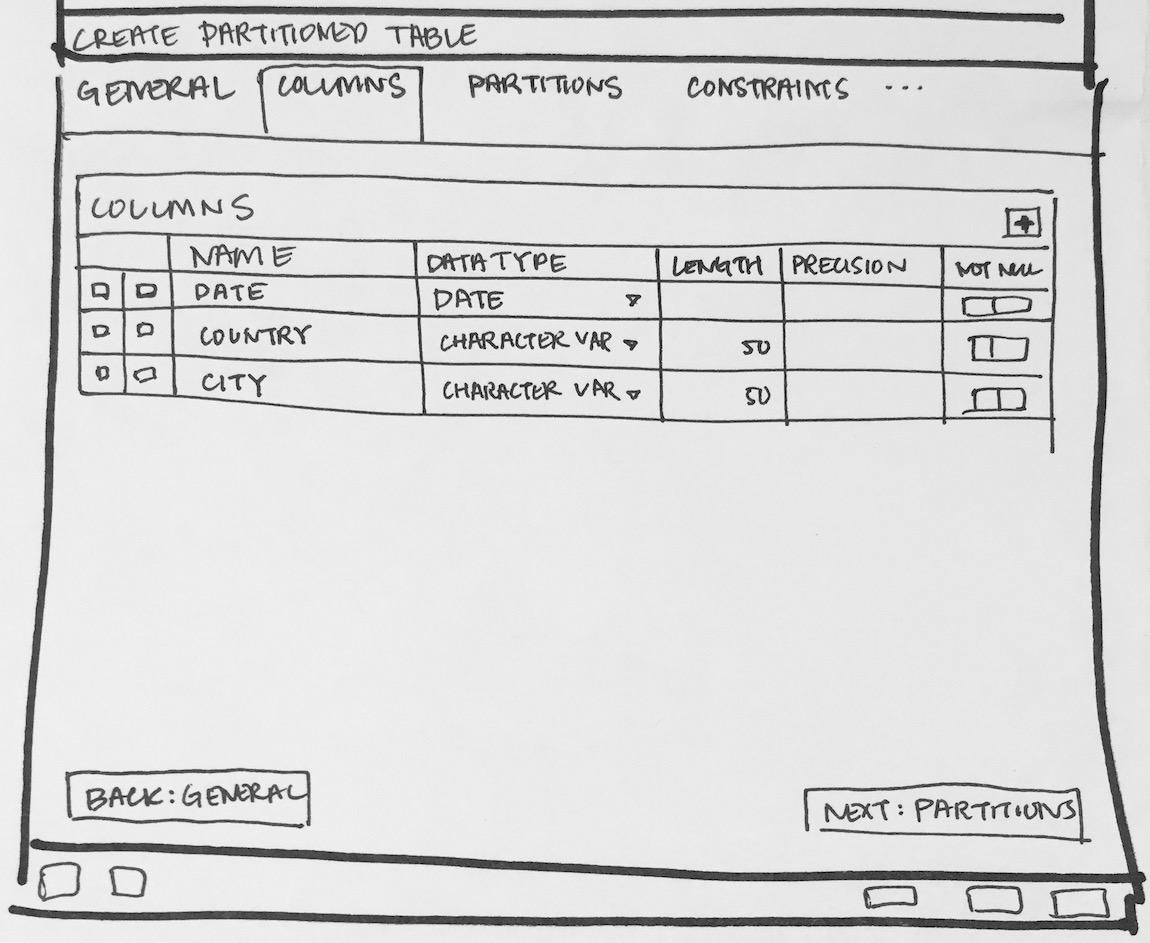
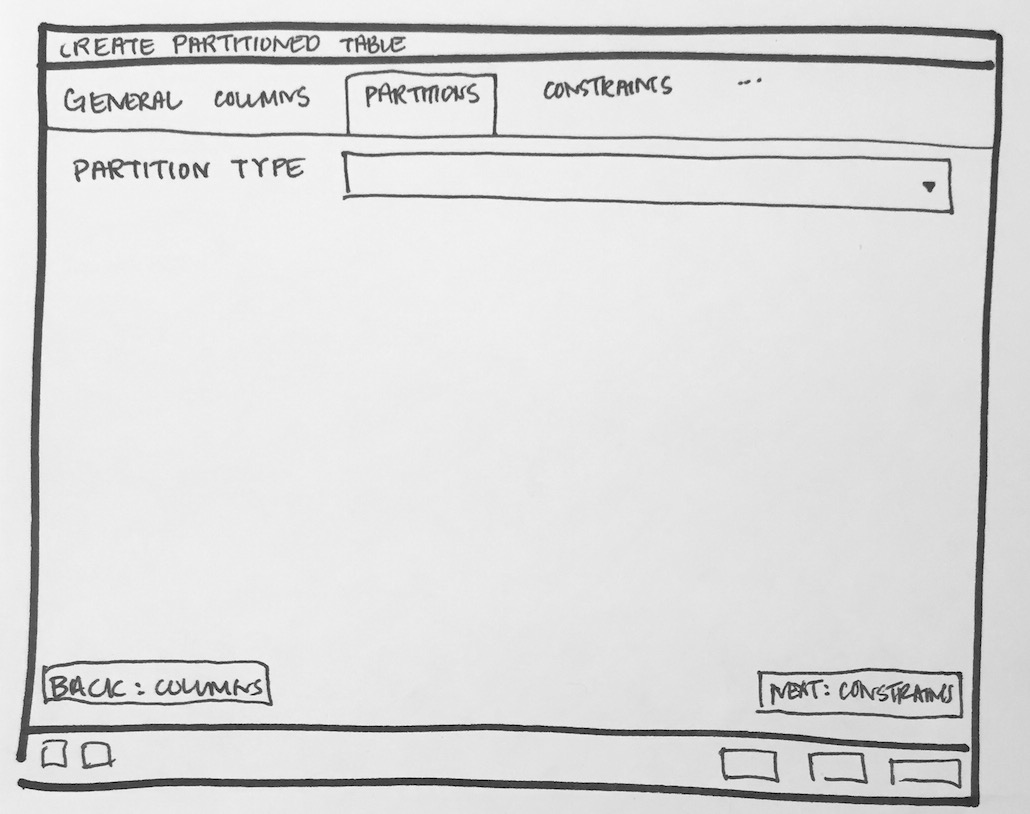
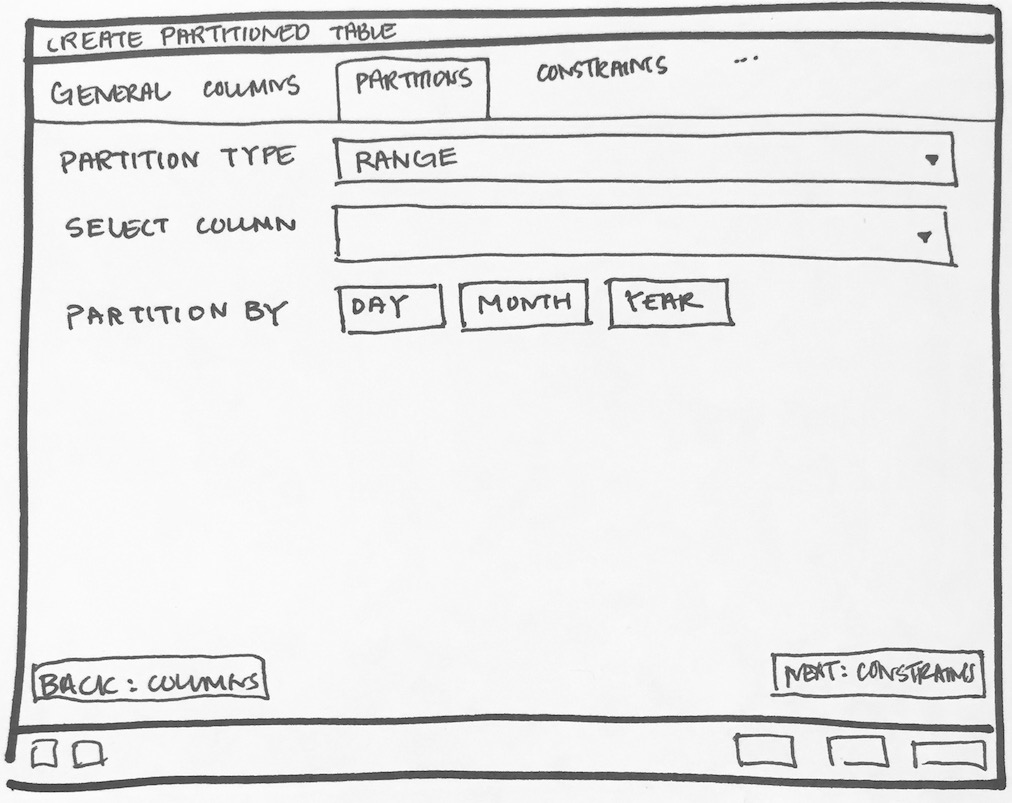
I think - there are some details missing.
Here - we're limiting the range/list partition only on one column, which is clearly wrong.
partition can be any number of columns.
Also - column can be of any type (not just date).
Current implementation (WIP) patch, shared by Akshay, has consider all those possibilities.
05 User selects the column they want to partition by from the drop down, which should have columns prepopulated as options to choose from.06 Once the user selects 'Day', 'month', or 'year' partitions, they see a loading screen as the app generates partitions07 Partitions appear below as editable fields if users need to modify certain partition names.Note: We're assuming that the best naming convention here is the [tablename_partitionrange], but this could change. Given that a user might be creating tens or hundreds of partitions, this would be valuable to those who need a memorable name quickly.08 ConstraintsNot sure what would need to go on this screen or if it's necessary at this level to apply triggers or keys.
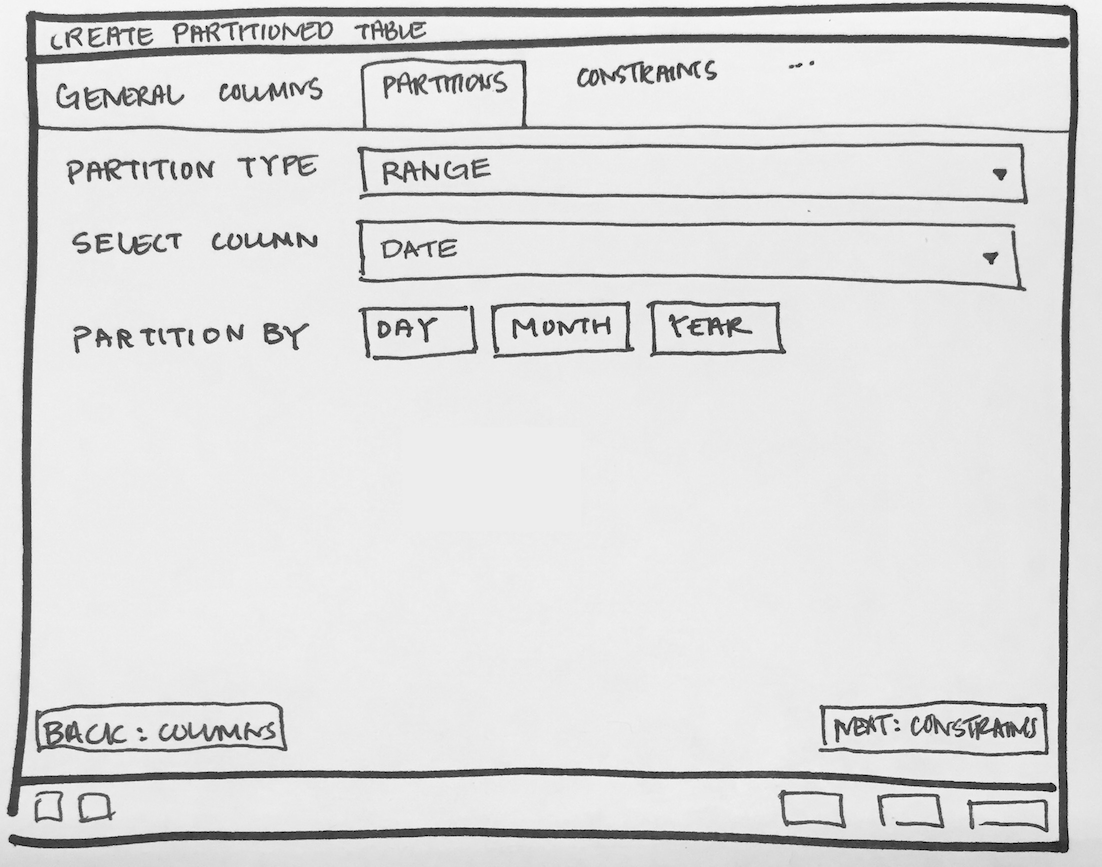

A parent table can have CHECK constraints.
So - we need the constraints tab.
-- Thanks, Ashesh
Also, here's a link to a clickable mockup if you'd like to try going through the app.ShirleyOn Tue, Jun 13, 2017 at 10:28 AM Shirley Wang <swang@pivotal.io> wrote:To add some interview context - from talking to DBAs, partitioning is the most frequent use case we should account for first. Breaking down child partitions into smaller pieces wasn't something we heard as a need. This is probably not the highest priority work needed now.We should think about when it would be good to release partitioning for some feedback. Did you already have this planned out?On Tue, Jun 13, 2017 at 9:46 AM Robert Eckhardt <reckhardt@pivotal.io> wrote:Akshay,Have you determined the minimum feature set you are shooting for before you commit this? The reason I ask is that we were thinking that some level of simple automation would probably be nice to make this super useful.Basically if you consider a simple example of partitioning 90 days of data by day the manual process of creating the names and to - from fields becomes rather painful. If you couple that with potentially wanting to do list subpartitioning if just multiplies the work.If we could get something committed then we could more easily work to define where simple automation makes sense and where it doesn't.-- RobOn Tue, Jun 13, 2017 at 6:59 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)To achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--
Attachment
On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:
On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?
psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.
They don't need particular key information.
In properties dialog, we need to find out - what individual partition key is? (column/expression).
Let me give an example.
I have a partition table with the following definition (with two partition keys).
CREATE TABLE public.sales
(
country character varying COLLATE pg_catalog."default" NOT NULL,
sales bigint,
saledate date
) PARTITION BY RANGE (country, EXTRACT(year from saledate));
And, the following query will give as:
SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';
relname | pg_get_partkeydef
---------+----------------------------------------------------
sales | RANGE (country, date_part('year'::text, saledate))
Here - we have two option in edit mode.
1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)
2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.
I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.
What do you say?
-- Thanks, Ashesh
To achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Jun 14, 2017 at 1:06 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:
On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.They don't need particular key information.In properties dialog, we need to find out - what individual partition key is? (column/expression).Let me give an example.I have a partition table with the following definition (with two partition keys).CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, EXTRACT(year from saledate));And, the following query will give as:SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';relname | pg_get_partkeydef---------+-------------------------------------------------- -- sales | RANGE (country, date_part('year'::text, saledate))Here - we have two option in edit mode.1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.What do you say?
I agree.
-- Thanks, AsheshTo achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Jun 14, 2017 at 3:42 AM Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:
Hi Shirley,
Please see my reply inline..
On Wed, Jun 14, 2017 at 5:29 AM, Shirley Wang <swang@pivotal.io> wrote:Some questions/comments/sketches:- The constraints tab as is implemented now enables constraints for the parent table, correct? If so, and if someone wants to apply constraints to partitions, as I understand it they would need to apply that to each child partition. If that is true, then the tab structure along the top would need to change to show constraints only after child partitions are created to avoid confusion. OR perhaps at the menu level, have an option for creating a partitioned table rather than table.Couple of observation about the table constraints:- PostgreSQL allow to create CHECK constraint on both partition (parent) table, and its children partitions.- Rest of the constraints may not be applicable on the parent table.So - the question is: whether we should allow to create constraints for the child partitions from the parent node, or not.If yes - then:We will need a switch control (flag) in each of the constraints (in the subnode control) to distinguish whether the constraint will be applied on parent/child table.
It think - we can also implement bulk triggers, constraints, indexes from the parent table, which can be applied to all the children partitions.We can give these functionality in the
I agree with you, potentially, as long as users are only seeing relevant info on that screen. For example, if only CHECK constraints work, if a user is creating a partitioned table they shouldn't be able to see non-working functionality. And if a user is creating a regular table, they should not see any additional UI elements that only relate to partitioning,
With what we have now, is there a way to do that gracefully? I feel like it'll be kind of difficult to navigate, especially with constraints. What are your thoughts on having 'Create -table' and 'Create-partitioned table' as two separate options?
- The steps to create a table with partitions seems to have very clear steps. I think it would benefit from a more 'wizard-like' step by step flow.Hmm.Are you saying - we should switch to use the Wizard for table creation?I think - that should be done in as a separate module.Any way - we will need to properties dialog for editing the properties of an existing partition table.
yes definitely. I don't think they need to be separate, the properties dialog could be a part of 'wizard'. Also, what do you mean by done in a separate module
Attachment
On Wed, Jun 14, 2017 at 5:39 PM, Dave Page <dpage@pgadmin.org> wrote:
On Wed, Jun 14, 2017 at 1:06 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.They don't need particular key information.In properties dialog, we need to find out - what individual partition key is? (column/expression).Let me give an example.I have a partition table with the following definition (with two partition keys).CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, EXTRACT(year from saledate));And, the following query will give as:SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';relname | pg_get_partkeydef---------+-------------------------------------------------- -- sales | RANGE (country, date_part('year'::text, saledate))Here - we have two option in edit mode.1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.What do you say?I agree.
I have modified the logic as per above suggestion. In create mode we will show "Partition Type" and "Partition Keys", so that user will be able to create partitioned table and in edit mode we will show "Partition Scheme" in NoteControl, as it's been difficult to parse and identify whether it is a column or expression. Please refer Create_Table.png.
Apart from that as per discussion with Dave yesterday I have remove the "Attach Partition" control and merge that functionality into "Partitions" control. I have added one switch control with text (Attach/Create). By default this control is disabled in create mode, while in edit mode user can create/attach partitions. When user select create then "Name" is input control and when user selects attach then "Name" is select2 control containing list of all the suitable(with same columns, datatype and oids ) tables to be attached. Refer Edit_Table.png
I have also added one NoteControl at the bottom which will give information about the Partitions control how to use that. Please correct the string if it looks wrong.
-- Thanks, AsheshTo achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.

Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.
When is the 'In' column in the Partitions subnode enabled?
For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?
On Thu, Jun 15, 2017 at 2:12 AM Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
On Wed, Jun 14, 2017 at 5:39 PM, Dave Page <dpage@pgadmin.org> wrote:On Wed, Jun 14, 2017 at 1:06 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.They don't need particular key information.In properties dialog, we need to find out - what individual partition key is? (column/expression).Let me give an example.I have a partition table with the following definition (with two partition keys).CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, EXTRACT(year from saledate));And, the following query will give as:SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';relname | pg_get_partkeydef---------+----------------------------------------------------sales | RANGE (country, date_part('year'::text, saledate))Here - we have two option in edit mode.1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.What do you say?I agree.I have modified the logic as per above suggestion. In create mode we will show "Partition Type" and "Partition Keys", so that user will be able to create partitioned table and in edit mode we will show "Partition Scheme" in NoteControl, as it's been difficult to parse and identify whether it is a column or expression. Please refer Create_Table.png.Apart from that as per discussion with Dave yesterday I have remove the "Attach Partition" control and merge that functionality into "Partitions" control. I have added one switch control with text (Attach/Create). By default this control is disabled in create mode, while in edit mode user can create/attach partitions. When user select create then "Name" is input control and when user selects attach then "Name" is select2 control containing list of all the suitable(with same columns, datatype and oids ) tables to be attached. Refer Edit_Table.pngI have also added one NoteControl at the bottom which will give information about the Partitions control how to use that. Please correct the string if it looks wrong.-- Thanks, AsheshTo achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers--Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:
Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.
I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.
Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.
We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.
When is the 'In' column in the Partitions subnode enabled?
In case of 'List' Partition.
For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?
'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.
On Wed, Jun 14, 2017 at 5:39 PM, Dave Page <dpage@pgadmin.org> wrote:On Wed, Jun 14, 2017 at 1:06 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.They don't need particular key information.In properties dialog, we need to find out - what individual partition key is? (column/expression).Let me give an example.I have a partition table with the following definition (with two partition keys).CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, EXTRACT(year from saledate));And, the following query will give as:SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';relname | pg_get_partkeydef---------+-------------------------------------------------- -- sales | RANGE (country, date_part('year'::text, saledate))Here - we have two option in edit mode.1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.What do you say?I agree.I have modified the logic as per above suggestion. In create mode we will show "Partition Type" and "Partition Keys", so that user will be able to create partitioned table and in edit mode we will show "Partition Scheme" in NoteControl, as it's been difficult to parse and identify whether it is a column or expression. Please refer Create_Table.png.Apart from that as per discussion with Dave yesterday I have remove the "Attach Partition" control and merge that functionality into "Partitions" control. I have added one switch control with text (Attach/Create). By default this control is disabled in create mode, while in edit mode user can create/attach partitions. When user select create then "Name" is input control and when user selects attach then "Name" is select2 control containing list of all the suitable(with same columns, datatype and oids ) tables to be attached. Refer Edit_Table.pngI have also added one NoteControl at the bottom which will give information about the Partitions control how to use that. Please correct the string if it looks wrong.-- Thanks, AsheshTo achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Hi All
Attached is the latest WIP patch. Following task is completed
- User will be able to create partitioned table (Range and List) using columns and expression as partition key.
- User will be able to create N partitions while creating the partitioned table itself.
- User will be able to see SQL of all partitions (child tables) along with the partitioned table in SQL pane when select parent node.
- Controls are disabled/hide from table dialog which are not supported by Partitioning.
- User will be able to create/attach/detach N no of partitions from the parent table dialog.
- User will be able to detach partition by selecting and clicking on "Detach Partition" menu. Visible only on partitions.
- Refresh Tables/Partitions collection when any new node is created or removed from the collection. For example user will detach/create/attach N no of partitions from parent table in that case we will have to refresh the complete Tables/Partitions collection. Need some suggestions how we can achieve it.
- Table dialog for child tables(Partitions). (Harshal working on it.)
- Displaying Constraints, Indexes, Rules, Triggers collection/node when expanding partition node. (Harshal working on it.)
On Mon, Jun 19, 2017 at 11:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.On Wed, Jun 14, 2017 at 5:39 PM, Dave Page <dpage@pgadmin.org> wrote:On Wed, Jun 14, 2017 at 1:06 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.They don't need particular key information.In properties dialog, we need to find out - what individual partition key is? (column/expression).Let me give an example.I have a partition table with the following definition (with two partition keys).CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, EXTRACT(year from saledate));And, the following query will give as:SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';relname | pg_get_partkeydef---------+-------------------------------------------------- -- sales | RANGE (country, date_part('year'::text, saledate))Here - we have two option in edit mode.1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.What do you say?I agree.I have modified the logic as per above suggestion. In create mode we will show "Partition Type" and "Partition Keys", so that user will be able to create partitioned table and in edit mode we will show "Partition Scheme" in NoteControl, as it's been difficult to parse and identify whether it is a column or expression. Please refer Create_Table.png.Apart from that as per discussion with Dave yesterday I have remove the "Attach Partition" control and merge that functionality into "Partitions" control. I have added one switch control with text (Attach/Create). By default this control is disabled in create mode, while in edit mode user can create/attach partitions. When user select create then "Name" is input control and when user selects attach then "Name" is select2 control containing list of all the suitable(with same columns, datatype and oids ) tables to be attached. Refer Edit_Table.pngI have also added one NoteControl at the bottom which will give information about the Partitions control how to use that. Please correct the string if it looks wrong.-- Thanks, AsheshTo achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246
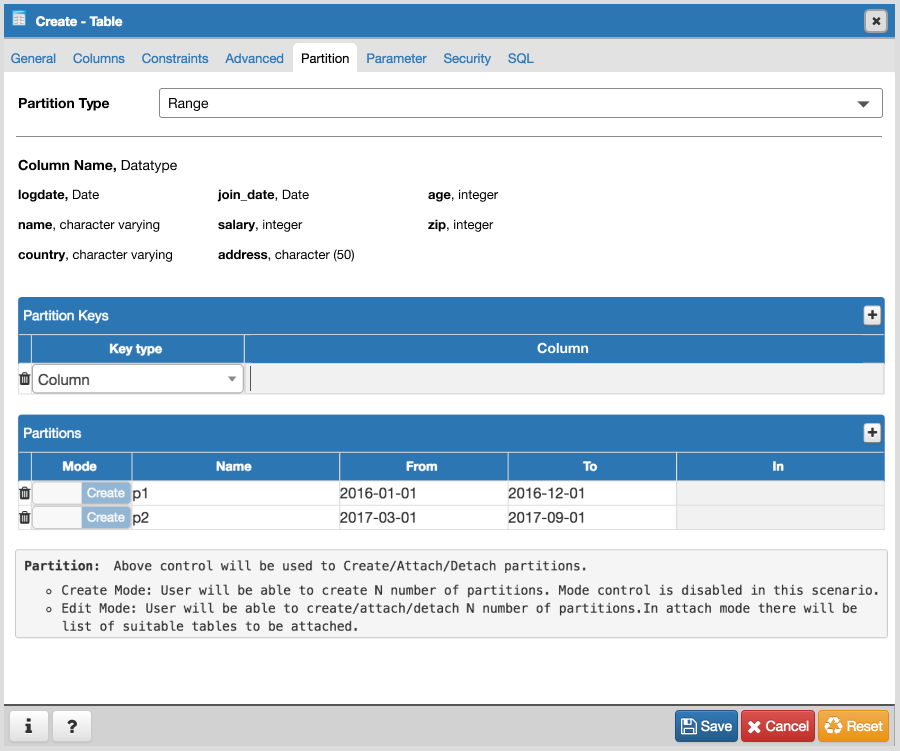
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
Hi
--
On Mon, Jun 19, 2017 at 10:31 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AllAttached is the latest WIP patch. Following task is completedFollowing tasks are remaining:
- User will be able to create partitioned table (Range and List) using columns and expression as partition key.
- User will be able to create N partitions while creating the partitioned table itself.
- User will be able to see SQL of all partitions (child tables) along with the partitioned table in SQL pane when select parent node.
- Controls are disabled/hide from table dialog which are not supported by Partitioning.
- User will be able to create/attach/detach N no of partitions from the parent table dialog.
- User will be able to detach partition by selecting and clicking on "Detach Partition" menu. Visible only on partitions.
Please review/run the latest patch and let me know your thoughts/suggestions on it.
- Refresh Tables/Partitions collection when any new node is created or removed from the collection. For example user will detach/create/attach N no of partitions from parent table in that case we will have to refresh the complete Tables/Partitions collection. Need some suggestions how we can achieve it.
- Table dialog for child tables(Partitions). (Harshal working on it.)
- Displaying Constraints, Indexes, Rules, Triggers collection/node when expanding partition node. (Harshal working on it.)
I did some quick testing, and the main issue for me is the fact that you're automatically quoting values in the from/to/in lists. I think that should be left to the user (as is the case for default values), as it's easy to get wrong. I tried to create a table partitioned by date for example, and it quoted my dates which created incorrect SQL. I also found that it was displaying lists incorrectly as well - for example, given:
CREATE TABLE cities (
city_id bigserial not null,
name text not null,
population int
) PARTITION BY LIST (initcap(name));
CREATE TABLE cities_west
PARTITION OF cities (
CONSTRAINT city_id_nonzero CHECK (city_id != 0)
) FOR VALUES IN ('Los Angeles', 'San Francisco');
The "in" list is shown as
'Los
Otherwise, I think it's looking good. We'll need to do some string review, but that's minor.
On Mon, Jun 19, 2017 at 11:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.On Wed, Jun 14, 2017 at 5:39 PM, Dave Page <dpage@pgadmin.org> wrote:On Wed, Jun 14, 2017 at 1:06 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.They don't need particular key information.In properties dialog, we need to find out - what individual partition key is? (column/expression).Let me give an example.I have a partition table with the following definition (with two partition keys).CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, EXTRACT(year from saledate));And, the following query will give as:SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';relname | pg_get_partkeydef---------+-------------------------------------------------- -- sales | RANGE (country, date_part('year'::text, saledate))Here - we have two option in edit mode.1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.What do you say?I agree.I have modified the logic as per above suggestion. In create mode we will show "Partition Type" and "Partition Keys", so that user will be able to create partitioned table and in edit mode we will show "Partition Scheme" in NoteControl, as it's been difficult to parse and identify whether it is a column or expression. Please refer Create_Table.png.Apart from that as per discussion with Dave yesterday I have remove the "Attach Partition" control and merge that functionality into "Partitions" control. I have added one switch control with text (Attach/Create). By default this control is disabled in create mode, while in edit mode user can create/attach partitions. When user select create then "Name" is input control and when user selects attach then "Name" is select2 control containing list of all the suitable(with same columns, datatype and oids ) tables to be attached. Refer Edit_Table.pngI have also added one NoteControl at the bottom which will give information about the Partitions control how to use that. Please correct the string if it looks wrong.-- Thanks, AsheshTo achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Mon, Jun 19, 2017 at 4:28 PM, Dave Page <dpage@pgadmin.org> wrote:
HiOn Mon, Jun 19, 2017 at 10:31 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllAttached is the latest WIP patch. Following task is completedFollowing tasks are remaining:
- User will be able to create partitioned table (Range and List) using columns and expression as partition key.
- User will be able to create N partitions while creating the partitioned table itself.
- User will be able to see SQL of all partitions (child tables) along with the partitioned table in SQL pane when select parent node.
- Controls are disabled/hide from table dialog which are not supported by Partitioning.
- User will be able to create/attach/detach N no of partitions from the parent table dialog.
- User will be able to detach partition by selecting and clicking on "Detach Partition" menu. Visible only on partitions.
Please review/run the latest patch and let me know your thoughts/suggestions on it.
- Refresh Tables/Partitions collection when any new node is created or removed from the collection. For example user will detach/create/attach N no of partitions from parent table in that case we will have to refresh the complete Tables/Partitions collection. Need some suggestions how we can achieve it.
- Table dialog for child tables(Partitions). (Harshal working on it.)
- Displaying Constraints, Indexes, Rules, Triggers collection/node when expanding partition node. (Harshal working on it.)
I did some quick testing, and the main issue for me is the fact that you're automatically quoting values in the from/to/in lists. I think that should be left to the user (as is the case for default values), as it's easy to get wrong. I tried to create a table partitioned by date for example, and it quoted my dates which created incorrect SQL. I also found that it was displaying lists incorrectly as well - for example, given:
Should I remove the quotes from displaying it for existing partitions too? If I'll remove quoting then user will have to add quote for each comma separated value for the "from/to/in" field. For example '100','200','300'
CREATE TABLE cities (city_id bigserial not null,name text not null,population int) PARTITION BY LIST (initcap(name));CREATE TABLE cities_westPARTITION OF cities (CONSTRAINT city_id_nonzero CHECK (city_id != 0)) FOR VALUES IN ('Los Angeles', 'San Francisco');The "in" list is shown as'LosOtherwise, I think it's looking good. We'll need to do some string review, but that's minor.On Mon, Jun 19, 2017 at 11:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.On Wed, Jun 14, 2017 at 5:39 PM, Dave Page <dpage@pgadmin.org> wrote:On Wed, Jun 14, 2017 at 1:06 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.They don't need particular key information.In properties dialog, we need to find out - what individual partition key is? (column/expression).Let me give an example.I have a partition table with the following definition (with two partition keys).CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, EXTRACT(year from saledate));And, the following query will give as:SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';relname | pg_get_partkeydef---------+-------------------------------------------------- -- sales | RANGE (country, date_part('year'::text, saledate))Here - we have two option in edit mode.1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.What do you say?I agree.I have modified the logic as per above suggestion. In create mode we will show "Partition Type" and "Partition Keys", so that user will be able to create partitioned table and in edit mode we will show "Partition Scheme" in NoteControl, as it's been difficult to parse and identify whether it is a column or expression. Please refer Create_Table.png.Apart from that as per discussion with Dave yesterday I have remove the "Attach Partition" control and merge that functionality into "Partitions" control. I have added one switch control with text (Attach/Create). By default this control is disabled in create mode, while in edit mode user can create/attach partitions. When user select create then "Name" is input control and when user selects attach then "Name" is select2 control containing list of all the suitable(with same columns, datatype and oids ) tables to be attached. Refer Edit_Table.pngI have also added one NoteControl at the bottom which will give information about the Partitions control how to use that. Please correct the string if it looks wrong.-- Thanks, AsheshTo achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
On Mon, Jun 19, 2017 at 2:07 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
On Mon, Jun 19, 2017 at 4:28 PM, Dave Page <dpage@pgadmin.org> wrote:HiOn Mon, Jun 19, 2017 at 10:31 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllAttached is the latest WIP patch. Following task is completedFollowing tasks are remaining:
- User will be able to create partitioned table (Range and List) using columns and expression as partition key.
- User will be able to create N partitions while creating the partitioned table itself.
- User will be able to see SQL of all partitions (child tables) along with the partitioned table in SQL pane when select parent node.
- Controls are disabled/hide from table dialog which are not supported by Partitioning.
- User will be able to create/attach/detach N no of partitions from the parent table dialog.
- User will be able to detach partition by selecting and clicking on "Detach Partition" menu. Visible only on partitions.
Please review/run the latest patch and let me know your thoughts/suggestions on it.
- Refresh Tables/Partitions collection when any new node is created or removed from the collection. For example user will detach/create/attach N no of partitions from parent table in that case we will have to refresh the complete Tables/Partitions collection. Need some suggestions how we can achieve it.
- Table dialog for child tables(Partitions). (Harshal working on it.)
- Displaying Constraints, Indexes, Rules, Triggers collection/node when expanding partition node. (Harshal working on it.)
I did some quick testing, and the main issue for me is the fact that you're automatically quoting values in the from/to/in lists. I think that should be left to the user (as is the case for default values), as it's easy to get wrong. I tried to create a table partitioned by date for example, and it quoted my dates which created incorrect SQL. I also found that it was displaying lists incorrectly as well - for example, given:Should I remove the quotes from displaying it for existing partitions too? If I'll remove quoting then user will have to add quote for each comma separated value for the "from/to/in" field. For example '100','200','300'
Yes, I think so. That confused me when I added a partition, as I first typed:
'New York', 'Orlando'
then
New York, Orlando
and finally:
New York,Orlando
Before I finally got what I wanted. Perhaps more importantly, what if I wanted to partition based on 'New York, NY', 'Orlando, FL'. That wouldn't have worked at all!
I think we should just leave it to the user to quote/list as needed, as we do in a few other similar places.
CREATE TABLE cities (city_id bigserial not null,name text not null,population int) PARTITION BY LIST (initcap(name));CREATE TABLE cities_westPARTITION OF cities (CONSTRAINT city_id_nonzero CHECK (city_id != 0)) FOR VALUES IN ('Los Angeles', 'San Francisco');The "in" list is shown as'LosOtherwise, I think it's looking good. We'll need to do some string review, but that's minor.On Mon, Jun 19, 2017 at 11:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.On Wed, Jun 14, 2017 at 5:39 PM, Dave Page <dpage@pgadmin.org> wrote:On Wed, Jun 14, 2017 at 1:06 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.They don't need particular key information.In properties dialog, we need to find out - what individual partition key is? (column/expression).Let me give an example.I have a partition table with the following definition (with two partition keys).CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, EXTRACT(year from saledate));And, the following query will give as:SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';relname | pg_get_partkeydef---------+-------------------------------------------------- -- sales | RANGE (country, date_part('year'::text, saledate))Here - we have two option in edit mode.1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.What do you say?I agree.I have modified the logic as per above suggestion. In create mode we will show "Partition Type" and "Partition Keys", so that user will be able to create partitioned table and in edit mode we will show "Partition Scheme" in NoteControl, as it's been difficult to parse and identify whether it is a column or expression. Please refer Create_Table.png.Apart from that as per discussion with Dave yesterday I have remove the "Attach Partition" control and merge that functionality into "Partitions" control. I have added one switch control with text (Attach/Create). By default this control is disabled in create mode, while in edit mode user can create/attach partitions. When user select create then "Name" is input control and when user selects attach then "Name" is select2 control containing list of all the suitable(with same columns, datatype and oids ) tables to be attached. Refer Edit_Table.pngI have also added one NoteControl at the bottom which will give information about the Partitions control how to use that. Please correct the string if it looks wrong.-- Thanks, AsheshTo achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
On Mon, Jun 19, 2017 at 3:01 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:

Hi AllAttached is the latest WIP patch. Following task is completedFollowing tasks are remaining:
- User will be able to create partitioned table (Range and List) using columns and expression as partition key.
- User will be able to create N partitions while creating the partitioned table itself.
- User will be able to see SQL of all partitions (child tables) along with the partitioned table in SQL pane when select parent node.
- Controls are disabled/hide from table dialog which are not supported by Partitioning.
- User will be able to create/attach/detach N no of partitions from the parent table dialog.
- User will be able to detach partition by selecting and clicking on "Detach Partition" menu. Visible only on partitions.
- Refresh Tables/Partitions collection when any new node is created or removed from the collection. For example user will detach/create/attach N no of partitions from parent table in that case we will have to refresh the complete Tables/Partitions collection. Need some suggestions how we can achieve it.
- Table dialog for child tables(Partitions). (Harshal working on it.)
- Displaying Constraints, Indexes, Rules, Triggers collection/node when expanding partition node. (Harshal working on it.)
Listing and creation of constraints, index, rules, triggers on table partition is completed.
Also listing of table partition under table partition (upto n levels) is also completed.
Please review/run the latest patch and let me know your thoughts/suggestions on it.On Mon, Jun 19, 2017 at 11:29 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.On Wed, Jun 14, 2017 at 5:39 PM, Dave Page <dpage@pgadmin.org> wrote:On Wed, Jun 14, 2017 at 1:06 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Wed, Jun 14, 2017 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:On Tue, Jun 13, 2017 at 2:59 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFor further implementation following task needs to be work upon:
- How to parse and show partitions keys. For example user has created below partitioned table
CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, date_part('year'::text, sale date))When user open the properties dialog I am not able to figure out how to parse keys(displayed in bold in above example) and show them in our control that we used. For the time being I have hide that control in 'Edit' mode (Refer Attach Partition.png)I assume psql with display that info with \dt or similar? What does it do? Failing that, look at pg_dump?psql, and pg_dump use 'pg_get_partkeydef' function for reverse engineering, and we too.They don't need particular key information.In properties dialog, we need to find out - what individual partition key is? (column/expression).Let me give an example.I have a partition table with the following definition (with two partition keys).CREATE TABLE public.sales(country character varying COLLATE pg_catalog."default" NOT NULL,sales bigint,saledate date) PARTITION BY RANGE (country, EXTRACT(year from saledate));And, the following query will give as:SELECT relname, pg_get_partkeydef(oid) FROM pg_catalog.pg_class WHERE relname like 'sal%';relname | pg_get_partkeydef---------+-------------------------------------------------- -- sales | RANGE (country, date_part('year'::text, saledate))Here - we have two option in edit mode.1. Parse the output of the 'pg_get_partkeydef', and identify all individual keys, and its detailed information (i.e. column/expression)2. Show that output about the partition keys in static control, and hide the Partition type, partition keys controls.I prefer the second option, as user can not modify the partition keys/type (RANGE/LIST), and we will not have to write logic to parse the keys from that output.What do you say?I agree.I have modified the logic as per above suggestion. In create mode we will show "Partition Type" and "Partition Keys", so that user will be able to create partitioned table and in edit mode we will show "Partition Scheme" in NoteControl, as it's been difficult to parse and identify whether it is a column or expression. Please refer Create_Table.png.Apart from that as per discussion with Dave yesterday I have remove the "Attach Partition" control and merge that functionality into "Partitions" control. I have added one switch control with text (Attach/Create). By default this control is disabled in create mode, while in edit mode user can create/attach partitions. When user select create then "Name" is input control and when user selects attach then "Name" is select2 control containing list of all the suitable(with same columns, datatype and oids ) tables to be attached. Refer Edit_Table.pngI have also added one NoteControl at the bottom which will give information about the Partitions control how to use that. Please correct the string if it looks wrong.-- Thanks, AsheshTo achieve above I have made some changes in GUI (Refer Sub Partition.png).
- Support of sub partitioning: To implement sub-partitioning, specify the PARTITION BY clause in the commands used to create individual partitions, for example:
CREATE TABLE measurement_y2006 PARTITION OF measurement FOR VALUES FROM ('2006-02-01') TO ('2006-03-01') PARTITION BY RANGE (peaktemp);Complex and challenging part here is "measurement_y2006" is partition of "measurement" and parent table for other partitions too which user can create later. How we will going to show this in browser tree?One option could beTables->measurement(table)->Partitions->measurement_y2006(Partition of measurement and parent of p1)->Partitions->p1Urgh. But yeah. I think that makes logical sense.
- Attach Partitions: To implement attach N partitions I have made some changes in GUI( Refer Attach Partition.png). Attach Partitions control will only be visible in "Edit" mode.
I have only modified the UI changes, there are lots of work needs to be done to complete that.I don't think I'd include Attach on the dialog. I think it should be a separate menu option, with a simple dialogue to let the user choose the table to attach.The reason for that is that Attach is an action not a property. On the Properties panels we expect any changes we make to be the same the next time the dialogue is opened - e.g. if you toggle "Enable Trigger" to disabled and hit OK, then next time you open the dialogue you see the switch in the same position. With Attach, that's not the case - you'll list one or more tables to attach, hit OK, and when you next open the Properties dialogue, those partitions will be listed in the partition list, not the Attach list.Please review the design. Suggestions/Comments are welcome.On Tue, Jun 6, 2017 at 4:30 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Tue, Jun 6, 2017 at 4:32 AM, Dave Page <dpage@pgadmin.org> wrote:For roll up this pattern seems obvious, identify the n partitions you need/want to combine and then run a job to combine them.You're thinking Greenplum :-). There is no roll up in PostgreSQL, unless you're thinking we should create such a feature in pgAdmin.Of course, I have no objection to extending what we do in PG to add GP feature support, but let's start with PG.No not at all. That was a very specific and consistent pattern described by users leveraging time based range partitions in Postgres. I'm not sure if that same use case will be supported with partitioning as implemented in Postgres 10 but it is a Postgres pattern.-- RobFor other patterns such as creating indexes and such it requires a bit more thought. Generally users described wanting to treat all of the children like a single table (just like Oracle), however, other users described potentially modifying chunks of partitions differently depending on some criterion. This means that users will need to identify the subset they want to optimize and then ideally be able to act on them all at once.Right.-- RobSo... it sounds like we're on the right lines :-)For the former, this can be addressed by enabling users to modify one or more child partitions at the same time. For the latter, that is a workflow that might be addressed outside of the create table with partition workflow we're working on currently.On Mon, Jun 5, 2017 at 5:21 AM Dave Page <dpage@pgadmin.org> wrote:On Fri, Jun 2, 2017 at 9:01 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AllFollowing are the further implementation updates to support Declarative Partitioning:
- Show all the existing partitions of the parent table in Partitions tab (Refer Existing_Partitions.png)
- Ability to create N partitions and detach existing partitions. Refer (Create_Detach_Partition.png), in this example I have detach two existing partition and create two new partitions.
- Added "Detach Partition" menu to partitions node only and user will be able to detach from there as well. Refer (Detach.png)
That's looking good to me :-)--On Wed, May 24, 2017 at 8:00 PM, Robert Eckhardt <reckhardt@pivotal.io> wrote:On Wed, May 24, 2017 at 3:35 AM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Taking average of two columns is just an example/representation of expression, there is no use case of that. As I am also in learning phase. Below are some use case that I can think of:
id serial not null,
username text not null,
password text,
created_on timestamptz not null,
last_logged_on timestamptz not null
)PARTITION BY RANGE ( lower( left( username, 1 ) ) );
CREATE TABLE users_0
partition of users (id, primary key (id), unique (username))
for values from ('a') to ('g');
CREATE TABLE users_1
partition of users (id, primary key (id), unique (username))
for values from ('g') to (unbounded);- Partition based on country's sale for each month of an year.
Apart from above there may be N number of use cases that depends on specific requirement of user.CREATE TABLE public.sales(country text NOT NULL,sales bigint NOT NULL,saledate date) PARTITION BY RANGE (country, (extract (YEAR FROM saledate)), (extract(MONTH FROM saledate)))CREATE TABLE public.sale_usa_2017_jan PARTITION OF salesFOR VALUES FROM ('usa', 2017, 01) TO ('usa', 2017, 02);CREATE TABLE public.sale_india_2017_jan PARTITION OF salesFOR VALUES FROM ('india', 2017, 01) TO ('india', 2017, 02);CREATE TABLE public.sale_uk_2017_jan PARTITION OF salesFOR VALUES FROM ('uk', 2017, 01) TO ('uk', 2017, 02);INSERT INTO sales VALUES ('india', 10000, '2017-1-15');INSERT INTO sales VALUES ('uk', 20000, '2017-1-08');INSERT INTO sales VALUES ('usa', 30000, '2017-1-10');Thank you for the example, you are absolutely correct and we were confused.Given our new found understanding do you mind if we iterate a bit on the UI/UX? What we were suggesting with the daily/monthly/yearly drop down was a specific example of an expression. Given that fact that doesn't seem to be required in an MVP, however, I do think a more interactive experience between the definition of the child partitions and the creation of the partitions would be optimal.I'm not sure where you are with respect to implementing the UI but I'd love to float some ideas and mock ups past you.-- Rob--
Sent via pgadmin-hackers mailing list (pgadmin-hackers@postgresql.org)
To make changes to your subscription:
http://www.postgresql.org/mailpref/pgadmin-hackers --Dave Page--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company----Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246
On Mon, Jun 19, 2017 at 1:59 AM Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.
Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdown
Can a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.
Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.
Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.
If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.
When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.
It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.
For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.
I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.
Hi,
Please find attached patch for partition support.
This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.
Thanks,
--
Harshal Dhumal
Sr. Software Engineer
On Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:
On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.

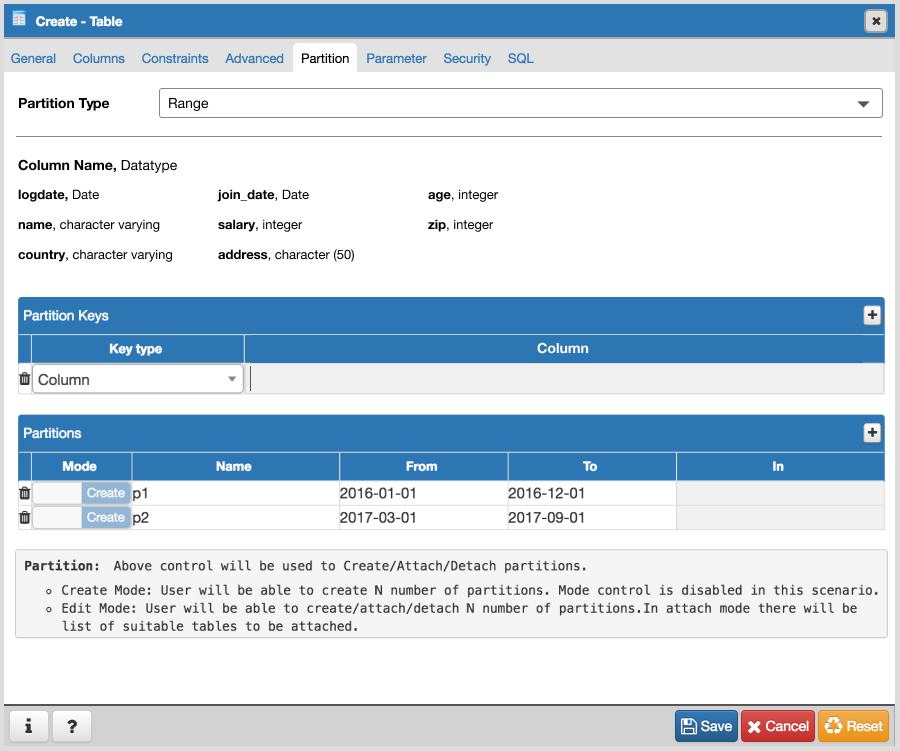
Attachment
P.S. Akshay is working on test cases for same and will send separate patch.
--
Harshal Dhumal
Sr. Software Engineer
On Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote:
Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.
Thanks - Ashesh, can you review/commit this please? Additional reviews welcome as well of course.
On Fri, Jun 23, 2017 at 2:25 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote:
Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi All
I have implemented test cases for partitioned table. Attached is the patch file. Please review it and if it looks good then please commit it.
--
On Fri, Jun 23, 2017 at 8:54 PM, Dave Page <dpage@pgadmin.org> wrote:
Thanks - Ashesh, can you review/commit this please? Additional reviews welcome as well of course.--On Fri, Jun 23, 2017 at 2:25 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
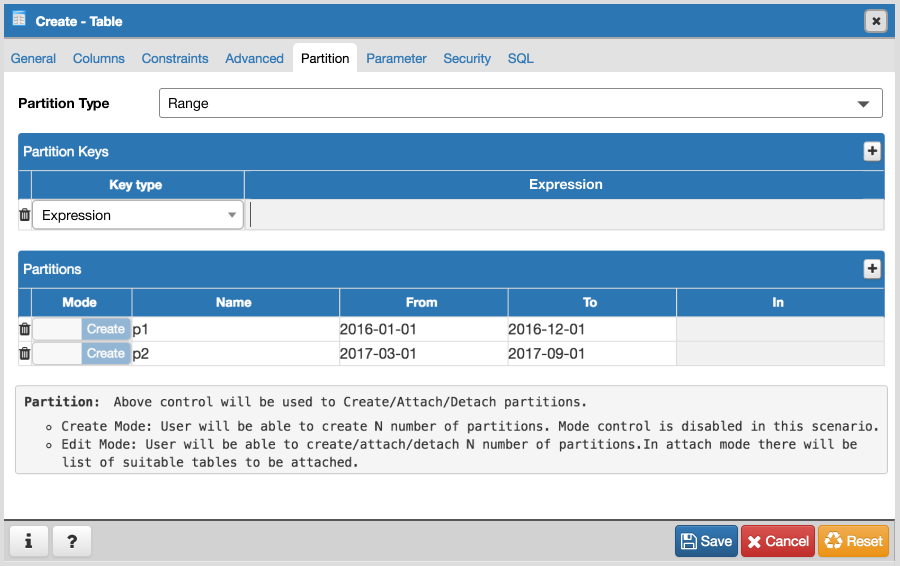
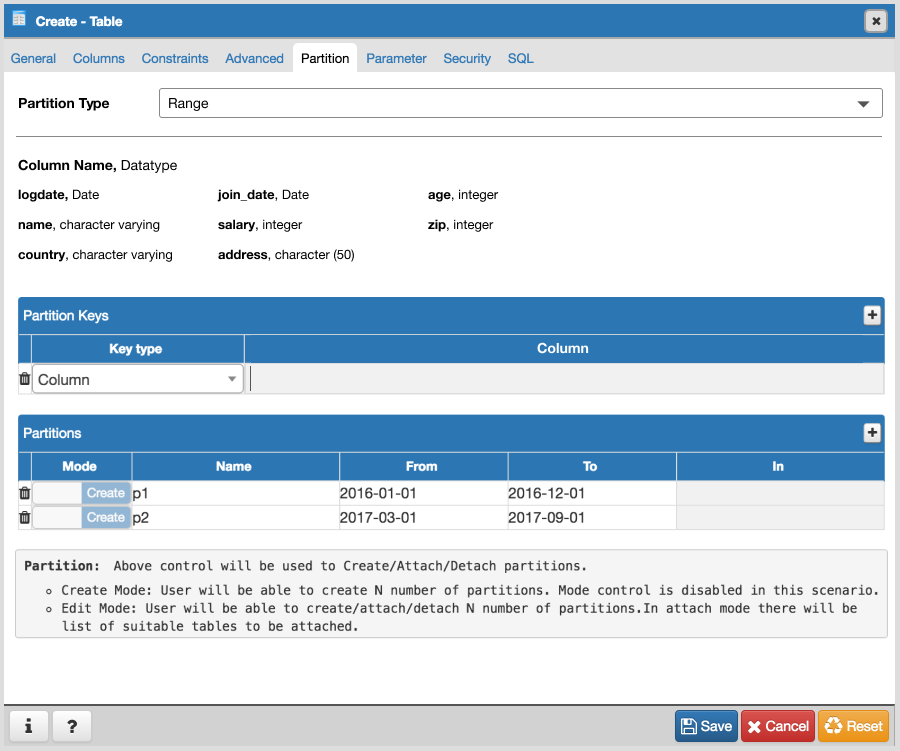
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
Hi Harshal,
These are initial review comments.
1.
Please share a separate patch for generic code changes from this patch for the following files:
- web/pgadmin/tools/user_management/templates/user_management/js/user_management.js
- web/pgadmin/static/js/backform.pgadmin.js
- web/pgadmin/static/js/backgrid.pgadmin.js
This should be committed as separate functionality, and should not be part of this commit.
2.
Please put a space after a colon (:) in javascript object definition.
i.e.
{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'}
3.
Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.
Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.
I will keep you posted for further review comments.
On Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote:
Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.
On Thu, Jun 29, 2017 at 5:02 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com
Hi Harshal,These are initial review comments.1.Please share a separate patch for generic code changes from this patch for the following files:- web/pgadmin/tools/user_management/templates/user_management/ js/user_management.js - web/pgadmin/static/js/backform.pgadmin.js - web/pgadmin/static/js/backgrid.pgadmin.js This should be committed as separate functionality, and should not be part of this commit.2.Please put a space after a colon (:) in javascript object definition.i.e.{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'} 3.Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.I will keep you posted for further review comments.
4.
URL definition of the javascript for tables & partition tables utility must be exposed from the table/partition table module, and not from the database module.
i.e.
No changes should be done in the database module for this feature. Hence - I don't expect any change in the file:
web/pgadmin/browser/server_groups/servers/databases/__init__.py
-- Thanks, Ashesh
On Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.
Hi Ashesh
--
On Fri, Jun 30, 2017 at 12:46 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:
On Thu, Jun 29, 2017 at 5:02 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: Hi Harshal,These are initial review comments.1.Please share a separate patch for generic code changes from this patch for the following files:- web/pgadmin/tools/user_management/templates/user_management/ js/user_management.js - web/pgadmin/static/js/backform.pgadmin.js - web/pgadmin/static/js/backgrid.pgadmin.js This should be committed as separate functionality, and should not be part of this commit.
Committed.
2.Please put a space after a colon (:) in javascript object definition.i.e.{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'} 3.Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.I will keep you posted for further review comments.
4.URL definition of the javascript for tables & partition tables utility must be exposed from the table/partition table module, and not from the database module.i.e.No changes should be done in the database module for this feature. Hence - I don't expect any change in the file:web/pgadmin/browser/server_groups/servers/databases/__ init__.py
Fixed.
Apart from above this patch contains test cases as well.
-- Thanks, AsheshOn Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.


Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
Hi Akshay,
I found couple of issues, and fixed them in the updated patch.
- Validation issue resolved
- Disable "Is primary key?" in columns subnode for partitioned table.
Review comments:
- Add note about - what value is expected in 'from', and 'to' field. Please add an example in the note.
- PostgreSQL allows to create partioned table using 'OF TYPE'.
- We should add collation, and opclass for 'partition by statement (We can do this later).
- Refresh the browser tree after creating, attaching, and detaching the partitions.
-- Thanks, Ashesh
On Mon, Jul 3, 2017 at 3:14 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AsheshOn Fri, Jun 30, 2017 at 12:46 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Thu, Jun 29, 2017 at 5:02 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: Hi Harshal,These are initial review comments.1.Please share a separate patch for generic code changes from this patch for the following files:- web/pgadmin/tools/user_management/templates/user_management/ js/user_management.js - web/pgadmin/static/js/backform.pgadmin.js - web/pgadmin/static/js/backgrid.pgadmin.js This should be committed as separate functionality, and should not be part of this commit.Committed.2.Please put a space after a colon (:) in javascript object definition.i.e.{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'} 3.Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.I will keep you posted for further review comments.4.URL definition of the javascript for tables & partition tables utility must be exposed from the table/partition table module, and not from the database module.i.e.No changes should be done in the database module for this feature. Hence - I don't expect any change in the file:web/pgadmin/browser/server_groups/servers/databases/__init__ .py Fixed.Apart from above this patch contains test cases as well.-- Thanks, AsheshOn Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246

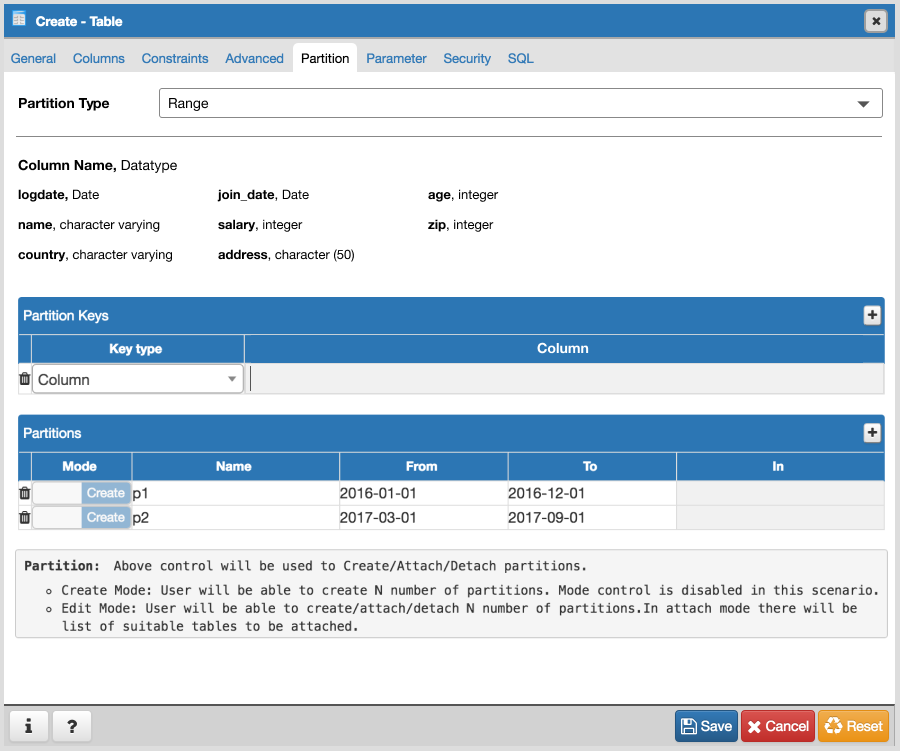
Attachment
Hi Akshay,
Please find the patch, generated using the 'git --binary' command for inclusion of the icons.
On Tue, Jul 4, 2017 at 11:35 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:
Hi Akshay,I found couple of issues, and fixed them in the updated patch.- Validation issue resolved- Disable "Is primary key?" in columns subnode for partitioned table.Review comments:- Add note about - what value is expected in 'from', and 'to' field. Please add an example in the note.- PostgreSQL allows to create partioned table using 'OF TYPE'.- We should add collation, and opclass for 'partition by statement (We can do this later).- Refresh the browser tree after creating, attaching, and detaching the partitions.-- Thanks, AsheshOn Mon, Jul 3, 2017 at 3:14 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AsheshOn Fri, Jun 30, 2017 at 12:46 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Thu, Jun 29, 2017 at 5:02 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: Hi Harshal,These are initial review comments.1.Please share a separate patch for generic code changes from this patch for the following files:- web/pgadmin/tools/user_management/templates/user_management/ js/user_management.js - web/pgadmin/static/js/backform.pgadmin.js - web/pgadmin/static/js/backgrid.pgadmin.js This should be committed as separate functionality, and should not be part of this commit.Committed.2.Please put a space after a colon (:) in javascript object definition.i.e.{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'} 3.Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.I will keep you posted for further review comments.4.URL definition of the javascript for tables & partition tables utility must be exposed from the table/partition table module, and not from the database module.i.e.No changes should be done in the database module for this feature. Hence - I don't expect any change in the file:web/pgadmin/browser/server_groups/servers/databases/__init__ .py Fixed.Apart from above this patch contains test cases as well.-- Thanks, AsheshOn Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246


Attachment
Hi Ashesh
--
On Tue, Jul 4, 2017 at 11:35 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:
Hi Akshay,I found couple of issues, and fixed them in the updated patch.- Validation issue resolved- Disable "Is primary key?" in columns subnode for partitioned table.Review comments:- Add note about - what value is expected in 'from', and 'to' field. Please add an example in the note.
Fixed.
- PostgreSQL allows to create partioned table using 'OF TYPE'.
I have tried to add support of the above, but there are couple of issues in existing functionality. I'll create one RM case for this. Once that is fixed, I'll add support.
- We should add collation, and opclass for 'partition by statement (We can do this later).
It requires some R&D, so we will add it later.
- Refresh the browser tree after creating, attaching, and detaching the partitions.
As per our discussion, I have modified the logic and return oid and schema id for all the created/attached/detached partitions.
Attached is the latest patch, can you please review it.
-- Thanks, AsheshOn Mon, Jul 3, 2017 at 3:14 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AsheshOn Fri, Jun 30, 2017 at 12:46 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Thu, Jun 29, 2017 at 5:02 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: Hi Harshal,These are initial review comments.1.Please share a separate patch for generic code changes from this patch for the following files:- web/pgadmin/tools/user_management/templates/user_management/ js/user_management.js - web/pgadmin/static/js/backform.pgadmin.js - web/pgadmin/static/js/backgrid.pgadmin.js This should be committed as separate functionality, and should not be part of this commit.Committed.2.Please put a space after a colon (:) in javascript object definition.i.e.{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'} 3.Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.I will keep you posted for further review comments.4.URL definition of the javascript for tables & partition tables utility must be exposed from the table/partition table module, and not from the database module.i.e.No changes should be done in the database module for this feature. Hence - I don't expect any change in the file:web/pgadmin/browser/server_groups/servers/databases/__init__ .py Fixed.Apart from above this patch contains test cases as well.-- Thanks, AsheshOn Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246
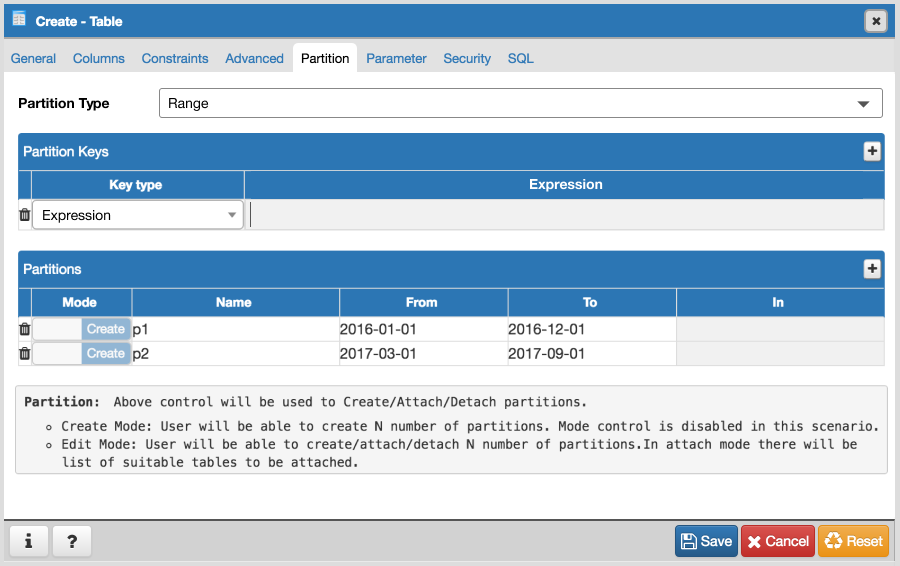

Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
On Mon, Jul 3, 2017 at 3:14 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
Hi AsheshOn Fri, Jun 30, 2017 at 12:46 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Thu, Jun 29, 2017 at 5:02 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: Hi Harshal,These are initial review comments.1.Please share a separate patch for generic code changes from this patch for the following files:- web/pgadmin/tools/user_management/templates/user_management/ js/user_management.js - web/pgadmin/static/js/backform.pgadmin.js - web/pgadmin/static/js/backgrid.pgadmin.js This should be committed as separate functionality, and should not be part of this commit.Committed.2.Please put a space after a colon (:) in javascript object definition.i.e.{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'} 3.Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.I will keep you posted for further review comments.4.URL definition of the javascript for tables & partition tables utility must be exposed from the table/partition table module, and not from the database module.i.e.No changes should be done in the database module for this feature. Hence - I don't expect any change in the file:web/pgadmin/browser/server_groups/servers/databases/__init__ .py Fixed.Apart from above this patch contains test cases as well.
One bug:
If I rename the partitioned table from the properties dialog, and attach a partition at the same time, then - it generates wrong modified queries.
-- Thanks, Ashesh
-- Thanks, AsheshOn Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246
On Tue, Jul 4, 2017 at 3:59 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:
On Mon, Jul 3, 2017 at 3:14 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AsheshOn Fri, Jun 30, 2017 at 12:46 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Thu, Jun 29, 2017 at 5:02 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: Hi Harshal,These are initial review comments.1.Please share a separate patch for generic code changes from this patch for the following files:- web/pgadmin/tools/user_management/templates/user_management/ js/user_management.js - web/pgadmin/static/js/backform.pgadmin.js - web/pgadmin/static/js/backgrid.pgadmin.js This should be committed as separate functionality, and should not be part of this commit.Committed.2.Please put a space after a colon (:) in javascript object definition.i.e.{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'} 3.Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.I will keep you posted for further review comments.4.URL definition of the javascript for tables & partition tables utility must be exposed from the table/partition table module, and not from the database module.i.e.No changes should be done in the database module for this feature. Hence - I don't expect any change in the file:web/pgadmin/browser/server_groups/servers/databases/__init__ .py Fixed.Apart from above this patch contains test cases as well.One bug:If I rename the partitioned table from the properties dialog, and attach a partition at the same time, then - it generates wrong modified queries.
Fixed. Attached is the latest patch
-- Thanks, Ashesh-- Thanks, AsheshOn Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246


Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246
Attachment
Hi Akshay,
Please find the updated patch with the refresh logic.
Please create redmine cases for the following todos:
- PostgreSQL allows to create partioned table using 'OF TYPE'.
- We should add collation, and opclass for 'partition by statement.
- Allow to attach/create/detach partitions on the partition table directly, open the subcontrol in dialog for the same. (We support detaching an individual partitions, not the bulk operation.)
Please review it, and commit it (if possible).
On Tue, Jul 4, 2017 at 5:42 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote:
On Tue, Jul 4, 2017 at 3:59 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Jul 3, 2017 at 3:14 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AsheshOn Fri, Jun 30, 2017 at 12:46 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Thu, Jun 29, 2017 at 5:02 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: Hi Harshal,These are initial review comments.1.Please share a separate patch for generic code changes from this patch for the following files:- web/pgadmin/tools/user_management/templates/user_management/ js/user_management.js - web/pgadmin/static/js/backform.pgadmin.js - web/pgadmin/static/js/backgrid.pgadmin.js This should be committed as separate functionality, and should not be part of this commit.Committed.2.Please put a space after a colon (:) in javascript object definition.i.e.{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'} 3.Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.I will keep you posted for further review comments.4.URL definition of the javascript for tables & partition tables utility must be exposed from the table/partition table module, and not from the database module.i.e.No changes should be done in the database module for this feature. Hence - I don't expect any change in the file:web/pgadmin/browser/server_groups/servers/databases/__init__ .py Fixed.Apart from above this patch contains test cases as well.One bug:If I rename the partitioned table from the properties dialog, and attach a partition at the same time, then - it generates wrong modified queries.Fixed. Attached is the latest patch-- Thanks, Ashesh-- Thanks, AsheshOn Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246


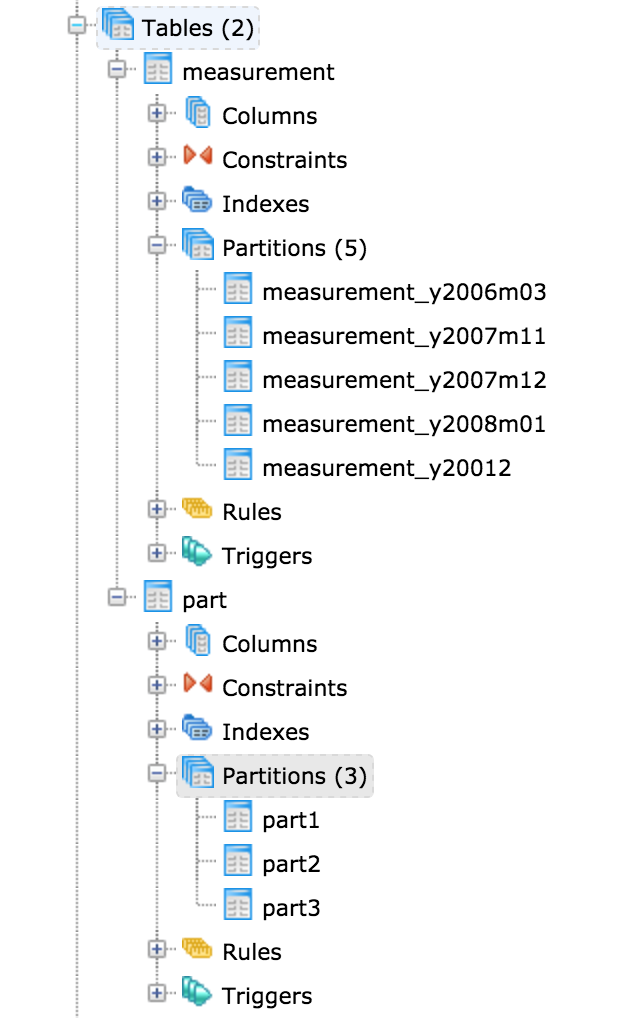{kind=link}
{kind=link}
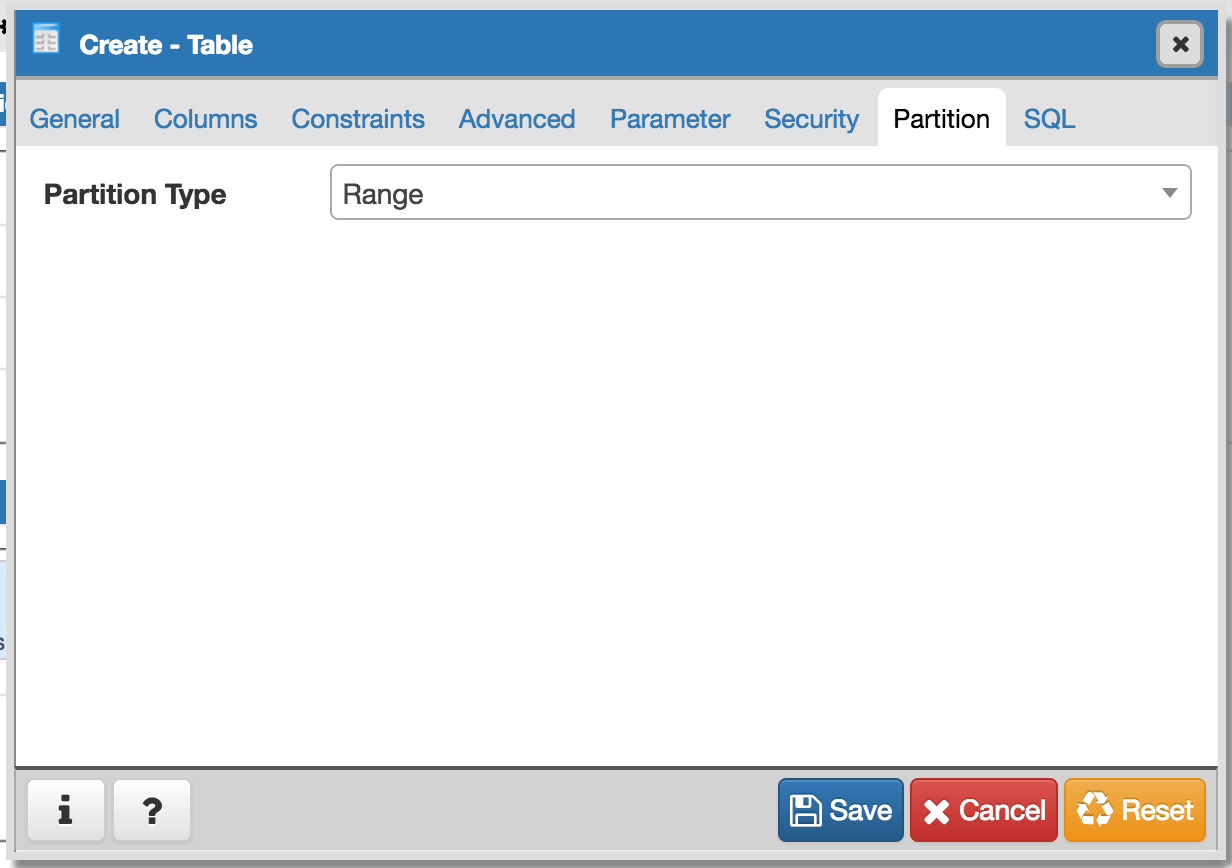{kind=link}
{kind=link}
{kind=link}
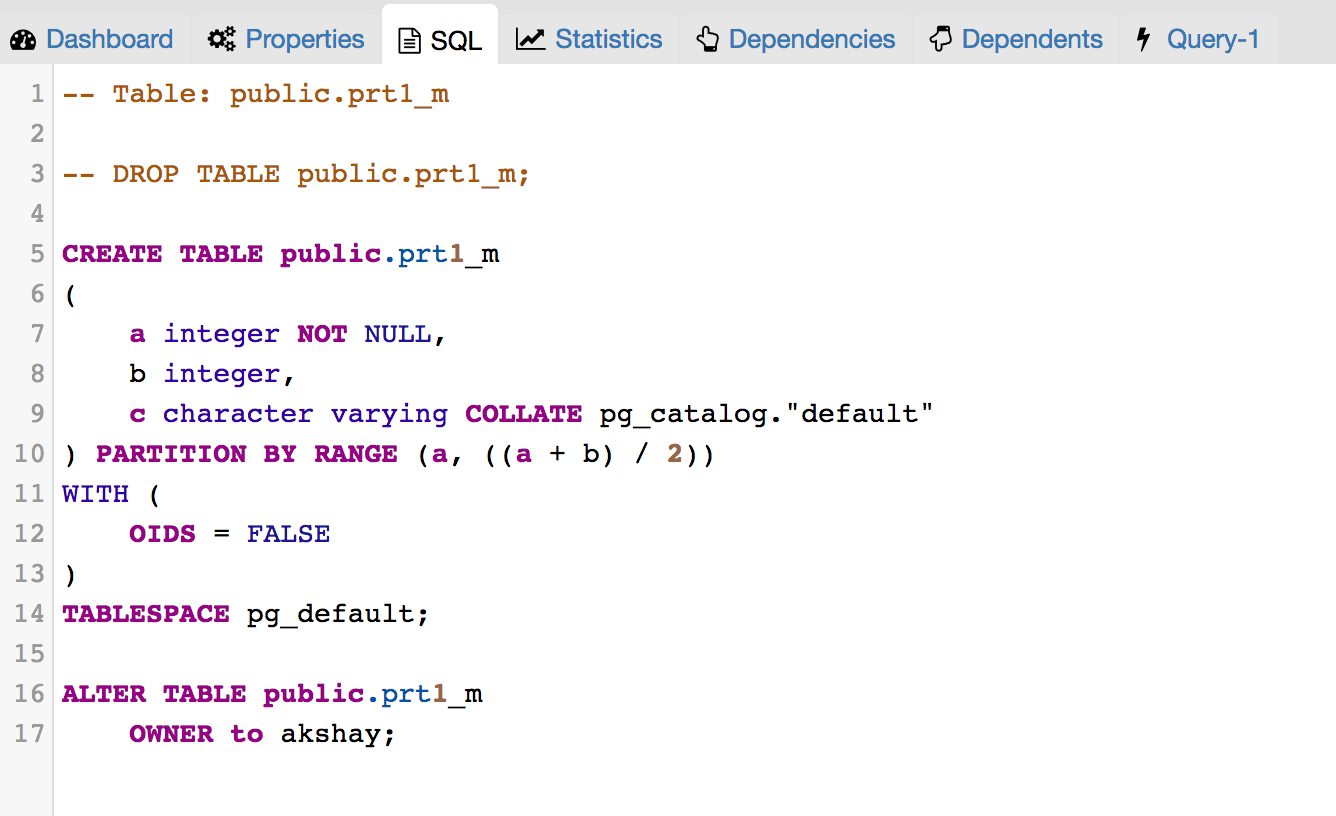{kind=link}
{kind=link}
{kind=link}
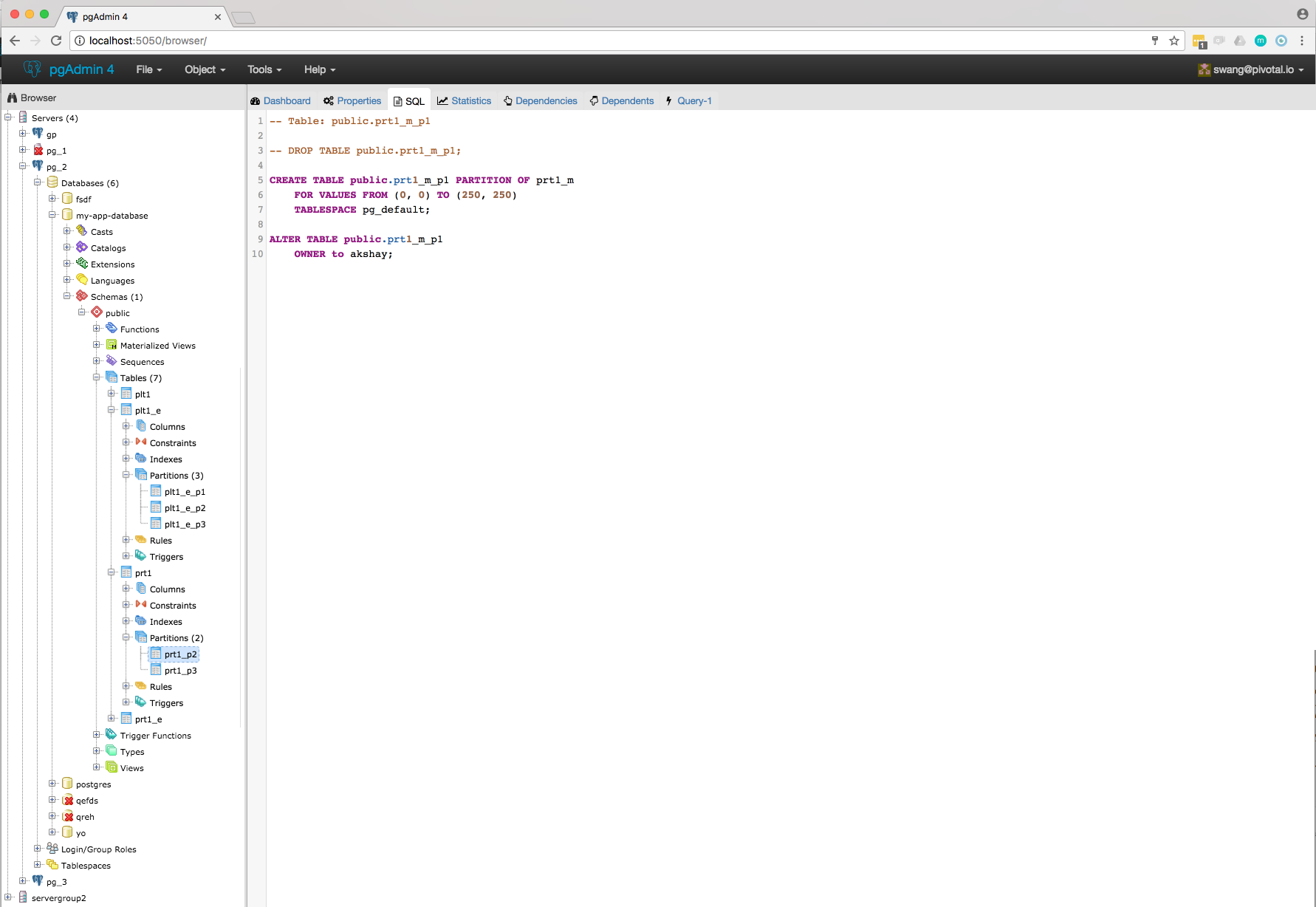{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
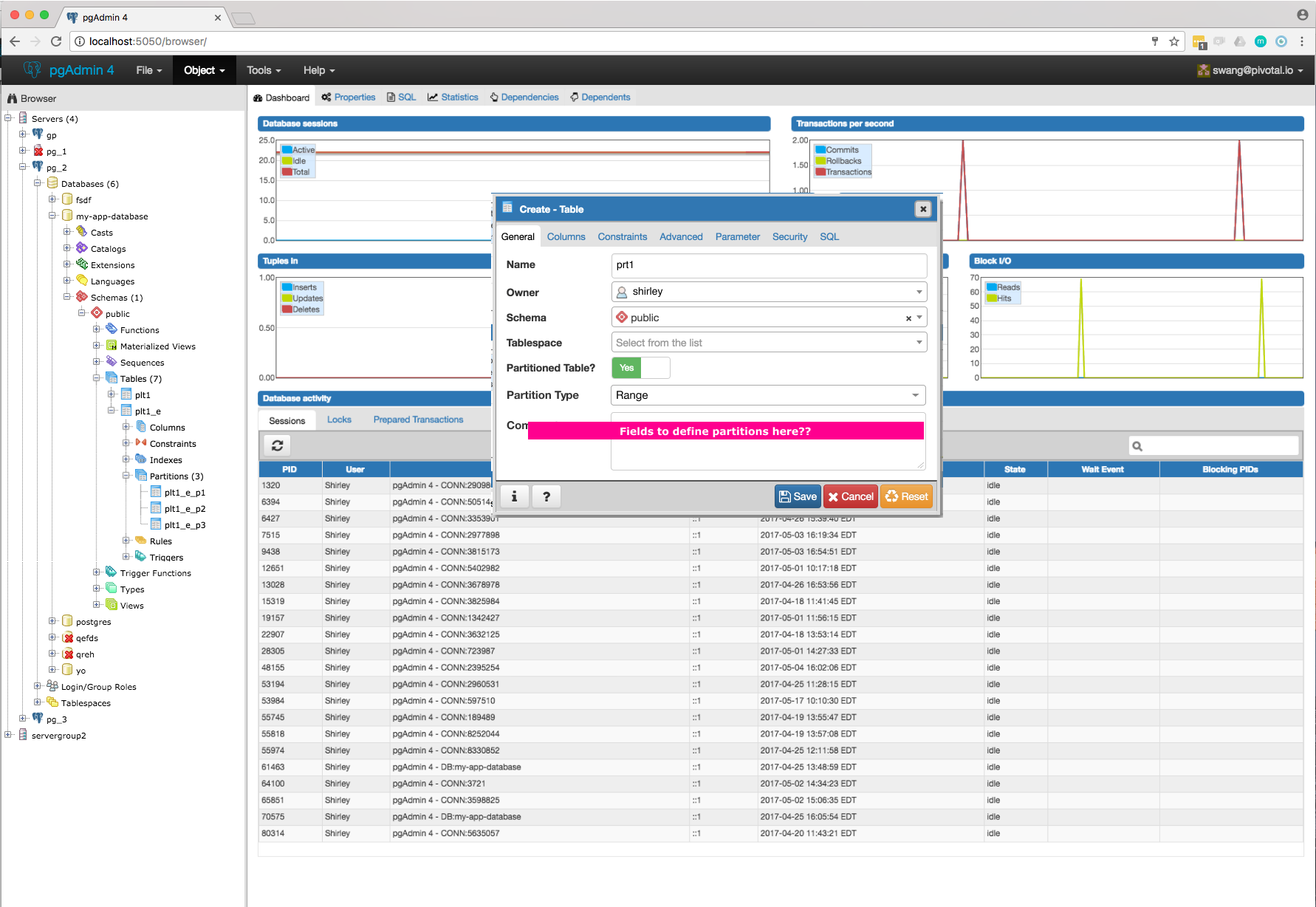{kind=link}
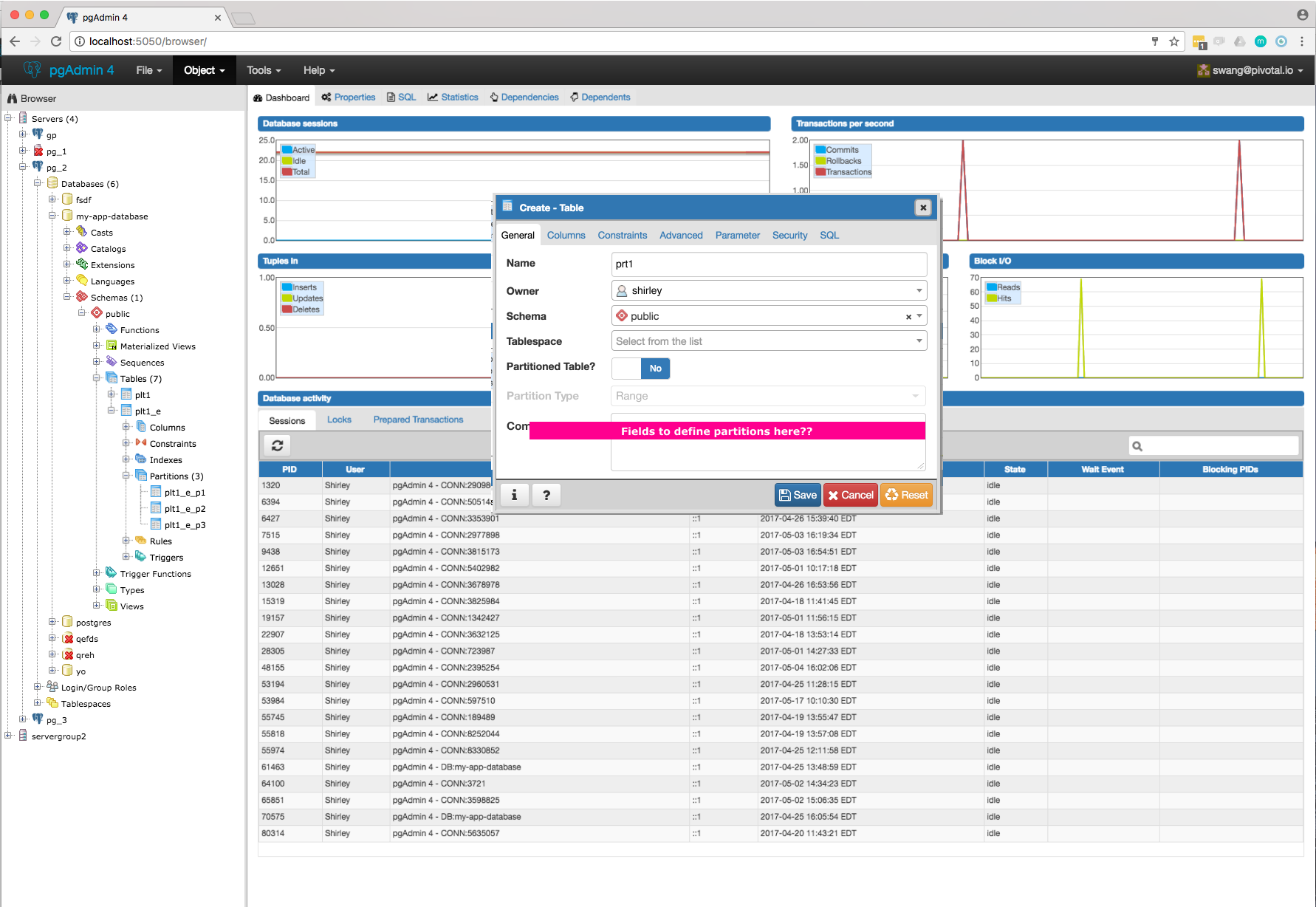{kind=link}
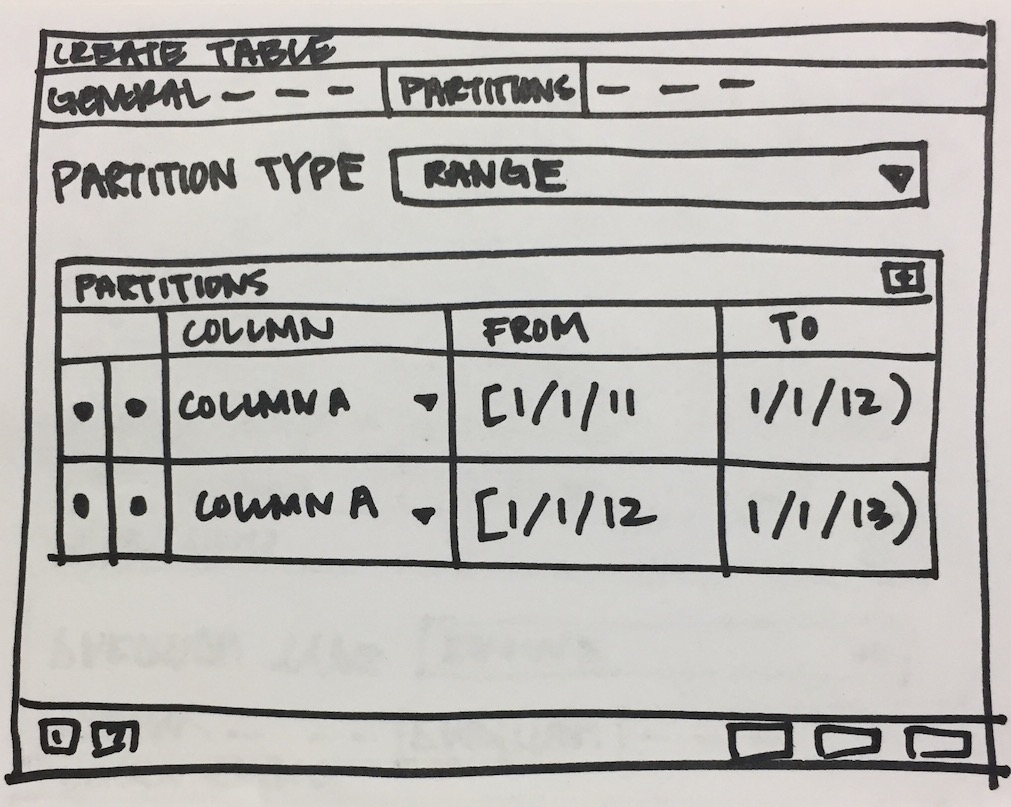{kind=link}
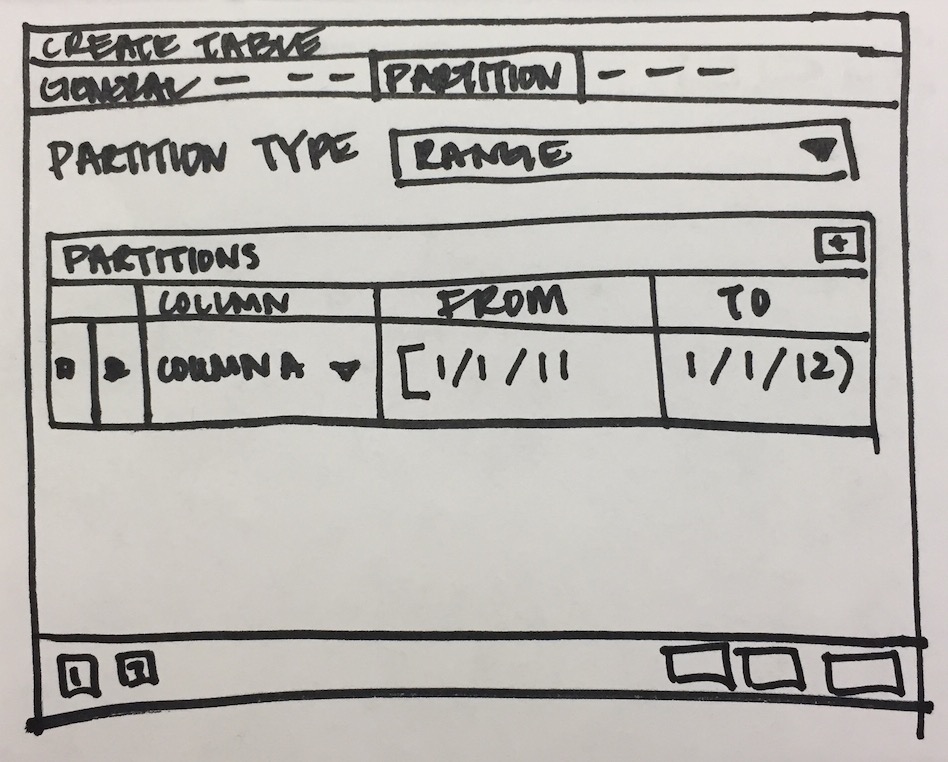{kind=link}
{kind=link}
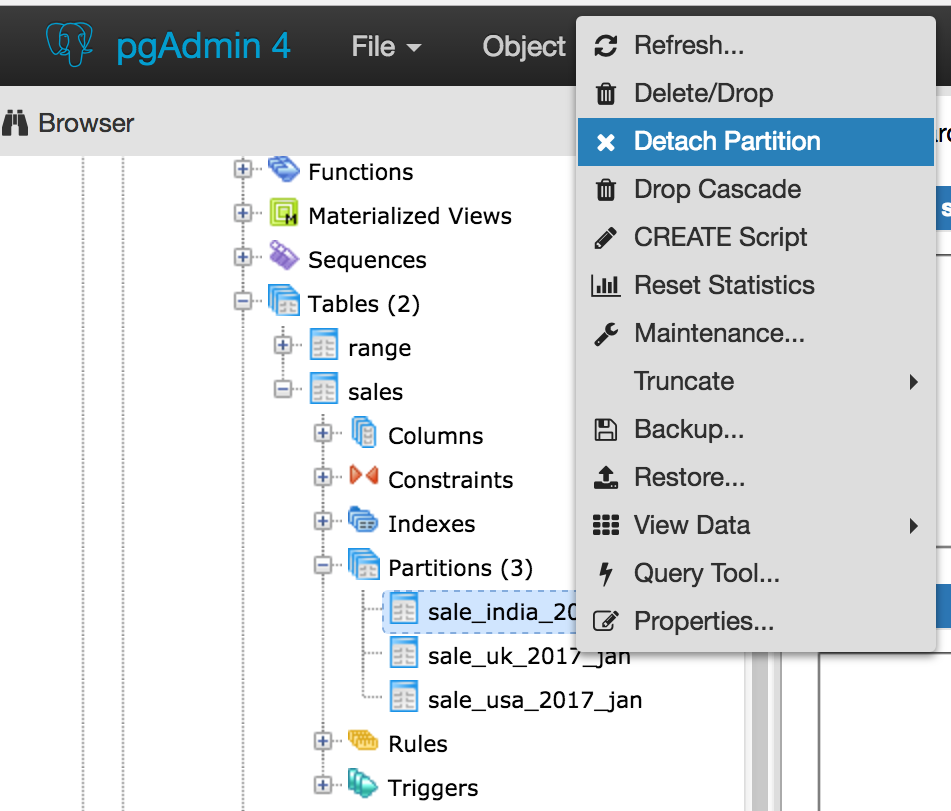{kind=link}
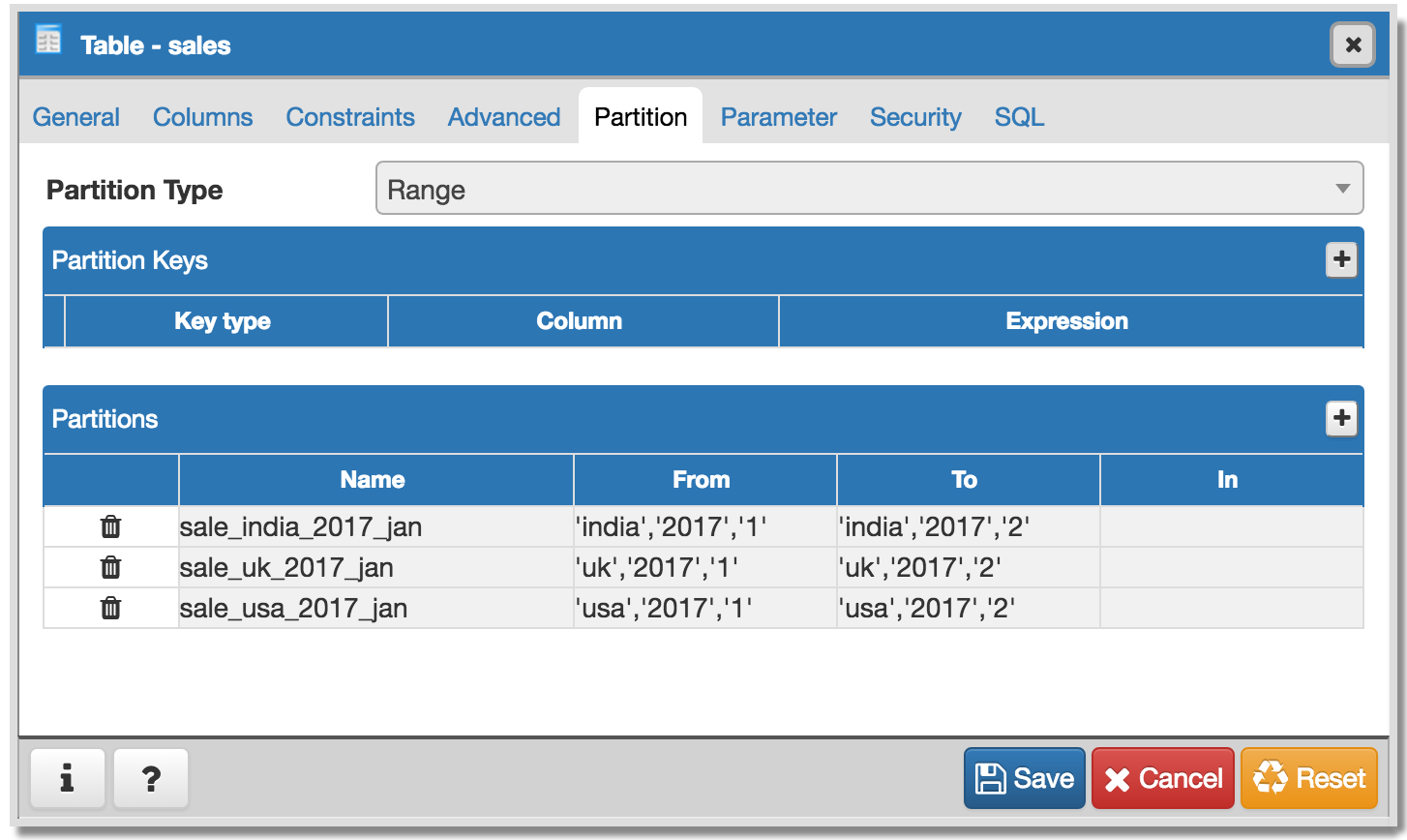{kind=link}
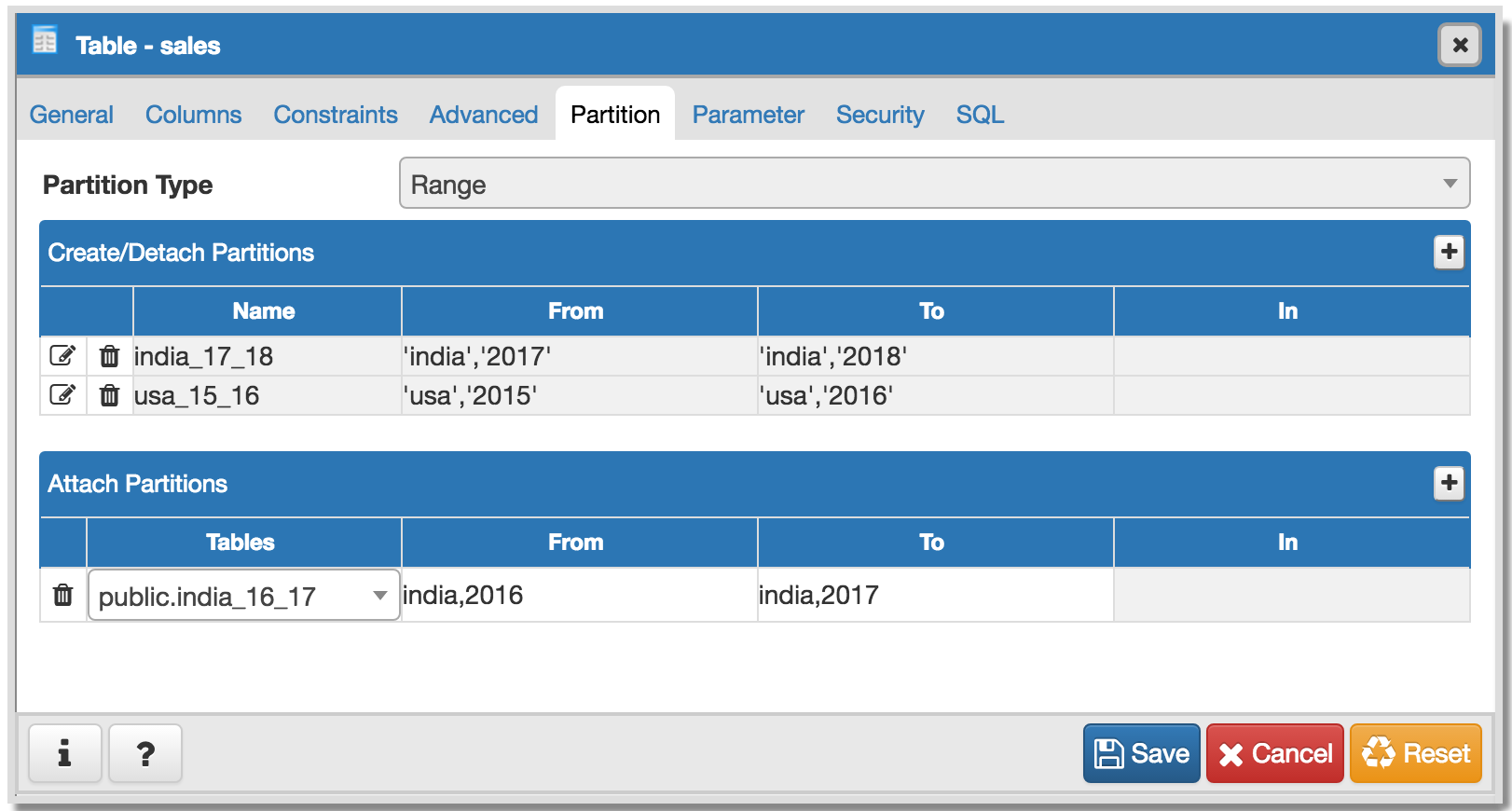{kind=link}
{kind=link}
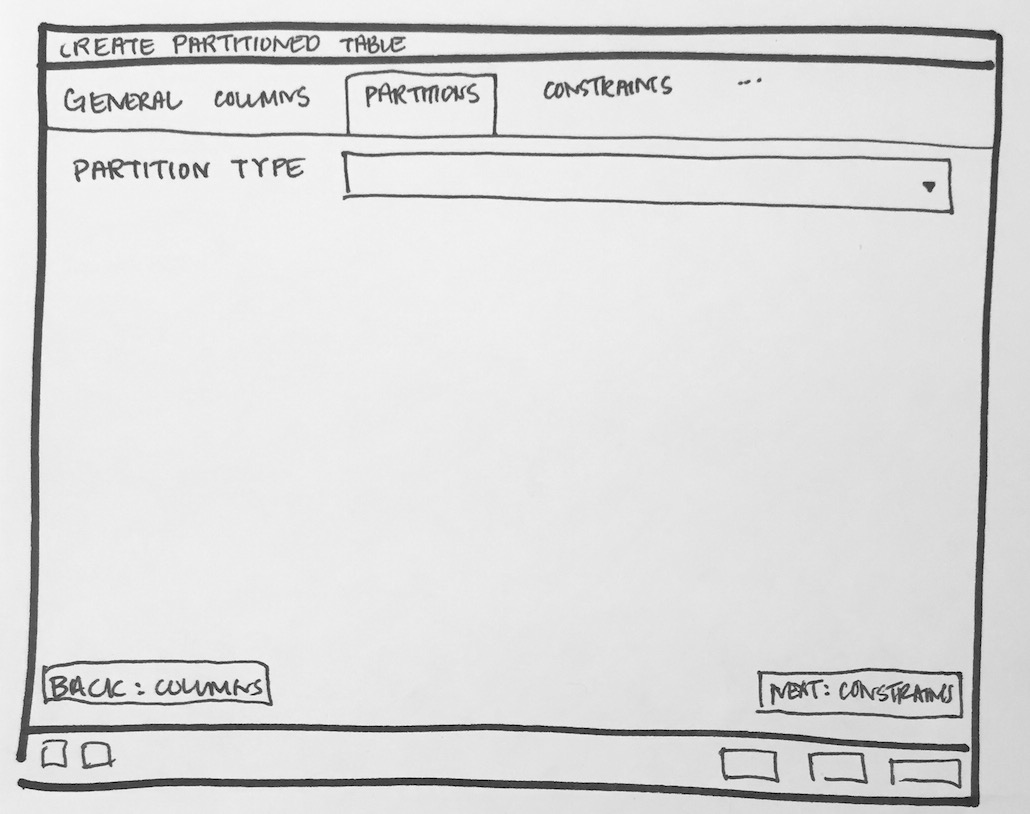{kind=link}
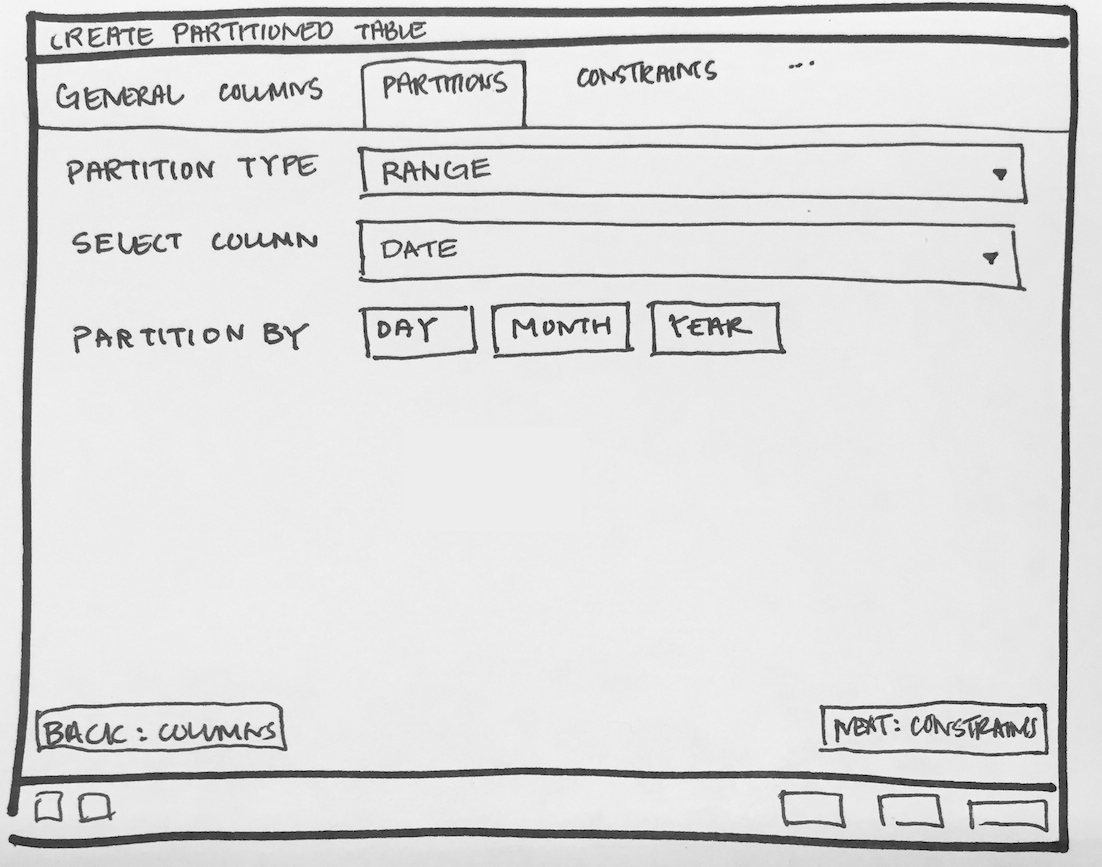{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
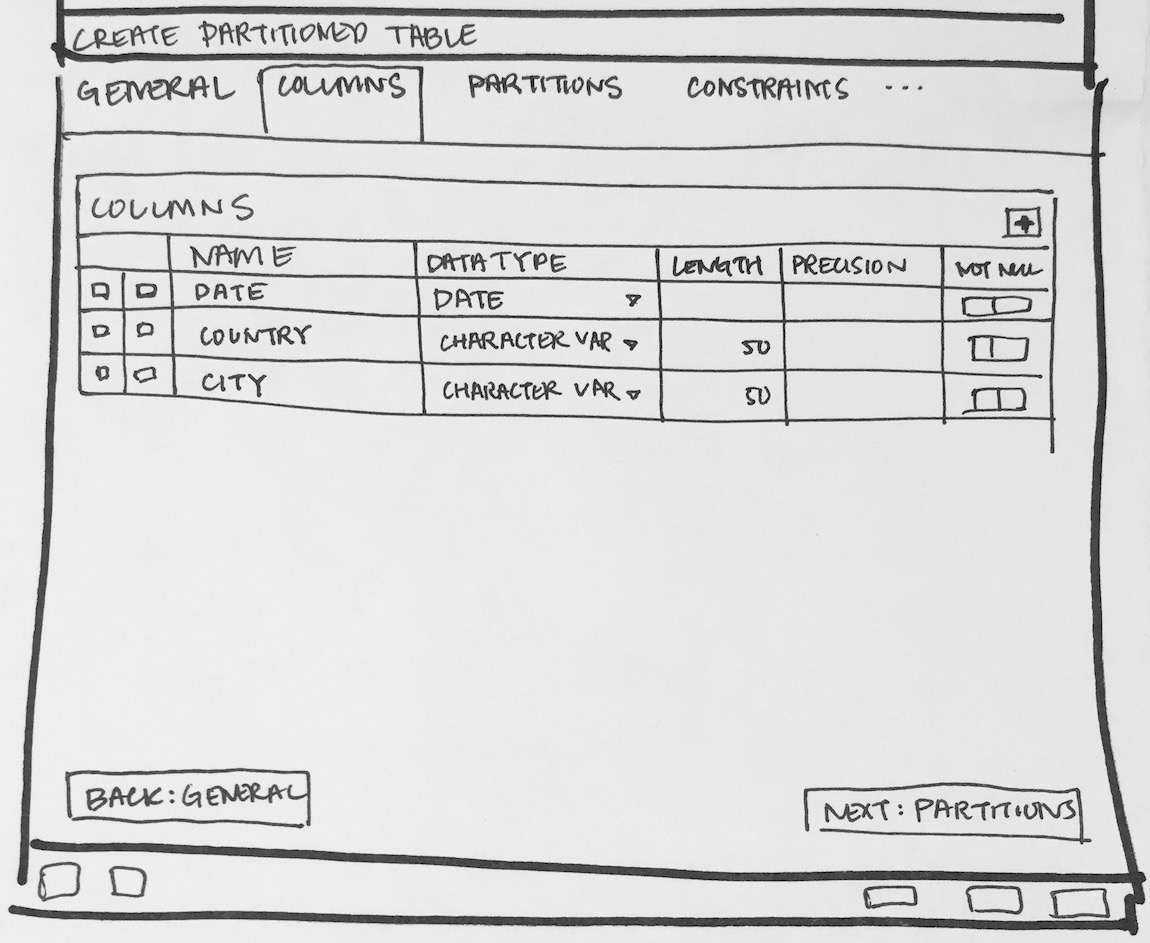{kind=link}
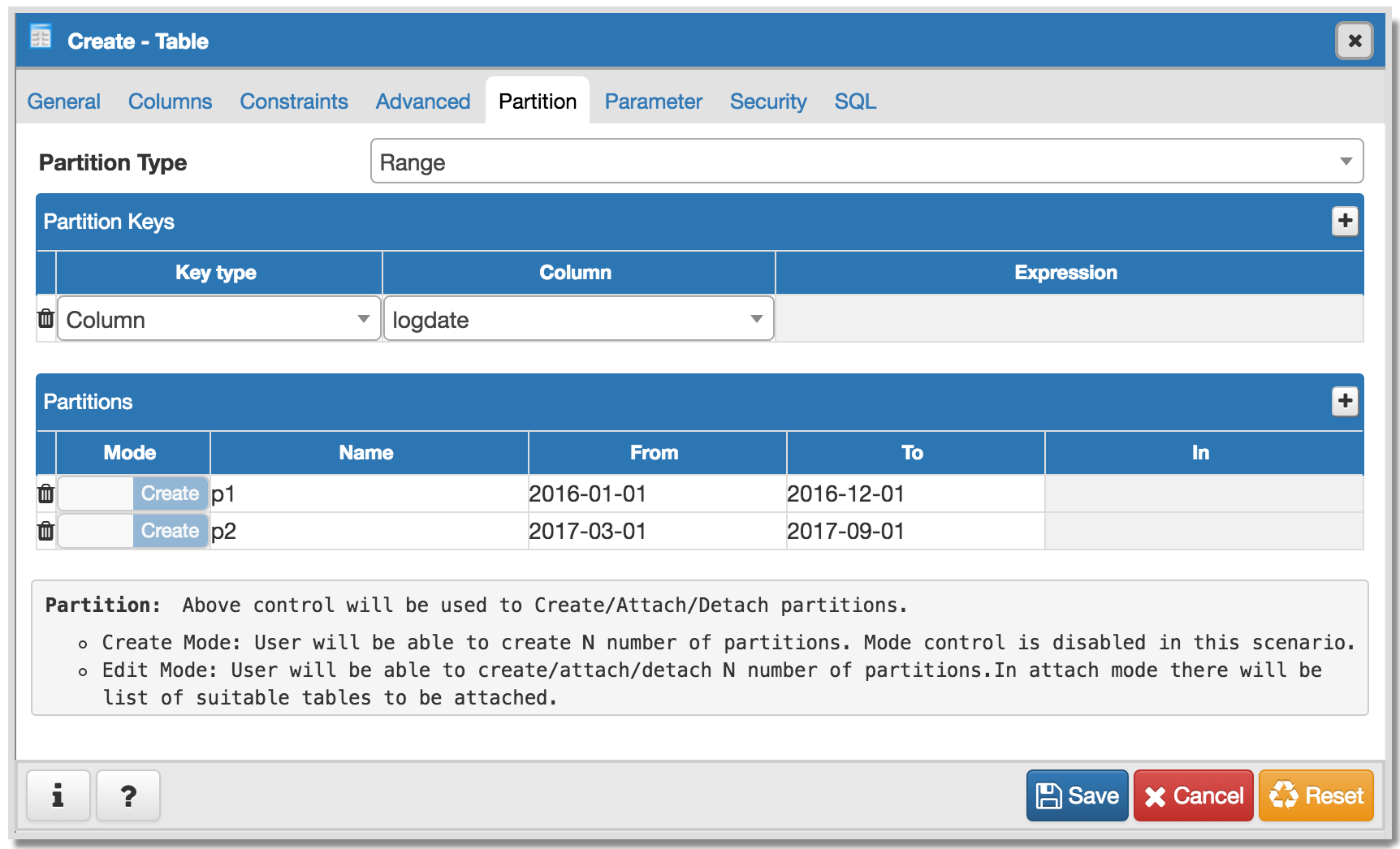{kind=link}
{kind=link}
Attachment
Hi Ashesh
--
On Fri, Jul 7, 2017 at 9:01 AM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:
Hi Akshay,Please find the updated patch with the refresh logic.Please create redmine cases for the following todos:- PostgreSQL allows to create partioned table using 'OF TYPE'.- We should add collation, and opclass for 'partition by statement.- Allow to attach/create/detach partitions on the partition table directly, open the subcontrol in dialog for the same. (We support detaching an individual partitions, not the bulk operation.)
We are supporting detach as bulk operation from parent table. I'll create RM's for the above todo's.
Please review it, and commit it (if possible).
Code looks good to me. I have committed the code.
Thanks Harshal and Ashesh for your support to finish this feature.
On Tue, Jul 4, 2017 at 5:42 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: On Tue, Jul 4, 2017 at 3:59 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Mon, Jul 3, 2017 at 3:14 PM, Akshay Joshi <akshay.joshi@enterprisedb.com> wrote: Hi AsheshOn Fri, Jun 30, 2017 at 12:46 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: On Thu, Jun 29, 2017 at 5:02 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: Hi Harshal,These are initial review comments.1.Please share a separate patch for generic code changes from this patch for the following files:- web/pgadmin/tools/user_management/templates/user_management/ js/user_management.js - web/pgadmin/static/js/backform.pgadmin.js - web/pgadmin/static/js/backgrid.pgadmin.js This should be committed as separate functionality, and should not be part of this commit.Committed.2.Please put a space after a colon (:) in javascript object definition.i.e.{cell: Backgrid.Extension.StringDepCell, cellHeaderClasses: 'width_percent_30'} 3.Conversion of ptid (partition table OID) to tid (table OID) for its children must not be in 'web/pgadmin/browser/utils.py' file.Please create a inherited class of PGChildNodeView, and extend the functionality in it, and use it as the base class for all children of table.I will keep you posted for further review comments.4.URL definition of the javascript for tables & partition tables utility must be exposed from the table/partition table module, and not from the database module.i.e.No changes should be done in the database module for this feature. Hence - I don't expect any change in the file:web/pgadmin/browser/server_groups/servers/databases/__init__ .py Fixed.Apart from above this patch contains test cases as well.One bug:If I rename the partitioned table from the properties dialog, and attach a partition at the same time, then - it generates wrong modified queries.Fixed. Attached is the latest patch-- Thanks, Ashesh-- Thanks, AsheshOn Fri, Jun 23, 2017 at 6:55 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: Hi,Please find attached patch for partition support.This patch includes all the work done by Akashy and support for child nodes (constraints, rules, index, triggers and partition itself ) under partition node.Thanks,--Harshal DhumalSr. Software EngineerOn Tue, Jun 20, 2017 at 12:16 AM, Shirley Wang <swang@pivotal.io> wrote:On Fri, Jun 16, 2017 at 11:16 PM, Shirley Wang <swang@pivotal.io> wrote:Looks good. I noticed people clicking back and forth to the columns tab to remember which columns they've created while filling out the Expressions column. It might be better to have a list of the columns and the datatype above the 'Partition Keys' subnode and have columns as a type field rather than a drop down.I think we should not duplicate that data as we already have all the information on "Columns" tab and by providing drop down user can select columns from there only.Also, I think the fields someone sees after selecting the Key type needs to depend on what they select. Seeing both Column and Expressions type field might lead someone to think they need to fill out both fields.We can't, because user can select one column and provide an expression as partition key in this case we will have to show both the columns in subnode control. Anyways when user select columns I have disabled the expression cell and if user selects expression column cell is disabled.Ah I see what you mean. What I meant was that the column would change depending on if someone selects Column or Expressions from the dropdownCan a user select more than one key type? The use case I can see where hiding 'Columns' or 'Expressions' would fail is if someone can create an expression key type and a column key type.Disabling a feature is one way to guide user behavior, but it doesn't provide enough context for someone to understand why it's disabled. It's better to only display what is absolutely necessary and hide fields that are unrelated to the workflow.Typically, disabling a UI element is useful when that disabled UI element also provides some context or value while disabled. In this case, I'm not sure it is.If hiding options isn't possible, providing some text in the fields (like N/A or --) would be helpful.When is the 'In' column in the Partitions subnode enabled?In case of 'List' Partition.It would improve the experience if the 'In' column was removed when a user selects 'Range' partitions then. And then if a user is creating a 'List' partition, 'From/To' should be hidden. In this case, 'From/To' and 'In' are dependent on that first drop down step, so seeing 'In' while on 'Range partitions' (and 'From/To' on 'List partitions') is not providing any value.For the NoteControl on the bottom, what do 'Mode Control' or 'Attach Mode' refer to? And how can I tell the difference between 'Create Mode' and 'Edit Mode'?'Mode control' is a switch control in subnode control that should be "Mode switch control". 'Create Mode' is when user creates the new table by clicking create-> table and 'Edit Mode' is when user open the properties dialog for the existing table. In case of 'Edit Mode' there are two ways user can create/attach partitions. In Attach mode we will identify and list down the suitable tables to be attached.I see. Describing these various states is great in case a user needs it. What are your thoughts on having it live in the documentation of pgAdmin4 rather than in the dialog? This seems to be the established pattern for all other explanations.--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246--Akshay JoshiPrincipal Software EngineerPhone: +91 20-3058-9517
Mobile: +91 976-788-8246
Akshay Joshi
Principal Software Engineer
Phone: +91 20-3058-9517
Mobile: +91 976-788-8246
Mobile: +91 976-788-8246