Thread: Excessive memory used for INSERT
Hi,
Software and hardware running postgresql are:
- postgresql92-9.2.3-1.1.1.x86_64
- openSuSE 12.3 x64_86
- 16 GB of RAM
- 2 GB of swap
- 8-core Intel(R) Xeon(R) CPU E5-2407 0 @ 2.20GHz
- ext4 filesystem hold on a hardware Dell PERC H710 RAID10 with 4x4TB SATA HDs.
- 2 GB of RAM are reserved for a virtual machine.
The single database used was created by
CREATE FUNCTION msg_function() RETURNS trigger
LANGUAGE plpgsql
AS $_$ DECLARE _tablename text; _date text; _slot timestamp; BEGIN _slot := NEW.slot; _date := to_char(_slot, 'YYYY-MM-DD'); _tablename := 'MSG_'||_date; PERFORM 1 FROM pg_catalog.pg_class c JOIN pg_catalog.pg_namespace n ON n.oid = c.relnamespace WHERE c.relkind = 'r' AND c.relname = _tablename AND n.nspname = 'public'; IF NOT FOUND THEN EXECUTE 'CREATE TABLE public.' || quote_ident(_tablename) || ' ( ) INHERITS (public.MSG)'; EXECUTE 'ALTER TABLE public.' || quote_ident(_tablename) || ' OWNER TO seviri'; EXECUTE 'GRANT ALL ON TABLE public.' || quote_ident(_tablename) || ' TO seviri'; EXECUTE 'ALTER TABLE ONLY public.' || quote_ident(_tablename) || ' ADD CONSTRAINT ' || quote_ident(_tablename||'_pkey') || ' PRIMARY KEY (slot,msg)'; END IF; EXECUTE 'INSERT INTO public.' || quote_ident(_tablename) || ' VALUES ($1.*)' USING NEW; RETURN NULL; END; $_$;
CREATE TABLE msg (
slot timestamp(0) without time zone NOT NULL,
msg integer NOT NULL,
hrv bytea,
vis006 bytea,
vis008 bytea,
ir_016 bytea,
ir_039 bytea,
wv_062 bytea,
wv_073 bytea,
ir_087 bytea,
ir_097 bytea,
ir_108 bytea,
ir_120 bytea,
ir_134 bytea,
pro bytea,
epi bytea,
clm bytea,
tape character varying(10)
);
Basically, this database consists of daily tables with the date stamp appended in their names, i.e.
MSG_YYYY-MM-DD and a global table MSG linked to these tables allowing to list all the records.
A cron script performing a single insert (upsert, see log excerpt below) runs every 15 minutes and
never had any issue.
However, I also need to submit historical records. This is achieved by a bash script parsing a text file
and building insert commands which are submitted 10 at a time to the database using psql through a
temp file in a BEGIN; ...; COMMIT block. When running this script, I noticed that the INSERT
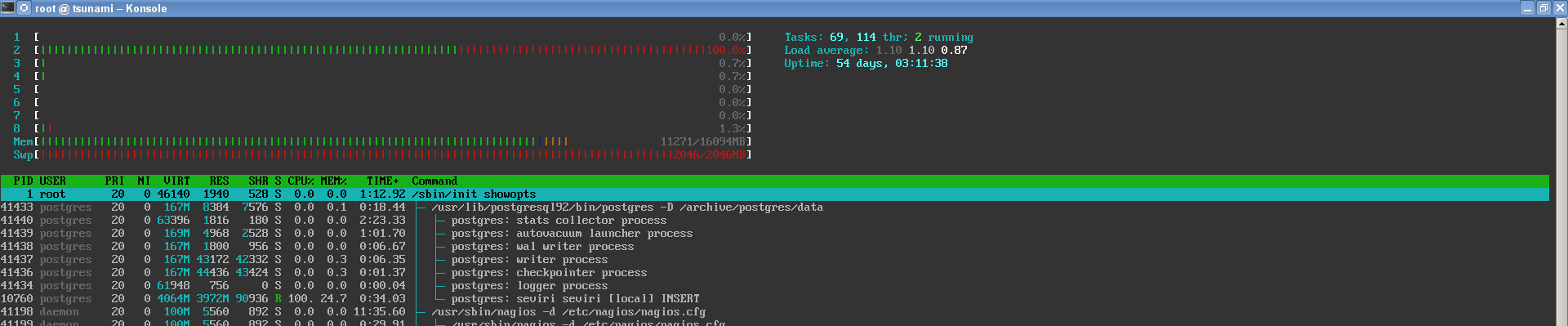
subprocess can reached around 4GB of memory using htop (see attached screenshot). After a while,
the script inevitably crashes with the following messages
psql:/tmp/tmp.a0ZrivBZhD:10: connection to server was lost
Could not submit SQL request file /tmp/tmp.a0ZrivBZhD to database
and the associated entries in the log:
2014-12-15 17:54:07 GMT LOG: server process (PID 21897) was terminated by signal 9: Killed
2014-12-15 17:54:07 GMT DETAIL: Failed process was running: WITH upsert AS (update MSG set (slot,MSG,HRV,VIS006,VIS008,IR_016,IR_039,WV_062,WV_073,IR_087,IR_097,IR_108,IR_120,IR_134,PRO,EPI,CLM,TAPE) = (to_timestamp('201212032145', 'YYYYMMDDHH24MI'),2,'\xffffff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\x01','\x01','\x7f','LTO5_020') where slot=to_timestamp('201212032145', 'YYYYMMDDHH24MI') and MSG=2 RETURNING *) insert into MSG (slot,MSG,HRV,VIS006,VIS008,IR_016,IR_039,WV_062,WV_073,IR_087,IR_097,IR_108,IR_120,IR_134,PRO,EPI,CLM,TAPE) select to_timestamp('201212032145', 'YYYYMMDDHH24MI'),2,'\xffffff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\x01','\x01','\x7f','LTO5_020' WHERE NOT EXISTS (SELECT * FROM upsert);
2014-12-15 17:54:07 GMT LOG: terminating any other active server processes
2014-12-15 17:54:07 GMT WARNING: terminating connection because of crash of another server process
2014-12-15 17:54:07 GMT DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
2014-12-15 17:54:07 GMT HINT: In a moment you should be able to reconnect to the database and repeat your command.
2014-12-15 17:54:07 GMT seviri seviri WARNING: terminating connection because of crash of another server process
2014-12-15 17:54:07 GMT seviri seviri DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
2014-12-15 17:54:07 GMT seviri seviri HINT: In a moment you should be able to reconnect to the database and repeat your command.
2014-12-15 17:54:07 GMT LOG: all server processes terminated; reinitializing
2014-12-15 17:54:08 GMT LOG: database system was interrupted; last known up at 2014-12-15 17:49:38 GMT
2014-12-15 17:54:08 GMT LOG: database system was not properly shut down; automatic recovery in progress
2014-12-15 17:54:08 GMT LOG: redo starts at 0/58C1C060
2014-12-15 17:54:08 GMT LOG: record with zero length at 0/58C27950
2014-12-15 17:54:08 GMT LOG: redo done at 0/58C27920
2014-12-15 17:54:08 GMT LOG: last completed transaction was at log time 2014-12-15 17:53:33.898086+00
2014-12-15 17:54:08 GMT LOG: autovacuum launcher started
2014-12-15 17:54:08 GMT LOG: database system is ready to accept connections
My postgresql.conf contains the following modified parameters:
listen_addresses = '*'
max_connections = 100
shared_buffers = 96MB # increased from the default value of 24MB, because script was failing in the beginning
together with the /etc/sysctl.conf settings:
sys.kernel.shmmax = 268435456
sys.kernel.shmall = 268435456
Am I doing something wrong, either in my database definition (function, upsert) or in the parameters
used (shared buffers) ? Or is such memory consumption usual ?
Many thanks,
Alessandro.
Attachment
{kind=link}
Hello Alessandro,
> 2014-12-15 17:54:07 GMT DETAIL: Failed process was running: WITH upsert
> AS (update MSG set
> (slot,MSG,HRV,VIS006,VIS008,IR_016,IR_039,WV_062,WV_073,IR_087,IR_097,IR_108,IR_120,IR_134,PRO,EPI,CLM,TAPE)
> = (to_timestamp('201212032145',
>
'YYYYMMDDHH24MI'),2,'\xffffff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\x01','\x01','\x7f','LTO5_020')
> where slot=to_timestamp('201212032145', 'YYYYMMDDHH24MI') and MSG=2
> RETURNING *) insert into MSG
> (slot,MSG,HRV,VIS006,VIS008,IR_016,IR_039,WV_062,WV_073,IR_087,IR_097,IR_108,IR_120,IR_134,PRO,EPI,CLM,TAPE)
> select to_timestamp('201212032145',
>
'YYYYMMDDHH24MI'),2,'\xffffff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\xff','\x01','\x01','\x7f','LTO5_020'
> WHERE NOT EXISTS (SELECT * FROM upsert);
How many rows is "(SELECT * FROM upsert)" returning? Without knowing
more i would guess, that the result-set is very big and that could be
the reason for the memory usage.
I would add an WHERE clause to reduce the result-set (an correct index
can fasten this method even more).
Greetings,
Torsten
Torsten Zuehlsdorff <mailinglists@toco-domains.de> writes:
> How many rows is "(SELECT * FROM upsert)" returning? Without knowing
> more i would guess, that the result-set is very big and that could be
> the reason for the memory usage.
Result sets are not ordinarily accumulated on the server side.
Alessandro didn't show the trigger definition, but my guess is that it's
an AFTER trigger, which means that a trigger event record is accumulated
in server memory for each inserted/updated row. If you're trying to
update a huge number of rows in one command (or one transaction, if it's
a DEFERRED trigger) you'll eventually run out of memory for the event
queue.
An easy workaround is to make it a BEFORE trigger instead. This isn't
really nice from a theoretical standpoint; but as long as you make sure
there are no other BEFORE triggers that might fire after it, it'll work
well enough.
Alternatively, you might want to reconsider the concept of updating
hundreds of millions of rows in a single operation ...
regards, tom lane
Hi Torsten,
Thanks for your answer.
I have modified
(SELECT * FROM upsert)
to
(SELECT * FROM upsert WHERE slot=to_timestamp('201212032145', 'YYYYMMDDHH24MI') and MSG=2)
according to your suggestion to reduce the result-set to a single row. However, the INSERT process is still consuming
thesame amount of RAM.
Regards,
Alessandro.
On Wednesday 17 December 2014 16:26:32 Torsten Zuehlsdorff wrote:
> Hello Alessandro,
>
> > 2014-12-15 17:54:07 GMT DETAIL: Failed process was running: WITH upsert
> > AS (update MSG set
> > (slot,MSG,HRV,VIS006,VIS008,IR_016,IR_039,WV_062,WV_073,IR_087,IR_097,IR_1
> > 08,IR_120,IR_134,PRO,EPI,CLM,TAPE) = (to_timestamp('201212032145',
> > 'YYYYMMDDHH24MI'),2,'\xffffff','\xff','\xff','\xff','\xff','\xff','\xff','
> > \xff','\xff','\xff','\xff','\xff','\x01','\x01','\x7f','LTO5_020') where
> > slot=to_timestamp('201212032145', 'YYYYMMDDHH24MI') and MSG=2 RETURNING
> > *) insert into MSG
> > (slot,MSG,HRV,VIS006,VIS008,IR_016,IR_039,WV_062,WV_073,IR_087,IR_097,IR_1
> > 08,IR_120,IR_134,PRO,EPI,CLM,TAPE) select to_timestamp('201212032145',
> > 'YYYYMMDDHH24MI'),2,'\xffffff','\xff','\xff','\xff','\xff','\xff','\xff','
> > \xff','\xff','\xff','\xff','\xff','\x01','\x01','\x7f','LTO5_020' WHERE
> > NOT EXISTS (SELECT * FROM upsert);
>
> How many rows is "(SELECT * FROM upsert)" returning? Without knowing
> more i would guess, that the result-set is very big and that could be
> the reason for the memory usage.
>
> I would add an WHERE clause to reduce the result-set (an correct index
> can fasten this method even more).
>
> Greetings,
> Torsten
Hi, My dtrigger definition is CREATE TRIGGER msg_trigger BEFORE INSERT ON msg FOR EACH ROW EXECUTE PROCEDURE msg_function(); so it seems that it is a BEFORE trigger. To be totally honest, I have "really" limited knownledge in SQL and postgresql and all these were gathered from recipes foundon the web... Regards, Alessandro. On Wednesday 17 December 2014 10:41:31 Tom Lane wrote: > Torsten Zuehlsdorff <mailinglists@toco-domains.de> writes: > > How many rows is "(SELECT * FROM upsert)" returning? Without knowing > > more i would guess, that the result-set is very big and that could be > > the reason for the memory usage. > > Result sets are not ordinarily accumulated on the server side. > > Alessandro didn't show the trigger definition, but my guess is that it's > an AFTER trigger, which means that a trigger event record is accumulated > in server memory for each inserted/updated row. If you're trying to > update a huge number of rows in one command (or one transaction, if it's > a DEFERRED trigger) you'll eventually run out of memory for the event > queue. > > An easy workaround is to make it a BEFORE trigger instead. This isn't > really nice from a theoretical standpoint; but as long as you make sure > there are no other BEFORE triggers that might fire after it, it'll work > well enough. > > Alternatively, you might want to reconsider the concept of updating > hundreds of millions of rows in a single operation ... > > regards, tom lane
Alessandro Ipe <Alessandro.Ipe@meteo.be> writes:
> My dtrigger definition is
> CREATE TRIGGER msg_trigger BEFORE INSERT ON msg FOR EACH ROW EXECUTE PROCEDURE msg_function();
> so it seems that it is a BEFORE trigger.
Hm, no AFTER triggers anywhere? Are there foreign keys, perhaps?
regards, tom lane
On 17/12/14 16:14, Alessandro Ipe wrote: > 2014-12-15 17:54:07 GMT LOG: server process (PID 21897) was terminated > by signal 9: Killed since it was killed by SIGKILL, maybe it's the kernel's OOM killer? Torsten
Hi, A grep in a nightly dump of this database did not return any AFTER trigger. The only keys are primary on each daily table, through ADD CONSTRAINT "MSG_YYYY-MM-DD_pkey" PRIMARY KEY (slot, msg); and on the global table ADD CONSTRAINT msg_pkey PRIMARY KEY (slot, msg); Regards, A. On Wednesday 17 December 2014 12:49:03 Tom Lane wrote: > Alessandro Ipe <Alessandro.Ipe@meteo.be> writes: > > My dtrigger definition is > > CREATE TRIGGER msg_trigger BEFORE INSERT ON msg FOR EACH ROW EXECUTE > > PROCEDURE msg_function(); so it seems that it is a BEFORE trigger. > > Hm, no AFTER triggers anywhere? Are there foreign keys, perhaps? > > regards, tom lane
On Thursday 18 December 2014 08:51:47 Torsten Förtsch wrote:
> On 17/12/14 16:14, Alessandro Ipe wrote:
> > 2014-12-15 17:54:07 GMT LOG: server process (PID 21897) was terminated
> > by signal 9: Killed
>
> since it was killed by SIGKILL, maybe it's the kernel's OOM killer?
Indeed and this hopefully prevented postgresql to crash my whole system due to RAM exhaustion. But the problem remains : why an INSERT requires that huge amount of memory ?
Regards,
A.
Hi,
I tried also with an upsert function
CREATE FUNCTION upsert_func(sql_insert text, sql_update text) RETURNS void
LANGUAGE plpgsql
AS $$
BEGIN
EXECUTE sql_update;
IF FOUND THEN
RETURN;
END IF;
BEGIN
EXECUTE sql_insert;
EXCEPTION WHEN OTHERS THEN
EXECUTE sql_update;
END;
RETURN;
END;
$$;
with the same result on the memory used...
The tables hold 355000 rows in total.
Regards,
A.
On Thursday 18 December 2014 12:16:49 Alessandro Ipe wrote:
> Hi,
>
>
> A grep in a nightly dump of this database did not return any AFTER trigger.
> The only keys are primary on each daily table, through
> ADD CONSTRAINT "MSG_YYYY-MM-DD_pkey" PRIMARY KEY (slot, msg);
> and on the global table
> ADD CONSTRAINT msg_pkey PRIMARY KEY (slot, msg);
>
>
> Regards,
>
>
> A.
>
> On Wednesday 17 December 2014 12:49:03 Tom Lane wrote:
> > Alessandro Ipe <Alessandro.Ipe@meteo.be> writes:
> > > My dtrigger definition is
> > > CREATE TRIGGER msg_trigger BEFORE INSERT ON msg FOR EACH ROW EXECUTE
> > > PROCEDURE msg_function(); so it seems that it is a BEFORE trigger.
> >
> > Hm, no AFTER triggers anywhere? Are there foreign keys, perhaps?
> >
> > regards, tom lane
Alessandro Ipe <Alessandro.Ipe@meteo.be> writes:
> Hi,
> I tried also with an upsert function
> CREATE FUNCTION upsert_func(sql_insert text, sql_update text) RETURNS void
> LANGUAGE plpgsql
> AS $$
> BEGIN
> EXECUTE sql_update;
> IF FOUND THEN
> RETURN;
> END IF;
> BEGIN
> EXECUTE sql_insert;
> EXCEPTION WHEN OTHERS THEN
> EXECUTE sql_update;
> END;
> RETURN;
> END;
> $$;
> with the same result on the memory used...
If you want to provide a self-contained test case, possibly we could look
into it, but these fragmentary bits of what you're doing don't really
constitute an investigatable problem statement.
I will note that EXCEPTION blocks aren't terribly cheap, so if you're
reaching the "EXECUTE sql_insert" a lot of times that might have something
to do with it.
regards, tom lane
Hi,
I can send a full dump of my database (< 2MB) if it is OK for you.
Thanks,
A.
On Thursday 18 December 2014 12:05:45 Tom Lane wrote:
> Alessandro Ipe <Alessandro.Ipe@meteo.be> writes:
> > Hi,
> > I tried also with an upsert function
> > CREATE FUNCTION upsert_func(sql_insert text, sql_update text) RETURNS void
> >
> > LANGUAGE plpgsql
> > AS $$
> >
> > BEGIN
> > EXECUTE sql_update;
> > IF FOUND THEN
> >
> > RETURN;
> >
> > END IF;
> > BEGIN
> >
> > EXECUTE sql_insert;
> > EXCEPTION WHEN OTHERS THEN
> > EXECUTE sql_update;
> > END;
> >
> > RETURN;
> >
> > END;
> > $$;
> > with the same result on the memory used...
>
> If you want to provide a self-contained test case, possibly we could look
> into it, but these fragmentary bits of what you're doing don't really
> constitute an investigatable problem statement.
>
> I will note that EXCEPTION blocks aren't terribly cheap, so if you're
> reaching the "EXECUTE sql_insert" a lot of times that might have something
> to do with it.
>
> regards, tom lane
Hi, I guess the memory consumption is depending on the size of my database, so only giving a reduced version of it won't allow to hit the issue. The pg_dumpall file of my database can be found at the address https://gerb.oma.be/owncloud/public.php?service=files&t=5e0e9e1bb06dce1d12c95662a9ee1c03 The queries causing the issue are given in files - tmp.OqOavPYbHa (with the new upsert_func function) - tmp.f60wlgEDWB (with WITH .. AS statement) I hope it will help. Thanks. Regards, A. On Thursday 18 December 2014 12:05:45 Tom Lane wrote: > Alessandro Ipe <Alessandro.Ipe@meteo.be> writes: > > Hi, > > I tried also with an upsert function > > CREATE FUNCTION upsert_func(sql_insert text, sql_update text) RETURNS void > > > > LANGUAGE plpgsql > > AS $$ > > > > BEGIN > > EXECUTE sql_update; > > IF FOUND THEN > > > > RETURN; > > > > END IF; > > BEGIN > > > > EXECUTE sql_insert; > > EXCEPTION WHEN OTHERS THEN > > EXECUTE sql_update; > > END; > > > > RETURN; > > > > END; > > $$; > > with the same result on the memory used... > > If you want to provide a self-contained test case, possibly we could look > into it, but these fragmentary bits of what you're doing don't really > constitute an investigatable problem statement. > > I will note that EXCEPTION blocks aren't terribly cheap, so if you're > reaching the "EXECUTE sql_insert" a lot of times that might have something > to do with it. > > regards, tom lane
Attachment
Alessandro Ipe <Alessandro.Ipe@meteo.be> writes: > I guess the memory consumption is depending on the size of my database, so > only giving a reduced version of it won't allow to hit the issue. > The pg_dumpall file of my database can be found at the address > https://gerb.oma.be/owncloud/public.php?service=files&t=5e0e9e1bb06dce1d12c95662a9ee1c03 > The queries causing the issue are given in files > - tmp.OqOavPYbHa (with the new upsert_func function) > - tmp.f60wlgEDWB (with WITH .. AS statement) Well, the core of the problem here is that you've chosen to partition the MSG table at an unreasonably small grain: it's got 3711 child tables and it looks like you plan to add another one every day. For forty-some megabytes worth of data, I'd have said you shouldn't be partitioning at all; for sure you shouldn't be partitioning like this. PG's inheritance mechanisms are only meant to cope with order-of-a-hundred child tables at most. Moreover, the only good reason to partition is if you want to do bulk data management by, say, dropping the oldest partition every so often. It doesn't look like you're planning to do that at all, and I'm sure if you do, you don't need 1-day granularity of the drop. I'd recommend you either dispense with partitioning entirely (which would simplify your life a great deal, since you'd not need all this hacky partition management code), or scale it back to something like one partition per year. Having said that, it looks like the reason for the memory bloat is O(N^2) space consumption in inheritance_planner() while trying to plan the "UPDATE msg SET" commands. We got rid of a leading term in that function's space consumption for many children awhile ago, but it looks like you've found the next largest term :-(. I might be able to do something about that. In the meantime, if you want to stick with this partitioning design, couldn't you improve that code so the UPDATE is only applied to the one child table it's needed for? regards, tom lane
Hi, Doing the UPDATE on the child table (provided that the table does exist) as you recommended solved all my memory consumption issue. Thanks a lot, Alessandro. On Tuesday 23 December 2014 15:27:41 Tom Lane wrote: > Alessandro Ipe <Alessandro.Ipe@meteo.be> writes: > > I guess the memory consumption is depending on the size of my database, so > > only giving a reduced version of it won't allow to hit the issue. > > > > The pg_dumpall file of my database can be found at the address > > https://gerb.oma.be/owncloud/public.php?service=files&t=5e0e9e1bb06dce1d12 > > c95662a9ee1c03 > > > > The queries causing the issue are given in files > > - tmp.OqOavPYbHa (with the new upsert_func function) > > - tmp.f60wlgEDWB (with WITH .. AS statement) > > Well, the core of the problem here is that you've chosen to partition the > MSG table at an unreasonably small grain: it's got 3711 child tables and > it looks like you plan to add another one every day. For forty-some > megabytes worth of data, I'd have said you shouldn't be partitioning at > all; for sure you shouldn't be partitioning like this. PG's inheritance > mechanisms are only meant to cope with order-of-a-hundred child tables at > most. Moreover, the only good reason to partition is if you want to do > bulk data management by, say, dropping the oldest partition every so > often. It doesn't look like you're planning to do that at all, and I'm > sure if you do, you don't need 1-day granularity of the drop. > > I'd recommend you either dispense with partitioning entirely (which would > simplify your life a great deal, since you'd not need all this hacky > partition management code), or scale it back to something like one > partition per year. > > Having said that, it looks like the reason for the memory bloat is O(N^2) > space consumption in inheritance_planner() while trying to plan the > "UPDATE msg SET" commands. We got rid of a leading term in that > function's space consumption for many children awhile ago, but it looks > like you've found the next largest term :-(. I might be able to do > something about that. In the meantime, if you want to stick with this > partitioning design, couldn't you improve that code so the UPDATE is > only applied to the one child table it's needed for? > > regards, tom lane