Thread: Investigating the reason for a very big TOAST table size
Hi,
We have a table which its TOAST table size is 66 GB, and we believe should be smaller.
The table size is 472 kb. And the table has 4 columns that only one of them should be toasted.
The table has only 8 dead tuples, so apparently this is not the problem.
This table contains a column with bytea type data (kept as TOAST). We tried to check what is the size of the toasted data in each row by using the following query (the data_blob is the bytea column):
SELECT nid, octet_length(data_blob) FROM my_table ORDER BY octet_length(data_blob) DESC;
This result contain 1782 rows. The sizes I get from each row are between 35428 to 42084.
1782 * 38000 = 67716000 byte = 64.579 MB .
What can be the reason for a table size of 66 GB? What else should I check?
Thanks in advance,
Liron
On Sun, Aug 26, 2012 at 5:46 AM, Liron Shiri <lirons@checkpoint.com> wrote: > Hi, > > > > We have a table which its TOAST table size is 66 GB, and we believe should > be smaller. > > The table size is 472 kb. And the table has 4 columns that only one of them > should be toasted. > > > > The table has only 8 dead tuples, so apparently this is not the problem. > > > > This table contains a column with bytea type data (kept as TOAST). We tried > to check what is the size of the toasted data in each row by using the > following query (the data_blob is the bytea column): > > > > SELECT nid, octet_length(data_blob) FROM my_table ORDER BY > octet_length(data_blob) DESC; > > > > This result contain 1782 rows. The sizes I get from each row are between > 35428 to 42084. > > > > 1782 * 38000 = 67716000 byte = 64.579 MB . > > > > What can be the reason for a table size of 66 GB? What else should I check? Is the size of the database continuing to grow over time, or is it stable? Have you done a hot-standby promotion on this database, perchance? I have an open bug report on an unusual situation that began after that: http://archives.postgresql.org/pgsql-bugs/2012-08/msg00108.php -- fdr
There were no "hot standby" configuration, but the DB has start grow fast after restoring from a base backup as describedin http://www.postgresql.org/docs/8.3/static/continuous-archiving.html#BACKUP-BASE-BACKUP The DB has been growing for a while, and now it seems to become stable after adjusting the autovacuum cost parameters tobe more aggressive. The DB version is 8.3.7. Do you think it might be the same issue? What can we do in order to decrease DB size? -----Original Message----- From: Daniel Farina [mailto:daniel@heroku.com] Sent: Monday, August 27, 2012 7:42 PM To: Liron Shiri Cc: pgsql-performance@postgresql.org Subject: Re: [PERFORM] Investigating the reason for a very big TOAST table size On Sun, Aug 26, 2012 at 5:46 AM, Liron Shiri <lirons@checkpoint.com> wrote: > Hi, > > > > We have a table which its TOAST table size is 66 GB, and we believe > should be smaller. > > The table size is 472 kb. And the table has 4 columns that only one of > them should be toasted. > > > > The table has only 8 dead tuples, so apparently this is not the problem. > > > > This table contains a column with bytea type data (kept as TOAST). We > tried to check what is the size of the toasted data in each row by > using the following query (the data_blob is the bytea column): > > > > SELECT nid, octet_length(data_blob) FROM my_table ORDER BY > octet_length(data_blob) DESC; > > > > This result contain 1782 rows. The sizes I get from each row are > between > 35428 to 42084. > > > > 1782 * 38000 = 67716000 byte = 64.579 MB . > > > > What can be the reason for a table size of 66 GB? What else should I check? Is the size of the database continuing to grow over time, or is it stable? Have you done a hot-standby promotion on this database, perchance? I have an open bug report on an unusual situation thatbegan after that: http://archives.postgresql.org/pgsql-bugs/2012-08/msg00108.php -- fdr Scanned by Check Point Total Security Gateway.
On Mon, Aug 27, 2012 at 11:24 PM, Liron Shiri <lirons@checkpoint.com> wrote: > There were no "hot standby" configuration, but the DB has start grow fast after restoring from a base backup as describedin http://www.postgresql.org/docs/8.3/static/continuous-archiving.html#BACKUP-BASE-BACKUP Very interesting. That is more or less the same concept, but it might eliminate some variables. What's your workload on the bloaty toast table? Mine is per the bug report, which is repeated concatenation of strings. > The DB has been growing for a while, and now it seems to become stable after adjusting the autovacuum cost parameters tobe more aggressive. My database has taken many days (over a week) to stabilize. I was about to write that it never stops growing (we'd eventually have to VACUUM FULL or do a column rotation), but that is not true. This graph is a bit spotty for unrelated reasons, but here's something like what I'm seeing: http://i.imgur.com/tbj1n.png The standby promotion sticks out quite a bit. I wonder if the original huge size is not the result of a huge delete (which I surmised) but rather another standby promotion. We tend to do that a lot here. > The DB version is 8.3.7. > > Do you think it might be the same issue? > What can we do in order to decrease DB size? One weakness of Postgres is can't really debloat online or incrementally yet, but luckily your table is quite small: you can use "CLUSTER" to lock and re-write the table, which will then be small. Do not use VACUUM FULL on this old release, but for future reference, VACUUM FULL has been made more like CLUSTER in newer releases anyway, and one can use that in the future. Both of these do table rewrites of the live data -- fdr
{kind=link}
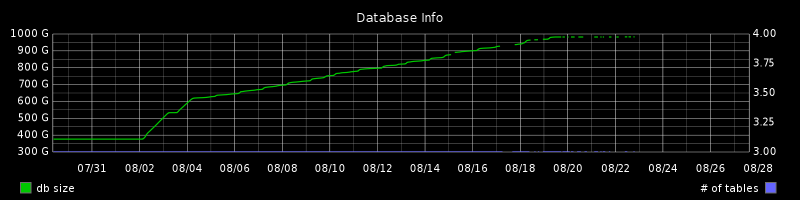
On Tue, Aug 28, 2012 at 1:57 AM, Daniel Farina <daniel@heroku.com> wrote: > My database has taken many days (over a week) to stabilize. I was > about to write that it never stops growing (we'd eventually have to > VACUUM FULL or do a column rotation), but that is not true. This > graph is a bit spotty for unrelated reasons, but here's something like > what I'm seeing: > > http://i.imgur.com/tbj1n.png Graph in attachment form for posterity of the archives. I forgot they take attachments. -- fdr
Attachment
{kind=link}
On Mon, Aug 27, 2012 at 11:24 PM, Liron Shiri <lirons@checkpoint.com> wrote: > There were no "hot standby" configuration, but the DB has start grow fast after restoring from a base backup as describedin http://www.postgresql.org/docs/8.3/static/continuous-archiving.html#BACKUP-BASE-BACKUP I'm trying to confirm a theory about why this happens. Can you answer a question for me? I've just seen this happen twice. Both are involving toasted columns, but the other critical thing they share is that they use in-database operators to modify the toasted data. For example, here is something that would not display pathological warm/hot standby-promotion bloat, if I am correct: UPDATE foo SET field='value'; But here's something that might: UPDATE foo SET field=field || 'value' Other examples might include tsvector_update_trigger (also: that means that triggers can cause this workload also, even if you do not write queries that directly use such modification operators) , but in principle any operation that does not completely overwrite the value may be susceptible, or so the information I have would indicate. What do you think, does that sound like your workload, or do you do full replacement of values in your UPDATEs, which would invalidate this theory? I'm trying to figure out why standby promotion works so often with no problems but sometimes bloats in an incredibly pathological way sometimes, and obviously I think it might be workload dependent. -- fdr
We do not use in-database operators to modify the toasted data. The update operations we perform on the problematic table are in the form of UPDATE foo SET field='value' WHERE nid = to_uid(#objId#) -----Original Message----- From: Daniel Farina [mailto:daniel@heroku.com] Sent: Thursday, August 30, 2012 11:11 AM To: Liron Shiri Cc: pgsql-performance@postgresql.org Subject: Re: [PERFORM] Investigating the reason for a very big TOAST table size On Mon, Aug 27, 2012 at 11:24 PM, Liron Shiri <lirons@checkpoint.com> wrote: > There were no "hot standby" configuration, but the DB has start grow > fast after restoring from a base backup as described in > http://www.postgresql.org/docs/8.3/static/continuous-archiving.html#BA > CKUP-BASE-BACKUP I'm trying to confirm a theory about why this happens. Can you answer a question for me? I've just seen this happen twice. Both are involving toasted columns, but the other critical thing they share is that theyuse in-database operators to modify the toasted data. For example, here is something that would not display pathological warm/hot standby-promotion bloat, if I am correct: UPDATE foo SET field='value'; But here's something that might: UPDATE foo SET field=field || 'value' Other examples might include tsvector_update_trigger (also: that means that triggers can cause this workload also, even ifyou do not write queries that directly use such modification operators) , but in principle any operation that does notcompletely overwrite the value may be susceptible, or so the information I have would indicate. What do you think, doesthat sound like your workload, or do you do full replacement of values in your UPDATEs, which would invalidate this theory? I'm trying to figure out why standby promotion works so often with no problems but sometimes bloats in an incredibly pathologicalway sometimes, and obviously I think it might be workload dependent. -- fdr Scanned by Check Point Total Security Gateway.
On Thu, Aug 30, 2012 at 1:34 AM, Liron Shiri <lirons@checkpoint.com> wrote: > We do not use in-database operators to modify the toasted data. > The update operations we perform on the problematic table are in the form of > > UPDATE foo SET field='value' WHERE nid = to_uid(#objId#) Ah, well, there goes that idea, although it may still be good enough to reproduce the problem, even if it is not responsible for all reproductions... I guess it's time to clear some time to try. -- fdr