Thread: O_DIRECT for WAL writes
This patch ticks off the following TODO items: Consider use of open/fcntl(O_DIRECT) to minimize OS caching, especially for WAL writes. The patch adds a new choice "open_direct" to wal_sync_method. It uses O_DIRECT flags for WAL writes, like O_SYNC. I had sent a patch looked like this before (http://candle.pha.pa.us/mhonarc/patches2/msg00131.html) but I found it is not always needed to write multiple pages in one write() because most disks have writeback-cache. So, I left only O_DIRECT routines in the patch and it impacts a present source code less. --- ITAGAKI Takahiro NTT Cyber Space Laboratories
Attachment
ITAGAKI Takahiro wrote: > The patch adds a new choice "open_direct" to wal_sync_method. > It uses O_DIRECT flags for WAL writes, like O_SYNC. Have you looked at what the performance difference of this option is? For example, these benchmark results seem to indicate that an older version of the patch is not a performance win, at least for OSDL's workload: http://www.mail-archive.com/pgsql-patches@postgresql.org/msg07186.html Is this data still applicable to the revised patch? -Neil
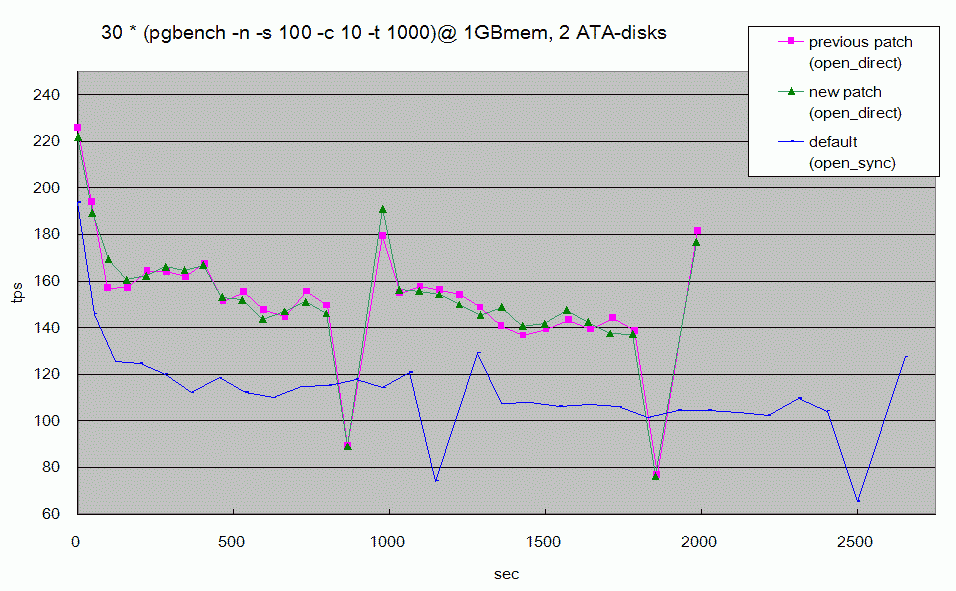
Neil Conway <neilc@samurai.com> wrote: > > The patch adds a new choice "open_direct" to wal_sync_method. > Have you looked at what the performance difference of this option is? Yes, I've tested pgbench and dbt2 and their performances have improved. The two results are as follows: 1. pgbench -s 100 on one Pentium4, 1GB mem, 2 ATA disks, Linux 2.6.8 (attached image) tps | wal_sync_method -------+------------------------------------------------------- 147.0 | open_direct + write multipage (previous patch) 147.2 | open_direct (this patch) 109.9 | open_sync 2. dbt2 100WH on two opterons, 8GB mem, 12 SATA-RAID disks, Linux 2.4.20 tpm | wal_sync_method --------+------------------------------------------------------ 1183.9 | open_direct (this patch) 911.3 | fsync > http://www.mail-archive.com/pgsql-patches@postgresql.org/msg07186.html > Is this data still applicable to the revised patch? Direct-IO might be good on some machines, and bad on others. This data is another reason that I revised the patch; If you don't use open_direct, WAL writer behaves quite similarly to former. However, the performances did not go down at least on my benchmarks. I have no idea why the above data was bad... --- ITAGAKI Takahiro NTT Cyber Space Laboratories
Attachment
{kind=link}
On Mon, 2005-05-30 at 10:59 +0900, ITAGAKI Takahiro wrote:
> Yes, I've tested pgbench and dbt2 and their performances have improved.
> The two results are as follows:
>
> 1. pgbench -s 100 on one Pentium4, 1GB mem, 2 ATA disks, Linux 2.6.8
> (attached image)
> tps | wal_sync_method
> -------+-------------------------------------------------------
> 147.0 | open_direct + write multipage (previous patch)
> 147.2 | open_direct (this patch)
> 109.9 | open_sync
I'm surprised this makes as much of a difference as that benchmark would
suggest. I wonder if we're benchmarking the right thing, though: is
opening a file with O_DIRECT sufficient to ensure that a write(2) does
not return until the data has hit disk? (As would be the case with
O_SYNC.) O_DIRECT means the OS will attempt to minimize caching, but
that is not necessarily the same thing: for example, I can imagine an
implementation in which the kernel would submit the appropriate I/O to
the disk when it sees a write(2) on a file opened with O_DIRECT, but
then let the write(2) return before getting confirmation from the disk
that the I/O has succeeded or failed. From googling, the MySQL
documentation for innodb_flush_method notes:
This option is only relevant on Unix systems. If set to
fdatasync, InnoDB uses fsync() to flush both the data and log
files. If set to O_DSYNC, InnoDB uses O_SYNC to open and flush
the log files, but uses fsync() to flush the datafiles. If
O_DIRECT is specified (available on some GNU/Linux versions
starting from MySQL 4.0.14), InnoDB uses O_DIRECT to open the
datafiles, and uses fsync() to flush both the data and log
files.
That would suggest O_DIRECT by itself is not sufficient to force a flush
to disk -- if anyone has some more definitive evidence that would be
welcome.
Anyway, if the above is true, we'll need to use O_DIRECT as well as one
of the existing wal_sync_methods.
BTW, from the patch:
+ /* TODO: Aligment depends on OS and filesystem. */
+ #define O_DIRECT_BUFFER_ALIGN 4096
I suppose there's no reasonable way to autodetect this, so we'll need to
expose it as a GUC variable (or perhaps a configure option), which is a
bit unfortunate.
-Neil
Neil Conway <neilc@samurai.com> writes: > I wonder if we're benchmarking the right thing, though: is > opening a file with O_DIRECT sufficient to ensure that a write(2) does > not return until the data has hit disk? Some googling suggests so, eg http://www.die.net/doc/linux/man/man2/open.2.html There are several useful tidbits about O_DIRECT on that page, including this quote: > "The thing that has always disturbed me about O_DIRECT is that the whole > interface is just stupid, and was probably designed by a deranged monkey > on some serious mind-controlling substances." -- Linus Somehow I find that less than confidence-building... regards, tom lane
On Mon, 2005-05-30 at 02:52 -0400, Tom Lane wrote: > Some googling suggests so, eg > http://www.die.net/doc/linux/man/man2/open.2.html Well, that claims that "data is guaranteed to have been transferred", but transferred to *where* is the question :) Transferring data to the disk's buffers and then not asking for the buffer to be flushed is not sufficient, for example. IMHO the fact that InnoDB uses both O_DIRECT and fsync() is more convincing. I'm still looking for a definitive answer, though. The other question is whether these semantics are identical among the various O_DIRECT implementations (e.g. Linux, FreeBSD, AIX, IRIX, and others). -Neil
Tom Lane wrote: > Neil Conway <neilc@samurai.com> writes: >>is opening a file with O_DIRECT sufficient to ensure that >>a write(2) does not return until the data has hit disk? > > Some googling suggests so, eg > http://www.die.net/doc/linux/man/man2/open.2.html Really? On that page I read: "O_DIRECT...at the completion of the read(2) or write(2) system call, data is guaranteed to have been transferred." which sounds to me like transfered to the device's cache but not necessarily flushed through the device's cache. It says nothing about physical media. That wording feels different to me from O_SYNC which reads: "O_SYNC will block the calling process until the data has been physically written to the underlying hardware." which does suggest to me that it writes to physical media. Or am I reading that wrong? PS: I've gotten way out of my depth here, but... ...attempting to browse the Linux source(!!) Looking at the O_SYNC stuff in ext3: http://lxr.linux.no/source/fs/ext3/file.c#L67 it looks like in this conditional: if (file->f_flags & O_SYNC) { ... goto force_commit; } the goto branch calls ext3_force_commit() in much the same way that it seems fsync() does here: http://lxr.linux.no/source/fs/ext3/fsync.c#L71 so I believe O_SYNC does at least as much as fsync(). However I can't find O_DIRECT anywhere in the ext3 stuff, so if it does work it's less obvious how or if it could. Moreover I see O_SYNC used lots of places: http://lxr.linux.no/ident?i=O_SYNC in various places like fs/ext3/; and and I don't see O_DIRECT in nearly as many places http://lxr.linux.no/ident?i=O_DIRECT It looks like reiserfs and xfs seem look at O_DIRECT, but ext3 doesn't appear to unless it's somewhere outside the fs/ext3 directory. PPS: Of course not even fsync() flushed correctly until very recent kernels: http://hardware.slashdot.org/comments.pl?sid=149349&cid=12519114 In that article Jeff Garzik (the linux SATA driver guy) suggests that until very recent kernels ext3 did not have write barrier support that issues the FLUSH CACHE (IDE) or SYNCHRONIZE CACHE (SCSI) commands even on fsync. PPPS: No, I don't understand the kernel - I'm just showing what quick grep commands showed without any deep understanding.
Neil Conway <neilc@samurai.com> writes:
> On Mon, 2005-05-30 at 02:52 -0400, Tom Lane wrote:
> Well, that claims that "data is guaranteed to have been transferred",
> but transferred to *where* is the question :)
Oh, I see what you are worried about. I think you are right: what the
doc promises is only that the DMA transfer has finished (ie, it's safe
to scribble on your buffer again). So you'd still need an fsync;
which makes O_DIRECT orthogonal to wal_sync_method rather than a
valid choice for it. (Hm, I wonder if specifying both O_DIRECT and
O_SYNC works ...)
> The other question is whether these semantics are identical among the
> various O_DIRECT implementations (e.g. Linux, FreeBSD, AIX, IRIX, and
> others).
Wouldn't count on it :-(. One thing I'm particularly worried about is
buffer cache consistency: does the kernel guarantee to flush any buffers
it has that overlap the O_DIRECT write operation? Without this, an
application reading the WAL using normal non-O_DIRECT I/O might see the
wrong data; which is bad news for PITR.
regards, tom lane
On Mon, 2005-05-30 at 11:24 -0400, Tom Lane wrote:
> Wouldn't count on it :-(. One thing I'm particularly worried about is
> buffer cache consistency: does the kernel guarantee to flush any buffers
> it has that overlap the O_DIRECT write operation?
At least on Linux I believe the kernel guarantees consistency between
O_DIRECT and non-O_DIRECT operations. From googling, it seems AIX also
provides consistency, albeit not for free[1]:
To avoid consistency issues, if there are multiple calls to open
a file and one or more of the calls did not specify O_DIRECT and
another open specified O_DIRECT, the file stays in the normal
cached I/O mode. Similarly, if the file is mapped into memory
through the shmat() or mmap() system calls, it stays in normal
cached mode. If the last conflicting, non-direct access is
eliminated, then the file system will move the file into direct
I/O mode (either by using the close(), munmap(), or shmdt()
subroutines). Changing from normal mode to direct I/O mode can
be expensive because all modified pages in memory will have to
be flushed to disk at that point.
-Neil
[1]
http://publib16.boulder.ibm.com/pseries/en_US/aixbman/prftungd/diskperf9.htm
On Mon, 2005-05-30 at 16:29 +1000, Neil Conway wrote: > On Mon, 2005-05-30 at 10:59 +0900, ITAGAKI Takahiro wrote: > > Yes, I've tested pgbench and dbt2 and their performances have improved. > > The two results are as follows: > > > > 1. pgbench -s 100 on one Pentium4, 1GB mem, 2 ATA disks, Linux 2.6.8 > > (attached image) > > tps | wal_sync_method > > -------+------------------------------------------------------- > > 147.0 | open_direct + write multipage (previous patch) > > 147.2 | open_direct (this patch) > > 109.9 | open_sync > > I'm surprised this makes as much of a difference as that benchmark would > suggest. I wonder if we're benchmarking the right thing, though: is > opening a file with O_DIRECT sufficient to ensure that a write(2) does > not return until the data has hit disk? (As would be the case with > O_SYNC.) O_DIRECT means the OS will attempt to minimize caching, but > that is not necessarily the same thing: for example, I can imagine an > implementation in which the kernel would submit the appropriate I/O to > the disk when it sees a write(2) on a file opened with O_DIRECT, but > then let the write(2) return before getting confirmation from the disk > that the I/O has succeeded or failed. From googling, the MySQL > documentation for innodb_flush_method notes: > > This option is only relevant on Unix systems. If set to > fdatasync, InnoDB uses fsync() to flush both the data and log > files. If set to O_DSYNC, InnoDB uses O_SYNC to open and flush > the log files, but uses fsync() to flush the datafiles. If > O_DIRECT is specified (available on some GNU/Linux versions > starting from MySQL 4.0.14), InnoDB uses O_DIRECT to open the > datafiles, and uses fsync() to flush both the data and log > files. > > That would suggest O_DIRECT by itself is not sufficient to force a flush > to disk -- if anyone has some more definitive evidence that would be > welcome. I know I'm late to this discussion, and I haven't made it all the way through this thread to see if your questions on Linux writes were resolved. If you are still interested, I recommend read a very good one page description of reliable writes buried in the Data Center Linux Goals and Capabilities document. It is on page 159 of the document, the item is "R.ReliableWrites" in this _giant PDF file (do a wget and open it locally ; don't try to read it directly): http://www.osdlab.org/lab_activities/data_center_linux/DCL_Goals_Capabilities_1.1.pdf The information came from me interviewing Daniel McNeil, an OSDL Engineer who wrote and tested much of the Linux async IO code, after I was similarly confused about when a write is "guaranteed". Reliable writes, as you can imagine, are very important to Data Center folks, which is how it happens to be in this document. Hope this helps. > > Anyway, if the above is true, we'll need to use O_DIRECT as well as one > of the existing wal_sync_methods. > > BTW, from the patch: > > + /* TODO: Aligment depends on OS and filesystem. */ > + #define O_DIRECT_BUFFER_ALIGN 4096 > > I suppose there's no reasonable way to autodetect this, so we'll need to > expose it as a GUC variable (or perhaps a configure option), which is a > bit unfortunate. > > -Neil > > > > ---------------------------(end of broadcast)--------------------------- > TIP 4: Don't 'kill -9' the postmaster -- Mary Edie Meredith maryedie@osdl.org 503-906-1942 Data Center Linux Initiative Manager Open Source Development Labs
On Wed, 2005-06-01 at 17:08 -0700, Mary Edie Meredith wrote: > I know I'm late to this discussion, and I haven't made it all the way > through this thread to see if your questions on Linux writes were > resolved. If you are still interested, I recommend read a very good > one page description of reliable writes buried in the Data Center Linux > Goals and Capabilities document. This suggests that on Linux a write() on a file opened with O_DIRECT has the same synchronization guarantees as a write() on a file opened with O_SYNC, which is precisely the opposite of what was concluded down thread. So now I'm more confused :) (Regardless of behavior on Linux, I would guess O_DIRECT doesn't behave this way on all platforms -- for example, FreeBSD's open(2) manpage does not mention I/O synchronization when referring to O_DIRECT. So even if we can skip the fsync() with O_DIRECT on Linux, I doubt we'll be able to do that on all platforms.) -Neil
On Thu, 2005-06-02 at 11:39 +1000, Neil Conway wrote: > On Wed, 2005-06-01 at 17:08 -0700, Mary Edie Meredith wrote: > > I know I'm late to this discussion, and I haven't made it all the way > > through this thread to see if your questions on Linux writes were > > resolved. If you are still interested, I recommend read a very good > > one page description of reliable writes buried in the Data Center Linux > > Goals and Capabilities document. > > This suggests that on Linux a write() on a file opened with O_DIRECT has > the same synchronization guarantees as a write() on a file opened with > O_SYNC, which is precisely the opposite of what was concluded down > thread. So now I'm more confused :) > > (Regardless of behavior on Linux, I would guess O_DIRECT doesn't behave > this way on all platforms -- for example, FreeBSD's open(2) manpage does > not mention I/O synchronization when referring to O_DIRECT. So even if > we can skip the fsync() with O_DIRECT on Linux, I doubt we'll be able to > do that on all platforms.) My understanding is that O_DIRECT means "direct" as in "no buffering by the OS" which implies that if you write from your buffer, the write is not going to return unless the OS thinks the write is completed (or unless you are using Async IO). Otherwise you might reuse your buffer (there _is no other buffer after all) and if the write were incomplete before refill you buffer for another, the first write might go from your buffer with wrong data. Now if you want to avoid _waiting for the write to complete, you need to employ async io, which is why most databases that support direct io for their datafiles also have implemented some form of async io as well (either via OS calls or some built-in mechanism as is the case with SAP-DB). With AIO you have to manage your buffers so that you reuse them only when you are notified the IO is completed. Historically this was done with raw datafiles, but currently (at least for Linux) you can also do this with files. For logging, though, I think you want synchronous IO to guarantee order. The cool thing about buffering the datafile data yourself is that _you (the database engine) can control what stays in (shared) memory and what does not. You can add configuration options or add intelligence, so that frequently used data (like hot indexes) can stay in memory indefinitely. The OS can never do that so specifically. In addition, you can avoid having data from table scans overwrite hot objects. Of course, at the moment you are discussing the use for logging, but there should be benefits to extending this to datafiles as well, assuming you also implement async io. Bottom line: if you do not implement direct/async IO so that you optimize caching of hot database objects and minimize memory utilization of objects used once, you are probably leaving performance on the table for datafiles. Daniel is on vacation, but I will ask him to confirm once he returns. > > -Neil > -- Mary Edie Meredith maryedie@osdl.org 503-906-1942 Data Center Linux Initiative Manager Open Source Development Labs
On Thu, 2005-06-02 at 11:49 -0700, Mary Edie Meredith wrote: > My understanding is that O_DIRECT means "direct" as in "no buffering by > the OS" which implies that if you write from your buffer, the write is > not going to return unless the OS thinks the write is completed Right, I think that's definitely the case. The question is whether a write() under O_DIRECT will also flush the disk's write cache -- i.e. when the write() completes, we need it to be durable over a spontaneous power loss. fsync() or O_SYNC should provide this (modulo braindamaged IDE hardware), but I wouldn't be surprised if O_DIRECT by itself will not (otherwise you would hurt the performance of applications using O_DIRECT that don't need these durability guarantees). > Bottom line: if you do not implement direct/async IO so that you > optimize caching of hot database objects and minimize memory utilization > of objects used once, you are probably leaving performance on the table > for datafiles. Absolutely -- patches are welcome :) I agree async IO + O_DIRECT in some form would be interesting, but the changes required are far from trivial -- my guess is there are lower hanging fruit. -Neil
On Fri, 2005-06-03 at 10:37 +1000, Neil Conway wrote: > On Thu, 2005-06-02 at 11:49 -0700, Mary Edie Meredith wrote: > > My understanding is that O_DIRECT means "direct" as in "no buffering by > > the OS" which implies that if you write from your buffer, the write is > > not going to return unless the OS thinks the write is completed > > Right, I think that's definitely the case. The question is whether a > write() under O_DIRECT will also flush the disk's write cache -- i.e. > when the write() completes, we need it to be durable over a spontaneous > power loss. fsync() or O_SYNC should provide this (modulo braindamaged > IDE hardware), but I wouldn't be surprised if O_DIRECT by itself will > not (otherwise you would hurt the performance of applications using > O_DIRECT that don't need these durability guarantees). My understanding is that for Linux, with respect to "Guaranteed writes" a write with the fd opened as O_DIRECT behaves the _same as a write/fsync on an fd opened without O_DIRECT, i.e. whether the write completes all the way to the disk itself depends on when the particular device responds to those equivalent sequences. Quoting from the Capabilities Document "'Guarantee a write completion ' means the operating system has issued a write to the I/O subsystem, and the device has returned an affirmative response. Once an affirmative response is sent, recovery from power down without data loss is the responsibility of the I/O subsystem." Don't most disk drives have a battery backup so that it can flush its cache if power is lost? Ditto for Disk arrays with fancier cache and write-back set on (not advised for the paranoid). Looking at this from another angle, is there really any way that you can say a write is truly guaranteed in the event of a failure? I think in the end to be safe, you cannot. That's why (and I'm not telling you anything new) there is no substitute for backups and log archiving for databases. Databases must be able to recognize the last _good transaction logged and roll forward to that from the backup (including detecting partial writes to the log). I'm sure the PostgreSQL community has worked hard to do the equivalent of that within the PostgreSQL architecture. > > > Bottom line: if you do not implement direct/async IO so that you > > optimize caching of hot database objects and minimize memory utilization > > of objects used once, you are probably leaving performance on the table > > for datafiles. > > Absolutely -- patches are welcome :) How about testing patches (--: > I agree async IO + O_DIRECT in some > form would be interesting, but the changes required are far from trivial > -- my guess is there are lower hanging fruit. Since the log has to be sequential, I think you are on the right track! Believe me, I didn't mean to imply that it is trivial to implement. For those databases that have async/direct, the functionality appeared over a span of several major versions. I just thought I detected an opinion that it would not help. Sorry for the misunderstanding. I absolutely don't mean to sound critical. At OSDL we have the greatest respect for the PostgreSQL community. > > -Neil -- Mary Edie Meredith maryedie@osdl.org 503-906-1942 Data Center Linux Initiative Manager Open Source Development Labs
On Fri, Jun 03, 2005 at 09:43:13 -0700, Mary Edie Meredith <maryedie@osdl.org> wrote: > > Looking at this from another angle, is there really any way that you can > say a write is truly guaranteed in the event of a failure? I think in > the end to be safe, you cannot. That's why (and I'm not telling you > anything new) there is no substitute for backups and log archiving for > databases. Databases must be able to recognize the last _good > transaction logged and roll forward to that from the backup (including > detecting partial writes to the log). I'm sure the PostgreSQL community > has worked hard to do the equivalent of that within the PostgreSQL > architecture. Some assumptions are made about what order blocks are written to the disk. If these assumptions are not true, you may not be able to recover using the WAL log and have to resort to falling back to your last consistant snapshot.
I think the conclusion from the discussion is that O_DIRECT is in addition to the sync method, rather than in place of it, because O_DIRECT doesn't have the same media write guarantees as fsync(). Would you update the patch to do O_DIRECT in addition to O_SYNC or fsync() and see if there is a performance win? Thanks. --------------------------------------------------------------------------- ITAGAKI Takahiro wrote: > Neil Conway <neilc@samurai.com> wrote: > > > > The patch adds a new choice "open_direct" to wal_sync_method. > > Have you looked at what the performance difference of this option is? > > Yes, I've tested pgbench and dbt2 and their performances have improved. > The two results are as follows: > > 1. pgbench -s 100 on one Pentium4, 1GB mem, 2 ATA disks, Linux 2.6.8 > (attached image) > tps | wal_sync_method > -------+------------------------------------------------------- > 147.0 | open_direct + write multipage (previous patch) > 147.2 | open_direct (this patch) > 109.9 | open_sync > > 2. dbt2 100WH on two opterons, 8GB mem, 12 SATA-RAID disks, Linux 2.4.20 > tpm | wal_sync_method > --------+------------------------------------------------------ > 1183.9 | open_direct (this patch) > 911.3 | fsync > > > > > http://www.mail-archive.com/pgsql-patches@postgresql.org/msg07186.html > > Is this data still applicable to the revised patch? > > Direct-IO might be good on some machines, and bad on others. > This data is another reason that I revised the patch; > If you don't use open_direct, WAL writer behaves quite similarly to former. > > However, the performances did not go down at least on my benchmarks. > I have no idea why the above data was bad... > > --- > ITAGAKI Takahiro > NTT Cyber Space Laboratories > [ Attachment, skipping... ] > > ---------------------------(end of broadcast)--------------------------- > TIP 1: subscribe and unsubscribe commands go to majordomo@postgresql.org -- Bruce Momjian | http://candle.pha.pa.us pgman@candle.pha.pa.us | (610) 359-1001 + If your life is a hard drive, | 13 Roberts Road + Christ can be your backup. | Newtown Square, Pennsylvania 19073