Thread: Excessive WAL generation and related performance issue
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 I have run into a situation where bulk loading a table with fairly narrow rows and two indexes causes WAL to be generated at about 20:1 or higher ratio to the actual heap data (table plus indexes). There are 560 million loaded rows which ultimately produce a table of about 50 GB and indexes consuming about 75 GB for a grand total of 125 GB table+index heap size. This generates over 3 TB of WAL. The loading progresses fairly fast at first and then drops off sharply so that the load takes 4 plus days on production hardware. Near the end of the load the heap grows very slowly -- measured in tens of MBs per hour. I have reproduced the case on a test machine like so: create table foo ( pid varchar(11) not null, sprid varchar(5) not null, cid varchar(11) not null, csdt date not null, pcind char(1) not null,cedt date, csnum int2 not null default 767, rcd char(2) not null default '99'::bpchar, rrind char(1) not null default'K'::bpchar, its timestamp not null default now(), luts timestamp not null default now(), primary key (pid,sprid,cid,csdt,rcd) ); create index fooidx on foo(cid,pid); - -- creates 77GB file for test load copy ( select (id % 2604380)::text, (id % 30)::text, (id % 7906790)::text, now() - ((id % 8777)::text || ' days')::interval, (id % 3)::text, now() - ((id % 6351)::text || ' days')::interval, (id % 5)::int2, (id % 27)::text, (id % 2)::text, now() - ((id % 16922)::text || ' seconds')::interval, now() - ((id % 27124)::text || ' seconds')::intervalfrom generate_series(10000000000,10000000000 + 559245675) as g(id) ) to '/home/postgres/foo.dump'; grep -E "^($|#|\s.*#?)" -v $PGDATA/postgresql.conf max_connections = 1200 superuser_reserved_connections = 30 shared_buffers = 12288MB work_mem = 8MB maintenance_work_mem = 128MB wal_level = hot_standbyhot_standby checkpoint_segments = 96 checkpoint_timeout = 10min checkpoint_completion_target = 0.7 archive_mode = on archive_command = 'cp -i %p /home/postgres/archive/%f </dev/null' max_wal_senders = 5 wal_keep_segments = 256 log_line_prefix = '%m;' psql --echo-all \ --single-transaction \ --set ON_ERROR_STOP=on \ --dbname=test \ --file=/home/postgres/foo.dump I had to kill it at just over half way done because I ran out of disk space for WAL. This chart shows the growth of heap and WAL against number of rows copied over time (I added an elog LOG to get messages during XlogInsert). http://www.joeconway.com/presentations/test01.png Also worth noting is that once this thing gets going, using "perf top" I could see XLogInsert consuming 20-40% of all cycles, and the vast majority of that was going into the CRC calculation. I realize there are many things that can be done to improve my specific scenario, e.g. drop indexes before loading, change various configs, etc. My purpose for this post is to ask if it is really expected to get over 20 times as much WAL as heap data? Oh, and this is all on postgres 9.2.latest. I have not yet tried to reproduce on git master but intend to do so. Thoughts? Thanks, Joe - -- Joe Conway credativ LLC: http://www.credativ.us Linux, PostgreSQL, and general Open Source Training, Service, Consulting, & 24x7 Support -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.14 (GNU/Linux) Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/ iQIcBAEBAgAGBQJTTFQPAAoJEDfy90M199hlO+cP/jthKJJqkNMyVwWADHjZaeOC 4fgYSPvEGi8y2AtRZwBIKMWSVhCKbwZ+ZLdpUk3jJ1eIPOvxTAlbdf/haXctRDHv ZLgs6uBSihbG2guijkxnMtSPjXql6WKmai+UncuGGcsqHvEwvnqIGdr7eg5Rd+c4 Q0b36DhoadKVJEwT3qWGfUXxcpkQIG5hgh39GOhQtL7xW+Tf6odLrep0/lmiNCaz 9eIcbVCzc8cIG8jGugSsGGHo1UA/s5A0aEd3mx5ZnroHjUvEWdHuTNY7ijXs6pqk ynSHSJtDikTGVxJlj68nv/wGtHN0+xbsci/qv0sTZfOUh8mwfkBZAiOEyzK6lDcc cxzafqAkFIpIL9cDPyhxWbSOI8LAqXfRGTiM5rsguX4iCuf3SEYl48f6sZ9CW3Jt zNDlns2BZKKWWx88H/EL84sajo/SJS0Ml+9ppmV3TpA4zHHfiEpn3Rg4/Nsj0qzj H/kx2UwSXA7iQiQ860gL+EggN0MmVcN+/KOAAg/9cJ4DL8TiVTv/vn5Rspv19Hu1 A12tWnioxGaFsuPAjtZCpxHPUOD3jUUSEJEAYJTCW3eJ7a6SPgAIq3eGE0Fj4v00 RWsCVhqydteuvB59MSAvtA06MHfer/fDvOK2rquY/HnOtwwdPkGG7QZ21lyfhdH1 UKo0u4OmvQuHJsiT7Z2W =xxw3 -----END PGP SIGNATURE-----
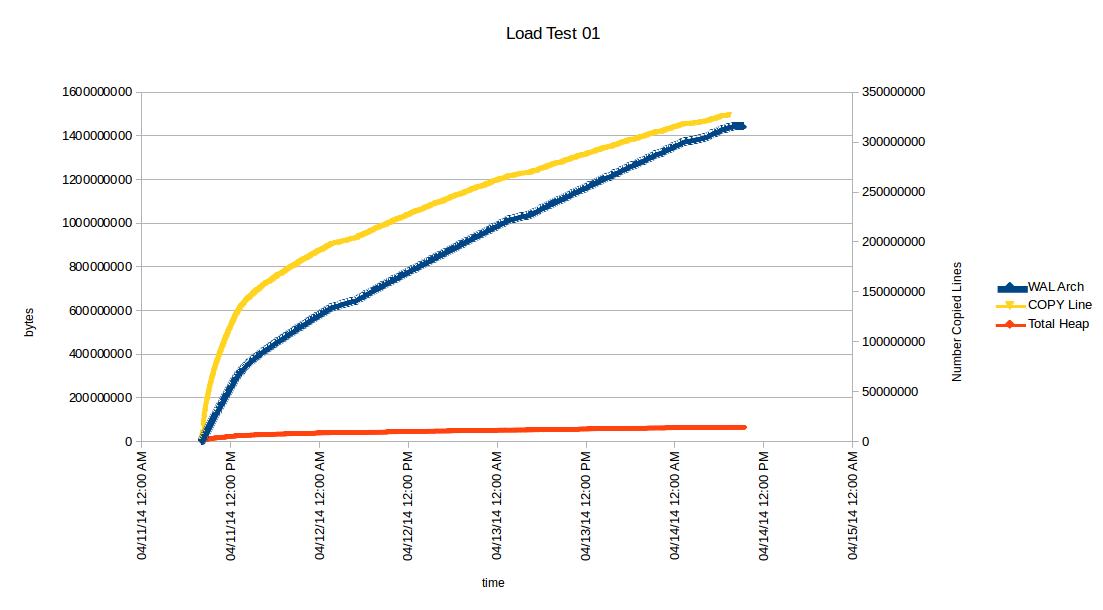{kind=link}
Hi, On 2014-04-14 14:33:03 -0700, Joe Conway wrote: > checkpoint_segments = 96 > checkpoint_timeout = 10min > I realize there are many things that can be done to improve my > specific scenario, e.g. drop indexes before loading, change various > configs, etc. My purpose for this post is to ask if it is really > expected to get over 20 times as much WAL as heap data? I'd bet a large percentage of this will be full page images of the index. The values you index are essentially distributed over the whole index, so you'll modifiy the same indx values repeatedly. But often enough it won't be in the same checkpoint and thus will create full page images. I bet you'll see noticeably - while still not great - better performance by setting checkpoint_timeout to an hour (with a corresponding increase in checkpoint_segments). Have you checked how often checkpoints are actually created? I'd bet it's far more frequent than every 10min with that _segments setting and such a load. Greetings, Andres Freund
On 4/14/14, 4:50 PM, Andres Freund wrote: > Hi, > > On 2014-04-14 14:33:03 -0700, Joe Conway wrote: >> checkpoint_segments = 96 >> checkpoint_timeout = 10min > >> I realize there are many things that can be done to improve my >> specific scenario, e.g. drop indexes before loading, change various >> configs, etc. My purpose for this post is to ask if it is really >> expected to get over 20 times as much WAL as heap data? > > I'd bet a large percentage of this will be full page images of the > index. The values you index are essentially distributed over the whole > index, so you'll modifiy the same indx values repeatedly. But often > enough it won't be in the same checkpoint and thus will create full page > images. My thought exactly... ISTM that we should be able to push all the index inserts to the end of the transaction. That should greatly reduce the amountof full page writes. That would also open the door for doing all the index inserts in parallel. -- Jim C. Nasby, Data Architect jim@nasby.net 512.569.9461 (cell) http://jim.nasby.net
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 On 04/14/2014 03:17 PM, Jim Nasby wrote: > On 4/14/14, 4:50 PM, Andres Freund wrote: >> On 2014-04-14 14:33:03 -0700, Joe Conway wrote: >>> I realize there are many things that can be done to improve my >>> specific scenario, e.g. drop indexes before loading, change >>> various configs, etc. My purpose for this post is to ask if it >>> is really expected to get over 20 times as much WAL as heap >>> data? >> >> I'd bet a large percentage of this will be full page images of >> the index. The values you index are essentially distributed over >> the whole index, so you'll modifiy the same indx values >> repeatedly. But often enough it won't be in the same checkpoint >> and thus will create full page images. > > My thought exactly... > > ISTM that we should be able to push all the index inserts to the > end of the transaction. That should greatly reduce the amount of > full page writes. That would also open the door for doing all the > index inserts in parallel. That's the thing. I'm sure there is tuning and other things to improve this particular case, but creating over 20 times as much WAL as real data seems like pathological behavior to me. Joe - -- Joe Conway credativ LLC: http://www.credativ.us Linux, PostgreSQL, and general Open Source Training, Service, Consulting, & 24x7 Support -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.14 (GNU/Linux) Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/ iQIcBAEBAgAGBQJTTGZ8AAoJEDfy90M199hlhXQQAJfs/FOk6W83bVdU4pRN5bVI HW0jeMwX4NtUigW2vk5tKWcCgWKDTZvvV2TE3C7XPQnoa4TC51bjFJDHErKxNV8i vFk47OFvg4AEoILeRgsemLJFCc0jDlc5VClnNiH8esUjmOAv9vFktJ3JymVdaIYL 3ytxMyF/KYiCeWQlu6WZTfFD9qqdZh6dWIkm6m8gVXJstr+jVVkxHe2lNQe77nEi DycHy/4dmMd4QThxw3sRzEGW1GNGGk/6X1zmZECXYu7v95E5dFLl1oD2CFUMpoGh D5LWZqfuyhN0lHLe5nwTvvYeTGMg5+r/fVm1Y4oWbAQPjWycZcrMCFPho7U+5CHC XPt6FuaIZlZ4GBPCNj398xyPZdwWkOBEhfvhu601ibOVbQwBECnWQxGpMTukCvxT giaZD8C1Ty/MAq0lleAPdkNN91GPqMkhd46sG/aVMDOGtjfJkfYFeqj6b7rbFknw +wdioB0+vTFQ+hJ3yzVIAR09RoL0o3UW/8C1kOE5jIjJZPxdta5or7ZD77y1RLJI /UVU2LVcyS82ddmWcWM6/q5LaqlPgityZZmIoi8Hxp1ywNzIZcyY0t1RJkMrrb0I LIOTSizFA1zFM3lDNV7sF261DQS9IjOSgeSMIfB9zJQArWWwJ7c/DiTEbwpZu7iz 0VKmaJk15zqf1FWEdX+I =l6F9 -----END PGP SIGNATURE-----
On 4/14/14, 5:51 PM, Joe Conway wrote: > -----BEGIN PGP SIGNED MESSAGE----- > Hash: SHA1 > > On 04/14/2014 03:17 PM, Jim Nasby wrote: >> On 4/14/14, 4:50 PM, Andres Freund wrote: >>> On 2014-04-14 14:33:03 -0700, Joe Conway wrote: >>>> I realize there are many things that can be done to improve my >>>> specific scenario, e.g. drop indexes before loading, change >>>> various configs, etc. My purpose for this post is to ask if it >>>> is really expected to get over 20 times as much WAL as heap >>>> data? >>> >>> I'd bet a large percentage of this will be full page images of >>> the index. The values you index are essentially distributed over >>> the whole index, so you'll modifiy the same indx values >>> repeatedly. But often enough it won't be in the same checkpoint >>> and thus will create full page images. >> >> My thought exactly... >> >> ISTM that we should be able to push all the index inserts to the >> end of the transaction. That should greatly reduce the amount of >> full page writes. That would also open the door for doing all the >> index inserts in parallel. > > That's the thing. I'm sure there is tuning and other things to improve > this particular case, but creating over 20 times as much WAL as real > data seems like pathological behavior to me. Can you take a look at what's actually going into WAL when the wheels fall off? I think it should be pretty easy to testthe theory that it's a ton of full page writes of index leaf pages... -- Jim C. Nasby, Data Architect jim@nasby.net 512.569.9461 (cell) http://jim.nasby.net
Andres Freund <andres@2ndquadrant.com> writes:
> On 2014-04-14 14:33:03 -0700, Joe Conway wrote:
>> checkpoint_segments = 96
>> checkpoint_timeout = 10min
> I bet you'll see noticeably - while still not great - better performance
> by setting checkpoint_timeout to an hour (with a corresponding increase
> in checkpoint_segments).
> Have you checked how often checkpoints are actually created? I'd bet
> it's far more frequent than every 10min with that _segments setting and
> such a load.
My thoughts exactly. It's not hard to blow through WAL at multiple
megabytes per second with modern machines. I'd turn on checkpoint logging
and then do whatever you need to do to get the actual intercheckpoint time
up to 10-15 minutes at least.
regards, tom lane
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 On 04/14/2014 04:17 PM, Tom Lane wrote: > Andres Freund <andres@2ndquadrant.com> writes: >> On 2014-04-14 14:33:03 -0700, Joe Conway wrote: >>> checkpoint_segments = 96 checkpoint_timeout = 10min > >> I bet you'll see noticeably - while still not great - better >> performance by setting checkpoint_timeout to an hour (with a >> corresponding increase in checkpoint_segments). Have you checked >> how often checkpoints are actually created? I'd bet it's far more >> frequent than every 10min with that _segments setting and such a >> load. > > My thoughts exactly. It's not hard to blow through WAL at > multiple megabytes per second with modern machines. I'd turn on > checkpoint logging and then do whatever you need to do to get the > actual intercheckpoint time up to 10-15 minutes at least. That'll help performance, but lets say I generally keep WAL files for PITR and don't turn that off before starting -- shouldn't I be very surprised to need over 3TB of archive storage when loading a 50GB table with a couple of indexes? Joe - -- Joe Conway credativ LLC: http://www.credativ.us Linux, PostgreSQL, and general Open Source Training, Service, Consulting, & 24x7 Support -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.14 (GNU/Linux) Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/ iQIcBAEBAgAGBQJTTG3IAAoJEDfy90M199hluaIP/00NYTg+AiRNTaMkhZAqFxxl 8Fysfbe9UXedGU/3hzcq0rCNuQEuG4qiNjGEBCgsQuW9smxvzIzuT5EAAmdOP6jR lWGW1574g9qaRT2GNTnlt5hKArVJtE+wlmzspAK12aiLlhSax4o0dAIibRliZ+nZ a7Ay8ZcrwcNCyZKg0UjXhZ75SXQyxdYxygIhMzmYgB9UyfTxh0Dbujd692QvpzyG gnBl6iqZH/EJFkU821QILf7UNzGALdZ3aSpfijwtkAnIyMt5ZB5JzuEFCd/+Xpe7 GZnl4hKpyD9chqQ+vv4YRJrdAxH3pfsYPo/ksyMZrRnBl5ezDLehdopLXEsh4hZI XDVqQPgC1tPR6DNAYAWT2bR2iO11GZLyhmZ8aU7eDVbBlUe7bE37L3f4yr3shzsm A98J1GbDq4NYWJPeta8x0o8xg3A+HR/Q/+qYqH4hgRU+RhuV4kQ5Vl1xIP9a0gqV +95y6sznGM0mtDfZMvqf3uNotKpIKeBCsHyshMXXYiPr4JxkymIAuh1zYLzQMBN5 wrJ2hUG2wIH2hra3sihokyZeqK9CeO7jEtVEtaGz8CEL2ihHnAMkO6uRWzpsOgW4 Xk8+iWt+RO7dfPBNa1N0urCCgr3KYOE0M5TaxtrGnfT7/bGlcNKpVIC9a48SqK+U acttmBm6Ev8XVyEqpUit =GT5+ -----END PGP SIGNATURE-----
On 2014-04-14 16:22:48 -0700, Joe Conway wrote: > -----BEGIN PGP SIGNED MESSAGE----- > Hash: SHA1 > > On 04/14/2014 04:17 PM, Tom Lane wrote: > > Andres Freund <andres@2ndquadrant.com> writes: > >> On 2014-04-14 14:33:03 -0700, Joe Conway wrote: > >>> checkpoint_segments = 96 checkpoint_timeout = 10min > > > >> I bet you'll see noticeably - while still not great - better > >> performance by setting checkpoint_timeout to an hour (with a > >> corresponding increase in checkpoint_segments). Have you checked > >> how often checkpoints are actually created? I'd bet it's far more > >> frequent than every 10min with that _segments setting and such a > >> load. > > > > My thoughts exactly. It's not hard to blow through WAL at > > multiple megabytes per second with modern machines. I'd turn on > > checkpoint logging and then do whatever you need to do to get the > > actual intercheckpoint time up to 10-15 minutes at least. > > That'll help performance, but lets say I generally keep WAL files for > PITR and don't turn that off before starting -- shouldn't I be very > surprised to need over 3TB of archive storage when loading a 50GB > table with a couple of indexes? The point is that more frequent checkpoints will increase the WAL volume *significantly* because more full page writes will have to be generated. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 On 04/14/2014 04:25 PM, Andres Freund wrote: > On 2014-04-14 16:22:48 -0700, Joe Conway wrote: >> That'll help performance, but lets say I generally keep WAL files >> for PITR and don't turn that off before starting -- shouldn't I >> be very surprised to need over 3TB of archive storage when >> loading a 50GB table with a couple of indexes? > > The point is that more frequent checkpoints will increase the WAL > volume *significantly* because more full page writes will have to > be generated. OK, I'll see how much it can be brought down through checkpoint tuning and report back. Thanks! Joe - -- Joe Conway credativ LLC: http://www.credativ.us Linux, PostgreSQL, and general Open Source Training, Service, Consulting, & 24x7 Support -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.14 (GNU/Linux) Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/ iQIcBAEBAgAGBQJTTHCgAAoJEDfy90M199hlRnUP/3kJket9GmwEQoMUhndpxmDu 7+qDX4gFsZEGkndF6OxivSxZdRrjdioJA0STinx82w+GTpwZuBbjBfPmmjbW7kY+ t8QfuJzAauoSnscaE/NRVL2IJivRsAWbNpwWvC7nbLIhZmE4rXytN53izJwAHwP6 qJlyLmlvMB3IH75uoVo3AMQggE+gMy6kmDSfQST7e0RpkxE7Zsp51B7m6MLOxXjc gpf8ukZztCUvxFwI1ds++hEeUR7qpAT5V/1hhcFBqKOCoYXeTxH7PUrPofdcg7PT rzlGyBARQNz6apnEUCB3/bhQENHdXjmrXBeeyNUNug2jSXsi7BJpccJhPYN49XB4 FAGGxyQLB4Gl75oSO9cYJ8B0b0peYYIm9VhBOPUw1iPgouNsdlh+yA4QagPp3VnW O8+Fdf/6lcBgbABEfDwCRBBkyaVSvckqrzp946YnasiCENad3zz4UEWfekEpRzk6 QTyVsObjjKHmOFt9mGeUOH7hGpTwleT5oXDttCWOxPtDkwB6tT1pC7DnRPpmYCvt FWQC11sN0RNIeOl2W2Zo18P3dtlI8anQ/ano4FE1Dx8GKypncxAIm7RlRCKuax+C anL7fNie/ObZRMNxQ0m7nJvbzOKjVooslUDnBTje4um1Aw1ljS74brqqKkWUOP6C 3GReDBEE20wLsD/5t6L+ =/L/M -----END PGP SIGNATURE-----
* Joe Conway (mail@joeconway.com) wrote:
> That's the thing. I'm sure there is tuning and other things to improve
> this particular case, but creating over 20 times as much WAL as real
> data seems like pathological behavior to me.
Setting things up such that you are updating a single value on each page
in an index during each checkpoint, which then requires basically
rewriting the entire index as full page writes at checkpoint time, is
definitely pathological behavior- but sadly, not behavior we are likely
to be able to fix..
This sounds like a great example of the unlogged table -> logged table
use-case and makes me wonder if we could provide an optimization similar
to the existing CREATE TABLE + COPY under wal_level = minimal case,
where we wouldn't WAL log anything for CREATE TABLE + COPY even when
wal_level is above minimal, until COMMIT, at which point we'll blast the
whole thing out in one shot.
Another option that you might consider is ordering your input, if
possible, to improve the chances that the same page is changed multiple
times inside a given checkpoint, hopefully reducing the number of pages
changed.
Thanks,
Stephen
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 On 04/14/2014 05:40 PM, Stephen Frost wrote: > This sounds like a great example of the unlogged table -> logged > table use-case and makes me wonder if we could provide an > optimization similar to the existing CREATE TABLE + COPY under > wal_level = minimal case, where we wouldn't WAL log anything for > CREATE TABLE + COPY even when wal_level is above minimal, until > COMMIT, at which point we'll blast the whole thing out in one > shot. I was definitely thinking that it would be nice if we could alter this table to make it unlogged, load it, and then alter again to make it logged. Obviously easier said than done though ;-) > Another option that you might consider is ordering your input, if > possible, to improve the chances that the same page is changed > multiple times inside a given checkpoint, hopefully reducing the > number of pages changed. Nice idea but doesn't work well when you have two indexes with different first column correlations. Joe - -- Joe Conway credativ LLC: http://www.credativ.us Linux, PostgreSQL, and general Open Source Training, Service, Consulting, & 24x7 Support -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.14 (GNU/Linux) Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/ iQIcBAEBAgAGBQJTTIj5AAoJEDfy90M199hlJ5AP/RQBGkdOpcVzFsZOmj0keN5z SB7BmyX8qzzL9C8xNirHektyJ0QvFFuUIMN3vTC9hvQJQjoJEn8FO3GMlvmNlK4J edFDEQVWj3e1etQhEnGJlDeALAqWc9emwOVvCsdllONq0KWMYIKW8ex5i921W3ya 1yzCc9fHuihCBb3UYakkEKoKgpJ4JkLPA3Ak9cEcHZOUWp+JEudiUpD12OgKqyZ7 HwmW5clpQWLwyIZtx9e+/5psjDTytBNIYb1xpF4XuSv1CqbL8UEynNs5KjgDdziY 0w+DOF+xe1gWCj4Qou/c466YybFeo68YU5O1YSydfl/e0IxX7AwYTu+LfiUCUutP 0SNhrpPksoZQQ9hwlYcJLDskl8AAlUbTmSGfU7rvfZq1FDe5AramBkGUhQkwigIn HXpZ2CWLMvive9NwXM2s69Rsnb51lu9LQ9ewmbDY9mPsdOye1WEy89xr3JG624UV CuOQAzCmPI0HXJsPuDNdqJY9Hgk3Prypq3viBbfmQzDCIc+v1dT3S9SELOtERnZp HejpcXoSck6A3SrTRPAe1F8kx5ssiJF83Tnc6kdiHndzK2vN85RXHIAA1DX4lKpF oS7+l1y6Gx1Y1K3Tru87+P3j6CNHcdaca2ZdzMlPyEcuZ08/M949SSQkoILNrHAA BtB+B/XiJE8Sn9cBhG1J =7qHf -----END PGP SIGNATURE-----
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA1
On 04/14/2014 04:34 PM, Joe Conway wrote:
> On 04/14/2014 04:25 PM, Andres Freund wrote:
>> On 2014-04-14 16:22:48 -0700, Joe Conway wrote:
>>> That'll help performance, but lets say I generally keep WAL
>>> files for PITR and don't turn that off before starting --
>>> shouldn't I be very surprised to need over 3TB of archive
>>> storage when loading a 50GB table with a couple of indexes?
>
>> The point is that more frequent checkpoints will increase the
>> WAL volume *significantly* because more full page writes will
>> have to be generated.
>
> OK, I'll see how much it can be brought down through checkpoint
> tuning and report back.
One more question before I get to that. I had applied the following
patch to XLogInsert
8<--------------------------
diff --git a/src/backend/access/transam/xlog.c
b/src/backend/access/transam/xlog.c
index 2f71590..e39cd37 100644
- --- a/src/backend/access/transam/xlog.c
+++ b/src/backend/access/transam/xlog.c
@@ -737,10 +737,12 @@ XLogInsert(RmgrId rmid, uint8 info, XLogRecData
*rdata) uint32 len, write_len; unsigned i;
+ unsigned inorm; bool updrqst; bool doPageWrites; bool
isLogSwitch= (rmid == RM_XLOG_ID && info ==
XLOG_SWITCH); uint8 info_orig = info;
+ uint32 xl_tot_len;
/* cross-check on whether we should be here or not */ if (!XLogInsertAllowed())
@@ -924,8 +926,23 @@ begin:; * header. */ INIT_CRC32(rdata_crc);
+ i = 0;
+ inorm = 0; for (rdt = rdata; rdt != NULL; rdt = rdt->next)
+ { COMP_CRC32(rdata_crc, rdt->data, rdt->len);
+
+ if (rdt_lastnormal == rdt)
+ {
+ inorm = i;
+ i = 0;
+ }
+ else
+ i++;
+ }
+ xl_tot_len = SizeOfXLogRecord + write_len;
+ if ((inorm + i) > 4 || xl_tot_len > 2000)
+ elog(LOG,
"XLogInsert;tot_nml_blks;%d;tot_bkp_blks;%d;tot_Xlog_Len;%d", inorm,
i, xl_tot_len);
START_CRIT_SECTION();
8<--------------------------
The idea was to record number of normal and backup blocks, and total
size of the record. I have quite a few entries in the log from the
test run which are like:
8<--------------------------
2014-04-11 08:42:06.904 PDT;LOG:
XLogInsert;tot_nml_blks;4;tot_bkp_blks;5;tot_Xlog_Len;16168
2014-04-11 09:03:12.790 PDT;LOG:
XLogInsert;tot_nml_blks;4;tot_bkp_blks;5;tot_Xlog_Len;16172
2014-04-11 10:16:57.949 PDT;LOG:
XLogInsert;tot_nml_blks;3;tot_bkp_blks;5;tot_Xlog_Len;16150
8<--------------------------
and
8<--------------------------
2014-04-11 11:17:08.313 PDT;LOG:
XLogInsert;tot_nml_blks;4;tot_bkp_blks;6;tot_Xlog_Len;12332
2014-04-11 11:17:08.338 PDT;LOG:
XLogInsert;tot_nml_blks;4;tot_bkp_blks;6;tot_Xlog_Len;16020
2014-04-11 11:17:08.389 PDT;LOG:
XLogInsert;tot_nml_blks;4;tot_bkp_blks;6;tot_Xlog_Len;12332
8<--------------------------
In other words, based on my inserted logic, it appears that there are
5 and 6 backup blocks on a fairly regular basis.
However in xlog.h it says:
8<--------------------------* If we backed up any disk blocks with the XLOG record, we use flag* bits in xl_info to
signalit. We support backup of up to 4 disk* blocks per XLOG record.
8<--------------------------
So is my logic to record number of backup blocks wrong, or is the
comment wrong, or am I otherwise misunderstanding something?
Thanks,
Joe
- --
Joe Conway
credativ LLC: http://www.credativ.us
Linux, PostgreSQL, and general Open Source
Training, Service, Consulting, & 24x7 Support
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1.4.14 (GNU/Linux)
Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/
iQIcBAEBAgAGBQJTTZxJAAoJEDfy90M199hl15MQAKTcv9BoZTsXDleSu9JrU1ha
UhHUnDALRmxWLgyPYsgtifxMQ3jLp5eLrkMHGnQbVD17619OgHckuOiEphc2bdQp
MfZlv3jrEqxnmsh6qKhK1J23mHj0cohWXQ9EUoyjE6tlZueLPyMigaIV662KP1d2
pUXCh6IEJYMMaPfqhR5Mxi62s+HMkpAULhafWeEeAwcU1eYNijFWlyxJWlsv7D6X
9ZuDSmRtqnAP0g23GcbxNkL/I9Yv090Uxar7um2Rw5SEUV+Uv1kMY0GVCjHluE0k
qZhSF1tE2jypThhSnv5xRHT3ZzdKoJtNmfLekjws7+dFZbSBLgNOj4EdV0H/wUgf
NqO71kkeRhd44uMRzii0cr03LwBiwqC2apCYoZy7s0X3rl10hZfKgVEKkyhaZ4VJ
QdfR1WdY/hC7mKW7NPnkycF+Es1ykEfuPnKHHsyJ3fHeFGxkKD3I6A8jGnNnS6VL
ba+jx+t3qnrcKQAW8lqQ3rAij5Jkb97Ljibc7o6w8cgnGA4S0tqsE6jDrdDR1FO4
ns5uULTs4REU8clFwiKNZnQfINRUUfqY1mtlRneJMANeafm0j2CyIzvqLqB2mdOH
YL9SS2lIngQlVSfgpu7EiSS7sJx8XGe3a3YFE9DoTBpq009scrscH40+kuN823wp
yruufkzaBN6lyAjo3zoR
=GQDN
-----END PGP SIGNATURE-----
Joe Conway <mail@joeconway.com> writes:
> In other words, based on my inserted logic, it appears that there are
> 5 and 6 backup blocks on a fairly regular basis.
> However in xlog.h it says:
> 8<--------------------------
> * If we backed up any disk blocks with the XLOG record, we use flag
> * bits in xl_info to signal it. We support backup of up to 4 disk
> * blocks per XLOG record.
> 8<--------------------------
> So is my logic to record number of backup blocks wrong, or is the
> comment wrong, or am I otherwise misunderstanding something?
The comment is correct, so you did something wrong. From memory,
there's a goto-label retry loop in that function; maybe you need
to zero your counters after the retry label?
regards, tom lane
On 04/15/2014 11:53 PM, Joe Conway wrote:
> One more question before I get to that. I had applied the following
> patch to XLogInsert
>
> 8<--------------------------
> diff --git a/src/backend/access/transam/xlog.c
> b/src/backend/access/transam/xlog.c
> index 2f71590..e39cd37 100644
> - --- a/src/backend/access/transam/xlog.c
> +++ b/src/backend/access/transam/xlog.c
> @@ -737,10 +737,12 @@ XLogInsert(RmgrId rmid, uint8 info, XLogRecData
> *rdata)
> uint32 len,
> write_len;
> unsigned i;
> + unsigned inorm;
> bool updrqst;
> bool doPageWrites;
> bool isLogSwitch = (rmid == RM_XLOG_ID && info ==
> XLOG_SWITCH);
> uint8 info_orig = info;
> + uint32 xl_tot_len;
>
> /* cross-check on whether we should be here or not */
> if (!XLogInsertAllowed())
> @@ -924,8 +926,23 @@ begin:;
> * header.
> */
> INIT_CRC32(rdata_crc);
> + i = 0;
> + inorm = 0;
> for (rdt = rdata; rdt != NULL; rdt = rdt->next)
> + {
> COMP_CRC32(rdata_crc, rdt->data, rdt->len);
> +
> + if (rdt_lastnormal == rdt)
> + {
> + inorm = i;
> + i = 0;
> + }
> + else
> + i++;
> + }
> + xl_tot_len = SizeOfXLogRecord + write_len;
> + if ((inorm + i) > 4 || xl_tot_len > 2000)
> + elog(LOG,
> "XLogInsert;tot_nml_blks;%d;tot_bkp_blks;%d;tot_Xlog_Len;%d", inorm,
> i, xl_tot_len);
>
> START_CRIT_SECTION();
> 8<--------------------------
>
> The idea was to record number of normal and backup blocks, and total
> size of the record. I have quite a few entries in the log from the
> test run which are like:
>
> 8<--------------------------
> 2014-04-11 08:42:06.904 PDT;LOG:
> XLogInsert;tot_nml_blks;4;tot_bkp_blks;5;tot_Xlog_Len;16168
> 2014-04-11 09:03:12.790 PDT;LOG:
> XLogInsert;tot_nml_blks;4;tot_bkp_blks;5;tot_Xlog_Len;16172
> 2014-04-11 10:16:57.949 PDT;LOG:
> XLogInsert;tot_nml_blks;3;tot_bkp_blks;5;tot_Xlog_Len;16150
> 8<--------------------------
>
> and
>
> 8<--------------------------
> 2014-04-11 11:17:08.313 PDT;LOG:
> XLogInsert;tot_nml_blks;4;tot_bkp_blks;6;tot_Xlog_Len;12332
> 2014-04-11 11:17:08.338 PDT;LOG:
> XLogInsert;tot_nml_blks;4;tot_bkp_blks;6;tot_Xlog_Len;16020
> 2014-04-11 11:17:08.389 PDT;LOG:
> XLogInsert;tot_nml_blks;4;tot_bkp_blks;6;tot_Xlog_Len;12332
> 8<--------------------------
>
>
> In other words, based on my inserted logic, it appears that there are
> 5 and 6 backup blocks on a fairly regular basis.
>
> However in xlog.h it says:
> 8<--------------------------
> * If we backed up any disk blocks with the XLOG record, we use flag
> * bits in xl_info to signal it. We support backup of up to 4 disk
> * blocks per XLOG record.
> 8<--------------------------
>
> So is my logic to record number of backup blocks wrong, or is the
> comment wrong, or am I otherwise misunderstanding something?
You're counting XLogRecData structs, not backup blocks. Each backup
block typically consists of three XLogRecData structs, one to record a
BkpBlock struct, one to record the data before the unused "hole" in the
middle of the page, and one for after. Sometimes just two, if there is
no hole to skip. See the loop just before the CRC calculation, that's
where the XLogRecData entries for backup blocks are created.
- Heikki
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 On 04/15/2014 02:15 PM, Heikki Linnakangas wrote: > You're counting XLogRecData structs, not backup blocks. Each > backup block typically consists of three XLogRecData structs, one > to record a BkpBlock struct, one to record the data before the > unused "hole" in the middle of the page, and one for after. > Sometimes just two, if there is no hole to skip. See the loop just > before the CRC calculation, that's where the XLogRecData entries > for backup blocks are created. > > - Heikki Ah, thanks for the explanation! Joe - -- Joe Conway credativ LLC: http://www.credativ.us Linux, PostgreSQL, and general Open Source Training, Service, Consulting, & 24x7 Support -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.14 (GNU/Linux) Comment: Using GnuPG with Thunderbird - http://www.enigmail.net/ iQIcBAEBAgAGBQJTTaLxAAoJEDfy90M199hlwuQP/3Tuea1TUe+4L21ZdProNIIF fUtejFNUwqhkyWNcnePlubgSyTEIfHGEG9hatrB5/MWdzpiyEvXdDkvV1ODakEhJ CVKZbnQ4dmnrevypy2f2YdhlbB9du/DDFhFcPOZGbn+vLywwM9oMPS8tQmsol37e aITe2GnD5LpEcmCSqzz04OL+xAxKLe8fXaI9dDsTRWXb9qdj4pDHI706CeixwSFb sGsGcIHXmnWieMby9qfWc0WGpc38iMRRkE+LeaEULhsycFP/2x09irXdhbl5T1SH 4PItwX0/ZgLskklG2gaD4HpNe75+Emj1i22PHDYhXSoAzpykHUf+kZZwMUr0AbaF 5QVCer071jHaMacpaVC7/qwUt8zISx4/1wtJuQzfk5H3P2q4L+b/xPmod5/cqs9z /wFp+9kjMT4349sSMe1eDPTDoIZKgRh8Eiag5IfJtrOAjoK+FN+k8uWNikiyFDMu z/3l+6mbfrl7FAmfeXLFC9fqhhGOiGLHoZufB/4qFgEikj4S94Hx9Q0nHqkMsFvM Fcd3qcpLI06Xku7LmBPRvdZ8OVFGWAirH1jBlrdsvC9E5VoZxgByxg90EaTlwjAQ 1ZaGOsbQoXdOPOwe/rGx2ONGwgZp8uFwHSXzUY+CJucvfYQh2AD67AlEhS7Jb9NC ummpulzJ6arce0815KaT =Y+m4 -----END PGP SIGNATURE-----