Thread: Proposing pg_hibernate
Please find attached the pg_hibernate extension. It is a set-it-and-forget-it solution to enable hibernation of Postgres shared-buffers. It can be thought of as an amalgam of pg_buffercache and pg_prewarm.
It uses the background worker infrastructure. It registers one worker process (BufferSaver) to save the shared-buffer metadata when server is shutting down, and one worker per database (BlockReader) when restoring the shared buffers.
It stores the buffer metadata under $PGDATA/pg_database/, one file per database, and one separate file for global objects. It sorts the list of buffers before storage, so that when it encounters a range of consecutive blocks of a relation's fork, it stores that range as just one entry, hence reducing the storage and I/O overhead.
On-disk binary format, which is used to create the per-database save-files, is defined as:
1. One or more relation filenodes; stored as r<relfilenode>.
2. Each realtion is followed by one or more fork number; stored as f<forknumber>
3. Each fork number is followed by one or more block numbers; stored as b<blocknumber>
4. Each block number is followed by zero or more range numbers; stored as N<number>
{r {f {b N* }+ }+ }+
Possible enhancements:
- Ability to save/restore only specific databases.
- Control how many BlockReaders are active at a time; to avoid I/O storms.
- Be smart about lowered shared_buffers across the restart.
- Different modes of reading like pg_prewarm does.
- Include PgFincore functionality, at least for Linux platforms.
The extension currently works with PG 9.3, and may work on 9.4 without any changes; I haven't tested, though. If not, I think it'd be easy to port to HEAD/PG 9.4. I see that 9.4 has put a cap on maximum background workers via a GUC, and since my aim is to provide a non-intrusive no-tuning-required extension, I'd like to use the new dynamic-background-worker infrastructure in 9.4, which doesn't seem to have any preset limits (I think it's limited by max_connections, but I may be wrong). I can work on 9.4 port, if there's interest in including this as a contrib/ module.
To see the extension in action:
.) Compile it.
.) Install it.
.) Add it to shared_preload_libraries.
.) Start/restart Postgres.
.) Install pg_buffercache extension, to inspect the shared buffers.
.) Note the result of pg_buffercache view.
.) Work on your database to fill up the shared buffers.
.) Note the result of pg_buffercache view, again; there should be more blocks than last time we checked.
.) Stop and start the Postgres server.
.) Note the output of pg_buffercache view; it should contain the blocks seen just before the shutdown.
.) Future server restarts will automatically save and restore the blocks in shared-buffers.
The code is also available as Git repository at https://github.com/gurjeet/pg_hibernate/It uses the background worker infrastructure. It registers one worker process (BufferSaver) to save the shared-buffer metadata when server is shutting down, and one worker per database (BlockReader) when restoring the shared buffers.
It stores the buffer metadata under $PGDATA/pg_database/, one file per database, and one separate file for global objects. It sorts the list of buffers before storage, so that when it encounters a range of consecutive blocks of a relation's fork, it stores that range as just one entry, hence reducing the storage and I/O overhead.
On-disk binary format, which is used to create the per-database save-files, is defined as:
1. One or more relation filenodes; stored as r<relfilenode>.
2. Each realtion is followed by one or more fork number; stored as f<forknumber>
3. Each fork number is followed by one or more block numbers; stored as b<blocknumber>
4. Each block number is followed by zero or more range numbers; stored as N<number>
{r {f {b N* }+ }+ }+
Possible enhancements:
- Ability to save/restore only specific databases.
- Control how many BlockReaders are active at a time; to avoid I/O storms.
- Be smart about lowered shared_buffers across the restart.
- Different modes of reading like pg_prewarm does.
- Include PgFincore functionality, at least for Linux platforms.
The extension currently works with PG 9.3, and may work on 9.4 without any changes; I haven't tested, though. If not, I think it'd be easy to port to HEAD/PG 9.4. I see that 9.4 has put a cap on maximum background workers via a GUC, and since my aim is to provide a non-intrusive no-tuning-required extension, I'd like to use the new dynamic-background-worker infrastructure in 9.4, which doesn't seem to have any preset limits (I think it's limited by max_connections, but I may be wrong). I can work on 9.4 port, if there's interest in including this as a contrib/ module.
To see the extension in action:
.) Compile it.
.) Install it.
.) Add it to shared_preload_libraries.
.) Start/restart Postgres.
.) Install pg_buffercache extension, to inspect the shared buffers.
.) Note the result of pg_buffercache view.
.) Work on your database to fill up the shared buffers.
.) Note the result of pg_buffercache view, again; there should be more blocks than last time we checked.
.) Stop and start the Postgres server.
.) Note the output of pg_buffercache view; it should contain the blocks seen just before the shutdown.
.) Future server restarts will automatically save and restore the blocks in shared-buffers.
Demo:
$ make -C contrib/pg_hibernate/
$ make -C contrib/pg_hibernate/ install
$ vi $B/db/data/postgresql.conf
$ grep shared_preload_libraries $PGDATA/postgresql.conf
shared_preload_libraries = 'pg_hibernate' # (change requires restart)
$ pgstart
waiting for server to start.... done
server started
$ pgsql -c 'create extension pg_buffercache;'
CREATE EXTENSION
$ pgsql -c 'select count(*) from pg_buffercache where relblocknumber is not null group by reldatabase;'
count
-------
163
14
(2 rows)
$ pgsql -c 'create table test_hibernate as select s as a, s::char(1000) as b from generate_series(1, 100000) as s;'
SELECT 100000
$ pgsql -c 'create index on test_hibernate(a);'
CREATE INDEX
$ pgsql -c 'select count(*) from pg_buffercache where relblocknumber is not null group by reldatabase;'
count
-------
2254
14
(2 rows)
$ pgstop
waiting for server to shut down....... done
server stopped
$ pgstart
waiting for server to start.... done
server started
$ pgsql -c 'select count(*) from pg_buffercache where relblocknumber is not null group by reldatabase;'
count
-------
2264
17
(2 rows)
There are a few more blocks than the time they were saved, but all the blocks from before the restart are present in shared buffers after the restart.
Best regards,
--
Attachment
Please find attached the updated code of Postgres Hibenator. Notable
changes since the first proposal are:
.) The name has been changed to pg_hibernator (from pg_hibernate), to
avoid confusion with the ORM Hibernate.
.) Works with Postgres 9.4
.) Uses DynamicBackgroundWorker infrastructure.
.) Ability to restore one database at a time, to avoid random-read
storms. Can be disabled by parameter.
.) A couple of bug-fixes.
.) Detailed documentation.
I am pasting the README here (also included in the attachment).
Best regards,
Postgres Hibernator
===================
This Postgres extension is a set-it-and-forget-it solution to save and restore
the Postgres shared-buffers contents, across Postgres server restarts.
It performs the automatic save and restore of database buffers, integrated with
database shutdown and startup, hence reducing the durations of
database maintenance
windows, in effect increasing the uptime of your applications.
Postgres Hibernator automatically saves the list of shared buffers to the disk
on database shutdown, and automatically restores the buffers on
database startup.
This acts pretty much like your Operating System's hibernate feature, except,
instead of saving the contents of the memory to disk, Postgres Hibernator saves
just a list of block identifiers. And it uses that list after startup to restore
the blocks from data directory into Postgres' shared buffers.
Why
--------------
DBAs are often faced with the task of performing some maintenance on their
database server(s) which requires shutting down the database. The maintenance
may involve anything from a database patch application, to a hardware upgrade.
One ugly side-effect of restarting the database server/service is that all the
data currently in database server's memory will be all lost, which was
painstakingly fetched from disk and put there in response to application queries
over time. And this data will have to be rebuilt as applications start querying
database again. The query response times will be very high until all the "hot"
data is fetched from disk and put back in memory again.
People employ a few tricks to get around this ugly truth, which range from
running a `select * from app_table;`, to `dd if=table_file ...`, to using
specialized utilities like pgfincore to prefetch data files into OS cache.
Wouldn't it be ideal if the database itself could save and restore its memory
contents across restarts!
The duration for which the server is building up caches, and trying to reach its
optimal cache performance is called ramp-up time. Postgres Hibernator is aimed
at reducing the ramp-up time of Postgres servers.
How
--------------
Compile and install the extension (you'll need a Postgres instalation and its
`pg_config` in `$PATH`):
$ cd pg_hibernator
$ make install
Then.
1. Add `pg_hibernator` to the `shared_preload_libraries` variable in
`postgresql.conf` file.
2. Restart the Postgres server.
3. You are done.
How it works
--------------
This extension uses the `Background Worker` infrastructure of
Postgres, which was
introduced in Postgres 9.3. When the server starts, this extension registers
background workers; one for saving the buffers (called `Buffer Saver`) when the
server shuts down, and one for each database in the cluster (called
`Block Readers`)
for restoring the buffers saved during previous shutdown.
When the Postgres server is being stopped/shut down, the `Buffer
Saver` scans the
shared-buffers of Postgres, and stores the unique block identifiers of
each cached
block to the disk. This information is saved under the `$PGDATA/pg_hibernator/`
directory. For each of the database whose blocks are resident in shared buffers,
one file is created; for eg.: `$PGDATA/pg_hibernator/2.postgres.save`.
During the next startup sequence, the `Block Reader` threads are
registered, one for
each file present under `$PGDATA/pg_hibernator/` directory. When the
Postgres server
has reached stable state (that is, it's ready for database connections), these
`Block Reader` processes are launched. The `Block Reader` process
reads the save-files
looking for block-ids to restore. It then connects to the respective database,
and requests Postgres to fetch the blocks into shared-buffers.
Configuration
--------------
This extension can be controlled via the following parameters. These parameters
can be set in postgresql.conf or on postmaster's command-line.
- `pg_hibernator.enabled`
Setting this parameter to false disables the hibernator features. That is,
on server startup the BlockReader processes will not be launched, and on
server shutdown the list of blocks in shared buffers will not be saved.
Note that the BuffersSaver process exists at all times, even when this
parameter is set to `false`. This is to allow the DBA to enable/disable the
extension without having to restart the server. The BufferSaver process
checks this parameter during server startup and right before shutdown, and
honors this parameter's value at that time.
To enable/disable Postgres Hibernator at runtime, change the value in
`postgresql.conf` and use `pg_ctl reload` to make Postgres re-read the new
parameter values from `postgresql.conf`.
Default value: `true`.
- `pg_hibernator.parallel`
This parameter controls whether Postgres Hibernator launches the BlockReader
processes in parallel, or sequentially, waiting for current BlockReader to
exit before launching the next one.
When enabled, all the BlockReaders, one for each database, will be launched
simultaneously, and this may cause huge random-read flood on disks if there
are many databases in cluster. This may also cause some BlockReaders to fail
to launch successfully because of `max_worker_processes` limit.
Default value: `false`.
- `pg_hibernator.default_database`
The BufferSaver process needs to connect to a database in order to perform
the database-name lookups etc. This parameter controls which database the
BufferSaver process connects to for performing these operations.
Default value: `postgres`.
Caveats
--------------
- Buffer list is saved only when Postgres is shutdown in "smart" and
"fast" modes.
That is, buffer list is not saved when database crashes, or on "immediate"
shutdown.
- A reduction in `shared_buffers` is not detected.
If the `shared_buffers` is reduced across a restart, and if the combined
saved buffer list is larger than the new shared_buffers, Postgres
Hibernator continues to read and restore blocks even after `shared_buffers`
worth of buffers have been restored.
FAQ
--------------
- What is the relationship between `pg_buffercache`, `pg_prewarm`, and
`pg_hibernator`?
They all allow you to do different things with Postgres' shared buffers.
+ pg_buffercahce:
Inspect and show contents of shared buffers
+ pg_prewarm:
Load some table/index/fork blocks into shared buffers. User needs
to tell it which blocks to load.
+ pg_hibernator:
Upon shutdown, save list of blocks stored in shared buffers. Upon
startup, loads those blocks back into shared buffers.
The goal of Postgres Hibernator is to be invisible to the user/DBA.
Whereas with `pg_prewarm` the user needs to know a lot of stuff about
what they really want to do, most likely information gathered via
`pg_buffercahce`.
- Does `pg_hibernate` use either `pg_buffercache` or `pg_prewarm`?
No, Postgres Hibernator works all on its own.
If the concern is, "Do I have to install pg_buffercache and pg_prewarm
to use pg_hibernator", the answer is no. pg_hibernator is a stand-alone
extension, although influenced by pg_buffercache and pg_prewarm.
With `pg_prewarm` you can load blocks of **only** the database
you're connected
to. So if you have `N` databases in your cluster, to restore blocks of all
databases, the DBA will have to connect to each database and invoke
`pg_prewarm` functions.
With `pg_hibernator`, DBA isn't required to do anything, let alone
connecting to the database!
- Where can I learn more about it?
There are a couple of blog posts and initial proposal to Postgres
hackers' mailing list. They may provide a better understanding of
Postgres Hibernator.
[Proposal](http://www.postgresql.org/message-id/CABwTF4Ui_anAG+ybseFunAH5Z6DE9aw2NPdy4HryK+M5OdXCCA@mail.gmail.com)
[Introducing Postrges
Hibernator](http://gurjeet.singh.im/blog/2014/02/03/introducing-postgres-hibernator/)
[Demostrating Performance
Benefits](http://gurjeet.singh.im/blog/2014/04/30/postgres-hibernator-reduce-planned-database-down-times/)
On Mon, Feb 3, 2014 at 7:18 PM, Gurjeet Singh <gurjeet@singh.im> wrote:
> Please find attached the pg_hibernate extension. It is a
> set-it-and-forget-it solution to enable hibernation of Postgres
> shared-buffers. It can be thought of as an amalgam of pg_buffercache and
> pg_prewarm.
>
> It uses the background worker infrastructure. It registers one worker
> process (BufferSaver) to save the shared-buffer metadata when server is
> shutting down, and one worker per database (BlockReader) when restoring the
> shared buffers.
>
> It stores the buffer metadata under $PGDATA/pg_database/, one file per
> database, and one separate file for global objects. It sorts the list of
> buffers before storage, so that when it encounters a range of consecutive
> blocks of a relation's fork, it stores that range as just one entry, hence
> reducing the storage and I/O overhead.
>
> On-disk binary format, which is used to create the per-database save-files,
> is defined as:
> 1. One or more relation filenodes; stored as r<relfilenode>.
> 2. Each realtion is followed by one or more fork number; stored as
> f<forknumber>
> 3. Each fork number is followed by one or more block numbers; stored as
> b<blocknumber>
> 4. Each block number is followed by zero or more range numbers; stored as
> N<number>
>
> {r {f {b N* }+ }+ }+
>
> Possible enhancements:
> - Ability to save/restore only specific databases.
> - Control how many BlockReaders are active at a time; to avoid I/O storms.
> - Be smart about lowered shared_buffers across the restart.
> - Different modes of reading like pg_prewarm does.
> - Include PgFincore functionality, at least for Linux platforms.
>
> The extension currently works with PG 9.3, and may work on 9.4 without any
> changes; I haven't tested, though. If not, I think it'd be easy to port to
> HEAD/PG 9.4. I see that 9.4 has put a cap on maximum background workers via
> a GUC, and since my aim is to provide a non-intrusive no-tuning-required
> extension, I'd like to use the new dynamic-background-worker infrastructure
> in 9.4, which doesn't seem to have any preset limits (I think it's limited
> by max_connections, but I may be wrong). I can work on 9.4 port, if there's
> interest in including this as a contrib/ module.
>
> To see the extension in action:
>
> .) Compile it.
> .) Install it.
> .) Add it to shared_preload_libraries.
> .) Start/restart Postgres.
> .) Install pg_buffercache extension, to inspect the shared buffers.
> .) Note the result of pg_buffercache view.
> .) Work on your database to fill up the shared buffers.
> .) Note the result of pg_buffercache view, again; there should be more
> blocks than last time we checked.
> .) Stop and start the Postgres server.
> .) Note the output of pg_buffercache view; it should contain the blocks seen
> just before the shutdown.
> .) Future server restarts will automatically save and restore the blocks in
> shared-buffers.
>
> The code is also available as Git repository at
> https://github.com/gurjeet/pg_hibernate/
>
> Demo:
>
> $ make -C contrib/pg_hibernate/
> $ make -C contrib/pg_hibernate/ install
> $ vi $B/db/data/postgresql.conf
> $ grep shared_preload_libraries $PGDATA/postgresql.conf
> shared_preload_libraries = 'pg_hibernate' # (change requires restart)
>
> $ pgstart
> waiting for server to start.... done
> server started
>
> $ pgsql -c 'create extension pg_buffercache;'
> CREATE EXTENSION
>
> $ pgsql -c 'select count(*) from pg_buffercache where relblocknumber is not
> null group by reldatabase;'
> count
> -------
> 163
> 14
> (2 rows)
>
> $ pgsql -c 'create table test_hibernate as select s as a, s::char(1000) as b
> from generate_series(1, 100000) as s;'
> SELECT 100000
>
> $ pgsql -c 'create index on test_hibernate(a);'
> CREATE INDEX
>
> $ pgsql -c 'select count(*) from pg_buffercache where relblocknumber is not
> null group by reldatabase;'
> count
> -------
> 2254
> 14
> (2 rows)
>
> $ pgstop
> waiting for server to shut down....... done
> server stopped
>
> $ pgstart
> waiting for server to start.... done
> server started
>
> $ pgsql -c 'select count(*) from pg_buffercache where relblocknumber is not
> null group by reldatabase;'
> count
> -------
> 2264
> 17
> (2 rows)
>
> There are a few more blocks than the time they were saved, but all the
> blocks from before the restart are present in shared buffers after the
> restart.
>
> Best regards,
> --
> Gurjeet Singh http://gurjeet.singh.im/
>
> EDB www.EnterpriseDB.com
--
Gurjeet Singh http://gurjeet.singh.im/
EDB www.EnterpriseDB.com
Attachment
On Wed, May 28, 2014 at 7:31 AM, Gurjeet Singh <gurjeet@singh.im> wrote:
> Caveats
> --------------
>
> - Buffer list is saved only when Postgres is shutdown in "smart" and
> "fast" modes.
>
> That is, buffer list is not saved when database crashes, or on "immediate"
> shutdown.
>
> - A reduction in `shared_buffers` is not detected.
>
> If the `shared_buffers` is reduced across a restart, and if the combined
> saved buffer list is larger than the new shared_buffers, Postgres
> Hibernator continues to read and restore blocks even after `shared_buffers`
> worth of buffers have been restored.
How about the cases when shared buffers already contain some
I am not sure if replacing shared buffer contents in such cases can
> Caveats
> --------------
>
> - Buffer list is saved only when Postgres is shutdown in "smart" and
> "fast" modes.
>
> That is, buffer list is not saved when database crashes, or on "immediate"
> shutdown.
>
> - A reduction in `shared_buffers` is not detected.
>
> If the `shared_buffers` is reduced across a restart, and if the combined
> saved buffer list is larger than the new shared_buffers, Postgres
> Hibernator continues to read and restore blocks even after `shared_buffers`
> worth of buffers have been restored.
How about the cases when shared buffers already contain some
data:
a. Before Readers start filling shared buffers, if this cluster wishes
to join replication as a slave and receive the data from master, then
this utility might need to evict some buffers filled during startup
phase.
b. As soon as the server completes startup (reached consistent
point), it allows new connections which can also use some shared
buffers before Reader process could use shared buffers or are you
planing to change the time when users can connect to database.
I am not sure if replacing shared buffer contents in such cases can
always be considered useful.
On Wed, May 28, 2014 at 2:15 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Wed, May 28, 2014 at 7:31 AM, Gurjeet Singh <gurjeet@singh.im> wrote: > > Caveats >> -------------- >> >> - Buffer list is saved only when Postgres is shutdown in "smart" and >> "fast" modes. >> >> That is, buffer list is not saved when database crashes, or on >> "immediate" >> shutdown. >> >> - A reduction in `shared_buffers` is not detected. >> >> If the `shared_buffers` is reduced across a restart, and if the >> combined >> saved buffer list is larger than the new shared_buffers, Postgres >> Hibernator continues to read and restore blocks even after >> `shared_buffers` >> worth of buffers have been restored. > > How about the cases when shared buffers already contain some > data: > a. Before Readers start filling shared buffers, if this cluster wishes > to join replication as a slave and receive the data from master, then > this utility might need to evict some buffers filled during startup > phase. A cluster that wishes to be a replication standby, it would do so while it's in startup phase. The BlockReaders are launched immediately on cluster reaching consistent state, at which point, I presume, in most of the cases, most of the buffers would be unoccupied. Hence BlockReaders might evict the occupied buffers, which may be a small fraction of total shared_buffers. > b. As soon as the server completes startup (reached consistent > point), it allows new connections which can also use some shared > buffers before Reader process could use shared buffers or are you > planing to change the time when users can connect to database. The BlockReaders are launched immediately after the cluster reaches consistent state, that is, just about when it is ready to accept connections. So yes, there is a possibility that the I/O caused by the BlockReaders may affect the performance of queries executed right at cluster startup. But given that the performance of those queries was anyway going to be low (because of empty shared buffers), and that BlockReaders tend to cause sequential reads, and that by default there's only one BlockReader active at a time, I think this won't be a concern in most of the cases. By the time the shared buffers start getting filled up, the buffer replacement strategy will evict any buffers populated by BlockReaders if they are not used by the normal queries. In the 'Sample Runs' section of my blog [1], I compared the cases 'Hibernator w/ App' and 'Hibernator then App', which demonstrate that launching application load while the BlockReaders are active does cause performance of both to be impacted by each other. But overall it's a net win for application performance. > I am not sure if replacing shared buffer contents in such cases can > always be considered useful. IMHO, all of these caveats, would affect a very small fraction of use-cases and are eclipsed by the benefits this extension provides in normal cases. [1]: http://gurjeet.singh.im/blog/2014/04/30/postgres-hibernator-reduce-planned-database-down-times/ Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Wed, May 28, 2014 at 5:30 PM, Gurjeet Singh <gurjeet@singh.im> wrote:
> On Wed, May 28, 2014 at 2:15 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > How about the cases when shared buffers already contain some
> > data:
> > a. Before Readers start filling shared buffers, if this cluster wishes
> > to join replication as a slave and receive the data from master, then
> > this utility might need to evict some buffers filled during startup
> > phase.
>
> A cluster that wishes to be a replication standby, it would do so
> while it's in startup phase. The BlockReaders are launched immediately
> on cluster reaching consistent state, at which point, I presume, in
> most of the cases, most of the buffers would be unoccupied.
> On Wed, May 28, 2014 at 2:15 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > How about the cases when shared buffers already contain some
> > data:
> > a. Before Readers start filling shared buffers, if this cluster wishes
> > to join replication as a slave and receive the data from master, then
> > this utility might need to evict some buffers filled during startup
> > phase.
>
> A cluster that wishes to be a replication standby, it would do so
> while it's in startup phase. The BlockReaders are launched immediately
> on cluster reaching consistent state, at which point, I presume, in
> most of the cases, most of the buffers would be unoccupied.
Even to reach consistent state, it might need to get the records
from master (example to get to STANDBY_SNAPSHOT_READY state).
> Hence
> BlockReaders might evict the occupied buffers, which may be a small
> fraction of total shared_buffers.
Yes, but I think still it depends on how much redo replay happens
> BlockReaders might evict the occupied buffers, which may be a small
> fraction of total shared_buffers.
Yes, but I think still it depends on how much redo replay happens
on different pages.
> > b. As soon as the server completes startup (reached consistent
> > point), it allows new connections which can also use some shared
> > buffers before Reader process could use shared buffers or are you
> > planing to change the time when users can connect to database.
>
> The BlockReaders are launched immediately after the cluster reaches
> consistent state, that is, just about when it is ready to accept
> connections. So yes, there is a possibility that the I/O caused by the
> BlockReaders may affect the performance of queries executed right at
> cluster startup. But given that the performance of those queries was
> anyway going to be low (because of empty shared buffers), and that
> BlockReaders tend to cause sequential reads, and that by default
> there's only one BlockReader active at a time, I think this won't be a
> concern in most of the cases. By the time the shared buffers start
> getting filled up, the buffer replacement strategy will evict any
> buffers populated by BlockReaders if they are not used by the normal
> queries.
> > b. As soon as the server completes startup (reached consistent
> > point), it allows new connections which can also use some shared
> > buffers before Reader process could use shared buffers or are you
> > planing to change the time when users can connect to database.
>
> The BlockReaders are launched immediately after the cluster reaches
> consistent state, that is, just about when it is ready to accept
> connections. So yes, there is a possibility that the I/O caused by the
> BlockReaders may affect the performance of queries executed right at
> cluster startup. But given that the performance of those queries was
> anyway going to be low (because of empty shared buffers), and that
> BlockReaders tend to cause sequential reads, and that by default
> there's only one BlockReader active at a time, I think this won't be a
> concern in most of the cases. By the time the shared buffers start
> getting filled up, the buffer replacement strategy will evict any
> buffers populated by BlockReaders if they are not used by the normal
> queries.
Even Block Readers might need to evict buffers filled by user
queries or by itself in which case there is chance of contention, but
again all these are quite rare scenario's.
> > I am not sure if replacing shared buffer contents in such cases can
> > always be considered useful.
>
> IMHO, all of these caveats, would affect a very small fraction of
> use-cases and are eclipsed by the benefits this extension provides in
> normal cases.
> > I am not sure if replacing shared buffer contents in such cases can
> > always be considered useful.
>
> IMHO, all of these caveats, would affect a very small fraction of
> use-cases and are eclipsed by the benefits this extension provides in
> normal cases.
I agree with you that there are only few corner cases where evicting
shared buffers by this utility would harm, but was wondering if we could
even save those, say if it would only use available free buffers. I think
currently there is no such interface and inventing a new interface for this
case doesn't seem to reasonable unless we see any other use case of
such a interface.
<p dir="ltr"><br /> On May 29, 2014 12:12 AM, "Amit Kapila" <<a href="mailto:amit.kapila16@gmail.com">amit.kapila16@gmail.com</a>>wrote:<br /> ><br /> > I agree with you that thereare only few corner cases where evicting<br /> > shared buffers by this utility would harm, but was wondering ifwe could<br /> > even save those, say if it would only use available free buffers. I think<br /> > currently thereis no such interface and inventing a new interface for this<br /> > case doesn't seem to reasonable unlesswe see any other use case of<br /> > such a interface.<p dir="ltr">+1
On Tue, May 27, 2014 at 10:01 PM, Gurjeet Singh <gurjeet@singh.im> wrote: > When the Postgres server is being stopped/shut down, the `Buffer > Saver` scans the > shared-buffers of Postgres, and stores the unique block identifiers of > each cached > block to the disk. This information is saved under the `$PGDATA/pg_hibernator/` > directory. For each of the database whose blocks are resident in shared buffers, > one file is created; for eg.: `$PGDATA/pg_hibernator/2.postgres.save`. This file-naming convention seems a bit fragile. For example, on my filesystem (HFS) if I create a database named "foo / bar", I'll get a complaint like: ERROR: could not open "pg_hibernator/5.foo / bar.save": No such file or directory during shutdown. Josh
On Fri, May 30, 2014 at 5:33 PM, Josh Kupershmidt <schmiddy@gmail.com> wrote: > On Tue, May 27, 2014 at 10:01 PM, Gurjeet Singh <gurjeet@singh.im> wrote: > >> When the Postgres server is being stopped/shut down, the `Buffer >> Saver` scans the >> shared-buffers of Postgres, and stores the unique block identifiers of >> each cached >> block to the disk. This information is saved under the `$PGDATA/pg_hibernator/` >> directory. For each of the database whose blocks are resident in shared buffers, >> one file is created; for eg.: `$PGDATA/pg_hibernator/2.postgres.save`. > > This file-naming convention seems a bit fragile. For example, on my > filesystem (HFS) if I create a database named "foo / bar", I'll get a > complaint like: > > ERROR: could not open "pg_hibernator/5.foo / bar.save": No such file > or directory > > during shutdown. Thanks for the report. I have reworked the file naming, and now the save-file name is simply '<integer>.save', so the name of a database does not affect the file name on disk. Instead, the null-terminated database name is now written in the file, and read back for use when restoring the buffers. Attached is the new version of pg_hibernator, with updated code and README. Just a heads up for anyone who might have read/reviewed previous version's code, there's some unrelated trivial code and Makefile changes as well in this version, which can be easily spotted by a `diff -r`. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
Attachment
On Thu, May 29, 2014 at 12:12 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >> IMHO, all of these caveats, would affect a very small fraction of >> use-cases and are eclipsed by the benefits this extension provides in >> normal cases. > > I agree with you that there are only few corner cases where evicting > shared buffers by this utility would harm, but was wondering if we could > even save those, say if it would only use available free buffers. I think > currently there is no such interface and inventing a new interface for this > case doesn't seem to reasonable unless we see any other use case of > such a interface. It seems like it would be best to try to do this at cluster startup time, rather than once recovery has reached consistency. Of course, that might mean doing it with a single process, which could have its own share of problems. But I'm somewhat inclined to think that if recovery has already run for a significant period of time, the blocks that recovery has brought into shared_buffers are more likely to be useful than whatever pg_hibernate would load. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jun 3, 2014 at 7:57 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Thu, May 29, 2014 at 12:12 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>> IMHO, all of these caveats, would affect a very small fraction of >>> use-cases and are eclipsed by the benefits this extension provides in >>> normal cases. >> >> I agree with you that there are only few corner cases where evicting >> shared buffers by this utility would harm, but was wondering if we could >> even save those, say if it would only use available free buffers. I think >> currently there is no such interface and inventing a new interface for this >> case doesn't seem to reasonable unless we see any other use case of >> such a interface. > > It seems like it would be best to try to do this at cluster startup > time, rather than once recovery has reached consistency. Of course, > that might mean doing it with a single process, which could have its > own share of problems. But I'm somewhat inclined to think that if > recovery has already run for a significant period of time, the blocks > that recovery has brought into shared_buffers are more likely to be > useful than whatever pg_hibernate would load. I am not absolutely sure of the order of execution between recovery process and the BGWorker, but ... For sizeable shared_buffers size, the restoration of the shared buffers can take several seconds. I have a feeling the users wouldn't like their master database take up to a few minutes to start accepting connections. From my tests [1], " In the 'App after Hibernator' [case] ... This took 70 seconds for reading the ~4 GB database." [1]: http://gurjeet.singh.im/blog/2014/04/30/postgres-hibernator-reduce-planned-database-down-times/ Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Tue, Jun 3, 2014 at 8:13 AM, Gurjeet Singh <gurjeet@singh.im> wrote: > On Tue, Jun 3, 2014 at 7:57 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Thu, May 29, 2014 at 12:12 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: >>>> IMHO, all of these caveats, would affect a very small fraction of >>>> use-cases and are eclipsed by the benefits this extension provides in >>>> normal cases. >>> >>> I agree with you that there are only few corner cases where evicting >>> shared buffers by this utility would harm, but was wondering if we could >>> even save those, say if it would only use available free buffers. I think >>> currently there is no such interface and inventing a new interface for this >>> case doesn't seem to reasonable unless we see any other use case of >>> such a interface. >> >> It seems like it would be best to try to do this at cluster startup >> time, rather than once recovery has reached consistency. Of course, >> that might mean doing it with a single process, which could have its >> own share of problems. But I'm somewhat inclined to think that if Currently pg_hibernator uses ReadBufferExtended() API, and AIUI, that API requires a database connection//shared-memory attachment, and that a backend process cannot switch between databases after the initial connection. >> own share of problems. But I'm somewhat inclined to think that if >> recovery has already run for a significant period of time, the blocks >> that recovery has brought into shared_buffers are more likely to be >> useful than whatever pg_hibernate would load. The applications that connect to a standby may have a different access pattern than the applications that are operating on the master database. So the buffers that are being restored by startup process may not be relevant to the workload on the standby. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Tue, Jun 3, 2014 at 5:43 PM, Gurjeet Singh <gurjeet@singh.im> wrote:
> On Tue, Jun 3, 2014 at 7:57 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> > It seems like it would be best to try to do this at cluster startup
> > time, rather than once recovery has reached consistency. Of course,
> > that might mean doing it with a single process, which could have its
> > own share of problems. But I'm somewhat inclined to think that if
> > recovery has already run for a significant period of time, the blocks
> > that recovery has brought into shared_buffers are more likely to be
> > useful than whatever pg_hibernate would load.
>
> I am not absolutely sure of the order of execution between recovery
> process and the BGWorker, but ...
>
> For sizeable shared_buffers size, the restoration of the shared
> buffers can take several seconds.
> On Tue, Jun 3, 2014 at 7:57 AM, Robert Haas <robertmhaas@gmail.com> wrote:
> > It seems like it would be best to try to do this at cluster startup
> > time, rather than once recovery has reached consistency. Of course,
> > that might mean doing it with a single process, which could have its
> > own share of problems. But I'm somewhat inclined to think that if
> > recovery has already run for a significant period of time, the blocks
> > that recovery has brought into shared_buffers are more likely to be
> > useful than whatever pg_hibernate would load.
>
> I am not absolutely sure of the order of execution between recovery
> process and the BGWorker, but ...
>
> For sizeable shared_buffers size, the restoration of the shared
> buffers can take several seconds.
Incase of recovery, the shared buffers saved by this utility are
from previous shutdown which doesn't seem to be of more use
than buffers loaded by recovery.
> I have a feeling the users wouldn't
> like their master database take up to a few minutes to start accepting
> connections.
I think this is fair point and to address this we can have an option to
> like their master database take up to a few minutes to start accepting
> connections.
I think this is fair point and to address this we can have an option to
decide when to load buffer's and have default value as load before
recovery.
> Currently pg_hibernator uses ReadBufferExtended() API, and AIUI, that
> API requires a database connection//shared-memory attachment, and that
> a backend process cannot switch between databases after the initial
> connection.
> API requires a database connection//shared-memory attachment, and that
> a backend process cannot switch between databases after the initial
> connection.
If recovery can load the buffer's to apply WAL, why can't it be done with
pg_hibernator. Can't we use ReadBufferWithoutRelcache() to achieve
the purpose of pg_hibernator?
One other point:
> Note that the BuffersSaver process exists at all times, even when this
> parameter is set to `false`. This is to allow the DBA to enable/disable the
> extension without having to restart the server. The BufferSaver process
> checks this parameter during server startup and right before shutdown, and
> honors this parameter's value at that time.
> parameter is set to `false`. This is to allow the DBA to enable/disable the
> extension without having to restart the server. The BufferSaver process
> checks this parameter during server startup and right before shutdown, and
> honors this parameter's value at that time.
Why can't it be done when user register's the extension by using dynamic
background facility "RegisterDynamicBackgroundWorker"?
On 2014-06-04 10:24:13 +0530, Amit Kapila wrote: > On Tue, Jun 3, 2014 at 5:43 PM, Gurjeet Singh <gurjeet@singh.im> wrote: > > On Tue, Jun 3, 2014 at 7:57 AM, Robert Haas <robertmhaas@gmail.com> wrote: > > > It seems like it would be best to try to do this at cluster startup > > > time, rather than once recovery has reached consistency. Of course, > > > that might mean doing it with a single process, which could have its > > > own share of problems. But I'm somewhat inclined to think that if > > > recovery has already run for a significant period of time, the blocks > > > that recovery has brought into shared_buffers are more likely to be > > > useful than whatever pg_hibernate would load. > > > > I am not absolutely sure of the order of execution between recovery > > process and the BGWorker, but ... > > > > For sizeable shared_buffers size, the restoration of the shared > > buffers can take several seconds. > > Incase of recovery, the shared buffers saved by this utility are > from previous shutdown which doesn't seem to be of more use > than buffers loaded by recovery. Why? The server might have been queried if it's a hot standby one? Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Jun 4, 2014 at 2:08 AM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-06-04 10:24:13 +0530, Amit Kapila wrote: >> On Tue, Jun 3, 2014 at 5:43 PM, Gurjeet Singh <gurjeet@singh.im> wrote: >> > On Tue, Jun 3, 2014 at 7:57 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> > > It seems like it would be best to try to do this at cluster startup >> > > time, rather than once recovery has reached consistency. Of course, >> > > that might mean doing it with a single process, which could have its >> > > own share of problems. But I'm somewhat inclined to think that if >> > > recovery has already run for a significant period of time, the blocks >> > > that recovery has brought into shared_buffers are more likely to be >> > > useful than whatever pg_hibernate would load. >> > >> > I am not absolutely sure of the order of execution between recovery >> > process and the BGWorker, but ... >> > >> > For sizeable shared_buffers size, the restoration of the shared >> > buffers can take several seconds. >> >> Incase of recovery, the shared buffers saved by this utility are >> from previous shutdown which doesn't seem to be of more use >> than buffers loaded by recovery. > > Why? The server might have been queried if it's a hot standby one? I think that's essentially the same point Amit is making. Gurjeet is arguing for reloading the buffers from the previous shutdown at end of recovery; IIUC, Amit, you, and I all think this isn't a good idea. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-06-04 09:51:36 -0400, Robert Haas wrote: > On Wed, Jun 4, 2014 at 2:08 AM, Andres Freund <andres@2ndquadrant.com> wrote: > > On 2014-06-04 10:24:13 +0530, Amit Kapila wrote: > >> Incase of recovery, the shared buffers saved by this utility are > >> from previous shutdown which doesn't seem to be of more use > >> than buffers loaded by recovery. > > > > Why? The server might have been queried if it's a hot standby one? > > I think that's essentially the same point Amit is making. Gurjeet is > arguing for reloading the buffers from the previous shutdown at end of > recovery; IIUC, Amit, you, and I all think this isn't a good idea. I think I am actually arguing for Gurjeet's position. If the server is actively being queried (i.e. hot_standby=on and actually used for queries) it's quite reasonable to expect that shared_buffers has lots of content that is *not* determined by WAL replay. There's not that much read IO going on during WAL replay anyway - after a crash/start from a restartpoint most of it is loaded via full page anyway. So it's only disadvantageous to fault in pages via pg_hibernate if that causes pages that already have been read in via FPIs to be thrown out. Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Jun 4, 2014 at 7:26 PM, Andres Freund <andres@2ndquadrant.com> wrote:
> On 2014-06-04 09:51:36 -0400, Robert Haas wrote:
> > On Wed, Jun 4, 2014 at 2:08 AM, Andres Freund <andres@2ndquadrant.com> wrote:
> > > On 2014-06-04 10:24:13 +0530, Amit Kapila wrote:
> > >> Incase of recovery, the shared buffers saved by this utility are
> > >> from previous shutdown which doesn't seem to be of more use
> > >> than buffers loaded by recovery.
> > >
> > > Why? The server might have been queried if it's a hot standby one?
Consider the case, crash (force kill or some other way) occurs when
> On 2014-06-04 09:51:36 -0400, Robert Haas wrote:
> > On Wed, Jun 4, 2014 at 2:08 AM, Andres Freund <andres@2ndquadrant.com> wrote:
> > > On 2014-06-04 10:24:13 +0530, Amit Kapila wrote:
> > >> Incase of recovery, the shared buffers saved by this utility are
> > >> from previous shutdown which doesn't seem to be of more use
> > >> than buffers loaded by recovery.
> > >
> > > Why? The server might have been queried if it's a hot standby one?
Consider the case, crash (force kill or some other way) occurs when
BGSaver is saving the buffers, now I think it is possible that it has
saved partial information (information about some buffers is correct
and others is missing) and it is also possible by that time checkpoint
record is not written (which means recovery will start from previous
restart point). So whats going to happen is that pg_hibernate might
load some less used buffers/blocks (which have lower usage count)
and WAL replayed blocks will be sacrificed. So the WAL data from
previous restart point and some more due to delay in start of
standby (changes occured in master during that time) will be
sacrificed.
Another case is of standalone server in which case there is always
high chance that blocks recovered by recovery are the active one's.
Now I agree that case of standalone servers is less, but still some
small applications might be using it. Also I think same is true if
the crashed server is master.
> > I think that's essentially the same point Amit is making. Gurjeet is
> > arguing for reloading the buffers from the previous shutdown at end of
> > recovery; IIUC, Amit, you, and I all think this isn't a good idea.
>
> I think I am actually arguing for Gurjeet's position. If the server is
> actively being queried (i.e. hot_standby=on and actually used for
> queries) it's quite reasonable to expect that shared_buffers has lots of
> content that is *not* determined by WAL replay.
Yes, that's quite possible, however there can be situations where it
> > arguing for reloading the buffers from the previous shutdown at end of
> > recovery; IIUC, Amit, you, and I all think this isn't a good idea.
>
> I think I am actually arguing for Gurjeet's position. If the server is
> actively being queried (i.e. hot_standby=on and actually used for
> queries) it's quite reasonable to expect that shared_buffers has lots of
> content that is *not* determined by WAL replay.
Yes, that's quite possible, however there can be situations where it
is not true as explained above.
> There's not that much read IO going on during WAL replay anyway - after
> a crash/start from a restartpoint most of it is loaded via full page
> anyway.
> There's not that much read IO going on during WAL replay anyway - after
> a crash/start from a restartpoint most of it is loaded via full page
> anyway.
> So it's only disadvantageous to fault in pages via pg_hibernate
> if that causes pages that already have been read in via FPIs to be
> thrown out.
So for such cases, pages loaded by pg_hibernate turn out to be loss.
> if that causes pages that already have been read in via FPIs to be
> thrown out.
So for such cases, pages loaded by pg_hibernate turn out to be loss.
Overall I think there can be both kind of cases when it is beneficial
to load buffers after recovery and before recovery, thats why I
mentioned above that either it can be a parameter from user to
decide the same or may be we can have a new API which will
load buffers by BGworker without evicting any existing buffer
(use buffers from free list only).
On Wed, Jun 4, 2014 at 9:56 AM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-06-04 09:51:36 -0400, Robert Haas wrote: >> On Wed, Jun 4, 2014 at 2:08 AM, Andres Freund <andres@2ndquadrant.com> wrote: >> > On 2014-06-04 10:24:13 +0530, Amit Kapila wrote: >> >> Incase of recovery, the shared buffers saved by this utility are >> >> from previous shutdown which doesn't seem to be of more use >> >> than buffers loaded by recovery. >> > >> > Why? The server might have been queried if it's a hot standby one? >> >> I think that's essentially the same point Amit is making. Gurjeet is >> arguing for reloading the buffers from the previous shutdown at end of >> recovery; IIUC, Amit, you, and I all think this isn't a good idea. > > I think I am actually arguing for Gurjeet's position. If the server is > actively being queried (i.e. hot_standby=on and actually used for > queries) it's quite reasonable to expect that shared_buffers has lots of > content that is *not* determined by WAL replay. > > There's not that much read IO going on during WAL replay anyway - after > a crash/start from a restartpoint most of it is loaded via full page > anyway. So it's only disadvantageous to fault in pages via pg_hibernate > if that causes pages that already have been read in via FPIs to be > thrown out. The thing I was concerned about is that the system might have been in recovery for months. What was hot at the time the base backup was taken seems like a poor guide to what will be hot at the time of promotion. Consider a history table, for example: the pages at the end, which have just been written, are much more likely to be useful than anything earlier. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2014-06-04 14:50:39 -0400, Robert Haas wrote: > The thing I was concerned about is that the system might have been in > recovery for months. What was hot at the time the base backup was > taken seems like a poor guide to what will be hot at the time of > promotion. Consider a history table, for example: the pages at the > end, which have just been written, are much more likely to be useful > than anything earlier. I'd assumed that the hibernation files would simply be excluded from the basebackup... Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On Wed, Jun 4, 2014 at 12:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Tue, Jun 3, 2014 at 5:43 PM, Gurjeet Singh <gurjeet@singh.im> wrote: >> >> For sizeable shared_buffers size, the restoration of the shared >> buffers can take several seconds. > > Incase of recovery, the shared buffers saved by this utility are > from previous shutdown which doesn't seem to be of more use > than buffers loaded by recovery. I feel the need to enumerate the recovery scenarios we're talking about so that we're all on the same page. 1) Hot backup (cp/rsync/pg_basebackup/.. while the master was running) followed by 1a) recovery using archives or streaming replication. 1a.i) database in hot-standby mode 1a.ii) databasenot in hot-standby mode, i.e. it's in warm-standby mode. 1b) minimal recovery, that is, recover only the WAL availablein pg_xlog, then come online. 2) Cold backup of a crashed master, followed by startup of the copy (causing crash recovery; IMHO same as case 1b above.). 3) Cold backup of clean-shutdown master, followed by startup of the copy (no recovery). In cases 1.x there won't be any save-files (*), because the BlockReader processes remove their respective save-file when they are done restoring the buffers, So the hot/warm-standby created thus will not inherit the save-files, and hence post-recovery will not cause any buffer restores. Case 2 also won't cause any buffer restores because the save-files are created only on clean shutdowons; not on a crash or immediate shutdown. Case 3, is the sweet spot of pg_hibernator. It will save buffer-list on shutdown, and restore them when the backup-copy is started (provided pg_hibernator is installed there). (*) If a hot-backup is taken immediately after database comes online, since BlockReaders may still be running and not have deleted the save-files, the save-files may end up in backup, and hence cause the recovery-time conflicts we're talking about. This should be rare in practice, and even when it does happen, at worst it will affect the initial performance of the cluster. >> I have a feeling the users wouldn't >> like their master database take up to a few minutes to start accepting >> connections. > > I think this is fair point and to address this we can have an option to > decide when to load buffer's and have default value as load before > recovery. Given the above description, I don't think crash/archive recovery is a concern anymore. But if that corner case is still a concern, I wouldn't favour making recovery slow by default, and make users of pg_hibernator pay for choosing to use the extension. I'd prefer the user explicitly ask for a behaviour that makes startups slow. > One other point: >> Note that the BuffersSaver process exists at all times, even when this >> parameter is set to `false`. This is to allow the DBA to enable/disable >> the >> extension without having to restart the server. The BufferSaver process >> checks this parameter during server startup and right before shutdown, and >> honors this parameter's value at that time. > > Why can't it be done when user register's the extension by using dynamic > background facility "RegisterDynamicBackgroundWorker"? There's no user interface to this extension except for the 3 GUC parameters; not even CREATE EXTENSION. The DBA is expected to append this extension's name in shared_preload_libraries. Since this extension declares one of its parameters PGC_POSTMASTER, it can't be loaded via the SQL 'LOAD ' command. postgres=# load 'pg_hibernator'; FATAL: cannot create PGC_POSTMASTER variables after startup FATAL: cannot create PGC_POSTMASTER variables after startup The connection to the server was lost. Attempting reset: Succeeded. Best regards, PS: I was out sick yesterday, so couldn't respond promptly. -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Wed, Jun 4, 2014 at 2:52 PM, Andres Freund <andres@2ndquadrant.com> wrote: > On 2014-06-04 14:50:39 -0400, Robert Haas wrote: >> The thing I was concerned about is that the system might have been in >> recovery for months. What was hot at the time the base backup was >> taken seems like a poor guide to what will be hot at the time of >> promotion. Consider a history table, for example: the pages at the >> end, which have just been written, are much more likely to be useful >> than anything earlier. > > I'd assumed that the hibernation files would simply be excluded from the > basebackup... Yes, they will be excluded, provided the BlockReader processes have finished, because each BlockReader unlinks its save-file after it is done restoring buffers listed in it. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Wed, Jun 4, 2014 at 2:50 PM, Robert Haas <robertmhaas@gmail.com> wrote: > The thing I was concerned about is that the system might have been in > recovery for months. What was hot at the time the base backup was > taken seems like a poor guide to what will be hot at the time of > promotion. Consider a history table, for example: the pages at the > end, which have just been written, are much more likely to be useful > than anything earlier. I think you are specifically talking about a warm-standby that runs recovery for months before being brought online. As described in my response to Amit, if the base backup used to create that standby was taken after the BlockReaders had restored the buffers (which should complete within few minutes of startup, even for large databases), then there's no concern since the base backup wouldn't contain the save-files. If it's a hot-standby, the restore process would start as soon as the database starts accepting connections, finish soon after, and get completely out of the way of the normal recovery process. At which point the buffers populated by the recovery would compete only with the buffers being requested by backends, which is the normal behaviour. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Thu, Jun 5, 2014 at 5:39 PM, Gurjeet Singh <gurjeet@singh.im> wrote:
>
> On Wed, Jun 4, 2014 at 12:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Tue, Jun 3, 2014 at 5:43 PM, Gurjeet Singh <gurjeet@singh.im> wrote:
> >>
> >> For sizeable shared_buffers size, the restoration of the shared
> >> buffers can take several seconds.
> >
> > Incase of recovery, the shared buffers saved by this utility are
> > from previous shutdown which doesn't seem to be of more use
> > than buffers loaded by recovery.
>
> I feel the need to enumerate the recovery scenarios we're talking
> about so that we're all on the same page.
>
> 1) Hot backup (cp/rsync/pg_basebackup/.. while the master was running)
> followed by
> 1a) recovery using archives or streaming replication.
> 1a.i) database in hot-standby mode
> 1a.ii) database not in hot-standby mode, i.e. it's in warm-standby mode.
> 1b) minimal recovery, that is, recover only the WAL available in
> pg_xlog, then come online.
>
> 2) Cold backup of a crashed master, followed by startup of the copy
> (causing crash recovery; IMHO same as case 1b above.).
>
> 3) Cold backup of clean-shutdown master, followed by startup of the
> copy (no recovery).
>
> In cases 1.x there won't be any save-files (*), because the
> BlockReader processes remove their respective save-file when they are
> done restoring the buffers, So the hot/warm-standby created thus will
> not inherit the save-files, and hence post-recovery will not cause any
> buffer restores.
>
> Case 2 also won't cause any buffer restores because the save-files are
> created only on clean shutdowons; not on a crash or immediate
> shutdown.
>
> On Wed, Jun 4, 2014 at 12:54 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > On Tue, Jun 3, 2014 at 5:43 PM, Gurjeet Singh <gurjeet@singh.im> wrote:
> >>
> >> For sizeable shared_buffers size, the restoration of the shared
> >> buffers can take several seconds.
> >
> > Incase of recovery, the shared buffers saved by this utility are
> > from previous shutdown which doesn't seem to be of more use
> > than buffers loaded by recovery.
>
> I feel the need to enumerate the recovery scenarios we're talking
> about so that we're all on the same page.
>
> 1) Hot backup (cp/rsync/pg_basebackup/.. while the master was running)
> followed by
> 1a) recovery using archives or streaming replication.
> 1a.i) database in hot-standby mode
> 1a.ii) database not in hot-standby mode, i.e. it's in warm-standby mode.
> 1b) minimal recovery, that is, recover only the WAL available in
> pg_xlog, then come online.
>
> 2) Cold backup of a crashed master, followed by startup of the copy
> (causing crash recovery; IMHO same as case 1b above.).
>
> 3) Cold backup of clean-shutdown master, followed by startup of the
> copy (no recovery).
>
> In cases 1.x there won't be any save-files (*), because the
> BlockReader processes remove their respective save-file when they are
> done restoring the buffers, So the hot/warm-standby created thus will
> not inherit the save-files, and hence post-recovery will not cause any
> buffer restores.
>
> Case 2 also won't cause any buffer restores because the save-files are
> created only on clean shutdowons; not on a crash or immediate
> shutdown.
How do you ensure that buffers are saved only on clean shutdown?
Buffer saver process itself can crash while saving or restoring
buffers.
IIUC on shutdown request, postmaster will send signal to BG Saver
and BG Saver will save the buffers and then postmaster will send
signal to checkpointer to shutdown. So before writing Checkpoint
record, BG Saver can crash (it might have saved half the buffers)
or may BG saver saves buffers, but checkpointer crashes (due to
power outage or any such thing).
Another thing is don't you want to handle SIGQUIT signal in bg saver?
On Thu, Jun 5, 2014 at 11:32 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > Another thing is don't you want to handle SIGQUIT signal in bg saver? I think bgworker_quickdie registered in StartBackgroundWorker() serves the purpose just fine. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Thu, Jun 5, 2014 at 11:32 PM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Jun 5, 2014 at 5:39 PM, Gurjeet Singh <gurjeet@singh.im> wrote: >> >> > On Tue, Jun 3, 2014 at 5:43 PM, Gurjeet Singh <gurjeet@singh.im> wrote: >> Case 2 also won't cause any buffer restores because the save-files are >> created only on clean shutdowons; not on a crash or immediate >> shutdown. > > How do you ensure that buffers are saved only on clean shutdown? Postmaster sends SIGTERM only in "smart" or "fast" shutdown requests. > Buffer saver process itself can crash while saving or restoring > buffers. True. That may lead to partial list of buffers being saved. And the code in Reader process tries hard to read only valid data, and punts at the first sight of data that doesn't make sense or on ERROR raised from Postgres API call. > IIUC on shutdown request, postmaster will send signal to BG Saver > and BG Saver will save the buffers and then postmaster will send > signal to checkpointer to shutdown. So before writing Checkpoint > record, BG Saver can crash (it might have saved half the buffers) Case handled as described above. > or may BG saver saves buffers, but checkpointer crashes (due to > power outage or any such thing). Checkpointer process' crash seems to be irrelevant to Postgres Hibernator's workings. I think you are trying to argue the wording in my claim "save-files are created only on clean shutdowons; not on a crash or immediate shutdown", by implying that a crash may occur at any time during and after the BufferSaver processing. I agree the wording can be improved. How about ... save-files are created only when Postgres is requested to shutdown in normal (smart or fast) modes. Note that I am leaving out the mention of crash. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On 6/4/14, 8:56 AM, Andres Freund wrote: > On 2014-06-04 09:51:36 -0400, Robert Haas wrote: >> >On Wed, Jun 4, 2014 at 2:08 AM, Andres Freund<andres@2ndquadrant.com> wrote: >>> > >On 2014-06-04 10:24:13 +0530, Amit Kapila wrote: >>>> > >>Incase of recovery, the shared buffers saved by this utility are >>>> > >>from previous shutdown which doesn't seem to be of more use >>>> > >>than buffers loaded by recovery. >>> > > >>> > >Why? The server might have been queried if it's a hot standby one? >> > >> >I think that's essentially the same point Amit is making. Gurjeet is >> >arguing for reloading the buffers from the previous shutdown at end of >> >recovery; IIUC, Amit, you, and I all think this isn't a good idea. > I think I am actually arguing for Gurjeet's position. If the server is > actively being queried (i.e. hot_standby=on and actually used for > queries) it's quite reasonable to expect that shared_buffers has lots of > content that is*not* determined by WAL replay. Perhaps instead of trying to get data actually into shared buffers it would be better to just advise the kernel that we thinkwe're going to need it? ISTM it's reasonably fast to pull data from disk cache into shared buffers. On a related note, what I really wish for is the ability to restore the disk cash after a restart/unmount... -- Jim C. Nasby, Data Architect jim@nasby.net 512.569.9461 (cell) http://jim.nasby.net
<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; -qt-user-state:0;">Lelundi 3 février 2014 19:18:54 Gurjeet Singh a écrit :<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px;margin-right:0px; -qt-block-indent:0; text-indent:0px; -qt-user-state:0;">> Possible enhancements:<p style="margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; -qt-user-state:0;">>- Ability to save/restore only specific databases.<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px;margin-right:0px; -qt-block-indent:0; text-indent:0px; -qt-user-state:0;">> - Control how many BlockReadersare active at a time; to avoid I/O<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px;-qt-block-indent:0; text-indent:0px; -qt-user-state:0;">> storms. - Be smart about lowered shared_buffersacross the restart.<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0;text-indent:0px; -qt-user-state:0;">> - Different modes of reading like pg_prewarm does.<p style="margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; -qt-user-state:0;">>- Include PgFincore functionality, at least for Linux platforms.<p style="-qt-paragraph-type:empty;margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0;text-indent:0px; "> <p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0;text-indent:0px; -qt-user-state:0;">Please note that pgfincore is working on any system where PostgreSQLprefetch is working, exactly like pg_prewarm. This includes linux, BSD and many unix-like. It *is not* limitedto linux.<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;-qt-user-state:0;">I never had a single request for windows, but windows does provides an API for that too(however I have no windows offhand to test).<p style="-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px;margin-right:0px; -qt-block-indent:0; text-indent:0px; "> <p style=" margin-top:0px; margin-bottom:0px; margin-left:0px;margin-right:0px; -qt-block-indent:0; text-indent:0px; -qt-user-state:0;">Another side note is that currentlyBSD (at least freeBSD) have a more advanced mincore() syscall than linux and offers a better analysis (dirty statusis known) and they implemented posix_fadvise...<p style="-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px;margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; "> <p style=" margin-top:0px; margin-bottom:0px;margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; -qt-user-state:0;">PS:<p style="margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px; -qt-user-state:0;">Thereis a previous thread about that hibernation feature. Mitsuru IWASAKI did a patch, and it triggerssome interesting discussions.<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0;text-indent:0px; -qt-user-state:0;">Some notes in this thread are outdated now, but it's worth havinga look at it:<p style="-qt-paragraph-type:empty; margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px;-qt-block-indent:0; text-indent:0px; "> <p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px;-qt-block-indent:0; text-indent:0px; -qt-user-state:0;">http://www.postgresql.org/message-id/20110504.231048.113741617.iwasaki@jp.FreeBSD.org<p style="-qt-paragraph-type:empty;margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0;text-indent:0px; "> <p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0;text-indent:0px; -qt-user-state:0;">https://commitfest.postgresql.org/action/patch_view?id=549<p style="-qt-paragraph-type:empty;margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0;text-indent:0px; "> <p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0;text-indent:0px; -qt-user-state:0;">-- <p style=" margin-top:0px; margin-bottom:0px; margin-left:0px;margin-right:0px; -qt-block-indent:0; text-indent:0px; -qt-user-state:0;">Cédric Villemain +33 (0)6 20 3022 52<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px; -qt-block-indent:0; text-indent:0px;-qt-user-state:0;">http://2ndQuadrant.fr/<p style=" margin-top:0px; margin-bottom:0px; margin-left:0px; margin-right:0px;-qt-block-indent:0; text-indent:0px; -qt-user-state:0;">PostgreSQL: Support 24x7 - Développement, Expertiseet Formation
On Fri, Jun 6, 2014 at 5:31 PM, Gurjeet Singh <gurjeet@singh.im> wrote:
> On Thu, Jun 5, 2014 at 11:32 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Buffer saver process itself can crash while saving or restoring
> > buffers.
>
> True. That may lead to partial list of buffers being saved. And the
> code in Reader process tries hard to read only valid data, and punts
> at the first sight of data that doesn't make sense or on ERROR raised
> from Postgres API call.
Inspite of Reader Process trying hard, I think we should ensure by
> On Thu, Jun 5, 2014 at 11:32 PM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> > Buffer saver process itself can crash while saving or restoring
> > buffers.
>
> True. That may lead to partial list of buffers being saved. And the
> code in Reader process tries hard to read only valid data, and punts
> at the first sight of data that doesn't make sense or on ERROR raised
> from Postgres API call.
Inspite of Reader Process trying hard, I think we should ensure by
some other means that file saved by buffer saver is valid (may be
first write in tmp file and then rename it or something else).
> > IIUC on shutdown request, postmaster will send signal to BG Saver
> > and BG Saver will save the buffers and then postmaster will send
> > signal to checkpointer to shutdown. So before writing Checkpoint
> > record, BG Saver can crash (it might have saved half the buffers)
>
> Case handled as described above.
>
> > or may BG saver saves buffers, but checkpointer crashes (due to
> > power outage or any such thing).
>
> Checkpointer process' crash seems to be irrelevant to Postgres
> Hibernator's workings.
Yeap, but if it crashes before writing checkpoint record, it will lead to
> > IIUC on shutdown request, postmaster will send signal to BG Saver
> > and BG Saver will save the buffers and then postmaster will send
> > signal to checkpointer to shutdown. So before writing Checkpoint
> > record, BG Saver can crash (it might have saved half the buffers)
>
> Case handled as described above.
>
> > or may BG saver saves buffers, but checkpointer crashes (due to
> > power outage or any such thing).
>
> Checkpointer process' crash seems to be irrelevant to Postgres
> Hibernator's workings.
Yeap, but if it crashes before writing checkpoint record, it will lead to
recovery which is what we are considering.
> I think you are trying to argue the wording in my claim "save-files
> are created only on clean shutdowons; not on a crash or immediate
> shutdown", by implying that a crash may occur at any time during and
> after the BufferSaver processing. I agree the wording can be improved.
Not only wording, but in your above mail Case 2 and 1b would need to
> I think you are trying to argue the wording in my claim "save-files
> are created only on clean shutdowons; not on a crash or immediate
> shutdown", by implying that a crash may occur at any time during and
> after the BufferSaver processing. I agree the wording can be improved.
Not only wording, but in your above mail Case 2 and 1b would need to
load buffer's and perform recovery as well, so we need to decide which
one to give preference.
So If you agree that we should have consideration for recovery data
So If you agree that we should have consideration for recovery data
along with saved files data, then I think we have below options to
consider:
1. Have an provision for user to specify which data (recovery or
previous cached blocks) should be considered more important
and then load buffers before or after recovery based on that
input.
2. Always perform before recovery and mention in docs that users
can expect more time for servers to start in case they enable this
extension along with the advantages of the same.
3. Always perform after recovery and mention in docs that enabling
this extension might discard cached data by recovery or initial few
operations done by user.
4. Have an exposed API by BufMgr module such that Buffer loader
will only consider buffers in freelist to load buffers.
Based on opinion of others, I think we can decide on one of these
or if any other better way.
On Thu, Jun 5, 2014 at 8:32 AM, Gurjeet Singh <gurjeet@singh.im> wrote: > On Wed, Jun 4, 2014 at 2:50 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> The thing I was concerned about is that the system might have been in >> recovery for months. What was hot at the time the base backup was >> taken seems like a poor guide to what will be hot at the time of >> promotion. Consider a history table, for example: the pages at the >> end, which have just been written, are much more likely to be useful >> than anything earlier. > > I think you are specifically talking about a warm-standby that runs > recovery for months before being brought online. As described in my > response to Amit, if the base backup used to create that standby was > taken after the BlockReaders had restored the buffers (which should > complete within few minutes of startup, even for large databases), > then there's no concern since the base backup wouldn't contain the > save-files. > > If it's a hot-standby, the restore process would start as soon as the > database starts accepting connections, finish soon after, and get > completely out of the way of the normal recovery process. At which > point the buffers populated by the recovery would compete only with > the buffers being requested by backends, which is the normal > behaviour. I guess I don't see what warm-standby vs. hot-standby has to do with it. If recovery has been running for a long time, then restoring buffers from some save file created before that is probably a bad idea, regardless of whether the buffers already loaded were read in by recovery itself or by queries running on the system. But if you're saying that doesn't happen, then there's no problem there. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Tue, Jun 10, 2014 at 12:02 PM, Robert Haas <robertmhaas@gmail.com> wrote: > If recovery has been running for a long time, then restoring > buffers from some save file created before that is probably a bad > idea, regardless of whether the buffers already loaded were read in by > recovery itself or by queries running on the system. But if you're > saying that doesn't happen, then there's no problem there. Normally, it won't happen. There's one case I can think of, which has to coincide with a small window of time for such a thing to happen. Consider this: .) A database is shutdown, which creates the save-files in $PGDATA/pg_hibernator/. .) The database is restarted. .) BlockReaders begin to read and restore the disk blocks into buffers. .) Before the BlockReaders could finish*, a copy of the database is taken (rsync/cp/FS-snapshot/etc.) This causes the the save-files to be present in the copy, because the BlockReaders haven't deleted them, yet. * (The BlockReaders ideally finish their task in first few minutes after first of them is started.) .) The copy of the database is used to restore and erect a warm-standby. .) The warm-standby starts replaying logs from WAL archive/stream. .) Some time (hours/weeks/months) later, the warm-standby is promoted to be a master. .) It starts the Postgres Hibernator, which sees save-files in $PGDATA/pg_hibernator/ and launches BlockReaders. At this point, the BlockReaders will restore the blocks that were present in original DB's shared-buffers at the time of shutdown. So, this would fetch blocks into shared-buffers that may be completely unrelated to the blocks recently operated on by the recovery process. And it's probably accepted by now that such a bahviour is not catastrophic, merely inconvenient. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Sun, Jun 8, 2014 at 3:24 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Fri, Jun 6, 2014 at 5:31 PM, Gurjeet Singh <gurjeet@singh.im> wrote: >> On Thu, Jun 5, 2014 at 11:32 PM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: > >> > Buffer saver process itself can crash while saving or restoring >> > buffers. >> >> True. That may lead to partial list of buffers being saved. And the >> code in Reader process tries hard to read only valid data, and punts >> at the first sight of data that doesn't make sense or on ERROR raised >> from Postgres API call. > > Inspite of Reader Process trying hard, I think we should ensure by > some other means that file saved by buffer saver is valid (may be > first write in tmp file and then rename it or something else). I see no harm in current approach, since even if the file is partially written on shutdown, or if it is corrupted due to hardware corruption, the worst that can happen is the BlockReaders will try to restore, and possibly succeed, a wrong block to shared-buffers. I am okay with your approach of first writing to a temp file, if others see an advantage of doing this and insist on it. >> > IIUC on shutdown request, postmaster will send signal to BG Saver >> > and BG Saver will save the buffers and then postmaster will send >> > signal to checkpointer to shutdown. So before writing Checkpoint >> > record, BG Saver can crash (it might have saved half the buffers) >> >> Case handled as described above. >> >> > or may BG saver saves buffers, but checkpointer crashes (due to >> > power outage or any such thing). >> >> Checkpointer process' crash seems to be irrelevant to Postgres >> Hibernator's workings. > > Yeap, but if it crashes before writing checkpoint record, it will lead to > recovery which is what we are considering. Good point. In case of such recovery, the recovery process will read in the blocks that were recently modified, and were possibly still in shared-buffers when Checkpointer crashed. So after recovery finishes, the BlockReaders will be invoked (because save-files were successfully written before the crash), and they would request the same blocks to be restored. Most likely, those blocks would already be in shared-buffers, hence no cause of concern regarding BlockReaders evicting buffers populated by recovery. >> I think you are trying to argue the wording in my claim "save-files >> are created only on clean shutdowons; not on a crash or immediate >> shutdown", by implying that a crash may occur at any time during and >> after the BufferSaver processing. I agree the wording can be improved. > > Not only wording, but in your above mail Case 2 and 1b would need to > load buffer's and perform recovery as well, so we need to decide which > one to give preference. In the cases you mention, 1b and 2, ideally there will be no save-files because the server either (1b) was still running, or (2) crashed. If there were any save-files present during the previous startup (the one that happened before (1b) hot-backup or (2) crash) of the server, they would have been removed by the BlockReaders soon after the startup. > So If you agree that we should have consideration for recovery data > along with saved files data, then I think we have below options to > consider: I don't think any of the options you mention need any consideration because recovery and buffer-restore process don't seem to be at conflict with each other; not enough to be a concern, IMHO. Thanks and best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Wed, Jun 11, 2014 at 7:59 AM, Gurjeet Singh <gurjeet@singh.im> wrote:
> On Sun, Jun 8, 2014 at 3:24 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> >> > IIUC on shutdown request, postmaster will send signal to BG Saver
> >> > and BG Saver will save the buffers and then postmaster will send
> >> > signal to checkpointer to shutdown. So before writing Checkpoint
> >> > record, BG Saver can crash (it might have saved half the buffers)
> >>
> >> Case handled as described above.
> >>
> >> > or may BG saver saves buffers, but checkpointer crashes (due to
> >> > power outage or any such thing).
> >>
> >> Checkpointer process' crash seems to be irrelevant to Postgres
> >> Hibernator's workings.
> >
> > Yeap, but if it crashes before writing checkpoint record, it will lead to
> > recovery which is what we are considering.
>
> Good point.
>
> In case of such recovery, the recovery process will read in the blocks
> that were recently modified, and were possibly still in shared-buffers
> when Checkpointer crashed. So after recovery finishes, the
> >> I think you are trying to argue the wording in my claim "save-files
> >> are created only on clean shutdowons; not on a crash or immediate
> >> shutdown", by implying that a crash may occur at any time during and
> >> after the BufferSaver processing. I agree the wording can be improved.
> >
> > Not only wording, but in your above mail Case 2 and 1b would need to
> > load buffer's and perform recovery as well, so we need to decide which
> > one to give preference.
>
> In the cases you mention, 1b and 2, ideally there will be no
> save-files because the server either (1b) was still running, or (2)
> crashed.
>
> If there were any save-files present during the previous startup (the
> one that happened before (1b) hot-backup or (2) crash) of the server,
> they would have been removed by the BlockReaders soon after the
> startup.
I think Block Readers will remove file only after reading and populating
> On Sun, Jun 8, 2014 at 3:24 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
> >> > IIUC on shutdown request, postmaster will send signal to BG Saver
> >> > and BG Saver will save the buffers and then postmaster will send
> >> > signal to checkpointer to shutdown. So before writing Checkpoint
> >> > record, BG Saver can crash (it might have saved half the buffers)
> >>
> >> Case handled as described above.
> >>
> >> > or may BG saver saves buffers, but checkpointer crashes (due to
> >> > power outage or any such thing).
> >>
> >> Checkpointer process' crash seems to be irrelevant to Postgres
> >> Hibernator's workings.
> >
> > Yeap, but if it crashes before writing checkpoint record, it will lead to
> > recovery which is what we are considering.
>
> Good point.
>
> In case of such recovery, the recovery process will read in the blocks
> that were recently modified, and were possibly still in shared-buffers
> when Checkpointer crashed. So after recovery finishes, the
> BlockReaders will be invoked (because save-files were successfully
> written before the crash), and they would request the same blocks to
> be restored. Most likely, those blocks would already be in
> shared-buffers, hence no cause of concern regarding BlockReaders
> evicting buffers populated by recovery.
> written before the crash), and they would request the same blocks to
> be restored. Most likely, those blocks would already be in
> shared-buffers, hence no cause of concern regarding BlockReaders
> evicting buffers populated by recovery.
Not necessarily because after crash, recovery has to start from
previous checkpoint, so it might not perform operations on same
pages as are saved by buffer saver. Also as the file saved by
buffer saver can be a file which contains only partial list of
buffers which were in shared buffer's, it becomes more likely that
in such cases it can override the buffers populated by recovery.
Now as pg_hibernator doesn't give any preference to usage_count while
saving buffer's, it can also evict the buffers populated by recovery
with some lower used pages of previous run.
> >> I think you are trying to argue the wording in my claim "save-files
> >> are created only on clean shutdowons; not on a crash or immediate
> >> shutdown", by implying that a crash may occur at any time during and
> >> after the BufferSaver processing. I agree the wording can be improved.
> >
> > Not only wording, but in your above mail Case 2 and 1b would need to
> > load buffer's and perform recovery as well, so we need to decide which
> > one to give preference.
>
> In the cases you mention, 1b and 2, ideally there will be no
> save-files because the server either (1b) was still running, or (2)
> crashed.
>
> If there were any save-files present during the previous startup (the
> one that happened before (1b) hot-backup or (2) crash) of the server,
> they would have been removed by the BlockReaders soon after the
> startup.
I think Block Readers will remove file only after reading and populating
buffers from it and that's the reason I mentioned that it can lead to doing
both recovery as well as load buffers based on file saved by buffer
saver.
On Tue, Jun 10, 2014 at 10:03 PM, Gurjeet Singh <gurjeet@singh.im> wrote: > And it's probably accepted by now that such a bahviour is not > catastrophic, merely inconvenient. I think the whole argument for having pg_hibernator is that getting the block cache properly initialized is important. If it's not important, then we don't need pg_hibernator in the first place. But if it is important, then I think not loading unrelated blocks into shared_buffers is also important. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jun 11, 2014 at 12:25 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Wed, Jun 11, 2014 at 7:59 AM, Gurjeet Singh <gurjeet@singh.im> wrote: >> On Sun, Jun 8, 2014 at 3:24 AM, Amit Kapila <amit.kapila16@gmail.com> >> wrote: >> > Yeap, but if it crashes before writing checkpoint record, it will lead >> > to >> > recovery which is what we are considering. >> >> Good point. >> >> In case of such recovery, the recovery process will read in the blocks >> that were recently modified, and were possibly still in shared-buffers >> when Checkpointer crashed. So after recovery finishes, the >> BlockReaders will be invoked (because save-files were successfully >> written before the crash), and they would request the same blocks to >> be restored. Most likely, those blocks would already be in >> shared-buffers, hence no cause of concern regarding BlockReaders >> evicting buffers populated by recovery. > > Not necessarily because after crash, recovery has to start from > previous checkpoint, so it might not perform operations on same > pages as are saved by buffer saver. Granted, the recovery may not start that way (that is, reading in blocks that were in shared-buffers when shutdown was initiated), but it sure would end that way. Towards the end of recovery, the blocks it'd read back in are highly likely to be the ones that were present in shared-buffers at the time of shutdown. By the end of recovery, either (a) blocks read in at the beginning of recovery are evicted by later operations of recovery, or (b) they are still present in shared-buffers. So the blocks requested by the BlockReaders are highly likely to be already in shared-buffers at the end of recovery, because these are the same blocks that were dirty (and hence recorded in WAL) just before shutdown time. I guess what I am trying to say is that the blocks read in by the BlockReaders will be a superset of those read in by the reocvery process. At the time of shutdown/saving-buffers, the shared-buffers may have contained dirty and clean buffers. WAL contains the info of which blocks were dirtied. Recovery will read back the blocks that were dirty, to replay the WAL, and since the BlockReaders are started _after_ recovery finishes, the BlockReaders will effectively read in only those blocks that are not already read-in by the recovery. I am not yet convinced, at least in this case, that Postgres Hibernator would restore blocks that can cause eviction of buffers restored by recovery. I don't have intimate knowledge of recovery but I think the above assessment of recovery's operations holds true. If you still think this is a concern, can you please provide a bit firm example using which I can visualize the problem you're talking about. > Also as the file saved by > buffer saver can be a file which contains only partial list of > buffers which were in shared buffer's, it becomes more likely that > in such cases it can override the buffers populated by recovery. I beg to differ. As described above, the blocks read-in by the BlockReader will not evict the recovery-restored blocks. The save-files being written partially does not change that. > Now as pg_hibernator doesn't give any preference to usage_count while > saving buffer's, it can also evict the buffers populated by recovery > with some lower used pages of previous run. The case we're discussing (checkpointer/BufferSaver/some-other-process crash during a smart/fast shutdown) should occur rarely in practice. Although Postgres Hibernator is not yet proven to do the wrong thing in this case, I hope you'd agree that BlockReaders evicting buffers populated by recovery process is not catastrophic at all, merely inconvenient from performance perspective. Also, the impact is only on the initial performance immediately after startup, since application queries will re-prime the shared-buffers with whatever buffers they need. > I think Block Readers will remove file only after reading and populating > buffers from it Correct. > and that's the reason I mentioned that it can lead to doing > both recovery as well as load buffers based on file saved by buffer > saver. I am not sure I completely understand the implication here, but I think the above description of case where recovery-followed-by-BlockReaders not causing a concern may cover it. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Wed, Jun 11, 2014 at 10:56 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Tue, Jun 10, 2014 at 10:03 PM, Gurjeet Singh <gurjeet@singh.im> wrote: >> And it's probably accepted by now that such a bahviour is not >> catastrophic, merely inconvenient. > > I think the whole argument for having pg_hibernator is that getting > the block cache properly initialized is important. If it's not > important, then we don't need pg_hibernator in the first place. But > if it is important, then I think not loading unrelated blocks into > shared_buffers is also important. I was constructing a contrived scenario, something that would rarely happen in reality. I feel that the benefits of this feature greatly outweigh the minor performance loss caused in such an unlikely scenario. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB www.EnterpriseDB.com
On Thu, Jun 12, 2014 at 12:17 AM, Gurjeet Singh <gurjeet@singh.im> wrote: > On Wed, Jun 11, 2014 at 10:56 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Tue, Jun 10, 2014 at 10:03 PM, Gurjeet Singh <gurjeet@singh.im> wrote: >>> And it's probably accepted by now that such a bahviour is not >>> catastrophic, merely inconvenient. >> >> I think the whole argument for having pg_hibernator is that getting >> the block cache properly initialized is important. If it's not >> important, then we don't need pg_hibernator in the first place. But >> if it is important, then I think not loading unrelated blocks into >> shared_buffers is also important. > > I was constructing a contrived scenario, something that would rarely > happen in reality. I feel that the benefits of this feature greatly > outweigh the minor performance loss caused in such an unlikely scenario. So, are you proposing this for inclusion in PostgreSQL core? If not, I don't think there's much to discuss here - people can use it or not as they see fit, and we'll see what happens and perhaps design improvements will result, or not. If so, that's different: you'll need to demonstrate the benefits via convincing proof points, and you'll also need to show that the disadvantages are in fact minor and that the scenario is in fact unlikely. So far there are zero performance numbers on this thread, a situation that doesn't meet community standards for a performance patch. Thanks, -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jun 12, 2014 at 12:35 PM, Robert Haas <robertmhaas@gmail.com> wrote:
> So, are you proposing this for inclusion in PostgreSQL core?
Yes, as a contrib module.
> If so, that's different: you'll need to demonstrate the benefits via
> convincing proof points
Please see attached charts, and the spreadsheet that these charts were
generated from.
Quoting from my blog, where I first published these charts:
<quote>
As can be seen in the chart below, the database ramp-up time drops
dramatically when Postgres Hibernator is enabled. The sooner the
database TPS can reach the steady state, the faster your applications
can start performing at full throttle.
The ramp-up time is even shorter if you wait for the Postgres
Hibernator processes to end, before starting your applications.
As is quite evident, waiting for Postgres Hibernator to finish loading
the data blocks before starting the application yeilds a 97%
impprovement in database ramp-up time (2300 seconds to get to 122k TPS
without Postgres Hibernator vs. 70 seconds).
### Details
Please note that this is not a real benchmark, just something I
developed to showcase this extension at its sweet spot.
The full source of this mini benchmark is available with the source
code of the Postgres Hibernator, at its [Git repo][pg_hibernator_git].
```
Hardware: MacBook Pro 9,1
OS Distribution: Ubuntu 12.04 Desktop
OS Kernel: Linux 3.11.0-19-generic
RAM: 8 GB
Physical CPU: 1
CPU Count: 4
Core Count: 8
pgbench scale: 260 (~ 4 GB database)
```
Before every test run, except the last ('DB-only restart; No
Hibernator'), the Linux OS caches are dropped to simulate an OS
restart.
In 'First Run', the Postgres Hibernator is enabled, but since this is
the first ever run of the database, Postgres Hibernator doesn't kick
in until shutdown, to save the buffer list.
In 'Hibernator w/ App', the application (pgbench) is started right
after database restart. The Postgres Hibernator is restoring the data
blocks to shared buffers while the application is also querying the
database.
In the 'App after Hibernator' case, the application is started _after_
the Postgres Hibernator has finished reading database blocks. This
took 70 seconds for reading the ~4 GB database.
In 'DB-only restart; No Hibernator` run, the OS caches are not
dropped, but just the database service is restarted. This simulates
database minor version upgrades, etc.
</quote>
> and you'll also need to show that the
> disadvantages are in fact minor and that the scenario is in fact
> unlikely.
Attached is the new patch that addresses this concern. Right at
startup, Postgres hibernator renames all .save files to
.save.restoring. Later BlockReaders restore the blocks listed in the
.save.restoring files. If, for any reason, the database crashes and
restarts, the next startup of Hibernator will first remove all
.save.restoring files.
So in the case of my contrived example,
<scenario>
1) A database is shutdown, which creates the save-files in
$PGDATA/pg_hibernator/.
2) The database is restarted.
3) BlockReaders begin to read and restore the disk blocks into buffers.
4) Before the BlockReaders could finish*, a copy of the database is
taken (rsync/cp/FS-snapshot/etc.)
This causes the the save-files to be present in the copy, because
the BlockReaders haven't deleted them, yet.
* (The BlockReaders ideally finish their task in first few minutes
after first of them is started.)
5) The copy of the database is used to restore and erect a warm-standby.
6) The warm-standby starts replaying logs from WAL archive/stream.
7) Some time (hours/weeks/months) later, the warm-standby is promoted
to be a master.
8) It starts the Postgres Hibernator, which sees save-files in
$PGDATA/pg_hibernator/ and launches BlockReaders.
</scenario>
Right at step 2 the .save files will be renamed to .save.restoring,
and later at step 8 Hibernator removes all .save.restoring files
before proceeding further. So the BlockReaders will not restore stale
save-files.
Best regards,
--
Gurjeet Singh http://gurjeet.singh.im/
EDB www.EnterpriseDB.com
Attachment
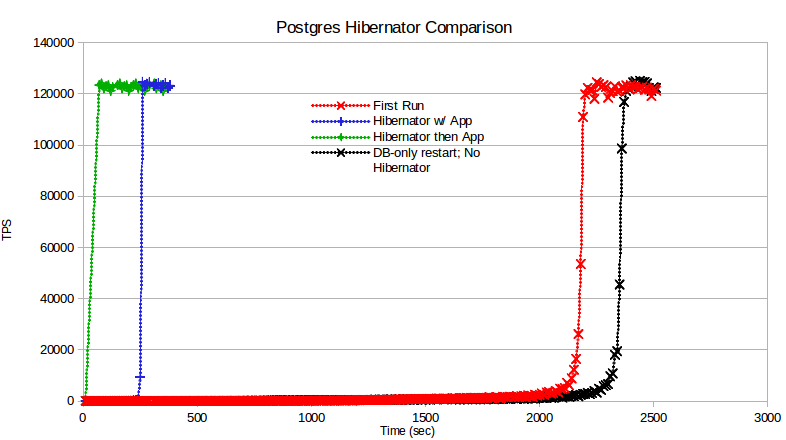{kind=link}
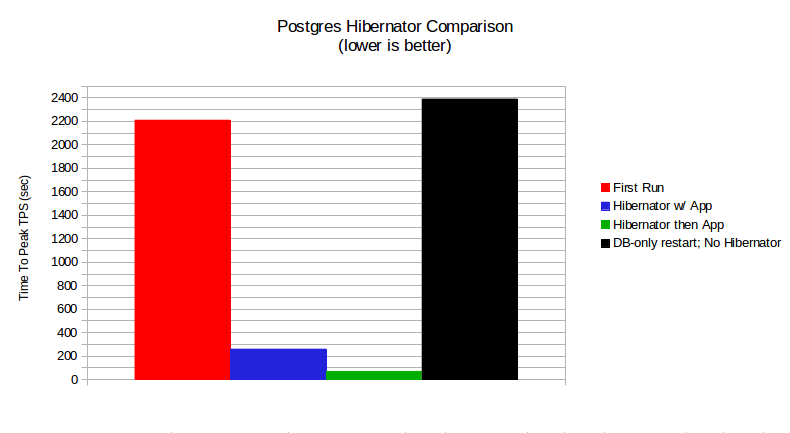{kind=link}
On Thu, Jun 12, 2014 at 9:31 AM, Gurjeet Singh <gurjeet@singh.im> wrote:
>
> I don't have intimate knowledge of recovery but I think the above
> assessment of recovery's operations holds true. If you still think
> this is a concern, can you please provide a bit firm example using
> which I can visualize the problem you're talking about.
Okay, let me try with an example:
>
> I don't have intimate knowledge of recovery but I think the above
> assessment of recovery's operations holds true. If you still think
> this is a concern, can you please provide a bit firm example using
> which I can visualize the problem you're talking about.
Okay, let me try with an example:
Assume No. of shared buffers = 5
Before Crash:
1. Pages in shared buffers numbered 3, 4, 5 have write operations
performed on them, followed by lot of reads which makes their
usage_count as 5.
2. Write operation happened on pages in shared buffers numbered
1, 2. Usage_count of these buffers is 1.
3. Now one read operation needs some different pages and evict
pages in shared buffers numbered 1 and 2 and read the required
pages, so buffers 1 and 2 will have usage count as 1.
4. At this moment shutdown initiated.
5. Bgwriter saved just buffers 1 and 2 and crashed.
After Crash:
1. Recovery will read in pages on which operations happened in
step-1 and 2 above.
2. Buffer loader (pg_hibernator) will load buffers on which operations
happened in step-3, so here it might needs to evict buffers which are
corresponding to buffers of step-1 before crash. So what this
essentially means is that pg_hibernator can lead to eviction of more
useful pages.
On Sun, Jun 15, 2014 at 2:51 AM, Amit Kapila <amit.kapila16@gmail.com> wrote: > On Thu, Jun 12, 2014 at 9:31 AM, Gurjeet Singh <gurjeet@singh.im> wrote: >> >> I don't have intimate knowledge of recovery but I think the above >> assessment of recovery's operations holds true. If you still think >> this is a concern, can you please provide a bit firm example using >> which I can visualize the problem you're talking about. > > Okay, let me try with an example: > > Assume No. of shared buffers = 5 > Before Crash: > > 1. Pages in shared buffers numbered 3, 4, 5 have write operations > performed on them, followed by lot of reads which makes their > usage_count as 5. > 2. Write operation happened on pages in shared buffers numbered > 1, 2. Usage_count of these buffers is 1. > 3. Now one read operation needs some different pages and evict > pages in shared buffers numbered 1 and 2 and read the required > pages, so buffers 1 and 2 will have usage count as 1. > 4. At this moment shutdown initiated. > 5. Bgwriter saved just buffers 1 and 2 and crashed. > > After Crash: > > 1. Recovery will read in pages on which operations happened in > step-1 and 2 above. > 2. Buffer loader (pg_hibernator) will load buffers on which operations > happened in step-3, so here it might needs to evict buffers which are > corresponding to buffers of step-1 before crash. So what this > essentially means is that pg_hibernator can lead to eviction of more > useful pages. Granted, you have demonstrated that the blocks restored by pg_hibernator can cause eviction of loaded-by-recovery blocks. But, one can argue that pg_hibernator brought the shared-buffer contents to to a state that is much closer to the pre-shutdown state than the recovery would have restored them to. I think this supports the case for pg_hibernator, that is, it is doing what it is supposed to do: restore shared-buffers to pre-shutdown state. I agree that there's uncertainty as to which buffers will be cleared, and hence which blocks will be evicted. So pg_hibernator may cause eviction of blocks that had higher usage count before the shutdown, because they may have a lower/same usage count as other blocks' buffers after recovery. There's not much that can be done for that, because usage count information is not saved anywhere on disk, and I don't think it's worth saving just for pg_hibernator's sake. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB : www.EnterpriseDB.com : The Enterprise PostgreSQL Company
On Sat, Jun 7, 2014 at 6:48 AM, Cédric Villemain <cedric@2ndquadrant.com> wrote: > Le lundi 3 février 2014 19:18:54 Gurjeet Singh a écrit : > >> Possible enhancements: >> - Ability to save/restore only specific databases. >> - Control how many BlockReaders are active at a time; to avoid I/O >> storms. FWIW, this has been implemented. By default, only one database is restored at a time. >>- Be smart about lowered shared_buffers across the restart. >> - Different modes of reading like pg_prewarm does. >> - Include PgFincore functionality, at least for Linux platforms. > > Please note that pgfincore is working on any system where PostgreSQL > prefetch is working, exactly like pg_prewarm. This includes linux, BSD and > many unix-like. It *is not* limited to linux. > > I never had a single request for windows, but windows does provides an API > for that too (however I have no windows offhand to test). > > Another side note is that currently BSD (at least freeBSD) have a more > advanced mincore() syscall than linux and offers a better analysis (dirty > status is known) and they implemented posix_fadvise... I have never used pgfincore, and have analyzed it solely based on the examples provided, second-hand info, and some code reading, so the following may be wrong; feel free to correct. The UI of pgfincore suggests that to save a snapshot of an object, pgfincore reads all the segments of the object and queries the OS cache. This may take a lot of time on big databases. If this is done at shutdown time, the time to finish shutdown will be proportional to the size of the database, rather than being proportional to the amount of data files in OS cache. > > There is a previous thread about that hibernation feature. Mitsuru IWASAKI > did a patch, and it triggers some interesting discussions. > > Some notes in this thread are outdated now, but it's worth having a look at > it: > > http://www.postgresql.org/message-id/20110504.231048.113741617.iwasaki@jp.FreeBSD.org > > https://commitfest.postgresql.org/action/patch_view?id=549 Thanks for sharing these. I agree with Greg's observations there that the shared-buffers are becoming increasingly smaller subset of the RAM available on modern machines. But until it can be done in a platform-independent way I doubt it will ever be accepted in Postgres. Even when it's accepted, it would have to be off by default because of the slow shutdown mentioned above. Best regards, -- Gurjeet Singh http://gurjeet.singh.im/ EDB : www.EnterpriseDB.com : The Enterprise PostgreSQL Company
On Wed, Jul 2, 2014 at 5:48 AM, Gurjeet Singh <gurjeet@singh.im> wrote:
>
> Granted, you have demonstrated that the blocks restored by
> pg_hibernator can cause eviction of loaded-by-recovery blocks. But,
> one can argue that pg_hibernator brought the shared-buffer contents to
> to a state that is much closer to the pre-shutdown state than the
> recovery would have restored them to. I think this supports the case
> for pg_hibernator, that is, it is doing what it is supposed to do:
> restore shared-buffers to pre-shutdown state.
>
> I agree that there's uncertainty as to which buffers will be cleared,
> and hence which blocks will be evicted. So pg_hibernator may cause
> eviction of blocks that had higher usage count before the shutdown,
> because they may have a lower/same usage count as other blocks'
> buffers after recovery.
>
> Granted, you have demonstrated that the blocks restored by
> pg_hibernator can cause eviction of loaded-by-recovery blocks. But,
> one can argue that pg_hibernator brought the shared-buffer contents to
> to a state that is much closer to the pre-shutdown state than the
> recovery would have restored them to. I think this supports the case
> for pg_hibernator, that is, it is doing what it is supposed to do:
> restore shared-buffers to pre-shutdown state.
>
> I agree that there's uncertainty as to which buffers will be cleared,
> and hence which blocks will be evicted. So pg_hibernator may cause
> eviction of blocks that had higher usage count before the shutdown,
> because they may have a lower/same usage count as other blocks'
> buffers after recovery.
I think we should address this uncertainty, else it would be difficult to
claim whether running pg_hibernator will increase the performance of
applications or decrease it. As mentioned upthread there can be other
cases as well which can be affected, I think the idea proposed by Robert
(try to do this at cluster startup time, rather than once recovery has
reached consistency.) is a neat way to handle all such uncertainties.
Doing so can increase the recovery time as well, because without
pg_hibernator, there is a high chance that it always get free shared
buffers unless recovery ran for long time and with pg_hibernator
there can situations where recovery might need to evict buffers filled
be pg_hibernator.
Overall I agree that following Robert's idea will increase the time to
make database server up and reach a state where apps can connect
and start operations, but I think atleast with such an approach we can
claim that after warming buffers with pg_hibernator apps will always
have performance greater than equal to the case when there is no
pg_hibernator.
> There's not much that can be done for that,
> because usage count information is not saved anywhere on disk, and I
> don't think it's worth saving just for pg_hibernator's sake.
Thats right, but I think if pg_hibernator can save usage count along with
> because usage count information is not saved anywhere on disk, and I
> don't think it's worth saving just for pg_hibernator's sake.
Thats right, but I think if pg_hibernator can save usage count along with
other info, then the claim that it can restore shared-buffers to pre-shutdown
state has more value.
Amit Kapila <amit.kapila16@gmail.com> wrote: > Overall I agree that following Robert's idea will increase the > time to make database server up and reach a state where apps can > connect and start operations, I agree that warming the cache before beginning to apply WAL would be best. > but I think atleast with such an approach we can claim that after > warming buffers with pg_hibernator apps will always have > performance greater than equal to the case when there is no > pg_hibernator. I would be careful of this claim in a NUMA environment. The whole reason I investigated NUMA issues and wrote the NUMA patch is that a customer had terrible performance which turned out to be caused by cache warming using a single connection (and thus a single process, and thus a single NUMA memory node). To ensure that this doesn't trash performance on machines with many cores and memory nodes, it would be best to try to spread the data around among nodes. One simple way of doing this would be to find some way to use multiple processes in hopes that they would run on difference CPU packages. -- Kevin Grittner EDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Hello, I'm reviewing this patch. I find this feature useful, so keep good work. I've just begun the review of pg_hibernate.c, and finished reviewing other files. pg_hibernate.c will probably take some time to review, so let me give you the result of my review so far. I'm sorry for trivial comments. (1) The build on Windows with MSVC 2008 Express failed. The error messages are as follows (sorry, they are in Japanese): ---------------------------------------- .\contrib\pg_hibernator\pg_hibernator.c(50): error C2373: 'CreateDirectoryA' : 再定義されています。異なる型修飾子です。 .\contrib\pg_hibernator\pg_hibernator.c(196): error C2373: 'CreateDirectoryA' : 再定義されています。異なる型修飾子です。 .\contrib\pg_hibernator\pg_hibernator.c(740): error C2198: 'CreateDirectoryA' : 呼び出しに対する引数が少なすぎます。 ---------------------------------------- The cause is that CreateDirectory() is an Win32 API. When I renamed it, the build succeeded. I think you don't need to make it a function, because its processing is simple and it is used only at one place. (2) Please look at the following messages. Block Reader read all blocks successfully but exited with 1, while the Buffer Reader exited with 0. I think the Block Reader also should exit 0 when it completes its job successfully, because the exit code 0 gives the impression of success. LOG: worker process: Buffer Saver (PID 2984) exited with exit code 0 ... LOG: Block Reader 1: all blocks read successfully LOG: worker process: Block Reader 2 (PID 6064) exited with exit code 1 In addition, the names "Buffer Saver" and "Block Reader" don't correspond, while they both operate on the same objects. I suggest using the word Buffer or Block for both processes. (3) Please add the definition of variable PGFILEDESC in Makefile. See pg_upgrade_support's Makefile for an example. It is necessary for the versioning info of DLLs on Windows. Currently, other contrib libraries lack the versioning info. Michael Paquier is adding the missing versioning info to other modules for 9.5. (4) Remove the following #ifdef, because you are attempting to include this module in 9.5. #if PG_VERSION_NUM >= 90400 (5) Add header comments at the beginning of source files like other files. (6) Add user documentation SGML file in doc/src/sgml instead of README.md. For reference, I noticed the following mistakes in README.md: instalation -> installation `Block Reader` threads -> `Block Reader` processes (7) The message "could not open \"%s\": %m" should better be: "could not open file \"%s\": %m" because this message is already used in many places. Please find and use existing messages for other places as much as possible. That will reduce the translation efforts for other languages. (8) fileClose() never returns false despite its comment: /* Returns true on success, doesn't return on error */ (9) I think it would be better for the Block Reader to include the name and/or OID of the database in its success message: LOG: Block Reader 1: restored 14 blocks (10) I think the save file name should better be <database OID>.save instead of <some arbitrary integer>.save. That also means %u.save instead of %d.save. What do you think? (11) Why don't you remove misc.c, removing unnecessary functions and keeping just really useful ones in pg_hibernator.c? For example, I don't think fileOpen(), fileClose(), fileRead() and fileWrite() need not be separate functions (see src/backend/postmaster/pgstat.c). And, there's only one call site of the following functions: readDBName getSavefileNameBeingRestored markSavefileBeingRestored Regards MauMau
Hello,
I've finished reviewing the code. I already marked this patch as waiting on
author. I'll be waiting for the revised patch, then proceed to running the
program when the patch seems reasonable.
(12)
Like worker_spi, save and restore errno in signal handlers.
(13)
Remove the following comment, and similar ones if any, because this module
is to be included in 9.5 and above.
/* * In Postgres version 9.4 and above, we use the dynamic background worker * infrastructure for BlockReaders, and the
BufferSaverprocess does the * legwork of registering the BlockReader workers. */
(14)
Expand the body following functions at their call sites and remove the
function definition, because they are called only once. It would be
straightforward to see the processing where it should be.
* DefineGUCs
* CreateDirectory
(15)
I don't understand the use case of pg_hibernator.enabled. Is this really
necessary? In what situations does this parameter "really" matter? If it's
not crucial, why don't we remove it and make the specification simpler?
(16)
As mentioned above, you can remove CreateDirectory(). Instead, you can just
mkdir() unconditionally and check the result, without first stat()ing.
(17)
Use AllocateDir/ReadDir/FreeDir instead of opendir/readdir/closedir in the
server process. Plus, follow the error handling style of other source files
using AllocateDir.
(18)
The local variable hibernate_dir appears to be unnecessary because it always
holds SAVE_LOCATION as its value. If so, remove it.
(19)
I think the severity below should better be WARNING, but I don't insist.
ereport(LOG, (errmsg("registration of background worker failed")));
(20)
"iff" should be "if".
/* Remove the element from pending list iff we could register a worker
successfully. */
(21)
How is this true? Does the shared system catalog always have at least one
shared buffer?
/* Make sure the first buffer we save belongs to global object. */ Assert(buf->database == InvalidOid);
... * Special case for global objects. The sort brings them to the * front of the list.
(22)
The format should be %u, not %d.
ereport(log_level, (errmsg("writer: writing block db %d filenode %d forknum %d blocknum
%d", database_counter, prev_filenode, prev_forknum, buf->blocknum)));
(23)
Why is the first while loop in BlockReaderMain() necessary? Just opening
the target save file isn't enough?
(24)
Use MemoryContextAllocHuge(). palloc() can only allocate chunks up to 1GB.
* This is not a concern as of now, so deferred; there's at least one other * place that allocates (NBuffers *
(much_bigger_struct)),so this seems to * be an acceptable practice. */
saved_buffers = (SavedBuffer *) palloc(sizeof(SavedBuffer) * NBuffers);
(25)
It's better for the .save files to be created per tablespace, not per
database. Tablespaces are more likely to be allocated on different storage
devices for I/O distribution and capacity. So, it would be more natural to
expect that we can restore buffers more quickly by letting multiple Block
Readers do parallel I/O on different storage devices.
(26)
Reading the below description in the documentation, it seems that Block
Readers can exit with 0 upon successful completion, because bgw_restart_time
is set to BGW_NEVER_RESTART.
"If bgw_restart_time for a background worker is configured as
BGW_NEVER_RESTART, or if it exits with an exit code of 0 or is terminated by
TerminateBackgroundWorker, it will be automatically unregistered by the
postmaster on exit."
(27)
As others said, I also think that Buffer Saver should first write to a temp
file, say *.tmp, then rename it to *.save upon completion. That prevents
the Block Reader from reading possibly corrupted half-baked file that does
not represent any hibernated state.
Regards
MauMau