Thread: Cost limited statements RFC
I'm working on a new project here that I wanted to announce, just to keep from duplicating effort in this area. I've started to add a cost limit delay for regular statements. The idea is that you set a new statement_cost_delay setting before running something, and it will restrict total resources the same way autovacuum does. I'll be happy with it when it's good enough to throttle I/O on SELECT and CREATE INDEX CONCURRENTLY. Modifying the buffer manager to account for statement-based cost accumulation isn't difficult. The tricky part here is finding the right spot to put the delay at. In the vacuum case, it's easy to insert a call to check for a delay after every block of I/O. It should be possible to find a single or small number of spots to put a delay check in the executor. But I expect that every utility command may need to be modified individually to find a useful delay point. This is starting to remind me of the SEPostgres refactoring, because all of the per-command uniqueness ends up requiring a lot of work to modify in a unified way. The main unintended consequences issue I've found so far is when a cost delayed statement holds a heavy lock. Autovacuum has some protection against letting processes with an exclusive lock on a table go to sleep. It won't be easy to do that with arbitrary statements. There's a certain amount of allowing the user to shoot themselves in the foot here that will be time consuming (if not impossible) to eliminate. The person who runs an exclusive CLUSTER that's limited by statement_cost_delay may suffer from holding the lock too long. But that might be their intention with setting the value. Hard to idiot proof this without eliminating useful options too. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Thu, May 23, 2013 at 8:27 PM, Greg Smith <greg@2ndquadrant.com> wrote: > The main unintended consequences issue I've found so far is when a cost > delayed statement holds a heavy lock. Autovacuum has some protection > against letting processes with an exclusive lock on a table go to sleep. It > won't be easy to do that with arbitrary statements. There's a certain > amount of allowing the user to shoot themselves in the foot here that will > be time consuming (if not impossible) to eliminate. The person who runs an > exclusive CLUSTER that's limited by statement_cost_delay may suffer from > holding the lock too long. But that might be their intention with setting > the value. Hard to idiot proof this without eliminating useful options too. Why not make the delay conditional on the amount of concurrency, kinda like the commit_delay? Although in this case, it should only count unwaiting connections. That way, if there's a "delay deadlock", the delay gets out of the way.
On 5/23/13 7:34 PM, Claudio Freire wrote: > Why not make the delay conditional on the amount of concurrency, kinda > like the commit_delay? Although in this case, it should only count > unwaiting connections. The test run by commit_delay is way too heavy to run after every block is processed. That code is only hit when there's a commit, which already assumes a lot of overhead is going on--the disk flush to WAL--so burning some processing/lock acquisition time isn't a big deal. The spot where statement delay is going is so performance sensitive that everything it touches needs to be local to the backend. For finding cost delayed statements that are causing trouble because they are holding locks, the only place I've thought of that runs infrequently and is poking at the right data is the deadlock detector. Turning that into a more general mechanism for finding priority inversion issues is an interesting idea. It's a bit down the road from what I'm staring at now though. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Thu, May 23, 2013 at 8:46 PM, Greg Smith <greg@2ndquadrant.com> wrote: > On 5/23/13 7:34 PM, Claudio Freire wrote: >> >> Why not make the delay conditional on the amount of concurrency, kinda >> like the commit_delay? Although in this case, it should only count >> unwaiting connections. > > > The test run by commit_delay is way too heavy to run after every block is > processed. That code is only hit when there's a commit, which already > assumes a lot of overhead is going on--the disk flush to WAL--so burning > some processing/lock acquisition time isn't a big deal. The spot where > statement delay is going is so performance sensitive that everything it > touches needs to be local to the backend. Besides of the obvious option of making a lighter check (doesn't have to be 100% precise), wouldn't this check be done when it would otherwise sleep? Is it so heavy still in that context?
On 5/23/13 7:56 PM, Claudio Freire wrote: > Besides of the obvious option of making a lighter check (doesn't have > to be 100% precise), wouldn't this check be done when it would > otherwise sleep? Is it so heavy still in that context? A commit to typical 7200RPM disk is about 10ms, while autovacuum_vacuum_cost_delay is 20ms. If the statement cost limit logic were no more complicated than commit_delay, it would be feasible to do something similar each time a statement was being put to sleep. I suspect that the cheapest useful thing will be more expensive than commit_delay's test. That's a guess though. I'll have to think about this more when I circle back toward usability. Thanks for the implementation idea. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Thu, May 23, 2013 at 7:27 PM, Greg Smith <greg@2ndquadrant.com> wrote: > I'm working on a new project here that I wanted to announce, just to keep > from duplicating effort in this area. I've started to add a cost limit > delay for regular statements. The idea is that you set a new > statement_cost_delay setting before running something, and it will restrict > total resources the same way autovacuum does. I'll be happy with it when > it's good enough to throttle I/O on SELECT and CREATE INDEX CONCURRENTLY. Cool. We have an outstanding customer request for this type of functionality; although in that case, I think the desire is more along the lines of being able to throttle writes rather than reads. But I wonder if we wouldn't be better off coming up with a little more user-friendly API. Instead of exposing a cost delay, a cost limit, and various charges, perhaps we should just provide limits measured in KB/s, like dirty_rate_limit = <amount of data you can dirty per second, in kB> and read_rate_limit = <amount of data you can read into shared buffers per second, in kB>. This is less powerful than what we currently offer for autovacuum, which allows you to come up with a "blended" measure of when vacuum has done too much work, but I don't have a lot of confidence that it's better in practice. > Modifying the buffer manager to account for statement-based cost > accumulation isn't difficult. The tricky part here is finding the right > spot to put the delay at. In the vacuum case, it's easy to insert a call to > check for a delay after every block of I/O. It should be possible to find a > single or small number of spots to put a delay check in the executor. But I > expect that every utility command may need to be modified individually to > find a useful delay point. This is starting to remind me of the SEPostgres > refactoring, because all of the per-command uniqueness ends up requiring a > lot of work to modify in a unified way. I haven't looked at this in detail, but I would hope it's not that bad. For one thing, many DDL commands don't do any significant I/O in the first place and so can probably be disregarded. Those that do are mostly things that rewrite the table and things that build indexes. I doubt there are more than 3 or 4 code paths to patch. > The main unintended consequences issue I've found so far is when a cost > delayed statement holds a heavy lock. Autovacuum has some protection > against letting processes with an exclusive lock on a table go to sleep. It > won't be easy to do that with arbitrary statements. There's a certain > amount of allowing the user to shoot themselves in the foot here that will > be time consuming (if not impossible) to eliminate. The person who runs an > exclusive CLUSTER that's limited by statement_cost_delay may suffer from > holding the lock too long. But that might be their intention with setting > the value. Hard to idiot proof this without eliminating useful options too. Well, we *could* have a system where, if someone blocks waiting for a lock held by a rate-limited process, the rate limits are raised or abolished. But I'm pretty sure that's a bad idea. I think that the people who want rate limits want them because allowing too much write (or maybe read?) activity hoses the performance of the entire system, and that's not going to be any less true if there are multiple jobs piling up. Let's say someone has a giant COPY into a huge table, and CLUSTER blocks behind it, waiting for AccessExclusiveLock. Well... making the COPY run faster so that we can hurry up and start CLUSTER-ing seems pretty clearly wrong. We want the COPY to run slower, and we want the CLUSTER to run slower, too. If we don't want that, then, as you say, we shouldn't set the GUC in the first place. Long story short, I'm inclined to define this as expected behavior. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 5/24/13 8:21 AM, Robert Haas wrote: > On Thu, May 23, 2013 at 7:27 PM, Greg Smith<greg@2ndquadrant.com> wrote: >> >I'm working on a new project here that I wanted to announce, just to keep >> >from duplicating effort in this area. I've started to add a cost limit >> >delay for regular statements. The idea is that you set a new >> >statement_cost_delay setting before running something, and it will restrict >> >total resources the same way autovacuum does. I'll be happy with it when >> >it's good enough to throttle I/O on SELECT and CREATE INDEX CONCURRENTLY. > Cool. We have an outstanding customer request for this type of > functionality; although in that case, I think the desire is more along > the lines of being able to throttle writes rather than reads. > > But I wonder if we wouldn't be better off coming up with a little more > user-friendly API. Instead of exposing a cost delay, a cost limit, > and various charges, perhaps we should just provide limits measured in > KB/s, like dirty_rate_limit = <amount of data you can dirty per > second, in kB> and read_rate_limit = <amount of data you can read into > shared buffers per second, in kB>. This is less powerful than what we > currently offer for autovacuum, which allows you to come up with a > "blended" measure of when vacuum has done too much work, but I don't > have a lot of confidence that it's better in practice. Doesn't that hit the old issue of not knowing if a read came from FS cache or disk? I realize that the current cost_delaymechanism suffers from that too, but since the API is lower level that restriction is much more apparent. Instead of KB/s, could we look at how much time one process is spending waiting on IO vs the rest of the cluster? Is it reasonablefor us to measure IO wait time for every request, at least on the most popular OSes? -- Jim C. Nasby, Data Architect jim@nasby.net 512.569.9461 (cell) http://jim.nasby.net
On 5/24/13 10:36 AM, Jim Nasby wrote: > Instead of KB/s, could we look at how much time one process is spending > waiting on IO vs the rest of the cluster? Is it reasonable for us to > measure IO wait time for every request, at least on the most popular OSes? It's not just an OS specific issue. The overhead of collecting timing data varies massively based on your hardware, which is why there's the pg_test_timing tool now to help quantify that. I have a design I'm working on that exposes the system load to the database usefully. That's what I think people really want if the goal is to be adaptive based on what else is going on. My idea is to use what "uptime" collects as a starting useful set of numbers to quantify what's going on. If you have both a short term load measurement and a longer term one like uptime provides, you can quantify both the overall load and whether it's rising or falling. I want to swipe some ideas on how moving averages are used to determine trend in stock trading systems: http://www.onlinetradingconcepts.com/TechnicalAnalysis/MASimple2.html Dynamic load-sensitive statement limits and autovacuum are completely feasible on UNIX-like systems. The work to insert a cost delay point needs to get done before building more complicated logic on top of it though, so I'm starting with this part. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On 5/24/13 9:21 AM, Robert Haas wrote: > But I wonder if we wouldn't be better off coming up with a little more > user-friendly API. Instead of exposing a cost delay, a cost limit, > and various charges, perhaps we should just provide limits measured in > KB/s, like dirty_rate_limit = <amount of data you can dirty per > second, in kB> and read_rate_limit = <amount of data you can read into > shared buffers per second, in kB>. I already made and lost the argument for doing vacuum in KB/s units, so I wasn't planning on putting that in the way of this one. I still think it's possible to switch to real world units and simplify all of those parameters. Maybe I'll get the energy to fight this battle again for 9.4. I do have a lot more tuning data from production deployments to use as evidence now. I don't think the UI end changes the bulk of the implementation work though. The time consuming part of this development is inserting all of the cost delay hooks and validating they work. Exactly what parameters and logic fires when they are called can easily be refactored later. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Fri, May 24, 2013 at 10:36 AM, Jim Nasby <jim@nasby.net> wrote: > Doesn't that hit the old issue of not knowing if a read came from FS cache > or disk? I realize that the current cost_delay mechanism suffers from that > too, but since the API is lower level that restriction is much more > apparent. Sure, but I think it's still useful despite that limitation. > Instead of KB/s, could we look at how much time one process is spending > waiting on IO vs the rest of the cluster? Is it reasonable for us to measure > IO wait time for every request, at least on the most popular OSes? I doubt that's going to be very meaningful. The backend that dirties the buffer is fairly likely to be different from the backend that writes it out. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Fri, May 24, 2013 at 11:51 AM, Greg Smith <greg@2ndquadrant.com> wrote:
On 5/24/13 9:21 AM, Robert Haas wrote:I already made and lost the argument for doing vacuum in KB/s units, so I wasn't planning on putting that in the way of this one.But I wonder if we wouldn't be better off coming up with a little more
user-friendly API. Instead of exposing a cost delay, a cost limit,
and various charges, perhaps we should just provide limits measured in
KB/s, like dirty_rate_limit = <amount of data you can dirty per
second, in kB> and read_rate_limit = <amount of data you can read into
shared buffers per second, in kB>.
I think the problem is that making that change would force people to relearn something that was already long established, and it was far from clear that the improvement, though real, was big enough to justify forcing people to do that. That objection would not apply to a new feature, as there would be nothing to re-learn. The other objection was that (at that time) we had some hope that the entire workings would be redone for 9.3, and it seemed unfriendly to re-name things in 9.2 without much change in functionality, and then redo them completely in 9.3.
Cheers,
Jeff
On Thu, Jun 6, 2013 at 3:34 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Fri, May 24, 2013 at 11:51 AM, Greg Smith <greg@2ndquadrant.com> wrote: >> >> On 5/24/13 9:21 AM, Robert Haas wrote: >> >>> But I wonder if we wouldn't be better off coming up with a little more >>> user-friendly API. Instead of exposing a cost delay, a cost limit, >>> and various charges, perhaps we should just provide limits measured in >>> KB/s, like dirty_rate_limit = <amount of data you can dirty per >>> second, in kB> and read_rate_limit = <amount of data you can read into >>> shared buffers per second, in kB>. >> >> >> I already made and lost the argument for doing vacuum in KB/s units, so I >> wasn't planning on putting that in the way of this one. > > > I think the problem is that making that change would force people to relearn > something that was already long established, and it was far from clear that > the improvement, though real, was big enough to justify forcing people to do > that. That objection would not apply to a new feature, as there would be > nothing to re-learn. The other objection was that (at that time) we had > some hope that the entire workings would be redone for 9.3, and it seemed > unfriendly to re-name things in 9.2 without much change in functionality, > and then redo them completely in 9.3. Right. Also, IIRC, the limits didn't really mean what they purported to mean. You set either a read or a dirty rate in KB/s, but what was really limited was the combination of the two, and the relative importance of the two factors was based on other settings in a severely non-obvious way. If we can see our way clear to ripping out the autovacuum costing stuff and replacing them with a read rate limit and a dirty rate limit, I'd be in favor of that. The current system limits the linear combination of those with user-specified coefficients, which is more powerful but less intuitive. If we need that, we'll have to keep it the way it is, but I'm hoping we don't. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 2013-06-06 12:34:01 -0700, Jeff Janes wrote: > On Fri, May 24, 2013 at 11:51 AM, Greg Smith <greg@2ndquadrant.com> wrote: > > > On 5/24/13 9:21 AM, Robert Haas wrote: > > > > But I wonder if we wouldn't be better off coming up with a little more > >> user-friendly API. Instead of exposing a cost delay, a cost limit, > >> and various charges, perhaps we should just provide limits measured in > >> KB/s, like dirty_rate_limit = <amount of data you can dirty per > >> second, in kB> and read_rate_limit = <amount of data you can read into > >> shared buffers per second, in kB>. > >> > > > > I already made and lost the argument for doing vacuum in KB/s units, so I > > wasn't planning on putting that in the way of this one. > > > I think the problem is that making that change would force people to > relearn something that was already long established, and it was far from > clear that the improvement, though real, was big enough to justify forcing > people to do that. I don't find that argument very convincing. Since you basically can translate the current variables into something like the above variables with some squinting we sure could have come up with some way to keep the old definition and automatically set the new GUCs and the other way round. guc.c should even have enough information to prohibit setting both in the config file... Greetings, Andres Freund -- Andres Freund http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 6/6/13 4:02 PM, Robert Haas wrote: > If we can see our way clear to ripping out the autovacuum costing > stuff and replacing them with a read rate limit and a dirty rate > limit, I'd be in favor of that. The current system limits the linear > combination of those with user-specified coefficients, which is more > powerful but less intuitive. There is also an implied memory bandwidth limit via the costing for a hit, which was the constraint keeping me from just going this way last time this came up. It essentially limits vacuum to 78MB/s of scanning memory even when there's no disk I/O involved. I wasn't sure if that was still important, you can also control it now via these coefficients, and most of the useful disk rate refactorings simplify a lot if that's gone. The rest of this message is some evidence that's not worth keeping though, which leads into a much cleaner plan than I tried to pitch before. I can now tell you that a busy server with decent memory can easily chug through 7.8GB/s of activity against shared_buffers, making the existing 78MB/s limit is a pretty tight one. 7.8GB/s of memory access is 1M buffers/second as measured by pg_stat_database.blks_read. I've attached a sample showing the highest rate I've seen as evidence of how fast servers can really go now, from a mainstream 24 Intel cores in 2 sockets system. Nice hardware, but by no means exotic stuff. And I can hit 500M buffers/s = 4GB/s of memory even with my laptop. I have also subjected some busy sites to a field test here since the original discussion, to try and nail down if this is really necessary. So far I haven't gotten any objections, and I've seen one serious improvement, after setting vacuum_cost_page_hit to 0. The much improved server is the one I'm showing here. When a page hit doesn't cost anything, the new limiter on how fast vacuum can churn through a well cached relation usually becomes the CPU speed of a single core. Nowadays, you can peg any single core like that and still not disrupt the whole server. If the page hit limit goes away, the user with a single core server who used to having autovacuum only pillage shared_buffers at 78MB/s might complain that if it became unbounded. I'm not scared of that impacting any sort of mainstream hardware from the last few years though. I think you'd have to be targeting PostgreSQL on embedded or weak mobile chips to even notice the vacuum page hit rate here in 2013. And even if your database is all in shared_buffers so it's possible to chug through it non-stop, you're way more likely to suffer from an excess dirty page write rate than this. Buying that it's OK to scrap the hit limit leads toward a simple to code implementation of read/write rate limits implemented like this: -vacuum_cost_page_* are removed as external GUCs. Maybe the internal accounting for them stays the same for now, just to keep the number of changes happening at once easier. -vacuum_cost_delay becomes an internal parameter fixed at 20ms. That's worked out OK in the field, there's not a lot of value to a higher setting, and lower settings are impractical due to the effective 10ms lower limit on sleeping some systems have. -vacuum_cost_limit goes away as an external GUC, and instead the actual cost limit becomes an internal value computed from the other parameters. At the default values the value that pops out will still be close to 200. Not messing with that will keep all of the autovacuum worker cost splitting logic functional. -New vacuum_read_limit and vacuum_write_limit are added as a kB value for the per second maximum rate. -1 means unlimited. The pair replaces changing the cost delay as the parameters that turns cost limiting on or off. That's 5 GUCs with complicated setting logic removed, replaced by 2 simple knobs, plus some churn in the autovacuum_* versions. Backwards compatibility for tuned systems will be shot. My position is that anyone smart enough to have navigated the existing mess of these settings and done something useful with them will happily take having their custom tuning go away, if it's in return for the simplification. At this point I feel exactly the same way I did about the parameters removed by the BGW auto-tuning stuff that went away in 8.3, with zero missing the old knobs that I heard. Another year of experiments and feedback has convinced me nobody is setting this usefully in the field who wouldn't prefer the new interface. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
Attachment
{kind=link}
On Thu, Jun 6, 2013 at 7:36 PM, Greg Smith <greg@2ndquadrant.com> wrote: > I have also subjected some busy sites to a field test here since the > original discussion, to try and nail down if this is really necessary. So > far I haven't gotten any objections, and I've seen one serious improvement, > after setting vacuum_cost_page_hit to 0. The much improved server is the > one I'm showing here. When a page hit doesn't cost anything, the new > limiter on how fast vacuum can churn through a well cached relation usually > becomes the CPU speed of a single core. Nowadays, you can peg any single > core like that and still not disrupt the whole server. Check. I have no trouble believing that limit is hurting us more than it's helping us. > If the page hit limit goes away, the user with a single core server who used > to having autovacuum only pillage shared_buffers at 78MB/s might complain > that if it became unbounded. Except that it shouldn't become unbounded, because of the ring-buffer stuff. Vacuum can pillage the OS cache, but the degree to which a scan of a single relation can pillage shared_buffers should be sharply limited. > Buying that it's OK to scrap the hit limit leads toward a simple to code > implementation of read/write rate limits implemented like this: > > -vacuum_cost_page_* are removed as external GUCs. Maybe the internal > accounting for them stays the same for now, just to keep the number of > changes happening at once easier. > > -vacuum_cost_delay becomes an internal parameter fixed at 20ms. That's > worked out OK in the field, there's not a lot of value to a higher setting, > and lower settings are impractical due to the effective 10ms lower limit on > sleeping some systems have. > > -vacuum_cost_limit goes away as an external GUC, and instead the actual cost > limit becomes an internal value computed from the other parameters. At the > default values the value that pops out will still be close to 200. Not > messing with that will keep all of the autovacuum worker cost splitting > logic functional. I think you're missing my point here, which is is that we shouldn't have any such things as a "cost limit". We should limit reads and writes *completely separately*. IMHO, there should be a limit on reading, and a limit on dirtying data, and those two limits should not be tied to any common underlying "cost limit". If they are, they will not actually enforce precisely the set limit, but some other composite limit which will just be weird. IOW, we'll need new logic to sleep when we exceed either the limit on read-rate OR when we exceed the limit on dirty-rate. The existing smushed-together "cost limit" should just go away entirely. If you want, I can mock up what I have in mind. I am pretty sure it won't be very hard. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 6/7/13 10:14 AM, Robert Haas wrote: >> If the page hit limit goes away, the user with a single core server who used >> to having autovacuum only pillage shared_buffers at 78MB/s might complain >> that if it became unbounded. > > Except that it shouldn't become unbounded, because of the ring-buffer > stuff. Vacuum can pillage the OS cache, but the degree to which a > scan of a single relation can pillage shared_buffers should be sharply > limited. I wasn't talking about disruption of the data that's in the buffer cache. The only time the scenario I was describing plays out is when the data is already in shared_buffers. The concern is damage done to the CPU's data cache by this activity. Right now you can't even reach 100MB/s of damage to your CPU caches in an autovacuum process. Ripping out the page hit cost will eliminate that cap. Autovacuum could introduce gigabytes per second of memory -> L1 cache transfers. That's what all my details about memory bandwidth were trying to put into context. I don't think it really matter much because the new bottleneck will be the processing speed of a single core, and that's still a decent cap to most people now. > I think you're missing my point here, which is is that we shouldn't > have any such things as a "cost limit". We should limit reads and > writes *completely separately*. IMHO, there should be a limit on > reading, and a limit on dirtying data, and those two limits should not > be tied to any common underlying "cost limit". If they are, they will > not actually enforce precisely the set limit, but some other composite > limit which will just be weird. I see the distinction you're making now, don't need a mock up to follow you. The main challenge of moving this way is that read and write rates never end up being completely disconnected from one another. A read will only cost some fraction of what a write does, but they shouldn't be completely independent. Just because I'm comfortable doing 10MB/s of reads and 5MB/s of writes, I may not be happy with the server doing 9MB/s read + 5MB/s write=14MB/s of I/O in an implementation where they float independently. It's certainly possible to disconnect the two like that, and people will be able to work something out anyway. I personally would prefer not to lose some ability to specify how expensive read and write operations should be considered in relation to one another. Related aside: shared_buffers is becoming a decreasing fraction of total RAM each release, because it's stuck with this rough 8GB limit right now. As the OS cache becomes a larger multiple of the shared_buffers size, the expense of the average read is dropping. Reads are getting more likely to be in the OS cache but not shared_buffers, which makes the average cost of any one read shrink. But writes are as expensive as ever. Real-world tunings I'm doing now reflecting that, typically in servers with >128GB of RAM, have gone this far in that direction: vacuum_cost_page_hit = 0 vacuum_cost_page_hit = 2 vacuum_cost_page_hit = 20 That's 4MB/s of writes, 40MB/s of reads, or some blended mix that considers writes 10X as expensive as reads. The blend is a feature. The logic here is starting to remind me of how the random_page_cost default has been justified. Read-world random reads are actually close to 50X as expensive as sequential ones. But the average read from the executor's perspective is effectively discounted by OS cache hits, so 4.0 is still working OK. In large memory servers, random reads keep getting cheaper via better OS cache hit odds, and it's increasingly becoming something important to tune for. Some of this mess would go away if we could crack the shared_buffers scaling issues for 9.4. There's finally enough dedicated hardware around to see the issue and work on it, but I haven't gotten a clear picture of any reproducible test workload that gets slower with large buffer cache sizes. If anyone has a public test case that gets slower when shared_buffers goes from 8GB to 16GB, please let me know; I've got two systems setup I could chase that down on now. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Fri, Jun 7, 2013 at 11:35 AM, Greg Smith <greg@2ndquadrant.com> wrote: > I wasn't talking about disruption of the data that's in the buffer cache. > The only time the scenario I was describing plays out is when the data is > already in shared_buffers. The concern is damage done to the CPU's data > cache by this activity. Right now you can't even reach 100MB/s of damage to > your CPU caches in an autovacuum process. Ripping out the page hit cost > will eliminate that cap. Autovacuum could introduce gigabytes per second of > memory -> L1 cache transfers. That's what all my details about memory > bandwidth were trying to put into context. I don't think it really matter > much because the new bottleneck will be the processing speed of a single > core, and that's still a decent cap to most people now. OK, I see. No objection here; not sure how others feel. >> I think you're missing my point here, which is is that we shouldn't >> have any such things as a "cost limit". We should limit reads and >> writes *completely separately*. IMHO, there should be a limit on >> reading, and a limit on dirtying data, and those two limits should not >> be tied to any common underlying "cost limit". If they are, they will >> not actually enforce precisely the set limit, but some other composite >> limit which will just be weird. > > I see the distinction you're making now, don't need a mock up to follow you. > The main challenge of moving this way is that read and write rates never end > up being completely disconnected from one another. A read will only cost > some fraction of what a write does, but they shouldn't be completely > independent. > > Just because I'm comfortable doing 10MB/s of reads and 5MB/s of writes, I > may not be happy with the server doing 9MB/s read + 5MB/s write=14MB/s of > I/O in an implementation where they float independently. It's certainly > possible to disconnect the two like that, and people will be able to work > something out anyway. I personally would prefer not to lose some ability to > specify how expensive read and write operations should be considered in > relation to one another. OK. I was hoping that wasn't a distinction that we needed to preserve, but if it is, it is. The trouble, though, is that I think it makes it hard to structure the GUCs in terms of units that are meaningful to the user. One could have something like io_rate_limit (measured in MB/s), io_read_multiplier = 1.0, io_dirty_multiplier = 1.0, and I think that would be reasonably clear. By default io_rate_limit would govern the sum of read activity and dirtying activity, but you could overweight or underweight either of those two things by adjusting the multiplier.That's not a huge improvement in clarity, though, especiallyif the default values aren't anywhere close to 1.0. If the limits aren't independent, I really *don't* think it's OK to name them as if they are. That just seems like a POLA violation. > Related aside: shared_buffers is becoming a decreasing fraction of total > RAM each release, because it's stuck with this rough 8GB limit right now. > As the OS cache becomes a larger multiple of the shared_buffers size, the > expense of the average read is dropping. Reads are getting more likely to > be in the OS cache but not shared_buffers, which makes the average cost of > any one read shrink. But writes are as expensive as ever. > > Real-world tunings I'm doing now reflecting that, typically in servers with >>128GB of RAM, have gone this far in that direction: > > vacuum_cost_page_hit = 0 > vacuum_cost_page_hit = 2 > vacuum_cost_page_hit = 20 > > That's 4MB/s of writes, 40MB/s of reads, or some blended mix that considers > writes 10X as expensive as reads. The blend is a feature. Fair enough, but note that limiting the two things independently, to 4MB/s and 40MB/s, would not be significantly different. If the workload is all reads or all writes, it won't be different at all. The biggest difference would many or all writes also require reads, in which case the write rate will drop from 4MB/s to perhaps as low as 3.6MB/s. That's not a big difference. In general, the benefits of the current system are greatest when the costs of reads and writes are similar. If reads and writes have equal cost, it's clearly very important to have a blended cost. But the more the cost of writes dominates the costs of reads, the less it really matters. It sounds like we're already well on the way to a situation where only the write cost really matters most of the time - except for large scans that read a lot of data without changing it, when only the read cost will matter. I'm not really questioning your conclusion that we need to keep the blended limit. I just want to make sure we're keeping it for a good reason, because I think it increases the user-perceived complexity here quite a bit. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 6/7/13 12:42 PM, Robert Haas wrote: > GUCs in terms of units that are meaningful to the user. One could > have something like io_rate_limit (measured in MB/s), > io_read_multiplier = 1.0, io_dirty_multiplier = 1.0, and I think that > would be reasonably clear. There's one other way to frame this: io_read_limit = 7.8MB/s # Maximum read rate io_dirty_multiplier = 2.0 # How expensive writes are considered relative to reads That still gives all of the behavior I'd like to preserve, as well as not changing the default I/O pattern. I don't think it's too complicated to ask people to grapple with that pair. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Fri, Jun 7, 2013 at 12:55 PM, Greg Smith <greg@2ndquadrant.com> wrote: > On 6/7/13 12:42 PM, Robert Haas wrote: >> GUCs in terms of units that are meaningful to the user. One could >> have something like io_rate_limit (measured in MB/s), >> io_read_multiplier = 1.0, io_dirty_multiplier = 1.0, and I think that >> would be reasonably clear. > > There's one other way to frame this: > > io_read_limit = 7.8MB/s # Maximum read rate > io_dirty_multiplier = 2.0 # How expensive writes are considered relative to > reads > > That still gives all of the behavior I'd like to preserve, as well as not > changing the default I/O pattern. I don't think it's too complicated to ask > people to grapple with that pair. That's unsatisfying to me because the io_read_limit is not really an io_read_limit at all. It is some kind of combined limit, but the name doesn't indicate that. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Thu, Jun 6, 2013 at 2:27 PM, Andres Freund <andres@2ndquadrant.com> wrote:
On 2013-06-06 12:34:01 -0700, Jeff Janes wrote:I don't find that argument very convincing. Since you basically can
> On Fri, May 24, 2013 at 11:51 AM, Greg Smith <greg@2ndquadrant.com> wrote:
>
> > On 5/24/13 9:21 AM, Robert Haas wrote:
> >
> > But I wonder if we wouldn't be better off coming up with a little more
> >> user-friendly API. Instead of exposing a cost delay, a cost limit,
> >> and various charges, perhaps we should just provide limits measured in
> >> KB/s, like dirty_rate_limit = <amount of data you can dirty per
> >> second, in kB> and read_rate_limit = <amount of data you can read into
> >> shared buffers per second, in kB>.
> >>
> >
> > I already made and lost the argument for doing vacuum in KB/s units, so I
> > wasn't planning on putting that in the way of this one.
>
>
> I think the problem is that making that change would force people to
> relearn something that was already long established, and it was far from
> clear that the improvement, though real, was big enough to justify forcing
> people to do that.
translate the current variables into something like the above variables
with some squinting we sure could have come up with some way to keep the
old definition and automatically set the new GUCs and the other way
round.
That may be, but it was not what the patch that was submitted did. And I don't think the author or the reviewers were eager to put in the effort to make that change, which would surely be quite a bit more work than the original patch was in the first place. Also, I'm not sure that such a complexity would even be welcomed. It sounds like an ongoing maintenance cost, and I'm sure the word "baroque" would get thrown around.
Anyway, I don't think that resistance to making user visible changes to old features should inhibit us from incorporating lessons from them into new features.
guc.c should even have enough information to prohibit setting
both in the config file...
Is there precedence/infrastructure for things like that? I could see uses for mutually exclusive complexes of configuration variables, but I wouldn't even know where to start in implementing such.
Cheers,
Jeff
On Thu, Jun 6, 2013 at 1:02 PM, Robert Haas <robertmhaas@gmail.com> wrote:
If we can see our way clear to ripping out the autovacuum costing
stuff and replacing them with a read rate limit and a dirty rate
limit, I'd be in favor of that. The current system limits the linear
combination of those with user-specified coefficients, which is more
powerful but less intuitive. If we need that, we'll have to keep it
the way it is, but I'm hoping we don't.
I don't know what two independent setting would look like. Say you keep two independent counters, where each can trigger a sleep, and the triggering of that sleep clears only its own counter. Now you still have a limit on the linear combination, it is just that summation has moved to a different location. You have two independent streams of sleeps, but they add up to the same amount of sleeping as a single stream based on a summed counter.
Or if one sleep clears both counters (the one that triggered it and the other one), I don't think that that is what I would call independent either. Or at least not if it has no memory. The intuitive meaning of independent would require that it keep track of which of the two counters was "controlling" over the last few seconds. Am I overthinking this?
Also, in all the anecdotes I've been hearing about autovacuum causing problems from too much IO, in which people can identify the specific problem, it has always been the write pressure, not the read, that caused the problem. Should the default be to have the read limit be inactive and rely on the dirty-limit to do the throttling?
Cheers,
Jeff
On 6/8/13 4:43 PM, Jeff Janes wrote: > Also, in all the anecdotes I've been hearing about autovacuum causing > problems from too much IO, in which people can identify the specific > problem, it has always been the write pressure, not the read, that > caused the problem. Should the default be to have the read limit be > inactive and rely on the dirty-limit to do the throttling? That would be bad, I have to carefully constrain both of them on systems that are short on I/O throughput. There all sorts of cases where cleanup of a large and badly cached relation will hit the read limit right now. I suspect the reason we don't see as many complaints is that a lot more systems can handle 7.8MB/s of random reads then there are ones that can do 3.9MB/s of random writes. If we removed that read limit, a lot more complaints would start rolling in about the read side. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Sat, Jun 8, 2013 at 1:57 PM, Greg Smith <greg@2ndquadrant.com> wrote:
Why is there so much random IO? Do your systems have autovacuum_vacuum_scale_factor set far below the default? Unless they do, most of the IO (both read and write) should be sequential. Or at least, I don't understand why they are not sequential.
On 6/8/13 4:43 PM, Jeff Janes wrote:That would be bad, I have to carefully constrain both of them on systems that are short on I/O throughput. There all sorts of cases where cleanup of a large and badly cached relation will hit the read limit right now.Also, in all the anecdotes I've been hearing about autovacuum causing
problems from too much IO, in which people can identify the specific
problem, it has always been the write pressure, not the read, that
caused the problem. Should the default be to have the read limit be
inactive and rely on the dirty-limit to do the throttling?
I wouldn't remove the ability, just change the default. You can still tune your exquisitely balanced systems :)
Of course if the default were to be changed, who knows what complaints we would start getting, which we don't get now because the current default prevents them.
But my gut feeling is that if autovacuum is trying to read faster than the hardware will support, it will just automatically get throttled, by inherent IO waits, at a level which can be comfortably supported. And this will cause minimal interference with other processes. It is self-limiting. If it tries to write too much, however, the IO system is reduced to a quivering heap, not just for that process, but for all others as well.
I suspect the reason we don't see as many complaints is that a lot more systems can handle 7.8MB/s of random reads then there are ones that can do 3.9MB/s of random writes. If we removed that read limit, a lot more complaints would start rolling in about the read side.
Cheers,
Jeff
Greg Smith <greg@2ndQuadrant.com> wrote: > I suspect the reason we don't see as many complaints is that a > lot more systems can handle 7.8MB/s of random reads then there > are ones that can do 3.9MB/s of random writes. If we removed > that read limit, a lot more complaints would start rolling in > about the read side. I'll believe that all of that is true, but I think there's another reason. With multiple layers of write cache (PostgreSQL shared_buffers, OS cache, controller or SSD cache) I think there's a tendency for an "avalanche" effect. Dirty pages stick to cache at each level like snow on the side of a mountain, accumulating over time. When it finally breaks loose at the top, it causes more from lower levels to break free as it passes. The result at the bottom can be devastating. Before I leave the metaphor, I will admit that I've sometimes done the equivalent of setting off an occasional stick of dynamite to cause things to cascade down before they have built up to a more dangerous level. Setting aside the colorful imagery, with a write cache you often see *very* fast writes for bursts or even sustained writes up to a certain point, after which you suddenly have serious latency spikes. Reads tend to degrade more gracefully, giving you a sense that you're starting to get into trouble while you still have time to react to prevent extreme conditions. At least that has been my experience. I think the "sudden onset" of problems from write saturation contributes to the complaints. -- Kevin Grittner EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 6/8/13 5:17 PM, Jeff Janes wrote: > But my gut feeling is that if autovacuum is trying to read faster than > the hardware will support, it will just automatically get throttled, by > inherent IO waits, at a level which can be comfortably supported. And > this will cause minimal interference with other processes. If this were true all the time autovacuum tuning would be a lot easier. You can easily make a whole server unresponsiveby letting loose one rogue process doing a lot of reads. Right now this isn't a problem for autovacuum because any one process running at 7.8MB/s is usually not a big deal. It doesn't take too much in the way of read-ahead logic and throughput to satisfy that. But I've seen people try and push the read rate upwards who didn't get very far beyond that before it was way too obtrusive. I could collect some data from troubled servers to see how high I can push the read rate before they suffer. Maybe there's a case there for increasing the default read rate because the write one is a good enough secondary limiter. I'd be surprised if we could get away with more than a 2 or 3X increase though, and the idea of going unlimited is really scary. It took me a year of before/after data collection before I was confident that it's OK to run unrestricted in all cache hit situations. > Why is there so much random IO? Do your systems have > autovacuum_vacuum_scale_factor set far below the default? Unless they > do, most of the IO (both read and write) should be sequential. Insert one process doing sequential reads into a stream of other activity and you can easily get random I/O against the disks out of the mix. You don't necessarily need the other activity to be random to get that. N sequential readers eventually acts like N random readers for high enough values of N. On busy servers, autovacuum is normally competing against multiple random I/O processes though. Also, the database's theoretical model that block number correlates directly with location on disk can break down. I haven't put a hard number to measuring it directly, but systems with vacuum problems seem more likely to have noticeable filesystem level fragmentation. I've been thinking about collecting data from a few systems with filefrag to see if I'm right about that. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On 6/8/13 5:20 PM, Kevin Grittner wrote: > I'll believe that all of that is true, but I think there's another > reason. With multiple layers of write cache (PostgreSQL > shared_buffers, OS cache, controller or SSD cache) I think there's > a tendency for an "avalanche" effect. Dirty pages stick to cache > at each level like snow on the side of a mountain, accumulating > over time. When it finally breaks loose at the top, it causes more > from lower levels to break free as it passes. I explained this once as being like a tower of leaky buckets where each one drips into the one below. Buckets draining out of the bottom at one rate, and new water comes in at another. You can add water much faster than it drains, for a while. But once one of the buckets fills you've got a serious mess. > I think the "sudden onset" of problems from write > saturation contributes to the complaints. It's also important to realize that vacuum itself doesn't even do the writes in many cases. If you have a large shared_buffers value, it wanders off making things dirty without any concern for what's going to disk. When the next checkpoint shows up is when pressure increases at the top. The way this discussion has wandered off has nicely confirmed I was right to try and avoid going into this area again :( -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
On Sat, Jun 8, 2013 at 4:43 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > I don't know what two independent setting would look like. Say you keep two > independent counters, where each can trigger a sleep, and the triggering of > that sleep clears only its own counter. Now you still have a limit on the > linear combination, it is just that summation has moved to a different > location. You have two independent streams of sleeps, but they add up to > the same amount of sleeping as a single stream based on a summed counter. > > Or if one sleep clears both counters (the one that triggered it and the > other one), I don't think that that is what I would call independent either. > Or at least not if it has no memory. The intuitive meaning of independent > would require that it keep track of which of the two counters was > "controlling" over the last few seconds. Am I overthinking this? Yep. Suppose the user has a read limit of 64 MB/s and a dirty limit of 4MB/s. That means that, each second, we can read 8192 buffers and dirty 512 buffers. If we sleep for 20 ms (1/50th of a second), that "covers" 163 buffer reads and 10 buffer writes, so we just reduce the accumulate counters by those amounts (minimum zero). > Also, in all the anecdotes I've been hearing about autovacuum causing > problems from too much IO, in which people can identify the specific > problem, it has always been the write pressure, not the read, that caused > the problem. Should the default be to have the read limit be inactive and > rely on the dirty-limit to do the throttling? The main time I think you're going to hit the read limit is during anti-wraparound vacuums. That problem may be gone in 9.4, if Heikki writes that patch we were discussing just recently. But at the moment, we'll do periodic rescans of relations that are already all-frozen, and that's potentially expensive. So I'm not particularly skeptical about the need to throttle reads. I suspect many people don't need it, but there are probably some who do, at least for anti-wraparound cases - especially on EC2, where the limit on I/O is often the GigE card. What I *am* skeptical about is the notion that people need the precise value of the write limit to depend on how many of the pages read are being found in shared_buffers versus not. That's essentially what the present system is accomplishing - at a great cost in user-visible complexity. Basically, I think that anti-wraparound vacuums may need either read throttling or write throttling depending on whether the data is already frozen; and regular vacuums probably only need write-throttling. But I have neither any firsthand experience nor any empirical reason to presume that the write limit needs to be lower when the read-rate is high. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
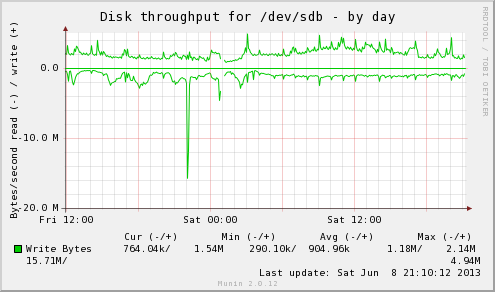
On 6/8/13 8:37 PM, Robert Haas wrote: > The main time I think you're going to hit the read limit is during > anti-wraparound vacuums. That's correct; a lot of the ones I see reading heavily are wraparound work. Those tend to be touching old blocks that are not in any cache. If the file isn't fragmented badly, this isn't as bad as it could be. Regular vacuum skips forward in relations regularly, due to the partial vacuum logic and all the mini-cleanup HOT does. Wraparound ones are more likely to hit all of the old blocks in sequence and get optimized by read-ahead. > But I have neither any firsthand experience nor any > empirical reason to presume that the write limit needs to be lower > when the read-rate is high. No argument from me that that this is an uncommon issue. Before getting into an example, I should highlight this is only an efficiency issue to me. If I can't blend the two rates together, what I'll have to do is set both read and write individually to lower values than I can right now. That's not terrible; I don't actually have a problem with that form of UI refactoring. I just need separate read and write limits of *some* form. If everyone thinks it's cleaner to give two direct limit knobs and eliminate the concept of multipliers and coupling, that's a reasonable refactoring. It just isn't the easiest change from what's there now, and that's what I was trying to push through before. Attached are some Linux graphs from a system that may surprise you, one where it would be tougher to tune aggressively without reads and writes sharing a cost limit. sdb is a RAID-1 with a pair of 15K RPM drives, and the workload is heavy on index lookups hitting random blocks on that drive. The reason this write-heavy server has so much weirdness with mixed I/O is that its disk response times are reversed from normal. Look at the latency graph (sdb-day.png). Writes are typically 10ms, while reads average 17ms! This is due to the size and manner of write caches. The server can absorb writes and carefully queue them for less seeking, across what I call a "sorting horizon" that includes a 512MB controller cache and the dirty memory in RAM. Meanwhile, when reads come in, they need to be done immediately to be useful. That means it's really only reordering/combining across the 32 element NCQ cache. (I'm sure that's the useful one because I can watch efficiency tank if I reduce that specific queue depth) The sorting horizon here is less than 1MB. On the throughput graph, + values above the axis are write throughput, while - ones are reads. It's subtle, but during the periods where the writes are heavy, the read I/O the server can support to the same drive drops too. Compare 6:00 (low writes, high reads) to 12:00 (high writes, low reads). When writes rise, it can't quite support the same read throughput anymore. This isn't that surprising on a system where reads cost more than writes do. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
Attachment
{kind=link}
{kind=link}
On Sat, Jun 8, 2013 at 10:00 PM, Greg Smith <greg@2ndquadrant.com> wrote: >> But I have neither any firsthand experience nor any >> empirical reason to presume that the write limit needs to be lower >> when the read-rate is high. > > No argument from me that that this is an uncommon issue. Before getting > into an example, I should highlight this is only an efficiency issue to me. > If I can't blend the two rates together, what I'll have to do is set both > read and write individually to lower values than I can right now. That's > not terrible; I don't actually have a problem with that form of UI > refactoring. I just need separate read and write limits of *some* form. If > everyone thinks it's cleaner to give two direct limit knobs and eliminate > the concept of multipliers and coupling, that's a reasonable refactoring. > It just isn't the easiest change from what's there now, and that's what I > was trying to push through before. OK, understood. Let's see what others have to say. > On the throughput graph, + values above the axis are write throughput, while > - ones are reads. It's subtle, but during the periods where the writes are > heavy, the read I/O the server can support to the same drive drops too. > Compare 6:00 (low writes, high reads) to 12:00 (high writes, low reads). > When writes rise, it can't quite support the same read throughput anymore. > This isn't that surprising on a system where reads cost more than writes do. That is indeed quite a surprising system, but I'm having trouble seeing the effect you're referring to, because it looks to me like a lot of the read peaks correspond to write peaks. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company