Thread: Re: [PERFORM] Slow query: bitmap scan troubles
[moved to hackers]
On Wednesday, December 5, 2012, Tom Lane wrote:
On Wednesday, December 5, 2012, Tom Lane wrote:
Jeff Janes <jeff.janes@gmail.com> writes:
> I now see where the cost is coming from. In commit 21a39de5809 (first
> appearing in 9.2) the "fudge factor" cost estimate for large indexes
> was increased by about 10 fold, which really hits this index hard.
> This was fixed in commit bf01e34b556 "Tweak genericcostestimate's
> fudge factor for index size", by changing it to use the log of the
> index size. But that commit probably won't be shipped until 9.3.
Hm. To tell you the truth, in October I'd completely forgotten about
the January patch, and was thinking that the 1/10000 cost had a lot
of history behind it. But if we never shipped it before 9.2 then of
course that idea is false. Perhaps we should backpatch the log curve
into 9.2 --- that would reduce the amount of differential between what
9.2 does and what previous branches do for large indexes.
I think we should backpatch it for 9.2.3. I've seen another email which is probably due to the same issue (nested loop vs hash join). And some monitoring of a database I am responsible for suggests it might be heading in that direction as well as the size grows.
But I am wondering if it should be present at all in 9.3. When it was introduced, the argument seemed to be that smaller indexes might be easier to keep in cache. And surely that is so. But if a larger index that covers the same type of queries exists when a smaller one also exists, we can assume the larger one also exists for a reason. While it may be easier to keep a smaller index in cache, it is not easier to keep both a larger and a smaller one in cache as the same time. So it seems to me that this reasoning is a wash. (Countering this argument is that a partial index is more esoteric, and so if one exists it is more likely to have been well-thought out)
The argument for increasing the penalty by a factor of 10 was that the smaller one could be "swamped by noise such as page-boundary-roundoff behavior". I don't really know what that means, but it seems to me that if it is so easily swamped by noise, then it probably isn't so important in the first place which one it chooses. Whereas, I think that even the log based penalty has the risk of being too much on large indexes. (For one thing, it implicitly assumes the fan-out ratio at each level of btree is e, when it will usually be much larger than e.)
One thing which depends on the index size which, as far as I can tell, is not currently being counted is the cost of comparing the tuples all the way down the index. This would be proportional to log2(indextuples) * cpu_index_tuple_cost, or maybe log2(indextuples) * (cpu_index_tuple_cost+cpu_operator_cost), or something like that. This cost would depend on the number index tuples, not baserel tuples, and so would penalize large indexes. It would be much smaller than the current log(pages/10000) penalty, but it would be more principle-based rather than heuristic-based.
The log(pages/10000) change is more suitable for back-patching because it is more conservative, being asymptotic with the previous behavior at the low end. But I don't think that the case for that previous behavior was ever all that strong.
If we really want a heuristic to give a bonus to partial indexes, maybe we should explicitly give them a bonus, rather than penalizing ordinary indexes.
maybe something like bonus = 0.05 * (reltuples-indextuples)/reltuples
Cheers,
Jeff
Jeff Janes <jeff.janes@gmail.com> writes:
> [moved to hackers]
> On Wednesday, December 5, 2012, Tom Lane wrote:
>> Hm. To tell you the truth, in October I'd completely forgotten about
>> the January patch, and was thinking that the 1/10000 cost had a lot
>> of history behind it. But if we never shipped it before 9.2 then of
>> course that idea is false. Perhaps we should backpatch the log curve
>> into 9.2 --- that would reduce the amount of differential between what
>> 9.2 does and what previous branches do for large indexes.
> I think we should backpatch it for 9.2.3. I've seen another email which is
> probably due to the same issue (nested loop vs hash join). And some
> monitoring of a database I am responsible for suggests it might be heading
> in that direction as well as the size grows.
I received an off-list report of a case where not only did the 1/10000
factor cause a nestloop-vs-hashjoin decision to be made wrongly, but
even adding the ln() computation as in commit bf01e34b556 didn't fix it.
I believe the index in question was on the order of 20000 pages, so
it's not too hard to see why this might be the case:
* historical fudge factor 4 * 20000/100000 = 0.8
* 9.2 fudge factor 4 * 20000/10000 = 8.0
* with ln() correction 4 * ln(1 + 20000/10000) = 4.39 or so
At this point I'm about ready to not only revert the 100000-to-10000
change, but keep the ln() adjustment, ie make the calculation be
random_page_cost * ln(1 + index_pages/100000). This would give
essentially the pre-9.2 behavior for indexes up to some tens of
thousands of pages, and keep the fudge factor from getting out of
control even for very very large indexes.
> But I am wondering if it should be present at all in 9.3. When it was
> introduced, the argument seemed to be that smaller indexes might be easier
> to keep in cache.
No. The argument is that if we don't have some such correction, the
planner is liable to believe that different-sized indexes have *exactly
the same cost*, if a given query would fetch the same number of index
entries. This is quite easy to demonstrate when experimenting with
partial indexes, in particular - without the fudge factor the planner
sees no advantage of a partial index over a full index from which the
query would fetch the same number of entries. We do want the planner
to pick the partial index if it's usable, and a fudge factor is about
the least unprincipled way to make it do so.
> The argument for increasing the penalty by a factor of 10 was that the
> smaller one could be "swamped by noise such as page-boundary-roundoff
> behavior".
Yeah, I wrote that, but in hindsight it seems like a mistaken idea.
The noise problem is that because we round off page count and row count
estimates to integers at various places, it's fairly easy for small
changes in statistics to move a plan's estimated cost by significantly
more than this fudge factor will. However, the case that the fudge
factor is meant to fix is indexes that are otherwise identical for
the query's purposes --- and any roundoff effects will be the same.
(The fudge factor itself is *not* rounded off anywhere, it flows
directly to the bottom-line cost for the indexscan.)
> One thing which depends on the index size which, as far as I can tell, is
> not currently being counted is the cost of comparing the tuples all the way
> down the index. This would be proportional to log2(indextuples) *
> cpu_index_tuple_cost, or maybe log2(indextuples) *
> (cpu_index_tuple_cost+cpu_operator_cost), or something like that.
Yeah, I know. I've experimented repeatedly over the years with trying
to account explicitly for index descent costs. But every time, anything
that looks even remotely principled turns out to produce an overly large
correction that results in bad plan choices. I don't know exactly why
this is, but it's true.
One other point is that I think it is better for any such correction
to depend on the index's total page count, not total tuple count,
because otherwise two indexes that are identical except for bloat
effects will appear to have identical costs. So from that standpoint,
the ln() form of the fudge factor seems quite reasonable as a crude form
of index descent cost estimate. The fact that we're needing to dial
it down so much reinforces my feeling that descent costs are close to
negligible in practice.
regards, tom lane
On Saturday, January 5, 2013, Tom Lane wrote:
Jeff Janes <jeff.janes@gmail.com> writes:
> [moved to hackers]
> On Wednesday, December 5, 2012, Tom Lane wrote:
>> Hm. To tell you the truth, in October I'd completely forgotten about
>> the January patch, and was thinking that the 1/10000 cost had a lot
>> of history behind it. But if we never shipped it before 9.2 then of
>> course that idea is false. Perhaps we should backpatch the log curve
>> into 9.2 --- that would reduce the amount of differential between what
>> 9.2 does and what previous branches do for large indexes.
> I think we should backpatch it for 9.2.3. I've seen another email which is
> probably due to the same issue (nested loop vs hash join). And some
> monitoring of a database I am responsible for suggests it might be heading
> in that direction as well as the size grows.
I received an off-list report of a case where not only did the 1/10000
factor cause a nestloop-vs-hashjoin decision to be made wrongly, but
even adding the ln() computation as in commit bf01e34b556 didn't fix it.
I believe the index in question was on the order of 20000 pages, so
it's not too hard to see why this might be the case:
* historical fudge factor 4 * 20000/100000 = 0.8
* 9.2 fudge factor 4 * 20000/10000 = 8.0
* with ln() correction 4 * ln(1 + 20000/10000) = 4.39 or so
At this point I'm about ready to not only revert the 100000-to-10000
change, but keep the ln() adjustment, ie make the calculation be
random_page_cost * ln(1 + index_pages/100000). This would give
essentially the pre-9.2 behavior for indexes up to some tens of
thousands of pages, and keep the fudge factor from getting out of
control even for very very large indexes.
Yeah, I agree that even the log function grows too rapidly, especially at the early stages. I didn't know if a change that changes that asymptote would be welcome in a backpatch, though.
> But I am wondering if it should be present at all in 9.3. When it was
> introduced, the argument seemed to be that smaller indexes might be easier
> to keep in cache.
No. The argument is that if we don't have some such correction, the
planner is liable to believe that different-sized indexes have *exactly
the same cost*, if a given query would fetch the same number of index
entries.
But it seems like they very likely *do* have exactly the same cost, unless you want to take either the CPU cost of descending the index into account, or take cachebility into account. If they do have the same cost, why shouldn't the estimate reflect that? Using cpu_index_tuple_cost * lg(# index tuples) would break the tie, but by such a small amount that it would easily get swamped by the stochastic nature of ANALYZE for nodes expected to return more than one row.
This is quite easy to demonstrate when experimenting with
partial indexes, in particular - without the fudge factor the planner
sees no advantage of a partial index over a full index from which the
query would fetch the same number of entries. We do want the planner
to pick the partial index if it's usable, and a fudge factor is about
the least unprincipled way to make it do so.
I noticed a long time ago that ordinary index scans seemed to be preferred over bitmap index scans with the same cost estimate, as best as I could determine because they are tested first and the tie goes to the first one (and there is something about it needs to be better by 1% to be counted as better--although that part might only apply when the start-up cost and the full cost disagree over which one is best). If I've reconstructed that correctly, could something similar be done for partial indexes, where they are just considered first? I guess the problem there is a index scan on a partial index is not a separate node type from a index scan on a full index, unlike index vs bitmap.
> The argument for increasing the penalty by a factor of 10 was that the
> smaller one could be "swamped by noise such as page-boundary-roundoff
> behavior".
Yeah, I wrote that, but in hindsight it seems like a mistaken idea.
The noise problem is that because we round off page count and row count
estimates to integers at various places, it's fairly easy for small
changes in statistics to move a plan's estimated cost by significantly
more than this fudge factor will. However, the case that the fudge
factor is meant to fix is indexes that are otherwise identical for
the query's purposes --- and any roundoff effects will be the same.
(The fudge factor itself is *not* rounded off anywhere, it flows
directly to the bottom-line cost for the indexscan.)
OK, and this agrees with my experience. It seemed like it was the stochastic nature of analyze, not round off problems, that caused the plans to go back and forth.
> One thing which depends on the index size which, as far as I can tell, is
> not currently being counted is the cost of comparing the tuples all the way
> down the index. This would be proportional to log2(indextuples) *
> cpu_index_tuple_cost, or maybe log2(indextuples) *
> (cpu_index_tuple_cost+cpu_operator_cost), or something like that.
Yeah, I know. I've experimented repeatedly over the years with trying
to account explicitly for index descent costs. But every time, anything
that looks even remotely principled turns out to produce an overly large
correction that results in bad plan choices. I don't know exactly why
this is, but it's true.
log2(indextuples) * cpu_index_tuple_cost should produce pretty darn small corrections, at least if cost parameters are at the defaults. Do you remember if that one of the ones you tried?
One other point is that I think it is better for any such correction
to depend on the index's total page count, not total tuple count,
because otherwise two indexes that are identical except for bloat
effects will appear to have identical costs.
This isn't so. A bloated index will be estimated to visit more pages than an otherwise identical non-bloated index, and so have a higher cost.
jeff=# create table bar as select * from generate_series(1,1000000);
jeff=# create index foo1 on bar (generate_series);
jeff=# create index foo2 on bar (generate_series);
jeff=# delete from bar where generate_series %100 !=0;
jeff=# reindex index foo1;
jeff=# analyze ;
jeff=# explain select count(*) from bar where generate_series between 6 and 60;
QUERY PLAN
--------------------------------------------------------------------------
Aggregate (cost=8.27..8.28 rows=1 width=0)
-> Index Scan using foo1 on bar (cost=0.00..8.27 rows=1 width=0)
Index Cond: ((generate_series >= 6) AND (generate_series <= 60))
(3 rows)
jeff=# begin; drop index foo1; explain select count(*) from bar where generate_series between 6 and 600; rollback;
QUERY PLAN
---------------------------------------------------------------------------
Aggregate (cost=14.47..14.48 rows=1 width=0)
-> Index Scan using foo2 on bar (cost=0.00..14.46 rows=5 width=0)
Index Cond: ((generate_series >= 6) AND (generate_series <= 600))
(3 rows)
This is due to this in genericcostestimate
if (index->pages > 1 && index->tuples > 1)
numIndexPages = ceil(numIndexTuples * index->pages / index->tuples);
If the index is bloated (or just has wider index tuples), index->pages will go up but index->tuples will not.
If it is just a partial index, however, then both will go down together and it will not be counted as a benefit from being smaller.
For the bloated index, this correction might even be too harsh. If the index is bloated by having lots of mostly-empty pages, then this seems fair. If it is bloated by having lots of entirely empty pages that are not even linked into the tree, then those empty ones will never be visited and so it shouldn't be penalized.
Worse, this over-punishment of bloat is more likely to penalize partial indexes. Since they are vacuumed on the table's schedule, not their own schedule, they likely get vacuumed less often relative to the amount of turn-over they experience and so have higher steady-state bloat. (I'm assuming the partial index is on the particularly hot rows, which I would expect is how partial indexes would generally be used)
This extra bloat was one of the reasons the partial index was avoided in "Why does the query planner use two full indexes, when a dedicated partial index exists?"
This extra bloat was one of the reasons the partial index was avoided in "Why does the query planner use two full indexes, when a dedicated partial index exists?"
So from that standpoint,
the ln() form of the fudge factor seems quite reasonable as a crude form
of index descent cost estimate. The fact that we're needing to dial
it down so much reinforces my feeling that descent costs are close to
negligible in practice.
If they are negligible, why do we really care that it use a partial index vs a full index? It seems like the only reason we would care is cacheability. Unfortunately we don't have any infrastructure to model that directly.
Cheers,
Jeff
Jeff Janes <jeff.janes@gmail.com> writes:
> On Saturday, January 5, 2013, Tom Lane wrote:
>> Jeff Janes <jeff.janes@gmail.com <javascript:;>> writes:
>>> One thing which depends on the index size which, as far as I can tell, is
>>> not currently being counted is the cost of comparing the tuples all the way
>>> down the index. This would be proportional to log2(indextuples) *
>>> cpu_index_tuple_cost, or maybe log2(indextuples) *
>>> (cpu_index_tuple_cost+cpu_operator_cost), or something like that.
>> Yeah, I know. I've experimented repeatedly over the years with trying
>> to account explicitly for index descent costs. But every time, anything
>> that looks even remotely principled turns out to produce an overly large
>> correction that results in bad plan choices. I don't know exactly why
>> this is, but it's true.
> log2(indextuples) * cpu_index_tuple_cost should produce pretty darn small
> corrections, at least if cost parameters are at the defaults. Do you
> remember if that one of the ones you tried?
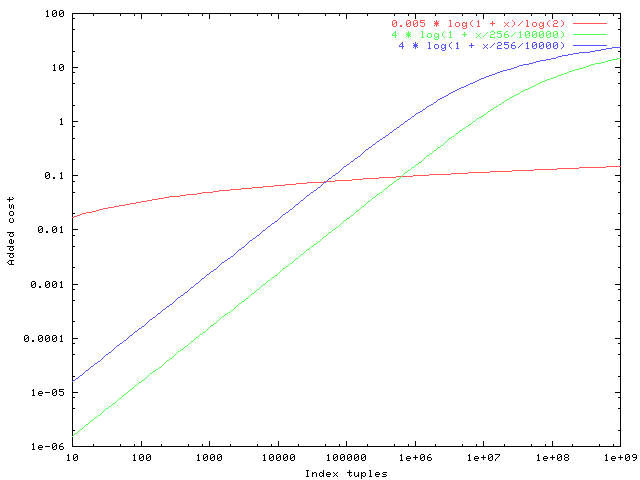
Well, a picture is worth a thousand words, so see the attached plot of
the various proposed corrections for indexes of 10 to 1e9 tuples. For
purposes of argument I've supposed that the index has loading factor
256 tuples/page, and I used the default values of random_page_cost and
cpu_index_tuple_cost. The red line is your proposal, the green one is
mine, the blue one is current HEAD behavior.
Both the blue and green lines get to values that might be thought
excessively high for very large indexes, but I doubt that that really
matters: if the table contains a billion rows, the cost of a seqscan
will be so high that it'll hardly matter if we overshoot the cost of an
index probe a bit. (Also, once the table gets that large it's debatable
whether the upper index levels all fit in cache, so charging an extra
random_page_cost or so isn't necessarily unrealistic.)
The real problem though is at the other end of the graph: I judge that
the red line represents an overcorrection for indexes of a few thousand
tuples.
It might also be worth noting that for indexes of a million or so
tuples, we're coming out to about the same place anyway.
>> One other point is that I think it is better for any such correction
>> to depend on the index's total page count, not total tuple count,
>> because otherwise two indexes that are identical except for bloat
>> effects will appear to have identical costs.
> This isn't so. A bloated index will be estimated to visit more pages than
> an otherwise identical non-bloated index, and so have a higher cost.
No it won't, or at least not reliably so, if there is no form of
correction for index descent costs. For instance, in a probe into a
unique index, we'll always estimate that we're visiting a single index
tuple on a single index page. The example you show is tweaked to ensure
that it estimates visiting more than one index page, and in that context
the leaf-page-related costs probably do scale with bloat; but they won't
if the query is only looking for one index entry.
> For the bloated index, this correction might even be too harsh. If the
> index is bloated by having lots of mostly-empty pages, then this seems
> fair. If it is bloated by having lots of entirely empty pages that are not
> even linked into the tree, then those empty ones will never be visited and
> so it shouldn't be penalized.
It's true that an un-linked empty page adds no cost by itself. But if
there are a lot of now-empty pages, that probably means a lot of vacant
space on upper index pages (which must once have held downlinks to those
pages). Which means more upper pages traversed to get to the target
leaf page than we'd have in a non-bloated index. Without more
experimental evidence than we've got at hand, I'm disinclined to suppose
that index bloat is free.
> This extra bloat was one of the reasons the partial index was avoided in
> "Why does the query planner use two full indexes, when a dedicated partial
> index exists?"
Interesting point, but it's far from clear that the planner was wrong in
supposing that that bloat had significant cost. We agree that the
current 9.2 correction is too large, but it doesn't follow that zero is
a better value.
>> So from that standpoint,
>> the ln() form of the fudge factor seems quite reasonable as a crude form
>> of index descent cost estimate. The fact that we're needing to dial
>> it down so much reinforces my feeling that descent costs are close to
>> negligible in practice.
> If they are negligible, why do we really care that it use a partial index
> vs a full index?
TBH, in situations like the ones I'm thinking about it's not clear that
a partial index is a win at all. The cases where a partial index really
wins are where it doesn't index rows that you would otherwise have to
visit and make a non-indexed predicate test against --- and those costs
we definitely do model. However, if the planner doesn't pick the
partial index if available, people are going to report that as a bug.
They won't be able to find out that they're wasting their time defining
a partial index if the planner won't pick it.
So, between the bloat issue and the partial-index issue, I think it's
important that there be some component of indexscan cost that varies
according to index size, even when the same number of leaf pages and
leaf index entries will be visited. It does not have to be a large
component; all experience to date says that it shouldn't be very large.
But there needs to be something.
regards, tom lane
Attachment
{kind=link}
On 5 January 2013 22:18, Tom Lane <tgl@sss.pgh.pa.us> wrote: >> But I am wondering if it should be present at all in 9.3. When it was >> introduced, the argument seemed to be that smaller indexes might be easier >> to keep in cache. > > No. The argument is that if we don't have some such correction, the > planner is liable to believe that different-sized indexes have *exactly > the same cost*, if a given query would fetch the same number of index > entries. The only difference between a large and a small index is the initial fetch, since the depth of the index may vary. After that the size of the index is irrelevant to the cost of the scan, since we're just scanning across the leaf blocks. (Other differences may exist but not related to size). Perhaps the cost of the initial fetch is what you mean by a "correction"? In that case, why not use the index depth directly from the metapage, rather than play with size? -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
On 6 January 2013 16:29, Jeff Janes <jeff.janes@gmail.com> wrote: > Worse, this over-punishment of bloat is more likely to penalize partial > indexes. Since they are vacuumed on the table's schedule, not their own > schedule, they likely get vacuumed less often relative to the amount of > turn-over they experience and so have higher steady-state bloat. (I'm > assuming the partial index is on the particularly hot rows, which I would > expect is how partial indexes would generally be used) That's an interesting thought. Thanks for noticing that. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> writes:
> On 5 January 2013 22:18, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> No. The argument is that if we don't have some such correction, the
>> planner is liable to believe that different-sized indexes have *exactly
>> the same cost*, if a given query would fetch the same number of index
>> entries.
> The only difference between a large and a small index is the initial
> fetch, since the depth of the index may vary. After that the size of
> the index is irrelevant to the cost of the scan, since we're just
> scanning across the leaf blocks. (Other differences may exist but not
> related to size).
Right: except for the "fudge factor" under discussion, all the indexscan
costs that we model come from accessing index leaf pages and leaf
tuples. So to the extent that the fudge factor has any principled basis
at all, it's an estimate of index descent costs. And in that role I
believe that total index size needs to be taken into account.
> Perhaps the cost of the initial fetch is what you mean by a
> "correction"? In that case, why not use the index depth directly from
> the metapage, rather than play with size?
IIRC, one of my very first attempts to deal with this was to charge
random_page_cost per level of index descended. This was such a horrid
overestimate that it never went anywhere. I think that reflects that in
practical applications, the upper levels of the index tend to stay in
cache. We could ignore I/O on that assumption and still try to model
CPU costs of the descent, which is basically what Jeff is proposing.
My objection to his formula is mainly that it ignores physical index
size, which I think is important to include somehow for the reasons
I explained in my other message.
regards, tom lane
On 6 January 2013 18:58, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Simon Riggs <simon@2ndQuadrant.com> writes: >> On 5 January 2013 22:18, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> No. The argument is that if we don't have some such correction, the >>> planner is liable to believe that different-sized indexes have *exactly >>> the same cost*, if a given query would fetch the same number of index >>> entries. > >> The only difference between a large and a small index is the initial >> fetch, since the depth of the index may vary. After that the size of >> the index is irrelevant to the cost of the scan, since we're just >> scanning across the leaf blocks. (Other differences may exist but not >> related to size). > > Right: except for the "fudge factor" under discussion, all the indexscan > costs that we model come from accessing index leaf pages and leaf > tuples. So to the extent that the fudge factor has any principled basis > at all, it's an estimate of index descent costs. And in that role I > believe that total index size needs to be taken into account. > >> Perhaps the cost of the initial fetch is what you mean by a >> "correction"? In that case, why not use the index depth directly from >> the metapage, rather than play with size? > > IIRC, one of my very first attempts to deal with this was to charge > random_page_cost per level of index descended. This was such a horrid > overestimate that it never went anywhere. I think that reflects that in > practical applications, the upper levels of the index tend to stay in > cache. We could ignore I/O on that assumption and still try to model > CPU costs of the descent, which is basically what Jeff is proposing. > My objection to his formula is mainly that it ignores physical index > size, which I think is important to include somehow for the reasons > I explained in my other message. Having a well principled approach will help bring us towards a realistic estimate. I can well believe what you say about random_page_cost * index_depth being an over-estimate. Making a fudge factor be random_page_cost * ln(1 + index_pages/100000)just seems to presume an effective cache of 8GB anda fixed depth:size ratio, which it might not be. On a busy system, or with a very wide index that could also be wrong. I'd be more inclined to explicitly discount the first few levels by using random_page_cost * (max(index_depth - 3, 0)) or even better use a formula that includes the effective cache size and index width to work out the likely number of tree levels cached for an index. Whatever we do we must document that we are estimating the cache effects on the cost of index descent, so we can pick that up on a future study on cacheing effects. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> writes:
> On 6 January 2013 18:58, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> IIRC, one of my very first attempts to deal with this was to charge
>> random_page_cost per level of index descended. This was such a horrid
>> overestimate that it never went anywhere. I think that reflects that in
>> practical applications, the upper levels of the index tend to stay in
>> cache. We could ignore I/O on that assumption and still try to model
>> CPU costs of the descent, which is basically what Jeff is proposing.
>> My objection to his formula is mainly that it ignores physical index
>> size, which I think is important to include somehow for the reasons
>> I explained in my other message.
> Having a well principled approach will help bring us towards a
> realistic estimate.
I thought about this some more and came up with what might be a
reasonably principled compromise. Assume that we know there are N
leaf entries in the index (from VACUUM stats) and that we know the
root page height is H (from looking at the btree metapage). (Note:
H starts at zero for a single-page index.) If we assume that the
number of tuples per page, P, is more or less uniform across leaf
and upper pages (ie P is the fanout for upper pages), then we have
N/P = number of leaf pages
N/P/P = number of level 1 pages
N/P^3 = number of level 2 pages
N/P^(h+1) = number of level h pages
Solving for the minimum P that makes N/P^(H+1) <= 1, we get
P = ceil(exp(ln(N)/(H+1)))
as an estimate of P given the known N and H values.
Now, if we consider only CPU costs of index descent, we expect
about log2(P) comparisons to be needed on each of the H upper pages
to be descended through, that is we have total descent cost
cpu_index_tuple_cost * H * log2(P)
If we ignore the ceil() step as being a second-order correction, this
can be simplified to
cpu_index_tuple_cost * H * log2(N)/(H+1)
I propose this, rather than Jeff's formula of cpu_index_tuple_cost *
log2(N), as our fudge factor. The reason I like this better is that
the additional factor of H/(H+1) provides the correction I want for
bloated indexes: if an index is bloated, the way that reflects into
the cost of any particular search is that the number of pages to be
descended through is larger than otherwise. The correction is fairly
small, particularly for large indexes, but that seems to be what's
expected given the rest of our discussion.
We could further extend this by adding some I/O charge when the index is
sufficiently large, as per Simon's comments, but frankly I think that's
unnecessary. Unless the fan-out factor is really awful, practical-sized
indexes probably have all their upper pages in memory. What's more, per
my earlier comment, when you start to think about tables so huge that
that's not true it really doesn't matter if we charge another
random_page_cost or two for an indexscan --- it'll still be peanuts
compared to the seqscan alternative.
To illustrate the behavior of this function, I've replotted my previous
graph, still taking the assumed fanout to be 256 tuples/page. I limited
the range of the functions to 0.0001 to 100 to keep the log-scale graph
readable, but actually the H/(H+1) formulation would charge zero for
indexes of less than 256 tuples. I think it's significant (and a good
thing) that this curve is nowhere significantly more than the historical
pre-9.2 fudge factor.
Thoughts?
regards, tom lane
set terminal png small color
set output 'new_fudge.png'
set logscale x
set logscale y
h(x) = (x <= 256) ? 0.0001/0.005 : (x <= 256*256) ? (1./2)*log(x)/log(2) : (x <= 256^3) ? (2./3)*log(x)/log(2) : (x <=
256^4)? (3./4)*log(x)/log(2) : (x <= 256^5) ? (4./5)*log(x)/log(2) : (5./6)*log(x)/log(2)
historical(x) = (4 * x/100000) < 100 ? 4 * x/100000 : 1/0
ninepoint2(x) = (4 * x/10000) < 100 ? 4 * x/10000 : 1/0
head(x) = 4*log(1 + x/10000)
plot [10:1e9] h(x)*0.005, 0.005 * log(x)/log(2), head(x), historical(x), ninepoint2(x)
Attachment
{kind=link}
I wrote:
> [ slightly bogus graph ]
Ooops, it seems the ^ operator doesn't do what I thought in gnuplot.
Here's a corrected version.
regards, tom lane
set terminal png small color
set output 'new_fudge.png'
set xlabel "Index tuples"
set ylabel "Added cost"
set logscale x
set logscale y
h(x) = (x <= 256) ? 0.0001/0.005 : (x <= 256*256) ? (1./2)*log(x)/log(2) : (x <= 256*256*256) ? (2./3)*log(x)/log(2) :
(x<= 256.0*256*256*256) ? (3./4)*log(x)/log(2) : (x <= 256.0*256*256*256*256) ? (4./5)*log(x)/log(2) :
(5./6)*log(x)/log(2)
historical(x) = (4 * x/100000) < 100 ? 4 * x/100000 : 1/0
ninepoint2(x) = (4 * x/10000) < 100 ? 4 * x/10000 : 1/0
head(x) = 4*log(1 + x/10000)
plot [10:1e9] h(x)*0.005, 0.005 * log(x)/log(2), head(x), historical(x), ninepoint2(x)
Attachment
{kind=link}
On 6 January 2013 23:03, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Simon Riggs <simon@2ndQuadrant.com> writes: >> On 6 January 2013 18:58, Tom Lane <tgl@sss.pgh.pa.us> wrote: >>> IIRC, one of my very first attempts to deal with this was to charge >>> random_page_cost per level of index descended. This was such a horrid >>> overestimate that it never went anywhere. I think that reflects that in >>> practical applications, the upper levels of the index tend to stay in >>> cache. We could ignore I/O on that assumption and still try to model >>> CPU costs of the descent, which is basically what Jeff is proposing. >>> My objection to his formula is mainly that it ignores physical index >>> size, which I think is important to include somehow for the reasons >>> I explained in my other message. > >> Having a well principled approach will help bring us towards a >> realistic estimate. > > I thought about this some more and came up with what might be a > reasonably principled compromise. Assume that we know there are N > leaf entries in the index (from VACUUM stats) and that we know the > root page height is H (from looking at the btree metapage). (Note: > H starts at zero for a single-page index.) If we assume that the > number of tuples per page, P, is more or less uniform across leaf > and upper pages (ie P is the fanout for upper pages), then we have > N/P = number of leaf pages > N/P/P = number of level 1 pages > N/P^3 = number of level 2 pages > N/P^(h+1) = number of level h pages > Solving for the minimum P that makes N/P^(H+1) <= 1, we get > P = ceil(exp(ln(N)/(H+1))) > as an estimate of P given the known N and H values. > > Now, if we consider only CPU costs of index descent, we expect > about log2(P) comparisons to be needed on each of the H upper pages > to be descended through, that is we have total descent cost > cpu_index_tuple_cost * H * log2(P) > > If we ignore the ceil() step as being a second-order correction, this > can be simplified to > > cpu_index_tuple_cost * H * log2(N)/(H+1) > > I propose this, rather than Jeff's formula of cpu_index_tuple_cost * > log2(N), as our fudge factor. The reason I like this better is that > the additional factor of H/(H+1) provides the correction I want for > bloated indexes: if an index is bloated, the way that reflects into > the cost of any particular search is that the number of pages to be > descended through is larger than otherwise. The correction is fairly > small, particularly for large indexes, but that seems to be what's > expected given the rest of our discussion. Seems good to have something with both N and H in it. This cost model favours smaller indexes over larger ones, whether that be because they're partial and so have smaller N, or whether the key values are thinner and so have lower H. > We could further extend this by adding some I/O charge when the index is > sufficiently large, as per Simon's comments, but frankly I think that's > unnecessary. Unless the fan-out factor is really awful, practical-sized > indexes probably have all their upper pages in memory. What's more, per > my earlier comment, when you start to think about tables so huge that > that's not true it really doesn't matter if we charge another > random_page_cost or two for an indexscan --- it'll still be peanuts > compared to the seqscan alternative. Considering that we're trying to decide between various indexes on one table, we don't have enough information to say which index the cache favours and the other aspects of cacheing are the same for all indexes of any given size. So we can assume those effects cancel out for comparison purposes, even if they're non-zero. And as you say, they're negligible in comparison with bitmapindexscans etc.. The only time I'd question that would be in the case of a nested loops join but that's not important here. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
I wrote:
> Now, if we consider only CPU costs of index descent, we expect
> about log2(P) comparisons to be needed on each of the H upper pages
> to be descended through, that is we have total descent cost
> cpu_index_tuple_cost * H * log2(P)
> If we ignore the ceil() step as being a second-order correction, this
> can be simplified to
> cpu_index_tuple_cost * H * log2(N)/(H+1)
I thought some more about this and concluded that the above reasoning is
incorrect, because it ignores the fact that initial positioning on the
index leaf page requires another log2(P) comparisons (to locate the
first matching tuple if any). If you include those comparisons then the
H/(H+1) factor drops out and you are left with just "cost * log2(N)",
independently of the tree height.
But all is not lost for including some representation of the physical
index size into this calculation, because it seems plausible to consider
that there is some per-page cost for descending through the upper pages.
It's not nearly as much as random_page_cost, if the pages are cached,
but we don't have to suppose it's zero. So that reasoning leads to a
formula like
cost-per-tuple * log2(N) + cost-per-page * (H+1)
which is better than the above proposal anyway because we can now
twiddle the two cost factors separately rather than being tied to a
fixed idea of how much a larger H hurts.
As for the specific costs to use, I'm now thinking that the
cost-per-tuple should be just cpu_operator_cost (0.0025) not
cpu_index_tuple_cost (0.005). The latter is meant to model costs such
as reporting a TID back out of the index AM to the executor, which is
not what we're doing at an upper index entry. I also propose setting
the per-page cost to some multiple of cpu_operator_cost, since it's
meant to represent a CPU cost not an I/O cost.
There is already a charge of 100 times cpu_operator_cost in
genericcostestimate to model "general costs of starting an indexscan".
I suggest that we should consider half of that to be actual fixed
overhead and half of it to be per-page cost for the first page, then
add another 50 times cpu_operator_cost for each page descended through.
That gives a formula of
cpu_operator_cost * log2(N) + cpu_operator_cost * 50 * (H+2)
This would lead to the behavior depicted in the attached plot, wherein
I've modified the comparison lines (historical, 9.2, and HEAD behaviors)
to include the existing 100 * cpu_operator_cost startup cost charge in
addition to the fudge factor we've been discussing so far. The new
proposed curve is a bit above the historical curve for indexes with
250-5000 tuples, but the value is still quite small there, so I'm not
too worried about that. The people who've been complaining about 9.2's
behavior have indexes much larger than that.
Thoughts?
regards, tom lane
set terminal png small color
set output 'new_costs.png'
set xlabel "Index tuples"
set ylabel "Added cost"
set logscale x
set logscale y
h(x) = (x <= 256.0) ? 0 : (x <= 256.0*256) ? 1 : (x <= 256.0*256*256) ? 2 : (x <= 256.0*256*256*256) ? 3 : (x <=
256.0*256*256*256*256)? 4 : 5
head(x) = 4*log(1 + x/10000) + 0.25
historical(x) = 4 * x/100000 + 0.25
ninepoint2(x) = 4 * x/10000 + 0.25
plot [10:1e9][0.1:10] 0.0025*log(x)/log(2) + 0.125*(h(x)+2), head(x), historical(x), ninepoint2(x)
Attachment
{kind=link}
On 7 January 2013 17:35, Tom Lane <tgl@sss.pgh.pa.us> wrote: > That gives a formula of > > cpu_operator_cost * log2(N) + cpu_operator_cost * 50 * (H+2) > > This would lead to the behavior depicted in the attached plot, wherein > I've modified the comparison lines (historical, 9.2, and HEAD behaviors) > to include the existing 100 * cpu_operator_cost startup cost charge in > addition to the fudge factor we've been discussing so far. The new > proposed curve is a bit above the historical curve for indexes with > 250-5000 tuples, but the value is still quite small there, so I'm not > too worried about that. The people who've been complaining about 9.2's > behavior have indexes much larger than that. > > Thoughts? Again, this depends on N and H, so thats good. I think my retinas detached while reading your explanation, but I'm a long way from coming up with a better or more principled one. If we can describe this as a heuristic that appears to fit the observed costs, we may keep the door open for something better a little later. -- Simon Riggs http://www.2ndQuadrant.com/PostgreSQL Development, 24x7 Support, Training & Services
Simon Riggs <simon@2ndQuadrant.com> writes:
> On 7 January 2013 17:35, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> That gives a formula of
>> cpu_operator_cost * log2(N) + cpu_operator_cost * 50 * (H+2)
> Again, this depends on N and H, so thats good.
> I think my retinas detached while reading your explanation, but I'm a
> long way from coming up with a better or more principled one.
> If we can describe this as a heuristic that appears to fit the
> observed costs, we may keep the door open for something better a
> little later.
I'm fairly happy with the general shape of this formula: it has a
principled explanation and the resulting numbers appear to be sane.
The specific cost multipliers obviously are open to improvement based
on future evidence. (In particular, I intend to code it in a way that
doesn't tie the "startup overhead" and "cost per page" numbers to be
equal, even though I'm setting them equal for the moment for lack of a
better idea.)
One issue that needs some thought is that the argument for this formula
is based entirely on thinking about b-trees. I think it's probably
reasonable to apply it to gist, gin, and sp-gist as well, assuming we
can get some estimate of tree height for those, but it's obviously
hogwash for hash indexes. We could possibly just take H=0 for hash,
and still apply the log2(N) part ... not so much because that is right
as because it's likely too small to matter.
regards, tom lane
On Mon, Jan 7, 2013 at 3:27 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > > One issue that needs some thought is that the argument for this formula > is based entirely on thinking about b-trees. I think it's probably > reasonable to apply it to gist, gin, and sp-gist as well, assuming we > can get some estimate of tree height for those, but it's obviously > hogwash for hash indexes. We could possibly just take H=0 for hash, > and still apply the log2(N) part ... not so much because that is right > as because it's likely too small to matter. Height would be more precisely "lookup cost" (in comparisons). Most indexing structures have a well-studied lookup cost. For b-trees, it's log_b(size), for hash it's 1 + size/buckets.
I wrote:
> I'm fairly happy with the general shape of this formula: it has a
> principled explanation and the resulting numbers appear to be sane.
> The specific cost multipliers obviously are open to improvement based
> on future evidence. (In particular, I intend to code it in a way that
> doesn't tie the "startup overhead" and "cost per page" numbers to be
> equal, even though I'm setting them equal for the moment for lack of a
> better idea.)
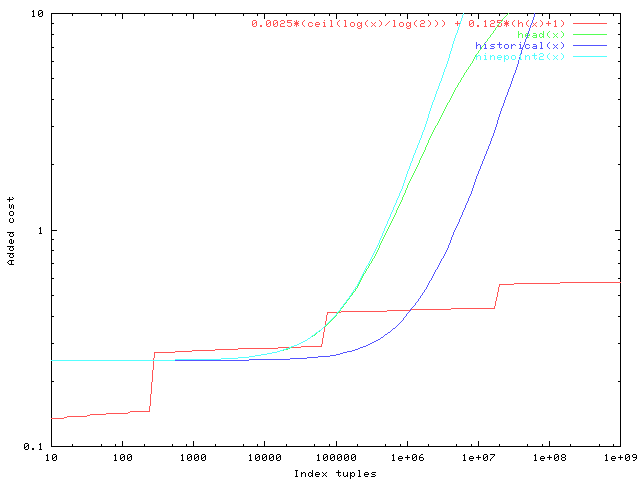
I realized that there was a rather serious error in the graphs I showed
before: they were computing the old cost models as #tuples/10000 or
#tuples/100000, but really it's #pages. So naturally that moves those
curves down quite a lot. After some playing around I concluded that the
best way to avoid any major increases in the attributed cost is to drop
the constant "costs of indexscan setup" charge that I proposed before.
(That was a little weird anyway since we don't model any similar cost
for any other sort of executor setup.) The attached graph shows the
corrected old cost curves and the proposed new one.
> One issue that needs some thought is that the argument for this formula
> is based entirely on thinking about b-trees. I think it's probably
> reasonable to apply it to gist, gin, and sp-gist as well, assuming we
> can get some estimate of tree height for those, but it's obviously
> hogwash for hash indexes. We could possibly just take H=0 for hash,
> and still apply the log2(N) part ... not so much because that is right
> as because it's likely too small to matter.
In the attached patch, I use the proposed formula for btree, gist, and
spgist indexes. For btree we read out the actual tree height from the
metapage and use that. For gist and spgist there's not a uniquely
determinable tree height, but I propose taking log100(#pages) as a
first-order estimate. For hash, I think we actually don't need any
corrections, for the reasons set out in the comment added to
hashcostestimate. I left the estimate for GIN alone; I've not studied
it enough to know whether it ought to be fooled with, but in any case it
behaves very little like btree.
A big chunk of the patch diff comes from redesigning the API of
genericcostestimate so that it can cheaply pass back some additional
values, so we don't have to recompute those values at the callers.
Other than that and the new code to let btree report out its tree
height, this isn't a large patch. It basically gets rid of the two
ad-hoc calculations in genericcostestimate() and inserts substitute
calculations in the per-index-type functions.
I've verified that this patch results in no changes in the regression
tests. It's worth noting though that there is now a small nonzero
startup-cost charge for indexscans, for example:
regression=# explain select * from tenk1 where unique1 = 42;
QUERY PLAN
-----------------------------------------------------------------------------
Index Scan using tenk1_unique1 on tenk1 (cost=0.29..8.30 rows=1 width=244)
Index Cond: (unique1 = 42)
(2 rows)
where in 9.2 the cost estimate was 0.00..8.28. I personally think this
is a good idea, but we'll have to keep our eyes open to see if it
changes any plans in ways we don't like.
This is of course much too large a change to consider back-patching.
What I now recommend we do about 9.2 is just revert it to the historical
fudge factor (#pages/100000).
Comments?
regards, tom lane
set terminal png small color
set output 'newer_costs.png'
set xlabel "Index tuples"
set ylabel "Added cost"
set logscale x
set logscale y
fo = 256.0
h(x) = (x <= fo) ? 0 : (x <= fo*fo) ? 1 : (x <= fo*fo*fo) ? 2 : (x <= fo*fo*fo*fo) ? 3 : (x <= fo*fo*fo*fo*fo) ? 4 : 5
head(x) = 4*log(1 + (x/fo)/10000) + 0.25
historical(x) = 4 * (x/fo)/100000 + 0.25
ninepoint2(x) = 4 * (x/fo)/10000 + 0.25
plot [10:1e9][0.1:10] 0.0025*(ceil(log(x)/log(2))) + 0.125*(h(x)+1), head(x), historical(x), ninepoint2(x)
Attachment
{kind=link}
On Thu, Jan 10, 2013 at 8:07 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Comments? I'm not sure I have anything intelligent to add to this conversation - does that make me the wisest of all the Greeks? - but I do think it worth mentioning that I have heard occasional reports within EDB of the query planner refusing to use extremely large indexes no matter how large a hammer was applied. I have never been able to obtain enough details to understand the parameters of the problem, let alone reproduce it, but I thought it might be worth mentioning anyway in case it's both real and related to the case at hand. Basically I guess that boils down to: it would be good to consider whether the costing model is correct for an index of, say, 1TB. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes: > I'm not sure I have anything intelligent to add to this conversation - > does that make me the wisest of all the Greeks? - but I do think it > worth mentioning that I have heard occasional reports within EDB of > the query planner refusing to use extremely large indexes no matter > how large a hammer was applied. I have never been able to obtain > enough details to understand the parameters of the problem, let alone > reproduce it, but I thought it might be worth mentioning anyway in > case it's both real and related to the case at hand. Basically I > guess that boils down to: it would be good to consider whether the > costing model is correct for an index of, say, 1TB. Well, see the cost curves at http://www.postgresql.org/message-id/13967.1357866454@sss.pgh.pa.us The old code definitely had an unreasonably large charge for indexes exceeding 1e8 or so tuples. This wouldn't matter that much for simple single-table lookup queries, but I could easily see it putting the kibosh on uses of an index on the inside of a nestloop. It's possible that the new code goes too far in the other direction: we're now effectively assuming that all inner btree pages stay in cache no matter how large the index is. At some point it'd likely be appropriate to start throwing in some random_page_cost charges for inner pages beyond the third/fourth/fifth(?) level, as Simon speculated about upthread. But I thought we could let that go until we start seeing complaints traceable to it. regards, tom lane
On Mon, Jan 14, 2013 at 12:23 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Robert Haas <robertmhaas@gmail.com> writes: >> I'm not sure I have anything intelligent to add to this conversation - >> does that make me the wisest of all the Greeks? - but I do think it >> worth mentioning that I have heard occasional reports within EDB of >> the query planner refusing to use extremely large indexes no matter >> how large a hammer was applied. I have never been able to obtain >> enough details to understand the parameters of the problem, let alone >> reproduce it, but I thought it might be worth mentioning anyway in >> case it's both real and related to the case at hand. Basically I >> guess that boils down to: it would be good to consider whether the >> costing model is correct for an index of, say, 1TB. > > Well, see the cost curves at > http://www.postgresql.org/message-id/13967.1357866454@sss.pgh.pa.us > > The old code definitely had an unreasonably large charge for indexes > exceeding 1e8 or so tuples. This wouldn't matter that much for simple > single-table lookup queries, but I could easily see it putting the > kibosh on uses of an index on the inside of a nestloop. The reported behavior was that the planner would prefer to sequential-scan the table rather than use the index, even if enable_seqscan=off. I'm not sure what the query looked like, but it could have been something best implemented as a nested loop w/inner index-scan. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert Haas <robertmhaas@gmail.com> writes:
> On Mon, Jan 14, 2013 at 12:23 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>> The old code definitely had an unreasonably large charge for indexes
>> exceeding 1e8 or so tuples. This wouldn't matter that much for simple
>> single-table lookup queries, but I could easily see it putting the
>> kibosh on uses of an index on the inside of a nestloop.
> The reported behavior was that the planner would prefer to
> sequential-scan the table rather than use the index, even if
> enable_seqscan=off. I'm not sure what the query looked like, but it
> could have been something best implemented as a nested loop w/inner
> index-scan.
Remember also that "enable_seqscan=off" merely adds 1e10 to the
estimated cost of seqscans. For sufficiently large tables this is not
exactly a hard disable, just a thumb on the scales. But I don't know
what your definition of "extremely large indexes" is.
regards, tom lane
On Mon, Jan 14, 2013 at 12:56:37PM -0500, Tom Lane wrote: > > The reported behavior was that the planner would prefer to > > sequential-scan the table rather than use the index, even if > > enable_seqscan=off. I'm not sure what the query looked like, but it > > could have been something best implemented as a nested loop w/inner > > index-scan. > > Remember also that "enable_seqscan=off" merely adds 1e10 to the > estimated cost of seqscans. For sufficiently large tables this is not > exactly a hard disable, just a thumb on the scales. But I don't know > what your definition of "extremely large indexes" is. Wow, do we need to bump up that value based on larger modern hardware? -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://enterprisedb.com + It's impossible for everything to be true. +
Bruce Momjian <bruce@momjian.us> writes:
> On Mon, Jan 14, 2013 at 12:56:37PM -0500, Tom Lane wrote:
>> Remember also that "enable_seqscan=off" merely adds 1e10 to the
>> estimated cost of seqscans. For sufficiently large tables this is not
>> exactly a hard disable, just a thumb on the scales. But I don't know
>> what your definition of "extremely large indexes" is.
> Wow, do we need to bump up that value based on larger modern hardware?
I'm disinclined to bump it up very much. If it's more than about 1e16,
ordinary cost contributions would disappear into float8 roundoff error,
causing the planner to be making choices that are utterly random except
for minimizing the number of seqscans. Even at 1e14 or so you'd be
losing a lot of finer-grain distinctions. What we want is for the
behavior to be "minimize the number of seqscans but plan normally
otherwise", so those other cost contributions are still important.
Anyway, at this point we're merely speculating about what's behind
Robert's report --- I'd want to see some concrete real-world examples
before changing anything.
regards, tom lane