Thread: new group commit behavior not helping?
Hoping to demonstrate the wonders of our new group commit code, I ran some benchmarks on the IBM POWER7 machine with synchronous_commit = on. But, it didn't come out much better than 9.1. pgbench, scale factor 300, median of 3 30-minute test runs, # clients = #threads, shared_buffers = 8GB, maintenance_work_mem = 1GB, synchronous_commit = on, checkpoint_segments = 300, checkpoint_timeout = 15min, checkpoint_completion_target = 0.9, wal_writer_delay = 20ms. By number of clients: master: 01 tps = 118.968446 (including connections establishing) 02 tps = 120.666865 (including connections establishing) 04 tps = 209.624437 (including connections establishing) 08 tps = 377.387029 (including connections establishing) 16 tps = 695.172899 (including connections establishing) 32 tps = 1318.468375 (including connections establishing) REL9_1_STABLE: 01 tps = 117.037056 (including connections establishing) 02 tps = 119.393871 (including connections establishing) 04 tps = 205.958750 (including connections establishing) 08 tps = 365.464735 (including connections establishing) 16 tps = 673.379394 (including connections establishing) 32 tps = 1101.324865 (including connections establishing) Is this expected behavior? Is this not the case where it's supposed to help? I thought Peter G. posted results showing a huge improvement on this kind of workload, and I thought Heikki reproduced them on a different server, so I'm confused why I can't. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 1 April 2012 01:10, Robert Haas <robertmhaas@gmail.com> wrote: > Hoping to demonstrate the wonders of our new group commit code, I ran > some benchmarks on the IBM POWER7 machine with synchronous_commit = > on. But, it didn't come out much better than 9.1. pgbench, scale > factor 300, median of 3 30-minute test runs, # clients = #threads, > shared_buffers = 8GB, maintenance_work_mem = 1GB, synchronous_commit = > on, checkpoint_segments = 300, checkpoint_timeout = 15min, > checkpoint_completion_target = 0.9, wal_writer_delay = 20ms. Why the low value for wal_writer_delay? > master: > 01 tps = 118.968446 (including connections establishing) > 02 tps = 120.666865 (including connections establishing) > 04 tps = 209.624437 (including connections establishing) > 08 tps = 377.387029 (including connections establishing) > 16 tps = 695.172899 (including connections establishing) > 32 tps = 1318.468375 (including connections establishing) > > REL9_1_STABLE: > 01 tps = 117.037056 (including connections establishing) > 02 tps = 119.393871 (including connections establishing) > 04 tps = 205.958750 (including connections establishing) > 08 tps = 365.464735 (including connections establishing) > 16 tps = 673.379394 (including connections establishing) > 32 tps = 1101.324865 (including connections establishing) (presumably s/tps/clients/ was intended here) > Is this expected behavior? Is this not the case where it's supposed > to help? I thought Peter G. posted results showing a huge improvement > on this kind of workload, and I thought Heikki reproduced them on a > different server, so I'm confused why I can't. The exact benchmark that I ran was the update.sql pgbench-tools benchmark, on my laptop. The idea was to produce a sympathetic benchmark with a workload that was maximally commit-bound. Heikki reproduced similar numbers on his laptop, iirc. Presumably the default TPC-B-like transaction test has been used here. You didn't mention what kind of disks this server has - I'm not sure if that information is available elsewhere. That could be highly pertinent. -- Peter Geoghegan http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training and Services
On Sat, Mar 31, 2012 at 8:31 PM, Peter Geoghegan <peter@2ndquadrant.com> wrote: > Why the low value for wal_writer_delay? A while back I was getting a benefit from cranking that down. I could try leaving it out and see if it matters. >> master: >> 01 tps = 118.968446 (including connections establishing) >> 02 tps = 120.666865 (including connections establishing) >> 04 tps = 209.624437 (including connections establishing) >> 08 tps = 377.387029 (including connections establishing) >> 16 tps = 695.172899 (including connections establishing) >> 32 tps = 1318.468375 (including connections establishing) >> >> REL9_1_STABLE: >> 01 tps = 117.037056 (including connections establishing) >> 02 tps = 119.393871 (including connections establishing) >> 04 tps = 205.958750 (including connections establishing) >> 08 tps = 365.464735 (including connections establishing) >> 16 tps = 673.379394 (including connections establishing) >> 32 tps = 1101.324865 (including connections establishing) > > (presumably s/tps/clients/ was intended here) The number at the beginning of each line is the number of clients. Everything after the first space is the output of pgbench for the median of three runs with that number of clients. >> Is this expected behavior? Is this not the case where it's supposed >> to help? I thought Peter G. posted results showing a huge improvement >> on this kind of workload, and I thought Heikki reproduced them on a >> different server, so I'm confused why I can't. > > The exact benchmark that I ran was the update.sql pgbench-tools > benchmark, on my laptop. The idea was to produce a sympathetic > benchmark with a workload that was maximally commit-bound. Heikki > reproduced similar numbers on his laptop, iirc. Presumably the default > TPC-B-like transaction test has been used here. Yes. > You didn't mention what kind of disks this server has - I'm not sure > if that information is available elsewhere. That could be highly > pertinent. I'm a little fuzzy on that, but I think it's a collection of 600GB 10K RPM SAS SFF disk drives with LVM sitting on top. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
<br /><br />On Saturday, March 31, 2012, Robert Haas <<a href="mailto:robertmhaas@gmail.com">robertmhaas@gmail.com</a>>wrote:<br />> Hoping to demonstrate the wonders of ournew group commit code, I ran<br />> some benchmarks on the IBM POWER7 machine with synchronous_commit =<br /> >on. But, it didn't come out much better than 9.1. <br /><br />Where I would expect (and have seen) much improvementis where #clients >> #CPU. Or "cores", whatever the term of art is.<br /><br />Of course I've mostly seenthis where CPU=1<br /><br />It looks like in your case tps was still scaling with clients when you gave up, so clientswas probably too small.<br /><br />Jeff
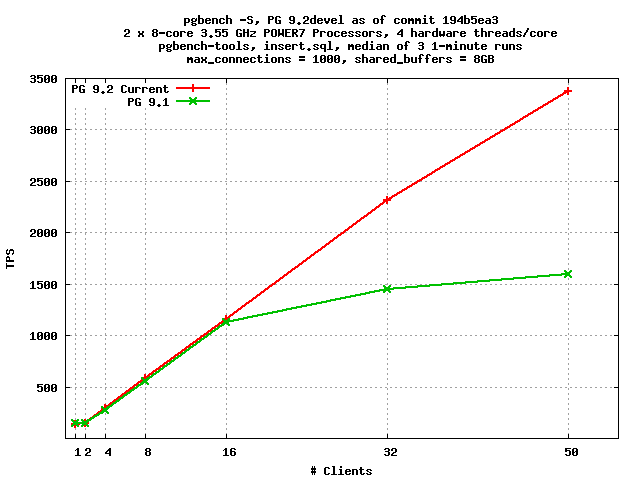
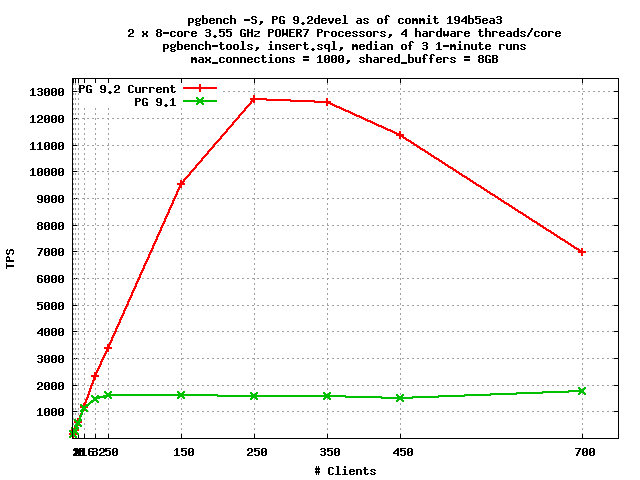
On Sat, Mar 31, 2012 at 8:31 PM, Peter Geoghegan <peter@2ndquadrant.com> wrote: > The exact benchmark that I ran was the update.sql pgbench-tools > benchmark, on my laptop. The idea was to produce a sympathetic > benchmark with a workload that was maximally commit-bound. Heikki > reproduced similar numbers on his laptop, iirc. Presumably the default > TPC-B-like transaction test has been used here. OK, I ran pgbench-tools with your configuration file. Graphs attached. Configuration otherwise as in my standard pgbench runs, except max_connections=1000 to accommodate the needs of the test. I now see the roughly order-of-magnitude increase you measured earlier. There seem to be too relevant differences between your test and mine: (1) your test is just a single insert per transaction, whereas mine is pgbench's usual update, select, update, update, insert and (2) it seems that, to really see the benefit of this patch, you need to pound the server with a very large number of clients. On this test, 250 clients was the sweet spot. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
{kind=link}
{kind=link}
On Sun, Apr 1, 2012 at 1:40 AM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Saturday, March 31, 2012, Robert Haas <robertmhaas@gmail.com> wrote: >> Hoping to demonstrate the wonders of our new group commit code, I ran >> some benchmarks on the IBM POWER7 machine with synchronous_commit = >> on. But, it didn't come out much better than 9.1. > > Where I would expect (and have seen) much improvement is where #clients >> > #CPU. Or "cores", whatever the term of art is. It seems you are right; see the email I just sent. > Of course I've mostly seen this where CPU=1 > > It looks like in your case tps was still scaling with clients when you gave > up, so clients was probably too small. What is kind of weird is that it actually seems to scale at almost exactly half of linear. Clients/tps on 9.2, with the pgbench-tools test Peter recommended: 1 140 2 143 4 289 8 585 16 1157 32 2317 50 3377 150 9511 250 12721 350 12582 450 11370 700 6972 You'll notice that at 2 clients we get basically no improvement. But 4 gets twice the single-client throughput; 8 gets about four times the single-client throughput; 16 gets about eight times the single-client throughput; 32 gets about sixteen times the single-client throughput; and 50 gets nearly 25 times the single-client throughput. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Saturday, March 31, 2012, Jeff Janes <<a href="mailto:jeff.janes@gmail.com">jeff.janes@gmail.com</a>> wrote:<br/>> On Saturday, March 31, 2012, Robert Haas <<a href="mailto:robertmhaas@gmail.com">robertmhaas@gmail.com</a>>wrote:<br /> >> On Sun, Apr 1, 2012 at 1:40 AM, JeffJanes <<a href="mailto:jeff.janes@gmail.com">jeff.janes@gmail.com</a>> wrote:<br />><br />>>> It lookslike in your case tps was still scaling with clients when you gave<br /> >>> up, so clients was probably toosmall.<br />>><br />>> What is kind of weird is that it actually seems to scale at almost<br />>> exactlyhalf of linear. <br /><br />This is expected. A very common pattern in commits/fsync is to see alterations between1 and C-1, or between 2 and C-2.<br /><br />To cure that, play with commit_delay. Don't make the mistake I did. Commit_delay is in micro seconds, not ms. That didn't mater when minimum kernel sleep was 10 or 4 ms anyway. Now withmuch finer sleeps, it makes a huge difference, so try ~5000.<br /><br />Cheers <br /><br />Jeff
On 1 April 2012 06:41, Robert Haas <robertmhaas@gmail.com> wrote: > There seem to be too relevant differences between your test and mine: > (1) your test is just a single insert per transaction, whereas mine is > pgbench's usual update, select, update, update, insert and (2) it > seems that, to really see the benefit of this patch, you need to pound > the server with a very large number of clients. On this test, 250 > clients was the sweet spot. *refers to original early January benchmark* While the graph that I produced was about the same shape as yours, the underlying hardware was quite different, and indeed with my benchmark group commit's benefits are more apparent earlier - at 32 clients, throughput has more-than doubled compared to pre group commit Postgres, which has already just about plateaued. I did include hdparm information for the disk that my benchmark was performed on at the time. While write-caching was not disabled, I would expect that the commit speed of my laptop - which has a fairly unremarkable 7200RPM disk - is slower than the 10K RPM SAS disks that you used. A formal benchmark of respective raw commit speeds may shed more light on this. Why did I even bother with such a sympathetic benchmark, when a benchmark on a large server could have been performed instead? Well, the reality is that many of our users have a commit speed that is comparable to my laptop. In particular, the increasing prevalence of "cloud" type deployments, make group commit a timely feature. If you wanted to demonstrate the wonders of group commit, I'd take that particular tone. I'm sure that if you re-ran this benchmark with a battery-backed cache, you would observe a much smaller though still very apparent benefit, but if you wanted to make the feature sound appealing to traditional enterprise users that are using a BBU, a good line would be "this is what will save your bacon that day that your procedures fail and your BBU battery dies". -- Peter Geoghegan http://www.2ndQuadrant.com/ PostgreSQL Development, 24x7 Support, Training and Services
On Mon, Apr 2, 2012 at 8:14 AM, Peter Geoghegan <peter@2ndquadrant.com> wrote: > While the graph that I produced was about the same shape as yours, the > underlying hardware was quite different, and indeed with my benchmark > group commit's benefits are more apparent earlier - at 32 clients, > throughput has more-than doubled compared to pre group commit > Postgres, which has already just about plateaued. I did include hdparm > information for the disk that my benchmark was performed on at the > time. While write-caching was not disabled, I would expect that the > commit speed of my laptop - which has a fairly unremarkable 7200RPM > disk - is slower than the 10K RPM SAS disks that you used. A formal > benchmark of respective raw commit speeds may shed more light on this. We could compare pg_test_fsync results if you are interested. > Why did I even bother with such a sympathetic benchmark, when a > benchmark on a large server could have been performed instead? Well, > the reality is that many of our users have a commit speed that is > comparable to my laptop. In particular, the increasing prevalence of > "cloud" type deployments, make group commit a timely feature. If you > wanted to demonstrate the wonders of group commit, I'd take that > particular tone. I'm sure that if you re-ran this benchmark with a > battery-backed cache, you would observe a much smaller though still > very apparent benefit, but if you wanted to make the feature sound > appealing to traditional enterprise users that are using a BBU, a good > line would be "this is what will save your bacon that day that your > procedures fail and your BBU battery dies". Well, on my pgbench tests, synchronous_commit=on is still far, far slower than synchronous_commit=off, even on 9.2; see the OP. It's certainly an improvement, of course: the 15-20% improvement at 32 clients is nothing to sneeze at, and it's hard to see how we can really hope to do much better. But it certainly makes me understand why people pay for BBUs. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company