Thread: checkpoint patches
There are two checkpoint-related patches in this CommitFest that haven't gotten much love, one from me and the other from Greg Smith: https://commitfest.postgresql.org/action/patch_view?id=752 https://commitfest.postgresql.org/action/patch_view?id=795 Mine uses sync_file_range() when available (i.e. on Linux) to add the already-dirty data to the kernel writeback queue at the beginning of each checkpoint, in the hopes of reducing the tendency of checkpoints to disrupt other activity on the system. Greg's adds an optional pause after each fsync() call for similar purposes. What we're lacking is any testimony to the effectiveness or ineffectiveness of either approach. I took a shot at trying to figure this out by throwing pgbench at it, but didn't get too far. Here's scale factor 300, which fits in shared_buffers, on the IBM POWER7 machine: resultsckpt.checkpoint-sync-pause-v1.1:tps = 14274.784431 (including connections establishing) resultsckpt.checkpoint-sync-pause-v1.2:tps = 12114.861879 (including connections establishing) resultsckpt.checkpoint-sync-pause-v1.3:tps = 14117.602996 (including connections establishing) resultsckpt.master.1:tps = 14485.394298 (including connections establishing) resultsckpt.master.2:tps = 14162.000100 (including connections establishing) resultsckpt.master.3:tps = 14307.221824 (including connections establishing) resultsckpt.writeback-v1.1:tps = 14264.851218 (including connections establishing) resultsckpt.writeback-v1.2:tps = 14314.773839 (including connections establishing) resultsckpt.writeback-v1.3:tps = 14230.219900 (including connections establishing) Looks like a whole lot of "that didn't matter". Of course then I realized that it was a stupid test, since if the whole database fits in shared_buffers then of course there won't be any data in the OS at checkpoint start time. So I ran some more tests with scale factor 1000, which doesn't fit in shared_buffers. Unfortunately an operating system crash intervened before the test finished, but it still looks like a whole lot of nothing: resultsckpt.checkpoint-sync-pause-v1.4:tps = 1899.745078 (including connections establishing) resultsckpt.checkpoint-sync-pause-v1.5:tps = 1925.848571 (including connections establishing) resultsckpt.checkpoint-sync-pause-v1.6:tps = 1920.624753 (including connections establishing) resultsckpt.master.4:tps = 1855.866476 (including connections establishing) resultsckpt.master.5:tps = 1862.413311 (including connections establishing) resultsckpt.writeback-v1.4:tps = 1869.536435 (including connections establishing) resultsckpt.writeback-v1.5:tps = 1912.669580 (including connections establishing) There might be a bit of improvement there with the patches, but it doesn't look like very much, and then you also have to think about the fact that they work by making checkpoints take longer, and therefore potentially less frequent, especially in the case of the checkpoint-sync-pause patch. Of course, this is maybe all not very surprising, since Greg already spent some time talking about the sorts of conditions he thought were needed to replicate his test, and they're more complicated than throwing transactions at the database at top speed. I don't know how to replicate those conditions, though, and there's certainly plenty of checkpoint-related latency to be quashed even on this test - a problem which these patches apparently do little if anything to address. So my feeling is that it's premature to change anything here and we should punt any changes in this area to 9.3. Thoughts? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Robert,
* Robert Haas (robertmhaas@gmail.com) wrote:
> Thoughts?
It was my impression that these patches were much about improving
overall tps and more about reducing latency spikes for specific
transactions that get hit by a checkpoint happening at a bad time.
Are there any reductions in max latency for these pgbench runs..?
Assuming that's information you can get..
Thanks,
Stephen
On Wed, Mar 21, 2012 at 3:34 PM, Stephen Frost <sfrost@snowman.net> wrote: > Robert, > > * Robert Haas (robertmhaas@gmail.com) wrote: >> Thoughts? > > It was my impression that these patches were much about improving > overall tps and more about reducing latency spikes for specific > transactions that get hit by a checkpoint happening at a bad time. > > Are there any reductions in max latency for these pgbench runs..? > Assuming that's information you can get.. It looks like I neglected to record that information for the last set of runs. But I can try another set of runs and gather that information. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Mar 21, 2012 at 3:38 PM, Robert Haas <robertmhaas@gmail.com> wrote: > It looks like I neglected to record that information for the last set > of runs. But I can try another set of runs and gather that > information. OK. On further review, my previous test script contained several bugs. So you should probably ignore the previous set of results. I did a new set of runs, and this time bumped up checkpoint_segments a bit more, in the hopes of giving the cache a bit more time to fill up with dirty data between checkpoints. Here's the full settings I used: shared_buffers = 8GB maintenance_work_mem = 1GB synchronous_commit = off checkpoint_timeout = 15min checkpoint_completion_target = 0.9 wal_writer_delay = 20ms log_line_prefix = '%t [%p] ' log_checkpoints='on' checkpoint_segments='1000' checkpoint_sync_pause='3' # for the checkpoint-sync-pause-v1 branch only With that change, each of the 6 tests (3 per branch) involved exactly 2 checkpoints, all triggered by time rather than by xlog. The tps results are: checkpoint-sync-pause-v1: 2613.439217, 2498.874628, 2477.282015 master: 2479.955432, 2489.480892, 2458.600233 writeback-v1: 2386.394628, 2457.038789, 2410.833487 The 90th percentile latency results are: checkpoint-sync-pause-v1: 1481, 1490, 1488 master: 1516, 1499, 1483 writeback-v1: 1497, 1502, 1491 However, looking at this a bit more, I think the checkpoint-sync-pause-v1 patch contains an obvious bug - the GUC is supposedly represented in seconds (though not marked with GUC_UNIT_S, oops) but what the sleep implements is actually *tenths of a second*. So I think I'd better rerun these tests with checkpoint_sync_pause=30 so that I get a three-second delay rather than a three-tenths-of-a-second delay between each fsync. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
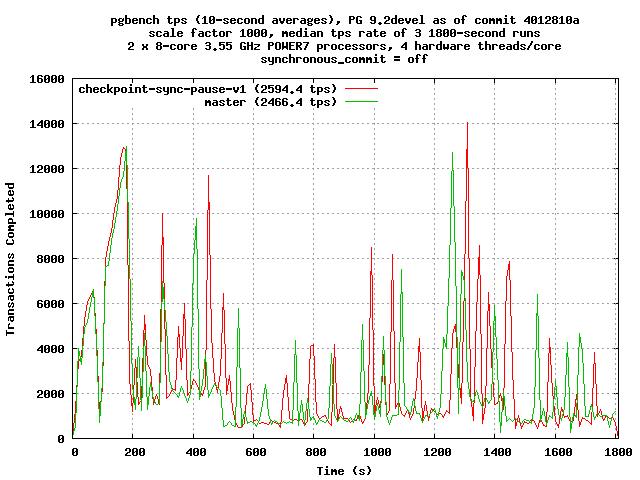
On Thu, Mar 22, 2012 at 9:07 AM, Robert Haas <robertmhaas@gmail.com> wrote: > However, looking at this a bit more, I think the > checkpoint-sync-pause-v1 patch contains an obvious bug - the GUC is > supposedly represented in seconds (though not marked with GUC_UNIT_S, > oops) but what the sleep implements is actually *tenths of a second*. > So I think I'd better rerun these tests with checkpoint_sync_pause=30 > so that I get a three-second delay rather than a > three-tenths-of-a-second delay between each fsync. OK, I did that, rerunning the test with just checkpoint-sync-pause-v1 and master, still with scale factor 1000 and 32 clients. Tests were run on the two branches in alternation, so checkpoint-sync-pause-v1, then master, then checkpoint-sync-pause-v1, then master, etc.; with a new initdb and data load each time. TPS numbers: checkpoint-sync-pause-v1: 2594.448538, 2600.231666, 2580.041376 master: 2466.399991, 2450.752843, 2291.613305 90th percentile latency: checkpoint-sync-pause-v1: 1487, 1488, 1481 master: 1493, 1519, 1507 That's about a 6% increase in throughput and about a 1.3% reduction in 90th-percentile latency. On the other hand, the two timed checkpoints on the master branch, on each test run, are exactly 15 minutes apart, whereas with the patch, they're 15 minutes and 30-40 seconds apart, which may account for some of the difference. I'm going to do a bit more testing to try to isolate that. I'm attaching a possibly-interesting graph comparing the first checkpoint-sync-pause-v1 run against the second master run; I chose that particular combination because those are the runs with the median tps results. It's interesting how eerily similar the two runs are to each other; they have spikes and dips in almost the same places, and what looks like random variation is apparently not so random after all. The graph attached here is based on tps averaged over ten second intervals. Thoughts? Comments? Ideas? -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
{kind=link}
* Robert Haas (robertmhaas@gmail.com) wrote:
> TPS numbers:
>
> checkpoint-sync-pause-v1: 2594.448538, 2600.231666, 2580.041376
> master: 2466.399991, 2450.752843, 2291.613305
>
> 90th percentile latency:
>
> checkpoint-sync-pause-v1: 1487, 1488, 1481
> master: 1493, 1519, 1507
Well, those numbers just aren't that exciting. :/
Then again, I'm a bit surprised that the latencies aren't worse, perhaps
the previous improvements have made the checkpoint pain go away for the
most part..
> The graph attached here is based on tps averaged over ten second
> intervals.
The graph is definitely interesting.. Would it be possible for you to
produce a graph of latency over the time of the run? I'd be looking for
spikes in latency near/around the 15m checkpoint marks and/or fsync
times. If there isn't really one, then perhaps the checkpoint spreading
is doing a sufficient job. Another option might be to intentionally
tune the checkpoint spreading down to force it to try and finish the
checkpoint faster and then see if the patches improve the latency in
that situation. Perhaps, in whatever workloads there are which are
better suited to faster checkpoints (there must be some, right?
otherwise there wouldn't be a GUC for it..), these patches would help.
Thanks,
Stephen
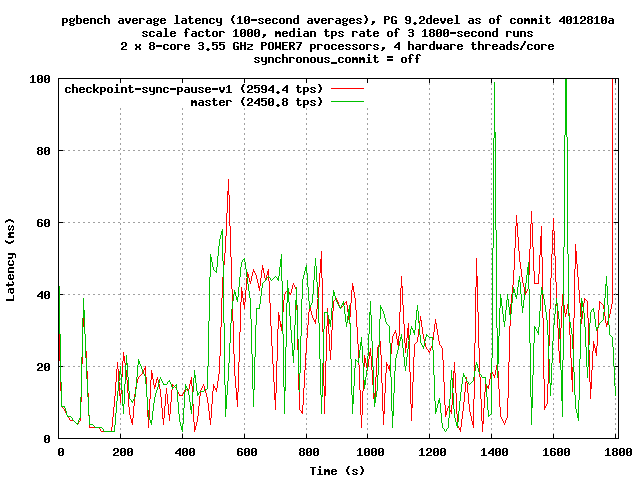
On Thu, Mar 22, 2012 at 3:45 PM, Stephen Frost <sfrost@snowman.net> wrote: > Well, those numbers just aren't that exciting. :/ Agreed. There's clearly an effect, but on this test it's not very big. > Then again, I'm a bit surprised that the latencies aren't worse, perhaps > the previous improvements have made the checkpoint pain go away for the > most part.. I think it's pretty obvious from the graph that the checkpoint pain hasn't gone away; it's just that this particular approach doesn't do anything to address the pain associated with this particular test. > The graph is definitely interesting.. Would it be possible for you to > produce a graph of latency over the time of the run? I'd be looking for > spikes in latency near/around the 15m checkpoint marks and/or fsync > times. If there isn't really one, then perhaps the checkpoint spreading > is doing a sufficient job. Another option might be to intentionally > tune the checkpoint spreading down to force it to try and finish the > checkpoint faster and then see if the patches improve the latency in > that situation. Perhaps, in whatever workloads there are which are > better suited to faster checkpoints (there must be some, right? > otherwise there wouldn't be a GUC for it..), these patches would help. See attached. It looks a whole lot like the tps graph, if you look at the tps graph upside with your 1/x glasses on. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Attachment
{kind=link}
On Thu, Mar 22, 2012 at 6:07 AM, Robert Haas <robertmhaas@gmail.com> wrote: > On Wed, Mar 21, 2012 at 3:38 PM, Robert Haas <robertmhaas@gmail.com> wrote: >> It looks like I neglected to record that information for the last set >> of runs. But I can try another set of runs and gather that >> information. > > OK. On further review, my previous test script contained several > bugs. So you should probably ignore the previous set of results. I > did a new set of runs, and this time bumped up checkpoint_segments a > bit more, in the hopes of giving the cache a bit more time to fill up > with dirty data between checkpoints. Here's the full settings I used: > > shared_buffers = 8GB > maintenance_work_mem = 1GB > synchronous_commit = off > checkpoint_timeout = 15min > checkpoint_completion_target = 0.9 > wal_writer_delay = 20ms > log_line_prefix = '%t [%p] ' > log_checkpoints='on' > checkpoint_segments='1000' > checkpoint_sync_pause='3' # for the checkpoint-sync-pause-v1 branch only > > With that change, each of the 6 tests (3 per branch) involved exactly > 2 checkpoints, all triggered by time rather than by xlog. Are you sure this is the case? If the server was restarted right before the pgbench -T 1800, then there should 15 minutes of no checkpoint, followed by about 15*0.9 minutes + some sync time of one checkpoint, and maybe just a bit of the starting of another checkpoint. If the server was not bounced between pgbench -i and pgbench -T 1800, then the first checkpoint would start at some unpredictable time into the benchmark run. Cheers, Jeff
On Thu, Mar 22, 2012 at 7:03 PM, Jeff Janes <jeff.janes@gmail.com> wrote: > On Thu, Mar 22, 2012 at 6:07 AM, Robert Haas <robertmhaas@gmail.com> wrote: >> On Wed, Mar 21, 2012 at 3:38 PM, Robert Haas <robertmhaas@gmail.com> wrote: >>> It looks like I neglected to record that information for the last set >>> of runs. But I can try another set of runs and gather that >>> information. >> >> OK. On further review, my previous test script contained several >> bugs. So you should probably ignore the previous set of results. I >> did a new set of runs, and this time bumped up checkpoint_segments a >> bit more, in the hopes of giving the cache a bit more time to fill up >> with dirty data between checkpoints. Here's the full settings I used: >> >> shared_buffers = 8GB >> maintenance_work_mem = 1GB >> synchronous_commit = off >> checkpoint_timeout = 15min >> checkpoint_completion_target = 0.9 >> wal_writer_delay = 20ms >> log_line_prefix = '%t [%p] ' >> log_checkpoints='on' >> checkpoint_segments='1000' >> checkpoint_sync_pause='3' # for the checkpoint-sync-pause-v1 branch only >> >> With that change, each of the 6 tests (3 per branch) involved exactly >> 2 checkpoints, all triggered by time rather than by xlog. > > Are you sure this is the case? If the server was restarted right > before the pgbench -T 1800, then there should 15 minutes of no > checkpoint, followed by about 15*0.9 minutes + some sync time of one > checkpoint, and maybe just a bit of the starting of another > checkpoint. If the server was not bounced between pgbench -i and > pgbench -T 1800, then the first checkpoint would start at some > unpredictable time into the benchmark run. I didn't stop and restart the server after pgbench -i; it fires off the test pgbench right after initializing. That seems to provide enough padding to ensure two checkpoints within the actual run. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
* Robert Haas (robertmhaas@gmail.com) wrote:
> On Thu, Mar 22, 2012 at 3:45 PM, Stephen Frost <sfrost@snowman.net> wrote:
> > Well, those numbers just aren't that exciting. :/
>
> Agreed. There's clearly an effect, but on this test it's not very big.
Ok, perhaps that was because of how you were analyzing it using the 90th
percetile..?
> See attached. It looks a whole lot like the tps graph, if you look at
> the tps graph upside with your 1/x glasses on.
Well, what I'm looking at with this graph are the spikes on master up to
near 100ms latency (as averaged across 10 seconds) while
checkpoint-sync-pause-v1 stays down closer to 60 and never above 70ms.
That makes this patch look much more interesting, in my view..
I'm assuming there's some anomaly or inconsistincy with the last few
seconds, where the latency drops for master and spikes with the patch.
If there isn't, then it'd be good to have a longer run to figure out if
there really is an issue with the checkpoint patch still having major
spikes.
Thanks,
Stephen
On Thu, Mar 22, 2012 at 8:44 PM, Stephen Frost <sfrost@snowman.net> wrote: > * Robert Haas (robertmhaas@gmail.com) wrote: >> On Thu, Mar 22, 2012 at 3:45 PM, Stephen Frost <sfrost@snowman.net> wrote: >> > Well, those numbers just aren't that exciting. :/ >> >> Agreed. There's clearly an effect, but on this test it's not very big. > > Ok, perhaps that was because of how you were analyzing it using the 90th > percetile..? Well, how do you want to look at it? Here's the data from 80th percentile through 100th percentile - percentile, patched, unpatched, difference - for the same two runs I've been comparing: 80 1321 1348 -27 81 1333 1360 -27 82 1345 1373 -28 83 1359 1387 -28 84 1373 1401 -28 85 1388 1417 -29 86 1404 1434 -30 87 1422 1452 -30 88 1441 1472 -31 89 1462 1494 -32 90 1487 1519 -32 91 1514 1548 -34 92 1547 1582 -35 93 1586 1625 -39 94 1637 1681 -44 95 1709 1762 -53 96 1825 1905 -80 97 2106 2288 -182 98 12100 24645 -12545 99 186043 201309 -15266 100 9513855 9074161 439694 Here are the 95th-100th percentiles for each of the six runs: ckpt.checkpoint-sync-pause-v1.10: 1709, 1825, 2106, 12100, 186043, 9513855 ckpt.checkpoint-sync-pause-v1.11: 1707, 1824, 2118, 16792, 196107, 8869602 ckpt.checkpoint-sync-pause-v1.12: 1693, 1807, 2091, 15132, 191207, 7246326 ckpt.master.10: 1734, 1875, 2235, 21145, 203214, 6855888 ckpt.master.11: 1762, 1905, 2288, 24645, 201309, 9074161 ckpt.master.12: 1746, 1889, 2272, 20309, 194459, 7833582 By the way, I reran the tests on master with checkpoint_timeout=16min, and here are the tps results: 2492.966759, 2588.750631, 2575.175993. So it seems like not all of the tps gain from this patch comes from the fact that it increases the time between checkpoints. Comparing the median of three results between the different sets of runs, applying the patch and setting a 3s delay between syncs gives you about a 5.8% increase throughput, but also adds 30-40 seconds between checkpoints. If you don't apply the patch but do increase time between checkpoints by 1 minute, you get about a 5.0% increase in throughput. That certainly means that the patch is doing something - because 5.8% for 30-40 seconds is better than 5.0% for 60 seconds - but it's a pretty small effect. And here are the latency results for 95th-100th percentile with checkpoint_timeout=16min. ckpt.master.13: 1703, 1830, 2166, 17953, 192434, 43946669 ckpt.master.14: 1728, 1858, 2169, 15596, 187943, 9619191 ckpt.master.15: 1700, 1835, 2189, 22181, 206445, 8212125 The picture looks similar here. Increasing checkpoint_timeout isn't *quite* as good as spreading out the fsyncs, but it's pretty darn close. For example, looking at the median of the three 98th percentile numbers for each configuration, the patch bought us a 28% improvement in 98th percentile latency. But increasing checkpoint_timeout by a minute bought us a 15% improvement in 98th percentile latency. So it's still not clear to me that the patch is doing anything on this test that you couldn't get just by increasing checkpoint_timeout by a few more minutes. Granted, it lets you keep your inter-checkpoint interval slightly smaller, but that's not that exciting. That having been said, I don't have a whole lot of trouble believing that there are other cases where this is more worthwhile. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
* Robert Haas (robertmhaas@gmail.com) wrote:
> Well, how do you want to look at it?
I thought the last graph you provided was a useful way to view the
results. It was my intent to make that clear in my prior email, my
apologies if that didn't come through.
> Here's the data from 80th
> percentile through 100th percentile - percentile, patched, unpatched,
> difference - for the same two runs I've been comparing:
[...]
> 98 12100 24645 -12545
> 99 186043 201309 -15266
> 100 9513855 9074161 439694
Those are the areas that I think we want to be looking at/for: the
outliers.
> By the way, I reran the tests on master with checkpoint_timeout=16min,
> and here are the tps results: 2492.966759, 2588.750631, 2575.175993.
> So it seems like not all of the tps gain from this patch comes from
> the fact that it increases the time between checkpoints. Comparing
> the median of three results between the different sets of runs,
> applying the patch and setting a 3s delay between syncs gives you
> about a 5.8% increase throughput, but also adds 30-40 seconds between
> checkpoints. If you don't apply the patch but do increase time
> between checkpoints by 1 minute, you get about a 5.0% increase in
> throughput. That certainly means that the patch is doing something -
> because 5.8% for 30-40 seconds is better than 5.0% for 60 seconds -
> but it's a pretty small effect.
That doesn't surprise me too much. As I mentioned before, and Greg
please correct me if I'm wrong, but I thought this patch was intended to
reduce the latency spikes that we suffer from under some workloads,
which can often be attributed back to i/o related contention. I don't
believe it's intended or expected to seriously increase throughput.
> The picture looks similar here. Increasing checkpoint_timeout isn't
> *quite* as good as spreading out the fsyncs, but it's pretty darn
> close. For example, looking at the median of the three 98th
> percentile numbers for each configuration, the patch bought us a 28%
> improvement in 98th percentile latency. But increasing
> checkpoint_timeout by a minute bought us a 15% improvement in 98th
> percentile latency. So it's still not clear to me that the patch is
> doing anything on this test that you couldn't get just by increasing
> checkpoint_timeout by a few more minutes. Granted, it lets you keep
> your inter-checkpoint interval slightly smaller, but that's not that
> exciting. That having been said, I don't have a whole lot of trouble
> believing that there are other cases where this is more worthwhile.
I could certainly see the checkpoint_timeout parameter, along with the
others, as being sufficient to address this, in which case we likely
don't need the patch. They're both more-or-less intended to do the same
thing and it's just a question of if being more granular ends up helping
or not.
Thanks,
Stephen
On 3/23/12 7:38 AM, Robert Haas wrote: > And here are the latency results for 95th-100th percentile with > checkpoint_timeout=16min. > > ckpt.master.13: 1703, 1830, 2166, 17953, 192434, 43946669 > ckpt.master.14: 1728, 1858, 2169, 15596, 187943, 9619191 > ckpt.master.15: 1700, 1835, 2189, 22181, 206445, 8212125 > > The picture looks similar here. Increasing checkpoint_timeout isn't > *quite* as good as spreading out the fsyncs, but it's pretty darn > close. For example, looking at the median of the three 98th > percentile numbers for each configuration, the patch bought us a 28% > improvement in 98th percentile latency. But increasing > checkpoint_timeout by a minute bought us a 15% improvement in 98th > percentile latency. So it's still not clear to me that the patch is > doing anything on this test that you couldn't get just by increasing > checkpoint_timeout by a few more minutes. Granted, it lets you keep > your inter-checkpoint interval slightly smaller, but that's not that > exciting. That having been said, I don't have a whole lot of trouble > believing that there are other cases where this is more worthwhile. I wouldn't be too quick to dismiss increasing checkpoint frequency (ie: decreasing checkpoint_timeout). On a high-value production system you're going to care quite a bit about recovery time. I certainly wouldn't want to runour systems with checkpoint_timeout='15 min' if I could avoid it. Another $0.02: I don't recall the community using pg_bench much at all to measure latency... I believe it's something fairlynew. I point this out because I believe there are differences in analysis that you need to do for TPS vs latency. Ithink Robert's graphs support my argument; the numeric X-percentile data might not look terribly good, but reducing peaklatency from 100ms to 60ms could be a really big deal on a lot of systems. My intuition is that one or both of thesepatches actually would be valuable in the real world; it would be a shame to throw them out because we're not sure howto performance test them... -- Jim C. Nasby, Database Architect jim@nasby.net 512.569.9461 (cell) http://jim.nasby.net
On Sun, Mar 25, 2012 at 4:29 PM, Jim Nasby <jim@nasby.net> wrote: > I wouldn't be too quick to dismiss increasing checkpoint frequency (ie: > decreasing checkpoint_timeout). I'm not dismissing that, but my tests show only a very small gain in that area. Now there may be another test where it shows a bigger gain, but finding such a test is the patch author's job, not mine. Patches that supposedly improve performance should be submitted with test results showing that they do. This patch was submitted more than two months ago with no performance results, no documentation, and bugs. Because I feel that this is an important area for us to try to improve, I devoted a substantial amount of time to trying to demonstrate that the patch does something good, but I didn't find anything very convincing, so I think it's time to punt this one for now and let Greg pursue the strategy he originally intended, which was to "leave this whole area alone until 9.3"[1]. I think he only submitted something at all because I kicked out a somewhat random attempt to solve the same problem[2]. Well, it turns out that, on the test cases I have available, neither one is any great shakes. Considering Greg Smith's long track record of ridiculously diligent research, I feel pretty confident he'll eventually come back to the table either with more evidence that this is the right approach (in which case we'll be able to document it in a reasonable way, which is currently impossible, since we don't have only the vaguest idea when setting it to a non-zero value might be useful, or what value to set) or with another proposed approach that he thinks is better and test results to back it up. Had someone other than Greg proposed this, I probably wouldn't have spent time on it at all, because by his own admission it's not really ready for prime time, but as it was I thought I'd try to see if I could fill in the gaps. Long story short, this may yet prove to be useful in some as-yet-unknown set of circumstances, but that's not a sufficient reason to commit it, so I've marked it (and my patch, which doesn't win either) Returned with Feedback. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company [1] http://archives.postgresql.org/message-id/4F13D856.60704@2ndQuadrant.com [2] https://commitfest.postgresql.org/action/patch_view?id=752
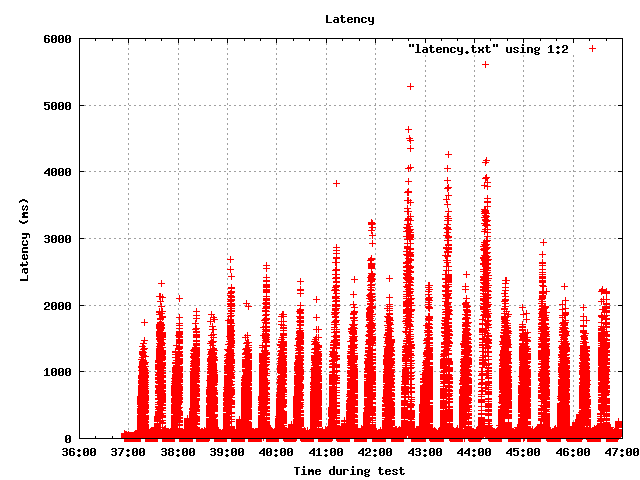
On 03/25/2012 04:29 PM, Jim Nasby wrote: > Another $0.02: I don't recall the community using pg_bench much at all > to measure latency... I believe it's something fairly new. I point > this out because I believe there are differences in analysis that you > need to do for TPS vs latency. I think Robert's graphs support my > argument; the numeric X-percentile data might not look terribly good, > but reducing peak latency from 100ms to 60ms could be a really big > deal on a lot of systems. My intuition is that one or both of these > patches actually would be valuable in the real world; it would be a > shame to throw them out because we're not sure how to performance test > them... One of these patches is already valuable in the real world. There it will stay, while we continue mining it for nuggets of deeper insight into the problem that can lead into a better test case. Starting at pgbench latency worked out fairly well for some things. Last year around this time I published some results I summarized at http://blog.2ndquadrant.com/en/gregs-planetpostgresql/2011/02/ , which included things like worst-case latency going from <=34 seconds on ext3 to <=5 seconds on xfs. The problem I keep hitting now is that 2 to 5 second latencies on Linux are extremely hard to get rid of if you overwhelm storage--any storage. That's where the wall is, where if you try to drive them lower than that you pay some hard trade-off penalties, if it works at all. Take a look at the graph I've attached. That's a slow drive not able to keep up with lots of random writes stalling, right? No. It's a Fusion-io card that will do 600MB/s of random I/O. But clog it up with an endless stream of pgbench writes, never with any pause to catch up, and I can get Linux to clog it for many seconds whenever I set it loose. This test workload is so not representative of the real world that I don't think we should be committing things justified by it, unless they are uncontested wins. And those aren't so easy to find on the write side of things. Thanks to Robert for shaking my poorly submitted patch and seeing what happened. I threw mine out in hopes that some larger checkpoint patch shoot-out might find it useful. Didn't happen, sorry I didn't get to looking more at the other horses. I do have some more neat benchmarks to share though -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com
Attachment
{kind=link}
On 4/3/12 11:30 PM, Greg Smith wrote: > On 03/25/2012 04:29 PM, Jim Nasby wrote: >> Another $0.02: I don't recall the community using pg_bench much at all to measure latency... I believe it's somethingfairly new. I point this out because I believe there are differences in analysis that you need to do for TPS vslatency. I think Robert's graphs support my argument; the numeric X-percentile data might not look terribly good, but reducingpeak latency from 100ms to 60ms could be a really big deal on a lot of systems. My intuition is that one or bothof these patches actually would be valuable in the real world; it would be a shame to throw them out because we're notsure how to performance test them... > > One of these patches is already valuable in the real world. There it will stay, while we continue mining it for nuggetsof deeper insight into the problem that can lead into a better test case. > > Starting at pgbench latency worked out fairly well for some things. Last year around this time I published some resultsI summarized at http://blog.2ndquadrant.com/en/gregs-planetpostgresql/2011/02/ , which included things like worst-caselatency going from <=34 seconds on ext3 to <=5 seconds on xfs. > > The problem I keep hitting now is that 2 to 5 second latencies on Linux are extremely hard to get rid of if you overwhelmstorage--any storage. That's where the wall is, where if you try to drive them lower than that you pay some hardtrade-off penalties, if it works at all. > > Take a look at the graph I've attached. That's a slow drive not able to keep up with lots of random writes stalling, right?No. It's a Fusion-io card that will do 600MB/s of random I/O. But clog it up with an endless stream of pgbench writes,never with any pause to catch up, and I can get Linux to clog it for many seconds whenever I set it loose. If there's a fundamental flaw in how linux deals with heavy writes that means you can't rely on certain latency windows,perhaps we should be looking at using a different OS to test those cases... -- Jim C. Nasby, Database Architect jim@nasby.net 512.569.9461 (cell) http://jim.nasby.net
On 04/05/2012 02:23 PM, Jim Nasby wrote: > If there's a fundamental flaw in how linux deals with heavy writes that > means you can't rely on certain latency windows, perhaps we should be > looking at using a different OS to test those cases... Performance under this sort of write overload is something that's been a major focus of more recent Linux kernel versions than I've tested yet. It may get better just via the passage of time. Today is surely far improved over the status quo a few years ago, when ext3 was the only viable filesystem choice and tens of seconds could pass with no activity. The other thing to recognize here is that some heavy write operations get quite a throughput improvement from how things work now, with VACUUM being the most obvious one. If I retune Linux to act more like other operating systems, with a smaller and more frequently flushed write cache, it will trash VACUUM write performance in the process. That's one of the reasons I submitted the MB/s logging to VACUUM for 9.2, to make it easier to measure what happens to that as write cache changes are made. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.com