Thread: Single client performance on trivial SELECTs
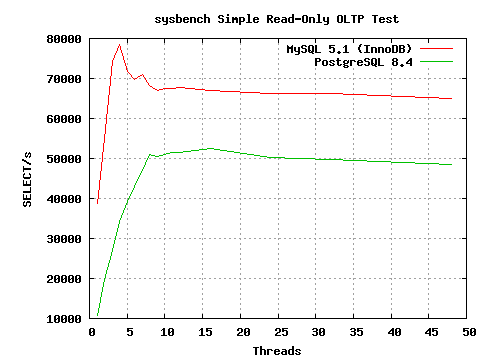
This week several list regulars here waded into the MySQL Convention. I decided to revisit PostgreSQL vs. MySQL performance using the sysbench program as part of that. It's not important to what I'm going to describe to understand exactly what statements sysbench runs here or how to use it, but if anyone is curious I've got some more details about how I ran the tests in my talk slides at http://projects.2ndquadrant.com/talks The program has recently gone through some fixes that make it run a bit better both in general and against PostgreSQL. The write tests are still broken against PostgreSQL, but it now seems to do a reasonable job simulating a simple SELECT-only workload. A fix from Jignesh recently made its way into the database generation side of the code that makes it less tedious to test with it too. The interesting part was how per-client scaling compared between the two databases; graph attached. On my 8 core server, PostgreSQL scales nicely up to a steady 50K TPS. I see the same curve, almost identical numbers, with PostgreSQL and pgbench--no reason to suspect sysbench is doing anything shady. The version of MySQL I used hits around 67K TPS with innodb when busy with lots of clients. That part doesn't bother me; nobody expects PostgreSQL to be faster on trivial SELECT statements and the gap isn't that big. The shocking part was the single client results. I'm using to seeing Postgres get around 7K TPS per core on those, which was the case here, and I never considered that an interesting limitation to think about before. MySQL turns out to hit 38K TPS doing the same work. Now that's a gap interesting enough to make me wonder what's going on. Easy enough to exercise the same sort of single client test case with pgbench and put it under a profiler: sudo opcontrol --init sudo opcontrol --setup --no-vmlinux createdb pgbench pgbench -i -s 10 pgbench psql -d pgbench -c "vacuum" sudo opcontrol --start sudo opcontrol --reset pgbench -S -n -c 1 -T 60 pgbench sudo opcontrol --dump ; sudo opcontrol --shutdown opreport -l image:$HOME/pgwork/inst/test/bin/postgres Here's the top calls, from my laptop rather than the server that I generated the graph against. It does around 5.5K TPS with 1 clients and 10K with 2 clients, so same basic scaling: samples % image name symbol name 53548 6.7609 postgres AllocSetAlloc 32787 4.1396 postgres MemoryContextAllocZeroAligned 26330 3.3244 postgres base_yyparse 21723 2.7427 postgres hash_search_with_hash_value 20831 2.6301 postgres SearchCatCache 19094 2.4108 postgres hash_seq_search 18402 2.3234 postgres hash_any 15975 2.0170 postgres AllocSetFreeIndex 14205 1.7935 postgres _bt_compare 13370 1.6881 postgres core_yylex 10455 1.3200 postgres MemoryContextAlloc 10330 1.3042 postgres LockAcquireExtended 10197 1.2875 postgres ScanKeywordLookup 9312 1.1757 postgres MemoryContextAllocZero I don't know nearly enough about the memory allocator to comment on whether it's possible to optimize it better for this case to relieve any bottleneck. Might just get a small gain then push the limiter to the parser or hash functions. I was surprised to find that's where so much of the time was going though. P.S. When showing this graph in my talk, I pointed out that anyone who is making decisions about which database to use based on trivial SELECTs on small databases isn't going to be choosing between PostgreSQL and MySQL anyway--they'll be deploying something like MongoDB instead if that's the important metric. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.us
Attachment
{kind=link}
Greg Smith <greg@2ndquadrant.com> writes:
> samples % image name symbol name
> 53548 6.7609 postgres AllocSetAlloc
> 32787 4.1396 postgres MemoryContextAllocZeroAligned
> 26330 3.3244 postgres base_yyparse
> 21723 2.7427 postgres hash_search_with_hash_value
> 20831 2.6301 postgres SearchCatCache
> 19094 2.4108 postgres hash_seq_search
> 18402 2.3234 postgres hash_any
> 15975 2.0170 postgres AllocSetFreeIndex
> 14205 1.7935 postgres _bt_compare
> 13370 1.6881 postgres core_yylex
> 10455 1.3200 postgres MemoryContextAlloc
> 10330 1.3042 postgres LockAcquireExtended
> 10197 1.2875 postgres ScanKeywordLookup
> 9312 1.1757 postgres MemoryContextAllocZero
Yeah, this is pretty typical ...
> I don't know nearly enough about the memory allocator to comment on
> whether it's possible to optimize it better for this case to relieve any
> bottleneck.
I doubt that it's possible to make AllocSetAlloc radically cheaper.
I think the more likely route to improvement there is going to be to
find a way to do fewer pallocs. For instance, if we had more rigorous
rules about which data structures are read-only to which code, we could
probably get rid of a lot of just-in-case tree copying that happens in
the parser and planner.
But at the same time, even if we could drive all palloc costs to zero,
it would only make a 10% difference in this example. And this sort of
fairly flat profile is what I see in most cases these days --- we've
been playing performance whack-a-mole for long enough now that there
isn't much low-hanging fruit left. For better or worse, the system
design we've chosen just isn't amenable to minimal overhead for simple
queries. I think a lot of this ultimately traces to the extensible,
data-type-agnostic design philosophy. The fact that we don't know what
an integer is until we look in pg_type, and don't know what an "="
operator does until we look up its properties, is great from a flexibility
point of view; but this sort of query is where the costs become obvious.
regards, tom lane
On Thu, Apr 14, 2011 at 10:43:16AM -0400, Tom Lane wrote: > > I doubt that it's possible to make AllocSetAlloc radically cheaper. > I think the more likely route to improvement there is going to be to > find a way to do fewer pallocs. For instance, if we had more rigorous > rules about which data structures are read-only to which code, we could > probably get rid of a lot of just-in-case tree copying that happens in > the parser and planner. How much work would that be, and how would it be enforced in new development? > But at the same time, even if we could drive all palloc costs to > zero, it would only make a 10% difference in this example. And this > sort of fairly flat profile is what I see in most cases these days > --- we've been playing performance whack-a-mole for long enough now > that there isn't much low-hanging fruit left. For better or worse, > the system design we've chosen just isn't amenable to minimal > overhead for simple queries. I think a lot of this ultimately > traces to the extensible, data-type-agnostic design philosophy. The > fact that we don't know what an integer is until we look in pg_type, > and don't know what an "=" operator does until we look up its > properties, is great from a flexibility point of view; but this sort > of query is where the costs become obvious. Is it time to revisit that decision? Should we wait until, say, we no longer claim to support 32-bit machines on the server side? Cheers, David. -- David Fetter <david@fetter.org> http://fetter.org/ Phone: +1 415 235 3778 AIM: dfetter666 Yahoo!: dfetter Skype: davidfetter XMPP: david.fetter@gmail.com iCal: webcal://www.tripit.com/feed/ical/people/david74/tripit.ics Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
On Thu, Apr 14, 2011 at 7:43 AM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > I doubt that it's possible to make AllocSetAlloc radically cheaper. > I think the more likely route to improvement there is going to be to > find a way to do fewer pallocs. For instance, if we had more rigorous > rules about which data structures are read-only to which code, we could > probably get rid of a lot of just-in-case tree copying that happens in > the parser and planner. > > But at the same time, even if we could drive all palloc costs to zero, > it would only make a 10% difference in this example. And this sort of > fairly flat profile is what I see in most cases these days --- we've > been playing performance whack-a-mole for long enough now that there > isn't much low-hanging fruit left. There are other architectural approaches that we could take to reducing the parsing overhead. Random ideas: 1. Separate the parser into a parser for DML statements only, and another parser for everything else, to avoid cluttering the main parser with lots of keywords and non-terminals that aren't going to be used for the kinds of queries people care about parsing speed. 2. Hand-code a parser, or use some tool other than bison to generate one. 3. Some kind of parse-tree cache, so that executing the same exact statement many times doesn't require reparsing it every time. It's fairly far down in the noise on this particular profile, but in the low-hanging fruit department, I think we should fix ScanKeywordLookup to use a smarter algorithm that is more like O(1) rather than O(lg n) in the number of keywords. It shouldn't be terribly difficult to come up with some kind of hash function based on, say, the first two characters of the keyword that would be a lot faster than what we're doing now. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On 14.04.2011 17:43, Tom Lane wrote: > Greg Smith<greg@2ndquadrant.com> writes: >> samples % image name symbol name >> 53548 6.7609 postgres AllocSetAlloc >> 32787 4.1396 postgres MemoryContextAllocZeroAligned >> 26330 3.3244 postgres base_yyparse >> 21723 2.7427 postgres hash_search_with_hash_value >> 20831 2.6301 postgres SearchCatCache >> 19094 2.4108 postgres hash_seq_search >> 18402 2.3234 postgres hash_any >> 15975 2.0170 postgres AllocSetFreeIndex >> 14205 1.7935 postgres _bt_compareSince >> 13370 1.6881 postgres core_yylex >> 10455 1.3200 postgres MemoryContextAlloc >> 10330 1.3042 postgres LockAcquireExtended >> 10197 1.2875 postgres ScanKeywordLookup >> 9312 1.1757 postgres MemoryContextAllocZero > > Yeah, this is pretty typical ... In this case you could just use prepared statements and get rid of all the parser related overhead, which includes much of the allocations. >> I don't know nearly enough about the memory allocator to comment on >> whether it's possible to optimize it better for this case to relieve any >> bottleneck. > > I doubt that it's possible to make AllocSetAlloc radically cheaper. > I think the more likely route to improvement there is going to be to > find a way to do fewer pallocs. For instance, if we had more rigorous > rules about which data structures are read-only to which code, we could > probably get rid of a lot of just-in-case tree copying that happens in > the parser and planner. > > But at the same time, even if we could drive all palloc costs to zero, > it would only make a 10% difference in this example. And this sort of > fairly flat profile is what I see in most cases these days --- we've > been playing performance whack-a-mole for long enough now that there > isn't much low-hanging fruit left. For better or worse, the system > design we've chosen just isn't amenable to minimal overhead for simple > queries. I think a lot of this ultimately traces to the extensible, > data-type-agnostic design philosophy. The fact that we don't know what > an integer is until we look in pg_type, and don't know what an "=" > operator does until we look up its properties, is great from a flexibility > point of view; but this sort of query is where the costs become obvious. I think the general strategy to make this kind of queries faster will be to add various fastpaths to cache and skip even more work. For example, There's one very low-hanging fruit here, though. I profiled the pgbench case, with -M prepared, and found that like in Greg Smith's profile, hash_seq_search pops up quite high in the list. Those calls are coming from LockReleaseAll(), where we scan the local lock hash to find all locks held. We specify the initial size of the local lock hash table as 128, which is unnecessarily large for small queries like this. Reducing it to 8 slashed the time spent in hash_seq_search(). I think we should make that hash table smaller. It won't buy much, somewhere between 1-5 % in this test case, but it's very easy to do and I don't see much downside, it's a local hash table so it will grow as needed. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On Thu, Apr 14, 2011 at 11:15:00AM -0700, Robert Haas wrote: > It's fairly far down in the noise on this particular profile, but in > the low-hanging fruit department, I think we should fix > ScanKeywordLookup to use a smarter algorithm that is more like O(1) > rather than O(lg n) in the number of keywords. +1 > It shouldn't be > terribly difficult to come up with some kind of hash function based > on, say, the first two characters of the keyword that would be a lot > faster than what we're doing now. I'd look at `gperf', which generates code for this from your keyword list.
Heikki Linnakangas <heikki.linnakangas@enterprisedb.com> writes:
> There's one very low-hanging fruit here, though. I profiled the pgbench
> case, with -M prepared, and found that like in Greg Smith's profile,
> hash_seq_search pops up quite high in the list. Those calls are coming
> from LockReleaseAll(), where we scan the local lock hash to find all
> locks held. We specify the initial size of the local lock hash table as
> 128, which is unnecessarily large for small queries like this. Reducing
> it to 8 slashed the time spent in hash_seq_search().
> I think we should make that hash table smaller. It won't buy much,
> somewhere between 1-5 % in this test case, but it's very easy to do and
> I don't see much downside, it's a local hash table so it will grow as
> needed.
8 sounds awfully small. Can you even get as far as preparing the
statements you intend to use without causing that to grow?
I agree that 128 may be larger than necessary, but I don't think we
should pessimize normal usage to gain a small fraction on trivial
queries. I'd be happier with something like 16 or 32.
regards, tom lane
Hi, On Thursday 14 April 2011 16:43:16 Tom Lane wrote: > I doubt that it's possible to make AllocSetAlloc radically cheaper. I actually doubt your doubt. I think you could add some SLAB like interface for common allocation sizes making it significantly faster for some uses (because allocation/deallocation is a single linked list operation). Maybe even treat everything < some_size as a slab object in the next bigger slab. Note that I think youre otherwise right... Andres
Excerpts from Andres Freund's message of jue abr 14 17:08:34 -0300 2011: > Hi, > > On Thursday 14 April 2011 16:43:16 Tom Lane wrote: > > I doubt that it's possible to make AllocSetAlloc radically cheaper. > I actually doubt your doubt. I think you could add some SLAB like interface > for common allocation sizes making it significantly faster for some uses > (because allocation/deallocation is a single linked list operation). > Maybe even treat everything < some_size as a slab object in the next bigger > slab. I think the problem with a slab allocator is that it would make hierarchical context management slower and/or more complicated (e.g. reset context on transaction abort). -- Álvaro Herrera <alvherre@commandprompt.com> The PostgreSQL Company - Command Prompt, Inc. PostgreSQL Replication, Consulting, Custom Development, 24x7 support
Heikki Linnakangas wrote: > In this case you could just use prepared statements and get rid of all > the parser related overhead, which includes much of the allocations. Trying that gives me around 9200 TPS instead of 5500 on my laptop, so a pretty big gain here. Will have to include that in my next round of graphs across multiple client loads once I'm home again and can run easily on my server. To provide a matching profile from the same system as the one I already submitted from, for archival sake, here's what the profile I get looks like with "-M prepared": samples % image name symbol name 33093 4.8518 postgres AllocSetAlloc 30012 4.4001 postgres hash_seq_search 27149 3.9803 postgres MemoryContextAllocZeroAligned 26987 3.9566 postgres hash_search_with_hash_value 25665 3.7628 postgres hash_any 16820 2.4660 postgres _bt_compare 14778 2.1666 postgres LockAcquireExtended 12263 1.7979 postgres AllocSetFreeIndex 11727 1.7193 postgres tas 11602 1.7010 postgres SearchCatCache 11022 1.6159 postgres pg_encoding_mbcliplen 10963 1.6073 postgres MemoryContextAllocZero 9296 1.3629 postgres MemoryContextCreate 8368 1.2268 postgres fmgr_isbuiltin 7973 1.1689 postgres LockReleaseAll 7423 1.0883 postgres ExecInitExpr 7309 1.0716 postgres pfree -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD
On Thu, Apr 14, 2011 at 2:08 AM, Greg Smith <greg@2ndquadrant.com> wrote: > This week several list regulars here waded into the MySQL Convention. I > decided to revisit PostgreSQL vs. MySQL performance using the sysbench > program as part of that. It's not important to what I'm going to describe > to understand exactly what statements sysbench runs here or how to use it, > but if anyone is curious I've got some more details about how I ran the > tests in my talk slides at http://projects.2ndquadrant.com/talks The > program has recently gone through some fixes that make it run a bit better > both in general and against PostgreSQL. The write tests are still broken > against PostgreSQL, but it now seems to do a reasonable job simulating a > simple SELECT-only workload. A fix from Jignesh recently made its way into > the database generation side of the code that makes it less tedious to test > with it too. > The interesting part was how per-client scaling compared between the two > databases; graph attached. On my 8 core server, PostgreSQL scales nicely up > to a steady 50K TPS. I see the same curve, almost identical numbers, with > PostgreSQL and pgbench--no reason to suspect sysbench is doing anything > shady. The version of MySQL I used hits around 67K TPS with innodb when > busy with lots of clients. That part doesn't bother me; nobody expects > PostgreSQL to be faster on trivial SELECT statements and the gap isn't that > big. > > The shocking part was the single client results. I'm using to seeing > Postgres get around 7K TPS per core on those, which was the case here, and I > never considered that an interesting limitation to think about before. > MySQL turns out to hit 38K TPS doing the same work. Now that's a gap > interesting enough to make me wonder what's going on. > > Easy enough to exercise the same sort of single client test case with > pgbench and put it under a profiler: > > sudo opcontrol --init > sudo opcontrol --setup --no-vmlinux > createdb pgbench > pgbench -i -s 10 pgbench > psql -d pgbench -c "vacuum" > sudo opcontrol --start > sudo opcontrol --reset > pgbench -S -n -c 1 -T 60 pgbench > sudo opcontrol --dump ; sudo opcontrol --shutdown > opreport -l image:$HOME/pgwork/inst/test/bin/postgres > > Here's the top calls, from my laptop rather than the server that I generated > the graph against. It does around 5.5K TPS with 1 clients and 10K with 2 > clients, so same basic scaling: > > samples % image name symbol name > 53548 6.7609 postgres AllocSetAlloc > 32787 4.1396 postgres MemoryContextAllocZeroAligned > 26330 3.3244 postgres base_yyparse > 21723 2.7427 postgres hash_search_with_hash_value > 20831 2.6301 postgres SearchCatCache > 19094 2.4108 postgres hash_seq_search > 18402 2.3234 postgres hash_any > 15975 2.0170 postgres AllocSetFreeIndex > 14205 1.7935 postgres _bt_compare > 13370 1.6881 postgres core_yylex > 10455 1.3200 postgres MemoryContextAlloc > 10330 1.3042 postgres LockAcquireExtended > 10197 1.2875 postgres ScanKeywordLookup > 9312 1.1757 postgres MemoryContextAllocZero > > I don't know nearly enough about the memory allocator to comment on whether > it's possible to optimize it better for this case to relieve any bottleneck. > Might just get a small gain then push the limiter to the parser or hash > functions. I was surprised to find that's where so much of the time was > going though. > > P.S. When showing this graph in my talk, I pointed out that anyone who is > making decisions about which database to use based on trivial SELECTs on > small databases isn't going to be choosing between PostgreSQL and MySQL > anyway--they'll be deploying something like MongoDB instead if that's the > important metric. on my workstation VM, I get: 6.7k selects single client, 12k selects piped through single user backend, 13.5k piped through single user backend, one transaction 23k in plpgsql 'execute' in loop (which is really two queries, one to build the query and one to execute), 100k in non dynamic query plpgsql in loop. in addition to parsing and planning, the network and the protocol really factor in. this is why i'm so keen on being able to inject queries directly in to the backend via stored procedure. I'm also really curious how a plpgsql-ish language performs when managing transactions itself. libpqtypes was written so you could stage data on the client and hand it off to the backend and act on it in plpgsl world. it works really well -- you can amortize the turnaround losses through the newtork over a lot of data. merlin
On Thursday 14 April 2011 22:21:26 Alvaro Herrera wrote: > Excerpts from Andres Freund's message of jue abr 14 17:08:34 -0300 2011: > > Hi, > > > > On Thursday 14 April 2011 16:43:16 Tom Lane wrote: > > > I doubt that it's possible to make AllocSetAlloc radically cheaper. > > > > I actually doubt your doubt. I think you could add some SLAB like > > interface for common allocation sizes making it significantly faster for > > some uses (because allocation/deallocation is a single linked list > > operation). Maybe even treat everything < some_size as a slab object in > > the next bigger slab. > I think the problem with a slab allocator is that it would make > hierarchical context management slower and/or more complicated (e.g. > reset context on transaction abort). I am not that sure that it would be slower. I think that if youre careful you mostly can reuse what currently is done for chunks to implement slabs. For context resets you can just throw away all chunks/blocks. Where I am with you is that its quite possible that it will not make sense (performancewise) for all contexts. Which is quite annoying. Andres
Andres Freund <andres@anarazel.de> writes:
> Where I am with you is that its quite possible that it will not make sense
> (performancewise) for all contexts. Which is quite annoying.
The mcxt stuff was designed from day one to support multiple types of
contexts, so it wouldn't be very hard at all to have different contexts
using different allocation policies. The issue is to figure out what
to use where ...
regards, tom lane
On Thu, Apr 14, 2011 at 12:45 PM, Noah Misch <noah@leadboat.com> wrote: >> It shouldn't be >> terribly difficult to come up with some kind of hash function based >> on, say, the first two characters of the keyword that would be a lot >> faster than what we're doing now. > > I'd look at `gperf', which generates code for this from your keyword list. I thought of that, but wasn't sure we wanted to introduce a dependency on that tool. That might be a pain, especially on Windows. But maybe we could steal the basic approach. -- Robert Haas EnterpriseDB: http://www.enterprisedb.com The Enterprise PostgreSQL Company
Noah Misch <noah@leadboat.com> writes:
> On Thu, Apr 14, 2011 at 11:15:00AM -0700, Robert Haas wrote:
>> It shouldn't be
>> terribly difficult to come up with some kind of hash function based
>> on, say, the first two characters of the keyword that would be a lot
>> faster than what we're doing now.
> I'd look at `gperf', which generates code for this from your keyword list.
FWIW, mysql used to use gperf for this purpose, but they've abandoned it
in favor of some homegrown hashing scheme. I don't know exactly why,
but I wonder if it was for licensing reasons. gperf itself is GPL, and
I don't see any disclaimer in the docs saying that its output isn't.
regards, tom lane
On Thu, Apr 14, 2011 at 4:10 PM, Tom Lane <tgl@sss.pgh.pa.us> wrote: > Noah Misch <noah@leadboat.com> writes: >> On Thu, Apr 14, 2011 at 11:15:00AM -0700, Robert Haas wrote: >>> It shouldn't be >>> terribly difficult to come up with some kind of hash function based >>> on, say, the first two characters of the keyword that would be a lot >>> faster than what we're doing now. > >> I'd look at `gperf', which generates code for this from your keyword list. > > FWIW, mysql used to use gperf for this purpose, but they've abandoned it > in favor of some homegrown hashing scheme. I don't know exactly why, > but I wonder if it was for licensing reasons. gperf itself is GPL, and > I don't see any disclaimer in the docs saying that its output isn't. I dont think it matters -- see the entry in the bison faq: "Is there some way that I can GPL the output people get from use of my program? For example, if my program is used to develop hardware designs, can I require that these designs must be free? In general this is legally impossible; copyright law does not give you any say in the use of the output people make from their data using your program. If the user uses your program to enter or convert his own data, the copyright on the output belongs to him, not you. More generally, when a program translates its input into some other form, the copyright status of the output inherits that of the input it was generated from." merlin
On Thursday 14 April 2011 23:10:41 Tom Lane wrote: > Noah Misch <noah@leadboat.com> writes: > > On Thu, Apr 14, 2011 at 11:15:00AM -0700, Robert Haas wrote: > >> It shouldn't be > >> terribly difficult to come up with some kind of hash function based > >> on, say, the first two characters of the keyword that would be a lot > >> faster than what we're doing now. > > > > I'd look at `gperf', which generates code for this from your keyword > > list. > > FWIW, mysql used to use gperf for this purpose, but they've abandoned it > in favor of some homegrown hashing scheme. I don't know exactly why, > but I wonder if it was for licensing reasons. gperf itself is GPL, and > I don't see any disclaimer in the docs saying that its output isn't. http://lists.gnu.org/archive/html/bug-gnu-utils/2008-08/msg00005.html : > Thanks for the suggestion; it indeed becomes sort of an FAQ. I've added > > this text to the documentation: > gperf is under GPL, but that does not cause the output produced > by gperf to be under GPL. The reason is that the output contains > only small pieces of text that come directly from gperf's source > code -- only about 7 lines long, too small for being significant --, > and therefore the output is not a "derivative work" of gperf (in the > sense of U.S.@: copyright law). Andres
David Fetter <david@fetter.org> writes:
> On Thu, Apr 14, 2011 at 10:43:16AM -0400, Tom Lane wrote:
>> ... I think a lot of this ultimately
>> traces to the extensible, data-type-agnostic design philosophy. The
>> fact that we don't know what an integer is until we look in pg_type,
>> and don't know what an "=" operator does until we look up its
>> properties, is great from a flexibility point of view; but this sort
>> of query is where the costs become obvious.
> Is it time to revisit that decision?
Umm ... what are you proposing? Toss user-defined data types and
user-defined operators overboard? No interest in that here.
regards, tom lane
On 14.04.2011 23:02, Tom Lane wrote: > Heikki Linnakangas<heikki.linnakangas@enterprisedb.com> writes: >> There's one very low-hanging fruit here, though. I profiled the pgbench >> case, with -M prepared, and found that like in Greg Smith's profile, >> hash_seq_search pops up quite high in the list. Those calls are coming >> from LockReleaseAll(), where we scan the local lock hash to find all >> locks held. We specify the initial size of the local lock hash table as >> 128, which is unnecessarily large for small queries like this. Reducing >> it to 8 slashed the time spent in hash_seq_search(). > >> I think we should make that hash table smaller. It won't buy much, >> somewhere between 1-5 % in this test case, but it's very easy to do and >> I don't see much downside, it's a local hash table so it will grow as >> needed. > > 8 sounds awfully small. Can you even get as far as preparing the > statements you intend to use without causing that to grow? I added a debug print into the locking code, the pgbench test case uses up to 6 locks. It needs those 6 locks at backend startup, for initializing caches I guess. The queries after that need only 3 locks. > I agree that 128 may be larger than necessary, but I don't think we > should pessimize normal usage to gain a small fraction on trivial > queries. I'd be happier with something like 16 or 32. I'll change it to 16. -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
On Thu, Apr 14, 2011 at 05:10:41PM -0400, Tom Lane wrote: > Noah Misch <noah@leadboat.com> writes: > > On Thu, Apr 14, 2011 at 11:15:00AM -0700, Robert Haas wrote: > >> It shouldn't be > >> terribly difficult to come up with some kind of hash function based > >> on, say, the first two characters of the keyword that would be a lot > >> faster than what we're doing now. > > > I'd look at `gperf', which generates code for this from your keyword list. > > FWIW, mysql used to use gperf for this purpose, but they've abandoned it > in favor of some homegrown hashing scheme. I don't know exactly why, > but I wonder if it was for licensing reasons. gperf itself is GPL, and > I don't see any disclaimer in the docs saying that its output isn't. Do you have any details, like when mysql did this? With a quick look, I'm failing to find confirmation that mysql ever did use gperf. (Drizzle has replaced the mysql homegrown scheme with gperf, apparently in 2009, though.)
On Thu, Apr 14, 2011 at 11:16:03PM -0400, Tom Lane wrote: > David Fetter <david@fetter.org> writes: > > On Thu, Apr 14, 2011 at 10:43:16AM -0400, Tom Lane wrote: > >> ... I think a lot of this ultimately traces to the extensible, > >> data-type-agnostic design philosophy. The fact that we don't > >> know what an integer is until we look in pg_type, and don't know > >> what an "=" operator does until we look up its properties, is > >> great from a flexibility point of view; but this sort of query is > >> where the costs become obvious. > > > Is it time to revisit that decision? > > Umm ... what are you proposing? Having a short, default path for the "only built-ins" case. Presumably people who create their own data types, operators, etc., understand that there's a performance trade-off for the feature. Cheers, David. -- David Fetter <david@fetter.org> http://fetter.org/ Phone: +1 415 235 3778 AIM: dfetter666 Yahoo!: dfetter Skype: davidfetter XMPP: david.fetter@gmail.com iCal: webcal://www.tripit.com/feed/ical/people/david74/tripit.ics Remember to vote! Consider donating to Postgres: http://www.postgresql.org/about/donate
Noah Misch <noah@leadboat.com> writes:
> On Thu, Apr 14, 2011 at 05:10:41PM -0400, Tom Lane wrote:
>> FWIW, mysql used to use gperf for this purpose, but they've abandoned it
>> in favor of some homegrown hashing scheme.
> Do you have any details, like when mysql did this? With a quick look, I'm
> failing to find confirmation that mysql ever did use gperf. (Drizzle has
> replaced the mysql homegrown scheme with gperf, apparently in 2009, though.)
Now I'm not sure. The evidence that I based that comment on is that Red
Hat's mysql RPMs have had "BuildRequires: gperf" since forever --- as
far back as I can find in their package CVS anyway --- and I doubt that
would've got put in unless it were really needed to build. But I can't
find any mention of gperf in either the current mysql releases or the
oldest mysql tarball I have, which is mysql 3.23.58. So if it really
was used, it was a very very long time ago. If the Drizzle guys went
in the other direction, that would suggest that they don't have any
institutional memory of having rejected gperf, so maybe that
BuildRequires is just a thinko after all.
regards, tom lane
All, While it would be nice to improve our performance on this workload, let me point out that it's not a very important workloadfrom the point of view of real performance challenges. Yes, there are folks out there with 100MB databases who onlyrun one-liner select queries. But frankly, Valemort/Redis/Mongo are going to whip both our and MySQL's butts on thatkind of workload anyway. Certainly any sacrifice of functionality in order to be faster at that kind of trivial workload would be foolhardy. -- Josh Berkus PostgreSQL Experts Inc. http://pgexperts.com San Francisco
On 04/15/2011 09:59 AM, Joshua Berkus wrote: > All, > > While it would be nice to improve our performance on this workload, let me point out that it's not a very important workloadfrom the point of view of real performance challenges. Yes, there are folks out there with 100MB databases who onlyrun one-liner select queries. But frankly, Valemort/Redis/Mongo are going to whip both our and MySQL's butts on thatkind of workload anyway. Yes but if we can kick MySQL's butt, that would certainly be a good thing. There are people (lots of people) that do not like the whole Valemort/Redis/Mongo paradigm. > Certainly any sacrifice of functionality in order to be faster at that kind of trivial workload would be foolhardy. Agreed. JD
Joshua Berkus <josh@agliodbs.com> writes:
> Certainly any sacrifice of functionality in order to be faster at that kind of trivial workload would be foolhardy.
Yeah, and I'd further say that any sacrifice of maintainability would be
equally foolhardy. In particular I'm repelled by David's proposal of a
whole parallel parse/plan/execute chain for "standard" datatypes
(whichever those are).
regards, tom lane
I did some more research into the memory allocation hotspots found in the profile, in regards to what MySQL has done in those areas. (And by "research" I mean "went to the bar last night and asked Baron about it") The issue of memory allocation being a limiter on performance has been nagging that community for long enough that the underlying malloc used can even be swapped with a LD_PRELOAD trick: http://dev.mysql.com/doc/refman/5.5/en/mysqld-safe.html#option_mysqld_safe_malloc-lib Plenty of people have benchmarked that and seen a big difference between the implementations; some sample graphs: http://locklessinc.com/articles/mysql_performance/ http://blogs.sun.com/timc/entry/mysql_5_1_memory_allocator http://mysqlha.blogspot.com/2009/01/double-sysbench-throughput-with_18.html To quote from the last of those, "Malloc is a bottleneck for sysbench OLTP readonly", so this problem is not unique to PostgreSQL. As of 5.5 the better builds are all defaulting to TCMalloc, which is interesting but probably not as useful because it's focused on improving multi-threaded performance: http://goog-perftools.sourceforge.net/doc/tcmalloc.html I'm not sure exactly what is useful to be learned from that specific work. But it does suggest two things: one, this is far from an easy thing to fix. Two, the only reason MySQL does so well on it is because there was some focused work on it, taking a quite a while to accomplish, and involving many people. Doing better for PostgreSQL is something I see as more of a long-term goal, rather than something it would be reasonable to expect quick progress on. -- Greg Smith 2ndQuadrant US greg@2ndQuadrant.com Baltimore, MD PostgreSQL Training, Services, and 24x7 Support www.2ndQuadrant.us
Greg Smith <greg@2ndquadrant.com> wrote: > I'm not sure exactly what is useful to be learned from that > specific work. But it does suggest two things: one, this is far > from an easy thing to fix. Two, the only reason MySQL does so > well on it is because there was some focused work on it, taking a > quite a while to accomplish, and involving many people. Doing > better for PostgreSQL is something I see as more of a long-term > goal, rather than something it would be reasonable to expect quick > progress on. Nice research. Thanks for putting that in front of people. -Kevin