Thread: There's random access and then there's random access
Recently there was a post on -performance about a particular case where Postgres doesn't make very good use of the I/O system. This is when you try to fetch many records spread throughout a table in random order. http://archives.postgresql.org/pgsql-performance/2007-12/msg00005.php Currently Postgres reads each record as needed and processes it. This means even if you have a large raid array you get no benefit from it since you're limited by the latency of each request. The raid array might let you run more queries simultaneously but not improve the response time of a single query. But in most cases, as in the use case in the email message above, we can do substantially better. We can arrange to issue all the read requests without blocking, then process the blocks either as they come in or in the order we want blocking until they're actually satisfied. Handling them as they come in is in theory more efficient but either way I would expect to see more or less a speedup nearly equal to the number of drives in the array. Even on a single drive it should slightly improve performance as it allows us to do some CPU work while the I/O requests are pending. The two interfaces I'm aware of for this are posix_fadvise() and libaio. I've run tests with a synthetic benchmark which generates a large file then reads a random selection of blocks from within it using either synchronous reads like we do now or either of those interfaces. I saw impressive speed gains on a machine with only three drives in a raid array. I did this a while ago so I don't have the results handy. I'll rerun the tests again and post them. I think this will be easiest to do for bitmap index scans. Since we gather up all the pages we'll need before starting the heap scan we can easily skim through them, issue posix_fadvises for at least a certain number ahead of the actual read point and then proceed with the rest of the scan unchanged. For regular index scans I'm not sure how easy it will be to beat them into doing this but I suspect it might not be too hard to at least prefetch the tuples in the page-at-a-time buffer. That's probably safer too since for such scans we're more likely to not actually read all the results anyways; there could be a limit or something else above which will stop us. -- Gregory Stark EnterpriseDB http://www.enterprisedb.com Get trained by Bruce Momjian - ask me about EnterpriseDB'sPostgreSQL training!
On 12/2/07, Gregory Stark <stark@enterprisedb.com> wrote: > > The two interfaces I'm aware of for this are posix_fadvise() and libaio. I've > run tests with a synthetic benchmark which generates a large file then reads a > random selection of blocks from within it using either synchronous reads like > we do now or either of those interfaces. I saw impressive speed gains on a > machine with only three drives in a raid array. I did this a while ago so I > don't have the results handy. I'll rerun the tests again and post them. The issue I've always seen raised with asynchronous I/O is portability--apparently some platforms PG runs on don't support it (or not well). AIUI Linux actually still has a fairly crappy implementation of AIO--glibc starts threads to do the I/O and then tracks when they finish. Not absolutely horrible, but a nice way to suddenly have a threaded backend when you're not expecting one. -Doug
"Douglas McNaught" <doug@mcnaught.org> writes: > On 12/2/07, Gregory Stark <stark@enterprisedb.com> wrote: >> >> The two interfaces I'm aware of for this are posix_fadvise() and libaio. I've >> run tests with a synthetic benchmark which generates a large file then reads a >> random selection of blocks from within it using either synchronous reads like >> we do now or either of those interfaces. I saw impressive speed gains on a >> machine with only three drives in a raid array. I did this a while ago so I >> don't have the results handy. I'll rerun the tests again and post them. > > The issue I've always seen raised with asynchronous I/O is > portability--apparently some platforms PG runs on don't support it (or > not well). AIUI Linux actually still has a fairly crappy > implementation of AIO--glibc starts threads to do the I/O and then > tracks when they finish. Not absolutely horrible, but a nice way to > suddenly have a threaded backend when you're not expecting one. In the tests I ran Linux's posix_fadvise worked well and that's the simpler interface for us to adapt to anyways. On Solaris there was no posix_fadvise but libaio worked instead. -- Gregory Stark EnterpriseDB http://www.enterprisedb.com Get trained by Bruce Momjian - ask me about EnterpriseDB'sPostgreSQL training!
Gregory Stark <stark@enterprisedb.com> writes: > Recently there was a post on -performance about a particular case where > Postgres doesn't make very good use of the I/O system. This is when you try to > fetch many records spread throughout a table in random order. > http://archives.postgresql.org/pgsql-performance/2007-12/msg00005.php Since the OP in that thread has still supplied zero information (no EXPLAIN, let alone ANALYZE, and no version info), it's pure guesswork as to what his problem is. regards, tom lane
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 Tom Lane wrote: > Gregory Stark <stark@enterprisedb.com> writes: >> Recently there was a post on -performance about a particular case where >> Postgres doesn't make very good use of the I/O system. This is when you try to >> fetch many records spread throughout a table in random order. > >> http://archives.postgresql.org/pgsql-performance/2007-12/msg00005.php > > Since the OP in that thread has still supplied zero information > (no EXPLAIN, let alone ANALYZE, and no version info), it's pure > guesswork as to what his problem is. Nonetheless, asynchronous IO will reap performance improvements. Wether a specific case would indeed benefit from it is imho irrelevant, if other cases can indeed be found, where performance would be improved significantly. I experimented with a raid of 8 solid state devices, and found that the blocks/second for random access improved signifacantly with the number of processes doing the access. I actually wanted to use said raid as a tablespace for postgresql, and alas, the speedup did not depend on the number of drives in the raid, which is very unfortunate. I still got the lower solid-state latency, but the raid did not help. Regards, Jens-Wolfhard Schicke -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.6 (GNU/Linux) iD8DBQFHUwM7zhchXT4RR5ARAsziAJ9qm/c8NuaJ+HqoJo9Ritb2t92fRwCgnF9J r5YU/Fa0mNYG7YXed4QW7K4= =Mvyj -----END PGP SIGNATURE-----
"Tom Lane" <tgl@sss.pgh.pa.us> writes: > Gregory Stark <stark@enterprisedb.com> writes: >> Recently there was a post on -performance about a particular case where >> Postgres doesn't make very good use of the I/O system. This is when you try to >> fetch many records spread throughout a table in random order. > >> http://archives.postgresql.org/pgsql-performance/2007-12/msg00005.php > > Since the OP in that thread has still supplied zero information > (no EXPLAIN, let alone ANALYZE, and no version info), it's pure > guesswork as to what his problem is. Sure, consider it a hypothetical which needs further experimentation. That's part of why I ran (and will rerun) those synthetic benchmarks to test whether posix_fadvise() actually speeds up subsequent reads on a few operating systems. Surely any proposed patch will have to prove itself on empirical grounds too. I could swear this has been discussed in the past too. I seem to recall Luke disparaging Postgres on the same basis but proposing an immensely complicated solution. posix_fadvise or using libaio in a simplistic fashion as a kind of fadvise would be fairly lightweight way to get most of the benefit of the more complex solutions. -- Gregory Stark EnterpriseDB http://www.enterprisedb.com Get trained by Bruce Momjian - ask me about EnterpriseDB'sPostgreSQL training!
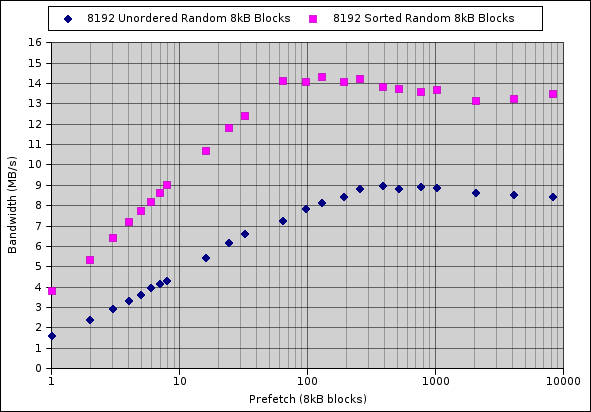
"Gregory Stark" <stark@enterprisedb.com> writes: > The two interfaces I'm aware of for this are posix_fadvise() and libaio. > I've run tests with a synthetic benchmark which generates a large file then > reads a random selection of blocks from within it using either synchronous > reads like we do now or either of those interfaces. I saw impressive speed > gains on a machine with only three drives in a raid array. I did this a > while ago so I don't have the results handy. I'll rerun the tests again and > post them. Here's the results of running the synthetic test program on a 3-drive raid array. Note that the results *exceeded* the 3x speedup I expected, even for ordered blocks. Either the drive (or the OS) is capable of reordering the block requests better than the offset into the file would appear or some other effect is kicking in. The test is with an 8GB file, picking 8,192 random 8k blocks from within it. The pink diamonds represent the bandwidth obtained if the random blocks are sorted before fetching (like a bitmap indexscan) and the blue if they're unsorted. for i in 1 2 3 4 5 6 7 8 16 24 32 64 96 128 192 256 384 512 768 1024 2048 4096 8192 ; do ./a.out pfa2 /mnt/data/test.data 8388608 8192 $i 8192 false ; done >> test-pfa-results for i in 1 2 3 4 5 6 7 8 16 24 32 64 96 128 192 256 384 512 768 1024 2048 4096 8192 ; do ./a.out pfa2 /mnt/data/test.data 8388608 8192 $i 8192 true ; done >> test-pfa-results -- Gregory Stark EnterpriseDB http://www.enterprisedb.com Ask me about EnterpriseDB's Slony Replication support!
Attachment
{kind=link}
Gregory Stark wrote: <blockquote cite="mid:87ve7egxow.fsf@oxford.xeocode.com" type="cite"><pre wrap="">"Gregory Stark" <aclass="moz-txt-link-rfc2396E" href="mailto:stark@enterprisedb.com"><stark@enterprisedb.com></a> writes</pre><blockquotetype="cite"><pre wrap="">The two interfaces I'm aware of for this are posix_fadvise() and libaio. I've run tests with a synthetic benchmark which generates a large file then reads a random selection of blocks from within it using either synchronous reads like we do now or either of those interfaces. I saw impressive speed gains on a machine with only three drives in a raid array. I did this a while ago so I don't have the results handy. I'll rerun the tests again and post them. </pre></blockquote><pre wrap="">Here's the results of running the synthetic test program on a 3-drive raid array. Note that the results *exceeded* the 3x speedup I expected, even for ordered blocks. Either the drive (or the OS) is capable of reordering the block requests better than the offset into the file would appear or some other effect is kicking in. The test is with an 8GB file, picking 8,192 random 8k blocks from within it. The pink diamonds represent the bandwidth obtained if the random blocks are sorted before fetching (like a bitmap indexscan) and the blue if they're unsorted. </pre></blockquote> I didn't see exceeded 3X in the graph. But I certainly see 2X+ for most of the graphic, and~3X for very small reads. Possibly, it is avoiding unnecessary read-ahead at the drive or OS levels? <br /><br /> I thinkwe expected to see raw reads significantly faster for the single process case. I thought your simulation was going toinvolve a tweak to PostgreSQL on a real query to see what overall effect it would have on typical queries and on specialqueries like Matthew's. Are you able to tweak the index scan and bitmap scan methods to do posfix_fadvise() beforerunning? Even if it doesn't do anything more intelligent such as you described in another post?<br /><br /> Cheers,<br/> mark<br /><br /><pre class="moz-signature" cols="72">-- Mark Mielke <a class="moz-txt-link-rfc2396E" href="mailto:mark@mielke.cc"><mark@mielke.cc></a> </pre>
"Mark Mielke" <mark@mark.mielke.cc> writes: > I didn't see exceeded 3X in the graph. But I certainly see 2X+ for most of the > graphic, and ~3X for very small reads. Possibly, it is avoiding unnecessary > read-ahead at the drive or OS levels? Then you're misreading the graph -- which would be my fault, my picture was only worth 500 words then. Ordered scans (simulating a bitmap index scan) is getting 3.8 MB/s a prefetch of 1 (effectively no prefetch) and 14.1 MB/s with a prefetch of 64. That's a factor of 3.7! Unordered scans have an even larger effect (unsurprisingly) going from 1.6MB/s to 8.9MB/s or a factor of 5.6. Another surprising bit is that prefetching 8192 blocks, ie, the whole set, doesn't erase the advantage of the presorting. I would have expected that when prefetching all the blocks it would make little difference what order we feed them to posix_fadvise. I guess since the all the blocks which have had i/o initiated on them haven't been read in yet when we reach the first real read() that forces some blocks to be read out-of-order. I'm surprised it makes nearly a 2x speed difference though. > I think we expected to see raw reads significantly faster for the single > process case. I thought your simulation was going to involve a tweak to > PostgreSQL on a real query to see what overall effect it would have on typical > queries and on special queries like Matthew's. Are you able to tweak the index > scan and bitmap scan methods to do posfix_fadvise() before running? Even if it > doesn't do anything more intelligent such as you described in another post? That's the next step. I'm debating between two ways to structure the code right now. Do I put the logic to peek ahead in nodeBitmapHeapScan to read ahead and remember the info seen or in tidbitmap with an new api function which is only really useful for this one use case. -- Gregory Stark EnterpriseDB http://www.enterprisedb.com Ask me about EnterpriseDB's Slony Replication support!
"Mark Mielke" <mark@mark.mielke.cc> writes: > I didn't see exceeded 3X in the graph. But I certainly see 2X+ for most of the > graphic, and ~3X for very small reads. Possibly, it is avoiding unnecessary > read-ahead at the drive or OS levels? Ahh! I think I see how you're misreading it now. You're comparing the pink with the blue. That's not what's going on. The X axis (which is logarithmic) is the degree of prefetch. So "1" means it's prefetching one block then immediately reading it -- effectively not prefetching at all. 10000 (actually the last data point is 8192) is completely prefetching the whole data set. The two data sets are the same tests run with ordered (ie, like a bitmap scan) or unordered (ie, like a regular index scan) blocks. Unsurprisingly ordered sets read faster with low levels of prefetch and both get faster the more blocks you prefetch. What's surprising to me is that the advantage of the ordered blocks doesn't diminish with prefetching. -- Gregory Stark EnterpriseDB http://www.enterprisedb.com Ask me about EnterpriseDB's On-Demand Production Tuning
On Dec 4, 2007, at 1:42 PM, Gregory Stark wrote: > I'm debating between two ways to structure the code right now. Do I > put the > logic to peek ahead in nodeBitmapHeapScan to read ahead and > remember the info > seen or in tidbitmap with an new api function which is only really > useful for > this one use case. There has been discussion of having a bg_reader, similar to the bg_writer. Perhaps that would be better than creating something that's specific to bitmap scans? Also, I would expect to see a speed improvement even on single drives if the OS is actually issuing multiple requests to the drive. Doing so allows the drive to optimally order all of the reads. -- Decibel!, aka Jim C. Nasby, Database Architect decibel@decibel.org Give your computer some brain candy! www.distributed.net Team #1828
"Decibel!" <decibel@decibel.org> writes: > On Dec 4, 2007, at 1:42 PM, Gregory Stark wrote: >> I'm debating between two ways to structure the code right now. Do I put the >> logic to peek ahead in nodeBitmapHeapScan to read ahead and remember the >> info >> seen or in tidbitmap with an new api function which is only really useful >> for >> this one use case. > > > There has been discussion of having a bg_reader, similar to the bg_writer. > Perhaps that would be better than creating something that's specific to bitmap > scans? Has there? AFAICT a bg_reader only makes sense if we move to a direct-i/o situation where we're responsible for read-ahead and have to read into shared buffers any blocks we decide are interesting to readahead. Regardless of what mechanism is used and who is responsible for doing it someone is going to have to figure out which blocks are specifically interesting to prefetch. Bitmap index scans happen to be the easiest since we've already built up a list of blocks we plan to read. Somehow that information has to be pushed to the storage manager to be acted upon. Normal index scans are an even more interesting case but I'm not sure how hard it would be to get that information. It may only be convenient to get the blocks from the last leaf page we looked at, for example. > Also, I would expect to see a speed improvement even on single drives if the > OS is actually issuing multiple requests to the drive. Doing so allows the > drive to optimally order all of the reads. Sure, but a 2x speed improvement? That's way more than I was expecting -- Gregory Stark EnterpriseDB http://www.enterprisedb.com Get trained by Bruce Momjian - ask me about EnterpriseDB'sPostgreSQL training!
"Gregory Stark" <stark@enterprisedb.com> writes:
> I think this will be easiest to do for bitmap index scans. Since we gather up
> all the pages we'll need before starting the heap scan we can easily skim
> through them, issue posix_fadvises for at least a certain number ahead of the
> actual read point and then proceed with the rest of the scan unchanged.
I've written up a simple test implementation of prefetching using
posix_fadvise(). Here are some nice results on a query accessing 1,000 records
from a 10G table with 300 million records:
postgres=# set preread_pages=0; explain analyze select (select count(*) from h where h = any (x)) from (select
random_array(1000,1,300000000)as x)x;
SET QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------Subquery
Scanx (cost=0.00..115.69 rows=1 width=32) (actual time=6069.505..6069.509 rows=1 loops=1) -> Result
(cost=0.00..0.01rows=1 width=0) (actual time=0.058..0.061 rows=1 loops=1) SubPlan -> Aggregate
(cost=115.66..115.67rows=1 width=0) (actual time=6069.425..6069.426 rows=1 loops=1) -> Bitmap Heap Scan on h
(cost=75.49..115.63rows=10 width=0) (actual time=3543.107..6068.335 rows=1000 loops=1) Recheck Cond: (h
=ANY ($0)) -> Bitmap Index Scan on hi (cost=0.00..75.49 rows=10 width=0) (actual
time=3542.220..3542.220rows=1000 loops=1) Index Cond: (h = ANY ($0))Total runtime: 6069.632 ms
(9 rows)
postgres=# set preread_pages=300; explain analyze select (select count(*) from h where h = any (x)) from (select
random_array(1000,1,300000000)as x)x;
SET QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------Subquery
Scanx (cost=0.00..115.69 rows=1 width=32) (actual time=3945.602..3945.607 rows=1 loops=1) -> Result
(cost=0.00..0.01rows=1 width=0) (actual time=0.060..0.064 rows=1 loops=1) SubPlan -> Aggregate
(cost=115.66..115.67rows=1 width=0) (actual time=3945.520..3945.521 rows=1 loops=1) -> Bitmap Heap Scan on h
(cost=75.49..115.63rows=10 width=0) (actual time=3505.546..3944.817 rows=1000 loops=1) Recheck Cond: (h
=ANY ($0)) -> Bitmap Index Scan on hi (cost=0.00..75.49 rows=10 width=0) (actual
time=3452.759..3452.759rows=1000 loops=1) Index Cond: (h = ANY ($0))Total runtime: 3945.730 ms
(9 rows)
Note that while the query itself is only 50% faster the bitmap heap scan
specifically is actually 575% faster than without readahead.
It would be nice to optimize the bitmap index scan as well but that will be a
bit trickier and it probably won't be able to cover as many pages. As a result
it probably won't be a 5x speedup like the heap scan.
Also, this is with a fairly aggressive readahead which only makes sense for
queries that look a lot like this and will read all the tuples. For a more
general solution I think it would make sense to water down the performance a
bit in exchange for some protection against doing unnecessary I/O in cases
where the query isn't actually going to read all the tuples.
-- Gregory Stark EnterpriseDB http://www.enterprisedb.com Ask me about EnterpriseDB's 24x7 Postgres support!
Gregory Stark wrote: > I could swear this has been discussed in the past too. I seem to recall Luke > disparaging Postgres on the same basis but proposing an immensely complicated > solution. posix_fadvise or using libaio in a simplistic fashion as a kind of > fadvise would be fairly lightweight way to get most of the benefit of the more > complex solutions. It has been on the TODO list for a long time:* Do async I/O for faster random read-ahead of data Async I/O allows multipleI/O requests to be sent to the disk with results coming back asynchronously. http://archives.postgresql.org/pgsql-hackers/2006-10/msg00820.php I have added your thread URL to this. -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://postgres.enterprisedb.com + If your life is a hard drive, Christ can be your backup. +
On Wed, Dec 05, 2007 at 01:49:20AM +0000, Gregory Stark wrote: > Regardless of what mechanism is used and who is responsible for doing it > someone is going to have to figure out which blocks are specifically > interesting to prefetch. Bitmap index scans happen to be the easiest since > we've already built up a list of blocks we plan to read. Somehow that > information has to be pushed to the storage manager to be acted upon. > > Normal index scans are an even more interesting case but I'm not sure how hard > it would be to get that information. It may only be convenient to get the > blocks from the last leaf page we looked at, for example. I guess it depends on how you're looking at things... I'm thinking more in terms of telling the OS to fetch stuff we're pretty sure we're going to need while we get on with other work. There's a lot of cases where you know that besides just a bitmap scan (though perhaps code-wise bitmap scan is easier to implement...) For a seqscan, we'd want to be reading some number of blocks ahead of where we're at right now. Ditto for index pages on an index scan. In addition, when we're scanning the index, we'd definitely want to issue heap page requests asynchronously, since that gives the filesystem, etc a better shot at re-ordering the reads to improve performance. -- Decibel!, aka Jim C. Nasby, Database Architect decibel@decibel.org Give your computer some brain candy! www.distributed.net Team #1828