Thread: Group Commit
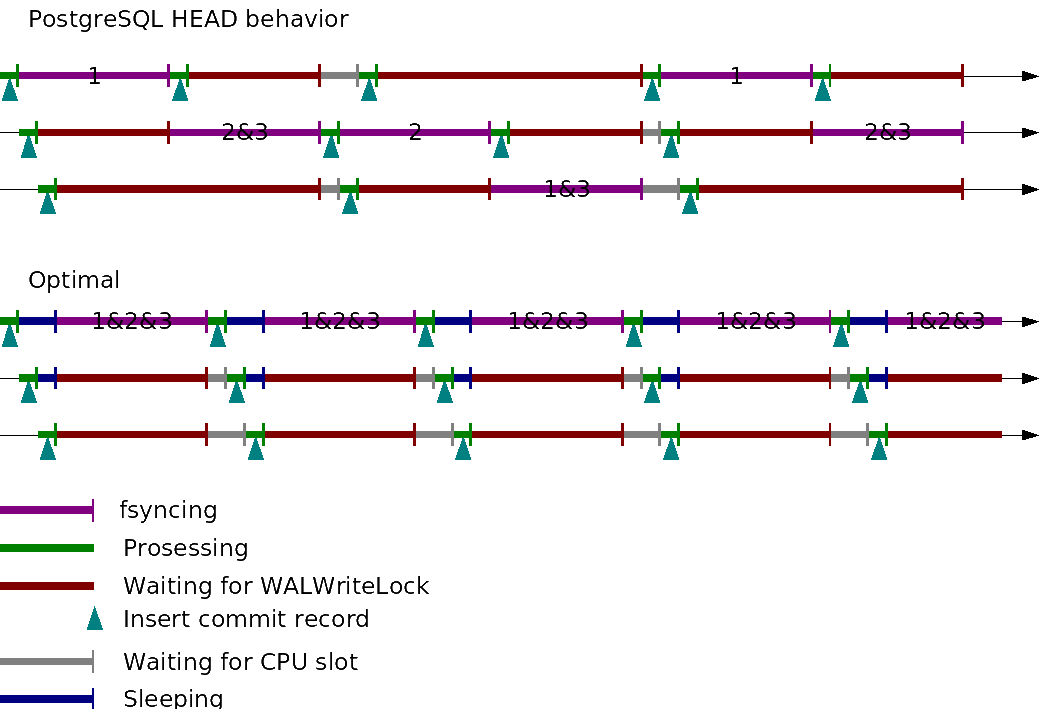
It's been known for years that commit_delay isn't very good at giving us group commit behavior. I did some experiments with this simple test case: "BEGIN; INSERT INTO test VALUES (1); COMMIT;", with different numbers of concurrent clients and with and without commit_delay. Summary for the impatient: 1. Current behavior sucks. 2. commit_delay doesn't help with # of clients < ~10. It does help with higher numbers, but it still sucks. 3. I'm working on a patch. I added logging to show how many commit records are flushed on each fsync. The output with otherwise unpatched PG head looks like this, with 5 clients: LOG: Flushed 4 out of 5 commits LOG: Flushed 1 out of 5 commits LOG: Flushed 4 out of 5 commits LOG: Flushed 1 out of 5 commits LOG: Flushed 4 out of 5 commits LOG: Flushed 1 out of 5 commits LOG: Flushed 4 out of 5 commits LOG: Flushed 1 out of 5 commits LOG: Flushed 3 out of 5 commits LOG: Flushed 2 out of 5 commits LOG: Flushed 3 out of 5 commits LOG: Flushed 2 out of 5 commits LOG: Flushed 3 out of 5 commits LOG: Flushed 2 out of 5 commits LOG: Flushed 3 out of 5 commits ... Here's what's happening: 1. Client 1 issues fsync (A) 2. Clients 2-5 write their commit record, and try to fsync, but they have to wait for fsync (A) to finish. 3. fsync (A) finishes, freeing client 1. 4. One of clients 2-5 starts the next fsync (B), which will flush commits of clients 2-5 to disk 5. Client 1 begins new transaction, inserts commit record and tries to fsync. Needs to wait for previous fsync (B) to finish 6. fsync B finishes, freeing clients 2-5 7. Client 1 issues fsync (C) 8. ... The 2-3-2-3 pattern can be explained with similar unfortunate "resonance", but with two clients instead of client 1 in the above possibly running in separate cores (test was run on a dual-core laptop). I also draw a diagram illustrating the above, attached. I wrote a quick & dirty patch for this that I'm going to refine further, but wanted to get the results out for others to look at first. I'm not posting the patch yet, but it basically adds some synchronization to the WAL flushes. It introduces a counter of inserted but not yet flushed commit records. Instead of the commit_delay, the counter is checked. If it's smaller than NBackends, the process waits until count reaches NBackends, or a timeout expires. There's two significant differences to commit_delay here: 1. Instead of waiting for commit_delay to expire, processes are woken and fsync is started immediately when we know there's no more commit records coming that we should wait for. Even though commit_delay is given in microseconds, the real granularity of the wait can be as high as 10 ms, which is in the same ball park as the fsync itself. 2. commit_delay is not used when there's less than commit_siblings non-idle backends in the system. With very short transactions, it's worthwhile to wait even if that's the case, because a client can begin and finish a transaction in much shorter time than it takes to fsync. This is what makes the commit_delay to not work at all in my test case with 2 clients. Here's a spreadsheet with the results of the tests I ran: http://community.enterprisedb.com/groupcommit-comparison.ods It contains a graph that shows that the patch works very well for this test case. It's not very good for real life as it is, though. An obvious flaw is that if you have a longer-running transaction, effect 1. goes away. Instead of waiting for NBackends commit records, we should try to guess the number of transactions that are likely to finish in a reasonably short time. I'm thinking of keeping a running average of commits per second, or # of transactions that finish while an fsync is taking place. Any thoughts? -- Heikki Linnakangas EnterpriseDB http://www.enterprisedb.com
Attachment
{kind=link}
Heikki Linnakangas wrote: > Here's what's happening: > > 1. Client 1 issues fsync (A) > 2. Clients 2-5 write their commit record, and try to fsync, but they > have to wait for fsync (A) to finish. > It contains a graph that shows that the patch works very well for this > test case. It's not very good for real life as it is, though. An obvious > flaw is that if you have a longer-running transaction, effect 1. goes > away. Instead of waiting for NBackends commit records, we should try to > guess the number of transactions that are likely to finish in a > reasonably short time. I'm thinking of keeping a running average of > commits per second, or # of transactions that finish while an fsync is > taking place. > > Any thoughts? Well, you did say *any* thoughts, so I guess mine count :-) Do you not want to minimise the cost of #2 in your sequence? Some measure of "total backend time spent waiting to commit". I don't know how simple it is to measure/estimate the time spent for "# of transactions that finish while an fsync is taking place". -- Richard Huxton Archonet Ltd
This is not ready for 8.3. This has been saved for the 8.4 release: http://momjian.postgresql.org/cgi-bin/pgpatches_hold --------------------------------------------------------------------------- Heikki Linnakangas wrote: > It's been known for years that commit_delay isn't very good at giving us > group commit behavior. I did some experiments with this simple test > case: "BEGIN; INSERT INTO test VALUES (1); COMMIT;", with different > numbers of concurrent clients and with and without commit_delay. > > Summary for the impatient: > 1. Current behavior sucks. > 2. commit_delay doesn't help with # of clients < ~10. It does help with > higher numbers, but it still sucks. > 3. I'm working on a patch. > > > I added logging to show how many commit records are flushed on each > fsync. The output with otherwise unpatched PG head looks like this, with > 5 clients: > > LOG: Flushed 4 out of 5 commits > LOG: Flushed 1 out of 5 commits > LOG: Flushed 4 out of 5 commits > LOG: Flushed 1 out of 5 commits > LOG: Flushed 4 out of 5 commits > LOG: Flushed 1 out of 5 commits > LOG: Flushed 4 out of 5 commits > LOG: Flushed 1 out of 5 commits > LOG: Flushed 3 out of 5 commits > LOG: Flushed 2 out of 5 commits > LOG: Flushed 3 out of 5 commits > LOG: Flushed 2 out of 5 commits > LOG: Flushed 3 out of 5 commits > LOG: Flushed 2 out of 5 commits > LOG: Flushed 3 out of 5 commits > ... > > Here's what's happening: > > 1. Client 1 issues fsync (A) > 2. Clients 2-5 write their commit record, and try to fsync, but they > have to wait for fsync (A) to finish. > 3. fsync (A) finishes, freeing client 1. > 4. One of clients 2-5 starts the next fsync (B), which will flush > commits of clients 2-5 to disk > 5. Client 1 begins new transaction, inserts commit record and tries to > fsync. Needs to wait for previous fsync (B) to finish > 6. fsync B finishes, freeing clients 2-5 > 7. Client 1 issues fsync (C) > 8. ... > > The 2-3-2-3 pattern can be explained with similar unfortunate > "resonance", but with two clients instead of client 1 in the above > possibly running in separate cores (test was run on a dual-core laptop). > > I also draw a diagram illustrating the above, attached. > > I wrote a quick & dirty patch for this that I'm going to refine further, > but wanted to get the results out for others to look at first. I'm not > posting the patch yet, but it basically adds some synchronization to the > WAL flushes. It introduces a counter of inserted but not yet flushed > commit records. Instead of the commit_delay, the counter is checked. If > it's smaller than NBackends, the process waits until count reaches > NBackends, or a timeout expires. There's two significant differences to > commit_delay here: > 1. Instead of waiting for commit_delay to expire, processes are woken > and fsync is started immediately when we know there's no more commit > records coming that we should wait for. Even though commit_delay is > given in microseconds, the real granularity of the wait can be as high > as 10 ms, which is in the same ball park as the fsync itself. > 2. commit_delay is not used when there's less than commit_siblings > non-idle backends in the system. With very short transactions, it's > worthwhile to wait even if that's the case, because a client can begin > and finish a transaction in much shorter time than it takes to fsync. > This is what makes the commit_delay to not work at all in my test case > with 2 clients. > > Here's a spreadsheet with the results of the tests I ran: > http://community.enterprisedb.com/groupcommit-comparison.ods > > It contains a graph that shows that the patch works very well for this > test case. It's not very good for real life as it is, though. An obvious > flaw is that if you have a longer-running transaction, effect 1. goes > away. Instead of waiting for NBackends commit records, we should try to > guess the number of transactions that are likely to finish in a > reasonably short time. I'm thinking of keeping a running average of > commits per second, or # of transactions that finish while an fsync is > taking place. > > Any thoughts? > > -- > Heikki Linnakangas > EnterpriseDB http://www.enterprisedb.com > > ---------------------------(end of broadcast)--------------------------- > TIP 9: In versions below 8.0, the planner will ignore your desire to > choose an index scan if your joining column's datatypes do not > match -- Bruce Momjian <bruce@momjian.us> http://momjian.us EnterpriseDB http://www.enterprisedb.com + If your life is a hard drive, Christ can be your backup. +