Thread: ARC Memory Usage analysis
I've been using the ARC debug options to analyse memory usage on the PostgreSQL 8.0 server. This is a precursor to more complex performance analysis work on the OSDL test suite. I've simplified some of the ARC reporting into a single log line, which is enclosed here as a patch on freelist.c. This includes reporting of: - the total memory in use, which wasn't previously reported - the cache hit ratio, which was slightly incorrectly calculated - a useful-ish value for looking at the "B" lists in ARC (This is a patch against cvstip, but I'm not sure whether this has potential for inclusion in 8.0...) The total memory in use is useful because it allows you to tell whether shared_buffers is set too high. If it is set too high, then memory usage will continue to grow slowly up to the max, without any corresponding increase in cache hit ratio. If shared_buffers is too small, then memory usage will climb quickly and linearly to its maximum. The last one I've called "turbulence" in an attempt to ascribe some useful meaning to B1/B2 hits - I've tried a few other measures though without much success. Turbulence is the hit ratio of B1+B2 lists added together. By observation, this is zero when ARC gives smooth operation, and goes above zero otherwise. Typically, turbulence occurs when shared_buffers is too small for the working set of the database/workload combination and ARC repeatedly re-balances the lengths of T1/T2 as a result of "near-misses" on the B1/B2 lists. Turbulence doesn't usually cut in until the cache is fully utilized, so there is usually some delay after startup. We also recently discussed that I would add some further memory analysis features for 8.1, so I've been trying to figure out how. The idea that B1, B2 represent something really useful doesn't seem to have been borne out - though I'm open to persuasion there. I originally envisaged a "shadow list" operating in extension of the main ARC list. This will require some re-coding, since the variables and macros are all hard-coded to a single set of lists. No complaints, just it will take a little longer than we all thought (for me, that is...) My proposal is to alter the code to allow an array of memory linked lists. The actual list would be [0] - other additional lists would be created dynamically as required i.e. not using IFDEFs, since I want this to be controlled by a SIGHUP GUC to allow on-site tuning, not just lab work. This will then allow reporting against the additional lists, so that cache hit ratios can be seen with various other "prototype" shared_buffer settings. Any thoughts? -- Best Regards, Simon Riggs
Attachment
On 10/22/2004 2:50 PM, Simon Riggs wrote:
> I've been using the ARC debug options to analyse memory usage on the
> PostgreSQL 8.0 server. This is a precursor to more complex performance
> analysis work on the OSDL test suite.
>
> I've simplified some of the ARC reporting into a single log line, which
> is enclosed here as a patch on freelist.c. This includes reporting of:
> - the total memory in use, which wasn't previously reported
> - the cache hit ratio, which was slightly incorrectly calculated
> - a useful-ish value for looking at the "B" lists in ARC
> (This is a patch against cvstip, but I'm not sure whether this has
> potential for inclusion in 8.0...)
>
> The total memory in use is useful because it allows you to tell whether
> shared_buffers is set too high. If it is set too high, then memory usage
> will continue to grow slowly up to the max, without any corresponding
> increase in cache hit ratio. If shared_buffers is too small, then memory
> usage will climb quickly and linearly to its maximum.
>
> The last one I've called "turbulence" in an attempt to ascribe some
> useful meaning to B1/B2 hits - I've tried a few other measures though
> without much success. Turbulence is the hit ratio of B1+B2 lists added
> together. By observation, this is zero when ARC gives smooth operation,
> and goes above zero otherwise. Typically, turbulence occurs when
> shared_buffers is too small for the working set of the database/workload
> combination and ARC repeatedly re-balances the lengths of T1/T2 as a
> result of "near-misses" on the B1/B2 lists. Turbulence doesn't usually
> cut in until the cache is fully utilized, so there is usually some delay
> after startup.
>
> We also recently discussed that I would add some further memory analysis
> features for 8.1, so I've been trying to figure out how.
>
> The idea that B1, B2 represent something really useful doesn't seem to
> have been borne out - though I'm open to persuasion there.
>
> I originally envisaged a "shadow list" operating in extension of the
> main ARC list. This will require some re-coding, since the variables and
> macros are all hard-coded to a single set of lists. No complaints, just
> it will take a little longer than we all thought (for me, that is...)
>
> My proposal is to alter the code to allow an array of memory linked
> lists. The actual list would be [0] - other additional lists would be
> created dynamically as required i.e. not using IFDEFs, since I want this
> to be controlled by a SIGHUP GUC to allow on-site tuning, not just lab
> work. This will then allow reporting against the additional lists, so
> that cache hit ratios can be seen with various other "prototype"
> shared_buffer settings.
All the existing lists live in shared memory, so that dynamic approach
suffers from the fact that the memory has to be allocated during ipc_init.
What do you think about my other theory to make C actually 2x effective
cache size and NOT to keep T1 in shared buffers but to assume T1 lives
in the OS buffer cache?
Jan
>
> Any thoughts?
>
>
>
> ------------------------------------------------------------------------
>
> Index: freelist.c
> ===================================================================
> RCS file: /projects/cvsroot/pgsql/src/backend/storage/buffer/freelist.c,v
> retrieving revision 1.48
> diff -d -c -r1.48 freelist.c
> *** freelist.c 16 Sep 2004 16:58:31 -0000 1.48
> --- freelist.c 22 Oct 2004 18:15:38 -0000
> ***************
> *** 126,131 ****
> --- 126,133 ----
> if (StrategyControl->stat_report + DebugSharedBuffers < now)
> {
> long all_hit,
> + buf_used,
> + b_hit,
> b1_hit,
> t1_hit,
> t2_hit,
> ***************
> *** 155,161 ****
> }
>
> if (StrategyControl->num_lookup == 0)
> ! all_hit = b1_hit = t1_hit = t2_hit = b2_hit = 0;
> else
> {
> b1_hit = (StrategyControl->num_hit[STRAT_LIST_B1] * 100 /
> --- 157,163 ----
> }
>
> if (StrategyControl->num_lookup == 0)
> ! all_hit = buf_used = b_hit = b1_hit = t1_hit = t2_hit = b2_hit = 0;
> else
> {
> b1_hit = (StrategyControl->num_hit[STRAT_LIST_B1] * 100 /
> ***************
> *** 166,181 ****
> StrategyControl->num_lookup);
> b2_hit = (StrategyControl->num_hit[STRAT_LIST_B2] * 100 /
> StrategyControl->num_lookup);
> ! all_hit = b1_hit + t1_hit + t2_hit + b2_hit;
> }
>
> errcxtold = error_context_stack;
> error_context_stack = NULL;
> ! elog(DEBUG1, "ARC T1target=%5d B1len=%5d T1len=%5d T2len=%5d B2len=%5d",
> T1_TARGET, B1_LENGTH, T1_LENGTH, T2_LENGTH, B2_LENGTH);
> ! elog(DEBUG1, "ARC total =%4ld%% B1hit=%4ld%% T1hit=%4ld%% T2hit=%4ld%% B2hit=%4ld%%",
> all_hit, b1_hit, t1_hit, t2_hit, b2_hit);
> ! elog(DEBUG1, "ARC clean buffers at LRU T1= %5d T2= %5d",
> t1_clean, t2_clean);
> error_context_stack = errcxtold;
>
> --- 168,187 ----
> StrategyControl->num_lookup);
> b2_hit = (StrategyControl->num_hit[STRAT_LIST_B2] * 100 /
> StrategyControl->num_lookup);
> ! all_hit = t1_hit + t2_hit;
> ! b_hit = b1_hit + b2_hit;
> ! buf_used = T1_LENGTH + T2_LENGTH;
> }
>
> errcxtold = error_context_stack;
> error_context_stack = NULL;
> ! elog(DEBUG1, "shared_buffers used=%8ld cache hits=%4ld%% turbulence=%4ld%%",
> ! buf_used, all_hit, b_hit);
> ! elog(DEBUG2, "ARC T1target=%5d B1len=%5d T1len=%5d T2len=%5d B2len=%5d",
> T1_TARGET, B1_LENGTH, T1_LENGTH, T2_LENGTH, B2_LENGTH);
> ! elog(DEBUG2, "ARC total =%4ld%% B1hit=%4ld%% T1hit=%4ld%% T2hit=%4ld%% B2hit=%4ld%%",
> all_hit, b1_hit, t1_hit, t2_hit, b2_hit);
> ! elog(DEBUG2, "ARC clean buffers at LRU T1= %5d T2= %5d",
> t1_clean, t2_clean);
> error_context_stack = errcxtold;
>
>
>
> ------------------------------------------------------------------------
>
>
> ---------------------------(end of broadcast)---------------------------
> TIP 1: subscribe and unsubscribe commands go to majordomo@postgresql.org
--
#======================================================================#
# It's easier to get forgiveness for being wrong than for being right. #
# Let's break this rule - forgive me. #
#================================================== JanWieck@Yahoo.com #
On Fri, 2004-10-22 at 20:35, Jan Wieck wrote: > On 10/22/2004 2:50 PM, Simon Riggs wrote: > > > > > My proposal is to alter the code to allow an array of memory linked > > lists. The actual list would be [0] - other additional lists would be > > created dynamically as required i.e. not using IFDEFs, since I want this > > to be controlled by a SIGHUP GUC to allow on-site tuning, not just lab > > work. This will then allow reporting against the additional lists, so > > that cache hit ratios can be seen with various other "prototype" > > shared_buffer settings. > > All the existing lists live in shared memory, so that dynamic approach > suffers from the fact that the memory has to be allocated during ipc_init. > [doh] - dreaming again. Yes of course, server startup it is then. [That way, we can include the memory for it at server startup, then allow the GUC to be turned off after a while to avoid another restart?] > What do you think about my other theory to make C actually 2x effective > cache size and NOT to keep T1 in shared buffers but to assume T1 lives > in the OS buffer cache? Summarised like that, I understand it. My observation is that performance varies significantly between startups of the database, which does indicate that the OS cache is working well. So, yes it does seem as if we have a 3 tier cache. I understand you to be effectively suggesting that we go back to having just a 2-tier cache. I guess we've got two options: 1. Keep ARC as it is, but just allocate much of the available physical memory to shared_buffers, so you know that effective_cache_size is low and that its either in T1 or its on disk. 2. Alter ARC so that we experiment with the view that T1 is in the OS and T2 is in shared_buffers, we don't bother keeping T1. (as you say) Hmmm...I think I'll pass on trying to judge its effectiveness - simplifying things is likely to make it easier to understand and predict behaviour. It's well worth trying, and it seems simple enough to make a patch that keeps T1target at zero. i.e. Scientific method: conjecture + experimental validation = theory If you make up a patch, probably against BETA4, Josh and I can include it in the performance testing that I'm hoping we cando over the next few weeks. Whatever makes 8.0 a high performance release is well worth it. Best Regards, Simon Riggs
On 10/22/2004 4:21 PM, Simon Riggs wrote: > On Fri, 2004-10-22 at 20:35, Jan Wieck wrote: >> On 10/22/2004 2:50 PM, Simon Riggs wrote: >> >> > >> > My proposal is to alter the code to allow an array of memory linked >> > lists. The actual list would be [0] - other additional lists would be >> > created dynamically as required i.e. not using IFDEFs, since I want this >> > to be controlled by a SIGHUP GUC to allow on-site tuning, not just lab >> > work. This will then allow reporting against the additional lists, so >> > that cache hit ratios can be seen with various other "prototype" >> > shared_buffer settings. >> >> All the existing lists live in shared memory, so that dynamic approach >> suffers from the fact that the memory has to be allocated during ipc_init. >> > > [doh] - dreaming again. Yes of course, server startup it is then. [That > way, we can include the memory for it at server startup, then allow the > GUC to be turned off after a while to avoid another restart?] > >> What do you think about my other theory to make C actually 2x effective >> cache size and NOT to keep T1 in shared buffers but to assume T1 lives >> in the OS buffer cache? > > Summarised like that, I understand it. > > My observation is that performance varies significantly between startups > of the database, which does indicate that the OS cache is working well. > So, yes it does seem as if we have a 3 tier cache. I understand you to > be effectively suggesting that we go back to having just a 2-tier cache. Effectively yes, just with the difference that we keep a pseudo T1 list and hope that what we are tracking there is what the OS is caching. As said before, if the effective cache size is set properly, that is what should happen. > > I guess we've got two options: > 1. Keep ARC as it is, but just allocate much of the available physical > memory to shared_buffers, so you know that effective_cache_size is low > and that its either in T1 or its on disk. > 2. Alter ARC so that we experiment with the view that T1 is in the OS > and T2 is in shared_buffers, we don't bother keeping T1. (as you say) > > Hmmm...I think I'll pass on trying to judge its effectiveness - > simplifying things is likely to make it easier to understand and predict > behaviour. It's well worth trying, and it seems simple enough to make a > patch that keeps T1target at zero. Not keeping T1target at zero, because that would keep T2 at the size of shared_buffers. What I suspect is that in the current calculation the T1target is underestimated. It is incremented on B1 hits, but B1 is only of T2 size. What it currently tells is what got pushed from T1 into the OS cache. It could well be that it would work much more effective if it would fuzzily tell what got pushed out of the OS cache to disk. Jan > > i.e. Scientific method: conjecture + experimental validation = theory > > If you make up a patch, probably against BETA4, Josh and I can include it in the performance testing that I'm hoping wecan do over the next few weeks. > > Whatever makes 8.0 a high performance release is well worth it. > > Best Regards, > > Simon Riggs -- #======================================================================# # It's easier to get forgiveness for being wrong than for being right. # # Let's break this rule - forgive me. # #================================================== JanWieck@Yahoo.com #
Jan Wieck <JanWieck@Yahoo.com> writes:
> What do you think about my other theory to make C actually 2x effective
> cache size and NOT to keep T1 in shared buffers but to assume T1 lives
> in the OS buffer cache?
What will you do when initially fetching a page? It's not supposed to
go directly into T2 on first use, but we're going to have some
difficulty accessing a page that's not in shared buffers. I don't think
you can equate the T1/T2 dichotomy to "is in shared buffers or not".
You could maybe have a T3 list of "pages that aren't in shared buffers
anymore but we think are still in OS buffer cache", but what would be
the point? It'd be a sufficiently bad model of reality as to be pretty
much useless for stats gathering, I'd think.
regards, tom lane
On Fri, 2004-10-22 at 21:45, Tom Lane wrote: > Jan Wieck <JanWieck@Yahoo.com> writes: > > What do you think about my other theory to make C actually 2x effective > > cache size and NOT to keep T1 in shared buffers but to assume T1 lives > > in the OS buffer cache? > > What will you do when initially fetching a page? It's not supposed to > go directly into T2 on first use, but we're going to have some > difficulty accessing a page that's not in shared buffers. I don't think > you can equate the T1/T2 dichotomy to "is in shared buffers or not". > Yes, there are issues there. I want Jan to follow his thoughts through. This is important enough that its worth it - there's only a few even attempting this. > You could maybe have a T3 list of "pages that aren't in shared buffers > anymore but we think are still in OS buffer cache", but what would be > the point? It'd be a sufficiently bad model of reality as to be pretty > much useless for stats gathering, I'd think. > The OS cache is in many ways a wild horse, I agree. Jan is trying to think of ways to harness it, whereas I had mostly ignored it - but its there. Raw disk usage never allowed this opportunity. For high performance systems, we can assume that the OS cache is ours to play with - what will we do with it? We need to use it for some purposes, yet would like to ignore it for others. -- Best Regards, Simon Riggs
On Fri, Oct 22, 2004 at 03:35:49PM -0400, Jan Wieck wrote: > On 10/22/2004 2:50 PM, Simon Riggs wrote: > > >I've been using the ARC debug options to analyse memory usage on the > >PostgreSQL 8.0 server. This is a precursor to more complex performance > >analysis work on the OSDL test suite. > > > >I've simplified some of the ARC reporting into a single log line, which > >is enclosed here as a patch on freelist.c. This includes reporting of: > >- the total memory in use, which wasn't previously reported > >- the cache hit ratio, which was slightly incorrectly calculated > >- a useful-ish value for looking at the "B" lists in ARC > >(This is a patch against cvstip, but I'm not sure whether this has > >potential for inclusion in 8.0...) > > > >The total memory in use is useful because it allows you to tell whether > >shared_buffers is set too high. If it is set too high, then memory usage > >will continue to grow slowly up to the max, without any corresponding > >increase in cache hit ratio. If shared_buffers is too small, then memory > >usage will climb quickly and linearly to its maximum. > > > >The last one I've called "turbulence" in an attempt to ascribe some > >useful meaning to B1/B2 hits - I've tried a few other measures though > >without much success. Turbulence is the hit ratio of B1+B2 lists added > >together. By observation, this is zero when ARC gives smooth operation, > >and goes above zero otherwise. Typically, turbulence occurs when > >shared_buffers is too small for the working set of the database/workload > >combination and ARC repeatedly re-balances the lengths of T1/T2 as a > >result of "near-misses" on the B1/B2 lists. Turbulence doesn't usually > >cut in until the cache is fully utilized, so there is usually some delay > >after startup. > > > >We also recently discussed that I would add some further memory analysis > >features for 8.1, so I've been trying to figure out how. > > > >The idea that B1, B2 represent something really useful doesn't seem to > >have been borne out - though I'm open to persuasion there. > > > >I originally envisaged a "shadow list" operating in extension of the > >main ARC list. This will require some re-coding, since the variables and > >macros are all hard-coded to a single set of lists. No complaints, just > >it will take a little longer than we all thought (for me, that is...) > > > >My proposal is to alter the code to allow an array of memory linked > >lists. The actual list would be [0] - other additional lists would be > >created dynamically as required i.e. not using IFDEFs, since I want this > >to be controlled by a SIGHUP GUC to allow on-site tuning, not just lab > >work. This will then allow reporting against the additional lists, so > >that cache hit ratios can be seen with various other "prototype" > >shared_buffer settings. > > All the existing lists live in shared memory, so that dynamic approach > suffers from the fact that the memory has to be allocated during ipc_init. > > What do you think about my other theory to make C actually 2x effective > cache size and NOT to keep T1 in shared buffers but to assume T1 lives > in the OS buffer cache? > > > Jan > Jan, From the articles that I have seen on the ARC algorithm, I do not think that using the effective cache size to set C would be a win. The design of the ARC process is to allow the cache to optimize its use in response to the actual workload. It may be the best use of the cache in some cases to have the entire cache allocated to T1 and similarly for T2. If fact, the ability to alter the behavior as needed is one of the key advantages. --Ken
On 10/22/2004 4:09 PM, Kenneth Marshall wrote: > On Fri, Oct 22, 2004 at 03:35:49PM -0400, Jan Wieck wrote: >> On 10/22/2004 2:50 PM, Simon Riggs wrote: >> >> >I've been using the ARC debug options to analyse memory usage on the >> >PostgreSQL 8.0 server. This is a precursor to more complex performance >> >analysis work on the OSDL test suite. >> > >> >I've simplified some of the ARC reporting into a single log line, which >> >is enclosed here as a patch on freelist.c. This includes reporting of: >> >- the total memory in use, which wasn't previously reported >> >- the cache hit ratio, which was slightly incorrectly calculated >> >- a useful-ish value for looking at the "B" lists in ARC >> >(This is a patch against cvstip, but I'm not sure whether this has >> >potential for inclusion in 8.0...) >> > >> >The total memory in use is useful because it allows you to tell whether >> >shared_buffers is set too high. If it is set too high, then memory usage >> >will continue to grow slowly up to the max, without any corresponding >> >increase in cache hit ratio. If shared_buffers is too small, then memory >> >usage will climb quickly and linearly to its maximum. >> > >> >The last one I've called "turbulence" in an attempt to ascribe some >> >useful meaning to B1/B2 hits - I've tried a few other measures though >> >without much success. Turbulence is the hit ratio of B1+B2 lists added >> >together. By observation, this is zero when ARC gives smooth operation, >> >and goes above zero otherwise. Typically, turbulence occurs when >> >shared_buffers is too small for the working set of the database/workload >> >combination and ARC repeatedly re-balances the lengths of T1/T2 as a >> >result of "near-misses" on the B1/B2 lists. Turbulence doesn't usually >> >cut in until the cache is fully utilized, so there is usually some delay >> >after startup. >> > >> >We also recently discussed that I would add some further memory analysis >> >features for 8.1, so I've been trying to figure out how. >> > >> >The idea that B1, B2 represent something really useful doesn't seem to >> >have been borne out - though I'm open to persuasion there. >> > >> >I originally envisaged a "shadow list" operating in extension of the >> >main ARC list. This will require some re-coding, since the variables and >> >macros are all hard-coded to a single set of lists. No complaints, just >> >it will take a little longer than we all thought (for me, that is...) >> > >> >My proposal is to alter the code to allow an array of memory linked >> >lists. The actual list would be [0] - other additional lists would be >> >created dynamically as required i.e. not using IFDEFs, since I want this >> >to be controlled by a SIGHUP GUC to allow on-site tuning, not just lab >> >work. This will then allow reporting against the additional lists, so >> >that cache hit ratios can be seen with various other "prototype" >> >shared_buffer settings. >> >> All the existing lists live in shared memory, so that dynamic approach >> suffers from the fact that the memory has to be allocated during ipc_init. >> >> What do you think about my other theory to make C actually 2x effective >> cache size and NOT to keep T1 in shared buffers but to assume T1 lives >> in the OS buffer cache? >> >> >> Jan >> > Jan, > >From the articles that I have seen on the ARC algorithm, I do not think > that using the effective cache size to set C would be a win. The design > of the ARC process is to allow the cache to optimize its use in response > to the actual workload. It may be the best use of the cache in some cases > to have the entire cache allocated to T1 and similarly for T2. If fact, > the ability to alter the behavior as needed is one of the key advantages. Only the "working set" of the database, that is the pages that are very frequently used, are worth holding in shared memory at all. The rest should be copied in and out of the OS disc buffers. The problem is, with a too small directory ARC cannot guesstimate what might be in the kernel buffers. Nor can it guesstimate what recently was in the kernel buffers and got pushed out from there. That results in a way too small B1 list, and therefore we don't get B1 hits when in fact the data was found in memory. B1 hits is what increases the T1target, and since we are missing them with a too small directory size, our implementation of ARC is propably using a T2 size larger than the working set. That is not optimal. If we would replace the dynamic T1 buffers with a max_backends*2 area of shared buffers, use a C value representing the effective cache size and limit the T1target on the lower bound to effective cache size - shared buffers, then we basically moved the T1 cache into the OS buffers. This all only holds water, if the OS is allowed to swap out shared memory. And that was my initial question, how likely is it to find this to be true these days? Jan -- #======================================================================# # It's easier to get forgiveness for being wrong than for being right. # # Let's break this rule - forgive me. # #================================================== JanWieck@Yahoo.com #
Jan Wieck <JanWieck@Yahoo.com> writes:
> This all only holds water, if the OS is allowed to swap out shared
> memory. And that was my initial question, how likely is it to find this
> to be true these days?
I think it's more likely that not that the OS will consider shared
memory to be potentially swappable. On some platforms there is a shmctl
call you can make to lock your shmem in memory, but (a) we don't use it
and (b) it may well require privileges we haven't got anyway.
This has always been one of the arguments against making shared_buffers
really large, of course --- if the buffers aren't all heavily used, and
the OS decides to swap them to disk, you are worse off than you would
have been with a smaller shared_buffers setting.
However, I'm still really nervous about the idea of using
effective_cache_size to control the ARC algorithm. That number is
usually entirely bogus. Right now it is only a second-order influence
on certain planner estimates, and I am afraid to rely on it any more
heavily than that.
regards, tom lane
Tom Lane <tgl@sss.pgh.pa.us> writes: > However, I'm still really nervous about the idea of using > effective_cache_size to control the ARC algorithm. That number is > usually entirely bogus. It wouldn't be too hard to have a port-specific function that tries to guess the total amount of memory. That isn't always right but it's at least a better ballpark default than a fixed arbitrary value. However I wonder about another approach entirely. If postgres timed how long reads took it shouldn't find it very hard to distinguish between a cached buffer being copied and an actual i/o operation. It should be able to track the percentage of time that buffers requested are in the kernel's cache and use that directly instead of the estimated cache size. Adding two gettimeofdays to every read call would be annoyingly expensive. But a port-specific function to check the cpu instruction counter could be useful. It doesn't have to be an accurate measurement of time (such as on some multi-processor machines) as long as it's possible to distinguish when a slow disk operation has occurred from when no disk operation has occurred. -- greg
Greg Stark <gsstark@MIT.EDU> writes: > However I wonder about another approach entirely. If postgres timed how long > reads took it shouldn't find it very hard to distinguish between a cached > buffer being copied and an actual i/o operation. It should be able to track > the percentage of time that buffers requested are in the kernel's cache and > use that directly instead of the estimated cache size. I tested this with a program that times seeking to random locations in a file. It's pretty easy to spot the break point. There are very few fetches that take between 50us and 1700us, probably they come from the drive's onboard cache. The 1700us bound probably would be lower for high end server equipment with 10k RPM drives and RAID arrays. But I doubt it will ever come close to the 100us edge, not without features like cache ram that Postgres would be better off considering to be part of "effective_cache" anyways. So I would suggest using something like 100us as the threshold for determining whether a buffer fetch came from cache. Here are two graphs, one showing a nice curve showing how disk seek times are distributed. It's neat to look at for that alone: This is the 1000 fastest data points zoomed to the range under 1800us: This is the program I wrote to test this: Here are the commands I used to generate the graphs: $ dd bs=1M count=1024 if=/dev/urandom of=/tmp/big $ ./a.out 10000 /tmp/big > /tmp/l $ gnuplot gnuplot> set terminal png gnuplot> set output "/tmp/plot1.png" gnuplot> plot '/tmp/l2' with points pointtype 1 pointsize 1 gnuplot> set output "/tmp/plot2.png" gnuplot> plot [0:2000] [0:1000] '/tmp/l2' with points pointtype 1 pointsize 1 -- greg
Attachment
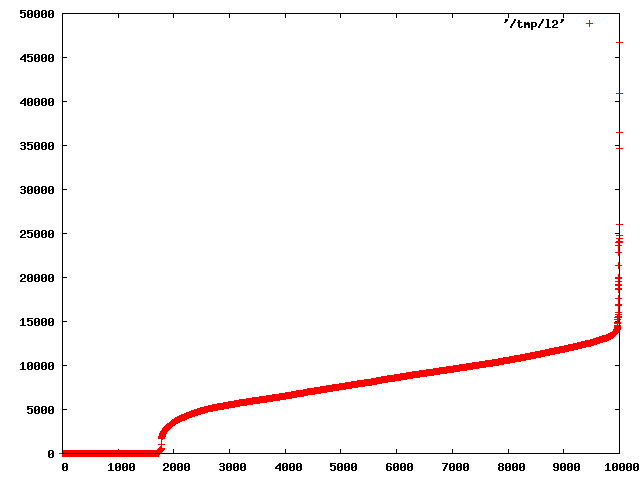{kind=link}
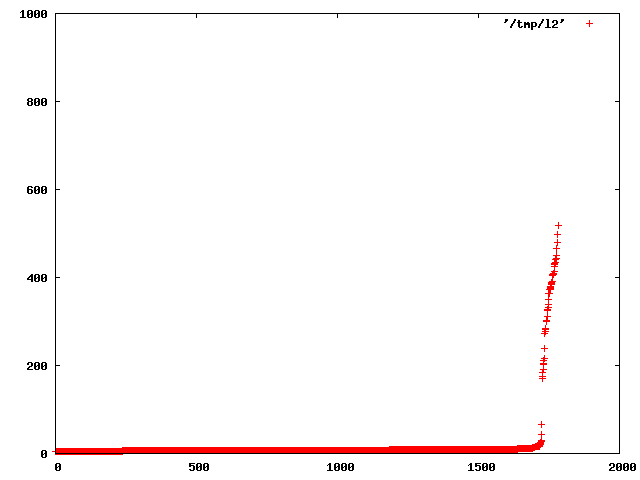{kind=link}
Greg Stark <gsstark@MIT.EDU> writes:
> So I would suggest using something like 100us as the threshold for
> determining whether a buffer fetch came from cache.
I see no reason to hardwire such a number. On any hardware, the
distribution is going to be double-humped, and it will be pretty easy to
determine a cutoff after minimal accumulation of data. The real question
is whether we can afford a pair of gettimeofday() calls per read().
This isn't a big issue if the read actually results in I/O, but if it
doesn't, the percentage overhead could be significant.
If we assume that the effective_cache_size value isn't changing very
fast, maybe it would be good enough to instrument only every N'th read
(I'm imagining N on the order of 100) for this purpose. Or maybe we
need only instrument reads that are of blocks that are close to where
the ARC algorithm thinks the cache edge is.
One small problem is that the time measurement gives you only a lower
bound on the time the read() actually took. In a heavily loaded system
you might not get the CPU back for long enough to fool you about whether
the block came from cache or not.
Another issue is what we do with the effective_cache_size value once we
have a number we trust. We can't readily change the size of the ARC
lists on the fly.
regards, tom lane
Kenneth Marshall <ktm@is.rice.edu> writes:
> How invasive would reading the "CPU counter" be, if it is available?
Invasive or not, this is out of the question; too unportable.
regards, tom lane
Tom Lane <tgl@sss.pgh.pa.us> writes: > I see no reason to hardwire such a number. On any hardware, the > distribution is going to be double-humped, and it will be pretty easy to > determine a cutoff after minimal accumulation of data. Well my stats-fu isn't up to the task. My hunch is that the wide range that the disk reads are spread out over will throw off more sophisticated algorithms. Eliminating hardwired numbers is great, but practically speaking it's not like any hardware is ever going to be able to fetch the data within 100us. If it does it's because it's really a solid state drive or pulling the data from disk cache and therefore really ought to be considered part of effective_cache_size anyways. > The real question is whether we can afford a pair of gettimeofday() calls > per read(). This isn't a big issue if the read actually results in I/O, but > if it doesn't, the percentage overhead could be significant. My thinking was to use gettimeofday by default but allow individual ports to provide a replacement function that uses the cpu TSC counter (via rdtsc) or equivalent. Most processors provide such a feature. If it's not there then we just fall back to gettimeofday. Your idea to sample only 1% of the reads is a fine idea too. My real question is different. Is it worth heading down this alley at all? Or will postgres eventually opt to use O_DIRECT and boost the size of its buffer cache? If it goes the latter route, and I suspect it will one day, then all of this is a waste of effort. I see mmap or O_DIRECT being the only viable long-term stable states. My natural inclination was the former but after the latest thread on the subject I suspect it'll be forever out of reach. That makes O_DIRECT And a Postgres managed cache the only real choice. Having both caches is just a waste of memory and a waste of cpu cycles. > Another issue is what we do with the effective_cache_size value once we > have a number we trust. We can't readily change the size of the ARC > lists on the fly. Huh? I thought effective_cache_size was just used as an factor the cost estimation equation. My general impression was that a higher effective_cache_size effectively lowered your random page cost by making the system think that fewer nonsequential block reads would really incur the cost. Is that wrong? Is it used for anything else? -- greg
Is something broken with the list software? I'm receiving other emails from the list but I haven't received any of the mails in this thread. I'm only able to follow the thread based on the emails people are cc'ing to me directly. I think I've caught this behaviour in the past as well. Is it a misguided list software feature trying to avoid duplicates or something like that? It makes it really hard to follow threads in MUAs with good filtering since they're fragmented between two mailboxes. -- greg
Greg Stark <gsstark@mit.edu> writes:
> Tom Lane <tgl@sss.pgh.pa.us> writes:
>> Another issue is what we do with the effective_cache_size value once we
>> have a number we trust. We can't readily change the size of the ARC
>> lists on the fly.
> Huh? I thought effective_cache_size was just used as an factor the cost
> estimation equation.
Today, that is true. Jan is speculating about using it as a parameter
of the ARC cache management algorithm ... and that worries me.
regards, tom lane
On Tue, 26 Oct 2004, Greg Stark wrote: > I see mmap or O_DIRECT being the only viable long-term stable states. My > natural inclination was the former but after the latest thread on the subject > I suspect it'll be forever out of reach. That makes O_DIRECT And a Postgres > managed cache the only real choice. Having both caches is just a waste of > memory and a waste of cpu cycles. I don't see why mmap is any more out of reach than O_DIRECT; it's not all that much harder to implement, and mmap (and madvise!) is more widely available. But if using two caches is only costing us 1% in performance, there's not really much point.... cjs -- Curt Sampson <cjs@cynic.net> +81 90 7737 2974 http://www.NetBSD.org Make up enjoying your city life...produced byBIC CAMERA
On Mon, 2004-10-25 at 16:34, Jan Wieck wrote: > The problem is, with a too small directory ARC cannot guesstimate what > might be in the kernel buffers. Nor can it guesstimate what recently was > in the kernel buffers and got pushed out from there. That results in a > way too small B1 list, and therefore we don't get B1 hits when in fact > the data was found in memory. B1 hits is what increases the T1target, > and since we are missing them with a too small directory size, our > implementation of ARC is propably using a T2 size larger than the > working set. That is not optimal. I think I have seen that the T1 list shrinks "too much", but need more tests...with some good test results The effectiveness of ARC relies upon the balance between the often conflicting requirements of "recency" and "frequency". It seems possible, even likely, that pgsql's version of ARC may need some subtle changes to rebalance it - if we are unlikely enough to find cases where it genuinely is out of balance. Many performance tests are required, together with a few ideas on extra parameters to include....hence my support of Jan's ideas. That's also why I called the B1+B2 hit ratio "turbulence" because it relates to how much oscillation is happening between T1 and T2. In physical systems, we expect the oscillations to be damped, but there is no guarantee that we have a nearly critically damped oscillator. (Note that the absence of turbulence doesn't imply that T1+T2 is optimally sized, just that is balanced). [...and all though the discussion has wandered away from my original patch...would anybody like to commit, or decline the patch?] > If we would replace the dynamic T1 buffers with a max_backends*2 area of > shared buffers, use a C value representing the effective cache size and > limit the T1target on the lower bound to effective cache size - shared > buffers, then we basically moved the T1 cache into the OS buffers. Limiting the minimum size of T1len to be 2* maxbackends sounds like an easy way to prevent overbalancing of T2, but I would like to follow up on ways to have T1 naturally stay larger. I'll do a patch with this idea in, for testing. I'll call this "T1 minimum size" so we can discuss it. Any other patches are welcome... It could be that B1 is too small and so we could use a larger value of C to keep track of more blocks. I think what is being suggested is two GUCs: shared_buffers (as is), plus another one, larger, which would allow us to track what is in shared_buffers and what is in OS cache. I have comments on "effective cache size" below.... On Mon, 2004-10-25 at 17:03, Tom Lane wrote: > Jan Wieck <JanWieck@Yahoo.com> writes: > > This all only holds water, if the OS is allowed to swap out shared > > memory. And that was my initial question, how likely is it to find this > > to be true these days? > > I think it's more likely that not that the OS will consider shared > memory to be potentially swappable. On some platforms there is a shmctl > call you can make to lock your shmem in memory, but (a) we don't use it > and (b) it may well require privileges we haven't got anyway. Are you saying we shouldn't, or we don't yet? I simply assumed that we did use that function - surely it must be at least an option? RHEL supports this at least.... It may well be that we don't have those privileges, in which case we turn off the option. Often, we (or I?) will want to install a dedicated server, so we should have all the permissions we need, in which case... > This has always been one of the arguments against making shared_buffers > really large, of course --- if the buffers aren't all heavily used, and > the OS decides to swap them to disk, you are worse off than you would > have been with a smaller shared_buffers setting. Not really, just an argument against making them *too* large. Large *and* utilised is OK, so we need ways of judging optimal sizing. > However, I'm still really nervous about the idea of using > effective_cache_size to control the ARC algorithm. That number is > usually entirely bogus. Right now it is only a second-order influence > on certain planner estimates, and I am afraid to rely on it any more > heavily than that. ...ah yes, effective_cache_size. The manual describes effective_cache_size as if it had something to do with the OS, and some of this discussion has picked up on that. effective_cache_size is used in only two places in the code (both in the planner), as an estimate for calculating the cost of a) nonsequential access and b) index access, mainly as a way of avoiding overestimates of access costs for small tables. There is absolutely no implication in the code that effective_cache_size measures anything in the OS; what it gives is an estimate of the number of blocks that will be available from *somewhere* in memory (i.e. in shared_buffers OR OS cache) for one particular table (the one currently being considered by the planner). Crucially, the "size" referred to is the size of the *estimate*, not the size of the OS cache (nor the size of the OS cache + shared_buffers). So setting effective_cache_size = total memory available or setting effective_cache_size = total memory - shared_buffers are both wildly irrelevant things to do, or any assumption that directly links memory size to that parameter. So talking about "effective_cache_size" as if it were the OS cache isn't the right thing to do. ...It could be that we use a very high % of physical memory as shared_buffers - in which case the effective_cache_size would represent the contents of shared_buffers. Note also that the planner assumes that all tables are equally likely to be in cache. Increasing effective_cache_size in postgresql.conf seems destined to give the wrong answer in planning unless you absolutely understand what it does. I will submit a patch to correct the description in the manual. Further comments: The two estimates appear to use effective_cache_size differently: a) assumes that a table of size effective_cache_size will be 50% in cache b) assumes that effective_cache_size blocks are available, so for a table of size == effective_cache_size, then it will be 100% available IMHO the GUC should be renamed "estimated_cached_blocks", with the old name deprecated to force people to re-read the manual description of what effective_cache_size means and then set accordingly.....all of that in 8.0.... -- Best Regards, Simon Riggs
On Tue, 2004-10-26 at 06:53, Tom Lane wrote: > Greg Stark <gsstark@mit.edu> writes: > > Tom Lane <tgl@sss.pgh.pa.us> writes: > >> Another issue is what we do with the effective_cache_size value once we > >> have a number we trust. We can't readily change the size of the ARC > >> lists on the fly. > > > Huh? I thought effective_cache_size was just used as an factor the cost > > estimation equation. > > Today, that is true. Jan is speculating about using it as a parameter > of the ARC cache management algorithm ... and that worries me. > ISTM that we should be optimizing the use of shared_buffers, not whats outside. Didn't you (Tom) already say that? BTW, very good ideas on how to proceed, but why bother? For me, if the sysadmin didn't give shared_buffers to PostgreSQL, its because the memory is intended for use by something else and so not available at all. At least not dependably. The argument against large shared_buffers because of swapping applies to that assumption also...the OS cache is too volatile to attempt to gauge sensibly. There's an argument for improving performance for people that haven't set their parameters correctly, but thats got to be a secondary consideration anyhow. -- Best Regards, Simon Riggs
On Tue, 2004-10-26 at 09:49, Simon Riggs wrote:
> On Mon, 2004-10-25 at 16:34, Jan Wieck wrote:
> > The problem is, with a too small directory ARC cannot guesstimate what
> > might be in the kernel buffers. Nor can it guesstimate what recently was
> > in the kernel buffers and got pushed out from there. That results in a
> > way too small B1 list, and therefore we don't get B1 hits when in fact
> > the data was found in memory. B1 hits is what increases the T1target,
> > and since we are missing them with a too small directory size, our
> > implementation of ARC is propably using a T2 size larger than the
> > working set. That is not optimal.
>
> I think I have seen that the T1 list shrinks "too much", but need more
> tests...with some good test results
>
> > If we would replace the dynamic T1 buffers with a max_backends*2 area of
> > shared buffers, use a C value representing the effective cache size and
> > limit the T1target on the lower bound to effective cache size - shared
> > buffers, then we basically moved the T1 cache into the OS buffers.
>
> Limiting the minimum size of T1len to be 2* maxbackends sounds like an
> easy way to prevent overbalancing of T2, but I would like to follow up
> on ways to have T1 naturally stay larger. I'll do a patch with this idea
> in, for testing. I'll call this "T1 minimum size" so we can discuss it.
>
Don't know whether you've seen this latest update on the ARC idea:
Sorav Bansal and Dharmendra S. Modha,
CAR: Clock with Adaptive Replacement,
in Proceedings of the USENIX Conference on File and Storage Technologies
(FAST), pages 187--200, March 2004.
[I picked up the .pdf here http://citeseer.ist.psu.edu/bansal04car.html]
In that paper Bansal and Modha introduce an update to ARC called CART
which they say is more appropriate for databases. Their idea is to
introduce a "temporal locality window" as a way of making sure that
blocks called twice within a short period don't fall out of T1, though
don't make it into T2 either. Strangely enough the "temporal locality
window" is made by increasing the size of T1... in an adpative way, of
course.
If we were going to put a limit on the minimum size of T1, then this
would put a minimal "temporal locality window" in place....rather than
the increased complexity they go to in order to make T1 larger. I note
test results from both the ARC and CAR papers that show that T2 usually
represents most of C, so the observations that T1 is very small is not
atypical. That implies that the cost of managing the temporal locality
window in CART is usually wasted, even though it does cut in as an
overall benefit: The results show that CART is better than ARC over the
whole range of cache sizes tested (16MB to 4GB) and workloads (apart
from 1 out 22).
If we were to implement a minimum size of T1, related as suggested to
number of users, then this would provide a reasonable approximation of
the temporal locality window. This wouldn't prevent the adaptation of T1
to be higher than this when required.
Jan has already optimised ARC for PostgreSQL by the addition of a
special lookup on transactionId required to optimise for the double
cache lookup of select/update that occurs on a T1 hit. That seems likely
to be able to be removed as a result of having a larger T1.
I'd suggest limiting T1 to be a value of:
shared_buffers <= 1000 T1limit = max_backends *0.75
shared_buffers <= 2000 T1limit = max_backends
shared_buffers <= 5000 T1limit = max_backends *1.5
shared_buffers > 5000 T1limit = max_backends *2
I'll try some tests with both
- minimum size of T1
- update optimisation removed
Thoughts?
--
Best Regards, Simon Riggs
Curt Sampson <cjs@cynic.net> writes: > On Tue, 26 Oct 2004, Greg Stark wrote: > > > I see mmap or O_DIRECT being the only viable long-term stable states. My > > natural inclination was the former but after the latest thread on the subject > > I suspect it'll be forever out of reach. That makes O_DIRECT And a Postgres > > managed cache the only real choice. Having both caches is just a waste of > > memory and a waste of cpu cycles. > > I don't see why mmap is any more out of reach than O_DIRECT; it's not > all that much harder to implement, and mmap (and madvise!) is more > widely available. Because there's no way to prevent a write-out from occurring and no way to be notified by mmap before a write-out occurs, and Postgres wants to do its WAL logging at that time if it hasn't already happened. > But if using two caches is only costing us 1% in performance, there's > not really much point.... Well firstly it depends on the work profile. It can probably get much higher than we saw in that profile if your work load is causing more fresh buffers to be fetched. Secondly it also reduces the amount of cache available. If you have 256M of ram with about 200M free, and 40Mb of ram set aside for Postgres's buffer cache then you really only get 160Mb. It's costing you 20% of your cache, and reducing the cache hit rate accordingly. Thirdly the kernel doesn't know as much as Postgres about the load. Postgres could optimize its use of cache based on whether it knows the data is being loaded by a vacuum or sequential scan rather than an index lookup. In practice Postgres has gone with ARC which I suppose a kernel could implement anyways, but afaik neither linux nor BSD choose to do anything like it. -- greg
Thomas, > As a result, I was intending to inflate the value of > effective_cache_size to closer to the amount of unused RAM on some of > the machines I admin (once I've verified that they all have a unified > buffer cache). Is that correct? Currently, yes. Right now, e_c_s is used just to inform the planner and make index vs. table scan and join order decisions. The problem which Simon is bringing up is part of a discussion about doing *more* with the information supplied by e_c_s. He points out that it's not really related to the *real* probability of any particular table being cached. At least, if I'm reading him right. -- --Josh Josh Berkus Aglio Database Solutions San Francisco
On Wed, 26 Oct 2004, Greg Stark wrote: > > I don't see why mmap is any more out of reach than O_DIRECT; it's not > > all that much harder to implement, and mmap (and madvise!) is more > > widely available. > > Because there's no way to prevent a write-out from occurring and no way to be > notified by mmap before a write-out occurs, and Postgres wants to do its WAL > logging at that time if it hasn't already happened. I already described a solution to that problem in a post earlier in this thread (a write queue on the block). I may even have described it on this list a couple of years ago, that being about the time I thought it up. (The mmap idea just won't die, but at least I wasn't the one to bring it up this time. :-)) > Well firstly it depends on the work profile. It can probably get much higher > than we saw in that profile.... True, but 1% was is much, much lower than I'd expected. That tells me that my intuitive idea of the performance model is wrong, which means, for me at least, it's time to shut up or put up some benchmarks. > Secondly it also reduces the amount of cache available. If you have 256M of > ram with about 200M free, and 40Mb of ram set aside for Postgres's buffer > cache then you really only get 160Mb. It's costing you 20% of your cache, and > reducing the cache hit rate accordingly. Yeah, no question about that. > Thirdly the kernel doesn't know as much as Postgres about the load. Postgres > could optimize its use of cache based on whether it knows the data is being > loaded by a vacuum or sequential scan rather than an index lookup. In practice > Postgres has gone with ARC which I suppose a kernel could implement anyways, > but afaik neither linux nor BSD choose to do anything like it. madvise(). cjs -- Curt Sampson <cjs@cynic.net> +81 90 7737 2974 http://www.NetBSD.org Make up enjoying your city life...produced byBIC CAMERA
On Mon, 2004-10-25 at 23:53, Tom Lane wrote: > Greg Stark <gsstark@mit.edu> writes: > > Tom Lane <tgl@sss.pgh.pa.us> writes: > >> Another issue is what we do with the effective_cache_size value once we > >> have a number we trust. We can't readily change the size of the ARC > >> lists on the fly. > > > Huh? I thought effective_cache_size was just used as an factor the cost > > estimation equation. > > Today, that is true. Jan is speculating about using it as a parameter > of the ARC cache management algorithm ... and that worries me. Because it's so often set wrong I take it. But if it's set right, and it makes the the database faster to pay attention to it, then I'd be in favor of it. Or at least having a switch to turn on the ARC buffer's ability to look at it. Or is it some other issue, having to do with the idea of knowing effective cache size cause a positive effect overall on the ARC algorhythm?
On Mon, Oct 25, 2004 at 05:53:25PM -0400, Tom Lane wrote: > Greg Stark <gsstark@MIT.EDU> writes: > > So I would suggest using something like 100us as the threshold for > > determining whether a buffer fetch came from cache. > > I see no reason to hardwire such a number. On any hardware, the > distribution is going to be double-humped, and it will be pretty easy to > determine a cutoff after minimal accumulation of data. The real question > is whether we can afford a pair of gettimeofday() calls per read(). > This isn't a big issue if the read actually results in I/O, but if it > doesn't, the percentage overhead could be significant. > How invasive would reading the "CPU counter" be, if it is available? A read operation should avoid flushing a cache line and we can throw out the obvious outliers since we only need an estimate and not the actual value. --Ken
On Mon, Oct 25, 2004 at 11:34:25AM -0400, Jan Wieck wrote: > On 10/22/2004 4:09 PM, Kenneth Marshall wrote: > > > On Fri, Oct 22, 2004 at 03:35:49PM -0400, Jan Wieck wrote: > >> On 10/22/2004 2:50 PM, Simon Riggs wrote: > >> > >> >I've been using the ARC debug options to analyse memory usage on the > >> >PostgreSQL 8.0 server. This is a precursor to more complex performance > >> >analysis work on the OSDL test suite. > >> > > >> >I've simplified some of the ARC reporting into a single log line, which > >> >is enclosed here as a patch on freelist.c. This includes reporting of: > >> >- the total memory in use, which wasn't previously reported > >> >- the cache hit ratio, which was slightly incorrectly calculated > >> >- a useful-ish value for looking at the "B" lists in ARC > >> >(This is a patch against cvstip, but I'm not sure whether this has > >> >potential for inclusion in 8.0...) > >> > > >> >The total memory in use is useful because it allows you to tell whether > >> >shared_buffers is set too high. If it is set too high, then memory usage > >> >will continue to grow slowly up to the max, without any corresponding > >> >increase in cache hit ratio. If shared_buffers is too small, then memory > >> >usage will climb quickly and linearly to its maximum. > >> > > >> >The last one I've called "turbulence" in an attempt to ascribe some > >> >useful meaning to B1/B2 hits - I've tried a few other measures though > >> >without much success. Turbulence is the hit ratio of B1+B2 lists added > >> >together. By observation, this is zero when ARC gives smooth operation, > >> >and goes above zero otherwise. Typically, turbulence occurs when > >> >shared_buffers is too small for the working set of the database/workload > >> >combination and ARC repeatedly re-balances the lengths of T1/T2 as a > >> >result of "near-misses" on the B1/B2 lists. Turbulence doesn't usually > >> >cut in until the cache is fully utilized, so there is usually some delay > >> >after startup. > >> > > >> >We also recently discussed that I would add some further memory analysis > >> >features for 8.1, so I've been trying to figure out how. > >> > > >> >The idea that B1, B2 represent something really useful doesn't seem to > >> >have been borne out - though I'm open to persuasion there. > >> > > >> >I originally envisaged a "shadow list" operating in extension of the > >> >main ARC list. This will require some re-coding, since the variables and > >> >macros are all hard-coded to a single set of lists. No complaints, just > >> >it will take a little longer than we all thought (for me, that is...) > >> > > >> >My proposal is to alter the code to allow an array of memory linked > >> >lists. The actual list would be [0] - other additional lists would be > >> >created dynamically as required i.e. not using IFDEFs, since I want this > >> >to be controlled by a SIGHUP GUC to allow on-site tuning, not just lab > >> >work. This will then allow reporting against the additional lists, so > >> >that cache hit ratios can be seen with various other "prototype" > >> >shared_buffer settings. > >> > >> All the existing lists live in shared memory, so that dynamic approach > >> suffers from the fact that the memory has to be allocated during ipc_init. > >> > >> What do you think about my other theory to make C actually 2x effective > >> cache size and NOT to keep T1 in shared buffers but to assume T1 lives > >> in the OS buffer cache? > >> > >> > >> Jan > >> > > Jan, > > > >>From the articles that I have seen on the ARC algorithm, I do not think > > that using the effective cache size to set C would be a win. The design > > of the ARC process is to allow the cache to optimize its use in response > > to the actual workload. It may be the best use of the cache in some cases > > to have the entire cache allocated to T1 and similarly for T2. If fact, > > the ability to alter the behavior as needed is one of the key advantages. > > Only the "working set" of the database, that is the pages that are very > frequently used, are worth holding in shared memory at all. The rest > should be copied in and out of the OS disc buffers. > > The problem is, with a too small directory ARC cannot guesstimate what > might be in the kernel buffers. Nor can it guesstimate what recently was > in the kernel buffers and got pushed out from there. That results in a > way too small B1 list, and therefore we don't get B1 hits when in fact > the data was found in memory. B1 hits is what increases the T1target, > and since we are missing them with a too small directory size, our > implementation of ARC is propably using a T2 size larger than the > working set. That is not optimal. > > If we would replace the dynamic T1 buffers with a max_backends*2 area of > shared buffers, use a C value representing the effective cache size and > limit the T1target on the lower bound to effective cache size - shared > buffers, then we basically moved the T1 cache into the OS buffers. > > This all only holds water, if the OS is allowed to swap out shared > memory. And that was my initial question, how likely is it to find this > to be true these days? > > > Jan > I've asked our linux kernel guys some quick questions and they say you can lock mmapped memory and sys v shared memory with mlock and SHM_LOCK, resp. Otherwise the OS will swap out memory as it sees fit, whether or not it's shared. Mark
Tom Lane wrote: > Greg Stark <gsstark@MIT.EDU> writes: > > So I would suggest using something like 100us as the threshold for > > determining whether a buffer fetch came from cache. > > I see no reason to hardwire such a number. On any hardware, the > distribution is going to be double-humped, and it will be pretty easy to > determine a cutoff after minimal accumulation of data. The real question > is whether we can afford a pair of gettimeofday() calls per read(). > This isn't a big issue if the read actually results in I/O, but if it > doesn't, the percentage overhead could be significant. > > If we assume that the effective_cache_size value isn't changing very > fast, maybe it would be good enough to instrument only every N'th read > (I'm imagining N on the order of 100) for this purpose. Or maybe we > need only instrument reads that are of blocks that are close to where > the ARC algorithm thinks the cache edge is. If it's decided to instrument reads, then perhaps an even better use of it would be to tune random_page_cost. If the storage manager knows the difference between a sequential scan and a random scan, then it should easily be able to measure the actual performance it gets for each and calculate random_page_cost based on the results. While the ARC lists can't be tuned on the fly, random_page_cost can. > One small problem is that the time measurement gives you only a lower > bound on the time the read() actually took. In a heavily loaded system > you might not get the CPU back for long enough to fool you about whether > the block came from cache or not. True, but that's information that you'd want to factor into the performance measurements anyway. The database needs to know how much wall clock time it takes for it to fetch a page under various circumstances from disk via the OS. For determining whether or not the read() hit the disk instead of just OS cache, what would matter is the average difference between the two. That's admittedly a problem if the difference is less than the noise, though, but at the same time that would imply that given the circumstances it really doesn't matter whether or not the page was fetched from disk: the difference is small enough that you could consider them equivalent. You don't need 100% accuracy for this stuff, just statistically significant accuracy. > Another issue is what we do with the effective_cache_size value once > we have a number we trust. We can't readily change the size of the > ARC lists on the fly. Compare it with the current value, and notify the DBA if the values are significantly different? Perhaps write the computed value to a file so the DBA can look at it later? Same with other values that are computed on the fly. In fact, it might make sense to store them in a table that gets periodically updated, and load their values from that table, and then the values in postgresql.conf or the command line would be the default that's used if there's nothing in the table (and if you really want fine-grained control of this process, you could stick a boolean column in the table to indicate whether or not to load the value from the table at startup time). -- Kevin Brown kevin@sysexperts.com
On 10/26/2004 1:53 AM, Tom Lane wrote: > Greg Stark <gsstark@mit.edu> writes: >> Tom Lane <tgl@sss.pgh.pa.us> writes: >>> Another issue is what we do with the effective_cache_size value once we >>> have a number we trust. We can't readily change the size of the ARC >>> lists on the fly. > >> Huh? I thought effective_cache_size was just used as an factor the cost >> estimation equation. > > Today, that is true. Jan is speculating about using it as a parameter > of the ARC cache management algorithm ... and that worries me. If we need another config option, it's not that we are running out of possible names, is it? Jan -- #======================================================================# # It's easier to get forgiveness for being wrong than for being right. # # Let's break this rule - forgive me. # #================================================== JanWieck@Yahoo.com #
Jan Wieck <JanWieck@Yahoo.com> writes:
> On 10/26/2004 1:53 AM, Tom Lane wrote:
>> Greg Stark <gsstark@mit.edu> writes:
> Tom Lane <tgl@sss.pgh.pa.us> writes:
>>> Another issue is what we do with the effective_cache_size value once we
>>> have a number we trust. We can't readily change the size of the ARC
>>> lists on the fly.
>>
> Huh? I thought effective_cache_size was just used as an factor the cost
> estimation equation.
>>
>> Today, that is true. Jan is speculating about using it as a parameter
>> of the ARC cache management algorithm ... and that worries me.
> If we need another config option, it's not that we are running out of
> possible names, is it?
No, the point is that the value is not very trustworthy at the moment.
regards, tom lane
On Wed, 2004-10-27 at 01:39, Josh Berkus wrote: > Thomas, > > > As a result, I was intending to inflate the value of > > effective_cache_size to closer to the amount of unused RAM on some of > > the machines I admin (once I've verified that they all have a unified > > buffer cache). Is that correct? > > Currently, yes. I now believe the answer to that is "no, that is not fully correct", following investigation into how to set that parameter correctly. > Right now, e_c_s is used just to inform the planner and make > index vs. table scan and join order decisions. Yes, I agree that is what e_c_s is used for. ...lets go deeper: effective_cache_size is used to calculate the number of I/Os required to index scan a table, which varies according to the size of the available cache (whether this be OS cache or shared_buffers). The reason to do this is because whether a table is in cache can make a very great difference to access times; *small* tables tend to be the ones that vary most significantly. PostgreSQL currently uses the Mackert and Lohman [1989] equation to assess how much of a table is in cache in a blocked DBMS with a finite cache. The Mackert and Lohman equation is accurate, as long as the parameter b is reasonably accurately set. [I'm discussing only the current behaviour here, not what it can or should or could be] If it is incorrectly set, then the equation will give the wrong answer for small tables. The same answer (i.e. same asymptotic behaviour) is returned for very large tables, but they are the ones we didn't worry about anyway. Getting the equation wrong means you will choose sub-optimal plans, potentially reducing your performance considerably. As I read it, effective_cache_size is equivalent to the parameter b, defined as (p.3) "minimum buffer size dedicated to a given scan". M&L they point out (p.3) "We...do not consider interactions of multiple users sharing the buffer for multiple file accesses". Either way, M&L aren't talking about "the total size of the cache", which we would interpret to mean shared_buffers + OS cache, in our effort to not forget the beneficial effect of the OS cache. They use the phrase "dedicated to a given scan".... AFAICS "effective_cache_size" should be set to a value that reflects how many other users of the cache there might be. If you know for certain you're the only user, set it according to the existing advice. If you know you aren't, then set it an appropriate factor lower. Setting that accurately on a system wide basis may clearly be difficult and setting it high will often be inappropriate. The manual is not clear as to how to set effective_cache_size. Other advice misses out the effect of the many scans/many tables issue and will give the wrong answer for many calculations, and thus produce incorrect plans for 8.0 (and earlier releases also). This is something that needs to be documented rather than a bug fix. It's a complex one, so I'll await all of your objections before I write a new doc patch. [Anyway, I do hope I've missed something somewhere in all that, though I've read their paper twice now. Fairly accessible, but requires interpretation to the PostgreSQL case. Mackert and Lohman [1989] "Index Scans using a finite LRU buffer: A validated I/O model"] > The problem which Simon is bringing up is part of a discussion about doing > *more* with the information supplied by e_c_s. He points out that it's not > really related to the *real* probability of any particular table being > cached. At least, if I'm reading him right. Yes, that was how Jan originally meant to discuss it, but not what I meant. Best regards, Simon Riggs