Thread: contrib/tree
Don, does your approach handle directed graphs ( DAG ) ? Actually our module is just a result of our research for new data type which could handle DAGs ( yahoo, dmoz -like hierarchies) effectively in PostgreSQL. While we didn't find a solution we decided to release this module because 64 children would quite ok for many people. Of course, 128 would be better :-) How about 'move' operation in your approach ? Regards, Oleg _____________________________________________________________ Oleg Bartunov, sci.researcher, hostmaster of AstroNet, Sternberg Astronomical Institute, Moscow University (Russia) Internet: oleg@sai.msu.su, http://www.sai.msu.su/~megera/ phone: +007(095)939-16-83, +007(095)939-23-83
Hannu Krosing wrote: >>How about 'move' operation in your approach ? >> > > I have not looked at his code long enough but it seems to still need > replacing all child nodes bitarray tails ... Yes, it does. But moving items around is a rare event in our environment. -- Don Baccus Portland, OR http://donb.photo.net, http://birdnotes.net, http://openacs.org
Oleg Bartunov writes: > does your approach handle directed graphs ( DAG ) ? > Actually our module is just a result of our research for new > data type which could handle DAGs ( yahoo, dmoz -like hierarchies) > effectively in PostgreSQL. > While we didn't find a solution we decided to release this module > because 64 children would quite ok for many people. > Of course, 128 would be better :-) I was under the impression that the typical way to handle tree structures in relational databases was with recursive unions. It's probably infinitely slower than stuffing everything into one datum, but it gets you all the flexibility that the DBMS has to offer. -- Peter Eisentraut peter_e@gmx.net
Peter Eisentraut wrote: > Oleg Bartunov writes: > > >>does your approach handle directed graphs ( DAG ) ? >>Actually our module is just a result of our research for new >>data type which could handle DAGs ( yahoo, dmoz -like hierarchies) >>effectively in PostgreSQL. >>While we didn't find a solution we decided to release this module >>because 64 children would quite ok for many people. >>Of course, 128 would be better :-) >> > > I was under the impression that the typical way to handle tree structures > in relational databases was with recursive unions. It's probably > infinitely slower than stuffing everything into one datum, but it gets you > all the flexibility that the DBMS has to offer. As I explained to Oleg privately (I think it was privately, at least) a key-based approach doesn't work well for DAGs because in essence you need a set of keys, one for each path that can reach the node. One of my websites tracks bird sightings for people in the Pacific NW and our geographical database is a DAG, not a tree (we have wildlife refuges that overlap states, counties etc). In that system I use a parent-child table to track the relationships. My impression is that there's no single "best way" to handle trees or graphs in an RDBMS that doesn't provide internal support (such as Oracle with its "CONNECT BY" extension). The method we use in OpenACS works very well for us. Insertion and selection are fast, and these are the common operations in *our* environment. YMMV, of course. Key-based approaches are fairly well known, at least none of us claim to have invented anything here. The only novelty, if you will, is our taking advantage of the fact that PG's implementation of BIT VARYING just happens to work really well as a datatype for storing keys. Full indexing support, substring, position, etc ... very slick. Someone asked about using an integer array to store the hierarchical information. I looked at that a few months back but it would require providing custom operators, so rejected it in favor of the approach we're now using. It is important to us that users be able to fire up OpenACS 4 on a vanilla PG, such as the one installed by their Linux or BSD distribution. That rules out special operators that require contrib code or the like. We do use Oleg's full-text search stuff, but searching's optional and can be added in after the user's more comfortable with our toolkit, PostgreSQL, etc. A lot of our users are new to Postgres, or at least have a lot more Oracle experience than PG experience. But the integer array approach might well work for folks who don't mind the need to build in special operators. -- Don Baccus Portland, OR http://donb.photo.net, http://birdnotes.net, http://openacs.org
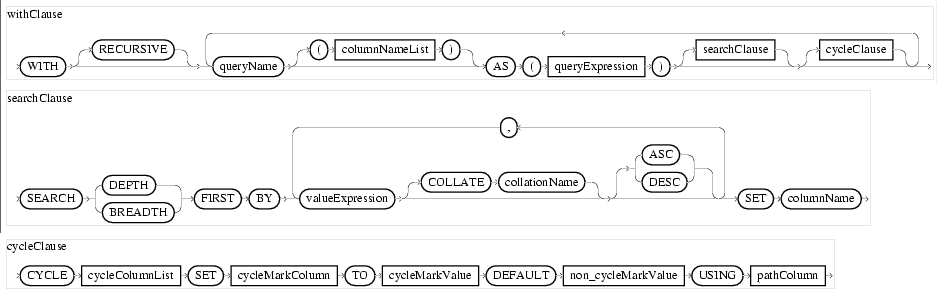
Hannu Krosing wrote: > On Sun, 2002-01-27 at 00:25, Don Baccus wrote: > >>Peter Eisentraut wrote: >> >>>I was under the impression that the typical way to handle tree structures >>>in relational databases was with recursive unions. It's probably >>>infinitely slower than stuffing everything into one datum, but it gets you >>>all the flexibility that the DBMS has to offer. >>> > > I see no reason why WITH RECURSIVE should be inherently slower than other > approaches except that checks for infinite recursion could be pricey. > > Other than that getting rows by index should be more or less equal in both > cases. We use Oracle's "CONNECT BY", not a key-oriented approach, in the Oracle version of the toolkit. There are some awkwardnesses involved in their implementation. You can't join with the table you're "connecting". If you do it in a subselect then join against the result, you get the right rows (of course) but Oracle's free to join in any order. So you can't get a "tree walk" output order if you need to join against your tree, meaning you have to fall back on a sort key anyway (a simpler one, though). I haven't looked at "WITH RECURSIVE" to see if it's defined to be more useful than Oracle's "CONNECT BY" since I don't use any RDBMS that implements it. >>My impression is that there's no single "best way" to handle trees or >>graphs in an RDBMS that doesn't provide internal support (such as Oracle >>with its "CONNECT BY" extension). >> > > The full SQL3 syntax for it is much more powerful and complex (see > attachment). > > I think that this is what should eventually go into postgresql. Yes, indeed. > I'll try if I can build the operators in PL/PGSL so one would not > "really" need to build special operators ;) > > Tell me if this is something impossible. There's the speed issue, of course ... and the extra space, which for deep trees could be significant. Our solution suits our needs very well, and we're happy with it. We do get 2 billion plus immediate children per node and a one-byte per level key for trees that aren't big and flat. The intarray approach is just a different storage technique for the same method, I don't see that moving nodes is any easier (you have to touch the same number of nodes if you move a subtree around). It takes more storage and the necessary comparisons (even if written in C) will be slower unless the tree's big and flat (because you're using four bytes for every level, while our BIT VARYING scheme, in practice, uses one byte for each level in a very large majority of cases). -- Don Baccus Portland, OR http://donb.photo.net, http://birdnotes.net, http://openacs.org
Hannu Krosing wrote: > Is there a simple query for getting all ancestors of a node ? Yes, a recursive SQL function that returns a rowset of ancestor keys. It works off the key directly, doesn't need to touch any tables, so is quite fast. -- Don Baccus Portland, OR http://donb.photo.net, http://birdnotes.net, http://openacs.org
On Sat, 2002-01-26 at 00:17, Oleg Bartunov wrote: > Don, > > does your approach handle directed graphs ( DAG ) ? > Actually our module is just a result of our research for new > data type which could handle DAGs ( yahoo, dmoz -like hierarchies) > effectively in PostgreSQL. Why not use intarray's instead of (n=6)bit-arrays? Is it just space savings ( 64(0) of anything is enough ;) ) or something more fundamental ? > While we didn't find a solution we decided to release this module > because 64 children would quite ok for many people. > Of course, 128 would be better :-) 4294967296 would be enough for almost everybody :) > How about 'move' operation in your approach ? I have not looked at his code long enough but it seems to still need replacing all child nodes bitarray tails ... -------------- Hannu
On Sun, 2002-01-27 at 06:06, Don Baccus wrote: > Hannu Krosing wrote: > > > > I'll try if I can build the operators in PL/PGSL so one would not > > "really" need to build special operators ;) Ok, I've done most of it (the comparison functions and operators), but now I'm stuck with inability to find any arrayconstructing functionality in postgres - the only way seems to be the text-to-type functions . Also arrays seem to be read only -- a[i] := 1 is a syntax error. And get/set slice operators are defined static in source ;( > > Tell me if this is something impossible. > > > There's the speed issue, of course ... and the extra space, which for > deep trees could be significant. > > Our solution suits our needs very well, and we're happy with it. We do > get 2 billion plus immediate children per node and a one-byte per level > key for trees that aren't big and flat. The intarray approach is just a > different storage technique for the same method, I don't see that moving > nodes is any easier (you have to touch the same number of nodes if you > move a subtree around). Is there a simple query for getting all ancestors of a node ? The intarray approach has all them already encoded . > It takes more storage and the necessary > comparisons (even if written in C) will be slower unless the tree's big > and flat (because you're using four bytes for every level, while our BIT > VARYING scheme, in practice, uses one byte for each level in a very > large majority of cases). I'm inclining more and more towards using your approach. I just even figured out that I don't rreally need to get the ancestors for my needs. ------------- Hannu
On Sun, 2002-01-27 at 00:25, Don Baccus wrote: > Peter Eisentraut wrote: > > I was under the impression that the typical way to handle tree structures > > in relational databases was with recursive unions. It's probably > > infinitely slower than stuffing everything into one datum, but it gets you > > all the flexibility that the DBMS has to offer. I see no reason why WITH RECURSIVE should be inherently slower than other approaches except that checks for infinite recursion could be pricey. Other than that getting rows by index should be more or less equal in both cases. > As I explained to Oleg privately (I think it was privately, at least) a > key-based approach doesn't work well for DAGs because in essence you > need a set of keys, one for each path that can reach the node. One of > my websites tracks bird sightings for people in the Pacific NW and our > geographical database is a DAG, not a tree (we have wildlife refuges > that overlap states, counties etc). In that system I use a > parent-child table to track the relationships. > > My impression is that there's no single "best way" to handle trees or > graphs in an RDBMS that doesn't provide internal support (such as Oracle > with its "CONNECT BY" extension). The full SQL3 syntax for it is much more powerful and complex (see attachment). I think that this is what should eventually go into postgresql. > Someone asked about using an integer array to store the hierarchical > information. I looked at that a few months back but it would require > providing custom operators, so rejected it in favor of the approach > we're now using. It is important to us that users be able to fire up > OpenACS 4 on a vanilla PG, such as the one installed by their Linux or > BSD distribution. That rules out special operators that require contrib > code or the like. > > We do use Oleg's full-text search stuff, but searching's optional and > can be added in after the user's more comfortable with our toolkit, > PostgreSQL, etc. A lot of our users are new to Postgres, or at least > have a lot more Oracle experience than PG experience. > > But the integer array approach might well work for folks who don't mind > the need to build in special operators. I'll try if I can build the operators in PL/PGSL so one would not "really" need to build special operators ;) Tell me if this is something impossible. ------------------ Hannu
Attachment
{kind=link}
dhogaza@pacifier.com (Don Baccus) writes: > Peter Eisentraut wrote: > > I was under the impression that the typical way to handle tree > > structures in relational databases was with recursive unions. > > It's probably infinitely slower than stuffing everything into one > > datum, but it gets you all the flexibility that the DBMS has to > > offer. > As I explained to Oleg privately (I think it was privately, at > least) a key-based approach doesn't work well for DAGs because in > essence you need a set of keys, one for each path that can reach the > node. One of my websites tracks bird sightings for people in the > Pacific NW and our geographical database is a DAG, not a tree (we > have wildlife refuges that overlap states, counties etc). In that > system I use a parent-child table to track the relationships. ... Where parent/child has the unfortunate demerit that walking the tree requires (more-or-less; it could get _marginally_ hidden in a stored procedure) a DB query for each node that gets explored. > My impression is that there's no single "best way" to handle trees > or graphs in an RDBMS that doesn't provide internal support (such as > Oracle with its "CONNECT BY" extension). > The method we use in OpenACS works very well for us. Insertion and > selection are fast, and these are the common operations in *our* > environment. YMMV, of course. Key-based approaches are fairly well > known, at least none of us claim to have invented anything here. > The only novelty, if you will, is our taking advantage of the fact > that PG's implementation of BIT VARYING just happens to work really > well as a datatype for storing keys. Full indexing support, > substring, position, etc ... very slick. Have you a URL for this? (A link to a relevant source code file would be acceptable...) > Someone asked about using an integer array to store the hierarchical > information. I looked at that a few months back but it would > require providing custom operators, so rejected it in favor of the > approach we're now using. It is important to us that users be able > to fire up OpenACS 4 on a vanilla PG, such as the one installed by > their Linux or BSD distribution. That rules out special operators > that require contrib code or the like. Are you referring to the "nested tree" model (particularly promoted by Joe Celko; I don't know of a seminal source behind him)? It unfortunately doesn't work with graphs... -- (concatenate 'string "cbbrowne" "@ntlug.org") http://www3.sympatico.ca/cbbrowne/nonrdbms.html "Did you ever walk in a room and forget why you walked in? I think that's how dogs spend their lives." -- Sue Murphy