Thread: bytea encode performance issues
-----BEGIN PGP SIGNED MESSAGE-----
Hash: SHA1
I am using postgresql 8.2.7 on gentoo for my dbmail backend.
I am also testing it on mysql 5.
I am trying to figure out if I need to tune my database configuration or
if querying a bytea field is just not practical in postgresql.
Searching with the mysql database takes under a minute and with the
postgresql database it takes approximately 10. It gets better when I fix
up the query a little, such as removing the group by and having and
including the clause as part of the where, but not anywhere close to the
mysql level.
This is the query that is used (I know it is not as efficient as it
could be, but this is the query it comes with):
SELECT m.message_idnr,k.messageblk FROM dbmail_messageblks k JOIN
dbmail_physmessage p ON k.physmessage_id = p.id JOIN dbmail_messages m
ON p.id = m.physmessage_id WHERE mailbox_idnr = 8 AND status IN (0,1 )
AND k.is_header = '0' GROUP BY m.message_idnr,k.messageblk HAVING
ENCODE(k.messageblk::bytea,'escape') LIKE '%John%'
The messageblk field is a bytea in postgresql and a longblob in mysql.
The only difference in the query is the MySQL does not need the encode
function.
I have plugged the query into the psql and mysql command line
applications, so I could evaluate the query without the application.
The database is using autovacuum and the estimated rows and the actual
rows are almost the same, so I assume it is working. There are 310266
rows in the dbmail_messageblks table.
Can someone make a suggestion for tuning the database?
The explain of the query is:
"HashAggregate (cost=43648.11..43648.85 rows=74 width=753)"
" -> Nested Loop (cost=42999.83..43647.74 rows=74 width=753)"
" -> Merge Join (cost=42999.83..43043.35 rows=74 width=769)"
" Merge Cond: (k.physmessage_id = m.physmessage_id)"
" -> Sort (cost=39264.12..39267.59 rows=1388 width=753)"
" Sort Key: k.physmessage_id"
" -> Seq Scan on dbmail_messageblks k
(cost=0.00..39191.68 rows=1388 width=753)"
" Filter: ((is_header = 0::smallint) AND
(encode(messageblk, 'escape'::text) ~~ '%John%'::text))"
" -> Sort (cost=3735.71..3754.59 rows=7552 width=16)"
" Sort Key: m.physmessage_id"
" -> Bitmap Heap Scan on dbmail_messages m
(cost=385.98..3249.26 rows=7552 width=16)"
" Recheck Cond: ((mailbox_idnr = 8) AND (status
= ANY ('{0,1}'::integer[])))"
" -> Bitmap Index Scan on dbmail_messages_8
(cost=0.00..384.10 rows=7552 width=0)"
" Index Cond: ((mailbox_idnr = 8) AND
(status = ANY ('{0,1}'::integer[])))"
" -> Index Scan using dbmail_physmessage_pkey on
dbmail_physmessage p (cost=0.00..8.15 rows=1 width=8)"
" Index Cond: (k.physmessage_id = p.id)"
-----BEGIN PGP SIGNATURE-----
Version: GnuPG v1.4.9 (MingW32)
Comment: Using GnuPG with Mozilla - http://enigmail.mozdev.org
iEYEARECAAYFAkiVhHwACgkQjDX6szCBa+o6wACgwa05ZbUBL4Ef18N4JJHQ2SP1
gfwAnjIA14QktV/Qs1TrPiY+Ma+rmJht
=WOQM
-----END PGP SIGNATURE-----
On Aug 3, 2008, at 12:12 PM, Sim Zacks wrote:
> This is the query that is used (I know it is not as efficient as it
> could be, but this is the query it comes with):
>
> SELECT m.message_idnr,k.messageblk FROM dbmail_messageblks k JOIN
> dbmail_physmessage p ON k.physmessage_id = p.id JOIN dbmail_messages m
> ON p.id = m.physmessage_id WHERE mailbox_idnr = 8 AND status IN (0,1 )
> AND k.is_header = '0' GROUP BY m.message_idnr,k.messageblk HAVING
> ENCODE(k.messageblk::bytea,'escape') LIKE '%John%'
That LIKE operator is probably your problem. An unbounded LIKE like
that (with a wildcard on both sides) means no index can be used,
hence you get a sequential scan.
There are apparently some possibilities with the new GIN indexes (or
maybe even using GIST), but I haven't had an opportunity to try those
yet. There were some messages about just that on this list recently.
If you create an index, make sure you create a _functional_ index
over ENCODE(messageblk, 'escape').
> The messageblk field is a bytea in postgresql and a longblob in
> mysql.
> The only difference in the query is the MySQL does not need the encode
> function.
Since when is e-mail binary data? I don't quite see why you'd use a
bytea field instead of text. If your problem is character encoding,
then just don't store that ("encode" the DB using SQLASCII).
> Can someone make a suggestion for tuning the database?
An explain analyze would have been a bit more useful, but the biggest
issue is probably the seqscan.
> The explain of the query is:
> "HashAggregate (cost=43648.11..43648.85 rows=74 width=753)"
> " -> Nested Loop (cost=42999.83..43647.74 rows=74 width=753)"
> " -> Merge Join (cost=42999.83..43043.35 rows=74 width=769)"
> " Merge Cond: (k.physmessage_id = m.physmessage_id)"
> " -> Sort (cost=39264.12..39267.59 rows=1388
> width=753)"
> " Sort Key: k.physmessage_id"
> " -> Seq Scan on dbmail_messageblks k
> (cost=0.00..39191.68 rows=1388 width=753)"
> " Filter: ((is_header = 0::smallint) AND
> (encode(messageblk, 'escape'::text) ~~ '%John%'::text))"
Here is your problem, a sequential scan over a presumably large
table. It's either caused by the LIKE expression or by the lack of a
functional index on messageblk, or both.
If you change the type of the messageblk field to text you won't need
a functional index anymore (although that only saves time on index
creation and inserts/updates).
> " -> Sort (cost=3735.71..3754.59 rows=7552 width=16)"
> " Sort Key: m.physmessage_id"
> " -> Bitmap Heap Scan on dbmail_messages m
> (cost=385.98..3249.26 rows=7552 width=16)"
> " Recheck Cond: ((mailbox_idnr = 8) AND
> (status
> = ANY ('{0,1}'::integer[])))"
> " -> Bitmap Index Scan on dbmail_messages_8
> (cost=0.00..384.10 rows=7552 width=0)"
> " Index Cond: ((mailbox_idnr = 8) AND
> (status = ANY ('{0,1}'::integer[])))"
> " -> Index Scan using dbmail_physmessage_pkey on
> dbmail_physmessage p (cost=0.00..8.15 rows=1 width=8)"
> " Index Cond: (k.physmessage_id = p.id)"
I notice some other oddities in that query/design. Why is is_header a
smallint instead of a boolean? I'm assuming this is for compatibility
with an other database?
Why use status IN (0, 1) instead of more descriptive keys? Is it even
constrained this way, or could arbitrary numbers end up as status
(say 99) and if so, what happens to those messages?
Alban Hertroys
--
If you can't see the forest for the trees,
cut the trees and you'll see there is no forest.
!DSPAM:737,48958f34243483105918576!
On Aug 3, 2008, at 2:36 PM, Sim Zacks wrote:
> The LIKE operator is likely the problem, but it is a critical part
> of an
> email application. Searches are done by, "Show me all emails
> containing
> the following word."
>
> I've tried using TSearch2's full text index. It made the query 50%
> faster, taking 5 minutes. This is still not even close to the less
> then
> a minute in MySQL.
>
>>
>> That LIKE operator is probably your problem. An unbounded LIKE
>> like that
>> (with a wildcard on both sides) means no index can be used, hence you
>> get a sequential scan.
>>
>> There are apparently some possibilities with the new GIN indexes (or
>> maybe even using GIST), but I haven't had an opportunity to try those
>> yet. There were some messages about just that on this list recently.
>>
>
> I don't think a functional index (or anything other then a FTI) would
> accomplish anything, being that I am doing unbounded Likes.
That's why I suggested to use a text field instead of bytea.
IIRC, You can have an index on word triplets and use tsearch. I don't
have intimate knowledge on how that works though, hopefully other
people will chime in here.
Without the need to convert each row before comparing it, and with an
appropriate index, that should significantly speed up your queries.
>> If you create an index, make sure you create a _functional_ index
>> over
>> ENCODE(messageblk, 'escape').
>>
>
> Email is binary when it contains attachments. I actually planned on
> using an ASCII encoding, but the dbmail people specifically said
> not to.
> I don't know if they were speaking from experience, or because ASCII
> sounds bad.
It shouldn't be; those attachments are MIME or UU encoded, are they not?
Don't confuse ASCII and SQLASCII. The latter accepts characters from
any encoding, which is probably what you want.
>> Since when is e-mail binary data? I don't quite see why you'd use a
>> bytea field instead of text. If your problem is character
>> encoding, then
>> just don't store that ("encode" the DB using SQLASCII).
>>
>
> As I mentioned, this is the system that came with dbmail. It runs on
> both PostGresql and MySQL, so they may have done some compatibility
> things. There are 4 statuses possible, 0,1,2,3 if you use the database
> through the software then a 99 could never appear there.
The software isn't the only client that might connect to the database.
It is usually bad practice to put data constraint logic in the client
instead of in the database. Especially since in client code there are
usually multiple sections of code that have to deal with those
constraints, which tends to result in small differences in their
handling.
Next to that, if those statuses would have a proper foreign key
constraint, it would be very easy to add labels to each status in a
way they would make a bit more sense than 0, 1, 2, 3.
I expect the label would be a sufficient foreign key by itself
though, no need for those silly numbers.
Well, there's probably not much you can do about that, being just a
user of dbMail.
>> I notice some other oddities in that query/design. Why is is_header a
>> smallint instead of a boolean? I'm assuming this is for compatibility
>> with an other database?
>>
>> Why use status IN (0, 1) instead of more descriptive keys? Is it even
>> constrained this way, or could arbitrary numbers end up as status
>> (say
>> 99) and if so, what happens to those messages?
You have a very odd way of quoting. You don't top post as such, but
you top post in context... Haven't seen that one before. Usually
people reply _below_ a section, not above it ;) It made my reply a
bit harder to write.
Alban Hertroys
--
If you can't see the forest for the trees,
cut the trees and you'll see there is no forest.
!DSPAM:737,4895b34b243488085013917!
The LIKE operator is likely the problem, but it is a critical part of an
email application. Searches are done by, "Show me all emails containing
the following word."
I've tried using TSearch2's full text index. It made the query 50%
faster, taking 5 minutes. This is still not even close to the less then
a minute in MySQL.
>
> That LIKE operator is probably your problem. An unbounded LIKE like that
> (with a wildcard on both sides) means no index can be used, hence you
> get a sequential scan.
>
> There are apparently some possibilities with the new GIN indexes (or
> maybe even using GIST), but I haven't had an opportunity to try those
> yet. There were some messages about just that on this list recently.
>
I don't think a functional index (or anything other then a FTI) would
accomplish anything, being that I am doing unbounded Likes.
> If you create an index, make sure you create a _functional_ index over
> ENCODE(messageblk, 'escape').
>
Email is binary when it contains attachments. I actually planned on
using an ASCII encoding, but the dbmail people specifically said not to.
I don't know if they were speaking from experience, or because ASCII
sounds bad.
> Since when is e-mail binary data? I don't quite see why you'd use a
> bytea field instead of text. If your problem is character encoding, then
> just don't store that ("encode" the DB using SQLASCII).
>
As I mentioned, this is the system that came with dbmail. It runs on
both PostGresql and MySQL, so they may have done some compatibility
things. There are 4 statuses possible, 0,1,2,3 if you use the database
through the software then a 99 could never appear there.
>
>
> I notice some other oddities in that query/design. Why is is_header a
> smallint instead of a boolean? I'm assuming this is for compatibility
> with an other database?
>
> Why use status IN (0, 1) instead of more descriptive keys? Is it even
> constrained this way, or could arbitrary numbers end up as status (say
> 99) and if so, what happens to those messages?
>
> Alban Hertroys
>
> --
> If you can't see the forest for the trees,
> cut the trees and you'll see there is no forest.
>
>
> !DSPAM:824,48958f30243481673380013!
>
>
Sim Zacks <sim@compulab.co.il> writes:
> The explain of the query is:
Could we see EXPLAIN ANALYZE, not EXPLAIN? Without actual facts
to work from, any suggestions would be mere guesswork.
Also, what can you tell us about the sizes of the messageblk
strings (max and avg would be interesting)?
regards, tom lane
Sim Zacks wrote: > (quoting someone:) >> That LIKE operator is probably your problem. An unbounded LIKE like that >> (with a wildcard on both sides) means no index can be used, hence you >> get a sequential scan. Was the message to which you responded posted to the newsgroup? It isn't appearing in my newsreader. Who wrote the message you quoted (you failed to cite the source)? -- Lew
The com.lewscanon@lew email address is invalid. I tried to send it this email: If I remember correctly, the news feed is gatewayed off the mailing list, so it's possible for a message to the list to not appear in the group if it gets dropped at the gateway. Sorry if this is redundant info for you. If you don't wish to receive spam on your regular email address (understandable) then either switch to reading and posting with a gmail account (got lots of invites, just ask) or set up a separate account to receive emails from pgsql and set up spam assassin and (/ or) a couple of whitelists and use that. It's kinda rude to ask me a question on a mailing list with an email address I can't respond to. I spend time writing up an answer that only you needed to see, and then can't send it to YOU, but only the whole list. On Sun, Aug 3, 2008 at 8:03 AM, Lew <com.lewscanon@lew> wrote: > Sim Zacks wrote: >> >> (quoting someone:) >>> >>> That LIKE operator is probably your problem. An unbounded LIKE like that >>> (with a wildcard on both sides) means no index can be used, hence you >>> get a sequential scan. > > Was the message to which you responded posted to the newsgroup? It isn't > appearing in my newsreader. > > Who wrote the message you quoted (you failed to cite the source)? > > -- > Lew > > -- > Sent via pgsql-general mailing list (pgsql-general@postgresql.org) > To make changes to your subscription: > http://www.postgresql.org/mailpref/pgsql-general >
On 04/08/2008, Lew <com.lewscanon@lew> wrote: > Was the message to which you responded posted to the newsgroup? It isn't > appearing in my newsreader. > > Who wrote the message you quoted (you failed to cite the source)? He was quoting Alban Hertroys, and it appeared on the general mailing list (I didn't even know there was a Newsgroup). There seems to be a problem with your mail address, however ... ;}
One last thing. I'd rather my emails just get dropped silently if that's the minimum someone can do. Use a valid email address that goes to /dev/null and I'll be happy. You may miss a few things sent directly to you, but since that's not what you want anyway, it's no big loss, right? On Sun, Aug 3, 2008 at 7:59 PM, Scott Marlowe <scott.marlowe@gmail.com> wrote: > The com.lewscanon@lew email address is invalid. I tried to send it this email: > > If I remember correctly, the news feed is gatewayed off the mailing > list, so it's possible for a message to the list to not appear in the > group if it gets dropped at the gateway. Sorry if this is redundant > info for you. > > If you don't wish to receive spam on your regular email address > (understandable) then either switch to reading and posting with a > gmail account (got lots of invites, just ask) or set up a separate > account to receive emails from pgsql and set up spam assassin and (/ > or) a couple of whitelists and use that. It's kinda rude to ask me a > question on a mailing list with an email address I can't respond to. > I spend time writing up an answer that only you needed to see, and > then can't send it to YOU, but only the whole list. > > On Sun, Aug 3, 2008 at 8:03 AM, Lew <com.lewscanon@lew> wrote: >> Sim Zacks wrote: >>> >>> (quoting someone:) >>>> >>>> That LIKE operator is probably your problem. An unbounded LIKE like that >>>> (with a wildcard on both sides) means no index can be used, hence you >>>> get a sequential scan. >> >> Was the message to which you responded posted to the newsgroup? It isn't >> appearing in my newsreader. >> >> Who wrote the message you quoted (you failed to cite the source)? >> >> -- >> Lew >> >> -- >> Sent via pgsql-general mailing list (pgsql-general@postgresql.org) >> To make changes to your subscription: >> http://www.postgresql.org/mailpref/pgsql-general >> >
On Sun, Aug 3, 2008 at 8:01 PM, Andrej Ricnik-Bay <andrej.groups@gmail.com> wrote: > On 04/08/2008, Lew <com.lewscanon@lew> wrote: > >> Was the message to which you responded posted to the newsgroup? It isn't >> appearing in my newsreader. >> >> Who wrote the message you quoted (you failed to cite the source)? > He was quoting Alban Hertroys, and it appeared on the general mailing list > (I didn't even know there was a Newsgroup). Wow! So, maybe everybody did need to see then. Still... > There seems to be a problem with your mail address, however ... ;}
On 04/08/2008, Scott Marlowe <scott.marlowe@gmail.com> wrote: > One last thing. I'd rather my emails just get dropped silently if > that's the minimum someone can do. Use a valid email address that > goes to /dev/null and I'll be happy. You may miss a few things sent > directly to you, but since that's not what you want anyway, it's no > big loss, right? Aye ... dodgy spam-protection methods like that really suck.
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 I got the response by email, but it was also addressed to the mailing list. My response was also an email sent to the mailing list, not to the newsgroup. I got one other response, that I do not see in the newsgroup. And I will reply to it also using the mailing list. Sim Lew wrote: > Sim Zacks wrote: >> (quoting someone:) >>> That LIKE operator is probably your problem. An unbounded LIKE like that >>> (with a wildcard on both sides) means no index can be used, hence you >>> get a sequential scan. > > Was the message to which you responded posted to the newsgroup? It > isn't appearing in my newsreader. > > Who wrote the message you quoted (you failed to cite the source)? > -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.9 (MingW32) Comment: Using GnuPG with Mozilla - http://enigmail.mozdev.org iEYEARECAAYFAkiWk20ACgkQjDX6szCBa+pwzwCffdE3KZAg0f2TjUiq+gFCOrML HM4An2wcV9G9aAE+94DH6Vwc6deMIHB4 =N0v/ -----END PGP SIGNATURE-----
Tom Lane wrote:
> Could we see EXPLAIN ANALYZE, not EXPLAIN? Without actual facts
> to work from, any suggestions would be mere guesswork.
This was taken immediately after a vacuum analyze on the database.
"HashAggregate (cost=41596.68..41596.84 rows=16 width=764) (actual
time=488263.802..488263.837 rows=40 loops=1)"
" -> Nested Loop (cost=0.00..41596.60 rows=16 width=764) (actual
time=23375.445..488260.311 rows=40 loops=1)"
" -> Nested Loop (cost=0.00..41463.32 rows=16 width=780)
(actual time=23375.344..488231.994 rows=40 loops=1)"
" -> Seq Scan on dbmail_messageblks k
(cost=0.00..39193.21 rows=259 width=764) (actual time=30.662..486585.126
rows=2107 loops=1)"
" Filter: ((is_header = 0::smallint) AND
(encode(messageblk, 'escape'::text) ~~ '%Yossi%'::text))"
" -> Index Scan using dbmail_messages_2 on dbmail_messages
m (cost=0.00..8.75 rows=1 width=16) (actual time=0.777..0.777 rows=0
loops=2107)"
" Index Cond: (m.physmessage_id = k.physmessage_id)"
" Filter: ((mailbox_idnr = 8) AND (status = ANY
('{0,1}'::integer[])))"
" -> Index Scan using dbmail_physmessage_pkey on
dbmail_physmessage p (cost=0.00..8.32 rows=1 width=8) (actual
time=0.701..0.703 rows=1 loops=40)"
" Index Cond: (k.physmessage_id = p.id)"
"Total runtime: 488264.192 ms"
> Also, what can you tell us about the sizes of the messageblk
> strings (max and avg would be interesting)?
>
select max(length(messageblk)),avg(length(messageblk)) from
dbmail_messageblks
MAX AVG
532259; 48115.630147120314
On 2008-08-03 12:12, Sim Zacks wrote:
> SELECT m.message_idnr,k.messageblk
> FROM dbmail_messageblks k
> JOIN dbmail_physmessage p ON k.physmessage_id = p.id
> JOIN dbmail_messages m ON p.id = m.physmessage_id
> WHERE
> mailbox_idnr = 8
> AND status IN (0,1 )
> AND k.is_header = '0'
> GROUP BY m.message_idnr,k.messageblk
> HAVING ENCODE(k.messageblk::bytea,'escape') LIKE '%John%'
What is this encode() for? I think it is not needed and kills
performance, as it needs to copy every message body in memory, possibly
several times.
Why not just "HAVING k.messageblk LIKE '%John%'"?
Try this:
=> \timing
=> create temporary table test as
select
decode(
repeat(
'lorem ipsum dolor sit amet '
||s::text||E'\n'
,1000
),
'escape'
) as a
from generate_series(1,10000) as s;
SELECT
Time: 10063.807 ms
=> select count(*) from test where a like '%John%';
count
-------
0
(1 row)
Time: 1280.973 ms
=> select count(*) from test where encode(a,'escape') like '%John%';
count
-------
0
(1 row)
Time: 5690.097 ms
Without encode search is 5 times faster. And for bigger bytea a
difference is even worse.
Even better:
=> select count(*) from test where position('John' in a) != 0;
select count(*) from test where position('John' in a) != 0;
count
-------
0
(1 row)
Time: 1098.768 ms
Regards
Tometzky
--
...although Eating Honey was a very good thing to do, there was a
moment just before you began to eat it which was better than when you
were...
Winnie the Pooh
Sim Zacks <sim@compulab.co.il> writes:
> Tom Lane wrote:
>> Could we see EXPLAIN ANALYZE, not EXPLAIN? Without actual facts
>> to work from, any suggestions would be mere guesswork.
> " -> Seq Scan on dbmail_messageblks k
> (cost=0.00..39193.21 rows=259 width=764) (actual time=30.662..486585.126
> rows=2107 loops=1)"
> " Filter: ((is_header = 0::smallint) AND
> (encode(messageblk, 'escape'::text) ~~ '%Yossi%'::text))"
okay, the time really is being spent in the seqscan ...
>> Also, what can you tell us about the sizes of the messageblk
>> strings (max and avg would be interesting)?
>>
> select max(length(messageblk)),avg(length(messageblk)) from
> dbmail_messageblks
> MAX AVG
> 532259; 48115.630147120314
... but given that, I wonder whether the cost isn't from fetching
the toasted messageblk data, and nothing directly to do with either
the encode() call or the ~~ test. It would be interesting to compare
the results of
explain analyze select encode(messageblk, 'escape') ~~ '%Yossi%'
from dbmail_messageblks where is_header = 0;
explain analyze select encode(messageblk, 'escape')
from dbmail_messageblks where is_header = 0;
explain analyze select messageblk = 'X'
from dbmail_messageblks where is_header = 0;
explain analyze select length(messageblk)
from dbmail_messageblks where is_header = 0;
(length is chosen with malice aforethought: unlike the other cases,
it doesn't require detoasting a toasted input)
regards, tom lane
Results below: > ... but given that, I wonder whether the cost isn't from fetching > the toasted messageblk data, and nothing directly to do with either > the encode() call or the ~~ test. It would be interesting to compare > the results of > > explain analyze select encode(messageblk, 'escape') ~~ '%Yossi%' > from dbmail_messageblks where is_header = 0; > "Seq Scan on dbmail_messageblks (cost=0.00..38449.06 rows=162096 width=756) (actual time=0.071..492776.008 rows=166748 loops=1)" " Filter: (is_header = 0)" "Total runtime: 492988.410 ms" > explain analyze select encode(messageblk, 'escape') > from dbmail_messageblks where is_header = 0; > "Seq Scan on dbmail_messageblks (cost=0.00..38043.81 rows=162096 width=756) (actual time=16.008..306408.633 rows=166750 loops=1)" " Filter: (is_header = 0)" "Total runtime: 306585.369 ms" > explain analyze select messageblk = 'X' > from dbmail_messageblks where is_header = 0; > "Seq Scan on dbmail_messageblks (cost=0.00..38043.81 rows=162096 width=756) (actual time=18.169..251212.223 rows=166754 loops=1)" " Filter: (is_header = 0)" "Total runtime: 251384.900 ms" > explain analyze select length(messageblk) > from dbmail_messageblks where is_header = 0; > "Seq Scan on dbmail_messageblks (cost=0.00..38043.81 rows=162096 width=756) (actual time=20.436..2585.098 rows=166757 loops=1)" " Filter: (is_header = 0)" "Total runtime: 2673.840 ms" > (length is chosen with malice aforethought: unlike the other cases, > it doesn't require detoasting a toasted input) > > regards, tom lane
Sim Zacks <sim@compulab.co.il> writes:
> Results below:
>> ... but given that, I wonder whether the cost isn't from fetching
>> the toasted messageblk data, and nothing directly to do with either
>> the encode() call or the ~~ test. It would be interesting to compare
>> the results of
Okay, so subtracting the totals we've got:
2.7 sec to scan the table proper
248.7 sec to fetch the toasted datums (well, this test also includes
an equality comparison, but since the text lengths are generally
going to be different, that really should be negligible)
55.2 sec to do the encode() calls
186.4 sec to do the LIKE comparisons
So getting rid of the encode() would help a bit, but it's hardly the
main source of your problem.
We've seen complaints about toast fetch time before. I don't think
there's any really simple solution. You could experiment with disabling
compression (SET STORAGE external) but I'd bet on that being a net loss
unless the data is only poorly compressible.
If the table is not updated very often, it's possible that doing a
CLUSTER every so often would help. I'm not 100% sure but I think that
would result in the toast table being rewritten in the same order as the
newly-built main table, which ought to cut down on the cost of fetching.
Also, what database encoding are you using? I note from the CVS logs
that some post-8.2 work was done to make LIKE faster in multibyte
encodings. (Though if you were doing the LIKE directly in bytea, that
wouldn't matter ... what was the reason for the encode() call again?)
regards, tom lane
-----BEGIN PGP SIGNED MESSAGE----- Hash: SHA1 Tom Lane wrote: > We've seen complaints about toast fetch time before. I don't think > there's any really simple solution. You could experiment with disabling > compression (SET STORAGE external) but I'd bet on that being a net loss > unless the data is only poorly compressible. I am trying it with External and then I'll try it with Plain. However, this is a hugely long process. After the alter table, then I have to update each row with an update dbmail_messageblks set messageblk=messageblk; so that it uses the new storage. After that I have to vacuum analyze (which is taking over an hour so far, most of it on toast). After this is complete, I'll test the examples again and go through the process using Plain. > If the table is not updated very often, it's possible that doing a > CLUSTER every so often would help. I'm not 100% sure but I think that > would result in the toast table being rewritten in the same order as the > newly-built main table, which ought to cut down on the cost of fetching. This is an email table, it is never updated, but constant inserts. Deletes only happen once a week. I'll try the cluster after I try the storage changes. > Also, what database encoding are you using? I note from the CVS logs > that some post-8.2 work was done to make LIKE faster in multibyte > encodings. (Though if you were doing the LIKE directly in bytea, that > wouldn't matter ... what was the reason for the encode() call again?) > We are using UTF-8, and I am testing SQL-ASCII at the moment. DBMail is a pre-built application, so until I am ready to start playing with its internals I don't really have a choice about a number of its features. The reason for the bytea is because of the multiple encodings, I have suggested using SQL-ASCII to them and then it will be possible to use a text datatype. I don't know the reason for using the encode, I assumed that it was because bytea wouldn't take a LIKE, but I see that I was mistaken. It could be that in an earlier release LIKE was not supported against bytea, but I don't know that for sure. Thanks for your help Sim -----BEGIN PGP SIGNATURE----- Version: GnuPG v1.4.9 (MingW32) Comment: Using GnuPG with Mozilla - http://enigmail.mozdev.org iEYEARECAAYFAkiZpDoACgkQjDX6szCBa+pJVACfbkAQuvsOqCCFdlMzpC1rx5yp KpAAoIV17U+gKjXcDYhlOjRIE1PHUbaK =A+Ru -----END PGP SIGNATURE-----
Sim Zacks <sim@compulab.co.il> writes:
> After the alter table, then I have to update each row with an
> update dbmail_messageblks set messageblk=messageblk;
> so that it uses the new storage.
I wouldn't actually bet on that changing anything at all ...
I'd try something like messageblk = messageblk || '' to make
completely sure the value gets detoasted.
regards, tom lane
Sim Zacks wrote: > DBMail is > a pre-built application, so until I am ready to start playing with its > internals I don't really have a choice about a number of its features. Have you heard of this? Might be worth a quick look: http://www.archiveopteryx.org/overview -- Richard Huxton Archonet Ltd
On Wed, Aug 6, 2008 at 9:16 AM, Sim Zacks <sim@compulab.co.il> wrote: > We are using UTF-8, and I am testing SQL-ASCII at the moment. DBMail is > a pre-built application, so until I am ready to start playing with its > internals I don't really have a choice about a number of its features. > The reason for the bytea is because of the multiple encodings, I have > suggested using SQL-ASCII to them and then it will be possible to use a > text datatype. > I don't know the reason for using the encode, I assumed that it was > because bytea wouldn't take a LIKE, but I see that I was mistaken. It > could be that in an earlier release LIKE was not supported against > bytea, but I don't know that for sure. I don't quite follow that...the whole point of utf8 encoded database is so that you can use text functions and operators without the bytea treatment. As long as your client encoding is set up properly (so that data coming in and out is computed to utf8), then you should be ok. Dropping to ascii is usually not the solution. Your data inputting application should set the client encoding properly and coerce data into the unicode text type...it's really the only solution. merlin
> I don't quite follow that...the whole point of utf8 encoded database > is so that you can use text functions and operators without the bytea > treatment. As long as your client encoding is set up properly (so > that data coming in and out is computed to utf8), then you should be > ok. Dropping to ascii is usually not the solution. Your data > inputting application should set the client encoding properly and > coerce data into the unicode text type...it's really the only > solution. > Email does not always follow a specific character set. I have tried converting the data that comes in to utf-8 and it does not always work. We receive Hebrew emails which come in mostly 2 flavors, UTF-8 and windows-1255. Unfortunately, they are not compatible with one another. SQL-ASCII and ASCII are different as someone on the list pointed out to me. According to the documentation, SQL-ASCII makes no assumption about encoding, so you can throw in any encoding you want.
I ran the update, but now (obviously) it wants to vacuum again and vacuum on that table took 9 hours yesterday. Do the statistics change when changing the storage type? Meaning does it really need to vacuum? Thank you Sim Tom Lane wrote: > Sim Zacks <sim@compulab.co.il> writes: >> After the alter table, then I have to update each row with an >> update dbmail_messageblks set messageblk=messageblk; >> so that it uses the new storage. > > I wouldn't actually bet on that changing anything at all ... > I'd try something like messageblk = messageblk || '' to make > completely sure the value gets detoasted. > > regards, tom lane
On Thu, Aug 7, 2008 at 1:16 AM, Sim Zacks <sim@compulab.co.il> wrote: > >> I don't quite follow that...the whole point of utf8 encoded database >> is so that you can use text functions and operators without the bytea >> treatment. As long as your client encoding is set up properly (so >> that data coming in and out is computed to utf8), then you should be >> ok. Dropping to ascii is usually not the solution. Your data >> inputting application should set the client encoding properly and >> coerce data into the unicode text type...it's really the only >> solution. >> > Email does not always follow a specific character set. I have tried > converting the data that comes in to utf-8 and it does not always work. > We receive Hebrew emails which come in mostly 2 flavors, UTF-8 and > windows-1255. Unfortunately, they are not compatible with one another. > SQL-ASCII and ASCII are different as someone on the list pointed out to > me. According to the documentation, SQL-ASCII makes no assumption about > encoding, so you can throw in any encoding you want. no, you can't! SQL-ASCII means that the database treats everything like ascii. This means that any operation that deals with text could (and in the case of Hebrew, almost certianly will) be broken. Simple things like getting the length of a string will be wrong. If you are accepting unicode input, you absolutely must be using a unicode encoded backend. If you are accepting text of different encodings from the client, you basically have two choices: a) set client_encoding on the fly to whatever text the client is encoded in b) pick an encoding (utf8) and convert all text to that before sending it to the database (preferred) you pretty much have to go with option 'b' if you are accepting any text for which there is no supported client encoding translation. merlin
On Thu, Aug 7, 2008 at 9:38 AM, Merlin Moncure <mmoncure@gmail.com> wrote: > On Thu, Aug 7, 2008 at 1:16 AM, Sim Zacks <sim@compulab.co.il> wrote: >> >>> I don't quite follow that...the whole point of utf8 encoded database >>> is so that you can use text functions and operators without the bytea >>> treatment. As long as your client encoding is set up properly (so >>> that data coming in and out is computed to utf8), then you should be >>> ok. Dropping to ascii is usually not the solution. Your data >>> inputting application should set the client encoding properly and >>> coerce data into the unicode text type...it's really the only >>> solution. >>> >> Email does not always follow a specific character set. I have tried >> converting the data that comes in to utf-8 and it does not always work. >> We receive Hebrew emails which come in mostly 2 flavors, UTF-8 and >> windows-1255. Unfortunately, they are not compatible with one another. >> SQL-ASCII and ASCII are different as someone on the list pointed out to >> me. According to the documentation, SQL-ASCII makes no assumption about >> encoding, so you can throw in any encoding you want. > > no, you can't! SQL-ASCII means that the database treats everything > like ascii. This means that any operation that deals with text could > (and in the case of Hebrew, almost certianly will) be broken. Simple > things like getting the length of a string will be wrong. If you are > accepting unicode input, you absolutely must be using a unicode > encoded backend. er, I see the problem (single piece of text with multiple encodings inside) :-). ok, it's more complicated than I thought. still, you need to convert the email to utf8. There simply must be a way, otherwise your emails are not well defined. This is a client side problem...if you push it to the server in ascii, you can't use any server side text operations reliably. merlin merlin
Merlin Moncure escribió: > er, I see the problem (single piece of text with multiple encodings > inside) :-). ok, it's more complicated than I thought. still, you > need to convert the email to utf8. There simply must be a way, > otherwise your emails are not well defined. This is a client side > problem...if you push it to the server in ascii, you can't use any > server side text operations reliably. I think the solution is to get the encoding from the email header and the set the client_encoding to that. However, as soon as an email with an unsopported encoding comes by, you are stuck. -- Alvaro Herrera http://www.CommandPrompt.com/ PostgreSQL Replication, Consulting, Custom Development, 24x7 support
Merlin, You are suggesting a fight with the flexible dynamics of email by fitting it into a UTF shell - it doesn't always work. I would suggest you read the postgresql definition of SQL-ASCII: > The SQL_ASCII setting behaves considerably differently from the other settings. When the server character set is SQL_ASCII,the server interprets byte values 0-127 according to the ASCII standard, while byte values 128-255 are taken asuninterpreted characters. No encoding conversion will be done when the setting is SQL_ASCII. Thus, this setting is notso much a declaration that a specific encoding is in use, as a declaration of ignorance about the encoding. In most cases,if you are working with any non-ASCII data, it is unwise to use the SQL_ASCII setting, because PostgreSQL will be unableto help you by converting or validating non-ASCII characters. It says, In most cases it is unwise to use it if you are working with non-ascii data. That is because most situations do not accept multiple encodings. However, email is a special case where the user does not have control of what is being sent. Therefore it is possible (and it happens to us) that we get emails that are not convertible to UTF-8. The only way I could convert from mysql, which does not check encoding to postgresql utf-8 was to first use the SQL-ASCII database as a bridge, because it did not check the encoding and load it into a bytea and then take a backup of the database and restore it into a UTF-8 database. Sim Merlin Moncure wrote: > On Thu, Aug 7, 2008 at 9:38 AM, Merlin Moncure <mmoncure@gmail.com> wrote: >> On Thu, Aug 7, 2008 at 1:16 AM, Sim Zacks <sim@compulab.co.il> wrote: >>>> I don't quite follow that...the whole point of utf8 encoded database >>>> is so that you can use text functions and operators without the bytea >>>> treatment. As long as your client encoding is set up properly (so >>>> that data coming in and out is computed to utf8), then you should be >>>> ok. Dropping to ascii is usually not the solution. Your data >>>> inputting application should set the client encoding properly and >>>> coerce data into the unicode text type...it's really the only >>>> solution. >>>> >>> Email does not always follow a specific character set. I have tried >>> converting the data that comes in to utf-8 and it does not always work. >>> We receive Hebrew emails which come in mostly 2 flavors, UTF-8 and >>> windows-1255. Unfortunately, they are not compatible with one another. >>> SQL-ASCII and ASCII are different as someone on the list pointed out to >>> me. According to the documentation, SQL-ASCII makes no assumption about >>> encoding, so you can throw in any encoding you want. >> no, you can't! SQL-ASCII means that the database treats everything >> like ascii. This means that any operation that deals with text could >> (and in the case of Hebrew, almost certianly will) be broken. Simple >> things like getting the length of a string will be wrong. If you are >> accepting unicode input, you absolutely must be using a unicode >> encoded backend. > > er, I see the problem (single piece of text with multiple encodings > inside) :-). ok, it's more complicated than I thought. still, you > need to convert the email to utf8. There simply must be a way, > otherwise your emails are not well defined. This is a client side > problem...if you push it to the server in ascii, you can't use any > server side text operations reliably. > > merlin > > merlin
Alvaro Herrera wrote: > Merlin Moncure escribió: > > > er, I see the problem (single piece of text with multiple encodings > > inside) :-). ok, it's more complicated than I thought. still, you > > need to convert the email to utf8. There simply must be a way, > > otherwise your emails are not well defined. This is a client side > > problem...if you push it to the server in ascii, you can't use any > > server side text operations reliably. > > I think the solution is to get the encoding from the email header and > the set the client_encoding to that. However, as soon as an email with > an unsopported encoding comes by, you are stuck. > Why not leave it as bytea? The postgres server has no encoding problems with storing whatever you want to throw at it, postgres client has no problem reading it back. It's then up to the imap/pop3/whatever client to deal with it. That's normally the way the email server world works. FWIW the RFC for email (822/2822) says it is all ASCII so it's not a problem at all as long as every email generator follows the IETF rules (body here is not just the text of the message - its the data after the blank line in the SMTP conversation until the CRLF.CRLF). "2.3. Body The body of a message is simply lines of US-ASCII characters. " The 2 things that will make a difference to the query is 1. get rid of the encode call and 2. stop it being toasted Assuming that the dbmail code can't be changed yet 1. make encode a no-op. - create schema foo; - create function foo.encode (bytea,text) returns bytea as $$ select $1 $$ language sql immutable; - change postgresql.conf search_path to foo,pg_catalog,.... This completly breaks encode so if anything uses it properly then it's broken that. From the query we've seen, we don't know if it's needed or not. What query do you get if you search for something that has utf or other encoding non-ASCII characters? If it looks like the output of escape (i.e. client used PQescapeByteaConn on the search text), then the escape might be required. 2. dbmail already chunks email up into ~500k blocks. If that is a configurable setting, turn it down to about 1.5k blocks. klint. -- Klint Gore Database Manager Sheep CRC A.G.B.U. University of New England Armidale NSW 2350 Ph: 02 6773 3789 Fax: 02 6773 3266 EMail: kgore4@une.edu.au
On Aug 7, 2008, at 5:28 PM, Klint Gore wrote: > Alvaro Herrera wrote: >> Merlin Moncure escribió: >> >> > er, I see the problem (single piece of text with multiple encodings >> > inside) :-). ok, it's more complicated than I thought. still, you >> > need to convert the email to utf8. There simply must be a way, >> > otherwise your emails are not well defined. This is a client side >> > problem...if you push it to the server in ascii, you can't use any >> > server side text operations reliably. >> >> I think the solution is to get the encoding from the email header and >> the set the client_encoding to that. However, as soon as an email >> with >> an unsopported encoding comes by, you are stuck. >> > Why not leave it as bytea? The postgres server has no encoding > problems with storing whatever you want to throw at it, postgres > client has no problem reading it back. It's then up to the imap/ > pop3/whatever client to deal with it. That's normally the way the > email server world works. > > FWIW the RFC for email (822/2822) says it is all ASCII so it's not a > problem at all as long as every email generator follows the IETF > rules (body here is not just the text of the message - its the data > after the blank line in the SMTP conversation until the CRLF.CRLF). That's not actually true for email, though. Content-Transfer-Encoding: 8bit, combined with ESMTP 8BITMIME, for example. So, yeah, you're right. Generally, email is too complex to deal with in the database as anything other than an opaque bytea blob, along with some metadata (that metadata might well include text fields that contain the text content of the mail, for search, for instance). Another option is to convert non-ascii mail to ascii before storing it, but that's not as trivial as it sounds. You cannot convert mail, in general, to utf8, as not all mail content is textual. > The 2 things that will make a difference to the query is 1. get rid > of the encode call and 2. stop it being toasted > > Assuming that the dbmail code can't be changed yet > 1. make encode a no-op. > - create schema foo; > - create function foo.encode (bytea,text) returns bytea as $$ > select $1 $$ language sql immutable; > - change postgresql.conf search_path to foo,pg_catalog,.... > This completly breaks encode so if anything uses it properly then > it's broken that. From the query we've seen, we don't know if it's > needed or not. What query do you get if you search for something > that has utf or other encoding non-ASCII characters? If it looks > like the output of escape (i.e. client used PQescapeByteaConn on the > search text), then the escape might be required. > > 2. dbmail already chunks email up into ~500k blocks. If that is a > configurable setting, turn it down to about 1.5k blocks. Cheers, Steve
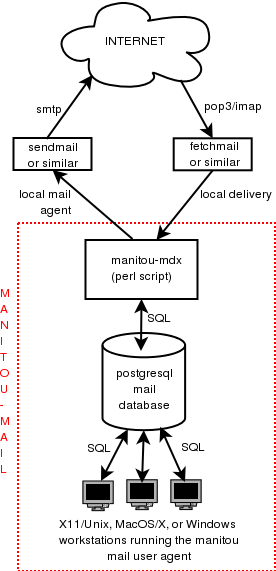
Steve Atkins wrote: > So, yeah, you're right. Generally, email is too complex to deal with > in the database as anything other than an opaque bytea blob, along > with some metadata Only because that's the choice made by dbmail. As an IMAP server, it doesn't _have_ to do more. The downside is that the database is not as useful as it could be. I happen to have developed my own OSS project on exactly this idea: to have a database of mail with contents in normalized form and ready-to-be-queried. An picture of the schema can be seen here: http://www.manitou-mail.org/articles/db-diagram.html the architecture being this: http://www.manitou-mail.org/schemas/schema1.png There's nothing particularly remarkable about the schema, except that there is no trace left of the initial encapsulation of the data inside an RFC822 message and its associated rules about structure and encoding. The next step has been to write a MUA that talks directly in SQL to the database, and the resulting speed and efficiency is much better than with traditional IMAP-based MUAs. As an example related to search, I have this 10Gb database containing 600k mails, and hundreds of results for a full-text search typically come back to the MUA in a couple of seconds, Gmail-like, on a low-grade server to which I'm remotely connected through an SSH tunnel. SQL is so much better without an IMAP layer on top of it... Now, my dedicated MUA isn't as feature-rich as other popular mailers, and it can't be used offline despite being a desktop app, and has other deficiencies, but other mailer/server combinations come with their own sets of problems and inadequacies, too :) Regards, -- Daniel PostgreSQL-powered mail user agent and storage: http://www.manitou-mail.org
{kind=link}