Thread: Regarding issue 1241
Hi Dave,
Regarding Issue 1241:
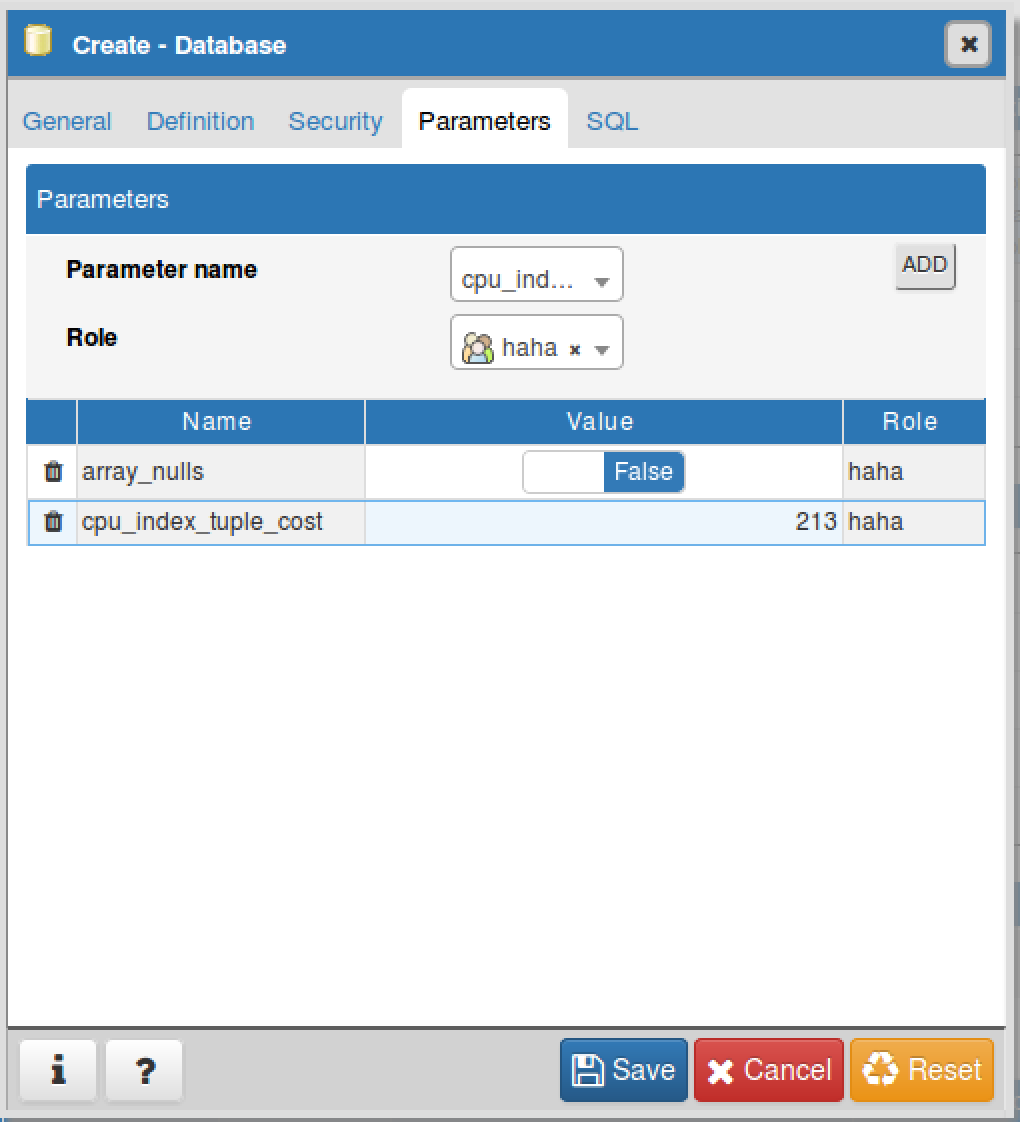
We have added header section for parameter tab deliberately so that we can force user to select parameter name (and therefore parameter's data type) before adding new row. This is required because behavior of second cell (Value cell) is dependent on what parameter name user has selected in first cell (Name cell). See attached screen-shot.
For example:
1. If user selects parameter 'array_nulls' then value for this should be either true or false (and hence switch cell).
2. If user selects parameter 'cpu_index_tuple_cost' then value for this should be Integer (and hence Integer cell).
Without the custom header (and forcing user to select parameter) we cannot decide what type of cell we need in second column.
Let me know your opinion on this.
Apart from this I have fixed column resize issue for Security label tab.
For Privileges tab I have reduced column resizing margin at some extent but not 100%.
Regards,
Attachment
{kind=link}
On Tue, May 31, 2016 at 8:53 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote:
Hi Dave,
Regarding Issue 1241:
We have added header section for parameter tab deliberately so that we can force user to select parameter name (and therefore parameter's data type) before adding new row. This is required because behavior of second cell (Value cell) is dependent on what parameter name user has selected in first cell (Name cell). See attached screen-shot.
For example:
1. If user selects parameter 'array_nulls' then value for this should be either true or false (and hence switch cell).
2. If user selects parameter 'cpu_index_tuple_cost' then value for this should be Integer (and hence Integer cell).
Without the custom header (and forcing user to select parameter) we cannot decide what type of cell we need in second column.
Let me know your opinion on this.
We need to figure out a way to fix it. Our difficulties encountered writing code should not dictate usability compromises. In this case, something that needs some thought and maybe some tricky code has caused us to create an inconsistent UI workflow to side-step the problem, which is not appropriate as it leads to a poor look and feel and potentially confusion for the user.
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Thu, Jun 2, 2016 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:
On Tue, May 31, 2016 at 8:53 PM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote:Hi Dave,
Regarding Issue 1241:
We have added header section for parameter tab deliberately so that we can force user to select parameter name (and therefore parameter's data type) before adding new row. This is required because behavior of second cell (Value cell) is dependent on what parameter name user has selected in first cell (Name cell). See attached screen-shot.
For example:
1. If user selects parameter 'array_nulls' then value for this should be either true or false (and hence switch cell).
2. If user selects parameter 'cpu_index_tuple_cost' then value for this should be Integer (and hence Integer cell).
Without the custom header (and forcing user to select parameter) we cannot decide what type of cell we need in second column.
Let me know your opinion on this.We need to figure out a way to fix it. Our difficulties encountered writing code should not dictate usability compromises.
In this case, something that needs some thought and maybe some tricky code has caused us to create an inconsistent UI workflow to side-step the problem, which is not appropriate as it leads to a poor look and feel and potentially confusion for the user.
Agree - we should handle these cases gracefully.
We need to over come the limitation by brain storming, which we already started offline. :-)
To be honest - it is a time consuming work, and there is no quick fix for this.
We can handle it as one case for each change instead of targeting all UI changes as one whole problem.
And, we can utilize the same time to fix a lot more cases in beta 2.
I can ask Harshal to find out all possible places, where the similar changes are required, and create a separate case for each (though - not without your agreement).
--
Thanks & Regards,
Ashesh Vashi
--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Jun 15, 2016 at 1:49 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote: > On Thu, Jun 2, 2016 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote: >> >> >> >> On Tue, May 31, 2016 at 8:53 PM, Harshal Dhumal >> <harshal.dhumal@enterprisedb.com> wrote: >>> >>> Hi Dave, >>> >>> Regarding Issue 1241: >>> >>> We have added header section for parameter tab deliberately so that we >>> can force user to select parameter name (and therefore parameter's data >>> type) before adding new row. This is required because behavior of second >>> cell (Value cell) is dependent on what parameter name user has selected in >>> first cell (Name cell). See attached screen-shot. >>> >>> For example: >>> 1. If user selects parameter 'array_nulls' then value for this should be >>> either true or false (and hence switch cell). >>> 2. If user selects parameter 'cpu_index_tuple_cost' then value for this >>> should be Integer (and hence Integer cell). >>> >>> Without the custom header (and forcing user to select parameter) we >>> cannot decide what type of cell we need in second column. >>> >>> Let me know your opinion on this. >> >> >> We need to figure out a way to fix it. Our difficulties encountered >> writing code should not dictate usability compromises. >> >> In this case, something that needs some thought and maybe some tricky code >> has caused us to create an inconsistent UI workflow to side-step the >> problem, which is not appropriate as it leads to a poor look and feel and >> potentially confusion for the user. > > Agree - we should handle these cases gracefully. > We need to over come the limitation by brain storming, which we already > started offline. :-) > > To be honest - it is a time consuming work, and there is no quick fix for > this. > We can handle it as one case for each change instead of targeting all UI > changes as one whole problem. > And, we can utilize the same time to fix a lot more cases in beta 2. As far as I'm aware, this is the only case where there's a real problem. > I can ask Harshal to find out all possible places, where the similar changes > are required, and create a separate case for each (though - not without your > agreement). I don't think we need to. This one sub-node grid (parameters) is the only one that I've seen where we deviate from the intended design - and I think I've seen them all now! -- Dave Page Blog: http://pgsnake.blogspot.com Twitter: @pgsnake EnterpriseDB UK: http://www.enterprisedb.com The Enterprise PostgreSQL Company
On Wed, Jun 15, 2016 at 6:25 PM, Dave Page <dpage@pgadmin.org> wrote:
As far as I'm aware, this is the only case where there's a real problem.On Wed, Jun 15, 2016 at 1:49 PM, Ashesh Vashi
<ashesh.vashi@enterprisedb.com> wrote:
> On Thu, Jun 2, 2016 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:
>>
>>
>>
>> On Tue, May 31, 2016 at 8:53 PM, Harshal Dhumal
>> <harshal.dhumal@enterprisedb.com> wrote:
>>>
>>> Hi Dave,
>>>
>>> Regarding Issue 1241:
>>>
>>> We have added header section for parameter tab deliberately so that we
>>> can force user to select parameter name (and therefore parameter's data
>>> type) before adding new row. This is required because behavior of second
>>> cell (Value cell) is dependent on what parameter name user has selected in
>>> first cell (Name cell). See attached screen-shot.
>>>
>>> For example:
>>> 1. If user selects parameter 'array_nulls' then value for this should be
>>> either true or false (and hence switch cell).
>>> 2. If user selects parameter 'cpu_index_tuple_cost' then value for this
>>> should be Integer (and hence Integer cell).
>>>
>>> Without the custom header (and forcing user to select parameter) we
>>> cannot decide what type of cell we need in second column.
>>>
>>> Let me know your opinion on this.
>>
>>
>> We need to figure out a way to fix it. Our difficulties encountered
>> writing code should not dictate usability compromises.
>>
>> In this case, something that needs some thought and maybe some tricky code
>> has caused us to create an inconsistent UI workflow to side-step the
>> problem, which is not appropriate as it leads to a poor look and feel and
>> potentially confusion for the user.
>
> Agree - we should handle these cases gracefully.
> We need to over come the limitation by brain storming, which we already
> started offline. :-)
>
> To be honest - it is a time consuming work, and there is no quick fix for
> this.
> We can handle it as one case for each change instead of targeting all UI
> changes as one whole problem.
> And, we can utilize the same time to fix a lot more cases in beta 2.
> I can ask Harshal to find out all possible places, where the similar changes
> are required, and create a separate case for each (though - not without your
> agreement).
I don't think we need to. This one sub-node grid (parameters) is the
only one that I've seen where we deviate from the intended design -
and I think I've seen them all now!
Hmm..
Unfortunately - some set of columns needs to be unique in most of the cases (where these controls are used), and the checks for the unique dataset is done at the control side, which was wrong at our end.
And, we will need to change the model validation code to check the uniqueness of data set at data level (through Backbone.Model) now, which will require a lot more changes than it looks.
For example - in table node, we have too many UniqueCollControl, which requires these changes.
--
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Jun 15, 2016 at 2:08 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:
On Wed, Jun 15, 2016 at 6:25 PM, Dave Page <dpage@pgadmin.org> wrote:
As far as I'm aware, this is the only case where there's a real problem.On Wed, Jun 15, 2016 at 1:49 PM, Ashesh Vashi
<ashesh.vashi@enterprisedb.com> wrote:
> On Thu, Jun 2, 2016 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:
>>
>>
>>
>> On Tue, May 31, 2016 at 8:53 PM, Harshal Dhumal
>> <harshal.dhumal@enterprisedb.com> wrote:
>>>
>>> Hi Dave,
>>>
>>> Regarding Issue 1241:
>>>
>>> We have added header section for parameter tab deliberately so that we
>>> can force user to select parameter name (and therefore parameter's data
>>> type) before adding new row. This is required because behavior of second
>>> cell (Value cell) is dependent on what parameter name user has selected in
>>> first cell (Name cell). See attached screen-shot.
>>>
>>> For example:
>>> 1. If user selects parameter 'array_nulls' then value for this should be
>>> either true or false (and hence switch cell).
>>> 2. If user selects parameter 'cpu_index_tuple_cost' then value for this
>>> should be Integer (and hence Integer cell).
>>>
>>> Without the custom header (and forcing user to select parameter) we
>>> cannot decide what type of cell we need in second column.
>>>
>>> Let me know your opinion on this.
>>
>>
>> We need to figure out a way to fix it. Our difficulties encountered
>> writing code should not dictate usability compromises.
>>
>> In this case, something that needs some thought and maybe some tricky code
>> has caused us to create an inconsistent UI workflow to side-step the
>> problem, which is not appropriate as it leads to a poor look and feel and
>> potentially confusion for the user.
>
> Agree - we should handle these cases gracefully.
> We need to over come the limitation by brain storming, which we already
> started offline. :-)
>
> To be honest - it is a time consuming work, and there is no quick fix for
> this.
> We can handle it as one case for each change instead of targeting all UI
> changes as one whole problem.
> And, we can utilize the same time to fix a lot more cases in beta 2.
> I can ask Harshal to find out all possible places, where the similar changes
> are required, and create a separate case for each (though - not without your
> agreement).
I don't think we need to. This one sub-node grid (parameters) is the
only one that I've seen where we deviate from the intended design -
and I think I've seen them all now!Hmm..Unfortunately - some set of columns needs to be unique in most of the cases (where these controls are used), and the checks for the unique dataset is done at the control side, which was wrong at our end.And, we will need to change the model validation code to check the uniqueness of data set at data level (through Backbone.Model) now, which will require a lot more changes than it looks.For example - in table node, we have too many UniqueCollControl, which requires these changes.
Perhaps - but I fail to see how this justifies the different UI design for this one use. Are we talking about the same thing?
Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
On Wed, Jun 15, 2016 at 7:24 PM, Dave Page <dpage@pgadmin.org> wrote:
On Wed, Jun 15, 2016 at 2:08 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Wed, Jun 15, 2016 at 6:25 PM, Dave Page <dpage@pgadmin.org> wrote:
As far as I'm aware, this is the only case where there's a real problem.On Wed, Jun 15, 2016 at 1:49 PM, Ashesh Vashi
<ashesh.vashi@enterprisedb.com> wrote:
> On Thu, Jun 2, 2016 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:
>>
>>
>>
>> On Tue, May 31, 2016 at 8:53 PM, Harshal Dhumal
>> <harshal.dhumal@enterprisedb.com> wrote:
>>>
>>> Hi Dave,
>>>
>>> Regarding Issue 1241:
>>>
>>> We have added header section for parameter tab deliberately so that we
>>> can force user to select parameter name (and therefore parameter's data
>>> type) before adding new row. This is required because behavior of second
>>> cell (Value cell) is dependent on what parameter name user has selected in
>>> first cell (Name cell). See attached screen-shot.
>>>
>>> For example:
>>> 1. If user selects parameter 'array_nulls' then value for this should be
>>> either true or false (and hence switch cell).
>>> 2. If user selects parameter 'cpu_index_tuple_cost' then value for this
>>> should be Integer (and hence Integer cell).
>>>
>>> Without the custom header (and forcing user to select parameter) we
>>> cannot decide what type of cell we need in second column.
>>>
>>> Let me know your opinion on this.
>>
>>
>> We need to figure out a way to fix it. Our difficulties encountered
>> writing code should not dictate usability compromises.
>>
>> In this case, something that needs some thought and maybe some tricky code
>> has caused us to create an inconsistent UI workflow to side-step the
>> problem, which is not appropriate as it leads to a poor look and feel and
>> potentially confusion for the user.
>
> Agree - we should handle these cases gracefully.
> We need to over come the limitation by brain storming, which we already
> started offline. :-)
>
> To be honest - it is a time consuming work, and there is no quick fix for
> this.
> We can handle it as one case for each change instead of targeting all UI
> changes as one whole problem.
> And, we can utilize the same time to fix a lot more cases in beta 2.
> I can ask Harshal to find out all possible places, where the similar changes
> are required, and create a separate case for each (though - not without your
> agreement).
I don't think we need to. This one sub-node grid (parameters) is the
only one that I've seen where we deviate from the intended design -
and I think I've seen them all now!Hmm..Unfortunately - some set of columns needs to be unique in most of the cases (where these controls are used), and the checks for the unique dataset is done at the control side, which was wrong at our end.And, we will need to change the model validation code to check the uniqueness of data set at data level (through Backbone.Model) now, which will require a lot more changes than it looks.For example - in table node, we have too many UniqueCollControl, which requires these changes.Perhaps - but I fail to see how this justifies the different UI design for this one use. Are we talking about the same thing?
Yes - we do.
It is not change in the design of the UI control, but - we will need to replace simplified subnode control (which is already present in the system), and make the validation check in each of the data model one at a time.
We need to keep the UI at other place, until we fix the data validation part at each of those places.
We will remove the UniqueColControl once we complete all these changes.That's why - I said it was mistake to do the validation in Control rather than the data (Backbone.Model).
--
Thanks & Regards,
Ashesh Vashi
--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Hi,
PFA patch for issue RM1241--
Harshal Dhumal
Software Engineer
On Wed, Jun 15, 2016 at 7:57 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:
On Wed, Jun 15, 2016 at 7:24 PM, Dave Page <dpage@pgadmin.org> wrote:
On Wed, Jun 15, 2016 at 2:08 PM, Ashesh Vashi <ashesh.vashi@enterprisedb.com> wrote:On Wed, Jun 15, 2016 at 6:25 PM, Dave Page <dpage@pgadmin.org> wrote:
As far as I'm aware, this is the only case where there's a real problem.On Wed, Jun 15, 2016 at 1:49 PM, Ashesh Vashi
<ashesh.vashi@enterprisedb.com> wrote:
> On Thu, Jun 2, 2016 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote:
>>
>>
>>
>> On Tue, May 31, 2016 at 8:53 PM, Harshal Dhumal
>> <harshal.dhumal@enterprisedb.com> wrote:
>>>
>>> Hi Dave,
>>>
>>> Regarding Issue 1241:
>>>
>>> We have added header section for parameter tab deliberately so that we
>>> can force user to select parameter name (and therefore parameter's data
>>> type) before adding new row. This is required because behavior of second
>>> cell (Value cell) is dependent on what parameter name user has selected in
>>> first cell (Name cell). See attached screen-shot.
>>>
>>> For example:
>>> 1. If user selects parameter 'array_nulls' then value for this should be
>>> either true or false (and hence switch cell).
>>> 2. If user selects parameter 'cpu_index_tuple_cost' then value for this
>>> should be Integer (and hence Integer cell).
>>>
>>> Without the custom header (and forcing user to select parameter) we
>>> cannot decide what type of cell we need in second column.
>>>
>>> Let me know your opinion on this.
>>
>>
>> We need to figure out a way to fix it. Our difficulties encountered
>> writing code should not dictate usability compromises.
>>
>> In this case, something that needs some thought and maybe some tricky code
>> has caused us to create an inconsistent UI workflow to side-step the
>> problem, which is not appropriate as it leads to a poor look and feel and
>> potentially confusion for the user.
>
> Agree - we should handle these cases gracefully.
> We need to over come the limitation by brain storming, which we already
> started offline. :-)
>
> To be honest - it is a time consuming work, and there is no quick fix for
> this.
> We can handle it as one case for each change instead of targeting all UI
> changes as one whole problem.
> And, we can utilize the same time to fix a lot more cases in beta 2.
> I can ask Harshal to find out all possible places, where the similar changes
> are required, and create a separate case for each (though - not without your
> agreement).
I don't think we need to. This one sub-node grid (parameters) is the
only one that I've seen where we deviate from the intended design -
and I think I've seen them all now!Hmm..Unfortunately - some set of columns needs to be unique in most of the cases (where these controls are used), and the checks for the unique dataset is done at the control side, which was wrong at our end.And, we will need to change the model validation code to check the uniqueness of data set at data level (through Backbone.Model) now, which will require a lot more changes than it looks.For example - in table node, we have too many UniqueCollControl, which requires these changes.Perhaps - but I fail to see how this justifies the different UI design for this one use. Are we talking about the same thing?Yes - we do.It is not change in the design of the UI control, but - we will need to replace simplified subnode control (which is already present in the system), and make the validation check in each of the data model one at a time.We need to keep the UI at other place, until we fix the data validation part at each of those places.We will remove the UniqueColControl once we complete all these changes.That's why - I said it was mistake to do the validation in Control rather than the data (Backbone.Model).--Thanks & Regards,Ashesh Vashi--Dave Page
Blog: http://pgsnake.blogspot.com
Twitter: @pgsnake
EnterpriseDB UK: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
Attachment
Thanks - committed with minor tweaks! On Mon, Jul 18, 2016 at 10:32 AM, Harshal Dhumal <harshal.dhumal@enterprisedb.com> wrote: > Hi, > > PFA patch for issue RM1241 > > Changes: 1. Altered variable control to make its UI consistence with > privileges and Security labels. > 2. Changed datamodel.js to handle duplicate rows at datamodel level and not > UI/Control level. (See variable control for example) > > > > -- > Harshal Dhumal > Software Engineer > > EnterpriseDB India: http://www.enterprisedb.com > The Enterprise PostgreSQL Company > > On Wed, Jun 15, 2016 at 7:57 PM, Ashesh Vashi > <ashesh.vashi@enterprisedb.com> wrote: >> >> On Wed, Jun 15, 2016 at 7:24 PM, Dave Page <dpage@pgadmin.org> wrote: >>> >>> >>> >>> On Wed, Jun 15, 2016 at 2:08 PM, Ashesh Vashi >>> <ashesh.vashi@enterprisedb.com> wrote: >>>> >>>> On Wed, Jun 15, 2016 at 6:25 PM, Dave Page <dpage@pgadmin.org> wrote: >>>>> >>>>> On Wed, Jun 15, 2016 at 1:49 PM, Ashesh Vashi >>>>> <ashesh.vashi@enterprisedb.com> wrote: >>>>> > On Thu, Jun 2, 2016 at 1:59 PM, Dave Page <dpage@pgadmin.org> wrote: >>>>> >> >>>>> >> >>>>> >> >>>>> >> On Tue, May 31, 2016 at 8:53 PM, Harshal Dhumal >>>>> >> <harshal.dhumal@enterprisedb.com> wrote: >>>>> >>> >>>>> >>> Hi Dave, >>>>> >>> >>>>> >>> Regarding Issue 1241: >>>>> >>> >>>>> >>> We have added header section for parameter tab deliberately so that >>>>> >>> we >>>>> >>> can force user to select parameter name (and therefore parameter's >>>>> >>> data >>>>> >>> type) before adding new row. This is required because behavior of >>>>> >>> second >>>>> >>> cell (Value cell) is dependent on what parameter name user has >>>>> >>> selected in >>>>> >>> first cell (Name cell). See attached screen-shot. >>>>> >>> >>>>> >>> For example: >>>>> >>> 1. If user selects parameter 'array_nulls' then value for this >>>>> >>> should be >>>>> >>> either true or false (and hence switch cell). >>>>> >>> 2. If user selects parameter 'cpu_index_tuple_cost' then value for >>>>> >>> this >>>>> >>> should be Integer (and hence Integer cell). >>>>> >>> >>>>> >>> Without the custom header (and forcing user to select parameter) we >>>>> >>> cannot decide what type of cell we need in second column. >>>>> >>> >>>>> >>> Let me know your opinion on this. >>>>> >> >>>>> >> >>>>> >> We need to figure out a way to fix it. Our difficulties encountered >>>>> >> writing code should not dictate usability compromises. >>>>> >> >>>>> >> In this case, something that needs some thought and maybe some >>>>> >> tricky code >>>>> >> has caused us to create an inconsistent UI workflow to side-step the >>>>> >> problem, which is not appropriate as it leads to a poor look and >>>>> >> feel and >>>>> >> potentially confusion for the user. >>>>> > >>>>> > Agree - we should handle these cases gracefully. >>>>> > We need to over come the limitation by brain storming, which we >>>>> > already >>>>> > started offline. :-) >>>>> > >>>>> > To be honest - it is a time consuming work, and there is no quick fix >>>>> > for >>>>> > this. >>>>> > We can handle it as one case for each change instead of targeting all >>>>> > UI >>>>> > changes as one whole problem. >>>>> > And, we can utilize the same time to fix a lot more cases in beta 2. >>>>> >>>>> As far as I'm aware, this is the only case where there's a real >>>>> problem. >>>>> >>>>> > I can ask Harshal to find out all possible places, where the similar >>>>> > changes >>>>> > are required, and create a separate case for each (though - not >>>>> > without your >>>>> > agreement). >>>>> >>>>> I don't think we need to. This one sub-node grid (parameters) is the >>>>> only one that I've seen where we deviate from the intended design - >>>>> and I think I've seen them all now! >>>> >>>> Hmm.. >>>> >>>> Unfortunately - some set of columns needs to be unique in most of the >>>> cases (where these controls are used), and the checks for the unique dataset >>>> is done at the control side, which was wrong at our end. >>>> And, we will need to change the model validation code to check the >>>> uniqueness of data set at data level (through Backbone.Model) now, which >>>> will require a lot more changes than it looks. >>>> >>>> For example - in table node, we have too many UniqueCollControl, which >>>> requires these changes. >>> >>> >>> Perhaps - but I fail to see how this justifies the different UI design >>> for this one use. Are we talking about the same thing? >> >> Yes - we do. >> It is not change in the design of the UI control, but - we will need to >> replace simplified subnode control (which is already present in the system), >> and make the validation check in each of the data model one at a time. >> >> We need to keep the UI at other place, until we fix the data validation >> part at each of those places. >> We will remove the UniqueColControl once we complete all these changes. >> >> That's why - I said it was mistake to do the validation in Control rather >> than the data (Backbone.Model). >> >> >> -- >> Thanks & Regards, >> Ashesh Vashi >> >>> >>> >>> -- >>> Dave Page >>> Blog: http://pgsnake.blogspot.com >>> Twitter: @pgsnake >>> >>> EnterpriseDB UK: http://www.enterprisedb.com >>> The Enterprise PostgreSQL Company >> >> > -- Dave Page Blog: http://pgsnake.blogspot.com Twitter: @pgsnake EnterpriseDB UK: http://www.enterprisedb.com The Enterprise PostgreSQL Company