This letter related to “Extended support for index-only-scan” from my previous message in the thread.
WIP version of the patch is ready for a while now and I think it is time to resume the work on the feature. BTW, I found a small article about Oracle vs Postgres focusing this issue -
https://blog.dbi-services.com/postgres-vs-oracle-access-paths-viii/Current WIP version of the patch is located here -
https://github.com/postgres/postgres/compare/88ba0ae2aa4aaba8ea0d85c0ff81cc46912d9308...michail-nikolaev:index_only_fetch, passing all checks. In addition, patch includes small optimization for caching of amcostestimate results.
For now, I decide to name the plan as “Index Only Fetch Scan”. Therefore:
* In case of “Index Scan” – we touch the index and heap for EVERY tuple we need to test
* For “Index Only Scan” – we touch the index for every tuple and NEVER touch the heap
* For “Index Only Fetch Scan” – we touch the index for every tuple and touch the heap for those tuples we need to RETURN ONLY.
I still have no idea – maybe it should be just “Index Only Scan”, or just “Index Scan” or whatever. Technically, it is implemented inside nodeIndexonlyscan.c for now.
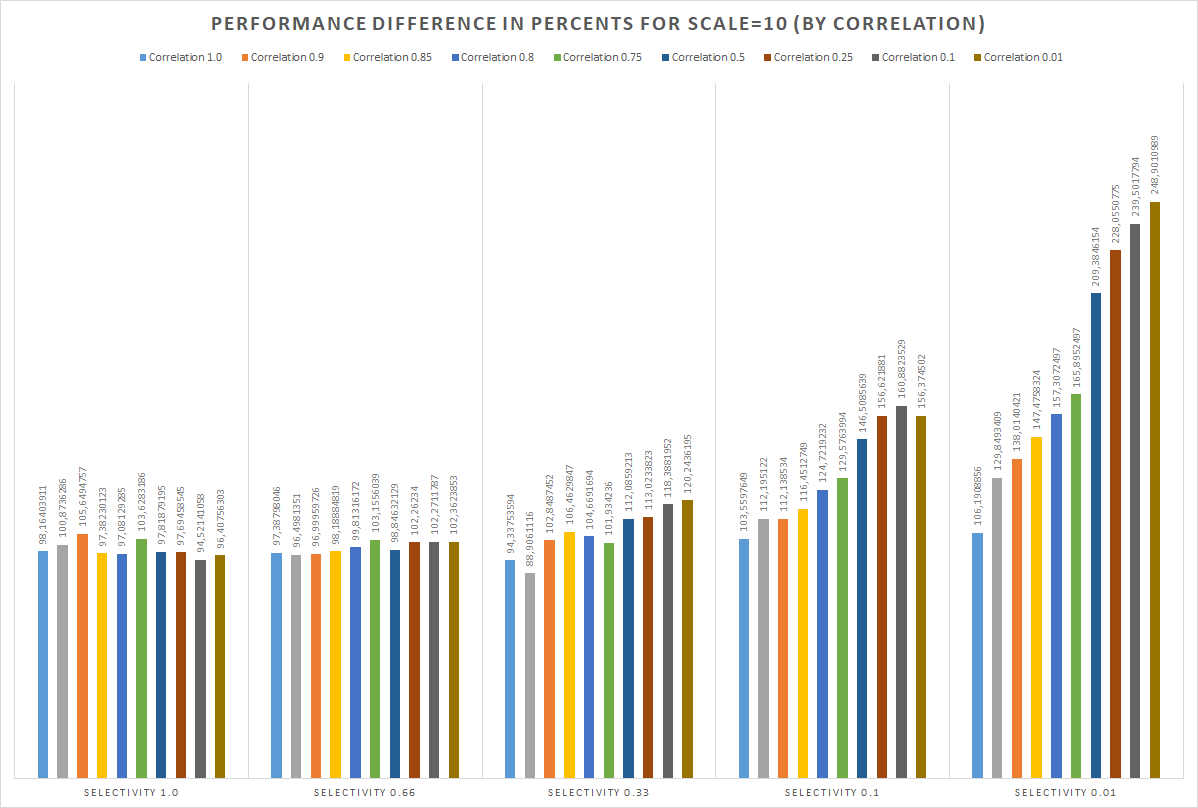
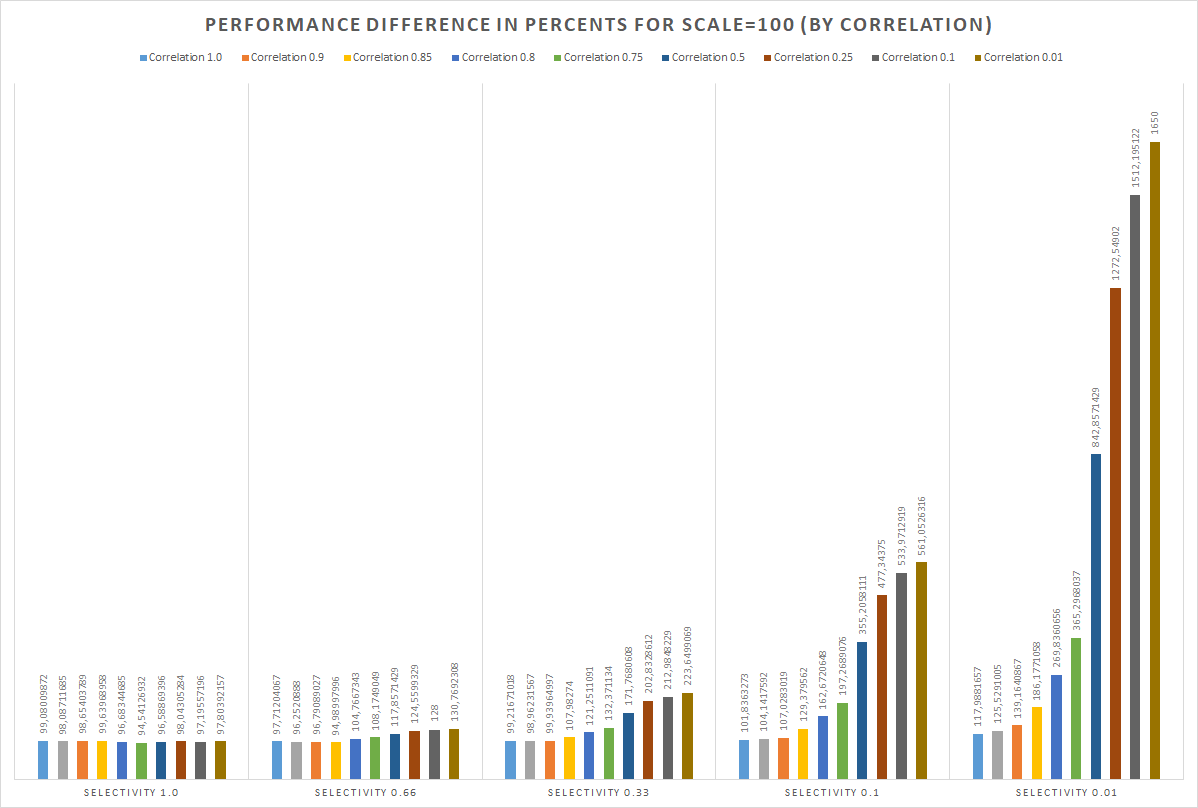
I made simple test framework based on pg_bench to compare performance under different conditions. It seems like performance boost mostly depends on two parameters – index correlation and predicate selectivity (and percentage of completely visible pages, of course). Testing script is located here -
https://gist.github.com/michail-nikolaev/23e1520a1db1a09ff2b48d78f0cde91dThere are raw testing results for SSD -
https://gist.github.com/michail-nikolaev/9cfbeee1555c6f051822bf1a2b2fe76d . In addition, some graphics are attached. Basically speaking - optimization provides great performance impact, especially for indexes with low correlation and queries with low predicate selectivity. However, to avoid 3-4% performance degradation in opposite cases – it is required to design and implement accurate costing solution.
I think it could be a great feature, especially together with covering indexes. However, am I still not sure how to name it, what is a better way to implement it (custom plan or part of index-only), is any chance to merge it once it is ready?
It seems to be kind of big deal – new type of scan (ignoring the fact is it not so new technically). Of course, it applies only to queries with predicates that are not used for index traverse but could be resolved using index data (qpquals).
Additionally, OFFSET optimization could be easily achieved once “Index Only Fetch” is implemented.
Still need some advice here…
{kind=link}
{kind=link}