On Fri, Jan 27, 2012 at 5:35 AM, Heikki Linnakangas
<heikki.linnakangas@enterprisedb.com> wrote:
> On 26.01.2012 04:10, Robert Haas wrote:
>
>>
>> I think you should break this off into a new function,
>> LWLockWaitUntilFree(), rather than treating it as a new LWLockMode.
>> Also, instead of adding lwWaitOnly, I would suggest that we generalize
>> lwWaiting and lwExclusive into a field lwWaitRequest, which can be set
>> to 1 for exclusive, 2 for shared, 3 for wait-for-free, etc. That way
>> we don't have to add another boolean every time someone invents a new
>> type of wait - not that that should hopefully happen very often. A
>> side benefit of this is that you can simplify the test in
>> LWLockRelease(): keep releasing waiters until you come to an exclusive
>> waiter, then stop. This possibly saves one shared memory fetch and
>> subsequent test instruction, which might not be trivial - all of this
>> code is extremely hot.
>
>
> Makes sense. Attached is a new version, doing exactly that.
Others are going to test this out on high-end systems. I wanted to
try it out on the other end of the scale. I've used a Pentium 4,
3.2GHz,
with 2GB of RAM and with a single IDE drive running ext4. ext4 is
amazingly bad on IDE, giving about 25 fsync's per second (and it lies
about fdatasync, but apparently not about fsync)
I ran three modes, head, head with commit_delay, and the group_commit patch
shared_buffers = 600MB
wal_sync_method=fsync
optionally with:
commit_delay=5
commit_siblings=1
pgbench -i -s40
for clients in 1 5 10 15 20 25 30
pgbench -T 30 -M prepared -c $clients -j $clients
ran 5 times each, taking maximum tps from the repeat runs.
The results are impressive.
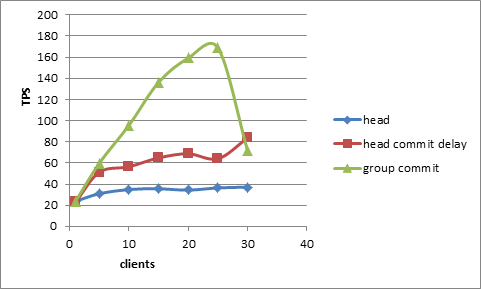
clients head head_commit_delay group_commit
1 23.9 23.0 23.9
5 31.0 51.3 59.9
10 35.0 56.5 95.7
15 35.6 64.9 136.4
20 34.3 68.7 159.3
25 36.5 64.1 168.8
30 37.2 83.8 71.5
I haven't inspected that deep fall off at 30 clients for the patch.
By way of reference, if I turn off synchronous commit, I get
tps=1245.8 which is 100% CPU limited. This sets an theoretical upper
bound on what could be achieved by the best possible group committing
method.
If the group_commit patch goes in, would we then rip out commit_delay
and commit_siblings?
Cheers,
Jeff
{kind=link}