Hi, Alexander!
> Let's see the performance results for the patchset. I'll properly
> revise the comments if results will be good.
>
> Pavel, could you please re-run your tests over revised patchset?
Since last time I've improved the test to avoid significant series
differences due to AWS storage access variation that is seen in [1].
I.e. each series of tests is run on a tmpfs with newly inited pgbench
tables and vacuum. Also, I've added a test for low-concurrency updates
where the locking optimization isn't expected to improve performance,
just to make sure the patches don't make things worse.
The tests are as follows:
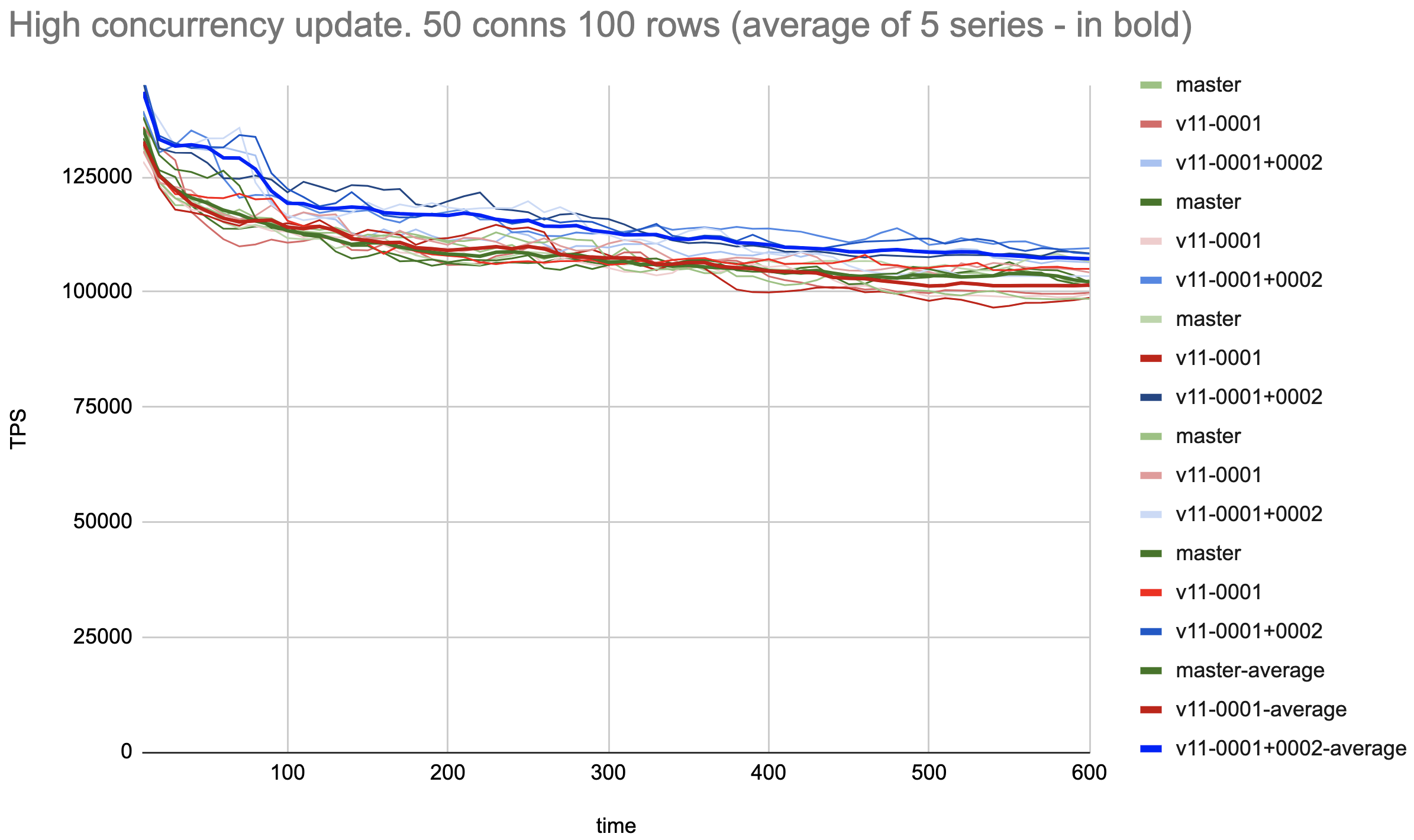
1. Heap updates with high tuple concurrency:
Prepare without pkeys (pgbench -d postgres -i -I dtGv -s 10 --unlogged-tables)
Update tellers 100 rows, 50 conns ( pgbench postgres -f
./update-only-tellers.sql -s 10 -P10 -M prepared -T 600 -j 5 -c 50 )
Result: Average of 5 series with patches (0001+0002) is around 5%
faster than both master and patch 0001. Still, there are some
fluctuations between different series of the measurements of the same
patch, but much less than in [1]
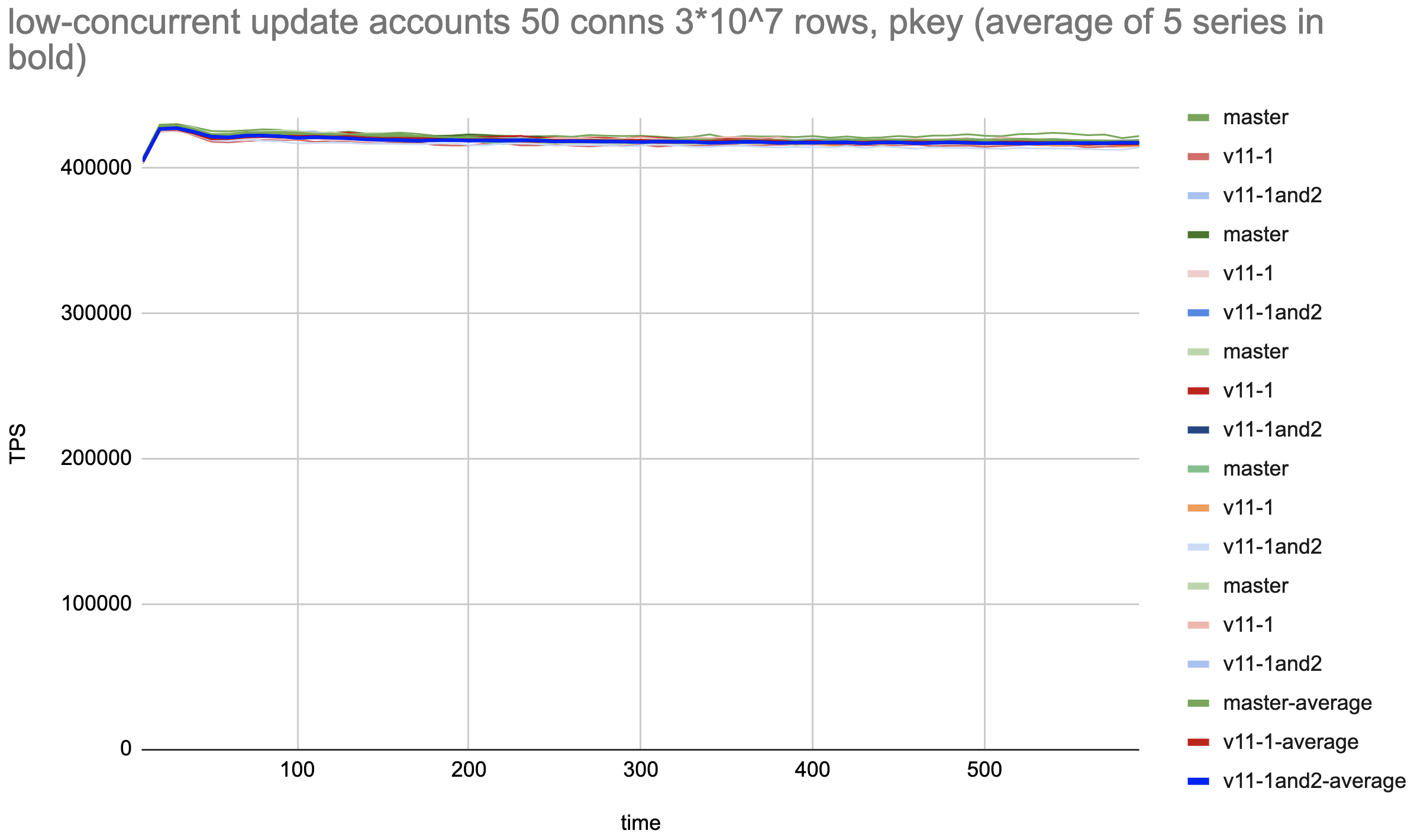
2. Heap updates with low tuple concurrency:
Prepare with pkeys (pgbench -d postgres -i -I dtGvp -s 300 --unlogged-tables)
Update 3*10^7 rows, 50 conns (pgbench postgres -f
./update-only-account.sql -s 300 -P10 -M prepared -T 600 -j 5 -c 50)
Result: Both patches and master are the same within a tolerance of
less than 0.7%.
Tests are run on the same 36-vcore AWS c5.9xlarge as [1]. The results
pictures are attached.
Using pkeys in low-concurrency cases is to make the index search of a
tuple to be updated. No pkeys in case of high concurrency is for
concurrent index updates not contribute to updates performance.
Common settings:
shared_memory 20Gb
max_worker_processes = 1024
max_parallel_workers = 1024
max_connections=10000
autovacuum_multixact_freeze_max_age=2000000000
autovacuum_freeze_max_age=2000000000
max_wal_senders=0
wal_level=minimal
max_wal_size = 10G
autovacuum = off
fsync = off
full_page_writes = off
Kind regards,
Pavel Borisov,
Supabase.
[1] https://www.postgresql.org/message-id/CALT9ZEGhxwh2_WOpOjdazW7CNkBzen17h7xMdLbBjfZb5aULgg%40mail.gmail.com
{kind=link}
{kind=link}