On Thu, Jul 1, 2021 at 10:43 AM Euler Taveira <euler@eulerto.com> wrote:
>
>
> Amit, thanks for rebasing this patch. I already had a similar rebased patch in
> my local tree. A recent patch broke your version v15 so I rebased it.
>
Hi,
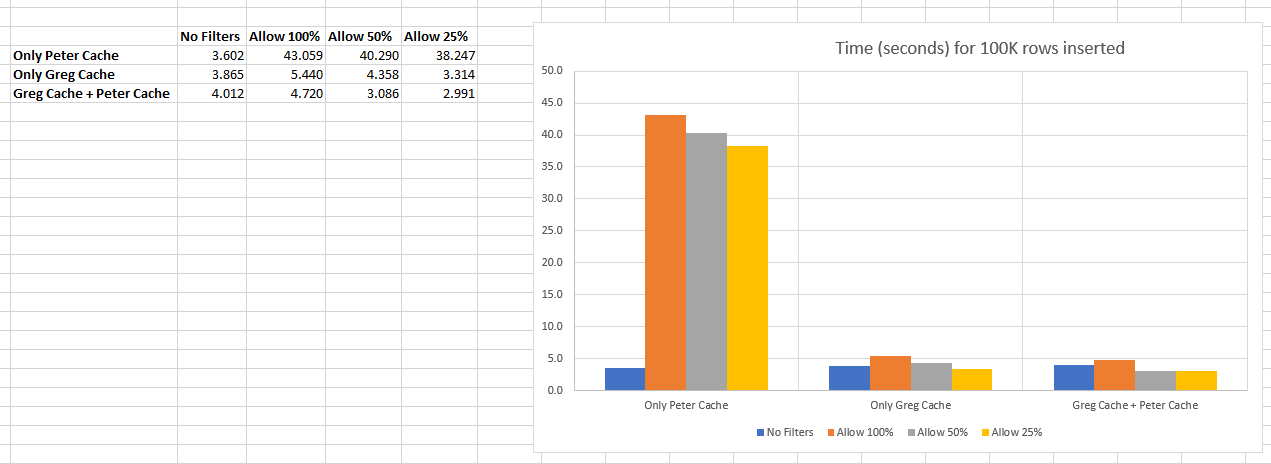
I did some testing of the performance of the row filtering, in the
case of the publisher INSERTing 100,000 rows, using a similar test
setup and timing as previously used in the “commands_to_perf_test.sql“
script posted by Önder Kalacı.
I found that with the call to ExecInitExtraTupleSlot() in
pgoutput_row_filter(), then the performance of pgoutput_row_filter()
degrades considerably over the 100,000 invocations, and on my system
it took about 43 seconds to filter and send to the subscriber.
However, by caching the tuple table slot in RelationSyncEntry, this
duration can be dramatically reduced by 38+ seconds.
A further improvement can be made using this in combination with
Peter's plan cache (v16-0004).
I've attached a patch for this, which relies on the latest v16-0001
and v16-0004 patches posted by Peter Smith (noting that v16-0001 is
identical to your previously-posted 0001 patch).
Also attached is a graph (created by Peter Smith – thanks!) detailing
the performance improvement.
Regards,
Greg Nancarrow
Fujitsu Australia
{kind=link}