Re: row filtering for logical replication - Mailing list pgsql-hackers
| From | Peter Smith |
|---|---|
| Subject | Re: row filtering for logical replication |
| Date | |
| Msg-id | CAHut+Ps5j7mkO0xLmNW=kXh0eezGoKyzBCiQc9bfkCiM_MVDrg@mail.gmail.com Whole thread |
| In response to | Re: row filtering for logical replication (Amit Kapila <amit.kapila16@gmail.com>) |
| Responses |
Re: row filtering for logical replication
|
| List | pgsql-hackers |
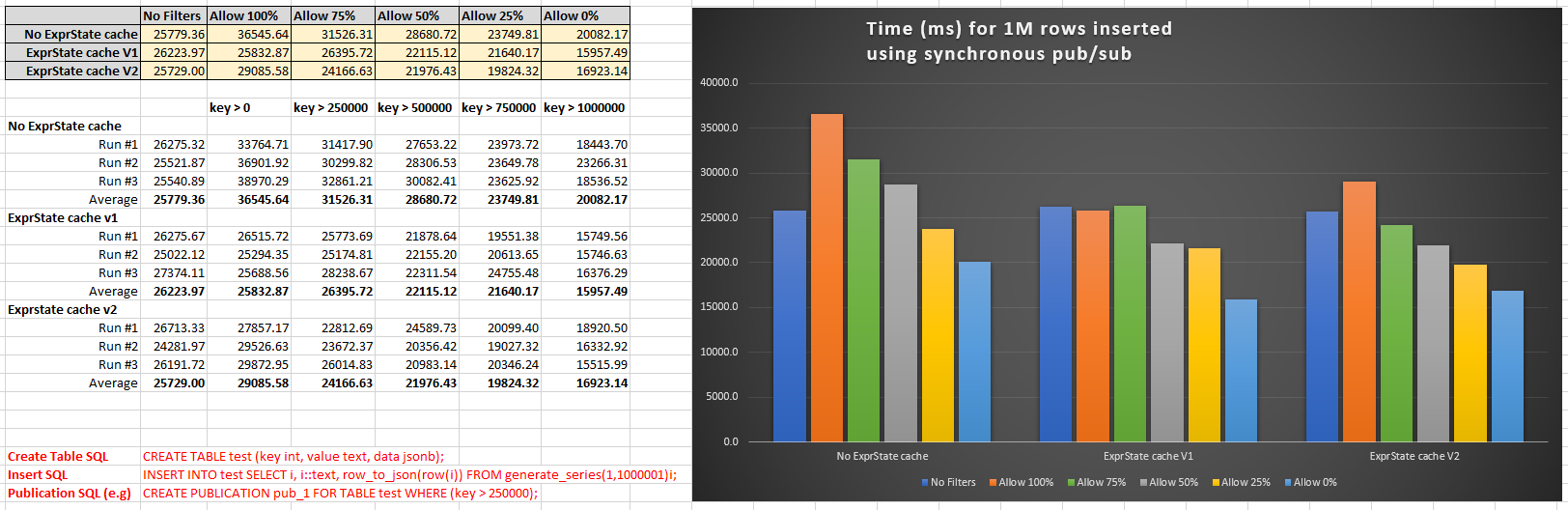
On Mon, Jul 12, 2021 at 7:35 PM Amit Kapila <amit.kapila16@gmail.com> wrote: > > On Mon, Jul 12, 2021 at 1:09 AM Euler Taveira <euler@eulerto.com> wrote: > > > > I did another measure using as baseline the previous patch (v16). > > > > without cache (v16) > > --------------------------- > > > > mean: 1.46 us > > stddev: 2.13 us > > median: 1.39 us > > min-max: [0.69 .. 1456.69] us > > percentile(99): 3.15 us > > mode: 0.91 us > > > > with cache (v18) > > ----------------------- > > > > mean: 0.63 us > > stddev: 1.07 us > > median: 0.55 us > > min-max: [0.29 .. 844.87] us > > percentile(99): 1.38 us > > mode: 0.41 us > > > > It represents -57%. It is a really good optimization for just a few extra lines > > of code. > > > > Good improvement but I think it is better to measure the performance > by using synchronous_replication by setting the subscriber as > standby_synchronous_names, which will provide the overall saving of > time. We can probably see when the timings when no rows are filtered, > when 10% rows are filtered when 30% are filtered and so on. > > I think the way caching has been done in the patch is a bit > inefficient. Basically, it always invalidates and rebuilds the > expressions even though some unrelated operation has happened on > publication. For example, say publication has initially table t1 with > rowfilter r1 for which we have cached the state. Now you altered > publication and added table t2, it will invalidate the entire state of > t1 as well. I think we can avoid that if we invalidate the rowfilter > related state only on relcache invalidation i.e in > rel_sync_cache_relation_cb and save it the very first time we prepare > the expression. In that case, we don't need to do it in advance when > preparing relsyncentry, this will have the additional advantage that > we won't spend cycles on preparing state unless it is required (for > truncate we won't require row_filtering, so it won't be prepared). > I have used debug logging to confirm that what Amit wrote [1] is correct; the row-filter ExprState of *every* table's row_filter will be invalidated (and so subsequently gets rebuilt) when the user changes the PUBLICATION tables. This was a side-effect of the rel_sync_cache_publication_cb which is freeing the cached ExprState and setting the entry->replicate_valid = false; for *every* entry. So yes, the ExprCache is getting rebuilt for some situations where it is not strictly necessary to do so. But... 1. Although the ExprState cache is effective, in practice the performance improvement was not very much. My previous results [2] showed only about 2sec saving for 100K calls to the pgoutput_row_filter function. So I think eliminating just one or two unnecessary calls in the get_rel_sync_entry is going to make zero observable difference. 2. IMO it is safe to expect that the ALTER PUBLICATION is a rare operation relative to the number of times that pgoutput_row_filter will be called (the pgoutput_row_filter is quite a "hot" function since it is called for every INSERT/UPDATE/DELETE). It will be orders of magnitude difference 1:1000, 1:100000 etc. ~~ Anyway, I have implemented the suggested cache change because I agree it is probably theoretically superior, even if in practice there is almost no difference. PSA 2 new patches (v24*) Summary: 1. Now the rfnode_list row-filter cache is built 1 time only in function get_rel_sync_entry. 2. Now the ExprState list cache is lazy-built 1 time only when first needed in function pgoutput_row_filter 3. Now those caches are invalidated in function rel_sync_cache_relation_cb; Invalidation of one relation's caches will no longer cause the other relations' row-filter caches to be re-built. ------ I also ran performance tests to compare the old/new ExprState caching. These tests are inserting 1 million rows using different percentages of row filtering. Please refer to the attached result data/results. The main takeaway points from the test results are: 1. Using row-filter ExprState caching is slightly better than having no ExprState caching. 2. The old/new style ExprState caches have approximately the same performance. Essentially the *only* runtime difference with the old/new cache is the added condition in the pgouput_row_filter to check if the ExprState cache needs to be lazy-built or not. Over a million rows maybe this extra condition accounts for a tiny difference or maybe the small before/after differences can be attributed just to natural runtime variations. ------ [1] https://www.postgresql.org/message-id/CAA4eK1%2BxQb06NGs6Y7OzwMtKYYixEqR8tdWV5THAVE4SAqNrDg%40mail.gmail.com [2] https://www.postgresql.org/message-id/CAHut%2BPs3GgPKUJ2npfY4bQdxAmYW%2ByQin%2BhQuBsMYvX%3DkBqEpA%40mail.gmail.com Kind Regards, Peter Smith. Fujitsu Australia
Attachment
{kind=link}
pgsql-hackers by date: