Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements - Mailing list pgsql-hackers
| From | Mihail Nikalayeu |
|---|---|
| Subject | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements |
| Date | |
| Msg-id | CADzfLwVOcZ9mg8gOG+KXWurt=MHRcqNv3XSECYoXyM3ENrxyfQ@mail.gmail.com Whole thread |
| In response to | Re: Revisiting {CREATE INDEX, REINDEX} CONCURRENTLY improvements (Mihail Nikalayeu <mihailnikalayeu@gmail.com>) |
| List | pgsql-hackers |
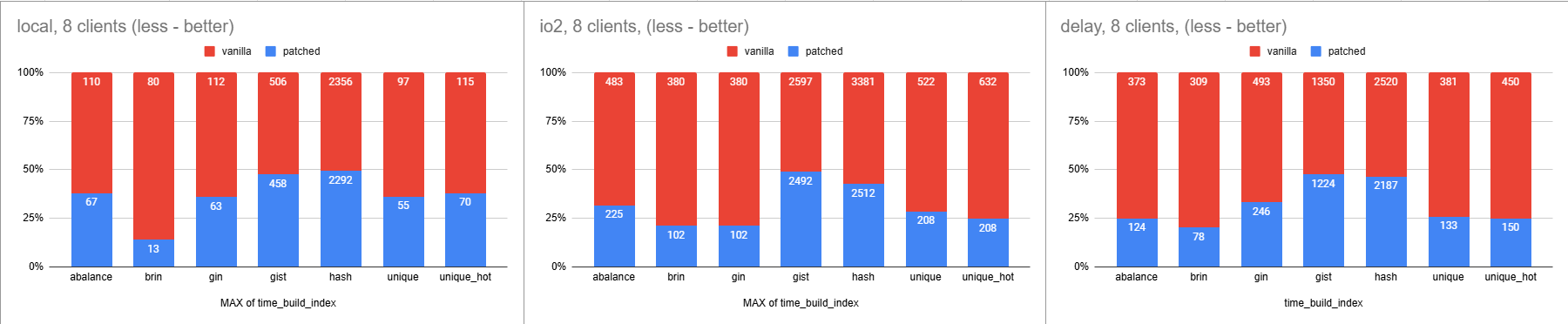
Hello, Andres! This is a gentle ping [1] about the patch related to optimization of RE|CREATE INDEX CONCURRENTLY. Below is an explanation of the patch set. QUICK INTRO What patch set does in a few words: "CIC/RIC are 2x-3x faster and does not prevent xmin horizon to advance, without any dirty tricks, even with removing one of them". How it works in a few words: "Reset snapshot between pages during the first phase. Replaces the second phase using a special auxiliary index to collect TIDs of tuples that need to be inserted into the target index after the first phase". What are drawbacks: "some additional complexity + additional auxiliary index-like structure involved." SOME HISTORY In 2021 Álvaro proposed [2] and committed [3] the feature: VACUUM ignores snapshots involved into concurrent indexing operations. This was a great feature in PG14. But in 2022 a bug related to the tuples missing in indexes was detected, and a little bit later explained by Andres [4]. As a result, feature was reverted [5] with Álvaro's comment[6]: > Deciding to revert makes me sad, because this feature is extremely > valuable for users. However, I understand the danger and I don't > disagree with the rationale so I can't really object. There were some proposals, like introducing a special horizon for HOT-pruning or stopping it during the CIC, but after some discussions Andres said [7]: > I'm also doubtful it's the right approach. > The problem here comes from needing a snapshot for the entire duration of the validation scan > ISTM that we should work on not needing that snapshot, rather than trying to reduce the consequences of holding that snapshot. > I think it might be possible to avoid it. So, given these two ideas I began the work on the patch. STRUCTURE Patch itself contains 4 parts, some of them may be reviewed/committed separately. All commit messages are detailed and contain additional explanation of changes. To not confuse CFBot, commits are presented in the following way: part 1, 2, 3 and 4. If you want only part 3 to test/review – check the files with "patch_" extensions. They differ a little bit, but changes are minor. PART 1 Test set (does not depend on anything) This is a set of stress tests and some fixes required for those tests to reliably succeed (even on current master branch). That part is not required for any other parts – its goal is to make sure everything is still working correctly while applying other parts/commits. It includes: - fixes related to races in case of ON CONFLICT UPDATE + REINDEX CONCURRENTLY (issue was discovered during testing of that patch) [8] - fixes in bt_index_parent_check (issue was discovered during testing of that patch with enormous amount of pain – I was looking for months for error in patch because of single fail of bt_index_parent_check but it was an issue with bt_index_parent_check itself) [9]. PART 2 Resetting snapshots during the first phase of CIC (does not depend on anything) It is based on Matthias' idea [10] - to just reset snapshots every so often during a concurrent index build. It may work only during the first scan (because we'll miss some tuples anyway during validation scan with such approach). Logic is simple – since the index built by the first scan already misses a lot of tuples – we may not worry to miss a few more – the validation phase is going to fix it anyway. Of course it is not so simple in case of unique indexes, but still possible. Once committed: xmin is advanced at least during the first phase of concurrent index build. Commits are: - Reset snapshots periodically in non-unique non-parallel concurrent index builds Apply this technique to the simplest case – non-unique and non-parallel. Snapshot is changed "between" pages. One possible place here to worry about – to ensure xmin advanced we need to call InvalidateCatalogSnapshot during each snapshot switch. So, theoretically it may cause some issues, but the table is locked to changes during the process. At least commit [3] (which ignored xmin of CIC backend) did the same thing actually. Another more "clear" option here - we may just extract a separate catalog snapshot horizon (one more field near xmin specially only for catalog snapshot), it seems to be a pretty straightforward change). - Support snapshot resets in parallel concurrent index builds Extend that technique to parallel builds. It is mostly about ensuring workers have an initial snapshot restored from the leader before the leader goes to reset it. - Support snapshot resets in concurrent builds of unique indexes The most tricky commit in the second part – apply that to unique indexes. Changing of snapshots may cause issues with validation of unique constraints. Currently validation is done during the sorting of tuples, but that doesn't work with tuples read with different snapshots (some of them are dead already). To deal with it: - in case we see two identical tuples during tuplesort – ignore if some of them are dead according to SnapshotSelf, but fail if two are alive. It is not a required part, it is just mechanics for fail-fast behavior and may be removed. - to provide the guarantee – during _bt_load compare the inserted index value with previously inserted. If they are equal – make sure only a single SnapshotSelf alive tuple exists in the whole equal "group" (it may include more than two tuples in general). Theoretically it may affect performance of _bt_load because of _bt_keep_natts(_fast) call for each tuple, but I was unable to notice any significant difference here. Anyway it is compensated by Part 3 for sure. PART 3 STIR-based validation phase CIC (does not depend on anything) That part is about a way to replace the second phase of CIC in a more effective way (and with the ability to allow horizon advance as an additional bonus). The role of the second phase is to find tuples which are not present in the index built by the first scan, because: - some of them were too new for the snapshot used during the first phase - even if we were to use SnapshotSelf to accept all alive tuples – some of them may be inserted in pages already visited by the scan The main idea is: - before starting the first scan lets prepare a special auxiliary super-lightweight index (it is not even an index or access method, just pretends to be) with the same columns, expressions and predicates - that access method (Short Term Index Replacement – STIR) just appends TID of new coming tuples, without WAL, minimum locking, simplest append-only structure, without actual indexed data - it remembers all new TIDs inserted to the table during the first phase - once our main (target) index receives updates itself we may safely clear "ready" flag on STIR - if our first phase scan missed something – it is guaranteed to be present in that STIR index - so, instead of requirement to compare the whole table to the index, we need only to compare to TIDs stored in the STIR - as a bonus we may reset snapshots during the comparison without risk of any issues caused by HOT pruning (the issue [4] caused revert of [3]). That approach provides a significant performance boost in terms of time required to build the index. STIR itself theoretically causes some performance impact, but I was not able to detect it. Also, some optimizations are applied to it (see below). Details of benchmarks are presented below as well. Commits are: - Add STIR access method and flags related to auxiliary indexes This one adds STIR code and some flags to distinguish real and auxiliary indexes. - Add Datum storage support to tuplestore Add ability to store Datum in tuplestore. It is used by the following commits to leverage performance boost from prefetching of the pages during validation phase. - Use auxiliary indexes for concurrent index operations The main part is here. It contains all the logic for creation of auxiliary index, managing its lifecycle, new validation phase and so on (including progress reporting, some documentation updates, ability to have unlogged index for logged table, etc). At the same time it still relies on a single referenced snapshot during the validation phase. - Track and drop auxiliary indexes in DROP/REINDEX That commit adds different techniques to avoid any additional administration requirements to deal with auxiliary indexes in case of error during the index build (junk auxiliary indexes). It adds dependency tracking, special logic for handling REINDEX calls and other small things to make administrator's life a little bit easier. - Optimize auxiliary index handling Since the STIR index does not contain any actual data we may skip preparation of that during tuple insert. Commit implements such optimization. - Refresh snapshot periodically during index validation Adds logic to the new validation phase to reset the snapshot every so often. Currently it does it every 4096 pages visited. PART 4 (depends on part 2 and part 3) Commits are: - Remove PROC_IN_SAFE_IC optimization This is a small part which makes sense in case both parts 2 and 3 were applied. Once it's done – CIC does not prevent the horizon from advancing regularly. It makes the PROC_IN_SAFE_IC optimization [11] obsolete, because one CIC now has no issue waiting for the xmin of the other (because it advances regularly). BENCHMARKS I have spent a lot of time benchmarking the patch in different environments (local SSD, local SSD with 1ms delay, io2 AWS) and the results look impressive. I can't measure any performance (or significant space usage) degradation because of STIR index presence, but performance boost because of new validation phases gives up to 3x -4x time boost. And without any VACUUM-related issues during that time (so, other operations on the databases will benefit from that easily compensating additional STIR-related cost). Description of benchmarks are available here [12]. Some results are here: [13] and here [14], code is here [15]. There is also a Discord thread here [16]. Feel free to ask any question and request benchmarks for some scenarios. Best regards, Mikhail. [1]: https://discord.com/channels/1258108670710124574/1334565506149253150/1339368558408372264 [2]: https://www.postgresql.org/message-id/flat/20210115142926.GA19300%40alvherre.pgsql#0988173cb0cf4b8eb710a6cdaa88fcac [3]: https://github.com/postgres/postgres/commit/d9d076222f5b94a85e0e318339cfc44b8f26022d [4]: https://www.postgresql.org/message-id/flat/20220524190133.j6ee7zh4f5edt5je%40alap3.anarazel.de#1781408f40034c414ad6738140c118ef [5]: https://github.com/postgres/postgres/commit/e28bb885196916b0a3d898ae4f2be0e38108d81b [6]: https://www.postgresql.org/message-id/flat/202205251643.2py5jjpaw7wy%40alvherre.pgsql#589508d30b480b905619dcb93dac8cf8 [7]: https://www.postgresql.org/message-id/flat/20220525170821.rf6r4dnbbu4baujp%40alap3.anarazel.de#accf63164fd552b6ad68ff0a870e60c0 [8]: https://commitfest.postgresql.org/patch/5160/ [9]: https://commitfest.postgresql.org/patch/5438/ [10]: https://www.postgresql.org/message-id/flat/CAEze2WgW6pj48xJhG_YLUE1QS%2Bn9Yv0AZQwaWeb-r%2BX%3DHAxU_g%40mail.gmail.com#b3809c158de4481bb1b29894aaa63fae [11]: https://github.com/postgres/postgres/commit/c98763bf51bf610b3ee7e209fc76c3ff9a6b3163 [12]: https://www.postgresql.org/message-id/flat/CANtu0ojHAputNCH73TEYN_RUtjLGYsEyW1aSXmsXyvwf%3D3U4qQ%40mail.gmail.com#b18fb8efab086bc22af1cb015e187cb7 [13]: https://www.postgresql.org/message-id/flat/CANtu0ojiVez054rKvwZzKNhneS2R69UXLnw8N9EdwQwqfEoFdQ%40mail.gmail.com#02b4ee45a5a5c1ccac6d168052173952 [14]: https://docs.google.com/spreadsheets/d/1UYaqpsWSfYdZdQxaqY4gVo0RW6KrT0d-U1VDNJB8lVk/edit?usp=sharing [15]: https://gist.github.com/michail-nikolaev/b33fb0ac1f35729388c89f72db234b0f [16]: https://discord.com/channels/1258108670710124574/1259884843165155471/1334565506149253150
Attachment
- bench.png
- v18-0004-Support-snapshot-resets-in-parallel-concurrent-i.patch
- v18-0003-Reset-snapshots-periodically-in-non-unique-non-p.patch
- v18-0001-This-is-https-commitfest.postgresql.org-50-5160-.patch
- v18-0005-Support-snapshot-resets-in-concurrent-builds-of-.patch
- v18-0002-Add-stress-tests-for-concurrent-index-builds.patch
- v18-0006-Add-STIR-access-method-and-flags-related-to-auxi.patch
- v18-0007-Add-Datum-storage-support-to-tuplestore.patch
- v18-0008-Use-auxiliary-indexes-for-concurrent-index-opera.patch
- v18-0009-Track-and-drop-auxiliary-indexes-in-DROP-REINDEX.patch
- v18-0010-Optimize-auxiliary-index-handling.patch
- v18-0011-Refresh-snapshot-periodically-during-index-valid.patch
- v18-0012-Remove-PROC_IN_SAFE_IC-optimization.patch
- v18-only-part-3-0001-Add-STIR-access-method-and-flags-rel.patch_
- v18-only-part-3-0004-Track-and-drop-auxiliary-indexes-in-.patch_
- v18-only-part-3-0003-Use-auxiliary-indexes-for-concurrent.patch_
- v18-only-part-3-0005-Optimize-auxiliary-index-handling.patch_
- v18-only-part-3-0002-Add-Datum-storage-support-to-tuplest.patch_
- v18-only-part-3-0006-Refresh-snapshot-periodically-during.patch_
{kind=link}
pgsql-hackers by date: