On Tue, 24 May 2022 at 09:36, Tom Lane <tgl@sss.pgh.pa.us> wrote:
>
> David Rowley <dgrowleyml@gmail.com> writes:
> > Handy wavy idea: It's probably too complex for now, and it also might
> > be too much overhead, but having GenerationPointerGetChunk() do a
> > binary search on a sorted-by-memory-address array of block pointers
> > might be a fast enough way to find the block that the pointer belongs
> > to. There should be far fewer blocks now since generation.c now grows
> > the block sizes. N in O(log2 N) the search complexity should never be
> > excessively high.
>
> > However, it would mean a binary search for every pfree, which feels
> > pretty horrible. My feeling is that it seems unlikely that saving 8
> > bytes by not storing the GenerationBlock would be a net win here.
>
> I think probably that could be made to work, since a Generation
> context should not contain all that many live blocks at any one time.
I've done a rough cut implementation of this and attached it here.
I've not done that much testing yet, but it does seem to fix the
performance regression that I mentioned in the blog post that I linked
in the initial post on this thread.
There are a couple of things to note about the patch:
1. I quickly realised that there's no good place to store the
sorted-by-memory-address array of GenerationBlocks. In the patch, I've
had to malloc() this array and also had to use a special case so that
I didn't try to do another malloc() inside GenerationContextCreate().
It's possible that the malloc() / repalloc of this array fails. In
which case, I think I've coded things in such a way that there will be
no memory leaks of the newly added block.
2. I did see GenerationFree() pop up in perf top a little more than it
used to. I considered that we might want to have
GenerationGetBlockFromChunk() cache the last found block for the set
and then check that one first. We expect generation contexts to
pfree() in an order that would likely make us hit this case most of
the time. I added a few lines to the attached v2 patch to add a
last_pfree_block field to the context struct. However, this seems to
hinder performance more than it helps. It can easily be removed from
the v2 patch.
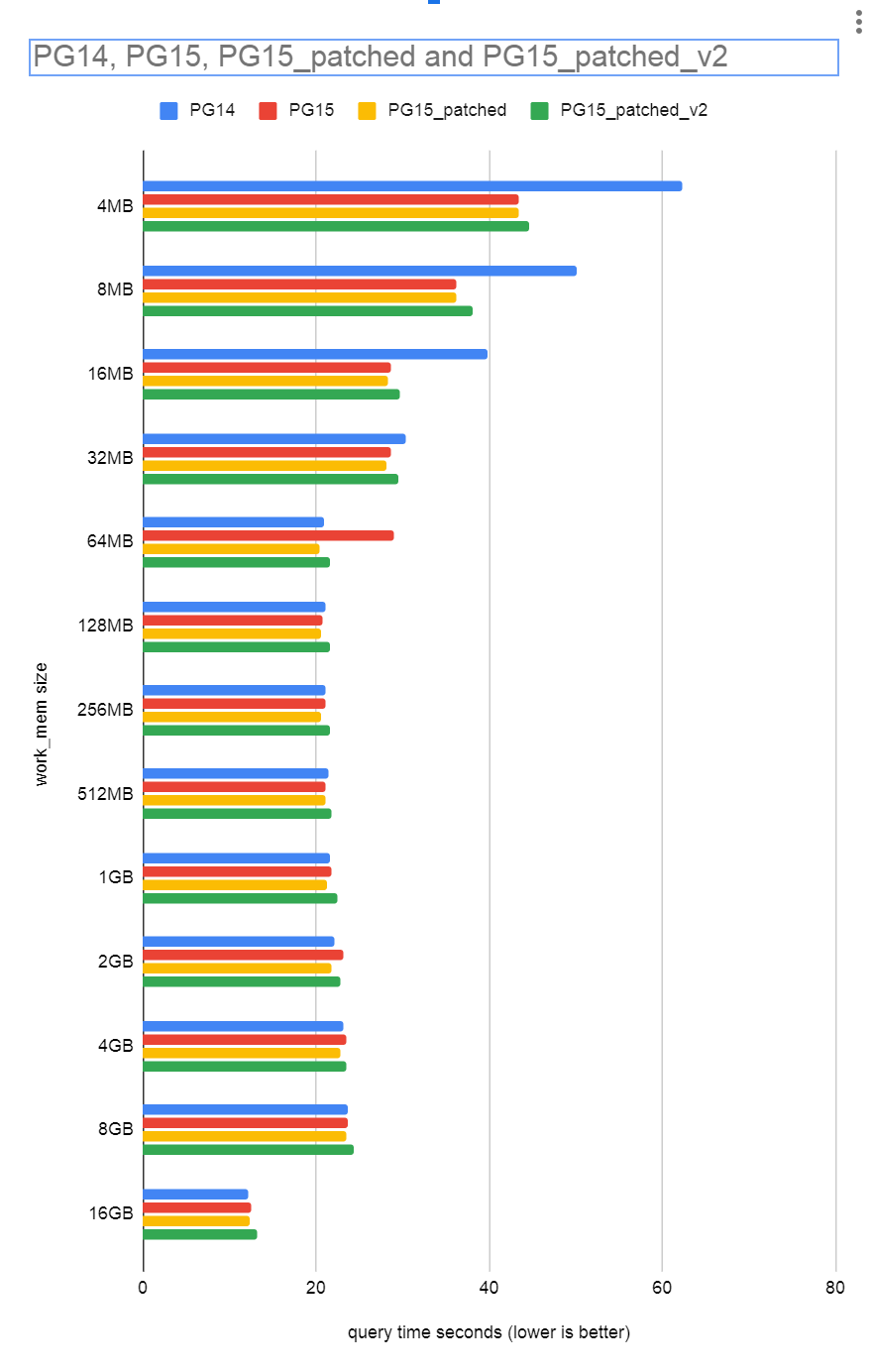
In the results you can see the PG14 + PG15 results the same as I
reported on the blog post I linked earlier. It seems that for
PG15_patched virtually all work_mem sizes produce results that are
faster than PG14. The exception here is the 16GB test where
PG15_patched is 0.8% slower, which seems within the noise threshold.
David
{kind=link}