Bloom filter Pushdown Optimization for Merge Join - Mailing list pgsql-hackers
| From | Zheng Li |
|---|---|
| Subject | Bloom filter Pushdown Optimization for Merge Join |
| Date | |
| Msg-id | CAAD30ULaxjR+Yv_aP1YAu8FmCiEqpYSne4a=n228nysuXD0LSA@mail.gmail.com Whole thread |
| Responses |
Re: Bloom filter Pushdown Optimization for Merge Join
Re: Bloom filter Pushdown Optimization for Merge Join |
| List | pgsql-hackers |
Hello,
A bloom filter provides early filtering of rows that cannot be joined
before they would reach the join operator, the optimization is also
called a semi join filter (SJF) pushdown. Such a filter can be created
when one child of the join operator must materialize its derived table
before the other child is evaluated.
For example, a bloom filter can be created using the the join keys for
the build side/inner side of a hash join or the outer side of a merge
join, the bloom filter can then be used to pre-filter rows on the
other side of the join operator during the scan of the base relation.
The thread about “Hash Joins vs. Bloom Filters / take 2” [1] is good
discussion on using such optimization for hash join without going into
the pushdown of the filter where its performance gain could be further
increased.
We worked on prototyping bloom filter pushdown for both hash join and
merge join. Attached is a patch set for bloom filter pushdown for
merge join. We also plan to send the patch for hash join once we have
it rebased.
Here is a summary of the patch set:
1. Bloom Filter Pushdown optimizes Merge Join by filtering rows early
during the table scan instead of later on.
-The bloom filter is pushed down along the execution tree to
the target SeqScan nodes.
-Experiments show that this optimization can speed up Merge
Join by up to 36%.
2. The planner makes the decision to use the bloom filter based on the
estimated filtering rate and the expected performance gain.
-The planner accomplishes this by estimating four numbers per
variable - the total number of rows of the relation, the number of
distinct values for a given variable, and the minimum and maximum
value of the variable (when applicable). Using these numbers, the
planner estimates a filtering rate of a potential filter.
-Because actually creating and implementing the filter adds
more operations, there is a minimum threshold of filtering where the
filter would actually be useful. Based on testing, we query to see if
the estimated filtering rate is higher than 35%, and that informs our
decision to use a filter or not.
3. If using a bloom filter, the planner also adjusts the expected cost
of Merge Join based on expected performance gain.
4. Capability to build the bloom filter in parallel in case of
parallel SeqScan. This is done efficiently by populating a local bloom
filter for each parallel worker and then taking a bitwise OR over all
the local bloom filters to form a shared bloom filter at the end of
the parallel SeqScan.
5. The optimization is GUC controlled, with settings of
enable_mergejoin_semijoin_filter and force_mergejoin_semijoin_filter.
We found in experiments that there is a significant improvement
when using the bloom filter during Merge Join. One experiment involved
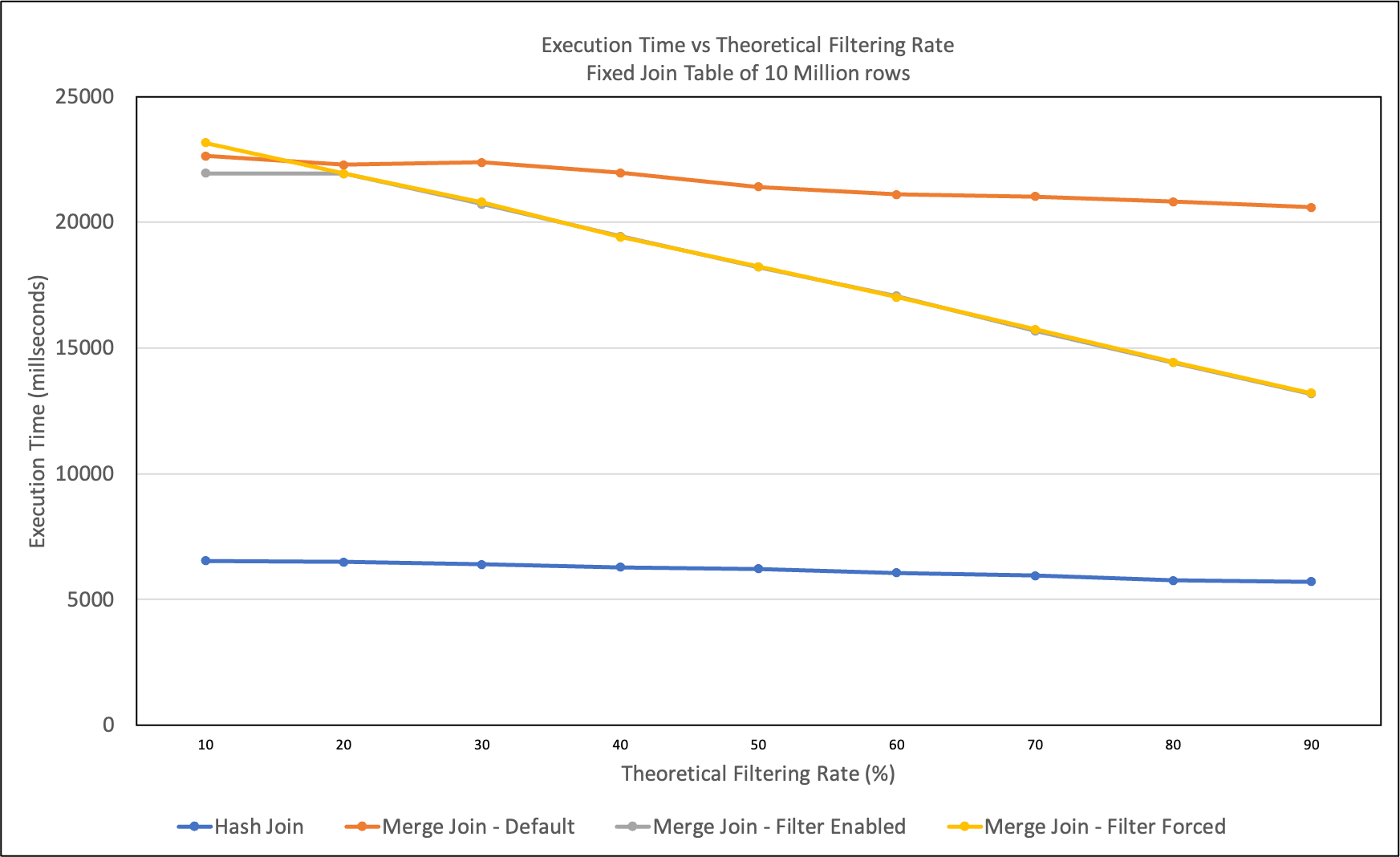
joining two large tables while varying the theoretical filtering rate
(TFR) between the two tables, the TFR is defined as the percentage
that the two datasets are disjoint. Both tables in the merge join were
the same size. We tested changing the TFR to see the change in
filtering optimization.
For example, let’s imagine t0 has 10 million rows, which contain the
numbers 1 through 10 million randomly shuffled. Also, t1 has the
numbers 4 million through 14 million randomly shuffled. Then the TFR
for a join of these two tables is 40%, since 40% of the tables are
disjoint from the other table (1 through 4 million for t0, 10 million
through 14 million for t4).
Here is the performance test result joining two tables:
TFR: theoretical filtering rate
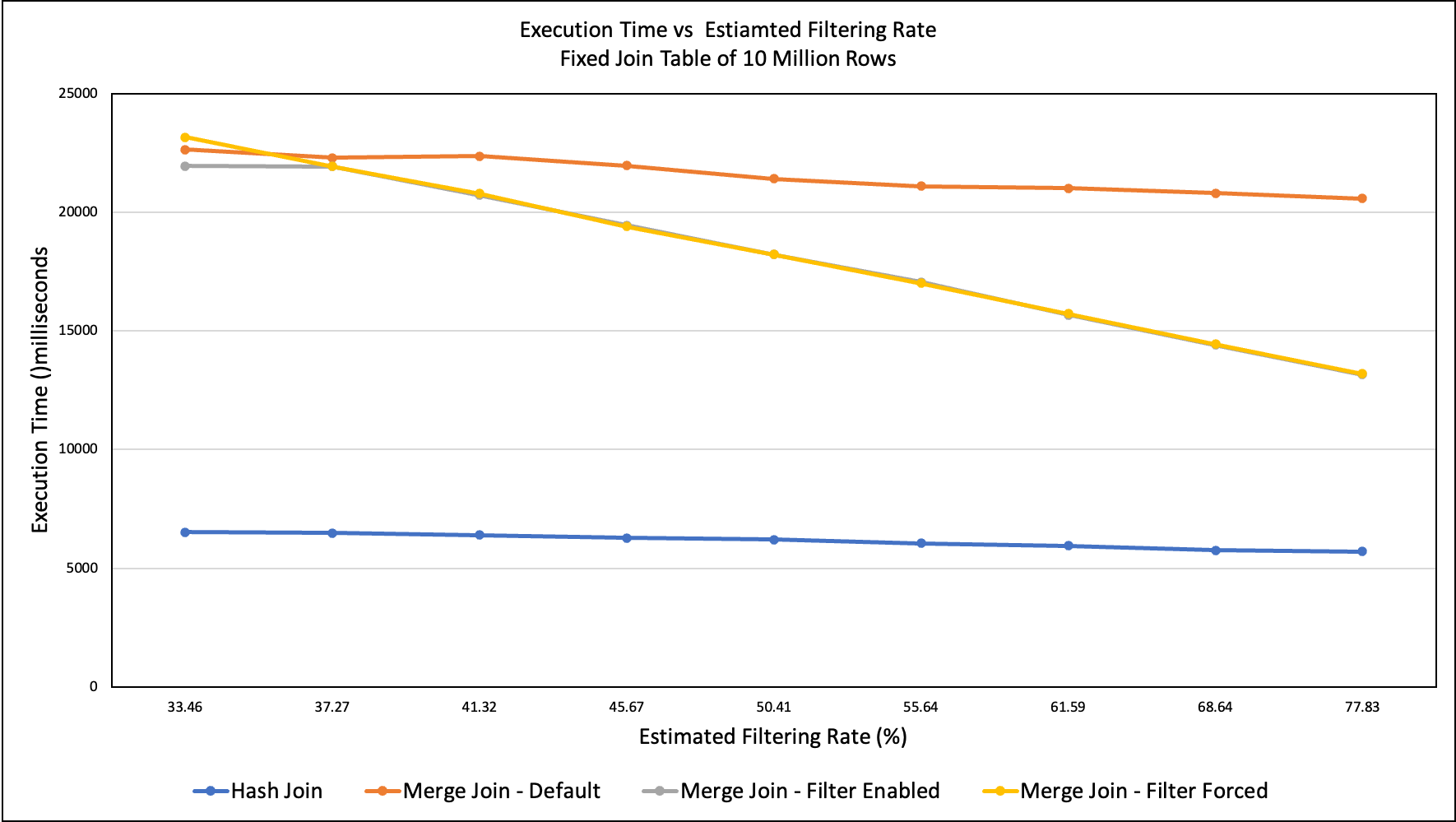
EFR: estimated filtering rate
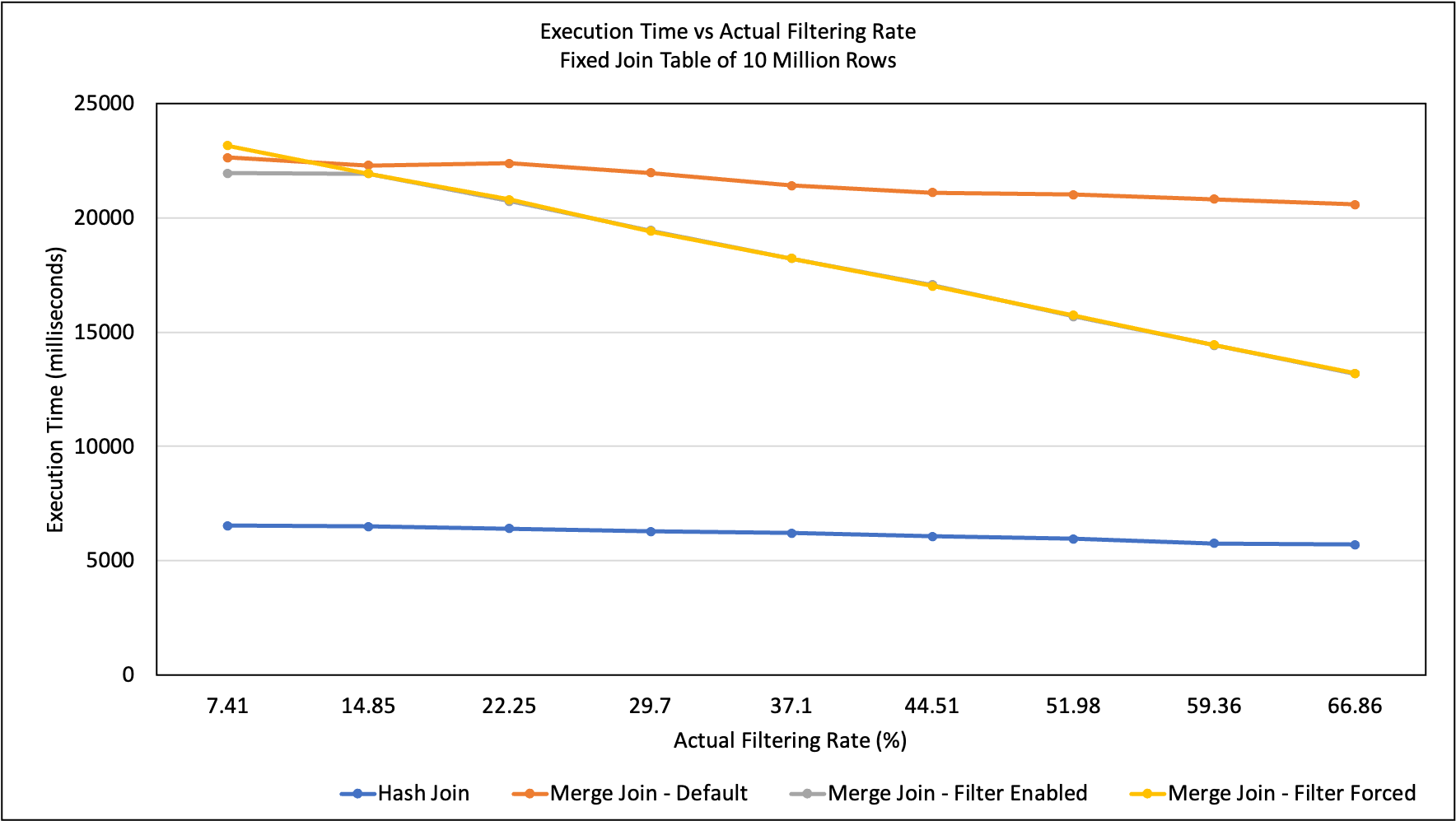
AFR: actual filtering rate
HJ: hash join
MJ Default: default merge join
MJ Filter: merge join with bloom filter optimization enabled
MJ Filter Forced: merge join with bloom filter optimization forced
TFR EFR AFR HJ MJ Default MJ Filter MJ Filter Forced
-------------------------------------------------------------------------------------
10 33.46 7.41 6529 22638 21949 23160
20 37.27 14.85 6483 22290 21928 21930
30 41.32 22.25 6395 22374 20718 20794
40 45.67 29.7 6272 21969 19449 19410
50 50.41 37.1 6210 21412 18222 18224
60 55.64 44.51 6052 21108 17060 17018
70 61.59 51.98 5947 21020 15682 15737
80 68.64 59.36 5761 20812 14411 14437
90 77.83 66.86 5701 20585 13171 13200
Table. Execution Time (ms) vs Filtering Rate (%) for Joining Two
Tables of 10M Rows.
Attached you can find figures of the same performance test and a SQL script
to reproduce the performance test.
The first thing to notice is that Hash Join generally is the most
efficient join strategy. This is because Hash Join is better at
dealing with small tables, and our size of 10 million is still small
enough where Hash Join outperforms the other join strategies. Future
experiments can investigate using much larger tables.
However, comparing just within the different Merge Join variants, we
see that using the bloom filter greatly improves performance.
Intuitively, all of these execution times follow linear paths.
Comparing forced filtering versus default, we can see that the default
Merge Join outperforms Merge Join with filtering at low filter rates,
but after about 20% TFR, the Merge Join with filtering outperforms
default Merge Join. This makes intuitive sense, as there are some
fixed costs associated with building and checking with the bloom
filter. In the worst case, at only 10% TFR, the bloom filter makes
Merge Join less than 5% slower. However, in the best case, at 90% TFR,
the bloom filter improves Merge Join by 36%.
Based on the results of the above experiments, we came up with a
linear equation for the performance ratio for using the filter
pushdown from the actual filtering rate. Based on the numbers
presented in the figure, this is the equation:
T_filter / T_no_filter = 1 / (0.83 * estimated filtering rate + 0.863)
For example, this means that with an estimated filtering rate of 0.4,
the execution time of merge join is estimated to be improved by 16.3%.
Note that the estimated filtering rate is used in the equation, not
the theoretical filtering rate or the actual filtering rate because it
is what we have during planning. In practice the estimated filtering
rate isn’t usually accurate. In fact, the estimated filtering rate can
differ from the theoretical filtering rate by as much as 17% in our
experiments. One way to mitigate the power loss of bloom filter caused
by inaccurate estimated filtering rate is to adaptively turn it off at
execution time, this is yet to be implemented.
Here is a list of tasks we plan to work on in order to improve this patch:
1. More regression testing to guarantee correctness.
2. More performance testing involving larger tables and complicated query plans.
3. Improve the cost model.
4. Explore runtime tuning such as making the bloom filter checking adaptive.
5. Currently, only the best single join key is used for building the
Bloom filter. However, if there are several keys and we know that
their distributions are somewhat disjoint, we could leverage this fact
and use multiple keys for the bloom filter.
6. Currently, Bloom filter pushdown is only implemented for SeqScan
nodes. However, it would be possible to allow push down to other types
of scan nodes.
7. Explore if the Bloom filter could be pushed down through a foreign
scan when the foreign server is capable of handling it – which could
be made true for postgres_fdw.
8. Better explain command on the usage of bloom filters.
This patch set is prepared by Marcus Ma, Lyu Pan and myself. Feedback
is appreciated.
With Regards,
Zheng Li
Amazon RDS/Aurora for PostgreSQL
[1] https://www.postgresql.org/message-id/flat/c902844d-837f-5f63-ced3-9f7fd222f175%402ndquadrant.com
Attachment
- 0001-Support-semijoin-filter-in-the-planner-optimizer.patch
- 0003-Support-semijoin-filter-in-the-executor-for-parallel.patch
- 0004-Integrate-EXPLAIN-command-with-semijoin-filter.patch
- 0002-Support-semijoin-filter-in-the-executor-for-non-para.patch
- 0005-Add-basic-regress-tests-for-semijoin-filter.patch
- semijoin_filter_performance.sql
- theoretical_filtering_rate.png
- estimated_filtering_rate.png
- actual_filtering_rate.png
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: