Re: Speed up Clog Access by increasing CLOG buffers - Mailing list pgsql-hackers
| From | Amit Kapila |
|---|---|
| Subject | Re: Speed up Clog Access by increasing CLOG buffers |
| Date | |
| Msg-id | CAA4eK1+Ebf4W7D74_1NfLZYEpUoXUKzxTjqxdankW0xMhqkLYw@mail.gmail.com Whole thread |
| In response to | Re: Speed up Clog Access by increasing CLOG buffers (Robert Haas <robertmhaas@gmail.com>) |
| Responses |
Re: Speed up Clog Access by increasing CLOG buffers
|
| List | pgsql-hackers |
On Thu, Dec 17, 2015 at 12:01 AM, Robert Haas <robertmhaas@gmail.com> wrote:
On Sat, Dec 12, 2015 at 8:03 AM, Amit Kapila <amit.kapila16@gmail.com> wrote:
>> I think it might be
>> advantageous to have at least two groups because otherwise things
>> might slow down when some transactions are rolling over to a new page
>> while others are still in flight for the previous page. Perhaps we
>> should try it both ways and benchmark.
>>
>
> Sure, I can do the benchmarks with both the patches, but before that
> if you can once check whether group_slots_update_clog_v3.patch is inline
> with what you have in mind then it will be helpful.
Benchmarking sounds good. This looks broadly like what I was thinking
about, although I'm not very sure you've got all the details right.
Unfortunately, I didn't have access to high end Intel m/c on which I took
the performance data last time, so I took on Power-8 m/c where I/O
sub-system is not that good, so the write performance data at lower scale
factor like 300 is reasonably good and at higher scale factor (>= 1000)
it is mainly I/O bound, so there is not much difference with or without
patch.
Performance Data
RAM = 492GB
-----------------------------
M/c configuration:
IBM POWER-8 24 cores, 192 hardware threadsRAM = 492GB
Non-default parameters
------------------------------------
max_connections = 300
shared_buffers=32GB
min_wal_size=10GB
max_wal_size=15GB
checkpoint_timeout =35min
maintenance_work_mem = 1GB
checkpoint_completion_target = 0.9
wal_buffers = 256MB
Attached files show the performance data with both the patches at
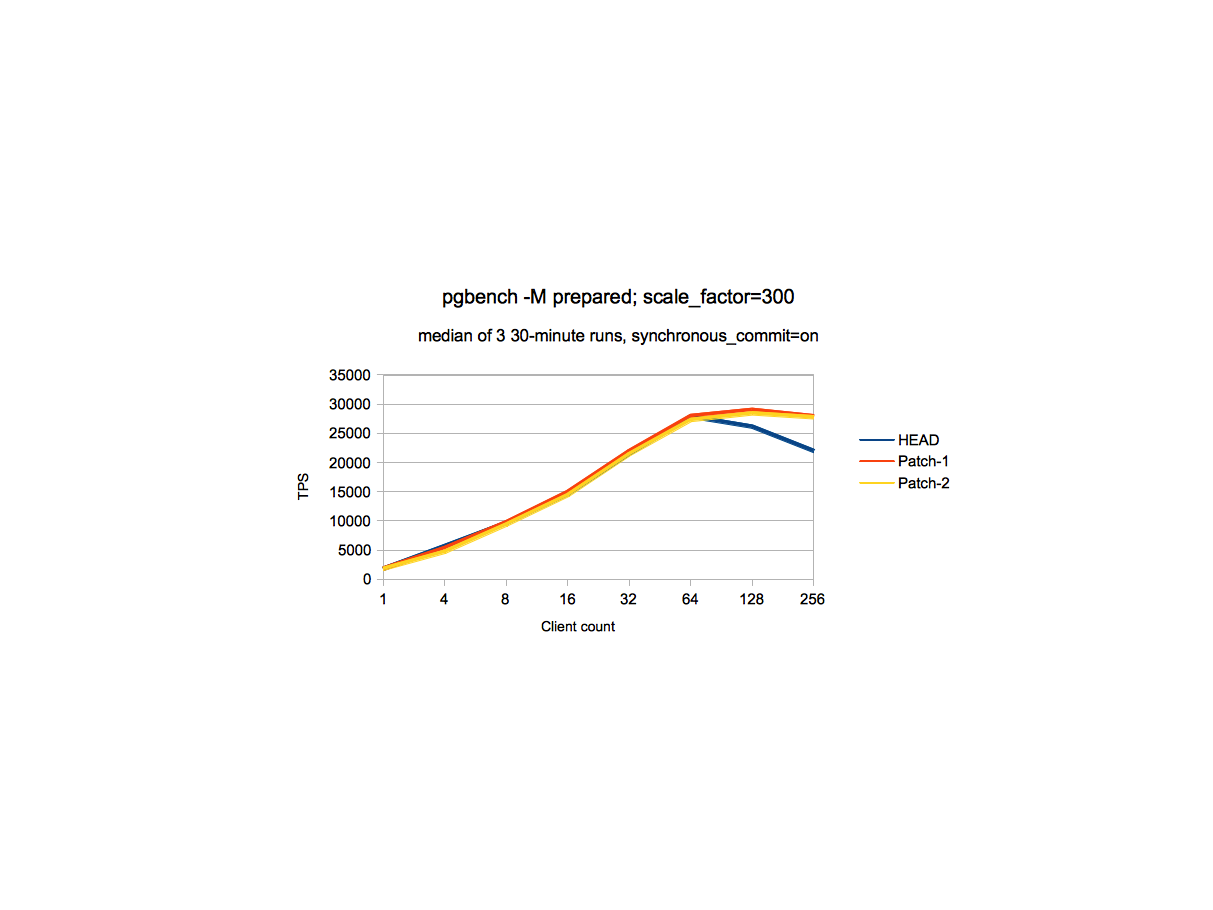
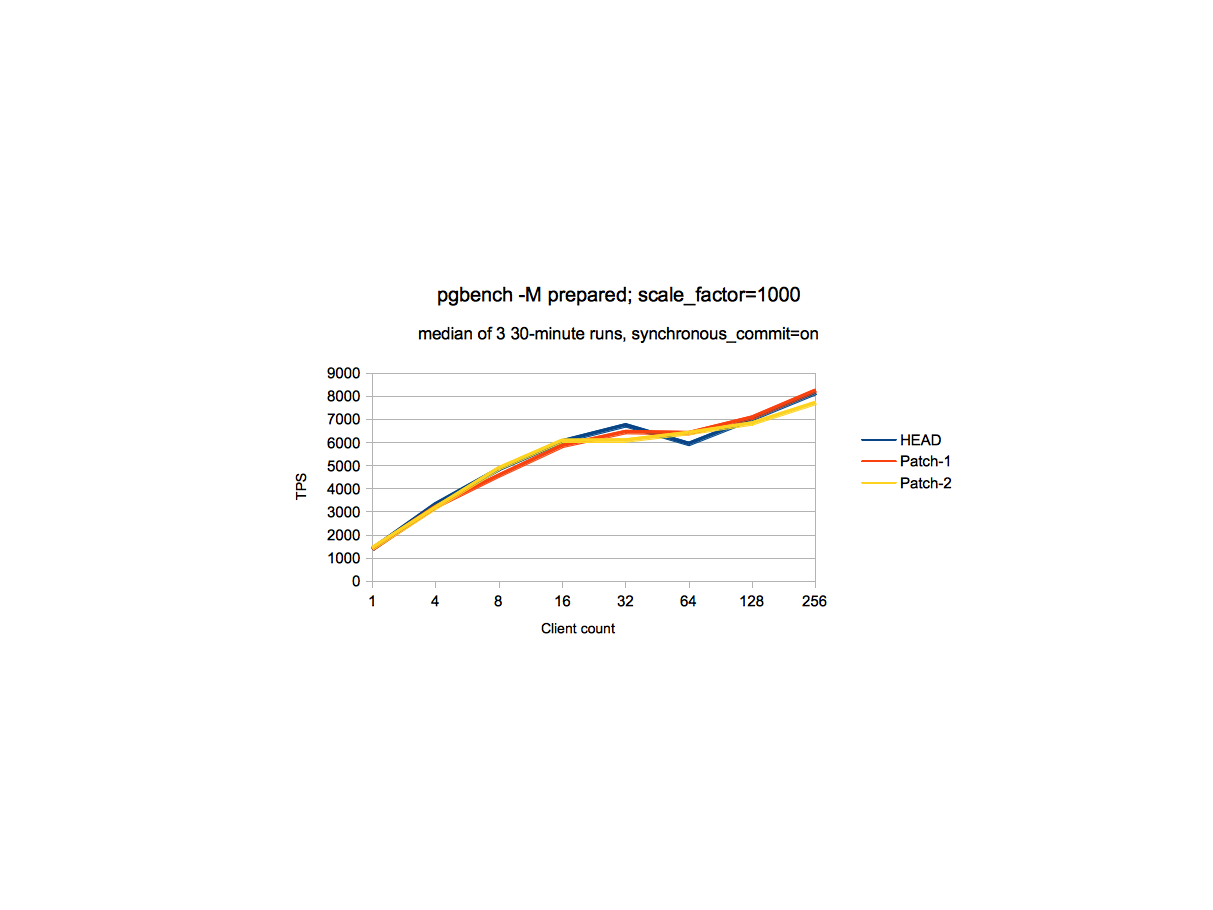
scale factor 300 and 1000.
Read Patch-1 and Patch-2 in graphs as below:
Patch-1 - group_update_clog_v3.patch
Patch-2 - group_slots_update_v3.patch
Observations
----------------------
1. At scale factor 300, there is gain of 11% at 128-client count and
27% at 256 client count with Patch-1. At 4 clients, the performance with
Patch is 0.6% less (which might be a run-to-run variation or there could
be a small regression, but I think it is too less to be bothered about)
2. At scale factor 1000, there is no visible difference and there is some
at lower client count there is a <1% regression which could be due to
I/O bound nature of test.
3. On these runs, Patch-2 is mostly always worse than Patch-1, but
the difference between them is not significant.
Some random comments:
- TransactionGroupUpdateXidStatus could do just as well without
add_proc_to_group. You could just say if (group_no >= NUM_GROUPS)
break; instead. Also, I think you could combine the two if statements
inside the loop. if (nextidx != INVALID_PGPROCNO &&
ProcGlobal->allProcs[nextidx].clogPage == proc->clogPage) break; or
something like that.
- memberXid and memberXidstatus are terrible names. Member of what?
How about changing them to clogGroupMemberXid and
clogGroupMemberXidStatus?
That's going to be clear as mud to the next person looking at the
definitiono f PGPROC.
I understand that you don't like the naming convention, but using
such harsh language could sometimes hurt others.
And the capitalization of memberXidstatus isn't
even consistent. Nor is nextupdateXidStatusElem. Please do give some
thought to the names you pick for variables and structure members.
Got it, I will do so.
Let me know what you think about whether we need to proceed with slots
approach and try some more performance data?
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: