On Tue, Dec 27, 2011 at 5:23 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
> On Sat, Dec 24, 2011 at 9:25 AM, Simon Riggs <simon@2ndquadrant.com> wrote:
>> On Thu, Dec 22, 2011 at 4:20 PM, Robert Haas <robertmhaas@gmail.com> wrote:
>
>>> Also, if it is that, what do we do about it? I don't think any of the
>>> ideas proposed so far are going to help much.
>>
>> If you don't like guessing, don't guess, don't think. Just measure.
>>
>> Does increasing the number of buffers solve the problems you see? That
>> must be the first port of call - is that enough, or not? If not, we
>> can discuss the various ideas, write patches and measure them.
>
> Just in case you want a theoretical prediction to test:
>
> increasing NUM_CLOG_BUFFERS should reduce the frequency of the spikes
> you measured earlier. That should happen proportionally, so as that is
> increased they will become even less frequent. But the size of the
> buffer will not decrease the impact of each event when it happens.
I'm still catching up on email, so apologies for the slow response on
this. I actually ran this test before Christmas, but didn't get
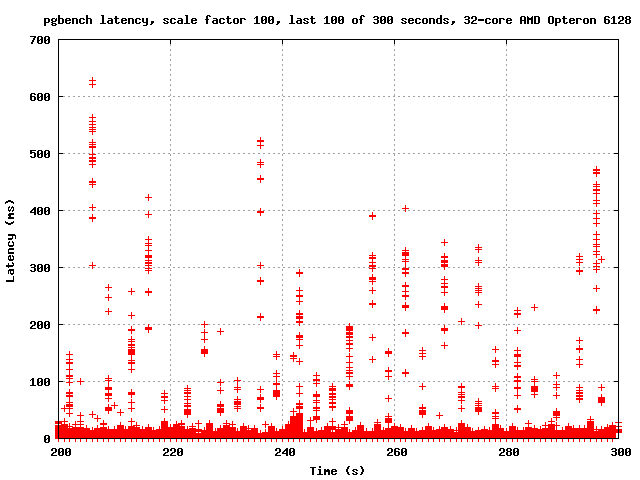
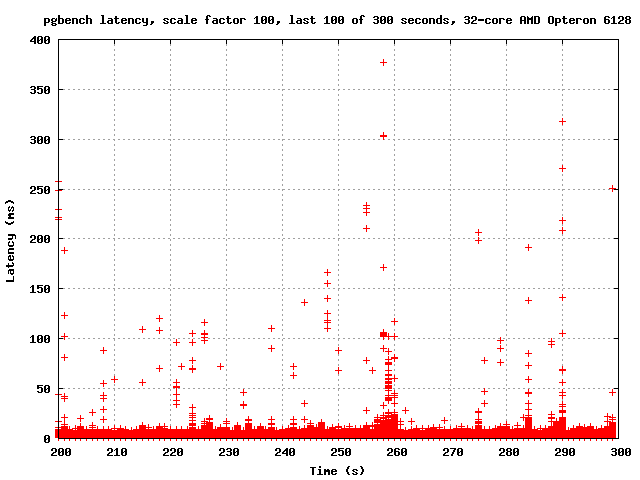
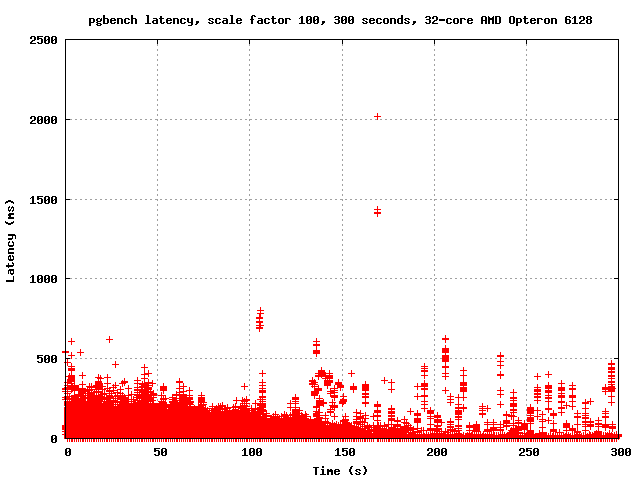
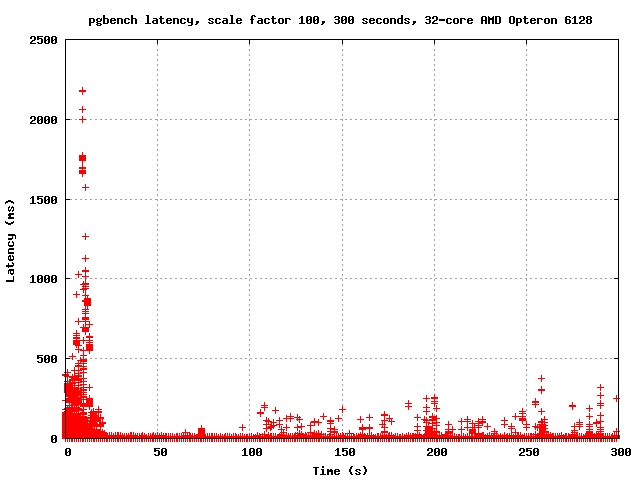
around to emailing the results. I'm attaching graphs of the last 100
seconds of a run with the normal count of CLOG buffers, and the last
100 seconds of a run with NUM_CLOG_BUFFERS = 32. I am also attaching
graphs of the entire runs.
It appears to me that increasing the number of CLOG buffers reduced
the severity of the latency spikes considerably. In the last 100
seconds, for example, master has several spikes in the 500-700ms
range, but with 32 CLOG buffers it never goes above 400 ms. Also, the
number of points associated with each spike is considerably less -
each spike seems to affect fewer transactions. So it seems that at
least on this machine, increasing the number of CLOG buffers both
improves performance and reduces latency.
I hypothesize that there are actually two kinds of latency spikes
here. Just taking a wild guess, I wonder if the *remaining* latency
spikes are caused by the effect that you mentioned before: namely, the
need to write an old CLOG page every time we advance onto a new one.
I further speculate that the spikes are more severe on the unpatched
code because this effect combines with the one I mentioned before: if
there are more simultaneous I/O requests than there are buffers, a new
I/O request has to wait for one of the I/Os already in progress to
complete. If the new I/O request that has to wait extra-long happens
to be the one caused by XID advancement, then things get really ugly.
If that hypothesis is correct, then it supports your previous belief
that more than one fix is needed here... but it also means we can get
a significant and I think quite worthwhile benefit just out of finding
a reasonable way to add some more buffers.
--
Robert Haas
EnterpriseDB: http://www.enterprisedb.com
The Enterprise PostgreSQL Company
{kind=link}
{kind=link}
{kind=link}
{kind=link}