Thanks Tom!
It sounds like that for multi-value IN/ANY, they act the same way as you mentioned. But I found the difference in plans for the single-value variant.
Imagine we have a btree(a, b) index. Compare two queries for one-element use case:
1. a='aaa' AND b=ANY('{bbb}')
2. a='aaa' AND b IN('bbb')
They may produce different plans: IN() always coalesces to field='aaa' in the plan, whilst =ANY() always remains =ANY(). This causes PG to choose a "post-filtering" plan sometimes:
1. For =ANY: Index Cond: (a='aaa'); Filter: b=ANY('{bbb}')
2. For IN(): Index Cond: (a='aaa') AND (b='bbb')
Do you think that this difference is significant? Or maybe something is off in the planner, should it treat them differently by design, is it intended?
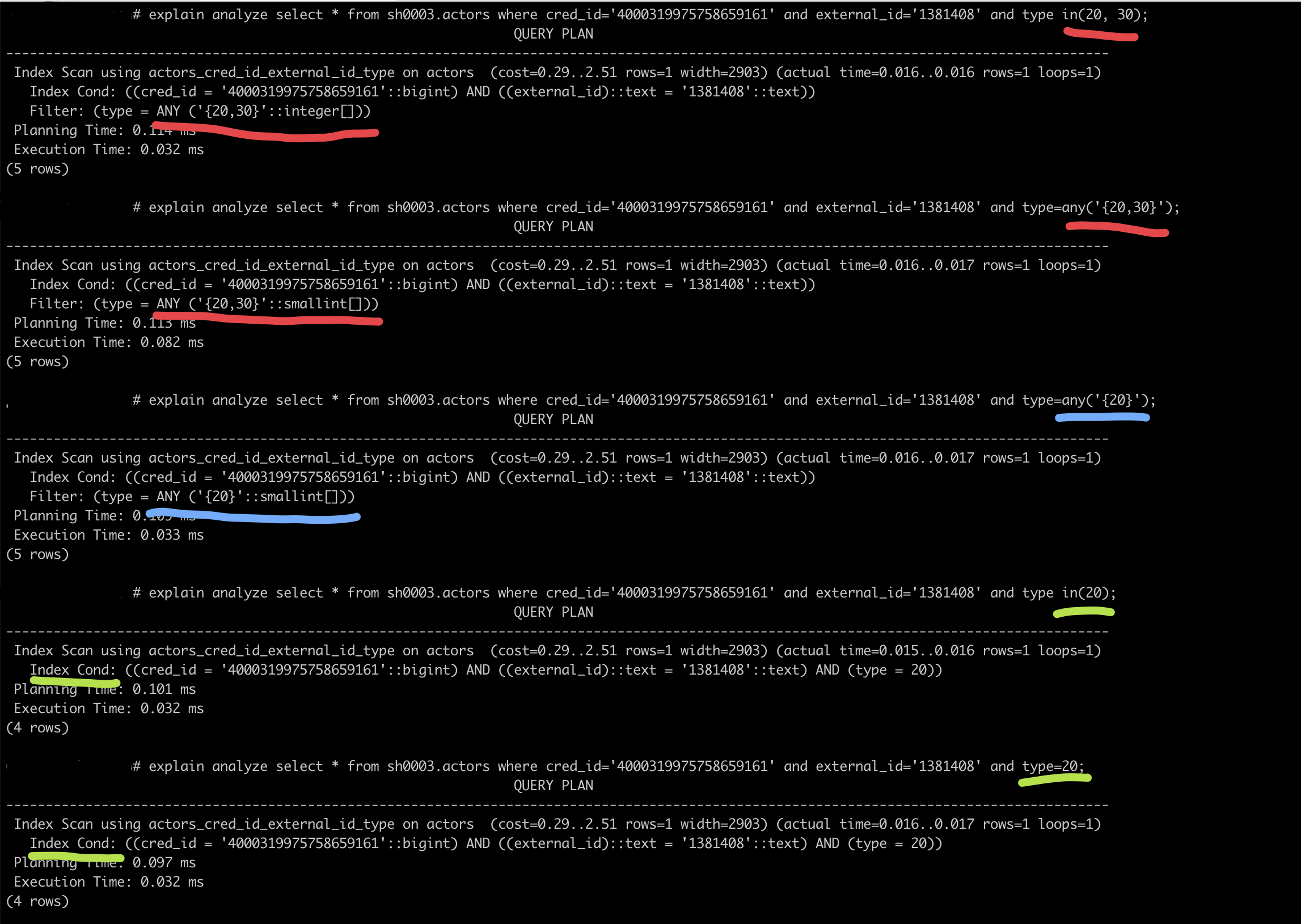
Below is an example screenshot from the production database with real data. We see that IN(20) is literally the same as =20 (green marker), whilst =any('{20}') causes PG to use post-filtering. (The cardinality of data in "type" field is low, just several unique values there in the entire table, so it probably doesn't make a big difference, whether a post-filtering is used or not, but anyways, the difference between IN() and =ANY looks a little scary. The index is "btree (cred_id, external_id, type)".)
Thanks!
Dmitry Koterov <dmitry.koterov@gmail.com> writes:
> PG13+. Assume we have two identical queries with no arguments (as a plain
> text, e.g. passed to PQexec - NOT to PQexecParams!):
> - one with "a=X AND b IN(...)"
> - and one with "a=X and b=ANY('{...}')
> The question: is it guaranteed that the planner will always choose
> identical plans for them (or, at least, the plan for ANY will not match an
> existing index worse than the plan with IN)?
This depends greatly on what "..." represents. But if it's a list
of constants, they're probably equivalent. transformAExprIn()
offers some caveats:
* We try to generate a ScalarArrayOpExpr from IN/NOT IN, but this is only
* possible if there is a suitable array type available. If not, we fall
* back to a boolean condition tree with multiple copies of the lefthand
* expression. Also, any IN-list items that contain Vars are handled as
* separate boolean conditions, because that gives the planner more scope
* for optimization on such clauses.
regards, tom lane