Re: index prefetching - Mailing list pgsql-hackers
| From | Tomas Vondra |
|---|---|
| Subject | Re: index prefetching |
| Date | |
| Msg-id | 64c8b824-6203-46a3-b045-5e95b796feee@vondra.me Whole thread Raw |
| In response to | Re: index prefetching (Tomas Vondra <tomas@vondra.me>) |
| Responses |
Re: index prefetching
Re: index prefetching |
| List | pgsql-hackers |
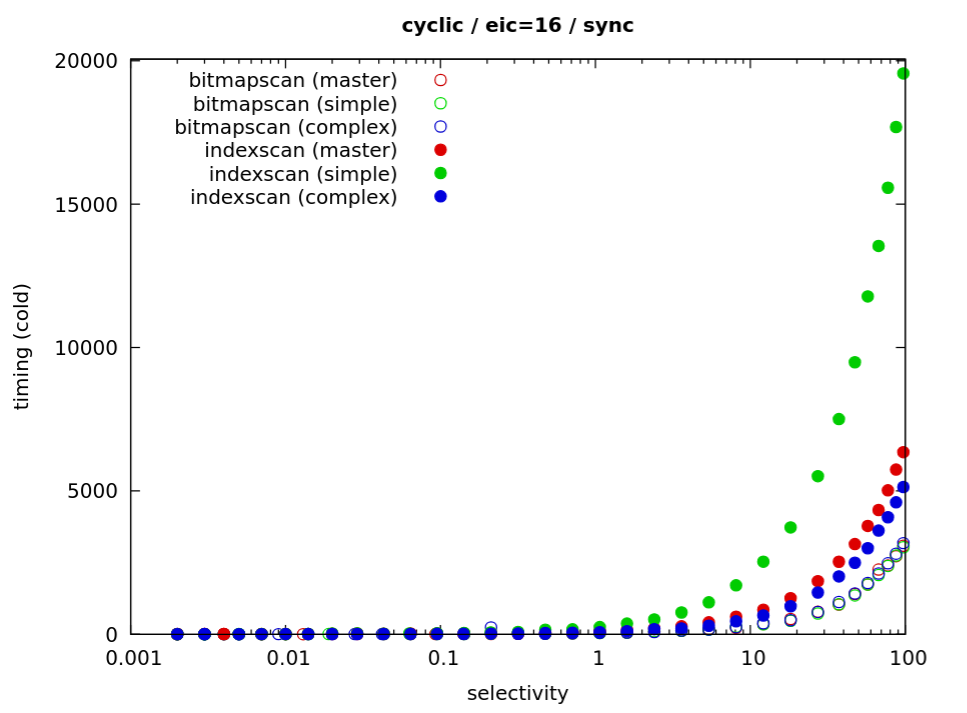
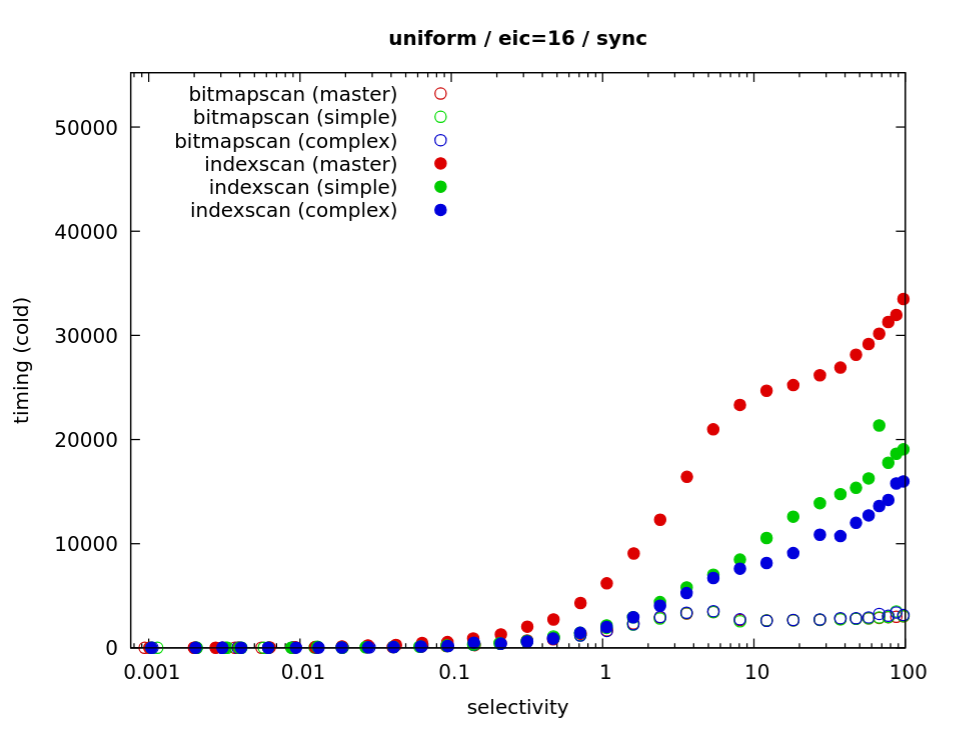
On 7/13/25 23:56, Tomas Vondra wrote: > > ... > >>> The one real limitation of the simpler approach is that prefetching is >>> limited to a single leaf page - we can't prefetch from the next one, >>> until the scan advances to it. But based on experiments comparing this >>> simpler and the "complex" approach, I don't think that really matters >>> that much. I haven't seen any difference for regular queries. >> >> Did you model/benchmark it? >> > > Yes. I did benchmark the simple and complex versions I had at the time. > But you know how it's with benchmarking - I'm sure it's possible to pick > queries where it'd make a (significant) difference. > > For example if you make the index tuples "fat" that would make the > prefetching less efficient. > > Another thing is hardware. I've been testing on local NVMe drives, and > those don't seem to need very long queues (it's diminishing returns). > Maybe the results would be different on systems with more I/O latency > (e.g. because the storage is not local). > I decided to do some fresh benchmarks, to confirm my claims about the simple vs. complex patches is still true even for the recent versions. And there's a lot of strange stuff / stuff I don't quite understand. The results are in git (still running, so only some data sets): https://github.com/tvondra/indexscan-prefetch-tests/ there's a run.sh script, it expects three builds - master, prefetch-simple and prefetch-complex (for the two patches). And then it does queries with index scans (and bitmap scans, for comparison), forcing different io_methods, eic, ... Tests are running on the same data directory, in random order. Consider for example this (attached): https://github.com/tvondra/indexscan-prefetch-tests/blob/master/d16-rows-cold-32GB-16-scaled.pdf There's one column for each io_method ("worker" has two different counts), different data sets in rows. There's not much difference between io_methods, so I'll focus on "sync" (it's the simplest one). For "uniform" data set, both prefetch patches do much better than master (for low selectivities it's clearer in the log-scale chart). The "complex" prefetch patch appears to have a bit of an edge for >1% selectivities. I find this a bit surprising, the leaf pages have ~360 index items, so I wouldn't expect such impact due to not being able to prefetch beyond the end of the current leaf page. But could be on storage with higher latencies (this is the cloud SSD on azure). But the thing I don't really understand it the "cyclic" dataset (for example). And the "simple" patch performs really badly here. This data set is designed to not work for prefetching, it's pretty much an adversary case. There's ~100 TIDs from 100 pages for each key value, and once you read the 100 pages you'll hit them many times for following values. Prefetching is pointless, and skipping duplicate blocks can't help, because the blocks are not effective. But how come the "complex" patch does so much better? It can't really benefit from prefetching TID from the next leaf - not this much. Yet it does a bit better than master. I'm looking at this since yesterday, and it makes no sense to me. Per "perf trace" it actually does 2x many fadvise calls compared to the "simple" patch (which is strange on it's own, I think), yet it's apparently so much faster? regards -- Tomas Vondra
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: