<tgl@sss.pgh.pa.us> wrote:
>
> TBH, you lost me there already. I know of no hardware on which that would
> be a sane depiction of reality, so I think you've probably overfitted the
> model to some particular case it was already inaccurate on. Any results
> you're getting using this setting will likely fall into the category of
> "garbage in, garbage out".
>
> What led you to choose that number?
Uh, it seems that the scale of our machine caused confusion.
It has a bit large disk array, and I think random_page_cost = 92.89 is reasonable
(the reason is described later).
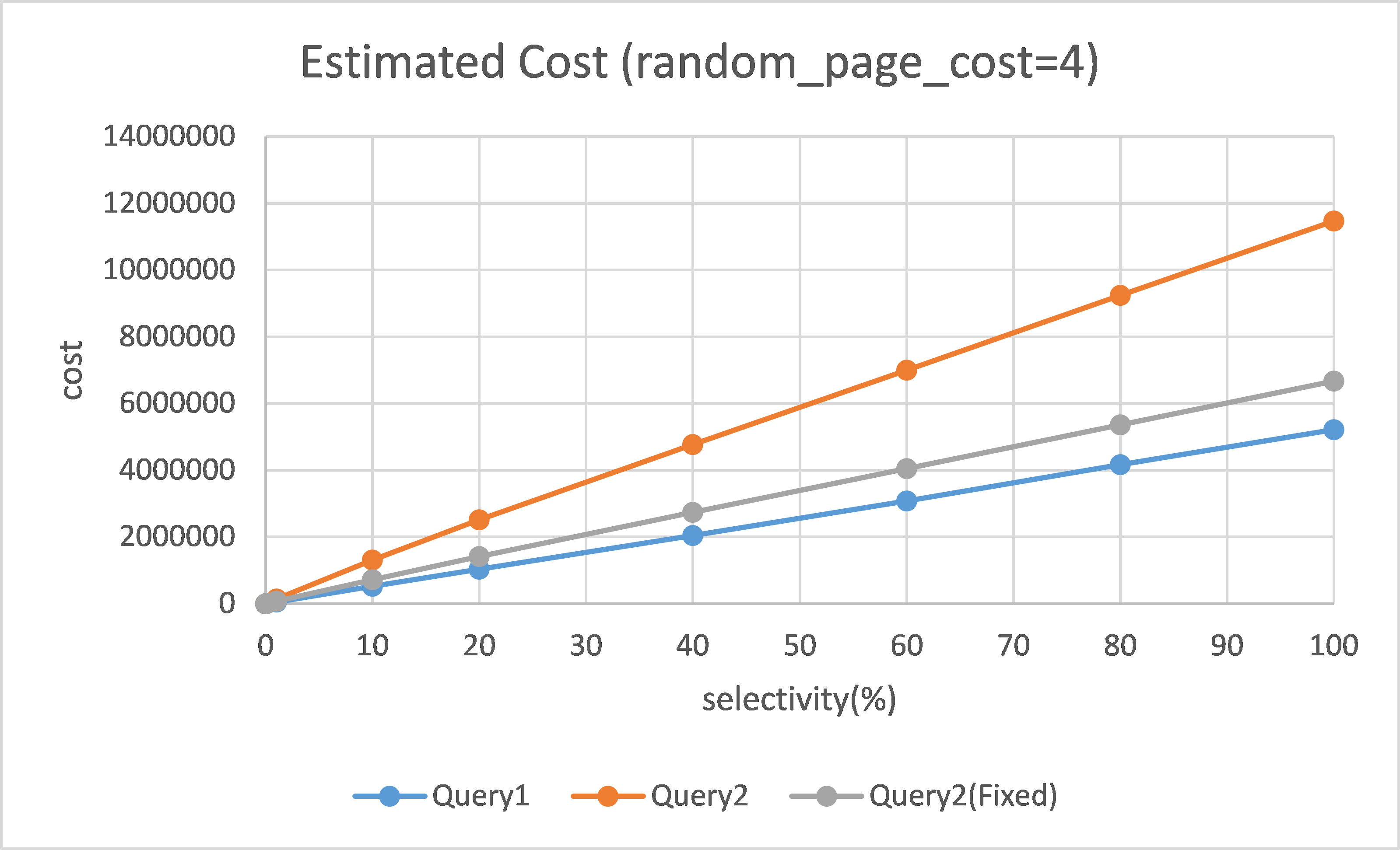
This problem could be observed in normal environment like random_page_cost = 4.
I checked estimated cost of query (1) and query (2) with random_page_cost = 4,
and there were noticeable cost estimation difference between them (see an attached graph).
As I explained in the first mail, execution time of query (1) and query (2) are
expected to be almost the same. If so, there is something wrong with cost estimation
logic, and this problem is not specific to particular environment. The result I
showed was just an example of confirmation of the problem.
Next, I'd like to explain our environment and the reason of random_page_cost value.
Our machine has a RAID6 array with 24 NL-SAS HDDs and its raw I/O performance is:
Sequential access: 2.5GB/s
Random access (8KB block): 1.6MB/s (=200 IOPS * 8KB )
For Postgres, we have filesystems and some calculations like tuple processing or
aggregations, so sequential access becomes slower. Here I show basic performance
values of I/O intensive queries like simple scan on a large table:
Sequential access: 200-300MB/s(*)
Random access: 200 IOPS * 8KB = 1.6MB/s
(*) depends on aggregation or any other calculations
So sequential access is 125-188 times faster than random access. We assume OLAP
workload, so cache hit ratio is not so high. That means performance gap between
sequential I/O and random I/O would not be mitigated by cache effect.
Therefore we think random_page_cost should be around 100 in our environment.
random_page_cost = 92.89 is the result of calibration with multiple TPC-H queries,
which covers from simple scan on single table to complex joins of multiple tables,
and this value gives good cost estimation for TPC-H queries.
Thanks.
Ryoji
{kind=link}