Bruce Momjian wrote:
>Tom Lane wrote:
>
>>Tatsuo Ishii <t-ishii@sra.co.jp> writes:
>>
>>>Ok, here is a pgbench (-s 10) result on an AIX 5L box (4 way).
>>>"7.2 with patch" is for the previous patch. "7.2 with patch (revised)"
>>>is for the this patch. I see virtually no improvement.
>>>
>>If anything, the revised patch seems to make things slightly worse :-(.
>>That agrees with my measurement on a single CPU.
>>
>>I am inclined to use the revised patch anyway, though, because I think
>>it will be less prone to starvation (ie, a process repeatedly being
>>awoken but failing to get the lock). The original form of lwlock.c
>>guaranteed that a writer could not be locked out by large numbers of
>>readers, but I had to abandon that goal in the first version of the
>>patch. The second version still doesn't keep the writer from being
>>blocked by active readers, but it does ensure that readers queued up
>>behind the writer won't be released. Comments?
>>
>
>OK, so now we know that while the new lock code handles the select(1)
>problem better, we also know that on AIX the old select(1) code wasn't
>as bad as we thought.
>
>As to why we don't see better numbers on AIX, we are getting 100tps,
>which seems pretty good to me. Tatsuo, were you expecting higher than
>100tps on that machine? My hardware is at listed at
>http://candle.pha.pa.us/main/hardware.html and I don't get over 16tps.
>
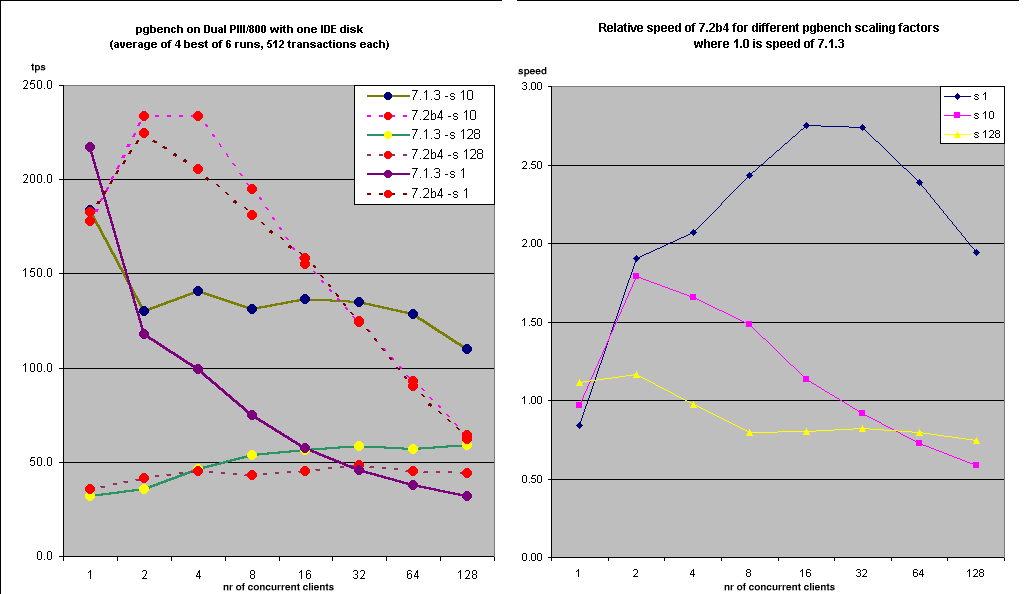
What scaling factor do you use ?
What OS ?
I got from ~40 tps for -s 128 up to 50-230 tps for -s 1 or 10 on dual
PIII 800 on IDE
disk (Model=IBM-DTLA-307045) with hdparm -t the following
/dev/hda:
Timing buffered disk reads: 64 MB in 3.10 seconds = 20.65 MB/sec
The only difference from Tom's hdparm is unmaskirq = 1 (on) (the -u
1 switch that
enables interrupts during IDE processing - there is an ancient warning
about it being a risk,
but I have been running so for years on very different configurations
with no problems)
I'll reattach the graph (old one, without either Tom's 7.2b4 patches).
This is on RedHat 7.2
>I believe we don't see improvement on SMP machines using pgbench because
>pgbench, at least at high scaling factors, is really testing disk i/o,
>not backend processing speed. It would be interesting to test pgbench
>using scaling factors that allowed most of the tables to sit in shared
>memory buffers. Then, we wouldn't be testing disk i/o and would be
>testing more backend processing throughput.
>
I suspect that we should run at about same level of disk i/o for same
TPS level regardless
of number of clients, so pgbench is measuring ability to run
concurrently in this scenario.
-----------------
Hannu
{kind=link}