Erroneous cost estimation for nested loop join - Mailing list pgsql-hackers
| From | kawamichi@tkl.iis.u-tokyo.ac.jp |
|---|---|
| Subject | Erroneous cost estimation for nested loop join |
| Date | |
| Msg-id | 1392146157.12658806.1447063737997.JavaMail.zimbra@tkl.iis.u-tokyo.ac.jp Whole thread Raw |
| Responses |
Re: Erroneous cost estimation for nested loop join
Re: Erroneous cost estimation for nested loop join Re: Erroneous cost estimation for nested loop join Re: Erroneous cost estimation for nested loop join |
| List | pgsql-hackers |
Hi guys,
I’ve been using Postgres for research at an university, and we found some interesting queries that the optimizer of
Postgreschose wrong query plans. I will describe one example query below.
The query is just a join of two tables, but the optimizer overestimates the cost of a nested loop join plan and selects
ahash join plan which execution time is 3.24 times slower than nested loop join in the worst case.
We investigated the query and we found that the cost model of current Postgres makes a wrong estimation for some nested
loopjoin plans. So we posted this mail for sharing the problem.
## Test environment:
These are machines we used for examination.
・Processor: Intel(R) Xeon(R) CPU E5-2680 0 @ 2.70GHz (8 cores) * 2 sockets
・Memory: 64GB (128MB was allocated for shared_buffers)
・Storage: RAID6 (22D+2P) with 24 NL-SAS 10krpm HDDs
- 19TB in total
- Maximum sequential read throughput: 2.5GB/s (measured by dd command)
・CentOS 5.8 (linux 2.6.18-371.1.2.el5)
・Postgres 9.4.1
- cost parameter calibration: random_page_cost = 92.89
We used two tables from TPC-H(*) benchmark dataset, and modified the join cardinality between orders and lineitem. It
is1:4 originally, but we modified it to 1:10000. So there are 10000 lineitem records per 1 orders record. There are
10,000records in orders, 100,000,000 records in lineitem, and these tables occupy 1,261 MB on disk.
(*)TPC-H is one of benchmark specification that supposes a decision support system (DSS).
## Query
In order to examine the cost estimation error of nested loop join, we measured the cost and the execution time of
followingtwo queries with various selectivity (the value of KEY). And we set the parameters “enable_hashjoin” and
“enable_seqscan”false not to select hash join.
Query1
select sum(l_quantity) from lineitem where l_orderkey <= [KEY];
This is an example of execution plan. (KEY=100)
Aggregate (cost=362288.74..362288.75 rows=1 width=5)
-> Index Scan using l_orderkey_idx2 on lineitem2 (cost=0.57..359788.73 rows=1000000 width=5)
Index Cond: (l_orderkey <= 100)
Query2
select sum(o_totalprice), sum(l_quantity) from orders inner join lineitem on (o_orderkey = l_orderkey) where o_orderkey
<=[KEY];
This is an example of execution plan. (KEY=100)
Aggregate (cost=2296937.99..2296938.00 rows=1 width=14)
-> Nested Loop (cost=0.85..2291887.98 rows=1010000 width=14)
-> Index Scan using orders_pkey2 on orders2 (cost=0.29..188.84 rows=101 width=13)
Index Cond: (o_orderkey <= 100)
-> Index Scan using l_orderkey_idx2 on lineitem2 (cost=0.57..22578.67 rows=11142 width=9)
Index Cond: (l_orderkey = orders2.o_orderkey)
## Results
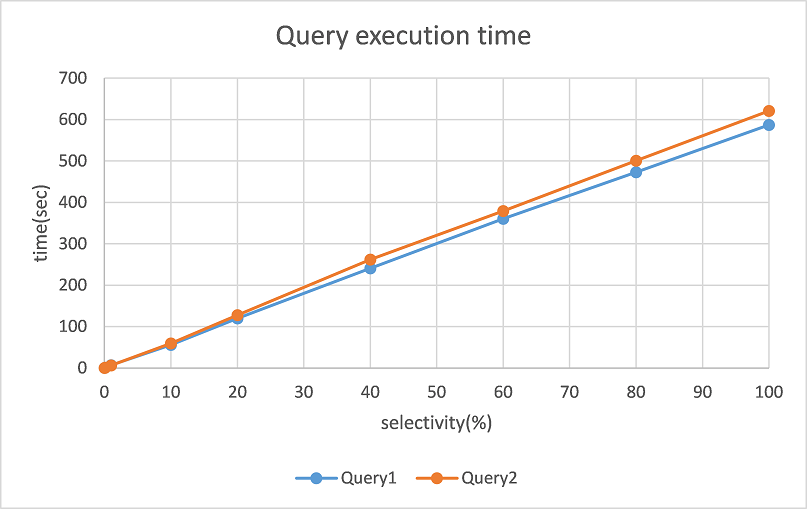
[Figure1.png]
We show the execution time of two queries as Figure 1. In this case, the selectivity is proportional to KEY, and become
100%when KEY=10000.
As we can see from this graph, the execution times of two queries are almost the same. Because the majority of these
costsare lineitem scanning, and the I/O workloads of these two scanning process are nearly identical.
Let me explain more detail why these two workloads are nearly identical. Lineitem has a clustered index on l_orderkey
column,and in Query1, this index is used on scanning lineitem, so I/O workload is sequencial scan of lineitem. In
Query2,this index is also used on scanning inner table (i.e. lineitem) repeatedly on nested loop join. And outer table
(i.e.orders) is scanned by the index on o_orderkey, so the key of inner scan is ordered by l_orderkey. That is to say,
lineitemis substantially scanned from head (Figure 2).
[Figure2.png]
So the I/O cost difference between Query1 and Query2 is the cost to scan outer table (i.e. orders), and it is very
smallbecause the outer table scan cost is very cheap in comparison to the inner table scan cost.
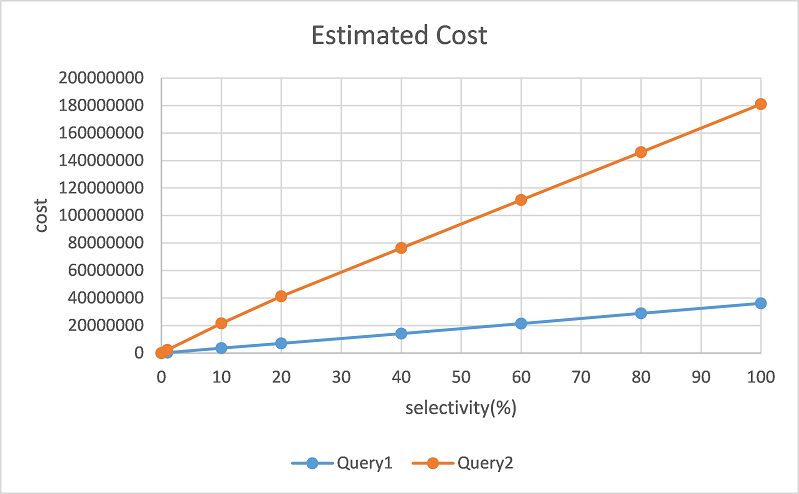
But when we check the cost with explain command, postgres overestimates the cost of Query2. For example, the cost of
Query2is 5 times of Query1 at KEY 10,000
[Figure3.png]
We can find that that the optimizer estimates the different cost value for two queries which have almost the same
executiontime.
So, the optimizer will select hash join even if nested loop is faster, and in the worst case, execution time of hash
joinwill be about 3.24 times of the execution time of nested loop for Query2.
We guessed the cause of this error would be in the cost model of Postgres, and investigated the source code of
optimizer,and we found the cause of this problem. It was in the index cost estimation process. On scanning inner table,
ifloop count is greater than 1, its I/O cost is counted as random access. In the case of Query2, in one loop (i.e. one
innertable scan) , much data is read sequentially with clustered index, so it seems to be wrong that optimizer thinks
itsI/O workload is random access.
Specifically, in function “cost_index” in “costsize.c”, if loop_count > 1, the cost estimate expression is as follows:
min_IO_cost = (pages_fetched * spc_random_page_cost) / loop_count;
We modified this code. The first page is randomly accessed and the rests is sequentially accessed.
min_IO_cost = spc_random_page_cost / (double)loop_count;
if (pages_fetched > 1) {
min_IO_cost += (pages_fetched - 1) * spc_seq_page_cost / loop_count;
}
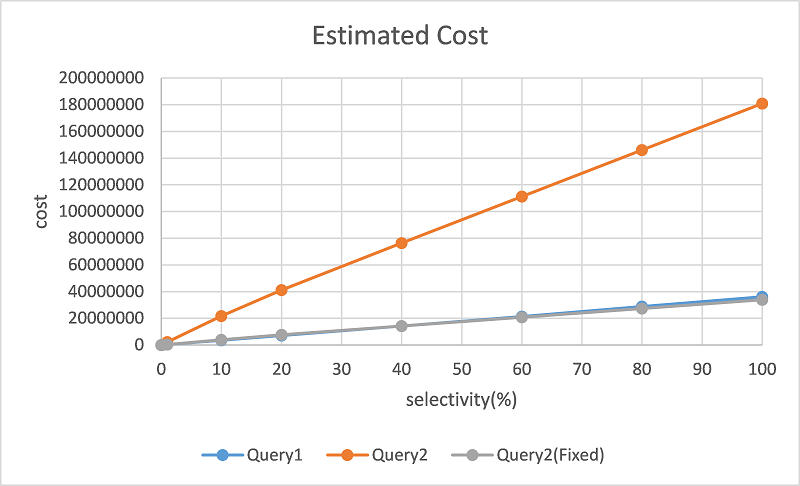
Then we get the modified cost line as Figure 4 (gray line).
[Figure4.png]
As this result shows, the difference between Query1 and Query2(Fixed) is smaller than original one, so the cost
estimationseems to be improved.
There is infinite query space, so this problem is thoroughly an example. To fix only this problem, that is enough to
modifythe code as previous. But we think the optimizer can still have another problems, so we want to hear your opinion
aboutthe problems like this because you have deep knowledge of Postgres. We think the cost model of optimizer is very
interestingfor research, so we want to expand the discussion from this problem, and contribute to Postgres community.
Thanks.
Ryoji
Attachment
{kind=link}
{kind=link}
{kind=link}
{kind=link}
pgsql-hackers by date: