Re: another autovacuum scheduling thread - Mailing list pgsql-hackers
| From | Greg Burd |
|---|---|
| Subject | Re: another autovacuum scheduling thread |
| Date | |
| Msg-id | bff7dc5a-f839-449b-b56a-aab36cd3e39d@app.fastmail.com Whole thread Raw |
| In response to | Re: another autovacuum scheduling thread (Nathan Bossart <nathandbossart@gmail.com>) |
| List | pgsql-hackers |
On Wed, Mar 18, 2026, at 12:09 PM, Nathan Bossart wrote:
> On Wed, Mar 18, 2026 at 12:06:34PM +1300, David Rowley wrote:
>> I think it would have been better to have done this about 3 months
>> ago, but I think it's probably still fine to do now. Feature freeze is
>> still quite a long way from release. I do expect that the most likely
>> time that someone would find issues with this change would be during
>> beta or RC, as that's when people would give PostgreSQL production
>> workloads to try out. During the dev cycle, I expect it's *mostly*
>> just hackers giving the database toy workloads in a very targeted way
>> to something specific that they're hacking on. Anyway, now since
>> you've added the GUCs to control the weights, there's a way for users
>> to have some influence, so at least there's an escape hatch.
>
> Thanks for chiming in.
Hey Nathan, et. al., I'll chime in too! Apologies in advance for the length of the message. I need to learn how to be
moreconcise...
First off, thanks for looking into this! I think your work is a significant improvement over where we are today and
shouldbe in v19. Put simply, I think that the v12 patch is no worse than pg_class order we use today and in many cases
muchbetter. That said, I think we should tweak it a bit more while we're at it.
>> I think the GUCs are probably a good idea. I expect the most likely
>> change that people might want to make would be to raise the priority
>> of analyze over vacuum since that's often much faster to complete. We
>> know that some workloads are very sensitive to outdated statistics.
>>
>> On the other hand, we shouldn't be taking adding 5 new autovacuum GUCs
>> lightly as there are already so many. If we are going to come up with
>> something better than this in a few years then it could be better to
>> wait to reduce the pain of having to remove GUCs in the future. I
>> don't personally have any better ideas, so I'd rather see it go in
>> than not.
>
> Yeah, adding these GUCs feels a bit like etching in stone, but if folks
> want configurability, and nobody has better ideas, I'm not sure what else
> to do.
I'm late in the review process. I know David Rowley proposed the unified scoring approach that became the foundation of
thispatch, and I think that's a great direction. However, I'm concerned that the patch's default scoring weights don't
giveXID-age urgency sufficient priority over dead-tuple urgency. The weight GUCs (autovacuum_vacuum_score_weight, etc.)
canaddress this, but they max at 1.0, meaning you can only reduce dead-tuple priority, not increase XID priority.
>> I didn't look at the patch in detail, but noticed that you might want
>> to add a "See Section N.N.N for more information." to the new GUCs to
>> link to the text you've added on how they're used.
>
> Good idea. I've added that.
>
>> Do you think it's worth making the call to
>> list_sort(tables_to_process, TableToProcessComparator) conditional on
>> a variable set like: sort_required |= (score != 0.0);? I recall that
>> someone had concerns that the actual sort itself could add overhead.
>
> I don't think it's necessary. I tested sorting 1M and 10M tables with
> randomly generated scores (on my MacBook, with assertions enabled). The
> former took ~150 milliseconds, and the latter took ~1770 milliseconds. I
> suspect there are far bigger problems to worry about if you have anywhere
> near that many tables.
>
> --
> nathan
>
> Attachments:
> * v12-0001-autovacuum-scheduling-improvements.patch
I decided to model before/after behavior using discrete-event simulation. With a bit of LLM help, we no have
autovacuum_simulation.pyand autovacuum_simulation_fixed.py to compare all three approaches (Before/v12/Proposed small
fixto v12) across 20 runs with randomized OID assignments.
Results from the models are at the end of this email. They simulate the before/after/fixed behavior of the v12
autovacuumscheduling patch and a suggested fix (I'll get to why in a minute).
They test a contention scenario: 100 tables (5 already past freeze_max_age, 15 approaching it at staggered rates, and
80high-churn tables constantly exceeding their dead-tuple vacuum thresholds) competing for 3 autovacuum workers over 7
days. I'm sure there are other scenarios that we could test, this felt representational enough to me based on what I've
seen.
With the first test, the "Before" scheduler processes tables in OID order; the "After" scheduler uses the patch's
urgencyscoring with all default GUC values.
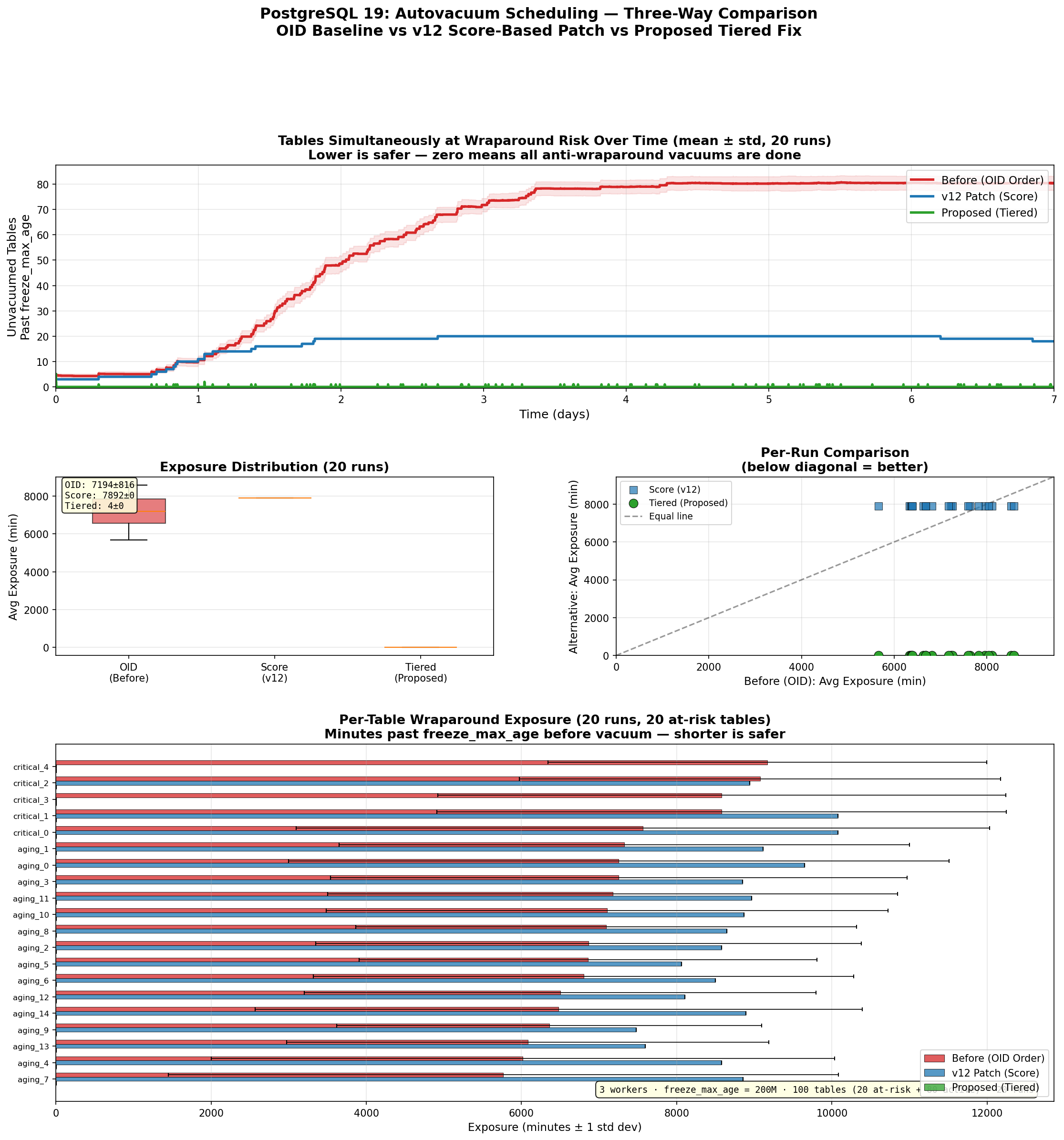
The model of the v12 patch produces a clear system-wide improvement: the number of tables simultaneously past
freeze_max_agepeaks at roughly 20 under score-based scheduling versus 80+ under OID order. This happens because
high-churntables earn high dead-tuple scores, get vacuumed frequently, and their relfrozenxid ages reset as a side
effect- preventing them from ever reaching freeze_max_age. Under OID order, high-OID active tables are *starved* (for
noother reason than they were created later than their counterparts!) and their XID ages grow needlessly into the
dangerzone. The v12 patch also correctly prioritizes the most dangerous force-vacuum tables first (those closest to
failsafeage), whereas OID order's success with any particular table is coincidental.
But there's a downside in v12, the simulation reveals a scoring-scale concern under default weights. Active tables
accumulatedead-tuple scores of 18–70+ within minutes of their last vacuum, while force-vacuum tables that have just
crossedfreeze_max_age carry XID scores of only 1.0–4.0 (age/freeze_max_age). The exponential boost doesn't activate
untilfailsafe age (1.6B), which is 8× the freeze_max_age threshold. In the gap between 200M and 1.6B, force-vacuum
tablesare consistently outranked by ordinary dead-tuple work. In the tested scenario this meant only 2 of 20 at-risk
tableswere actually vacuumed by the score-based scheduler (versus 5 by OID due to luck), and average per-table
wraparoundexposure was 26% worse.
One possible remedy within the current design would be to either raise the default autovacuum_freeze_score_weight or
applya floor multiplier when force_vacuum is true. For example, ensuring any force-vacuum score is at least as large
asthe maximum non-force-vacuum score in the current candidate set. Alternatively, the weight GUC range could be
expandedabove 1.0 to allow DBAs to explicitly boost XID-age priority. The existing 0.0–1.0 range only allows reducing
componentpriority, which makes it difficult to express "wraparound prevention is more important than bloat control.
Tiered sorting using the existing wraparound flag might be the simplest and safest fix. While the thread discussed
usingscoring with exponential boost to prioritize wraparound tables, I think a two-tier approach (wraparound tier vs
routinetier) would be more robust. We already treat wraparound as non-negotiable (force_vacuum bypasses av_enabled,
triggersemergency behavior). The scoring system should reflect this by making wraparound a hard priority tier, not a
scorecomponent competing with bloat cleanup.
Instead of sorting solely by score, sort first by wraparound, then by score within each tier. The score computation
staysexactly as-is; it's only used for relative ordering among force_vacuum tables and among non-force-vacuum tables.
Something like:
/*
* Comparison function for sorting TableToProcess candidates.
*
* Tables at risk of wraparound are always processed before routine
* maintenance work. Within each tier, tables are sorted by descending
* urgency score.
*/
static int
TableToProcessComparator(const ListCell *a, const ListCell *b)
{
TableToProcess *ta = (TableToProcess *) lfirst(a);
TableToProcess *tb = (TableToProcess *) lfirst(b);
/* Wraparound prevention always takes priority */
if (ta->wraparound && !tb->wraparound)
return -1;
if (!ta->wraparound && tb->wraparound)
return 1;
/* Within same tier, highest score first */
if (ta->score > tb->score)
return -1;
if (ta->score < tb->score)
return 1;
return 0;
}
The simulation code, workload generator, and visualizations are attached (in "foo_tgz" because my last attempt at this
emailwas stuck in the moderation queue). I'd welcome feedback on whether the scenario is representative. The
autovacuum_simulation_fixed.pyincludes the proposed fix and also runs a number of iteration where it randomized the
tableOids so as to remove any dependency on ordering that may be implied in our current algorithm (the before, or v18
algorithm).
The proposed addition to your fix is in the v20260318 patch attached.
best.
-greg
$ ./autovacuum_simulation.py
======================================================================
AUTOVACUUM SCHEDULING SIMULATION (v12 patch)
Accurate model of score-based prioritization
======================================================================
PostgreSQL config:
autovacuum_freeze_max_age = 200,000,000
vacuum_failsafe_age = 1,600,000,000
autovacuum_vacuum_threshold = 50
autovacuum_vacuum_scale_factor= 0.2
autovacuum_max_workers = 3
Simulation: 7 days, 60s steps, seed=42
Generating tables...
5 critical — already past freeze_max_age
15 aging — approaching freeze_max_age
80 active — high dead-tuple rate
BEFORE simulation (catalog OID order):
[OID order ] 0%
[OID order ] 20%
[OID order ] 40%
[OID order ] 60%
[OID order ] 80%
[OID order ] 100%
AFTER simulation (score-based priority):
[Score-based] 0%
[Score-based] 20%
[Score-based] 40%
[Score-based] 60%
[Score-based] 80%
[Score-based] 100%
==============================================================================
RESULTS: Exposure time (minutes at risk before vacuum)
Table OID Crossed Before After Change
------------------------------------------------------------------------------
critical_0 16465 day 0.0 10080m 10080m +0%
critical_1 16398 day 0.0 14m 10080m -71900%
critical_2 16387 day 0.0 4m 10080m -251900%
critical_3 16478 day 0.0 10080m 4m +100%
critical_4 16419 day 0.0 10080m 4m +100%
aging_0 16415 day 0.3 9648m 9648m +0%
aging_1 16412 day 0.7 9114m 9114m +0%
aging_7 16459 day 0.7 9027m 9027m +0%
aging_6 16395 day 0.8 9m 8982m -99700%
aging_10 16481 day 0.9 8721m 8721m +0%
aging_11 16472 day 0.9 8721m 8721m +0%
aging_2 16401 day 1.0 415m 8579m -1967%
aging_3 16397 day 1.0 12m 8578m -71383%
aging_4 16470 day 1.1 8499m 8499m +0%
aging_12 16411 day 1.1 8483m 8483m +0%
aging_8 16438 day 1.2 8296m 8296m +0%
aging_5 16453 day 1.3 8178m 8178m +0%
aging_14 16448 day 2.1 7101m 7101m +0%
aging_9 16388 day 2.2 4m 6979m -174375%
aging_13 16413 day 2.2 6959m 6959m +0%
------------------------------------------------------------------------------
AVERAGE 6172m 7806m -26%
MAXIMUM 10080m 10080m +0%
==============================================================================
Generating visualization...
✓ output/autovacuum_scheduling_impact.png
Done.
-------------------------------------------------------
$ ./autovacuum_simulation_fixed.py
========================================================================
THREE-WAY AUTOVACUUM SCHEDULING COMPARISON
Before (OID) vs v12 Patch (Score) vs Proposed Fix (Tiered)
========================================================================
Config: 3 workers, 7-day sim, 60s steps, 20 runs
Tables: 5 critical + 15 aging + 80 active = 100
freeze_max_age = 200,000,000
Estimated runtime: 3-8 minutes
Run OID avg Score avg Tiered avg
-------------------------------------------
1 7222m 7892m 4m
2 7642m 7892m 4m
3 7961m 7892m 4m
4 6333m 7892m 4m
5 8110m 7892m 4m
6 6359m 7892m 4m
7 6629m 7892m 4m
8 8526m 7892m 4m
9 6385m 7892m 4m
10 6813m 7892m 4m
11 8588m 7892m 4m
12 7261m 7892m 4m
13 6682m 7892m 4m
14 8035m 7892m 4m
15 5667m 7892m 4m
16 7595m 7892m 4m
17 6394m 7892m 4m
18 6686m 7892m 4m
19 7819m 7892m 4m
20 7178m 7892m 4m
========================================================================
AGGREGATE RESULTS
========================================================================
Avg exposure per run (minutes):
OID : 7194 ± 816 (min=5667, max=8588)
Score : 7892 ± 0 (min=7892, max=7892)
Tiered : 4 ± 0 (min=4, max=4)
Peak concurrent force_vacuum tables:
OID : 82 ± 3 (min=79, max=88)
Score : 20 ± 0 (min=20, max=20)
Tiered : 5 ± 0 (min=5, max=5)
Pairwise wins (lower avg exposure = better):
Score beats OID: 5/20 loses: 15/20 ties: 0/20
Tiered beats OID: 20/20 loses: 0/20 ties: 0/20
Tiered beats Score: 20/20 loses: 0/20 ties: 0/20
Variance (std dev of avg exposure across runs):
OID : 816 min
Score : 0 min
Tiered : 0 min
Per-table mean exposure (minutes):
Table OID Score Tiered
--------------------------------------------------------------
critical_0 7564±4470 10080±0 7±0
critical_1 8577±3671 10080±0 7±0
critical_2 9073±3099 8938±0 3±0
critical_3 8581±3661 4±0 4±0
critical_4 9167±2826 3±0 3±0
aging_0 7253±4256 9648±0 4±0
aging_1 7324±3675 9114±0 4±0
aging_2 6865±3517 8579±0 5±0
aging_3 7253±3714 8851±0 4±0
aging_4 6018±4014 8579±0 4±0
aging_5 6856±2951 8064±0 4±0
aging_6 6799±3482 8496±0 3±0
aging_7 5765±4318 8853±0 4±0
aging_8 7091±3227 8644±0 4±0
aging_9 6358±2738 7479±0 4±0
aging_10 7106±3620 8870±0 4±0
aging_11 7175±3673 8965±0 4±0
aging_12 6499±3299 8106±0 4±0
aging_13 6080±3108 7595±0 4±0
aging_14 6479±3913 8891±0 4±0
========================================================================
Completed in 108 seconds (1.8 minutes)
========================================================================
Generating visualization...
✓ output/three_way_comparison.png
Attachment
{kind=link}
pgsql-hackers by date: