WIP: "More fair" LWLocks - Mailing list pgsql-hackers
| From | Alexander Korotkov |
|---|---|
| Subject | WIP: "More fair" LWLocks |
| Date | |
| Msg-id | CAPpHfdvJhO1qutziOp=dy8TO8Xb4L38BxgKG4RPa1up1Lzh_UQ@mail.gmail.com Whole thread |
| Responses |
Re: WIP: "More fair" LWLocks
|
| List | pgsql-hackers |
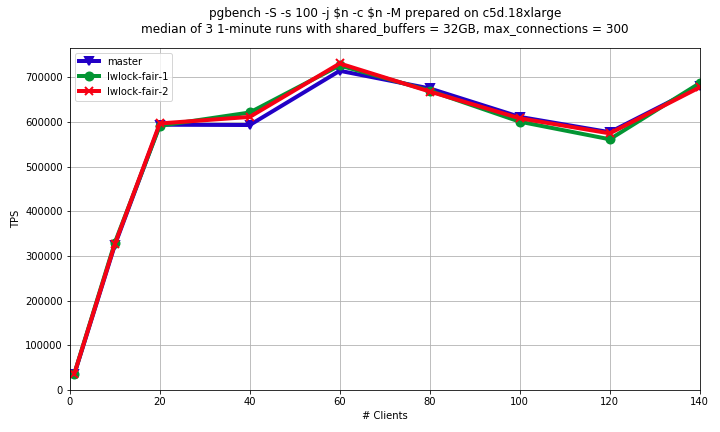
Hi! This subject was already raised multiple times [1], [2], [3]. In short, our LWLock implementation has pathological behavior when shared lockers constitute a continuous flood. In this case exclusive lock waiters are not guaranteed to eventually get the lock. When shared lock is held, other shared lockers goes without any queue. This is why despite individual shared lock durations are small, when flood of shared lockers is high enough then there might be no gap to process exclusive lockers. Such behavior is periodically reported on different LWLocks. And that leads to an idea of making our LWLocks "more fair", which would make infinite starvation of exclusive lock waiters impossible. This idea was a subject of critics. And I can summarize arguments of this critics as following: 1) LWLocks are designed to be unfair. Their unfairness is downside of high performance in majority of scenarios. 2) Attempt to make LWLocks "more fair" would lead to unacceptable general performance regression. 3) If exclusive locks waiters are faced with infinite starvation, then that's not a problem of tLWLocks implementation, but that's a problem of particular use case. So, we need to fix LWLocks use cases, not LWLocks themselves. I see some truth in these arguments. But I can't agree that we shouldn't try to fix LWLocks unfairness. And I see following arguments for that: 1) It doesn't look like we can ever fix all the LWLocks use cases in the way, which would make infinite starvation impossible. Usage of NUMA systems is rising, and more LWLocks use cases are becoming pathological. For instance, there been much efforts placed to reduce ProcArrayLock contention, but on multicore machine with heavy readonly workload it might be still impossible to login or commit transaction. Or another recent example: buffer mapping lock becomes reason of eviction blocking [3]. 2) The situation of infinite exclusive locker starvation is much worse than just bad overall DBMS performance. We are doing our best on removing high contention points in PostgreSQL. It's very good, but it's an infinite race, assuming that new hardware platforms are arriving. But situation when you can't connect to the database when the system have free resources is much worse than situation when PostgreSQL doesn't scale well enough on your brand new hardware. 3) It's not necessary to make LWLocks completely fair in order to exclude infinite starvation of exclusive lockers. So, it's not necessary to put all the shared lockers into the queue. In the majority of cases, shared lockers might still go through directly, but on some event we might decide that it's too much and they should to the queue. So, taking into account all of above I made some experiments with patches making LWLocks "more fair". I'd like to share some intermediate results. I've written two patches for comparison. 1) lwlock-far-1.patch Shared locker goes to the queue if there is already somebody in the queue, otherwise obtains lock immediately. 2) lwlock-far-2.patch New flag LW_FLAG_FAIR is introduced. This flag is set when first shared locker in the row releases the lock. When LW_FLAG_FAIR is set and there is already somebody in the queue, then shared locker goes to the queue. Basically it means that first shared locker "holds the door" for other shared lockers to go without queue. I run pgbench (read-write and read-only benchmarks) on Amazon c5d.18xlarge virtual machine, which has 72 VCPU (approximately same power as 36 physical cores). The results are attached (lwlock-fair-ro.png and lwlock-fair-rw.png). We can see that for read-only scenario there is no difference between master and both of patches. That's expected, because in this scenario no exclusive lock is obtained, so all shared lockers anyway go without queue. For read-write scenario we can see regression in both of patches. 1st version of patch gives dramatic regression in 2.5-3 times. 2nd version of patch behaves better, regression is about 15%, but it's still unacceptable. However, I think idea, that some event triggers path of shared lockers to the queue, is promising. We should just select this triggering event better. I'm going to continue my experiments trying to make "more fair" LWLocks (almost) without performance regression. Any feedback is welcome. Links: 1. https://www.postgresql.org/message-id/0A3221C70F24FB45833433255569204D1F578E83%40G01JPEXMBYT05 2. https://www.postgresql.org/message-id/CAPpHfdsytkTFMy3N-zfSo+kAuUx=u-7JG6q2bYB6Fpuw2cD5DQ@mail.gmail.com 3. https://www.postgresql.org/message-id/CAPpHfdt_HFxNKFbSUaDg5QHxzKcvPBB5OhRengRpVDp6ubdrFg%40mail.gmail.com ------ Alexander Korotkov Postgres Professional: http://www.postgrespro.com The Russian Postgres Company
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: