I wrote:
> Aside from that, this seems like a good place to settle down, so I'm
> going to create a CF entry for this. I'll start more rigorous
> performance testing in the near future.
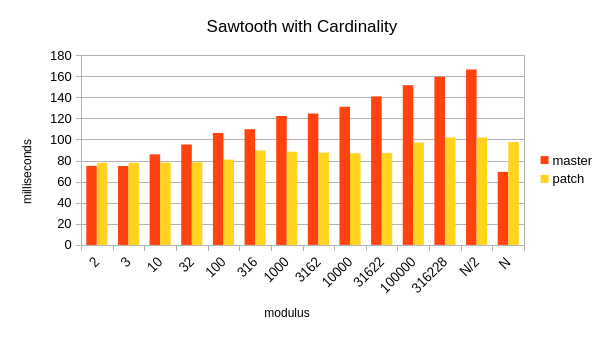
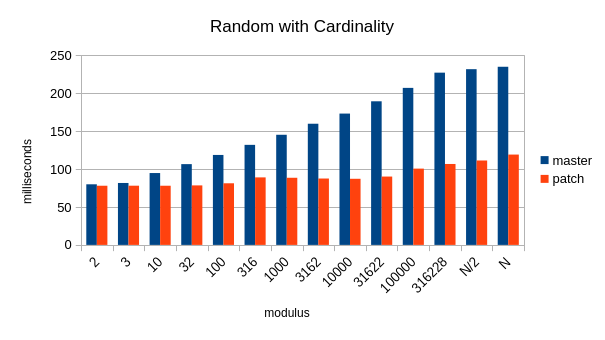
Here's the first systematic test results, with scripts. Overall, I'm
very pleased. With extremely low cardinality, it's close enough to our
B&M quicksort that any difference (a hair slower or faster) can be
discarded as insignificant. It's massively faster with most other
inputs, so I'll just highlight the exceptions:
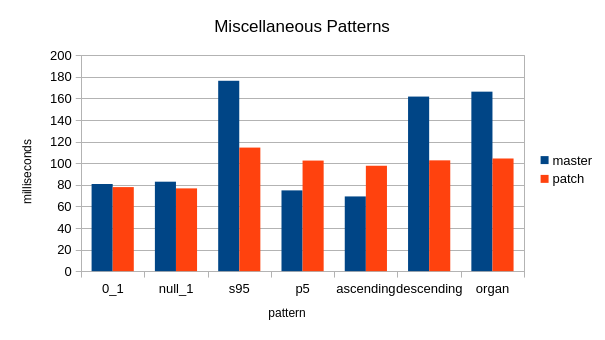
"ascending" - Our qsort runs a "presorted check" before every
partitioning step, and I hadn't done this for radix sort yet because I
wanted to see what the "natural" difference is. I'm inclined to put in
a single precheck at the beginning (people have come to expect that to
be there), but not one at every recursion because I don't think that's
useful. (Aside: that precheck at every recursion should be replaced by
something that detects ascending/descending runs at the very start,
but that's a separate thread)
"stagger" with multiplier = no. records / 2 - This seems to be a case
where the qsort's presorted check happens to get lucky. As I said
above, we should actually detect more sorted runs with something more
comprehensive.
"p5" - This is explicitly designed to favor the B&M qsort. The input
is 95% zeros, 2.5% negative numbers, and 2.5% positive numbers. The
first qsort pivot is pretty much guaranteed to be zero, and the first
partitioning step completes very quickly. Radix sort must do a lot
more work, but it not different than the amount of work it does with
other patterns -- it's much less sensitive to the input distribution
than qsort. In this case, there's a mix of negative and positive
bigints. That defeats common prefix detection, and the first iteration
deals into two piles: negative and non-negative. Then a few recursions
happen where there is only a single distinct byte, so no useful work
happens. I suppose I could try common prefix detection at every
recursion, but I don't think that's widely beneficial for integers.
Maybe the single-byte-plus comparator small qsort would help a little,
and I'm considering adding that anyway. In one sense this is the most
worrying, since there doesn't seem to be a widely-useful mitigation,
but in another sense it's the least worrying, since this case is
deliberately constructed to be at a disadvantage.
--
John Naylor
Amazon Web Services
{kind=link}
{kind=link}
{kind=link}
{kind=link}