Hello PostgreSQL community,
I have been working on a small extension that adds audio similarity
search to PostgreSQL. I would like to ask for your suggestions on the
approach and the SQL interface.
IDEA:
Once audio embeddings are generated, users can find similar audio with
a simple SELECT query:
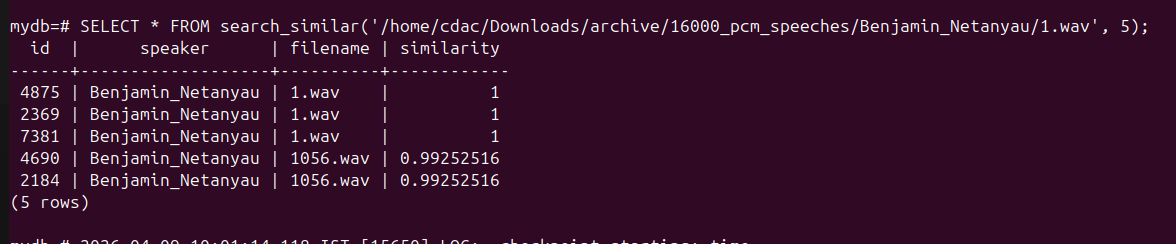
SELECT * FROM similar_audio(42, 5);
This returns the 5 most similar audio files to the file with id 42,
including similarity score, speaker name, and filename.
How it works
- Audio files are processed using MFCC (librosa) to produce
26‑dimensional embeddings.
- Embeddings are stored using `pgvector`.
- Similarity is cosine distance with an HNSW index for speed.
What I would like your feedback on
- Is the SELECT‑based interface intuitive enough for end users?
- Are there better patterns for similarity search in PostgreSQL?
- Any performance or design pitfalls I should be aware of?
The extension currently provides these functions:
- similar_audio(id, limit)– search by audio ID
- similar_audio_by_filename(filename, limit) – search by filename
- search_similar(file_path, limit) – search by full path
Requirements
- PostgreSQL 18+ (or 17/16)
- plpython3u and pgvector
- Python 3.11 with librosa, soundfile, numpy
I have tested it on 7,595 audio files (total ~10 hours) with good performance.
I would greatly appreciate any suggestions on improving the query
interface, indexing strategy, or embedding pipeline.
Thank you for your time.
{kind=link}