Re: Addressing buffer private reference count scalability issue - Mailing list pgsql-hackers
| From | Alexandre Felipe |
|---|---|
| Subject | Re: Addressing buffer private reference count scalability issue |
| Date | |
| Msg-id | CAE8JnxNqf=sYB-hfeHBEtXi+aC8jezqqukdgRuR2=t8nbetL=w@mail.gmail.com Whole thread |
| In response to | Re: Addressing buffer private reference count scalability issue (Andres Freund <andres@anarazel.de>) |
| Responses |
Re: Addressing buffer private reference count scalability issue
|
| List | pgsql-hackers |
Hi Hackers,
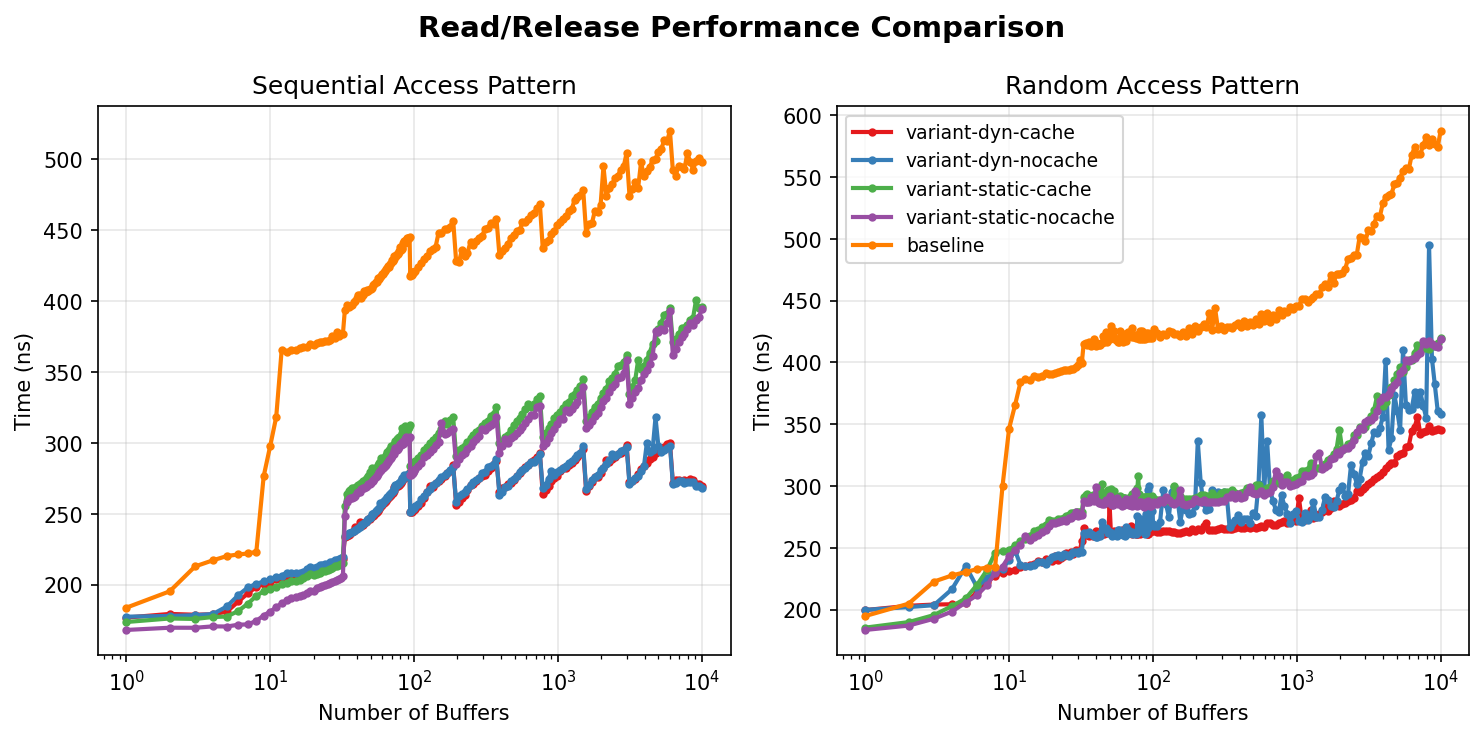
Please find attached version 2 of this patch and the results of the
ReadBuffer/ReleaseBuffer benchmark
For those who prefer plain text here goes an excerpt
baseline patch
num_buffers pattern
1 random 194.76 183.50
sequential 183.75 168.02
2 random 204.74 187.02
sequential 195.27 169.58
3 random 222.62 192.57
sequential 212.81 169.55
7 random 233.96 219.64
sequential 221.94 171.94
11 random 365.50 247.96
sequential 318.24 183.96
19 random 390.58 267.96
sequential 369.51 195.35
100 random 424.03 286.33
sequential 420.74 280.23
988 random 445.75 301.37
sequential 453.61 313.30
10000 random 587.13 418.91
sequential 497.92 394.10
baseline patch
num_buffers pattern
1 random 194.76 183.50
sequential 183.75 168.02
2 random 204.74 187.02
sequential 195.27 169.58
3 random 222.62 192.57
sequential 212.81 169.55
7 random 233.96 219.64
sequential 221.94 171.94
11 random 365.50 247.96
sequential 318.24 183.96
19 random 390.58 267.96
sequential 369.51 195.35
100 random 424.03 286.33
sequential 420.74 280.23
988 random 445.75 301.37
sequential 453.61 313.30
10000 random 587.13 418.91
sequential 497.92 394.10
On Sun, Mar 8, 2026 at 5:09 PM Andres Freund <andres@anarazel.de> wrote:
Hi,
On 2026-03-08 16:09:07 +0000, Alexandre Felipe wrote:
> 2.
>
> Refactoring reference counting: Before starting to change code and
> potentially breaking things I considered prudent to isolate it to limit the
> damage. This code was part of a 8k+ LOC file.
Not allowing, at least the fast paths, to be inlined will make the most common
cases measurably slower, I've tried that.
I made it inline in this time. I placed in a separate file, I am including the
.h at the top and the .c
> Here I assume that the buffer buffer sequence is independent enough from the
> array size, so I use the buffer as the hash key directly, omitting a hash
> function call.
I doubt that that's good enough. The hash table code relies on the bits being
well mixed, but you won't get that with buffer ids.
Introduced murmurhash32, it is noticeably worse for sequential access
(by buffer index), but has some mixing.
I'm rather sceptical that the overhead of needing to shift and mask is worth
it. I suspect we'll also want to add more state for each entry (e.g. I think
it may be worth getting rid of the io-in-progress resowner).
io-in-progress resowner name suggests that it runs only for reads...
so maybe it could be taken out of the way of buffer hits?
> REFCOUNT_ARRAY_ENTRIES=0: since the simplehash is basically some array
> lookup, it is worth trying to remove it completely and keep only the hash.
> For small values we would be trading a few branches for a buffer % SIZE,
> for the use case of prefetch where pin/unpin in a FIFO fashion, it will
> save an 8-entry array lookup, and some extra data moves.
I doubt that that's ok, in the vast majority of access we will have 0-2
buffers pinned. And even when we have pinned more buffers, it's *exceedingly*
common to access the same entry repeatedly (e.g. pin, lock, unlock, unpin),
adding a few cycles to each of those repeated accesses will quickly show up.
I brought back the array, but I eliminated the linear search.
1. USE_REFCOUNT_CACHE_ENTRY will enable the last entry cache.
2a. the dynamic array case
REFCOUNT_ARRAY_MAX_SIZE!=REFCOUNT_ARRAY_INITIAL_SIZE
will grow the array when it reaches a certain level of occupation.
I have set the default occupation level to 86% so that, if enabled, for a
random input it will grow when we have about 2*size pins in total.
If we find a sequential pattern then it will grow without growing the hash table.
For the array lookup I don't use a hash, so for small number of pins
it will be very fast.
2b. the static case
REFCOUNT_ARRAY_MAX_SIZE==REFCOUNT_ARRAY_INITIAL_SIZE
will use a static array, just as we had before and will not perform the linear
search. It still has to read the size and do mask input.
I tested the 4 variations and the winner is with the static array without
the cache for the last entry.
I increased the array size from 8 to 32, since you suggested before that
that this could help. At that point it would have the tradeoff of a longer
linear search, so it may help even more now.
> Incrementing/decrementing the count continue the same, just using
> 4 instead of 1, lock mode access will require one or two additional
> bitwise operations.
>
> No bit-shifts are required.
I don't know how that last sentence can be true, given that:
> -struct PrivateRefCountEntry
> +#define PRIVATEREFCOUNT_LOCKMODE_MASK 0x3
> +#define ONE_PRIVATE_REFERENCE 4 /* 1 << 2 */
> +
> +#define PrivateRefCountGetLockMode(d) ((BufferLockMode)((d) & PRIVATEREFCOUNT_LOCKMODE_MASK))
> +#define PrivateRefCountSetLockMode(d, m) ((d) = ((d) & ~PRIVATEREFCOUNT_LOCKMODE_MASK) | (m))
> +#define PrivateRefCountGetRefCount(d) ((int32)((d) >> 2))
> +#define PrivateRefCountIsZero(d) ((d) < ONE_PRIVATE_REFERENCE)
Involves shifts at least in PrivateRefCountGetRefCount()..
Yes, there was some unintended code there.
I am adding SharedBufferHasSingleRef to replace the (...) == 1 checks.
The actual count is used only for debugging, so the shift there shouldn't
be a problem.
Regards,
Alexandre
Attachment
{kind=link}
pgsql-hackers by date: