Re: index prefetching - Mailing list pgsql-hackers
| From | Alexandre Felipe |
|---|---|
| Subject | Re: index prefetching |
| Date | |
| Msg-id | CAE8JnxN_EwnTLLMWGhvgwaomYZ0ysm7NeogA-BqBd=Rs3S7Oqw@mail.gmail.com Whole thread |
| In response to | Re: index prefetching (Peter Geoghegan <pg@bowt.ie>) |
| Responses |
Re: index prefetching
Re: index prefetching Re: index prefetching |
| List | pgsql-hackers |
Hi,
I decided to test this PR.
I didn't take much time to go through the thread or the code in detail yet. But I have my first benchmark results and I would like to share.
EXPERIMENT
I tested [CF 4351] v10 - Index Prefetching
I created a table with 100k rows and
Sequential is, as guessed, 1,2,3,4 (indexed)
Periodic is a quasi random (i * jump) % num_rows, where gcd(jump, num_rows) = 1, guarantee that there are no repeated entries (indexed)
Random is a `row_number() over (order by random())` (indexed)
The payload is a fixed 200 character long string, just to make it more realistic.
For the tests, I disable sorting, sequential scans, index only scans and bitmap scans.
Since buffer cache always has a significant impact on the query performance, I shuffled the tests, and tried to adjust for the number of buffer hit/read, but later I found that the best way to control that was to use a table small enough to be entirely held in cache, and evict the buffers.
* off: buffers are kept in cache
* pg: buffers evicted from postgres pg_buffercache_evict from pg_buffercache extension.
* os: supported only in python, I separated the buffer eviction in purge_cache as it requires sudo (tested only in MacOS).
I varied
* max_parallel_workers_per_gather (although I guess it wasn't exploited),
* enable_index_prefetch
* the column used as sorting key and, as a result, the index used.
* and buffer eviction mode.
Running from python with psycopg
SUMMARY
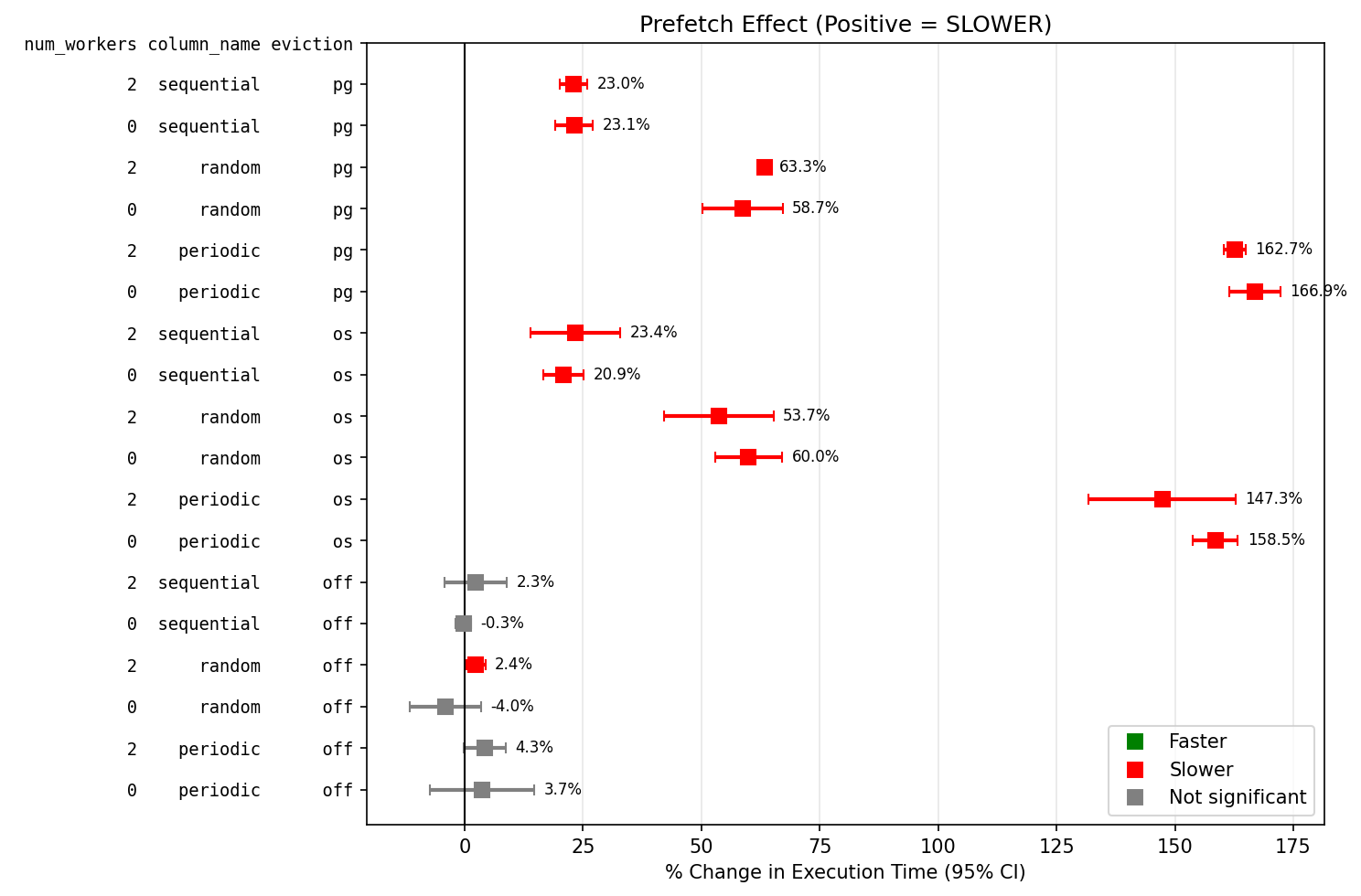
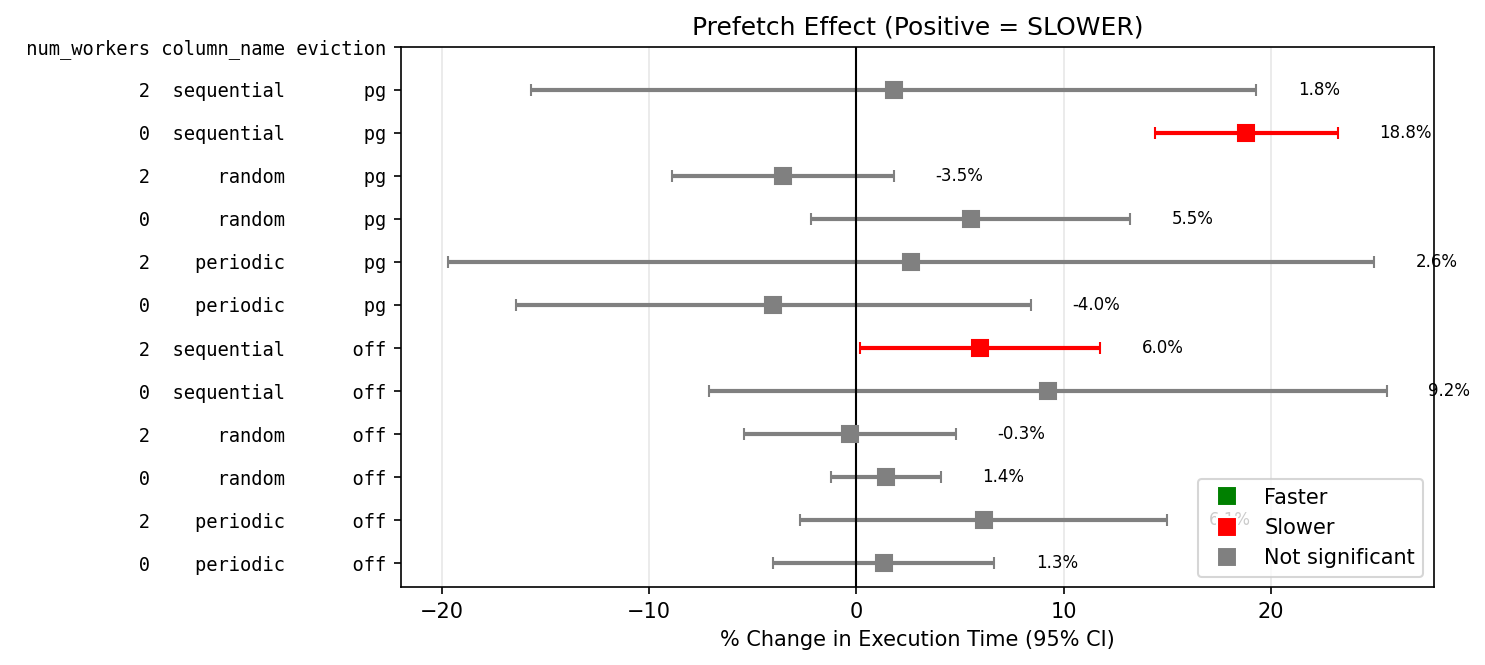
I could not see the expected positive impact and when using the python script and buffers evicted prefetch had a detrimental impact.
APPENDIX
psql run
column_name io_method num_workers evict n off_ms on_ms pct_change ci_low ci_high
periodic worker 0 off 10 172.4 182.8 6.024162 -3.7 15.7
periodic worker 0 pg 10 222.7 214.8 -3.539448 -13.0 5.9
periodic worker 2 off 10 173.5 172.7 -0.442660 -1.6 0.7
periodic worker 2 pg 10 226.3 213.2 -5.795049 -16.9 5.3
random worker 0 off 10 173.3 174.1 0.476657 -1.0 2.0
random worker 0 pg 10 216.6 218.1 0.704020 -2.8 4.3
random worker 2 off 10 182.7 175.3 -4.031139 -15.6 7.5
random worker 2 pg 10 217.2 213.7 -1.586813 -4.4 1.2
sequential worker 0 off 10 131.1 130.4 -0.568573 -3.4 2.3
sequential worker 0 pg 10 150.7 188.2 24.923924 22.2 27.6
sequential worker 2 off 10 129.7 130.2 0.421814 -1.0 1.9
sequential worker 2 pg 10 151.0 184.1 21.925935 19.5 24.3
periodic worker 0 off 10 172.4 182.8 6.024162 -3.7 15.7
periodic worker 0 pg 10 222.7 214.8 -3.539448 -13.0 5.9
periodic worker 2 off 10 173.5 172.7 -0.442660 -1.6 0.7
periodic worker 2 pg 10 226.3 213.2 -5.795049 -16.9 5.3
random worker 0 off 10 173.3 174.1 0.476657 -1.0 2.0
random worker 0 pg 10 216.6 218.1 0.704020 -2.8 4.3
random worker 2 off 10 182.7 175.3 -4.031139 -15.6 7.5
random worker 2 pg 10 217.2 213.7 -1.586813 -4.4 1.2
sequential worker 0 off 10 131.1 130.4 -0.568573 -3.4 2.3
sequential worker 0 pg 10 150.7 188.2 24.923924 22.2 27.6
sequential worker 2 off 10 129.7 130.2 0.421814 -1.0 1.9
sequential worker 2 pg 10 151.0 184.1 21.925935 19.5 24.3
psycopg run
column_name io_method num_workers evict n off_ms on_ms pct_change ci_low ci_high
periodic worker 0 off 10 186.7 193.7 3.701950 -7.3 14.7
periodic worker 0 os 10 207.0 535.2 158.507266 153.7 163.3
periodic worker 0 pg 10 201.2 537.0 166.923995 161.5 172.3
periodic worker 2 off 10 181.2 189.0 4.303359 -0.2 8.8
periodic worker 2 os 10 221.7 548.2 147.322934 131.8 162.9
periodic worker 2 pg 10 203.1 533.5 162.688738 160.4 165.0
random worker 0 off 10 194.6 186.8 -3.986974 -11.5 3.5
random worker 0 os 10 211.4 338.2 59.979252 52.9 67.1
random worker 0 pg 10 212.3 336.8 58.686711 50.2 67.1
random worker 2 off 10 183.3 187.7 2.364585 0.4 4.4
random worker 2 os 10 222.5 341.9 53.659704 42.1 65.2
random worker 2 pg 10 204.1 333.3 63.348746 62.3 64.4
sequential worker 0 off 10 129.9 129.5 -0.260586 -1.9 1.3
sequential worker 0 os 10 150.9 182.4 20.909424 16.6 25.2
sequential worker 0 pg 10 150.3 185.0 23.132583 19.2 27.1
sequential worker 2 off 10 129.9 132.9 2.323179 -4.3 9.0
sequential worker 2 os 10 153.8 189.8 23.402255 13.9 32.9
sequential worker 2 pg 10 151.1 185.9 22.997500 20.1 25.9
periodic worker 0 off 10 186.7 193.7 3.701950 -7.3 14.7
periodic worker 0 os 10 207.0 535.2 158.507266 153.7 163.3
periodic worker 0 pg 10 201.2 537.0 166.923995 161.5 172.3
periodic worker 2 off 10 181.2 189.0 4.303359 -0.2 8.8
periodic worker 2 os 10 221.7 548.2 147.322934 131.8 162.9
periodic worker 2 pg 10 203.1 533.5 162.688738 160.4 165.0
random worker 0 off 10 194.6 186.8 -3.986974 -11.5 3.5
random worker 0 os 10 211.4 338.2 59.979252 52.9 67.1
random worker 0 pg 10 212.3 336.8 58.686711 50.2 67.1
random worker 2 off 10 183.3 187.7 2.364585 0.4 4.4
random worker 2 os 10 222.5 341.9 53.659704 42.1 65.2
random worker 2 pg 10 204.1 333.3 63.348746 62.3 64.4
sequential worker 0 off 10 129.9 129.5 -0.260586 -1.9 1.3
sequential worker 0 os 10 150.9 182.4 20.909424 16.6 25.2
sequential worker 0 pg 10 150.3 185.0 23.132583 19.2 27.1
sequential worker 2 off 10 129.9 132.9 2.323179 -4.3 9.0
sequential worker 2 os 10 153.8 189.8 23.402255 13.9 32.9
sequential worker 2 pg 10 151.1 185.9 22.997500 20.1 25.9
Regards,
Alexandre
On Mon, Feb 9, 2026 at 10:45 PM Peter Geoghegan <pg@bowt.ie> wrote:
On Fri, Jan 30, 2026 at 7:18 PM Peter Geoghegan <pg@bowt.ie> wrote:
> Attached is v9.
Attached is v10. There are 2 major areas of improvement in this latest revision:
1. We have enhanced the read stream callback (heapam_getnext_stream,
which is added by
v10-0005-Add-prefetching-to-index-scans-using-batch-inter.patch),
making it yield at key intervals. When we yield, we temporarily
suspend prefetching -- but only for long enough to give the scan the
opportunity to return one more matching tuple (don't confuse yielding
with pausing; we do both, but the goals are rather different in each
case).
Yielding like this keeps the scan responsive during prefetching: the
scan should never go too long without returning at least one tuple
(except when that just isn't possible at all). Testing has shown that
keeping the scan responsive in this sense is particularly important
during scans that appear in "ORDER BY ... LIMIT N" queries, as well as
during scans that feed into certain merge joins. IOW, it is
particularly important that we "keep the scan responsive" whenever it
has the potential to allow the scan to shut down before it has
performed work that turns out to be unnecessary (though it also seems
to have some benefits even when that isn't the case).
There is a complex trade-off here: we want to yield when we expect
some benefit from doing so. But we don't want to yield when doing so
risks compromising the read stream's ability to maintain an adequate
prefetch distance. There are comments in heapam_getnext_stream that
describe the theory in more detail. There are heuristics that were
derived using adversarial benchmarking/stress-testing. I'm sure that
they need more work, but this does seem like roughly the right idea.
Note that we now test whether the scan's read stream is using its
fast-path mode (read stream uses this when the scan reads heap pages
that are all cached).
2. A new patch (v10-0007-Limit-get_actual_variable_range-to-scan-one-inde.patch)
compensates for the fact that the main prefetching commit removes
get_actual_variable_range's VISITED_PAGES_LIMIT mechanism. Since
VISITED_PAGES_LIMIT cannot easily be ported over to the new table AM
interface selfuncs.c now uses.
I described the problem that we need to address when I posted v9:
> selfuncs.c problem
> ------------------
>
> Also worth noting that we recently found a problem with selfuncs.c:
> the VISITED_PAGES_LIMIT stuff in selfuncs.c is broken right now. v9
> tears that code out, pending adding back a real fix (earlier versions
> of the patch had VISITED_PAGES_LIMIT, but it didn't work).
>
> The underlying problem is that the existing VISITED_PAGES_LIMIT design
> is incompatible with our new table_index_getnext_slot interface. The
> new interface doesn't stop scanning until it is able to at least
> return 1 tuple. But VISITED_PAGES_LIMIT was invented precisely because
> get_actual_variable_endpoint's index scans took far too long, even
> though they're only ever required to locate 1 tuple. So that just
> won't work.
>
> We'll need to invent some kind of API that directly acknowledges the
> needs of the selfuncs.c caller, and others like it. Doing it in an
> ad-hoc way just doesn't seem possible anymore. That will have to wait
> for the next revision, though (or the one after that).
The new patch deals with the problem in a completely different way,
and at a completely different layer: it adds a new
IndexScanDescData.xs_read_extremal_only field, set only by
get_actual_variable_range. When nbtree sees that the field has been
set, it gives up after scanning only one leaf page (the page that
contains extremal values that are of interest to
get_actual_variable_range). Note that we completely stop caring about
heap page fetches with this new approach.
There are good reasons to believe that the new
IndexScanDescData.xs_read_extremal_only approach will solve existing
problems with VISITED_PAGES_LIMIT. Recent benchmarking from Mark
Callaghan [1] (which I've independently recreated with my own minimal
test suite) shows that VISITED_PAGES_LIMIT becomes completely
ineffective, once we reach a tipping point where many index tuples at
one end of the index all have their LP_DEAD bit set.
I'm going to start a new thread to discuss the issues in this area
later today. I'm aiming to fix an existing, independent issue in this
new patch, so it makes sense to discuss it on a completely separate
thread.
[1] https://smalldatum.blogspot.com/2026/01/cpu-bound-insert-benchmark-vs-postgres.html
--
Peter Geoghegan
Attachment
{kind=link}
{kind=link}
pgsql-hackers by date: